JAVA在分布式機群計算中數據共享應用
2020-03-07 06:35:04
網絡安全技術與應用 2020年2期
(廈門安勝網絡科技有限公司 福建 361008)
隨著分布式系統及各種云系統,大數據應用的出現,人們對數據的計算需求越來越高,尤其對目前機器計算能力不能滿足人們對海量數據的分析和統計,機群計算的架構便時興起來,如分布式集群計算,云計算,邊緣計算等。在這些分散的機器間的計算數據,各計算機器分任務跑批數據,對數據進行清洗、集成、變換、歸約等處理[1],急切需要協同作業任務來協調各機器間的任務管理和數據匯聚。如果機器間有了一份共享同步數據區塊的話,那么不同機器間的協同作業問題便能很好的得到解決,包括分布式系統間的SESSION 同步問題。本文以JAVA語言為基礎編程語言說明分布式機群的數據共享及同步。
1 機群計算中數據塊共享研究
圖1為機群服務網絡圖。S1到S10為各計算服務,這里我們以一臺機器作為一個單實例進程來說明多臺機器或多個JVM 實例間的數據共享。機群間的數據共享多以星狀架構方案為主。其中中心服務也可以是機群服務,向外暴露統一的服務接口,當然也遵循CAP 定理:保證一致性Consistency,可用性[2]Availability,分區容錯Partition tolerance。其中共享數據塊可以通過值鍵對的形式進行傳輸存儲,也可進行系列化等形式進行傳輸存儲。下面介紹幾種共享數據的實現模式。
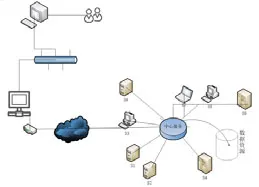
圖1 機群服務網絡圖
1.1 協同服務模式
創建一個(也可以是一組)專門的服務,讓其他任務都能訪問。如SOCKET、WEBSERVICE、RPC 等服務,通過雙方約定服務標準進行協同作業。把要同步共享的數據都傳到這個協同服務上[3],由協同服務統一處理,響應給各任務請求,從而實現數據同步及數據一致性。

圖2 機群服務星狀圖—協同服務
(1)SOCKET服務方式:服務端通過套接字服務對端口進行監聽,與客戶端通過字節流傳輸數據,從而實現數據的共享。
(2)WEBSERVICE服務方式:可以通過APACHE的Axis2進行搭建,也可以通過SPRINGBOOT微服務進行REST服務的構建,傳輸協議可以為XML或JSON等進行字符串系列化[4],再用標準工具對其進行解構生成OO對象或是MAP值鍵,從而實現數據的共享。
1.2 數據中心模式
各服務端把數據匯聚存到數據集中(結構化數據庫MYSQL、ORACLE 等,非結構化數據庫MONGO 等,緩存服務(REDIS,MENCACHE 等或消息隊列(如KALFKA 等)。各服務機器訪問統一的數據庫或訂閱主題服務從而獲取共享數據。
(1)數據庫中心方式:各服務器通過JDBC 或ODBC 等方式把數據系列化后存入結構化數據庫表,各服務器通過和中心數據庫進行交互通信實現對數據的刪除更新獲取操用,從而共享及同步數據。
(2)緩存服務中心方式:各服務器通過值鍵對數據構造MAP數據存儲到緩存,各服務再通過訪問統一緩存服務刪除更新獲取共享數據。
(3)消息隊列方式:各服務器通過消息隊列服務把數據以值鍵對的形式存入消息隊列中,再通過消息隊列獲取共享數據,以實現數據共享。
以KALFKA為例:
通過值鍵對,進行主題消息推送代碼如下:

對主題進行接收:

各服務器通過對KAFKA服務中的主題信息進行消息處理,從而實現數據共享。
1.3 通過廣播等方式
對各實例進程進行通知,如Hazelcast 等。以下以Hazelcast為例:
Hazelcast是一個內存分布式計算平臺,用于管理數據并并行執行應用程序。它用JAVA 編寫,與其他一些內存數據庫(如redis)不同,Hazelcast是多線程的,這意味著可從所有可用的CPU內核中受益。與其他內存數據網格不同,它設計用于分布式環境。它支持每個群集無限數量的map和緩存。根據基準測試,Hazelcast在獲取數據方面比Redis 快56%,在設置數據方面比Redis 快44%。項目中加入只需引入JAR 包.Hazelcast是集群的,數據可以在許多應用程序實例之間共享。
以下為Hazelcast存取數據塊的代碼:
存入:

2 機群計算中數據共享作用
有了共享數據,在機群中就可以方便我們在機群中進行分布式計算。把一個大的需要高性能要求的任務進行分解為多個的低性能要求的子任務進程或線程進行計算,通過共享數據塊中的置標識值位來跟進任務的執行狀態,當所有的數據都計算完成后再把共享數據塊中的標識置完結狀態,各子任務把結果進行匯聚,從而得到并行計算后的結果,大大減少計算時間,讓響應更實時。
有了共享數據塊,SESSION的共享就方便了。把SESSION對象直接通過鍵值對存入共享數據塊,通過MapReduce模式進行對SESSION 進行增刪改查,從而實現SESSION 共享。
有了共享數據塊,各服務就不再獨立,他們互相聯系、相互協用、互補資源,讓服務資源得到合理應用,也方便各服務狀態的指標的匯聚和管理,方便各服務器間的負載分配。
3 小結
分布式計算中,數據共享占據了至關重要的地位,只有通過數據共享,才能達到各機器間通信,各機器群間的協調處理,共同計算,為計算縮減時間,為計算贏取時間。
猜你喜歡
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
