基于LSTM 神經網絡的電網文本分類方法
2020-03-05 09:33:34張云翔饒竹一
現代計算機 2020年2期
張云翔,饒竹一
(深圳供電局有限公司,深圳518001)
0 引言
在電力物聯網高速發展的今天,電網系統中有著大量的電子文本,如電網客戶信息、電網業務數據等。而由于當前電網信息管理混亂,數據模型未統一,同一信息可能因為不同業務格式存在文本上的差異,沒有統一的標準,這會嚴重影響電網系統的各項業務效率和成本。因此,對電網系統中的海量電子文本進行檢索和信息提取,再進一步進行分類,就顯得十分有意義。
文本分類(Text Classification)是自然語言處理(NLP)的主要研究問題之一,指的是在一個被事先定義好的固定類別中根據文本的特征將給定的文本對象進行分類的技術。典型的應用有判定垃圾郵件、網頁自動分類[1]、情感分類[2]和新聞個性化推薦[3]等。在20 世紀50 年代,單純依靠文檔中出現與類名相同的詞來進行文檔分類的詞匹配法[4]出現,之后又出現了向量空間模型[5]和知識工程,但這些算法十分依賴于人力,且方法十分簡單,分類結果并不能滿足要求。之后,隨著機器學習算法的發展,SVM 模型[6]、貝葉斯網絡[7]、決策樹[8]等算法開始應用于文本分類。現如今,人工智能(AI)技術的快速發展使文本分類得到了新的發展,其成為了AI 子領域自然語言處理(NLP)的一個重要分支,神經網絡,如卷積神經網絡(CNN)[9]與深度神經網絡(DNN)[10]也越來越多的應用到文本分類中來。但這些傳統的網絡存在梯度消失問題,無法處理長時間序列數據,基于此,專門用于處理時間序列數據的長短期記憶網絡(LSTM)被提出,本文便是利用LSTM 神經網絡來進行電網文本分類。
1 方法準備
1.1 自然語言處理NLP
自然語言處理(NLP)是一種人機交互方式,目的是讓計算機理解人類所用的自然語言,從而實現諸如人機交互或是語言翻譯等功能[11]。它涉及人工智能、語言學和計算機科學三大領域,是人工智能的重要分支。從語言學角度,語言可以分為形式語言和自然語言,形式語言是人為創造的用數字等符號描述的語言,可以被機器處理,如編程語言、化學符號等,而自然進化的語言,如人類的語言就是自然語言,跟形式語言相比,它缺乏固定的格式,存在大量歧義語句、相似語句等,使得其無法直接被機器所理解。自然語言處理便是研究如何對自然語言進行加工處理,從而實現人機交互的學科。
NLP 的研究問題主要包括信息檢索、機器翻譯、機器寫作、語音識別、文本分類、文本挖掘和文本匹配等,其中文本分類便是本文的研究重點,由于自然語言是由大量人群進行長時間對話交流演變而來的語言,所以它是一種“經驗主義”的語言模型,即基于統計的模型。因此,將大規模的真實語言文本進行收集整理形成一個真實語言庫,再運用統計技術對該語言庫進行分析,就可以進行語言文本分類。文本分類一般分為文本預處理,文本特征提取和文本分類幾大部分。
1.2 LSTM神經網絡
長短期記憶網絡(LSTM)是一種專門用于處理時間序列數據的網絡[12],傳統的RNN 神經網絡的神經元是將輸入運用函數進行計算后進行輸出的單元,而LSTM 將神經元變為記憶單元,每個記憶單元由輸入門、遺忘門和輸出門構成,其單元結構圖如圖1 所示。其中長期狀態c 用于存儲長期記憶信息,使得序列的長期狀態可以保存下來,并傳遞到下一層,同時,遺忘門的設計又使得c 得到更新,丟棄已經過時的信息。LSTM 的這一設計解決了RNN 網絡存在的梯度消失和梯度爆炸問題。
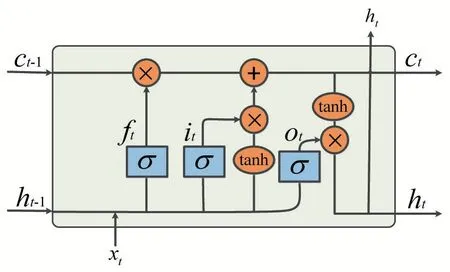
圖1 LSTM神經元
t 時刻的數據xt到達網絡后,與上一時刻LSTM 的輸出ht-1一起作為輸入,對Ct-1進行更新,得到新的長期狀態Ct,計算公式如公式(1)所示。
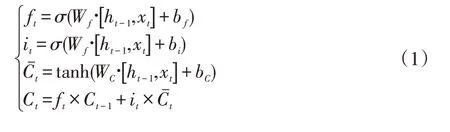
之后,輸入進行sigmod 計算后,與更新后的長期狀態Ct進行計算,得到該時刻的輸出ht,ht的計算公式如公式(2)所示。

2 方法構建
在本節,針對電網行業文本分類存在的問題,提出了一種基于LSTM 神經網絡的文本分類模型。模型主要分為三部分:預處理、特征提取以及文本分類。如圖1 所示為模型的三層框架。
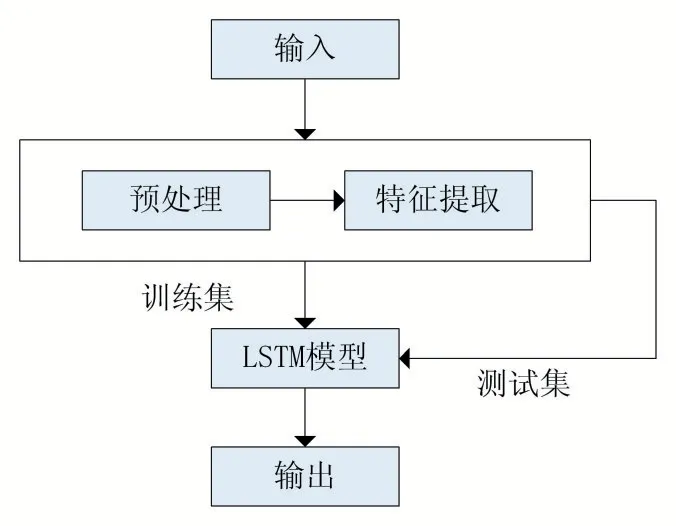
圖2 文本分類模型的三層框架
2.1 預處理模塊
在文本分類過程中,由于電網數據的多樣化的特點,導致存儲的大部分數據都為非結構化數據。面對這些復雜數據,計算機是無法直接處理的。這就需要先將文本進行預處理,并且將其轉換成計算機能夠識別出的形式。本文采用中科院的ICTCLAS 中文詞法分析系統進行分詞預處理并使用向量空間模型(VSM)進行文本模式化。
假設文檔集合Y 中某一文本X,其中Y 的文檔數量為N。向量空間模型是一種使用向量表示數據的模型,通過向量空間的模式化,可以降低文本分類的難度。 對于文本 X,通過向量空間模型得到,其中n 表示文本X 中詞的數量,xi表示文本X 的第i 個詞,wi為xi對應的特征權值,具體如下公式(3)所示:
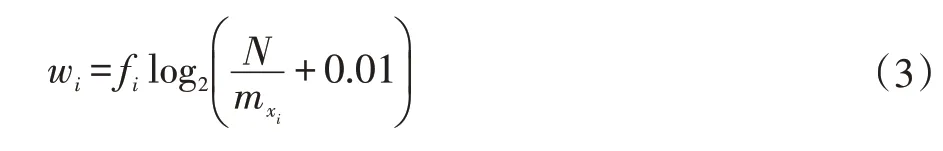
其中fi表示為xi在文檔X 中的出現次數,mxi表示為在集合Y 中出現xi的總文本數量。
對其進行歸一化處理,則wi由公式(4)所示:
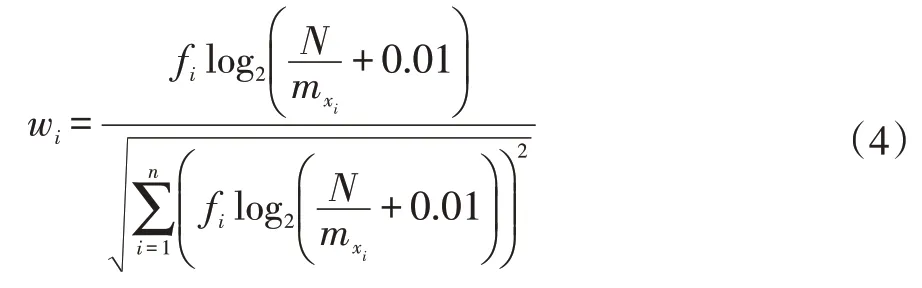
2.2 特征提取

由于互信息(MI)只考慮了xi和文本類別ck之間的關系,本文考慮到特征的選擇一定程度上還會收到xi在整個文本集合Y 中的出現頻率的影響,通過改進MI 算法得到如公式(5)所示:其中Pck表示屬于ck的文檔在集合Y 中所占比重,α 為控制閾值,為含有詞xi的文本屬于文本類別ck的比重,其表達式如下公式(6)所示:

其中hck表示為屬于類別ck的文本的數量,Su 表示為屬于類別ck的詞的總數,Fk為所有詞屬于ck類的數量。
設置合適的特征選擇閾值b,選擇互信息值高于閾值b 的詞,將其視為文本的特征值用于文本分類。
2.3 文本分類
假設經過上述預處理和特征提取之后得到的文本X 的對應特征向量為,其中w<=n。通過已知對應類別標簽的文本訓練集對文本分類模型進行訓練。本文采用LSTM 神經網絡作為文本分類模型進行分類訓練。其算法偽代碼如下所示:定義輸入為文本Y,其某個文本X 經過預處理以及特征提取得到特征向量,作為LSTM 神經網絡的輸入節點,輸出為分類模型對所有文本集合Y 做出的分類預測類別集合CY。
輸入:文本Y
輸出:分類預測類別CY
步驟3:根據控制閾值b 獲得模型輸入特征集合Y";
步驟4:CY=LSTM(Y");
3 實驗驗證
本文實驗部分的數據來自于國家電網提供的變電站信息系統數據。根據電網的相關要求,可以將這些數據具體分為電網設備檢修操作票、信息系統檢修計劃單、信息系統檢修工作票、信息系統檢修操作票、客服服務工作票。文本總量為3000 篇,平均每類為600篇。選取每類的70%作為文本訓練集用于訓練模型,剩余每類30%作為測試集測試分類模型的性能。經過訓練以及測試,其結果如下所示:其平均率可以達到91%以上。
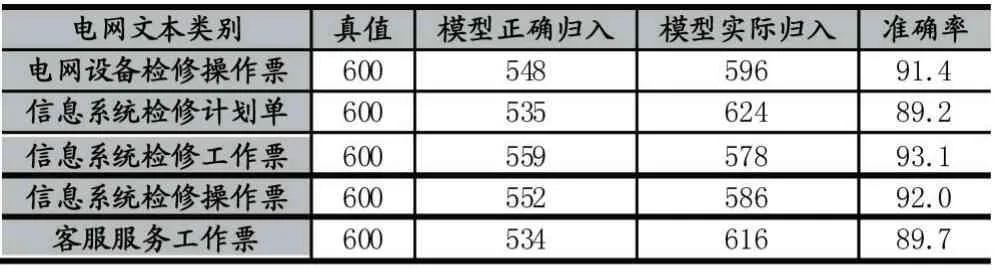
表1 實驗分類結果
4 結語
本文基于電網系統中存在大量電子文本,但當前電網信息管理較為混亂,沒有統一模型的現實,為了對電網系統中的海量電子文本進行檢索和信息提取,構建了一個LSTM 神經網絡分類模型來對電網文本信息進行分類,之后,通過基于國家電網提供的變電站信息系統數據的實驗驗證了本方法的有效性。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
文苑(2020年4期)2020-05-30 12:35:30
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學教學參考(2015年20期)2016-01-15 08:44:38
