基于關聯規則數據挖掘技術在音樂分類中應用
2020-03-03 13:20:44張婷婷
現代電子技術 2020年1期
關鍵詞:數據挖掘


摘 ?要: 為了提高音樂分類的精準性及個性化,提出基于關聯規則的數據挖掘技術在音樂分類中的使用,解決單一軌道提取的局限性問題。首先,對音樂文件預處理進行分析,主要包括提取主旋律、分析和聲;之后,對基于FP_Growth關聯規則挖掘算法的音樂風格進行分析。因為FP_Growth算法只需要掃描兩遍原始數據,對原始數據進行壓縮具有較高的效率,所以將FP_Growth關聯規則挖掘算法應用于音樂媒體的風格分類中,并且創建基于FP_Growth關聯規則挖掘的音樂風格分類,減少所需頻繁項集的數量,從而提高數據庫掃描速度,在此過程中不需要候選項集,實現音樂分類過程中的數據挖掘;最后,對數據挖掘的效率進行Matlab測試,測試結果表示,相比基于LAD和Apriori算法的音樂風格分類,基于FP_Growth的音樂風格分類減少了I/O開銷,提高了運行效率和分類的精準性。
關鍵詞: 音樂分類; 數據挖掘; 關聯規則算法; 音樂風格分析; 主旋律提取; FP_Growth
中圖分類號: TN911.1?34; TP393 ? ? ? ? ? ? ? ? ? 文獻標識碼: A ? ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2020)01?0099?03
Application of data mining technology based on association rules
in music classification
ZHANG Tingting
Abstract: In order to improve the accuracy and individualization of music classification, the application of data mining technology based on association rules in music classification is proposed to solve the limitation problem of single track extraction. The preprocessing of music files is analyzed, including extraction of the main melody and analysis of harmony. Then, the music style based on FP_Growth association rules mining algorithm is analyzed. Because the FP_Growth algorithm only needs to scan the original data twice, it is more efficient to compress the original data, so the FP_Growth association rule mining algorithm is applied to the style classification of music media, and the music style classification based on FP_Growth association rules mining is created to reduces the number of the needed frequent itemsets, so as to improve the scanning speed of the database. There is no need of candidate itemsets in this process for realization of the data mining in the process of music classification. The efficiency of data mining is tested with Matlab. The test results show that, in comparison with the music style classification based on LAD and Apriori algorithms, the music style classification based on FP_Growth algorithm can reduce the overhead of I/O, and improve the running efficiency and the classification accuracy.
Keywords: music classification; data mining; association rule algorithm; music style analysis; main melody extraction; FP_Growth
0 ?引 ?言
數字化技術的發展導致音樂產業發生了翻天覆地的變化,傳統模式的音樂運營已經逐漸銷聲匿跡,依托互聯網平臺的數字音樂產業已經成為現今社會的主流。隨著創新型個性化服務產業的發展,要求數字音樂媒體需要根據用戶的興趣不同,推薦符合其喜好風格的音樂,但是互聯網平臺中的音樂數據文件是海量的,如何在大規模音樂文件數據庫中進行風格分類是現階段研究的熱點問題[1?3]。
目前,主流的研究方向是采用數據挖掘技術實現音樂風格分類,例如文獻[4]提出基于LDA主體挖掘模型的音樂推薦算法,實現了基于音頻信息的音樂推薦以及協同過濾。文獻[5]提出基于特征旋律挖掘的二階馬爾可夫鏈算法,該算法是在關聯規則挖掘Apriori算法的基礎上引入特征旋律挖掘(Interval Sequence Mining,ISM)來實現音樂作曲風格訓練。常見的挖掘頻繁項集算法有兩類[5?9]:一類是Apriori算法;另一類是FP_Growth算法。因此,本文提出將FP_Growth關聯規則挖掘算法應用于音樂媒體的風格分類任務中,可有效提高數據庫掃描的速度且無需候選項集。此外,采用多維度數據庫中數據結構Skyline算法[10]提取多軌道的音頻媒體文件的主旋律,并進行和弦構成分析。
1 ?音樂媒體文件的預處理
1.1 ?主旋律提取
主旋律是音樂風格劃分的關鍵因素,直接影響后續分類算法的性能,是一個重要的預處理環節。目前,較為典型的主旋律提取算法是Skyline旋律提取算法,但是Skyline算法只能實現單一軌道的旋律提取,因此對每個軌道執行Skyline算法。具體通過如下公式對音軌[ci]的平均音調值[pi]進行計算:
[pi=j=1npijn] ? (1)
式中:[pij]表示音軌[ci]中音符[j]的音調值;[n]為音軌[ci]中音符的個數。
然后將每個音軌上音符的音調值做12維映射投影[10],每個統計表如下所示:
[hi=(hi1,hi2,…,hi12)] (2)
對于一個音樂媒體文件來說,12維映射的整體統計表示為:
[h=(h1,h2,…,h12)] (3)
其中:
[hi=j=1ChiCC] (4)
式中[C]表示音樂媒體文件中的音軌數量。
通過式(5)計算[hi=(hi1,hi2,…,hi12)]和[h=(h1,h2,…,h12)]之間的歐幾里得距離:
[edistj=i=112hij-hj2] (5)
在上述距離差計算結果的基礎上對兩個音軌進行簇劃分[11],判斷方式如下:
[edisti-edistj<δ for ?hi,hj] (6)
式中[δ]表示設定的閾值。如果任意兩個音軌[hi,hj]之間的歐幾里得距離滿足式(6)的條件,則表示這兩個音軌屬于同一簇。
1.2 ?和聲分析
設定[ni],[ni+1]分別表示不同的音符,[ei],[ei+1]分別表示兩個音符的停止時刻,[si],[si+1]分別表示兩個音符的開始時刻,則兩個音符和聲的表示方式為:
[ni,ni+1si≤si+1,ei>ei+1] (7)
[ni],[ni+1]的音程計算方式如下:
[Ii,i+1=pi-pi+1] (8)
式中[pi]和[pi+1]分別表示兩個音符的音調值。
此外,利用頻繁與不頻繁的統計來實施音樂的分箱操作[12],方式如下:
[fi=frequenet, ? ?f(xi)>δinot, ? ?else] (9)
式中[f(xi)]表示頻度。
2 ?基于FP_Growth關聯規則挖掘算法的音樂風格分類
關聯規則是指形如[X→Y]的表達式。關聯規則挖掘Apriori算法需要通過不斷地構造候選集、篩選候選集挖掘出頻繁項集,需要多次掃描原始數據,當原始數據較大時,磁盤I/O次數太多,效率比較低下。不同于Apriori算法的“試探”策略,作為一種常見的挖掘頻繁項集算法,FP_Growth算法只需掃描原始數據兩遍,通過FP?tree數據結構對原始數據進行壓縮,效率較高[13]。因此,將FP_Growth關聯規則挖掘算法應用于音樂媒體的風格分類任務中。
令[I=i1,i2,…,id]表示音樂數據中所有項的集合,而[T=t1,t2,…,tN]表示所有事務的集合。每個事務[ti]包含的項集都是[I]的子集。
在關聯分析中,支持度(support)和置信度(confidence)[14?15]的具體表示方式為:
[s(X→Y)=σ(X?Y)N] (10)
[c(X→Y)=σ(X?Y)σ(X)] (11)
式中[N]表示事務的數量。
本文提出的音樂分類方式的支持度計算方式如下:
[s={xx∈D,rulei∈x}] (12)
式中:[D]表示訓練數據集;[rulei]為[D]的規則。在關聯分析中集合被視為項集(itemset)。
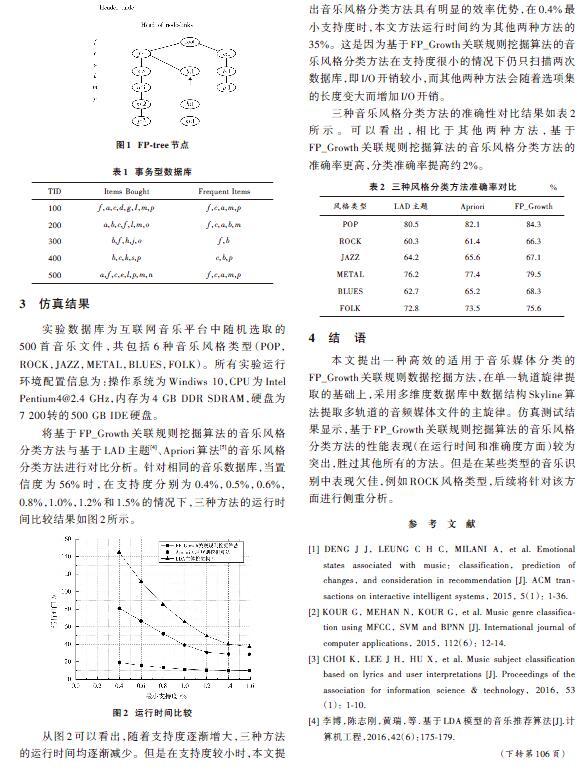
基于FP_Growth關聯規則挖掘的音樂風格分類的核心步驟是構建FP?tree樹節點,以便減少所需頻繁項集的數量。事務型數據庫的示例如表1所示,FP_tree樹的節點結構如圖1所示,其構造FP_tree樹的每個節點的結構體代碼如下:
class TreeNode {
private:
int32 N_Nodes; ?//節點名稱
int Numbers; ?//支持度計數
TreeNode *P_Nodes; ?//父節點
Vector
TreeNode *Ner_Nodes; ?//指向同名節點
…
}
3 ?仿真結果
實驗數據庫為互聯網音樂平臺中隨機選取的500首音樂文件,共包括6種音樂風格類型(POP,ROCK,JAZZ,METAL,BLUES,FOLK)。所有實驗運行環境配置信息為:操作系統為Windiws 10,CPU為Intel Pentium4@2.4 GHz,內存為4 GB DDR SDRAM,硬盤為7 200轉的500 GB IDE硬盤。
將基于FP_Growth關聯規則挖掘算法的音樂風格分類方法與基于LAD主題[4]、Apriori算法[5]的音樂風格分類方法進行對比分析。針對相同的音樂數據庫,當置信度為56%時,在支持度分別為0.4%,0.5%,0.6%,0.8%,1.0%,1.2%和1.5%的情況下,三種方法的運行時間比較結果如圖2所示。
從圖2可以看出,隨著支持度逐漸增大,三種方法的運行時間均逐漸減少。但是在支持度較小時,本文提出音樂風格分類方法具有明顯的效率優勢,在0.4%最小支持度時,本文方法運行時間約為其他兩種方法的35%。這是因為基于FP_Growth關聯規則挖掘算法的音樂風格分類方法在支持度很小的情況下仍只掃描兩次數據庫,即I/O開銷較小,而其他兩種方法會隨著選項集的長度變大而增加I/O開銷。
三種音樂風格分類方法的準確性對比結果如表2所示。可以看出,相比于其他兩種方法,基于FP_Growth關聯規則挖掘算法的音樂風格分類方法的準確率更高,分類準確率提高約2%。
4 ?結 ?語
本文提出一種高效的適用于音樂媒體分類的FP_Growth關聯規則數據挖掘方法,在單一軌道旋律提取的基礎上,采用多維度數據庫中數據結構Skyline算法提取多軌道的音頻媒體文件的主旋律。仿真測試結果顯示,基于FP_Growth關聯規則挖掘算法的音樂風格分類方法的性能表現(在運行時間和準確度方面)較為突出,勝過其他所有的方法。但是在某些類型的音樂識別中表現欠佳,例如ROCK風格類型,后續將針對該方面進行側重分析。
參考文獻
[1] DENG J J, LEUNG C H C, MILANI A, et al. Emotional states associated with music: classification, prediction of changes, and consideration in recommendation [J]. ACM tran?sactions on interactive intelligent systems, 2015, 5(1): 1?36.
[2] KOUR G, MEHAN N, KOUR G, et al. Music genre classification using MFCC, SVM and BPNN [J]. International journal of computer applications, 2015, 112(6): 12?14.
[3] CHOI K, LEE J H, HU X, et al. Music subject classification based on lyrics and user interpretations [J]. Proceedings of the association for information science & technology, 2016, 53(1): 1?10.
[4] 李博,陳志剛,黃瑞,等.基于LDA模型的音樂推薦算法[J].計算機工程,2016,42(6):175?179.
[5] 鄭銀環,王嘉珺,郭威,等.基于特征旋律挖掘的二階馬爾可夫鏈在算法作曲中的研究與應用[J].計算機應用研究,2018,35(3):849?853.
[6] NAJI M, FIROOZABADI M, AZADFALLAH P. Emotion classification during music listening from forehead biosignals [J]. Signal image & video processing, 2015, 9(6): 1365?1375.
[7] BANIYA B K, LEE J. Importance of audio feature reduction in automatic music genre classification [J]. Multimedia tools & applications, 2016, 75(6): 1?14.
[8] KHONGLAH B K, PRASANNA S R M. Speech/music classification using speech?specific features [J]. Digital signal proces?sing, 2016, 48(3): 71?83.
[9] RODRIGUES F A. A survey on symbolic data?based music genre classification [J]. Expert systems with applications, 2016, 60(3): 190?210.
[10] FARROKHMANESH M, HAMZEH A. Music classification as a new approach for malware detection [J]. Journal of computer virology & hacking techniques, 2018(2): 1?20.
[11] ULAGANATHAN A S, RAMANNA S. Granular methods in automatic music genre classification: a case study [J]. Journal of intelligent information systems, 2018(23): 1?21.
[12] ROSNER A, KOSTEK B. Automatic music genre classification based on musical instrument track separation [J]. Journal of intelligent information systems, 2017(2): 1?22.
[13] 王建明,袁偉.基于節點表的FP?Growth算法改進[J].計算機工程與設計,2018,39(1):140?145.
[14] WANG B, DAN C, SHI B, et al. Comprehensive association rules mining of health examination data with an extended FP?Growth method [J]. Mobile networks & applications, 2017, 22(2): 1?8.
[15] KHONGLAH B K, PRASANNA S R M. Clean speech/speech with background music classification using HNGD spectrum [J]. International journal of speech technology, 2017, 20(6): 1?14.
作者簡介:張婷婷(1983—),女,甘肅平涼人,碩士,講師,主要研究方向為音樂教育理論。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
