深度學習在故障診斷與預測中的應用
2020-02-19 14:07:20余萍,曹潔
計算機工程與應用 2020年3期
余 萍,曹 潔
1.蘭州理工大學 電氣工程與信息工程學院,蘭州730050
2.蘭州理工大學 甘肅省工業過程先進控制重點實驗室,蘭州730050
3.蘭州理工大學 電氣與控制工程國家實驗教學示范中心,蘭州730050
1 引言
深度學習(Deep Learning,DL)是一種源于人工神經網絡的機器學習方法,其本質是通過在層次結構中堆疊多層非線性信息處理模塊來模擬數據背后的高級表示,并對模式進行分類和預測。結合特定的領域任務,深度學習可以自動完成對數據的學習,提取出不同水平和維度的有效特征表示,有更高的數據解釋能力。早在20世紀80年代,多層神經網絡的理論就已經被提出[1],典型算法是采用了隨機設定初始值及梯度下降優化策略的BP(Back-Propagation)神經網絡[2-3]。然而過擬合、梯度消失及計算能力受限等問題制約了神經網絡的發展。直到2006年,Hinton團隊提出一種無監督深層神經網絡的有效訓練算法,即深度置信網絡(Deep Belief Networks,DBN)[4-5],它成功地訓練了具有多層網絡結構的受限玻爾茲曼機(Restricted Boltzmann Machine,RBM),在沒有任何監督的情況下呈現了數據的統計特性。這一技術的出現打破了神經網絡發展的瓶頸,同時,伴隨著處理器計算能力的提升,引發了深度學習的熱潮。近年來,涌現出許多新的模型訓練方法,并被用來有效解決越來越多極具挑戰性的問題,在圖像處理[6-7]、醫學圖像分析[8-9]、語音識別[10]、目標檢測[11-12]、文本檢測和識別[13-14]以及自然語言處理[15-16]等諸多領域均獲得了突破性進展。
表1列舉了近五年來一些重要的深度學習研究綜述和專著,這些文獻詳細地反映了深度學習取得的階段性進展或在某一領域的應用概況。表2列舉了目前主流的幾款深度學習開源仿真工具平臺,旨在為研究者提供參考。值得注意的是深度學習在故障診斷與預測中的應用仍屬于新興領域,因此,本文特別強調以下兩個方面:(1)圍繞故障診斷與預測這一研究主題,梳理了五種典型深度學習模型的結構、原理及區別;(2)整理了深度學習在故障診斷與預測領域的最新研究進展,對存在的問題、面臨的挑戰進行了分析,并就解決的辦法以及今后的發展趨勢和研究方向進行了展望。

表1 近五年發表的深度學習相關應用研究綜述和專著

表2 深度學習主流開源仿真工具
2 深度學習模型
2.1 AE及其變體
自動編碼器(AE)是一種典型的前饋無監督神經網絡[71],其結構如圖1所示:包括編碼器和解碼器兩個部分。

圖1 單隱含層自動編碼器結構
編碼器接受輸入x并將其映射到隱層h,其非線性映射關系如下:

式中,φf為非線性編碼激活函數,b為編碼器偏差向量,ω為輸入層與隱層間的連接權值矩陣。隱層H可以看作是數據樣本X的一種更抽象、更有意義的表示。然后,解碼器再以相似的方式將隱層表示映射回原始表示:

式中,φg為解碼激活函數,ω′為解碼器偏差向量,b′為隱層與輸出層間的連接權值矩陣。
定義θ為模型參數集合:

為了使得輸出y與輸入x的重構誤差最小,要對參數θ進行優化,相應的優化問題表示如下:

式(4)表示樣本的平均重構誤差優化指標,N為樣本數。
為了使隱含層的輸出更具魯棒性,三種典型的改進包括:稀疏自動編碼器(Sparse Auto-Encoder,SAE)、去噪自動編碼器(Denoising Auto-Encoder,DAE)和堆疊去噪自動編碼器(Stacked Denoising Auto-Encoder,SDAE)。
2.1.1 SAE
為防止樣本性質的波動,在隱層單元上增加稀疏性約束[72],使得學習到的隱層表示成為稀疏表示,相應的優化功能更新為:

式中,m是隱含層的層數,第二項是隱層單元上的Kullback-Leibler(KL)散度總和。其中:

式中,p是預先定義的平均激活目標,pj是整個數據集中第j個隱藏神經元的平均激活度。
2.1.2 DAE
DAE的思想是將含有噪聲的數據樣本作為輸入送入編碼器進行編碼,再通過解碼器從含噪的樣本中去重建去噪后的輸入。最常用的噪聲是dropout噪聲,它隨機地將輸入特征的一部分設置為零[73]。增加了去噪功能的DAE增強了噪聲干擾情況下的網絡魯棒性。
2.1.3 SDAE
SDAE的思想是通過將第j層的輸出作為第j+1層的輸入,這樣可以將多個DAE堆疊在一起,逐層完成貪婪訓練,從而形成更深層的網絡來學習高級表示[74]。SDAE依然采用梯度下降算法來訓練網絡參數。經過SDAE的分層預訓練后,可以將自動編碼器的參數設置為DNN所有隱藏層的初始值,然后執行受監督的微調以最小化預測錯誤。在網絡輸出端通常添加一個SoftMax回歸層,以將最后一層輸出映射到目標。研究表明,基于SDAE的預訓練DNN模型,相比隨機初始化條件下的DNN具有更強的收斂能力[75]。
2.2 DBN
深度置信網絡(DBN)是由疊加多個受限玻爾茲曼機(RBM)來構建的。RBM是具有一個顯層和一個隱層的雙層神經網絡,如圖2(a)所示,顯層(v)與隱層(h)之間存在對稱連接約束,但層內節點之間無任何連接。RBM可以從訓練數據分布中得到潛在的特征表示,因此它是一個生成模型[76]。

圖2 受限玻爾茲曼機(RBM)與深度置信網絡(DBN)
給定模型參數θ=[ω,a,b]時,能量函數可定義為:
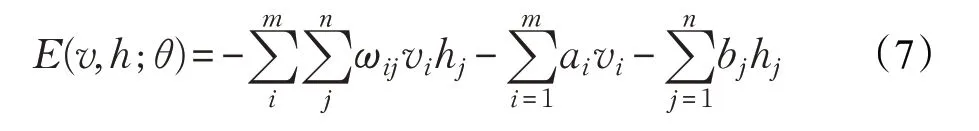
式(7)中,ωij表示顯層和隱層間的連接權值;ai表示可視層偏置值;bj表示隱層偏置值。根據能量函數E計算所有單元的聯合分布:


RBM采用了無監督的對比散度算法(Contrastive Divergence,CD)進行網絡訓練,訓練目標是使聯合概率最大化。
疊加多個RBM就構成了DBN,它具有學習訓練數據深層表示的能力,其中第i層(隱層)的輸出作為第i+1層(顯層)的輸入,結構如圖2(b)所示。與SDAE類似,DBN也是通過無監督的逐層貪婪學習算法進行網絡訓練,學習過程包含預訓練和微調兩個步驟。
2.3 CNN
卷積神經網絡(CNN)是一種典型的監督型前饋神經網絡,它的訓練目標是通過交替和疊加卷積核以及池化操作來實現對抽象特征的學習。結構上主要包含三部分:卷積層(Convolution layer)、池化層(Pooling layer)和全連接層(Fully Connected layer,FC layer),如圖3所示。
卷積層采用多個卷積核來實現對多特征的提取,每一層的輸出都是對多輸入特征進行卷積,數學模型如下:

池化層的作用是通過池化操作將特征空間的尺寸減半,從而在保證特征不變性的情況下,降低特征維度。常見的池化操作有最大值池化(Max-pooling)和均值池化(Mean-pooling)。
最后,輸入數據在經過多次卷積和池化后,傳遞到一個或多個完全連接(FC)層,其結果將作為頂層分類器(例如,SoftMax)的輸入。
CNN的訓練方式包括前向傳播和反向傳播。首先,輸入信號經過多次卷積、池化、全連接運算得到實際輸出信號,并計算實際輸出和理想輸出的差;然后利用BP算法反向逐層傳遞誤差;最后利用梯度下降法更新各層參數[77]。
近年來CNN的主要改進技術體現在兩方面:(1)采用ReLU、GeLU等改進的非線性激活函數[78],加速了網絡的收斂速度,更適應深層網絡的訓練;(2)采用了深層網絡的正則化方法[79],很大程度地防止了訓練過程中的過擬合現象。
2.4 RNN
循環神經網絡(RNN)是一個處理順序數據的框架,通過每層之間節點的連接結構來記憶之前的信息,并利用這些信息來影響后面節點的輸出。RNN可充分挖掘序列數據中的時序信息以及語義信息,這種方式在處理時序數據時比全連接神經網絡和CNN更具有深度表達能力。如圖4所示,多層感知器只能從輸入數據映射到目標向量,而RNN能夠從以前輸入的整個歷史映射到目標向量,從而利用過去的信息克服簡單神經網絡的局限性。RNN以后向傳播的方式通過時間對受監控的任務進行訓練。
RNN可以使用其內部存儲器來處理順序數據,t時刻的隱層神經元狀態ht由該時刻的輸入xt和前一時刻的隱層神經元狀態ht-1確定。在典型的vanilla RNN中:

圖3 基于CNN的故障診斷流程

圖4 多層感知器與典型RNN

式中,φ為非線性可微轉移函數,采用不同的轉移函數可以形成不同的RNN模型;ω為隱層與輸入層的連接權值,u為隱層神經元之間的連接權值,b為偏置值。
對于分類任務,通常加全連接層和softmax分類層,將序列映射到特定類別標簽[80]。
2.5 GAN
Goodfellow等人2014年提出了生成對抗網絡(Generative Adversarial Network,GAN)[81]。盡管出現的時間較短,但以其獨特的特點迅速成為了機器學習領域最令人興奮的突破之一。GAN結構如圖5所示,生成器(FG)和鑒別器(FD)巧妙地展開相互競爭,生成器試圖混淆鑒別器,而鑒別器則試圖區分輸入數據集中的生成器生成的樣本和原始的實際樣本,由此建立了一個零和博弈的框架。在這個框架中,生成器和鑒別器不斷競爭,各自獲得更強的模擬原始數據樣本和迭代識別的能力[82]。

圖5 GAN結構示意圖
3 深度學習在故障診斷與預測中的應用
3.1 研究背景
系統的異常檢測和故障診斷一直是學術界關注的重點問題,而隨著工業設備日趨復雜化、大型化和智能化,高效獲取準確、完備的診斷信息越來越困難。傳統的診斷技術已很難滿足現代工業的故障診斷需求,迫切需要能夠將故障機理、模型建立、特征提取與分類方法等相關問題相融合的混合智能故障診斷技術,而深度學習的出現為這一技術的實現提供了新的思路和途徑。下面從三個方面分析未來工業的故障診斷與預測為什么需要深度學習。
(1)故障復雜性
復雜工業系統從結構上來說具有多層次、互相關和復雜性等特點,這就導致了系統的故障具有了傳播性、耦合性、繼發性和不確定性的特點。舉例說明,一個微小故障的存在可能引發大型故障的出現,或隨著系統結構層次進行故障傳播從而引發一系列故障,繼發多故障的耦合,最終對設備構成致命性毀壞。在這一過程中僅故障種類就包含了早期微小故障、復合故障、系統故障等。微小故障具有潛在性和動態響應微弱的特點;復合故障和系統故障由于多因素耦合和傳遞路徑復雜,導致難以有效溯源故障成因。這些都為故障診斷帶來了難度,傳統基于數據的故障診斷技術中人工設計并提取故障特征的方法已遠遠不能滿足實際需要,而能夠進行數據深層挖掘、自動提取故障特征、具有端對端操作特點的深度學習技術必將成為整個故障診斷體系中的關鍵性技術。
(2)環境復雜性
系統未知的干擾和噪聲會對故障信號產生很大的影響,例如微小故障信號的幅值較低,很容易被未知擾動和噪聲信號所掩蓋,尤其是當噪聲和微小故障信號發生混疊時,就很難對其進行區別。而深度學習方法中已有很多優秀的改進模型用來幫助解決此類問題,如堆疊去噪自動編碼器(SDAE)、自帶去噪功能的CNN等。此外,由于數據采集、傳輸、存儲過程中受環境影響所導致的異常以及傳感器自身漂移等因素,都將使得系統的故障和征兆具有隨機性、模糊性和信息不確定性等特點,這些都需要進行深度的數據挖掘來實現故障的有效識別。
(3)數據復雜性
隨著信息化技術的發展,未來復雜工業系統將不僅能獲得到時間與空間兩個維度上不同尺度的海量數據,還能獲取到不同來源、不同工況、不同部門、不同類型的海量數據,這就為數據的處理帶來了巨大難度。如何實現對海量故障數據的快速分析和深度挖掘是大數據時代的挑戰性難點,而深度學習方法必將是攻克這一難題的有力武器。
3.2 發展趨勢
如圖6所示,隨著深度學習技術的不斷發展,在故障診斷領域中,數據處理的方法已由單一算法逐漸演變到混合模型算法,例如深層/淺層網絡的相互合作等;應用范圍也越來越廣,從最初的機械設備到風力發電設備,再到航空航天設備等,普遍性和實用性獲得了極大的提升;技術側重點也從故障診斷到退化狀態研究,再到故障預測。由此可見,深度學習在這一領域的發展是值得期待的。

圖6 基于深度學習的故障診斷與預測研究概覽
3.3 深度學習用于故障診斷的一般流程
基于深度學習的故障診斷基本框架如圖7所示,包括定義狀態階段、數據預處理階段、訓練階段、測試階段及診斷結果評估階段等五個步驟。

圖7 基于深度學習的故障診斷基本框架
易見,基于深度學習的故障診斷方法的特點在于:(1)與“淺”層網絡不同,深度學習沒有人工設計故障特征環節,將故障特征選擇提取和分類模型訓練合為一體;(2)深度學習是多隱層網絡,能夠避免維度災難和“淺”層網絡診斷能力不足的局限性。
3.4 數據來源
數據是所有機器學習和人工智能方法的基礎。為了進行有效的故障檢測,使得研究方法的驗證結果更有說服力,必須對數據集的可靠性、實用性和通用性做很好的評估。但實際采集數據耗時嚴重,例如軸承劣化過程可能需要很多年的時間,因此大多數研究人員都采用人工注入故障的方法來收集數據。因此,除了規范的實際實驗數據以外,目前幾種典型的可用于測試、評估和比較不同的算法的通用故障數據集如表3所示。從現有文獻來看,CWRU數據集[83]用于軸承故障識別的應用研究最多,有利于研究結果的對比。而更多的數據集的出現,也為深度學習故障診斷與預測提供了更豐富的選擇。
3.5 深度學習方法在故障診斷與預測中的應用
3.5.1 基于AE的故障診斷方法
在故障診斷中使用自動編碼器的研究報道較多。文獻[93]使用了深度為5的AE網絡實現了自適應提取故障特征及有效分類的軸承故障診斷,分類精度達到99.6%,明顯高于70%的反向傳播神經網絡。為減少噪聲對故障特征的干擾,文獻[94]以多級齒輪傳動系統為研究對象,在多工況條件下基于去噪自編碼器(DAE)對多種故障進行了診斷,實驗結果表明,其診斷準確率明顯高于單隱含層BPNN、多隱含層BPNN及基于常用特征的SVM分類。在文獻[95]中,實現了一種由三個堆疊的自編碼器組成的堆疊去噪自動編碼器(SDAE),實驗中原始的CWRU軸承數據受到15 db隨機噪聲的干擾,用以實現噪聲條件的模擬,并以多工況數據集作為測試集,檢驗其在轉速和負載變化下的故障識別能力。實驗表明,該方法達到了最低91.79%的診斷準確率,比傳統的SAE高3%~10%。在文獻[96]中使用了另一種形式的SDAE,CWRU數據集的信號與時間域中不同級別的人工隨機噪聲相結合,然后轉換為頻率信號。該方法比DBN網絡具有更高的診斷精度,特別是在附加噪聲的情況下,故障診斷精度提高了7%。文獻[97]有效集成了DAE和Elastic Net(EN)來解決故障診斷中的噪聲干擾問題,實驗結果表明,該方法能有效地檢測工業過程中的異常樣本,并能準確地將故障變量與正常變量隔離開來。為應對處理較大數據集的需要,文獻[98]提出一種引入了dropout技術和ReLU激活功能的堆疊式自動編碼器(SAEs)來解決齒輪箱故障診斷問題,在自動提取顯著故障特征的同時,減少了訓練過程中的過擬合問題,提高小訓練集的訓練性能。實驗結果表明,該方法優于原編碼器及其他一些傳統方法。文獻[99]構建了一種4層的堆疊稀疏自動編碼器(SSAE),該方法對振動數據進行非線性投影壓縮,壓縮比為70%,并在變換域內進行自適應特征提取,分類精度高達97.47%,比SVM高8%,比傳統單隱層人工神經網絡高60%,比多隱層人工神經網絡高46%。

表3 若干典型的故障診斷測試數據集
此外,研究者也開展了著重于混合式設計以改進診斷性能研究和早期微小故障的研究。如文獻[100]設計了一種由一系列不同激活功能的自動編碼器(AE)集成的深度自動編碼器(Ensemble Deep Auto-Encoders,EDAE),然后按照一種組合策略來確保診斷結果的準確性和穩定性。實驗結果表明該方法的分類精度為99.15%,與BPNN(88.22%)、SVM(90.81%)和RF(92.07%)相比,性能顯著提升。文獻[101]采用了一種基于自動編碼器的極限學習機(Extreme Learning Machine,ELM),綜合了自動編碼器的自動特征提取能力和ELM的高訓練速度優點。與小波包分解支持向量機(WPD-SVM)(94.17%)、經驗模態分解支持向量機(EMD-SVM)(82.83%)、WPD-ELM(86.75%)和EMDELM(81.55%)相比,平均準確率為99.83%。更重要的是,由于采用了ELM,使用相同的訓練和測試數據,所需的培訓時間減少了60%到70%。文獻[102]構造了一種深耦合自動編碼器(DCAE)模型,將捕獲到的不同多模數據之間的關鍵信息無縫集成到數據中加以融合,即從多模數據中獲取聯合信息進行故障診斷,實驗結果表明,該模型能夠進行準確的故障診斷,具有更好的性能。文獻[103]提出一種新的軸承智能診斷方法,通過創建新子集的方法從不同的故障模式中學習并識別特征,在此基礎上提出了一種具有自適應微調功能的基于子集的深度自動編碼器(Subset Based Deep Auto-Encoder,SBDA)模型來實現特征的自動提取。該方法以三個公共軸承數據集為對象進行了實驗驗證,平均測試精度分別為99.65%、99.66%和99.60%。與13種智能診斷方法的比較表明,SBDA能獲得更高的診斷精度。文獻[104]提出了一種由自動編碼器和SoftMax分類器構成深度學習網絡(Deep Learning Network,DLN),用于識別不同程度的軸承故障。首先,通過集成經驗模態分解(Ensemble Empirical Mode Decomposition,EEMD)方法形成高維特征向量作為DLN的輸入;然后,在DLN中完成學習和參數微調用以減小分類誤差。實驗結果表明,該方法對軸承故障診斷具有較好的效果,也為更復雜的數據分類提供了有力的理論與實驗研究基礎。文獻[105]提出了一種基于深度自動編碼器的無監督電機故障診斷方法。該方法利用加速度計獲取振動信號,僅通過正常數據進行網絡訓練。實驗以接收機工作特性曲線的曲線下面積(Area Under Curve,AUC)對診斷性能進行了評價,結果表明多層感知器(MLP)自動編碼器、卷積神經網絡自動編碼器和由長短期記憶(Long Short-Term Memory,LSTM)單元組成的循環式自動編碼器都優于OCSVM(One-Class Support Vector Machine)算法。這其中,MLP自動編碼器是性能最高的體系結構,實現了99.11%的AUC。文獻[106]基于疊層稀疏自動編碼器,實現了一種能夠提高分類和預測精度的實時在線處理方案,對傳統統計技術檢測不到的早期故障具有較高的檢測效率。
3.5.2 基于DBN的故障診斷方法
作為最早出現的深度學習模型,早在2013年就有報道基于DBN的故障診斷研究結果。文獻[107]提出基于DBN的多傳感器健康診斷可分為三個階段:第一階段,定義用于DBN訓練和測試的數據集;第二階段,開發基于預定義好的健康狀態的DBN分類診斷模型;第三階段,驗證DBN分類模型。并與現有的SVM等四種診斷技術進行了比較,證明了該方法的有效性。
近年來,DBN更多的是與其他技術相結合來解決故障診斷問題。文獻[108]實現了一種多傳感器振動數據融合技術,融合了通過多個二層SAE提取的時域和頻域特征;然后利用基于三層RBM的DBN進行分類。結果表明,即使在運行工況發生變化后,也能有效地識別軸承故障,該方法的診斷精度達97.82%。文獻[109]提出了一種基于DBN的變壓器故障診斷方法,通過分析變壓器油中溶解氣體與故障類型的關系,確定氣體的非編碼比作為DBN模型的特征參數,并采用多層和多維映射的方法提取斷層類型的更詳細差異,在此基礎上構建并測試了DBN診斷模型。通過不同的特征參數、不同的訓練數據集和樣本數據集,分析了DBN診斷模型的性能,實驗結果表明,該方法大大提高了電力變壓器故障診斷的準確性。文獻[110]針對軸承故障分類問題,提出了一種自適應DBN和雙樹復小波包(Dual-Tree Complex Wavelet Packet,DTCWPT)相結合的診斷方法。首先利用DTCWPT對振動信號進行預處理,在振動信號中生成具有9×8特征參數的原始特征集,然后利用5層自適應DBN(“72-400-250-100-16”結構)進行故障分類。實驗表明該方法的平均準確率為94.38%,遠高于ANN(63.13%)、GRNN(69.38%)和SVM(66.88%)的診斷精度。文獻[111]提出了一種改進的壓縮傳感卷積DBN網絡(Convolutional Deep Belief Network,CDBN),用于滾動軸承的故障特征學習和故障診斷。在采用CS(Compressed Sensing)降低振動數據量的基礎上,構造了一個新的CDBN模型并采用指數移動平均(Exponential Moving Average,EMA)技術,提高了網絡的泛化性能。實驗結果表明,相對于傳統方法,該方法更有效。類似的,在文獻[112]中,采用卷積RBMs構造卷積DBN,首先,將自動編碼器壓縮降維后的數據送入基于高斯可見單元的卷積DBN學習故障特征,然后利用SoftMax層進行分類,得到了97.44%的準確率,與同條件下的AE(90.76%)、DBN(88.10%)和CNN(91.24%)相比,具有更好的分類精度。在文獻[113]中,由多個DBN進行特征提取,然后根據提取的特征確定故障條件,在負載變化情況下進行診斷,并最終通過DS(Dempster-Shafer)證據理論融合診斷結果,診斷準確率達98.8%。為進一步克服缺陷、提高網絡性能,文獻[114]針對不平衡數據的分類問題,提出了一種進化的成本敏感DBN網絡(Evolutionary Cost-Sensitive Deep Belief Network,ECS-DBN)。ECS-DBN采用自適應差分進化算法,將錯誤分類成本進行優化后,應用于DBN網絡中。實驗結果表明,該方法在故障診斷基準數據集和現實數據集上均有很好的診斷能力。文獻[115]提出了一種結合奈斯特羅夫動量的自適應學習速率DBN網絡,分別在齒輪箱和機車軸承試驗臺的數據集上進行實驗驗證,結果表明,該方法的故障識別率得到顯著提升,證明了該方法的準確性和魯棒性。文獻[116]提出了一種基于DBN和傳遞學習策略的高壓斷路器機械故障診斷方法。首先,利用DBN實現了對樣本數據故障特征的深度挖掘和自適應提取,并結合傳遞學習方法,通過調整訓練樣本的權重來實現數據學習的目標。結果表明,該方法可獲得更強的泛化能力。
3.5.3 基于CNN的故障診斷方法
自2016年CNN被用于識別軸承故障以來,出現了很多基于這一主題的文獻報道,從數據源處理、抗噪、提速、結構改進、靈敏性等多方面、多角度不斷提升CNN的故障診斷性能和適用范圍。文獻[117]采用了一種傳感器融合方法,將從驅動端和風扇端兩個加速度傳感器采集的CWRU原始數據進行時空信息疊加,從而將一維時間序列數據轉換為二維輸入矩陣。樣本的70%用于訓練、15%用于驗證、15%用于測試;實驗結果表明,基于兩個傳感器數據的平均診斷精度為99.41%,高于只有一個傳感器時98.35%的平均診斷精度。文獻[118]中使用的自適應交疊CNN(Adaptive Overlapping Convolutional Neural Network,AOCNN),能夠直接處理一維原始振動信號,并消除嵌入在時域信號中的移位變量問題。該方法在自適應卷積層將樣本分割成若干段后,采用稀疏濾波(Sparse Filtering,SF)的方法獲取局部特征。分類結果表明,采用SF的AOCNN能診斷出軸承的10種健康狀況,檢測準確率達99.19%。針對實際軸承損傷數據很難甚至不可能收集到,轉而使用人工軸承損傷數據從而產生的應用差異問題,文獻[119]使用了德國Paderborn大學軸承數據集,此數據集包括人為誘發故障和機器老化導致的實際自然故障。該文獻提出了一種新的基于空洞卷積的深度初始網絡模型(Deep Inception Net with Atrous Convolution,ACDIN),當僅使用人工軸承損壞產生的數據進行訓練時,ACDIN將實際軸承故障的診斷精確度從75%(傳統數據驅動方法的最佳結果)提高到95%。此外,文中還利用特征可視化方法分析了該模型高性能背后的機理。文獻[120]提出了一種基于故障位置和損傷程度不同而對原始振動信號進行智能分類的故障診斷方法。通過將數據集轉換成光譜圖的方式,最大程度地保留時域信號的原始信息,然后利用深度全卷積神經網絡進行訓練。實驗結果表明,此方法收斂速度快,精度高達100%,具有更好的泛化能力。針對含噪信號所導致的診斷精度不高的問題,文獻[121]實現了具有2個卷積層和2個匯集層的4層CNN結構,其精度優于傳統的SVM和淺層SoftMax回歸分類器,特別是當振動信號與環境噪聲混合時,這種改進可以提升25%的診斷準確率,體現了CNN算法出色的去噪能力。文獻[122]提出了一種基于CNN的滾動軸承故障診斷新方法,通過將一維振動信號轉換成二維圖像,并利用CNN對圖像分類的有效性,可使CWRU軸承數據集達到100%的診斷精度。此外,當負載條件發生變化時,在不重新訓練分類器的情況下,該方法仍能以較高的精度獲得滿意的性能,具有較強的魯棒性和抗噪聲能力。為了節省CNN算法訓練時間,在文獻[123]中采用了多尺度深度CNN(Multi-Scale Deep Convolutional Neural Network,MS-DCNN),使用不同尺度的卷積核并行提取不同尺度的特征。實驗對比9層一維CNN、二維CNN和提出的MS-DCNN的平均精度分別為98.57%、98.25%和99.27%。此外,MS-DCNN需要確定的網絡參數數量僅為52 172個,遠遠低于一維CNN(171 606個)和二維CNN(213 206個)。文獻[124]構建了一個新的深度學習框架,并利用遷移學習來實現高精度的機器故障診斷,實驗結果表明該算法訓練速度快、精度高。文獻[125]在傳統CNN結構的基礎上,加入一個錯位層,可以更好地提取不同信號之間的關系,最終實驗中獲得了96.32%的診斷準確率,相比傳統CNN83.39%的診斷準確率,性能得到了很大的提升。文獻[126]提出了一種新的基于LeNet-5的CNN故障診斷方法。將信號轉換成二維圖像作為網絡的輸入,并利用電機軸承、自吸離心泵、軸向柱塞液壓泵這三個基準數據集進行了測試,預測精度分別為99.79%、99.481%和100%。實驗結果優于自適應深度CNN、稀疏濾波、深度置信網絡和支持向量機等。文獻[127]提出了一種包含一維殘差塊的更深層的一維卷積神經網絡(Deeper One-Dimensional CNN,Der-1DCNN),在框架內還包含了殘差學習的思想并首次采用了寬卷積核和dropout技術,有效地緩解了網絡訓練難度和性能退化的問題,提高了網絡的泛化性能。實驗表明,該方法與目前常規的軸承故障診斷深度學習方法相比,具有更好的診斷性能。文獻[128]實現了一種基于CNN的新體系結構(即LiftingNet),該結構包括分割層、預測層、更新層、匯集層和完全連接層,主要學習過程有分割、預測、更新和循環。利用CWRU數據集對方法進行了分類性能驗證,轉速相同情況下分類精度為99.63%,四種不同的轉速下平均精度仍達到93.19%,比常規方法高14.38%。針對普遍存在的故障診斷中由于標記樣本的體積較小所造成的DL模型的深度較淺,限制了最終預測精度的問題,文獻[129]基于ResNet-50提出一種遷移學習卷積神經網絡(Transfer Convolutional Neural Network,TCNN)用于故障診斷。首先,將時域故障信號轉換為RGB圖像格式作為ResNet-50輸入;然后對所提出的TCNN在軸承損壞數據集、CWRU電機軸承數據集和自吸離心泵數據集三個數據集上進行測試。實驗結果表明TCNN(ResNet-50)的預測精度高達98.95%±0.007 4、99.99%±0和99.20%±0,明顯優于其他DL模型和傳統診斷方法。此外,從提高診斷靈敏性角度出發,以早期微小故障為對象的診斷方法研究是極具現實意義的研究方向,值得深入研究。文獻[130]提出了一種基于卷積神經網絡的變速軸承早期故障診斷新方法。結合譜能量圖(SEM)和DS-DLM算法,實現了可變操作速度下的軸承早期故障診斷,效果顯著。
3.5.4 基于RNN的故障診斷方法
早在2005年就出現了將RNN用于故障診斷的文獻[131],2008—2010年出現了大量此類文獻,但由于梯度消失/爆炸及難以訓練等問題該方法經歷了一段時間的沉寂,直到2015年才逐漸復蘇。文獻[132]中將RNN用于軸承故障診斷,首先,利用離散小波變換提取故障特征,并進行特征選擇,然后,輸入RNN進行故障分類。實驗表明,該方法在非平穩工況下也能準確地檢測和分類軸承故障。文獻[133]中提出了一種將一維CNN和LSTM結合起來進行軸承故障分類的方法,整體結構包括一維CNN層、Maxpooling層、LSTM層和SoftMax層。實驗測試精度為99.6%。文獻[134]中提出一種具有堆疊隱藏層的LSTM單元,以均方誤差(MSE)作為損失函數,并采用自適應學習率來提高訓練效果。基于CWRU數據集的診斷實驗顯示,該方法在轉速為1 750轉/min和1 797轉/min時的平均測試精度分別為94.75%和96.53%。文獻[135]提出了一種新的基于RNN的軸承故障診斷方法。該方法利用了具有很強的泛化能力的基于GRU的非線性預測去噪自動編碼器(GRU-NP-DAEs),從上一周期預測下一周期的多次振動值,然后利用下一周期數據與GRU-NP-DAE生成的輸出數據之間的重構誤差,對異常情況進行檢測,并進行故障分類。實驗結果表明,該方法具有較強的魯棒性和較高的分類精度,性能優秀。
3.5.5 基于GAN的故障診斷方法
2014年提出的生成對抗網絡(GAN)在故障診斷領域最早的應用報道出現在2017年[136],該文獻針對故障數據量遠小于正常數據量而導致的數據不平衡問題,設計了一個用于故障檢測和診斷的深度神經網絡,并將生成對抗網絡的過采樣與標準的過采樣技術進行了比較。仿真結果表明,在給定條件下,生成對抗網絡的過采樣性能良好,所設計的深度神經網絡能夠對異步電動機的故障進行高精度的分類。文獻[137]提出了一種用于滾動軸承無監督故障診斷的分類對抗式自動編碼器(Categorical Generative Adversarial Auto-Encoders,CatAAE)。該模型用對抗性方法訓練了一個在編碼空間上施加先驗分布的自動編碼器,然后,分類器通過預測分類和樣本間的信息平衡對輸入樣本進行聚類。實驗結果表明,當環境噪聲和電機負載發生變化時,該方法具有良好的性能和較高的聚類指標,且具有較強的魯棒性。文獻[138]提出了一種結合GAN和SDAE的故障診斷方法。首先,利用GAN生成器產生與振動信號原始樣本分布相似的新樣本。然后,將生成的樣本和等量原始樣本一起輸入SDAE進行分類,并對新模型進行了并行優化。實驗結果表明,該方法可在小樣本情況下實現精確故障分類,且具有良好的抗噪聲能力。文獻[139]提出了一種將Wasserstein GAN與傳統分類器相結合的混合生成對抗網絡,同樣可以解決小樣本情況下的能耗元件的自動故障診斷問題,在訓練過程中以有限的故障訓練樣本模擬現實場景進行故障診斷,實驗結果證明了該方法的有效性。文獻[140]提出了一種新的基于生成對抗網絡(GAN)的工業時間序列不平衡故障診斷方法。在GAN中采用了編碼器-解碼器-編碼器三個子網絡,該子網絡基于深度卷積生成對抗網絡(Deep convolutional GAN)。為了驗證該方法的有效性和可行性,利用CWRU滾動軸承數據進行了驗證,性能良好。
3.5.6 基于深度學習的故障預測方法
故障預測是依靠歷史數據來估計預測對象未來時刻工作狀態的方法。深度學習具有深度特征學習和復雜非線性函數逼近的能力,表明了其在故障預測中的有效性。然而,就目前的研究成果看,此類文獻還比較少,有待研究者做進一步研究。文獻[141]中,將多目標進化算法與傳統的DBN訓練技術相結合,將多個DBN同時進化為兩個相互沖突的目標,再用進化后的DBN構建一個用于剩余壽命(Remaining Useful Life,RUL)估計的集成模型,通過差分進化算法優化模型組合權重,并在幾種預測基準數據集上進行算法評估,驗證了方法的優越性。文獻[142]應用帶FNN的DBN進行自動特征學習,在軸承座上垂直于軸的方向安裝了兩個加速度計,每5分鐘采集一次數據,采樣頻率為102.4 kHz,持續時間為2 s,實驗結果表明,所提出的基于DBN的方法能夠準確預測未來5 min和50 min的真實RUL。文獻[143]研究了常規RNN、AdaBoost-LSTM和GRU(Gated Recurrent Unit)-LSTM三種RNN模型在航空發動機故障預測中的應用。文獻[144]提出了一個非常有效的RUL預測結構,設計了一種基于LSTM的編碼器-解碼器結構。首先,通過編碼器將多變量輸入序列轉換成固定長度的矢量,再利用該矢量生成目標序列,然后,在無監督情況下進行網絡訓練,最后,利用重建誤差計算健康指數,并將其用于RUL估計。從實驗結果可以看出,較大的重建誤差對應于更不健康的機器狀況,實現了基于重建誤差的機器健康狀況表征。文獻[145]提出了一種基于深度學習的故障預測方法,通過故障模型訓練、故障特征識別、故障演化等方法,在設備狀態監測和測試驗證的海量數據基礎上,實現了在線動態故障預測。文獻[146]提出了一種基于稀疏自動編碼器的深度轉移學習(DTL)網絡。采用三種轉移策略,將由歷史故障數據訓練的SAE轉移到新的目標上。并以刀具剩余使用壽命(RUL)預測為例,驗證了DTL方法的有效性。文獻[147]提出了一種基于長短期記憶(LSTM)網絡和支持向量機(SVM)的電力系統故障預測方法。根據南方電網萬江變電站的實際電力系統數據進行了實驗,結果表明與現有的數據挖掘方法相比,該方法有明顯的改進。文獻[148]分別用長短時記憶(LSTM)網絡、棧式自編碼器(SAE)和門循環單元(GRU)神經網絡,實現了電力負荷的預測,驗證了深度學習模型在預測應用中的可行性,并從中選擇了最佳預測模型。文獻[149]提出了一種新的在線數據驅動框架,利用深卷積神經網絡(CNN)預測軸承的RUL。首先利用Hilbert-Huang變換(HHT)對訓練數據進行處理,并構造一種新的非線性退化指標,然后利用CNN識別出退化指標與振動數據之間的隱藏模式,最終實現了對軸承退化的自動估計。實驗結果表明,與目前最先進的RUL估計方法相比,該框架具有更好的性能和通用性。
3.5.7 五種模型應用于故障診斷與預測的優缺點
結合文獻,表4整理了故障診斷與預測領域中常用的五種深度學習方法的優缺點。

表4 五種模型應用于故障診斷與預測的優缺點
4 總結與展望
4.1 存在的問題及解決方法探索
作為一個新興的、重要的研究領域,深度學習在很多應用中都顯示出巨大的威力和潛力。但是,在故障診斷方面仍然存在一些需要進一步發展和完善的空間。
4.1.1 從數據角度
(1)缺乏大量的有效數據
基于深度學習的故障診斷方法性能的好壞很大程度上取決于數據集的規模和質量,即依賴于大量優秀的數據。然而,現實中這通常是做不到的。首先,設備無法承受在故障條件下運行的嚴重后果,其次,設備存在發生預期故障前的潛在耗時退化過程,也就是說從非目標機器上采集的公共可用數據集或自收集數據集和實際的目標機器的運行軌跡不可能完全吻合,勢必由于目標設備的自然老化而存在差異性,即使在同一臺機器在不同的負載設置下,也不可避免地存在訓練集和測試集的分布差異,性能仍然會受到影響。相較于圖像識別領域中由包含1 000多萬個注釋圖像的大型數據集ImageNet作為支撐,基準CNN模型就能達到152層的巨大優勢,大量有效數據的缺乏是基于深度學習的故障診斷技術的發展瓶頸之一。
遷移學習的出現為解決這一問題提供了新的思路和方法,多種遷移學習的框架被提出[150]。目前比較流行的方法是域自適應[151],通過研究域不變特征自適應建立從源域到目標域的知識遷移。對于源域的標記數據和目標域的未標記數據,域自適應算法可以減小兩域之間的分布差異。從這個角度出發,設計新的域自適應模塊與深度學習體系結構相結合,用來克服有效數據的不足問題,是一個值得研究的方向。此外,GAN網絡的出現也為這一問題的解決提供了新思路,可以模擬任何數據分布的強大功能勢必使得GAN在解決有效數據量缺乏這一問題上提供非凡助力。
(2)使用數據源單一,且不平衡
從前述文獻分析中可以看到,現有文獻大多數使用了CWRU數據集。很多精度超過99%的DL方法都是在固定的運行條件下獲得的,這勢必影響測試精度的準確性,一旦受到噪聲或電機轉速/負載變化的影響,精度可能下降到90%以下,而這種影響在實際應用中是不可避免的。此外,樣本的選擇并沒有保證均衡抽樣,這意味著健康狀態和故障情況不接近1∶1,存在嚴重的不平衡,這時僅采用精度作為評估算法的唯一指標顯然會影響算法在實際應用中的有效性。
針對此問題,認為如果考慮選用通用數據集,則首先需要對原始數據集進行各種干擾以此來打破數據集的飽和度,即用隨機噪聲污染信號來測試算法的去噪能力,其次,可以選擇更為復雜的數據源,比如前文提到的德國Paderborn大學提供的故障數據庫,或多個數據源綜合驗證的方法進行性能比較可能結果更為準確和有效。同時,可搭建實驗仿真分析平臺,注入不同類型的故障,得到不同故障對應的仿真信號,通過分析故障機理的方式對深度學習方法進行有益的補充,或許是一個可行的研究思路。
(3)數據處理的復雜性
如前所述,數據的復雜性不言而喻,如何對樣本多源、且存在標注不規范、不統一、不全面的數據進行有效處理是提高深度學習性能不可回避的重要問題。筆者認為,增設完善的數據預處理平臺,多角度出發搭建各自獨立又逐層遞進的子網絡來實現不同類型的數據處理,待數據轉化為統一的數據規范類型后再輸入深度學習網絡中進行故障特征提取和分類不失為一種可行的思路。
4.1.2 從結構角度
(1)缺乏理論證據
目前,很多深度學習模型正被用于解決特定的故障診斷問題并取得了很好的效果。但是研究者沒有解釋深層網絡內部的計算機制,也就是說缺乏足夠豐富的理論證據說明為什么在故障診斷和預測中使用深度學習可以獲得特定的結果以及如何去選擇、設計或實現深度學習體系結構。
針對這一問題,認為模型和數據可視化是可以嘗試的途徑之一。學習的表示和應用模型的可視化可以為這些深度學習模型的選擇、設計提供參考。例如,用于高維數據可視化的t-SNE算法模型[152]以及2016年提出的可視化操作平臺Deep Motif Dashboard[153]等。
(2)深度網絡結構的優化
從前述文獻中不難看出,基于深度學習的故障診斷方法具有訓練數據多、計算量大的特點,這成為深度學習方法在故障診斷領域實現在線診斷以及故障預測的瓶頸之一。這就要求研究者施加結構限制以控制各種深度學習架構的計算量,同時,又不能以降低診斷精度為代價。尋找一些精度與速度之間的平衡,或者在保證精度的前提下,引入其他方法來提高速度的方法更加值得研究,例如,實現并行操作,包括GPU加速、數據并行和模型并行等。
(3)模型的參數優化
在模型構建過程中參數的動態優化調整是其發展的一大挑戰。從現有文獻看,針對優化學習模型參數的可見報道稀缺,基本集中在非線性激活函數的改進[154]和參數初始化[155]等方面,這無疑是制約深度學習技術發展的一大阻礙。今后的研究應該花更大的力氣多角度、多方法的實現模型參數優化,從而從根本上提高深度學習網路性能。
4.1.3 從方法角度
(1)發展混合算法
根據前述,深度學習模型因理論支撐不足而被人們稱為“黑匣子”,其在故障診斷領域的應用也給人“因人而異”的印象,這些問題的存在,使得其泛化能力備受質疑。由此,很多研究者進行了混合算法的初探,比如文獻[156-158]將深度學習和頻譜、小波、PCA等進行了混合,他們試圖通過加入人工提取特征環節來減少訓練時間。然而這種做法可能會在算法的早期訓練中就產生偏差從而導致結果不可靠,同時也違背了深度學習端到端學習的重要思想。近年來又涌現出了一些新的方法[104,159]試圖解決上述問題,這是一種好的現象,但目前還遠沒有達到各種方法“有機結合”的程度。因此,在今后的研究中還應繼續探索新的可能性,比如,將深層、淺層網絡進行組合構建新的具有優異性能的混合深度學習模型;將監測數據組合成為二維圖譜,以充分展示深度學習模型的圖形處理優勢等,最終通過各種方法取長補短、優勢互補的有機結合實現高效、高準確率的復雜工業系統的故障診斷與預測。
(2)缺乏對結果評價的基準
從前述文獻可以看出,很多研究者已成功應用各種深度學習方法實現了故障診斷和預測,并就診斷精度與SVM、單隱層神經網絡等方法進行比較,效果明顯。但這可能會產生誤導,因為使用多層信息處理模塊能夠得到更好的診斷結果這幾乎是可以預見的。然而,在實際應用中,得到一個好的診斷結果絕不是衡量一個故障診斷與預測方法好壞的唯一標準,可靠性、靈敏性、穩定性、效率、成本、泛化能力等都是不可忽視的問題。比如,實現架構是否為受控系統、實現方法是否很好地解決了故障診斷的可靠性問題、是否存在信息的丟失而影響了系統的穩定性、方法的靈敏性如何、時間是否有延遲等問題都有可能導致診斷失去意義。因此,制定結果評價基準是實現方法性能準確鑒定的必要前提條件。如何建立合理、全面、可操作的結果評價基準是今后研究中需要思考的問題。
4.1.4 從應用角度
故障診斷與預測技術絕不能僅僅停留在實驗研究層面,它一定是能夠進行實際應用的技術手段。因此,研究者應該從工業實際和學術雙角度出發,全面考慮環境、成本、可靠性、靈敏性、實用性、效率等眾多因素,且不能將工作集中在提高低設計級別的故障診斷上,故障的預測、停機時間的控制、故障的隔離、故障決策效率、微小故障的跟蹤、設備老化進程跟蹤、跨領域策略等等問題都應是今后的研究方向。
4.2 展望
對于工程界而言,深度學習已經為未來的研究開辟了一片廣闊的天地。正如本文所看到的,深度學習展示了很多的優點并取得了一定的成績,這使得它更具吸引力。然而,如上所述,其在故障診斷與預測領域中仍然存在很多的挑戰和難點,這也為今后發展的方向提供了指導。對應用深度學習進行故障診斷和預測的發展趨勢作如下展望:
(1)研究進程從故障診斷到退化狀態識別再到故障預測已成為必然趨勢。
(2)研究數據的來源、構建大數據庫、進行復雜數據的處理已成為基于深度學習的故障診斷與預測技術發展瓶頸的重要突破口。
(3)突破深度學習理論研究瓶頸,探索其內部算法打開“黑匣子”是其技術發展不可回避的問題。
(4)將深度學習與傳統淺層模型相結合,構建具有優異性能的混合深度學習模型勢在必行。
(5)從應用視角出發,嘗試用人工故障訓練的算法對自然故障進行預測,這實際上是對基于深度學習的故障診斷與預測算法在現實中應用的合理期望。
5 結束語
故障診斷與預測的最終目的是準確判斷部件的狀態從而預防事故的發生。與傳統淺層機器學習方法相比,深度學習在故障診斷和預測中能夠提供更好的表示和分類,因此利用深度學習方法進行故障診斷與預測是必要、可行的。本文首先對近年來深度學習及其在各領域發展的優秀綜述文獻以及主流的開源仿真工具平臺進行了整理,同時介紹了目前典型的五種深度學習模型,包括AE及其變體、DBN、CNN、RNN和GAN;其次就深度學習在故障診斷與預測中的應用研究進行了歸納總結,從研究背景、實現流程及研究動態等三個方面進行了闡述,并在研究動態中就發展趨勢、數據來源進行了介紹,系統梳理了近年來這一領域發表的相關論文;最后從研究實際出發就深度學習在故障診斷與預測領域應用中存在的問題、挑戰及解決方法進行了探討,并對未來的發展進行了展望。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
汽車維修與保養(2019年7期)2020-01-06 03:30:42
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
