分布式數(shù)據(jù)清洗系統(tǒng)設計
2020-03-07 06:44:26
網(wǎng)絡安全技術與應用 2020年2期
(陜西科技大學電子信息與人工智能學院 陜西 710021)
1 引言
隨著大數(shù)據(jù)的發(fā)展,數(shù)據(jù)[1]已經成為一個企業(yè)的生存根基,對于企業(yè)來說,合理的利用所掌握的數(shù)據(jù)資源,對企業(yè)的未來發(fā)展至關重要。數(shù)據(jù)倉庫[2]技術作為海量數(shù)據(jù)的存儲之地,為企業(yè)進行數(shù)據(jù)分析[3]時提供了一種解決方案,而在數(shù)據(jù)倉庫的構建中,數(shù)據(jù)清洗[4]則為最重要的一個環(huán)節(jié)。
數(shù)據(jù)清洗分為三個步驟,即抽取[5]、轉換[6]、加載[7]。當數(shù)據(jù)量增大時,傳統(tǒng)的清洗技術已無法滿足企業(yè)之間的技術支持,所以本文結合MapReduce 分而治之的思想[7]設計出分布式數(shù)據(jù)清洗系統(tǒng),具體如下:
(1)使用Hadoop 集群、HDFS[8]、MapReduce 等大數(shù)據(jù)相關技術進行集群搭建,然后將清洗后的數(shù)據(jù)加載到Hive[9]數(shù)據(jù)倉庫中。
(2)采用前后端分離思想對分布式數(shù)據(jù)清洗系統(tǒng)進行流程設計、架構設計、功能設計。
(3)采用改進后的分區(qū)聚合算法對Reduce 操作進行優(yōu)化,避免數(shù)據(jù)在清洗過程中造成數(shù)據(jù)積累,從而發(fā)生數(shù)據(jù)傾斜等問題。
2 分布式數(shù)據(jù)清洗系統(tǒng)設計
2.1 流程設計
分布式數(shù)據(jù)清洗系統(tǒng)以MapReduce[10]為設計核心,MapRduce將采集過來的日志數(shù)據(jù)通過Map和Reduce 進行操作,Map端從HDFS 分布式文件系統(tǒng)中讀取文件,然后將這個文件進行分割,不同的分片執(zhí)行不同的Map 任務,再經過shuffle 階段進入到Reduce階段進行聚合操作,流程圖如圖1所示:

圖1 MapReduce 流程圖
具體操作步驟如下:
(1)從HDFS中讀取文件,將這個文件進行分片,劃分成多個Key/Value 鍵值對。
(2)Map 根據(jù)Key計算Value值,然后進行統(tǒng)計。
(3)Combiner對每個分區(qū)Map所對應的key值進行聚合,將Map端的輸出作為Combiner的輸入。
(4)Partition 針對分片進行處理,將Combiner 統(tǒng)計出的key 進行分區(qū)。
(5)Reduce 完成最終的數(shù)據(jù)聚合,存入數(shù)據(jù)倉庫中。
2.2 架構設計
由于分布式數(shù)據(jù)清洗系統(tǒng)是對接日志分析的子系統(tǒng),其數(shù)據(jù)最終加載到數(shù)據(jù)倉庫中,所以在視圖層將不做深入探討,只將清洗過后的數(shù)據(jù)展示出來。按照分層思想將從四個層級進行設計,分別為視圖層、控制層、業(yè)務處理層、存儲層,并包括兩個主要的子系統(tǒng)模塊,分別是Mysql后端數(shù)據(jù)管理模塊和以MapReduce計算為主的數(shù)據(jù)清洗模塊,系統(tǒng)架構圖如圖2所示。
如圖2所示:系統(tǒng)總體設計包括視圖層、控制層、業(yè)務處理層以及存儲層四個層次。
(1)視圖層:主要是顯示清洗過后的數(shù)據(jù),前端界面采用HTML、CSS、JavaScript、JQuery[11]、Ajax[12]進行設計。
(2)控制層:在數(shù)據(jù)清洗過程中通過Map和Reduce 操作對海量數(shù)據(jù)實現(xiàn)快速過濾,去重,并采用改進的分區(qū)聚合算法來提高清洗效率。
(3)業(yè)務處理層:主要進行海量數(shù)據(jù)的批處理,數(shù)據(jù)集為旅游景點產生的log日志,通過Flume 將日志數(shù)據(jù)從服務器中采集過來上傳到HDFS中,運用Mapreduce 編程對日志數(shù)據(jù)進行抽取、轉換、加載等操作,完成一系列的清洗功能之后,存儲到數(shù)據(jù)倉庫中。
(4)存儲層:保存清洗之后的數(shù)據(jù),存儲工具包括HBase[13]、Hive、Mysql 等,為視圖層提供數(shù)據(jù)支持。
2.3 功能設計
分布式數(shù)據(jù)清洗系統(tǒng)包括數(shù)據(jù)界面展示模塊,數(shù)據(jù)清洗模塊、資源管理模塊、配置模塊等。本系統(tǒng)應用于各子系統(tǒng)并結合改進的分區(qū)聚合算法對大批量數(shù)據(jù)進行清洗,以保證日志數(shù)據(jù)的精準度和提升數(shù)據(jù)的清洗效率。分布式數(shù)據(jù)清洗系統(tǒng)功能模塊圖如圖3所示:

圖3 分布式數(shù)據(jù)清洗系統(tǒng)功能模塊圖
分布式數(shù)據(jù)清洗系統(tǒng)主要用于大數(shù)據(jù)集群之間節(jié)點配置、數(shù)據(jù)清洗之后的資源統(tǒng)計,系統(tǒng)登錄之后分為超級管理員和普通管理員兩類,超級管理員可以執(zhí)行所有權限,普通管理員可以進行集群配置和日志數(shù)據(jù)的清洗,數(shù)據(jù)清洗管理主要通過MapReduce 進行清洗,結合算法進行優(yōu)化,將清洗之后的數(shù)據(jù)存儲在數(shù)據(jù)倉庫中,資源統(tǒng)計管理進行數(shù)據(jù)展示以及數(shù)據(jù)統(tǒng)計。
3 清洗技術
3.1 數(shù)據(jù)清洗概述
數(shù)據(jù)清洗主要是對臟數(shù)據(jù)進行一個重新檢查、去重、過濾的過程,其中主要經過數(shù)據(jù)抽取,數(shù)據(jù)轉換,數(shù)據(jù)加載三個階段,目的在于刪除不合格數(shù)據(jù),只保留有用數(shù)據(jù),因為本文抽取的是從web網(wǎng)站中生成的日志數(shù)據(jù),所以相對而言主要是提高數(shù)據(jù)清洗的轉換效率。
針對清洗的轉換效率進行研究,重點解決數(shù)據(jù)傾斜效率問題。
3.2 改進的分區(qū)聚合算法
聚合處理一般發(fā)生在Shuffle 階段,在MapReduce中,Shuffle操作執(zhí)行前的Map 被分為一個階段,執(zhí)行后Reduce 會分為一個階段,但在一些情況下,由于第一階段產生的數(shù)據(jù)中,某些字段的Key值過大,那么在聚合時,就會出現(xiàn)99%的分區(qū)已經執(zhí)行完畢而1%的分區(qū)執(zhí)行時間過長的現(xiàn)象,就會出現(xiàn)數(shù)據(jù)傾斜。
如圖4所示:

圖4 Shuffle 發(fā)生數(shù)據(jù)傾斜
從圖4中可以看出,Shuffle 操作過程中,按照Key 鍵對數(shù)據(jù)進行重新劃分,其中Key(Tom)對應的數(shù)據(jù)量遠遠大于key(Name,China)的數(shù)量,這將導致后續(xù)數(shù)據(jù)清洗過程中,Task1的清洗時間遠遠超過Task2和Task3的運行時間總和,從而造成數(shù)據(jù)傾斜甚至內存溢出。
基于上述問題,本文提出改進后的分區(qū)聚合算法,將聚合階段分成兩階段,先局部聚合,再全局聚合。算法執(zhí)行示意圖如圖5所示:
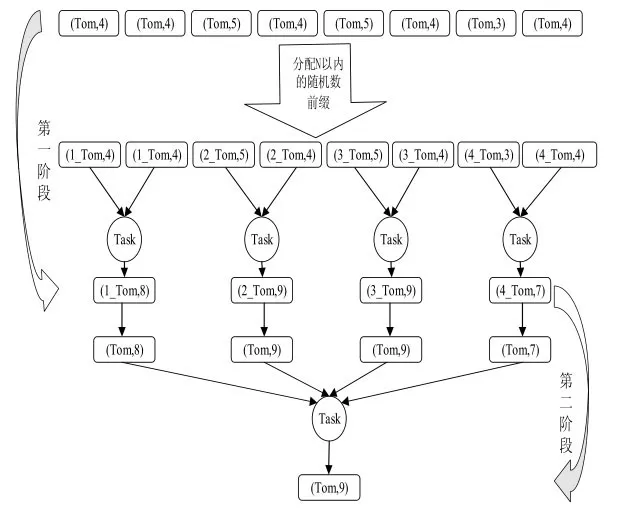
圖5 數(shù)據(jù)預處理算法
如圖5所示:第一階段對Key(Tom)加上N 以內的隨機數(shù)前綴,此時將Key(Tom)分散成N 份,然后對N 份Key(Tom)進行局部計算,產生N個計算結果。第二階段去除N 份Key(Tom)的隨機數(shù)前綴,然后做全局聚合,最終計算出結果。
4 實驗分析對比
4.1 實驗環(huán)境
為了對比傳統(tǒng)清洗系統(tǒng)與分布式清洗系統(tǒng)的清洗效率,本實驗進行Hadoop 進群搭建,采取5 臺服務器進行部署,分別命名為Hadoop1至Hadoop5 其中Hadoop1為主節(jié)點,Hadoop2 至Hadoop5為從節(jié)點,每臺服務器均安裝部署Centos-7,Hadoop-2.6.5,Jdk-8u191-linux-x64,Zookeeper-3.4.5,內存配置為8G、處理器內核總數(shù)為4,每個處理器的內核數(shù)量為2,磁盤大小為100G,集群開發(fā)工具使用IDEA。
4.2 實驗數(shù)據(jù)
本文實驗數(shù)據(jù)來自智慧咸陽大數(shù)據(jù)分析平臺中的一個旅游子系統(tǒng)產生的日志數(shù)據(jù),現(xiàn)采用200萬、400萬、600萬與800萬條日志數(shù)據(jù)進行實驗測試。
4.3 實驗結果
本實驗將從兩個方面進行大數(shù)據(jù)清洗效率對比。
(1)傳統(tǒng)清洗系統(tǒng)和分布式清洗系統(tǒng)在不同數(shù)據(jù)樣例下的運行速率,實驗結果如圖5所示:
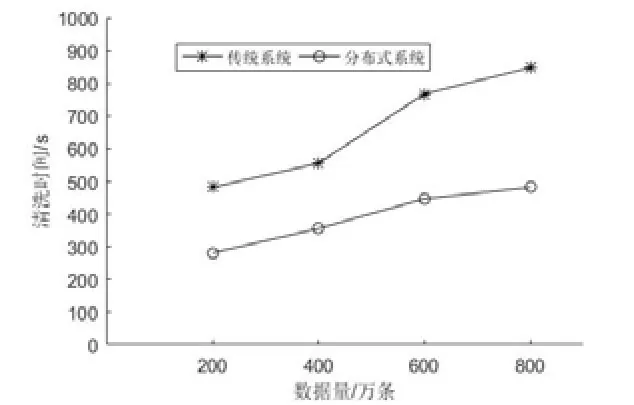
圖6 傳統(tǒng)系統(tǒng)與分布式系統(tǒng)清洗時間對比
如圖6所示,隨著數(shù)據(jù)的增長,兩種清洗方式所用的時間折線圖斜率逐漸變緩,但分布式清洗數(shù)據(jù)所用時間明顯少于普通系統(tǒng)所用時間。
(2)在分布式數(shù)據(jù)清洗系統(tǒng)中,使用改進的分區(qū)聚合算法和未使用改進的分區(qū)聚合算法進行實驗對比,實驗如圖7所示。實驗結果如圖7所示,在數(shù)據(jù)量相同時,改進的分區(qū)聚合算法清洗時間更短,效率更高。
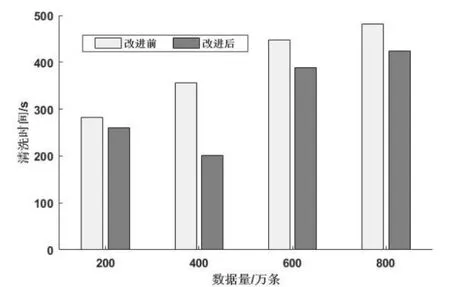
圖7 算法改進前后數(shù)據(jù)清洗時間對比
5 結束語
本文實現(xiàn)了分布式日志清洗系統(tǒng)設計,實驗結果表明相比于傳統(tǒng)清洗系統(tǒng)來說,清洗效率大大提升,能夠高效、快速地完成大數(shù)據(jù)的清洗任務。
(1)通過Hadoop,F(xiàn)lume,MapReduce 等大數(shù)據(jù)組件進行系統(tǒng)搭建。
(2)提出改進的分區(qū)聚合算法,對Reduce端進行優(yōu)化,避免數(shù)據(jù)在清洗過程中造成數(shù)據(jù)積累,從而發(fā)生數(shù)據(jù)傾斜等問題。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
工業(yè)設計(2022年8期)2022-09-09 07:43:20
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
