基于FP_Growth關聯規則挖掘的多軌道數字音頻文件分類研究
2020-03-03 13:20:44謝搶來楊威
現代電子技術 2020年1期
關鍵詞:數據挖掘
謝搶來 楊威


摘 ?要: 為從海量音頻信息中快速準確地獲取所需文件,研究基于FP_Growth關聯規則挖掘的多軌道數字音頻文件分類方法。以數據立方體下具有多維屬性的多軌道數字音頻文件為研究對象,采用FP_Growth關聯規則挖掘算法排序多軌道數字音頻文件數據集的頻繁1?相集,采用FP tree挖掘頻繁項集獲取多維關聯規則集。識別并提取多軌道數字音頻文件中某類型音頻文件中的音頻內容,使用刪除停用詞結合TF/IDF的計算方式獲取清潔的音頻文件,應用音頻文件數據集的多維關聯規則集,綜合考慮匹配規則數和置信度,搜索規則集,獲取該類型音頻文件最相配類別,完成多軌道數字音頻文件分類。實驗結果表明,所提方法能夠直觀有效地分類多軌道數字音頻文件,且分類結果準確率和召回率平均值分別達到96.60%和96.54%,顯著高于對比方法。
關鍵詞: 關聯規則; 數據挖掘; 多軌道; 數字音頻; 文件分類; 數據立方體
中圖分類號: TN911.72?34; TP301.6 ? ? ? ? ? ? ? ? ?文獻標識碼: A ? ? ? ? ? ? ? ?文章編號: 1004?373X(2020)01?0179?04
Research on multi?track digital audio file classification
based on FP_Growth association rule mining
XIE Qianglai, YANG Wei
Abstract: A multi?track digital audio file classification method based on FP_Growth association rule mining is studied to get the required files quickly and accurately from the massive audio information. By taking multi?track digital audio files with multidimensional attributes under the data cube as the research object, FP_Growth association rules mining algorithm is adopted to sort the frequent 1?phase sets of multi?track digital audio file data sets, and FP tree mining frequent item sets are adopted to obtain multidimensional association rules. The audio content in a certain type of audio file in multi?track digital audio files is identified and extracted, the calculation method of deleting stop words combined with TF/IDF is adopted to obtain clean audio files. The multidimensional association rules set of audio file data set is applied to take into account comprehensively the matching rule number and degree of confidence, search the rule sets, obtain the most suitable type of audio file categories and complete the classification of multi?track digital audio files. The experimental results show that the proposed method can intuitively and effectively classify multi?track digital audio files, and the averages of accuracy and recall rate of classification result reach 96.60% and 96.54% respectively, significantly higher than the comparison method.
Keywords: association rule; data mining; multi?track; digital audio; file classification; data cube
0 ?引 ?言
不同類型音頻信號經采集、量化編碼壓縮、多軌錄入等數字化處理后,以文件形式存儲在計算機硬盤等存儲媒體內,最終形成多軌道數字音頻文件。從多軌道數字音頻文件中快速準確地獲取所需類型音頻文件,在視頻編輯、影像分析等領域具有重要的應用價值[1]。
數據挖掘是挖掘并分析項集之間某種潛在關系,這種潛在關系稱為關聯規則,關聯規則可劃分為維間、單維、多維、量化等不同類型[2]。由于多軌道數字音頻文件具有多維屬性[3],因此在分類文件之前需將多軌道數字音頻文件數據集內海量多維數據以數據立方體的形式存儲起來,這種存儲方式不僅簡單,且基于數據立方體挖掘數據間關聯規則不僅能夠節省挖掘時間,還可提升數據挖掘準確率。FP_Growth算法是當前挖掘頻繁項集算法中應用最廣,且不產生候選項集的關聯規則挖掘算法[4?5]。因此,本文研究基于FP_Growth關聯規則挖掘的多軌道數字音頻文件分類方法,在數據立方體基礎上采用FP_Growth多維關聯規則挖掘算法挖掘多軌道數字音頻文件中不同類型音頻間關聯規則,根據挖掘到的關聯規則對不同類型的數字音頻文件進行分類。
1 ?基本概念
1.1 ?關聯規則
假設[I]和[D]代表項的集合和全體事務集合,而事務[T]是集合[I]的一個子集,則[T?I]。每個事務都有獨立的標識,每個標識用[TID]表示。假設[A]是一個項集,[A]在事務[T]之中,則[A?T],關聯規則就是類似于[A?B]的蘊涵式,當項集[A]屬于事務[T],項集[B]屬于項的集合[I],且[A?B=][?]。全體事務集[D]支持規則[A?B],支持度為[s],[s]是全體事務集[D]包含[A?B]的百分比,其條件概率可表示為[PA?B]。[c]為規則[A?B]在全體事務集[D]中的置信度,[c]是全體事務集[D]中同時包含[A]和[B]的事務占[D]總量的百分比,此時條件概率為[PBA],表達式為:
[supportA?B=PA?B] (1)
[confidenceA?B=PBA] (2)
支持最小支持度的同時也支持最小置信度的閾值(min?conf)規則叫做強規則[6]。
1.2 ?多維關聯規則
假若規則不僅只有一個維度,而是具有兩個以上的維度,則該規則叫做多維關系規則。例如規則:
[agex,″32…41″∧income x,″43Κ…47Κ″ ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?buysx,″?highresolutionTV″] (3)
1.3 ?數據立方體
使用數據立方體構建多軌道數字音頻文件數據集中數據和[OLAP]多維數據模型,數據立方體構建數據模型前需要從多維角度對數據實行角度[7]觀察,對數據特定角度的觀察、分析所采用的一類特殊屬性稱為維,數據屬性的集合就能形成一個維。數據立方體由維和事實定義,其中事實由數值衡量獲取。
數據集中的數據立方體是多維數據存儲的一種形象化比喻,且維度不僅限于2維或者3維,它可以是多維的,用[n]維描述,任意[n]維立方體都是[n-1]維立方體的序列。數據立方體中每一個方格記錄的都是相應維成員的頻繁衡量值[8],可用[count]表示,數據立方體的每一個方格都能夠提供預計算的匯總數據,使得多維關聯規則支持度以及置信度的計算更加簡便。
2 ?FP_Growth多維關聯規則挖掘算法
通過Apriori算法變換可獲得基于數據立方體的多維關聯規則挖掘算法,但Apriori算法在挖掘關聯規則時會受兩種非平凡開銷影響,導致挖掘結果存在偏差。FP_Growth關聯規則挖掘算法是一種在挖掘頻繁項集過程中不產生候選項集的算法,該算法構建一個壓縮度較高的數據結構(FP),壓縮原來的事務數據集。FP_Growth關聯規則挖掘算法采用模式增長方式挖掘多軌道數字音頻文件中數據集的頻繁項集,該算法步驟如下:
1) 頻繁1?項集排序。獲取頻繁1?項集[L]和相應的支持度,掃描多軌道數字音頻文件中數據集[L]。
2) 構建[FP tree]。使用“[null]”標記[FP tree]構建的基本點[9],假設[k?]謂詞集屬于全體事務集合[D],則按照頻繁謂詞集[L]對[k?]謂詞集進行由大到小排列,并用[gG]代表排列后的[k?]謂詞集列表。[g]代表第一個謂詞元素,[G]代表剩余元素的列表,使用[insert?treegG?T]表示,以下為[FP tree]基本點構建過程執行情況:假設[T]有孩子[N],并設置[N]=[g],即[N.item?name=g.item?name],那么[N]的數量多1;如果[N]≠[g],則需要構建新節點[N],并設置[N]=[g],計數設置為1,與其父節點[T]產生鏈接,并與具有同[item?name]節點相串聯,該串聯過程要通過使用節點鏈結構實現。若剩余元素的列表[G]并不為空[10],則可以調動自身的[insert?treeG.N]。
3) FP tree挖掘。從長度為1的頻繁模式開始,構造相應條件模式基。模式基構建完成后,開始構建FP tree,且在FP tree上遞歸實行[FP tree]挖掘。
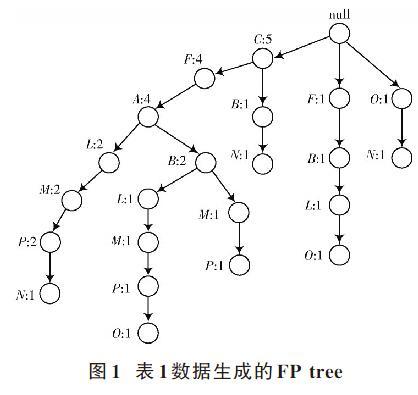
FP_Growth關聯規則挖掘算法基本包括上述三個步驟,重點是構建FP tree的過程。給定一個事務數據集后,依據FP_Growth關聯規則挖掘算法構建FP tree,可對數據集頻繁項信息實行反饋,挖掘承載體由數據集變為FP tree,可簡化數據集頻繁項挖掘過程。表1為給定的事務數據集,圖1為根據表1所示數據并在支持度計數為2時構建的FP tree。
對事物數據集的每個事務分別調用[insert?treegG?T]算法過程就是構建FP tree的過程。假設[Li]是頻繁表項,[T]是FP tree,[Lij]代表[Li]的第[j]項,則[g=Li1,G=Li2,…,G=Lin],調用[insert?tree]算法,假設[Lij]代表頻繁表項,現將[Lij]嵌入到頻繁模式樹FP tree中,以算法原理為依據首先判定[T]是否有子節點[N],且設置[N]=[g=Li1],若相同則計數加1,如果不相同則需要構建一個[T]的新子節點,即每一步[insert?treegG?T]算法調用都將遍及[T]的子節點,且遍及子節點的時間復雜度越高,[T]的子節點個數就越多。
假設[Li]有[m]個節點([Li1,Li2,…,Lim])與[T]的子節點([T1,T2,…,Tm],[Tm]是[Tm-1]的子節點)對應相同,設定[brotherTm]代表樹節點[Tm]兄弟節點個數,由于函數每一步[insert?treegG?T]算法調用都將遍及[T]的子節點[11],因此[Li]嵌入頻繁模式樹FP tree的時間復雜度與遍及每一個[Tk],[1≤k≤m]子節點的時間復雜度[O]相乘后的結果相等,即[k=1mObrotherTk]。
通過上述過程基于數據立方體獲取多軌道數據音頻文件數據集的多維關聯規則集。
3 ?多軌道數字音頻文件分類關聯規則
目前對數字型多軌道音頻文件分類時經常使用關聯規則方法,以多軌道數字音頻文件數據集中的最強關聯規則為分類依據[12]。為實現優質的多軌道數字音頻文件分類,需結合上文所述的FP_Growth多維關聯規則挖掘算法,研究基于FP_Growth關聯規則挖掘的多軌道數字音頻文件分類方法。
3.1 ?多軌道數字音頻文件的關聯規則表示和預處理
識別并提取多軌道數字音頻文件中某類型音頻文件的音頻內容,每個音頻主題數據使用數據立方體表示。設定某類型數字音頻文件的類標簽和音頻分別為[C]和[TT=t1,t2,…,tm],該類型數字音頻文件可采用全體事務集[D]的表示方法[D:C,t1,t2,…,tm]描述。多軌道數字音頻文件中不同類型音頻文件可表示成事務集,某一類型的音頻文件由音頻和音頻文件所屬類別共同組成該類型音頻文件事務集合的項集,每一條關聯規則都從表示該類型音頻文件集的事務集中產生。當清理數據時,刪除對構造關聯分類器作用很小甚至沒有作用的音頻,為提高多軌道數字音頻文件中某一類型音頻文件的清潔度[13],通常使用刪除停用詞結合TF/IDF的計算方式清理音頻文件。TF/IDF值獲取的計算公式為:
[TFIDFi=TFWi,Doc?log DDFWi] (4)
式中:[TFWi,Doc]代表單音頻[Wi]在音頻文件中出現的頻率;[D]代表數字音頻文件總數;[DFWi]代表單音頻[Wi]在其中出現至少一次的數字音頻文件數目。以下為對TF/IDF權歸一化處理公式:
[dij=TFIDFij=1nTFIDF2i] (5)
設置TF/IDF閾值,為獲取一個清潔的數字音頻文件事務集,需要在該數字音頻文件事務集中清除低于該閾值的音頻,并基于FP_Growth關聯規則挖掘算法對該清潔的數字音頻文件事務集進行多維關聯規則挖掘,挖掘過程在第2節中有詳細描述,此處不再重復。
3.2 ?利用關聯規則進行多軌道數字音頻文件分類
經過FP_Growth關聯規則挖掘算法挖掘清潔的多軌道數字音頻文件事務集獲取多維關聯規則后,依據該關聯規則分類數字音頻文件[14],通過搜索規則集獲取與該類型音頻文件最相配類別的過程,稱為多軌道數字音頻文件的分類處理過程。通常情況下將多軌道數字音頻文件中不同類型音頻文件分配到與之規則匹配最多的類別,或是分配給與其第一個規則相匹配的類別。但這種分配方式有一個缺陷,就是在分配過程中沒有考慮置信度作用,為解決這一缺陷要綜合考慮匹配規則數和置信度的作用。
現給定多軌道數字音頻文件中的某一類型數字音頻文件,以數字音頻文件的音頻為依據生成規則列表。將該規則列表按類標簽分組,設置一個固定的置信度閾值,刪除該類型音頻文件分組中低于該置信度閾值的匹配規則,并將所有分組按照置信度的和排序[15]。以下為類識別規則:選擇置信度和最大分組的標簽作為該類型數字音頻文件的類標簽;當置信度的和均相等時,將匹配規則最多組的標簽作為該類型數字音頻文件類標簽。具體過程如下:
輸入:待分類多軌道數字音頻文件中的某類型數字音頻文件[Doc=t1,t2,…,tm];關聯分類器;置信度閾值[τ]。
輸出:待分類多軌道數字音頻文件中的某類型數字音頻文件[Doc]的類標簽
方法:
1) [Count=0]
2) 初始化音頻文件事務集[S←Φ]
3) 檢索規則庫中的每個規則
//以規則前件和[Doc]數字音頻文件音頻為依據,生成規則列表
4) [ifr Doc ∧r.confidence>τ]
5) [S←S?r]
6) 以類標簽為依據將入選規則集分成多個子集,該子集可表示為[S1,S2,…,Sn]
7) 檢索子集[S1,S2,…,Sn]
8) 匯總規則信任度,統計規則數
9) 根據置信排序子集[S1,S2,…,Sn]
10) 將類分配給新音頻文件
4 ?仿真測試
采用本文提出的基于FP_Growth關聯規則挖掘的多軌道數字音頻文件分類方法對某類型音樂廣播電臺多軌道數字音頻文件中不同類型的音頻文件進行分類,得到分類結果如圖2所示。
圖2中,上面的音頻波(綠色)為MP3歌曲音頻文件,下面的音頻波(紅色)為WAV語音廣播音頻文件,不同類型音頻文件使用不同顏色標注,且從圖中可看出兩種音頻波形并不一致,說明本文方法可以有效地分類出實驗多軌道數字音頻文件中不同類型的音頻文件。
為驗證本文方法對多軌道數字音頻文件分類方面的優越性能,對上一實驗中的實驗對象進行關聯規則挖掘識別。實驗對象中包含MP3,WMA,MIDI,WAV,CDA,AU,AIF,RM,VOC等格式數字音頻文件共計4 296份,隨機抽取其中95%作為訓練集,余下5%作為測試集。采用三種方法挖掘訓練多軌道數字音頻文件數據集中的音頻文件,并將挖掘到的關聯規則運用到測試數據集中完成數字音頻文件分類,分類結果見表2。
由表2可知,采用本文方法分類多軌道數字音頻文件中不同類型音頻文件的分類結果準確率最高,平均值達到96.60%,且召回率也是三種方法中最高的,平均值達到96.54%,說明本文方法分類多軌道數字音頻文件的性能較好。
5 ?結 ?論
快速準確地從海量多軌道數字音頻文件數據中找到有用的信息是網絡技術發展的必然要求。本文研究基于FP_Growth關聯規則挖掘的多軌道數字音頻文件分類方法,該方法不僅降低了多軌道數字音頻文件數據挖掘過程中候選項目集的產生數量,還減少了數字音頻文件數據掃描次數,提高多軌道數字音頻文件分類效率。本文方法在對多軌道數字音頻文件分類方面具有較好的發展前景。
參考文獻
[1] 呂璐成,趙亞娟,王學昭,等.基于關聯規則挖掘的研發團隊識別方法[J].科技管理研究,2016,36(17):148?152.
[2] 張雪萍,李圍成,祝玉華.基于 FP?樹的時空關聯規則挖掘算法研究[J].微電子學與計算機,2016,33(8):130?133.
[3] 張穩,羅可.一種基于Spark框架的并行FP_Growth挖掘算法[J].計算機工程與科學,2017,39(8):1403?1409.
[4] 申彥,朱玉全,劉春華.基于磁盤存儲1項集計數的增量FP_Growth算法[J].計算機研究與發展,2015,52(3):569?578.
[5] 王建明,袁偉.基于節點表的FP_Growth算法改進[J].計算機工程與設計,2018,39(1):140?145.
[6] 李維娜,任家東.軟件群體中基于交互序列的頻繁模式挖掘算法研究[J].小型微型計算機系統,2018,39(5):1046?1051.
[7] 王艷輝,王淑君,李曼,等.基于改進FP_Growth算法的CRHX型動車組牽引系統關聯失效模型研究[J].鐵道學報,2016,38(9):72?80.
[8] 程廣,王曉峰.基于MapReduce的并行關聯規則增量更新算法[J].計算機工程,2016,42(2):21?25.
[9] 唐曉東.基于關聯規則映射的生物信息網絡多維數據挖掘算法[J].計算機應用研究,2015,32(6):1614?1616.
[10] 徐開勇,龔雪容,成茂才.基于改進Apriori算法的審計日志關聯規則挖掘[J].計算機應用,2016,36(7):1847?1851.
[11] 劉軍煜,賈修一.一種利用關聯規則挖掘的多標記分類算法[J].軟件學報,2017,28(11):2865?2878.
[12] 王雯,趙衎衎,李翠平,等.Spark平臺下的短文本特征擴展與分類研究[J].計算機科學與探索,2017,11(5):732?741.
[13] 王莉莉.多維多層數據的無冗余跨層挖掘算法[J].微電子學與計算機,2018,35(2):113?117.
[14] 李洪成,吳曉平,俞藝涵.基于多維頻繁序列挖掘的攻擊軌跡識別方法[J].海軍工程大學學報,2018,30(1):40?45.
[15] 郭燁,海霞,趙長青,等.數字音頻廣播與航空無線電導航業務兼容性研究[J].電視技術,2017,41(6):62?67.
作者簡介:謝搶來(1984—),湖南人,工程碩士,講師,研究方向為數據挖掘、數據庫信息優化。
楊 ?威(1985—),湖北人,工程碩士,講師,研究方向為計算機應用。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
