證據權重方法在企業信用風險評估應用
2020-02-22 06:52:25危明鑄沈鳳山袁峰麥偉杰
科技創新導報 2020年29期
危明鑄 沈鳳山 袁峰 麥偉杰

摘? 要:本文以廣東省各個行政部門的企業數據為基礎,研究了證據權重在企業信用風險等級評估中的應用,并且根據國家“企業信用風險分類評價標準”系統建立了企業信用評價指標,成功地將證據權重邏輯回歸算法應用到真實的企業信用數據集,建立企業信用風險評估模型,使得監管部門能夠準確地掌握企業的信用情況。通過與經典的邏輯算法比較,驗證了該方法的有效性。
關鍵詞:證據權重? 邏輯回歸? 信用風險? 企業信用
中圖分類號:O212? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A? ? ? ? ? ? ? ? ? ? 文章編號:1674-098X(2020)10(b)-0137-07
Abstract: Based on the enterprise data of various administrative departments in Guangdong Province, this paper studies the application of weight of evidence in the assessment of enterprise credit risk levels, and establishes enterprise credit evaluation indicators based on the national "Enterprise Credit Risk Classification and Evaluation Standards". The weight-of-evidence logistic regression algorithm is applied to real enterprise credit data sets to establish enterprise credit risk assessment model, enabling regulators to accurately grasp the enterprise credit situation. Compared with the classical logic algorithm, the validity of the method is verified.
Key Words: Weight of evidence; Logistic regression; Credit risk; Credit of enterprise
企業信用是市場經濟的產物,是對各類市場參與主體履行相應經濟契約的能力及其企業整體的可信程度所進行的一種綜合分析和測定,是企業的一項重要無形資產。隨著市場主體“寬進嚴管”改革的不斷深入,國務院相繼頒發了《國務院辦公廳關于推廣隨機抽查規范事中事后監管的通知》(國辦發[2015]58號)[1]、《國務院關于“先照后證”改革后加強事中事后監管的意見》(國發[2015]62號)[2]和《國務院關于印發2016年推進簡政放權放管結合優化服務改革工作要點的通知》(國發[2016]30號)[3]等相關文件,企業信用在社會經營活動中變成一個有效的“身份證”,塑造了一個企業在社會的面目和形象。
針對目前市場主體規模龐大、難以把握重點監管對象、雙隨機抽查的靶向性不強等不足,有些學者已經發表了自己的研究成果。Odom等人[4]早在1990年把人工神經網絡應用到企業信用風險評估上,并將其與經典的多元回歸分析比較,實驗表明人工神經網絡具有更優越的性能;Prinzie等人把邏輯回歸(Logistic)引入隨機森林算法并對其進行優化以及改進,然后將改進的算法應用于預測公司的信用風險[5];Lin F等人研究隨機森林與KMV模型結合,提出將違約距離作為隨機森林的輸入,實驗表明對企業信用風險預測性能更有效[6];Traskin等人利用隨機森林具有篩選重要變量的特征,提出將其應用在保險公司償付判別中[7];吳麗麗運用Logistic回歸模型深入探討了我國商業銀行信用風險監管的問題[8];郭玉華根據微型企業的特征,運用Logit模型進行實證分析,銀行可以借助該模型對微企的信用風險進行評估[9];方匡南,范新妍等人指出傳統的Logistic回歸建立企業運行風險預警模型效果不夠好,提出了基于網絡結構關系的Logistic模型[10];楊俊等人使用Gradient Boosting算法對中國建設銀行上海分行的企業貸款客戶數據建立模型,并和邏輯回歸以及專家規則進行橫向比較,結果表明Gradient Boosting算法的模型要優于另外兩種模型[11];熊正得等人利用因子分析法對深滬A股上市的制造企業財務數據構建風險評價體系,并在違約測度階段應用Logistic回歸對不同組樣本進行測度[12];劉丹等人使用證據權重、逐步回歸對信用評價指標進行篩選,構建一套具有區分違約能力的信用風險模型[13];劉麗君、韓靜磊等人運用WOE法評估了生活垃圾焚燒廠固化飛灰中重金屬的非致癌健康風險,并將其與傳統的非致癌健康風險評價方法進行比較[14];趙雅迪等人通過信息值(information value,Ⅳ)及證據權重轉化(weight of evidence,WOE)結合邏輯回歸算法構建用電客戶電費風險預測模型[15];陳超等人采用卡方分箱法和WOE編碼判別確定影響轉爐理想終點目標的關鍵工藝參數,并且運用邏輯回歸算法對編碼后數據構建的轉爐操作工藝評價模型[16];危明鑄等人在企業信用風險預測上綜合運用了各種機器學習算法比較各種方法的優缺點[17]。
本文對過去一定時期(如1年)出現過信用風險事件(如偷稅、行政處罰等)的企業數據集,根據國家“企業信用風險分類評價標準”系統建立企業信用評價指標體系。應用機器學習方法預處理評價指標數據集,如特征選擇(information value,IV)、缺失值處理、異常值處理,并將評價指標以證據權重(Weight of Evidence,WOE)編碼方式離散化形成woe數據集,之后結合邏輯回歸算法學習企業過去發生信用風險事件與否的規律,建模企業信用風險評分模型。
1? 相關技術
1.1 邏輯回歸
邏輯回歸(Logistic regression)是一種比較流行的二分類的機器學習算法。例如,探討企業信用風險與那些變量有關,可將企業數據集標記為兩組,假設存在信用風險的一組企業標記為1,那么沒有信用風險的一組為0,并用Y表示響應變量,X表示自變量,邏輯回歸用(1)式表達:
上面(8)式即為邏輯回歸的最后表達式,且有:,即與變量X為線性關系,而(9)式可以通過最大似然估計及梯度上升法[18]求解。
1.2 信息價值和證據權重
信息價值(Information Value,IV)是訓練模型之前所提取的有效的信息量,亦即提取有用的變量信息作為建模。當經典的邏輯回歸算法用于自變量多的企業數據建立分類模型時,經常存在諸多不足。譬如變量共線比較敏感、很難擬合真實的數據分布,因此需要對自變量進行特征篩選,因此引入信息價值。
IV可以根據量化指標的大小來衡量自變量的預測能力,它基于信息熵作為測量單位。信息熵用來描述“一個系統的混亂程度”,通常是度量樣本集合純度的一種指標。所謂“純”,就是讓分類器的一個分支擁有相同的屬性。當熵為1時,表示企業數據中某個變量趨于一個分段,此時信息價值IV較小;當熵為0時,表示企業數據中某個變量存在多個分段,此時信息價值IV較大。
設X是x個企業數據樣本的集合,具有個不同的連續變量,其概率密度函數為,它的信息熵表示如下[19]:
(10)式中E表示數學期望。
由于信息熵能夠精確地描述企業信用有風險與無風險樣本分布,本文將其引入企業信用風險評估中。對于給定的變量x,按照企業數據集將其分成兩部分,對應有信用風險的數據密度概率為,對應無信用風險的數據密度概率為,即IV值由有信用風險的數據分布與無信用風險的數據分布之比的信息熵加上無信用風險的數據分布與有信用風險的數據分布之比的信息熵[20]:
(13)式表明WOE為企業無信用風險概率與企業有信用風險概率之比取自然對數。到此,可以將(12)、(13)式寫在一起,得到IV與WOE的關系式:
在企業信用風險評估模型中,我們需要選擇具有好的預測能力變量,即要求信息價值值大。值越大,說明該變量對無信用風險的企業與有信用風險企業的區分度越大。從(14)關系式中可知,為了使得較大,必須保證該變量的WOE與分布函數具有一致性,亦即WOE與企業的數據分布單調一致,否則需要根據實際業務中的情況進行具體的分析。
2? 建模與過程
本文的企業信用風險評估使用評分卡的方式建立模型。評分卡是當前運用比較廣泛的信用風險評價方法,其原理是將評價指標以證據權重(WOE)編碼方式離散化之后,再運用邏輯回歸進行模型訓練。該方法的特點為可解釋性強,模型結果穩定。
整個建模過程包括數據獲取和整合、目標確定和訓練窗口選擇、變量分段并計算信息價值、模型訓練及模型評價。
2.1 數據獲取和整合
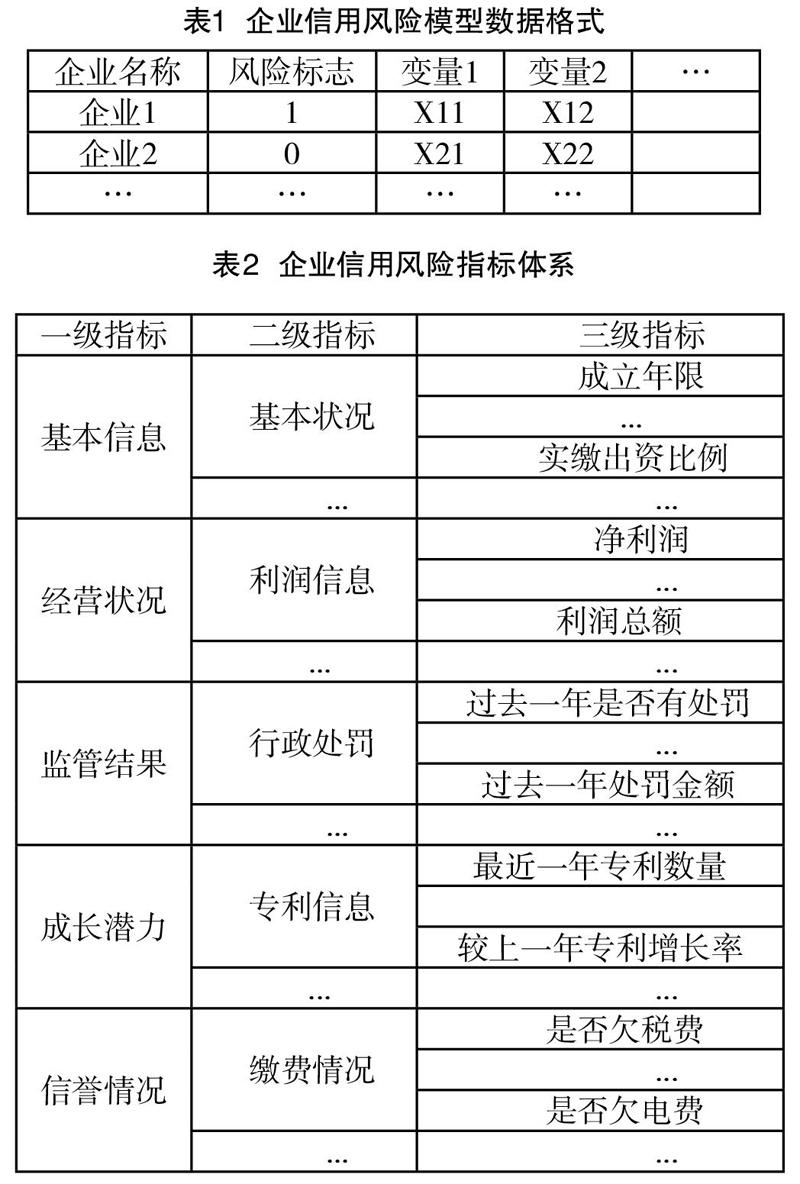
根據企業該領域的特殊性,文本在建模中抽取以下三類變量:
(1)原始變量。這些變量從數據庫中提取,概括了基本情況、各類原始明細等。通常來說,這些變量易于理解,但往往不是對模型最有效的;
(2)衍生業務指標。這些字段來源于原始變量,有明確業務含義(如企業過去3年被投訴舉報數量),這些變量通常比原始變量有更好地預測能力,也是評分卡最常用指標。然而,這些數據通常不自然存在于數據庫中,需要在實施階段通過計算得到;
(3)衍生模型指標。這些變量由分析人員對原始數據進行多層轉換和計算,通常由其他模型計算得出(如輿情風險指數),這些變量的預測能力一般是很好的,但和衍生業務指標相比,最大的區別在于缺少簡單清晰的業務含義,由模型高度抽象后計算得出。
2.2 目標確定和訓練窗口選擇
針對過去出現過信用風險事件的企業,其目標變量標記為1,過去未出現過信用風險事件的企業,其目標變量標記為0。
評分卡模型是用特定時間段的數據訓練的,這個特定時間段被稱為建模窗口。選用窗口過短,企業數據在短期內波動頻繁,容易引起模型預測結果的偏差,窗口過長則模型對企業及周圍環境的反應容易產生滯后現象。本文以1年為上限,即模型將預測企業在未來一年內是否發生信用風險事件的概率。
2.3 變量分段并計算信息價值
實際的企業信用風險數據集中變量有兩種情況,分別是定性變量和定量變量。
對于類別變量,已分好段,直接計算IV值;對于連續變量和離散變量,假設將變量X2分成K段,我們需要尋找K-1分點使得WOE與該變量保持單調性。必須注意的是變量X2可能有多種劃分保證這種單調性,這時我們選取IV的最大值作為最優分箱結果。
分段后,設PBK、PGK分別表示變量X2第K段對應目標變量為1(有信用風險)和0(無信用風險)的比例, 由(13)、(14)式得到:
其中,
有了每個分段的WOEK后,變量X2的信息價值的定義如下:
計算完IV后,根據實際企業業務情況,選擇IV≥0.01的變量入模,因為IV在0.01以下的變量幾乎毫無預測能力,可舍棄。
2.4 模型訓練
模型的理論基礎為邏輯回歸算法,計算模型事件發生(本文y=1,即出現過信用風險事件)的概率,有(8)式展開得:
這里,表示截距,為邏輯回歸中的系數,由最大似然法(ML)求解,為原始變量經轉換后的WOE值。
模型開始訓練時,通常會選擇用逐步回歸對變量持續進行篩選,每一步都移入對模型預測能力有幫助的變量,同時移除對模型無增益的變量。
除了模型本身對變量的選擇外,還考慮其它因素對變量進行選擇,如下幾項:
(1)變量獨立:即共線問題。回歸中的多重共線性是一個當模型中一些預測變量與其他預測變量高度相關時發生的條件。嚴重的多重共線性可能會產生問題,因為它可以增大回歸系數的方差,使它們變得不穩定。
(2)變量一致性:即變量訓練出來的參數正負性,和變量與目標變量的相關系數正負性必須一致,否則說明變量有偏差,需剔除;
(3)變量可解釋性:即變量及其變化趨勢是可以被業務理解和使用的,而不是完全黑盒不可解釋,或者變量趨勢無業務含義。
2.5 模型評價
模型性能的好壞決定其在實際中的應用效果,良好的模型會真實地反映出企業的發展趨勢。本文采用“柯爾莫哥洛夫-斯米爾諾夫曲線”和“受試者工作特征”對企業信用風險模型進行性能評價。
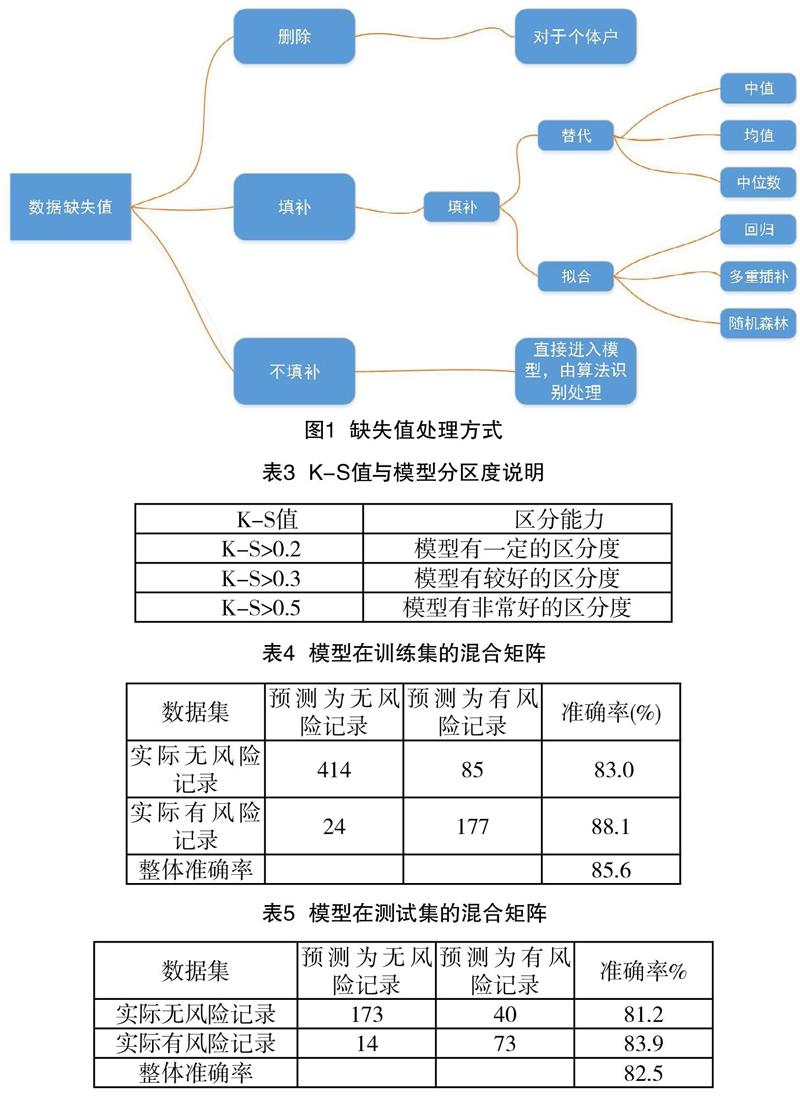
(1)柯爾莫哥洛夫-斯米爾諾夫曲線(Kolmogorov-Smirnov,K-S):將總體樣本進行n等分(通常選用較大數值,如1000),并按模型計算出的違約概率降序排序,計算每一等分中信用風險事件發生的累計百分比(Bad)和信用風險事件未發生的累計百分比(Good),繪制出兩者的差異,驗證兩者的一致性。
(2)受試者工作特征(Receiver Operating Characteristic,ROC)曲線:通過在0到1之間改變用于創建混淆矩陣(Confusion Matrix)的臨界值,繪制Sensitivity(靈敏度)與1-Specificity(1-特殊度)曲線。ROC曲線下的面積為AUC統計量,一般認為AUC統計量≥0.75時,建立的模型具有較好的預測能力。
3? 實例分析
3.1 數據說明與指標體系
本節先根據“國家‘互聯網+監管系統企業信用風險分類評價標準”建立企業信用風險指標體系,再從廣東省各個行政部門獲取過去一年內的企業有關數據集共1000條記錄。我們隨機選擇700條記錄作為模型訓練集;剩余300條記錄作為測試集,用來驗證模型的性能及有效性。其數據格式與指標體系分別如表1、表2所示。
3.2 前期工作
對1000條企業信用記錄,鑒于每條記錄擁有51個變量,可以考慮在建模前對了進行一些預處理工作。如下是實例分析前對數據集進行的預處理說明。
(1)變量的相同率:指的是某個數據集中某個變量的值有多少個是相同的。高度一致的變量值包含的信息量少,無法區分各條記錄的差異,因此會導致該變量對模型的建立不起作用。本文定義變量的相同率閾值identical_limit0.9,高于0.9的變量直接刪除;
(2)缺失值:這是數據挖掘建模中不可避免的步驟,造成數據缺失的原因是多方面的,文本根據企業業務情況,某變量的缺失率閾值missing_limit0.8,高于0.8的變量直接刪除,其余用到如圖1的方式處理。
3.3 結果分析
實例分別運用經典邏輯回歸及證據權重邏輯回歸對企業信用風險數據集建模,并在訓練集、測試集采用(Kolmogorov-Smirnov,K-S)、(Receiver Operating Characteristic,ROC)曲線檢驗模型的有效性。
圖2、圖3為證據權重邏輯回歸法在訓練集、測試集的K-S、ROC曲線圖。其中,圖中的虛線為訓練集、測試集的Good數據(企業無信用風險)與Bad(企業有信用風險)的累積概率分布,其意義表示兩個分布函數是否有差異,用p值衡量,并設置顯著水平為λ=0.05。這里,模型在訓練集、測試集均有,說明兩者來自同一分布。此外,K-S值越大模型性能越好,而模型在訓練集、測試集中分別有K-S=0.5541、K-S=0.5404,查看表3的參考值可知,模型具有非常好的分辨力能。再者,模型在訓練集、測試集的ROC曲線都有不錯的表現,由其與橫坐標圍成的圖形面積值分別為AUC=0.8279、AUC=0.8097,均大于0.75,說明模型的二分類性能良好。最后,我們根據二分類的混合矩陣分析模型在預測陰性(文本為‘無信用風險企業)和陽性(文本為‘有信用風險企業)的單側能力,模型的混合矩陣如表4、表5所示。從表中看到模型在訓練集中識別“有信用風險”的記錄能力為88.1%,201條‘有風險的記錄只有24條記錄被錯誤預測為‘無風險;在測試集中識別“有信用風險”的記錄能力為83.0%,87條‘有風險的記錄只有14條記錄被錯誤預測為‘無風險;同時,模型在上述數據集的整體準確率分別為85.6%、82.5%。
圖4、圖5為經典邏輯回歸算法在訓練集、測試集的K-S、ROC曲線圖,其在訓練集和測試集K-S的值分別為0.5225、0.4306;ROC中的AUC值分別為0.8387、0.7667,很明顯經典邏輯算法在訓練集上有過擬合現象。
不論從K-S值或ROC中的AUC值比較,實例證明帶證據權重邏輯回歸法在企業信用風險模型評估中顯然由于經典的邏輯回歸算法。
4? 結語
本文基于廣東省有關行政部門的真實企業數據,應用證據權重邏輯回歸對其進行信用風險建模。通過對模型的K-S值和ROC中AUC值作了深入分析,并與經典的邏輯回歸做比較,實例驗證了帶證據權重邏輯回歸法在預測企業信用方面的有效性。展望未來,我們會應用決策樹算法的信息增益結合證據權重再次探討它們在企業信用風險評估中的效果,然后做一個全面的分析、歸納。
參考文獻
[1] 國務院辦公廳關于推廣隨機抽查規范事中事后監管的通知[EB/OL].http://www.gov.cn/zhengce/content/2015-08/05/content_10051.htm.
[2] 國務院關于“先照后證”改革后加強事中事后監管的意見[EB/OL].http://www.gov.cn/zhengce/content/2015-11/03/content_10263.htm.
[3] 國務院關于印發2016年推進簡政放權放管結合優化服務改革工作要點的通知[EB/OL].http://www.gov.cn/zhengce/content/2016-05/24/content_5076241.htm.
[4] Odom M D,Sharda R.A neural network model for bankruptcy prediction[C]// IJCNN International Joint Conference on Neural Networks.IEEE, 1990:163-168.
[5] Prinzie A,Poel D V D. Random forest for multiclass classification: random multinomial logit[J]. Working Papers of Faculty of Economics & Business Administration Ghent University Belgium, 2008,34(3):1721-1732.
[6] Yeh C C, Lin F, Hsu C Y. A hybrid KMV model, random forests and rough set theory approach for credit rating[J]. Knowledge-Based Systems, 2012, 33(3):166-172.
[7] Kartasheva A V, Traskin M. Insurers insolvency prediction using random forest classification[J]. Social Science Electronic Publishing, 2013, 10(3): 16-62.
[8] 吳麗麗. 基于Logistic回歸模型的商業銀行信用風險管理研究[D].哈爾濱:哈爾濱工業大學,2007.
[9] 郭玉華. 微型企業信用風險評估——基于Logit模型的分析[J]. 經濟論壇,2011(11):213-216.
[10] 方匡南,范新妍,馬雙鴿.基于網絡結構Logistic模型的企業信用風險預警[J].統計研究,2016,33(4):50-55.
[11] 楊俊,夏晨琦.基于Gradient Boosting算法的小企業信用風險評估[J].浙江金融,2017(9):44-50.
[12] 熊正德,張帆,熊一鵬.引入WFCM算法能提高信用違約測度模型準確率嗎?——以滬深A股制造業上市公司為樣本的實證研究[J]. 財經理論與實踐,2018(1):147-153.
[13] 基于WOE-Probit逐步回歸的信用指標組合篩選模型及應用[J]. 管理科學,2018,48(2):76-87.
[14] 劉麗君,韓靜磊,錢益斌,等.利用靶器官毒性劑量法(TTD)和證據權重分析法(WOE) 評估固化飛灰中重金屬非致癌健康風險[J]. 環境化學,2019,38(5):1014-1020.
[15]趙雅迪,吳釗,李慶兵,等.電費回收風險預測的大數據方法應用[J]. 電信科學,2019,35(2):125-133.
[16] 陳超,王楠,于海洋,等.基于卡方分箱法和邏輯回歸算法的轉爐操作工藝評價模型[J]. 材料與冶金學報,2019,18(2):87-91.
[17] 危明鑄,麥偉杰,袁峰,等.基于機器學習企業運行風險研究[J]. 軟件,2019,40(8):29-37.
[18] H?rdleW, Sperlich S, et al. Nonparametric and semiparametric models[M]. Berlin: Springer, 2004:145-165.
[19] Siddiqi N. Credit risk scorecards[M]. John Wiley & Sons, 2006: 70-125.
[20] Good I J. Weight of evidence: a brief survey[J]. Bayesian statistics. North Holland, Amsterdam 1983, 2: 249-269.
