維吾爾語復雜形態對漢維機器翻譯的影響研究
2020-02-19 11:27:16穆妮熱穆合塔爾楊雅婷
計算機工程 2020年2期
穆妮熱·穆合塔爾,李 曉,楊雅婷
(1.中國科學院新疆理化技術研究所,烏魯木齊 830011; 2.中國科學院大學,北京 100049;3.新疆民族語音語言信息處理實驗室,烏魯木齊 830011)
0 概述
維吾爾語是典型的黏著語,其詞匯是通過詞干(詞根)和詞綴連接而衍生的,該屬性使其生成大量的語素組合,呈現出豐富且復雜的形態變化,大幅增加了詞匯量的規模,從而在漢語與維吾爾語之間的機器翻譯中造成了未登錄詞的增多和統計模型的數據稀疏性問題,為降低數據稀疏度,詞干、詞尾分解后只保留詞干而無條件地丟棄詞尾會失去很多有用的信息,相反若保留所有的詞尾則導致句子過長,會被詞語對齊工具過濾掉[1]。對維吾爾語詞尾粒度的切分采取選擇性的保留方法,可以降低因不同形態帶來的數據稀疏性問題,盡可能地增加漢語到維吾爾語的詞對齊的數量來提高詞對齊的正確率,從而可以達到提高漢維機器翻譯的質量的目的[2]。
本文搭建基于統計的漢維統計機器翻譯系統,通過詞語對齊質量和語言模型困惑度等對不同粒度的維吾爾語與漢維機器翻譯質量進行對比,最終根據實驗來選擇最佳粒度的維吾爾語語料。
1 維吾爾語形態特點

2 維吾爾語的復雜形態
維吾爾語詞類大致分為實詞、虛詞、感嘆詞等,而實詞分為動詞和靜詞,虛詞可分為后置詞、連詞、語氣詞等[5]。實詞包含具有表達意義和形態變化的詞類,虛詞包含沒有形態變化的詞類。維吾爾語中的名詞、形容詞、數詞等屬于靜詞范圍,在形態變化上具有一定的相似性。因為靜詞與動詞是并列關系,靜詞與動詞形態系統的差異較大[6]。維吾爾語靜詞構形詞綴有 65 個不同的詞綴,名詞有49 個詞綴,數詞有 57個詞綴,形容詞有55個詞綴,動詞有150個多詞綴。當一個詞干綴接不同的詞尾時會表現出不同的語法功能,在漢語跟維吾爾之間互相翻譯時會出現一個維吾爾詞語對應到漢語中一個短語的情況[7]。圖1是維吾爾語在沒有進行形態分析前的漢維對齊的情況。
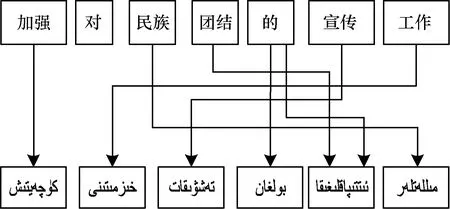
圖1 未進行形態分析前漢維詞語對齊的情況
如果對維吾爾語詞本身進行詞干與詞綴之間的切分,并且去除所有詞綴只保留詞干形式進行漢維詞語對齊時,其結果如圖2和圖3所示。
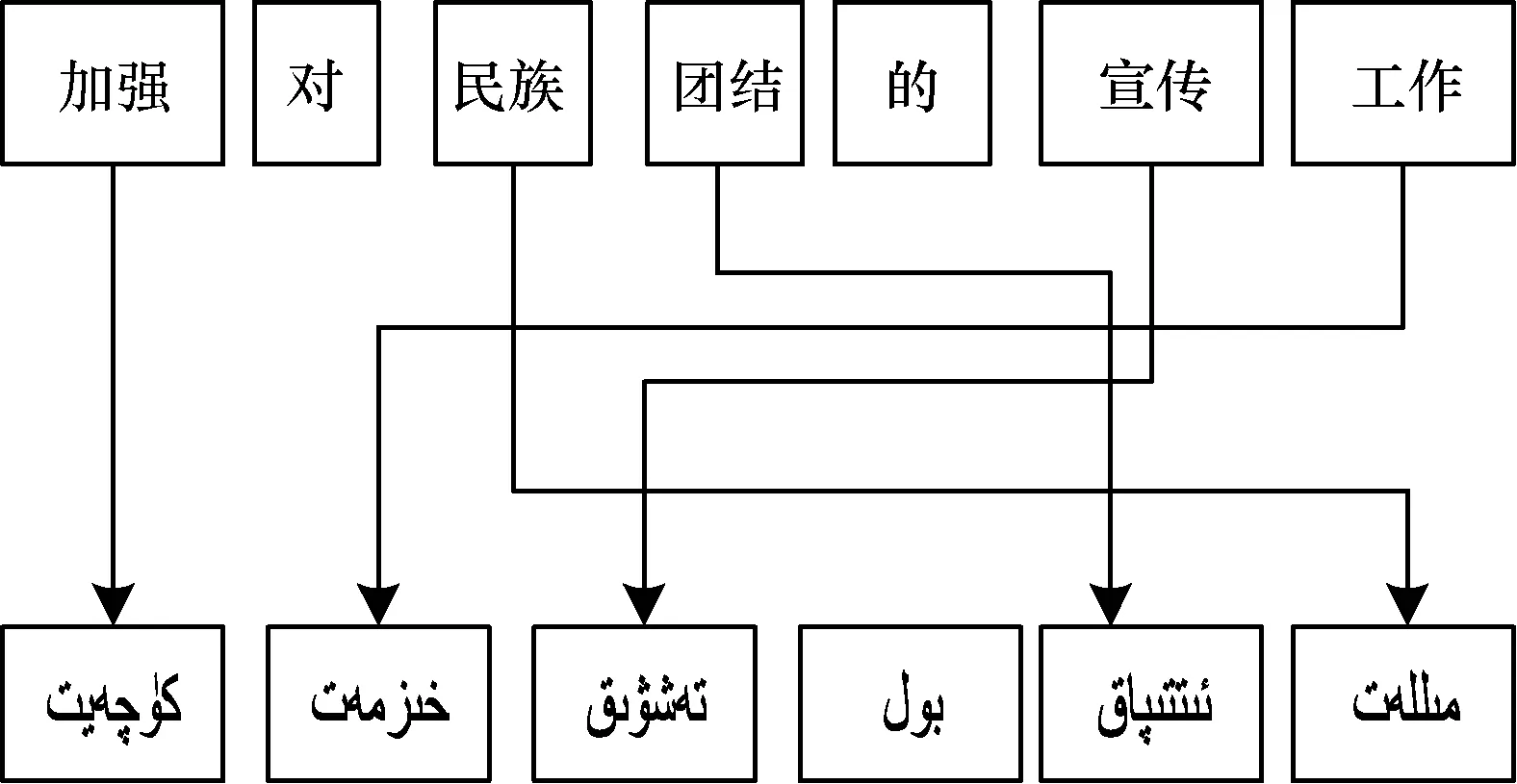
圖2 基于詞干的漢維詞語對齊情況

圖3 去掉詞尾后的詞干漢維詞語對齊情況
圖2和圖3顯示不同粒度的詞干詞語對齊結果,不同粒度的詞干指的是維吾爾語最小詞干(圖2)和去掉最后一個詞尾以后剩下的詞干部分(圖3),本文中均成最大詞干[9]。顯然基于不同粒度的詞干詞語對齊時沒有多對多的情況,能明顯降低數據稀疏性問題。當然,去掉詞綴后的詞干對齊雖然沒有多對多的情況,但是會導致詞綴自帶的部分重要語法信息的丟失[10]。因此,下一步對不同粒度的詞干-詞綴進行詞語對齊,如圖4(詞干+詞綴)和圖5(詞干+詞尾)所示。
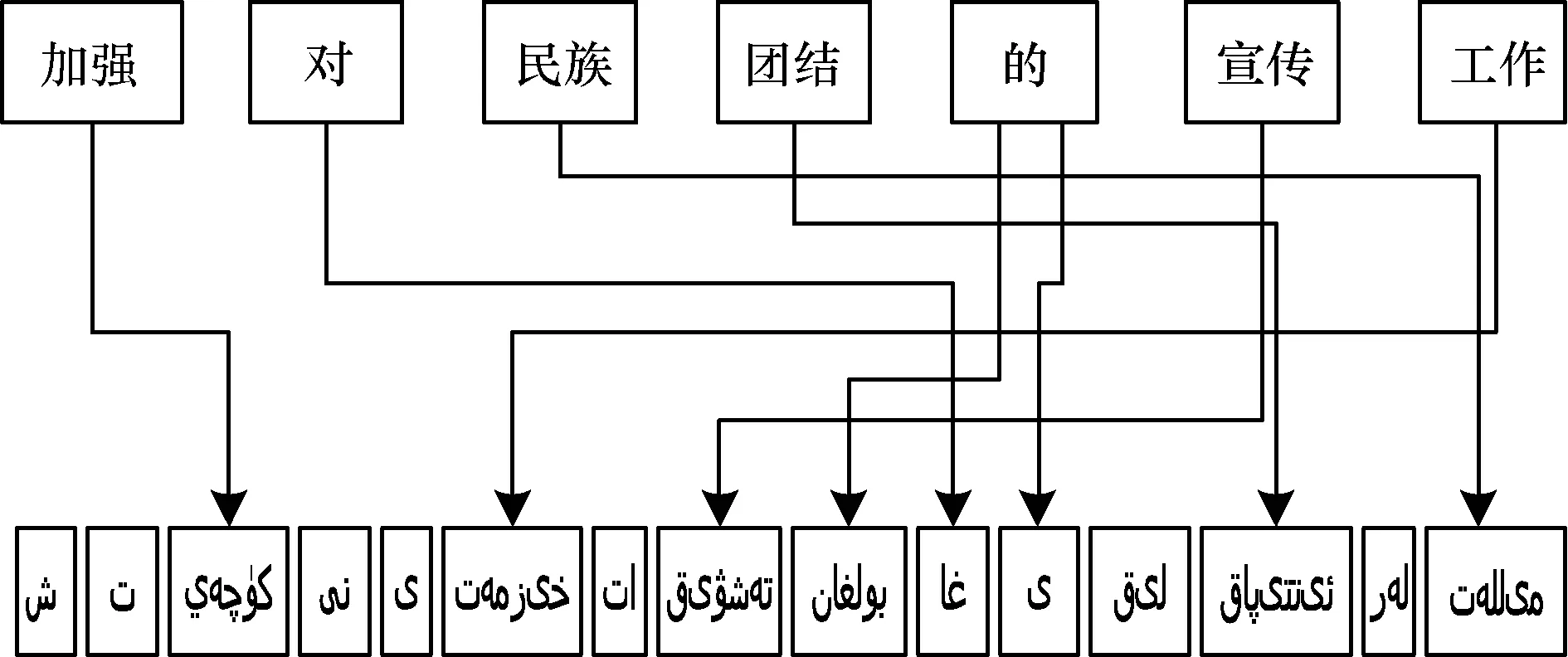
圖4 基于詞干-詞綴的漢維詞語對齊情況
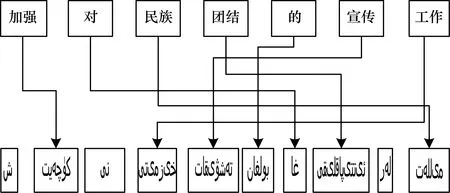
圖5 基于詞干-詞尾的漢維詞語對齊
3 實驗系統搭建
本文使用開源的Moses翻譯解碼器中基于短語的加碼器分別以不同粒度的維吾爾語語料為目標語言,并以漢語語料為源語言進行基于雙語平行語料的漢維翻譯。圖6所示為翻譯系統基本框架[14]。

圖6 漢維翻譯訓練及解碼流程
Fig.6Flowchart of Chinese-Uygher translation training and decoding
該系統由語料預處理、語言模型訓練、翻譯模型訓練和解碼等4個模塊組成。其中翻譯模型可以被Moses識別,一組特殊格式的文件集,其結構復雜,但是整體描述的是從漢語的“某個短語”翻譯成維吾爾語的“某個詞或者短語”。語料的預處理和語言模型訓練的過程將在3.1節介紹[15]。
3.1 語料預處理
在基于語料庫的漢維統計機器翻譯中進行翻譯時,由于語料的來源和獲取方式的不同,可以在訓練和翻譯過程中使用的語料需得進行預處理,除了用中科院計算技術研究所開發的分詞工具對漢語語料進行分詞外,還可用其他的工具對維吾爾語語料進行詞例化,本文用艾則孜等人開發出來的維吾爾語詞法分析工具,將維吾爾語語料進行預處理并準備了不同粒度的語料,如詞、詞干、詞干+詞綴、詞干+詞尾、最大詞干等5種不同粒度的維吾爾語語料以及已分詞好的漢語語料,2種語言語料是平行語料[16]。
3.2 詞語對齊
對現有的語料進行處理以后,訓練雙語語料時利用GIZA++進行無監督的漢語維吾爾語對齊訓練,在讀取要翻譯的輸入文件時GIZA++構造IBM模型的各個模型,然后通過期望最大化算法(EM)進行反復迭代訓練,生成最有可能性的對齊信息結果供下一步規則抽出使用。EM算法是一種從不太完整的或者有數據丟失的數據集中求解概率模型參數的最大擬然估計方法,EM算法中循環E步驟是求在當前參數值和樣本下的期望函數Q(隨機變量z的概率密度函數),M步驟是利用期望函數重新計算模型中新的估計值[17]。E步驟對于每一個i的計算公式如式(1)所示。
Qi(zi):=p(z(i)|x(i);θ)
(1)
M步驟是利用期望函數重新計算模型中新的估計值。M步驟計算公式如式(2)所示。
(2)
3.3 語言模型訓練
在統計機器翻譯中,語言模型對于整個翻譯系統而言是不可缺少的-部分,語言模型不僅能提高輸出句子的流利度,而且對詞匯順序和詞匯翻譯的決策過程也起著重要的作用。簡單來說,對本文語言模型函數的輸入是維吾爾語,而輸出是概率,最常用的語言模型建模方法是N-gram建模法,該模型是一個假設,即第N個詞的出現只與前面N-1個詞相關,整句的概率就是各個詞出現的乘積,例如,對一個由m個詞構成的句子t=w1,w2,…,wm,它的概率計算公式如式(3)所示[18]。本文中使用語言模型工具SRILM對漢維平行語料庫的維吾爾語語料進行訓練。
p(w1,w2,…,wn)=
p(w1)p(w2|pw1)…p(wn|w1,w2,…,wn-1)
(3)
本文分別對不同粒度的維吾爾語在不同單位的語料建立語言模型。在建立語言模型時,需要一個評價語言模型質量的測度,即困惑度,困惑度在交叉熵上的基礎上進行簡單變換。其基本思想是給測試集的句子賦予較高概率值,語言模型較好,當語言模型訓練完之后,測試集中的句子都是正常的句子,那么訓練好的模型在測試集上的概率越高越好[19],計算公式如式(4)所示。
PPP=2H(PLM)
(4)
由式(4)可知,困惑度越小,句子概率越大,語言模型也越好。表1是不同粒度語料在不同單位的N-gram語言模型的困惑度[20]。
表1 不同級別語言模型N-gram的困惑度
Table 1N-gram perplexity degree of different levels of language model
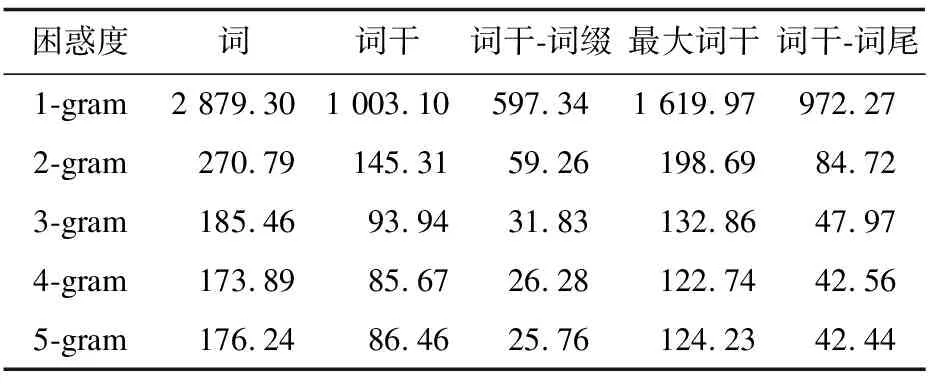
困惑度詞詞干詞干-詞綴最大詞干詞干-詞尾1-gram2879.301003.10597.341619.97972.272-gram270.79145.3159.26198.6984.723-gram185.4693.9431.83132.8647.974-gram173.8985.6726.28122.7442.565-gram176.2486.4625.76124.2342.44
由表1數據可知,在不同粒度的語言模型中,基于詞干-詞綴粒度的4-gram 語言模型的困惑度最低,僅次于詞干-詞尾粒度的5-gram語言模型。其他粒度的語言模型性能隨著N-gram單位的增加而增高。圖7所示是不同語言模型的困惑度。
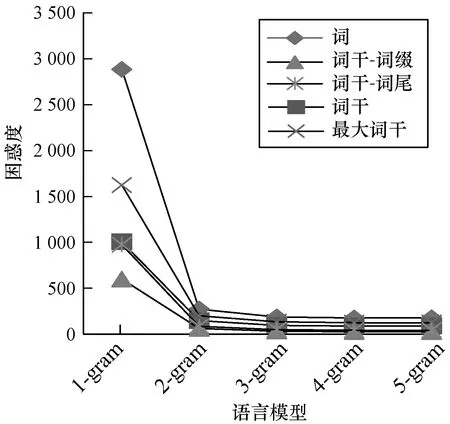
圖7 不同N-gram語言模型的困惑度
4 實驗結果與分析
本文在Linux工作環境下搭建了基于短語的漢維機器翻譯系統,分別在同樣規模和內容但級別不同的漢語-維吾爾語平行語料庫上進行實驗。上述級別分別是基于詞的、基于詞干的、基于詞干-詞綴的、基于詞干詞尾的和基于最大詞干的語料,3種語料的漢語端完全相同,維語端是根據需要分成上述的3種級別供實驗所用。實驗數據規模如表2和表3所示。
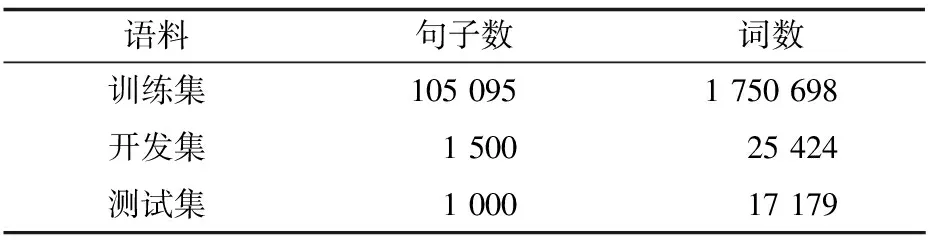
表2 漢語端語料信息統計
表3 基于不同粒度的維吾爾語語料端信息統計
Table 3 Information statistics Uyghur corpus based on different granularities
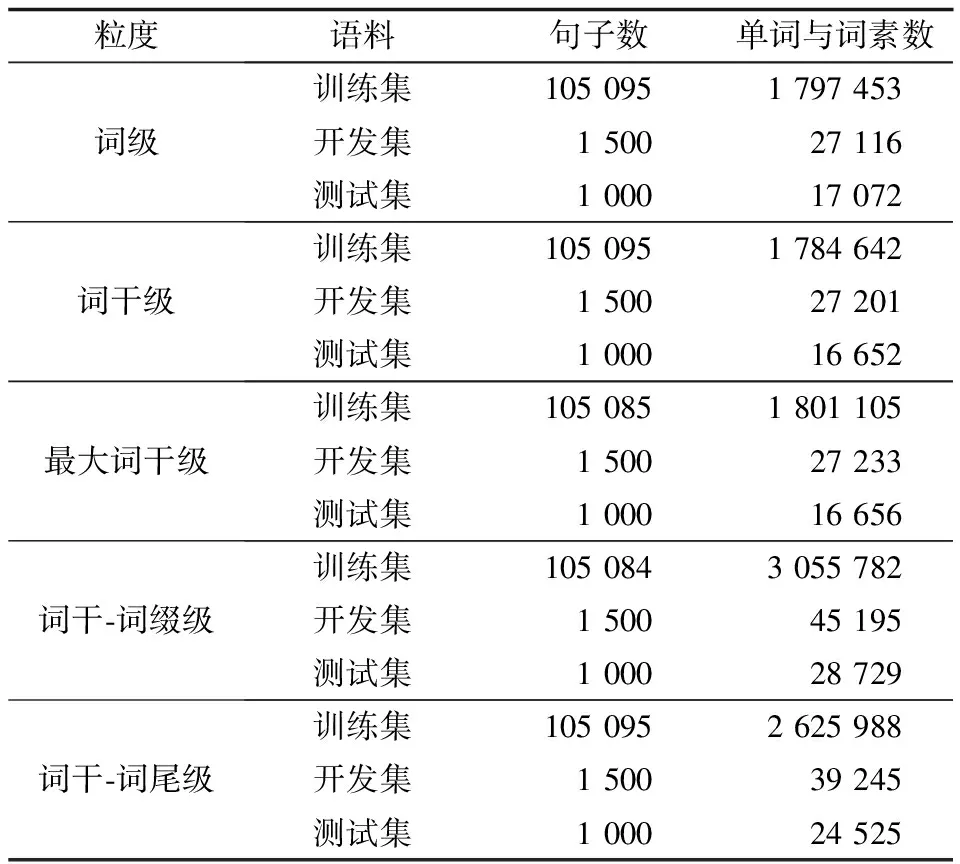
粒度語料句子數單詞與詞素數詞級訓練集1050951797453開發集150027116測試集100017072詞干級訓練集1050951784642開發集150027201測試集100016652最大詞干級訓練集1050851801105開發集150027233測試集100016656詞干-詞綴級訓練集1050843055782開發集150045195測試集100028729詞干-詞尾級訓練集1050952625988開發集150039245測試集100024525

表4 不同粒度漢維機器翻譯實驗結果
Table 4 Experimental results of Chinese-Uyghur machine translation with different granularities
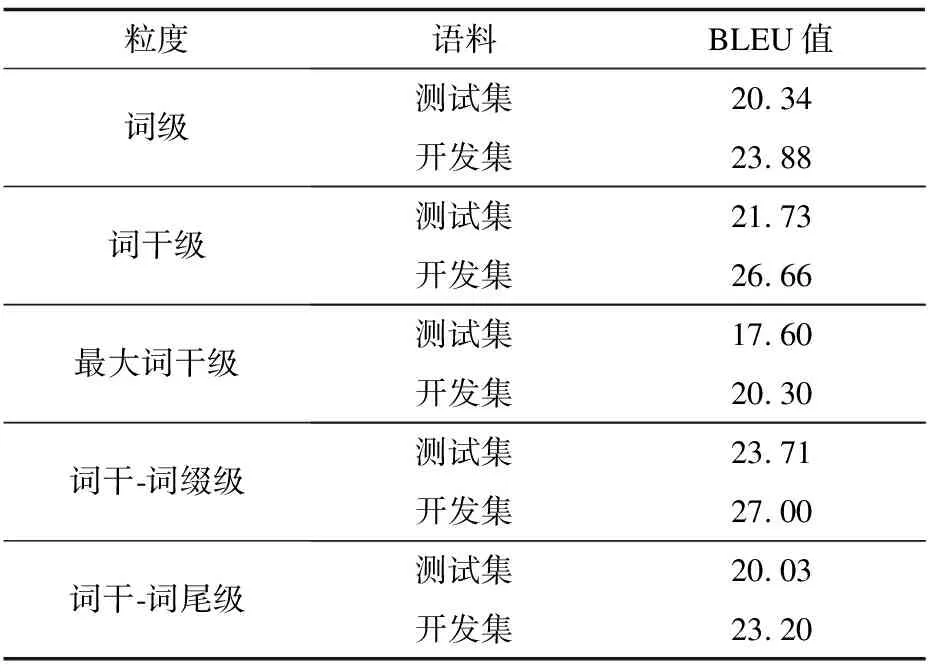
粒度語料BLEU值詞級測試集20.34開發集23.88詞干級測試集21.73開發集26.66最大詞干級測試集17.60開發集20.30詞干-詞綴級測試集23.71開發集27.00詞干-詞尾級測試集20.03開發集23.20
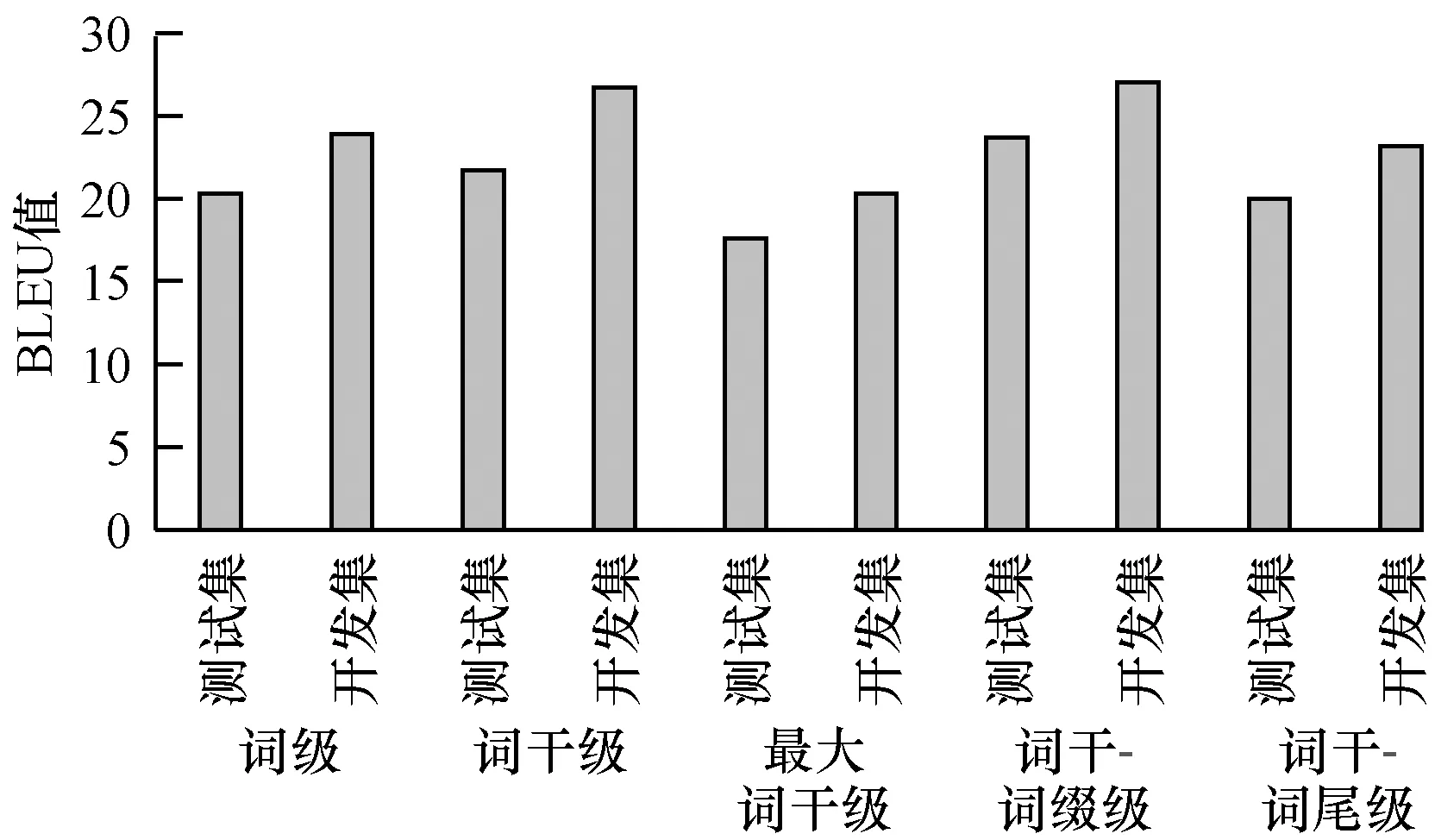
圖8 不同粒度漢維機器翻譯BLEU值對比結果
Fig.8 Comparison results of BLEU values of Chinese-uyghur machine translation with different granularities
從表4和圖8可以看出,基于詞干的翻譯結果的BLUE值明顯高于基于詞級的翻譯結果,但是因為基于詞干的維吾爾語中所有構形詞尾都被去除,所以詞語對齊時訓練不充分,導致一些重要的語法信息丟失,而基于詞干-詞綴級別的和基于詞干-詞尾級別粒度實驗中漢語與維吾爾語詞語對齊效果較好,其翻譯質量也明顯提升。
5 結束語
維吾爾語的復雜形態對基于統計的漢語與維吾爾語的詞語對齊及語言模型的質量有較大影響,直接關系到兩種語言之間的翻譯結果。本文對比了不同粒度的5種維吾爾語漢語平行語料,維吾爾語詞綴切分粒度的不同,基于不同粒度的N-Gram語言模型對BLEU值的提高幅度也不同。實驗結果表明,基于詞干的維吾爾語和基于詞干-詞尾的維吾爾語目標端語料的翻譯質量明顯高于其他3種語料。由于維吾爾語詞干詞綴自動切分工具功能的差異性影響最佳詞干-詞綴正確粒度的切分,導致部分的詞綴形態信息缺乏,下一步將采用相關維吾爾語形態還原方法得到帶有所需形態信息的完整句子,以保證翻譯結果的流利度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
紅河學院學報(2021年4期)2021-11-19 08:59:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
西夏研究(2017年1期)2017-07-10 08:16:55
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
