基于用戶-標(biāo)簽異構(gòu)網(wǎng)絡(luò)的社區(qū)問(wèn)答專家發(fā)現(xiàn)方法
2020-02-19 11:26:28劉永堅(jiān)
計(jì)算機(jī)工程 2020年2期
黃 輝,劉永堅(jiān),解 慶
(武漢理工大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,武漢 430070)
0 概述
在Stack Overflow、Quora等社區(qū)問(wèn)答(Community Question Answering,CQA)網(wǎng)站中,用戶提出新問(wèn)題等待其他用戶來(lái)回答,其他用戶能對(duì)該問(wèn)題下的回答表示贊同或者反對(duì),提問(wèn)者也可以采納其中一個(gè)答案,將其設(shè)置為“最佳回答”。這種互動(dòng)方式使得提問(wèn)者可以獲得具有針對(duì)性的答案,能減少用戶在互聯(lián)網(wǎng)中獲得知識(shí)的成本。CQA通過(guò)提供一個(gè)知識(shí)共享平臺(tái)來(lái)滿足用戶獲取和發(fā)布知識(shí)的需求,由于其具有開放性、交互性等特點(diǎn),因此受到廣大用戶的喜愛(ài)。
隨著用戶量的增多以及新問(wèn)題的不斷提出,問(wèn)答社區(qū)面臨一些新的挑戰(zhàn)。Stack Overflow是一個(gè)全球熱門的與計(jì)算機(jī)編程相關(guān)的問(wèn)答網(wǎng)站,本文以其為例分析2009年至2015年之間的問(wèn)答數(shù)據(jù):問(wèn)題數(shù)量不斷快速增長(zhǎng),到2013年,累積的問(wèn)題數(shù)量已經(jīng)超過(guò)200萬(wàn),但新問(wèn)題的增長(zhǎng)速度明顯減慢,同時(shí)未被解答的問(wèn)題比例由2009年的99.5%下降至2013年的90.9%,到2015年進(jìn)一步下降至79.5%。該網(wǎng)站中大量新問(wèn)題被提出,但是在一定時(shí)間內(nèi)都得不到任何人解答,由此可以認(rèn)為,未被解答的問(wèn)題增多會(huì)導(dǎo)致社區(qū)的用戶活躍度下降。
問(wèn)答社區(qū)需要合適的專家發(fā)現(xiàn)方法以尋找能夠提供正確答案的專家,這有利于提高用戶的活躍度并促進(jìn)用戶主動(dòng)分享知識(shí)。本文圍繞開放的問(wèn)答模式,針對(duì)問(wèn)答社區(qū)的特點(diǎn)提出一種基于用戶-標(biāo)簽網(wǎng)絡(luò)的專家發(fā)現(xiàn)方法。根據(jù)用戶的歷史回答記錄,以用戶和標(biāo)簽為節(jié)點(diǎn)構(gòu)建異構(gòu)網(wǎng)絡(luò),使用網(wǎng)絡(luò)嵌入方法得到用戶的向量表示,并為每個(gè)問(wèn)題組合標(biāo)題、標(biāo)簽、正文以生成問(wèn)題文本,對(duì)問(wèn)題進(jìn)行數(shù)據(jù)清洗以獲得適合訓(xùn)練的數(shù)據(jù)。在此基礎(chǔ)上,應(yīng)用深度語(yǔ)義匹配模型DSSM提取用戶特征和問(wèn)題文本特征,根據(jù)兩者的余弦相似度排序得到候選專家列表。
1 相關(guān)工作
社區(qū)問(wèn)答中的專家發(fā)現(xiàn)方法主要分為3種,即基于主題生成模型的方法、基于深度學(xué)習(xí)的方法和基于網(wǎng)絡(luò)的方法。
目前有一部分工作從挖掘文本主題信息的角度出發(fā),尋找問(wèn)題和用戶之間潛在主題信息的關(guān)聯(lián),而多數(shù)工作則使用LDA主題模型尋找用戶的領(lǐng)域,計(jì)算用戶在各個(gè)類別內(nèi)的專業(yè)程度從而進(jìn)行專家排序[1]。文獻(xiàn)[2]根據(jù)在線問(wèn)答社區(qū)中答案的產(chǎn)生過(guò)程,提出一種問(wèn)題-回答者-話題模型。文獻(xiàn)[3]應(yīng)用分段主題模型(Segmented Topic Model,STM)解決專家發(fā)現(xiàn)問(wèn)題,并且對(duì)比了TF-IDF模型、語(yǔ)言模型以及LDA模型,實(shí)驗(yàn)結(jié)果顯示STM表現(xiàn)更好。文獻(xiàn)[4]提出作者-主題模型(Author-Topic Model,ATM)以尋找作者、文檔、主題和詞之間的關(guān)系。文獻(xiàn)[5-6]提出標(biāo)簽詞主題模型(Tag Topic Model,TTM),利用問(wèn)題文本和問(wèn)題附帶的標(biāo)簽,使得每一個(gè)文本中的單詞都能和每一個(gè)標(biāo)簽組成“標(biāo)簽-詞”對(duì),從而解決因問(wèn)題文本較短導(dǎo)致傳統(tǒng)主題模型難以提取潛在主題的問(wèn)題。
深度學(xué)習(xí)被廣泛應(yīng)用于多個(gè)領(lǐng)域[7-9],一些工作將深度學(xué)習(xí)應(yīng)用于專家發(fā)現(xiàn)。這些方法根據(jù)用戶的歷史回答記錄建立用戶文檔,然后從中提取用戶特征。文獻(xiàn)[10]使用DSSM模型[11]提取文本特征和用戶特征,然后根據(jù)用戶文本特征和問(wèn)題文本特征的余弦相似度從大到小排序獲得專家列表。文獻(xiàn)[12]使用卷積神經(jīng)網(wǎng)絡(luò)提取文本特征,也取得了較好的效果。此外,傳統(tǒng)的支持向量機(jī)方法也被用于專家發(fā)現(xiàn)任務(wù)。文獻(xiàn)[13]提出RankingSVM模型,通過(guò)訓(xùn)練一個(gè)二分類器對(duì)樣本進(jìn)行分類,從而將排序轉(zhuǎn)化為一個(gè)分類問(wèn)題,利用機(jī)器學(xué)習(xí)的方法進(jìn)行排序。
基于網(wǎng)絡(luò)的方法根據(jù)問(wèn)答關(guān)系構(gòu)建社交網(wǎng)絡(luò),傳統(tǒng)的方法通常基于鏈接分析,如基于PageRank的方法[14]和基于HITS的方法[15]。近期的一些方法應(yīng)用了圖嵌入法生成網(wǎng)絡(luò)中節(jié)點(diǎn)的特征向量。文獻(xiàn)[16]構(gòu)建用戶與用戶、用戶與問(wèn)題之間的異構(gòu)網(wǎng)絡(luò),通過(guò)Random-Walk算法[17]得到用戶和問(wèn)題的向量表示,最后使用深度神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)提取特征并比較兩者之間的余弦相關(guān)度。文獻(xiàn)[18]設(shè)計(jì)了一種聯(lián)合網(wǎng)絡(luò)結(jié)構(gòu)信息和文本信息的動(dòng)態(tài)門裝置,然后使用神經(jīng)張量網(wǎng)絡(luò)(Neural Tensor Network,NTN)[19]得到問(wèn)題特征和用戶特征的匹配分?jǐn)?shù)。
以上方法均圍繞問(wèn)答關(guān)系抽象出用戶和問(wèn)題作為節(jié)點(diǎn)構(gòu)建網(wǎng)絡(luò),忽略了問(wèn)題附帶的標(biāo)簽。稀疏的標(biāo)簽難以利用,但卻能反映出問(wèn)題的領(lǐng)域性。因此,本文通過(guò)尋找用戶與標(biāo)簽的聯(lián)系,構(gòu)建用戶-標(biāo)簽異構(gòu)網(wǎng)絡(luò),以此減少節(jié)點(diǎn)數(shù),加快模型訓(xùn)練的速度,同時(shí)提高準(zhǔn)確性。
2 基于用戶-標(biāo)簽網(wǎng)絡(luò)的專家發(fā)現(xiàn)方法
本文基于用戶-標(biāo)簽網(wǎng)絡(luò)的專家發(fā)現(xiàn)方法框架如圖1所示。以用戶和標(biāo)簽為節(jié)點(diǎn),根據(jù)標(biāo)簽與標(biāo)簽之間的關(guān)系以及用戶與標(biāo)簽的關(guān)系構(gòu)建用戶-標(biāo)簽異構(gòu)網(wǎng)絡(luò),然后應(yīng)用DSSM模型[11]獲取用戶向量和問(wèn)題向量的相似度,最后得到候選專家列表。
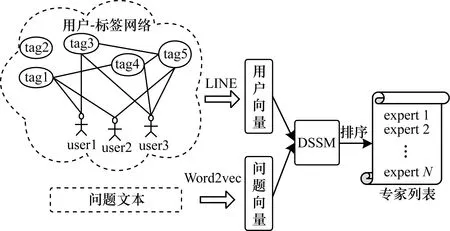
圖1 本文方法框架
2.1 用戶-標(biāo)簽異構(gòu)網(wǎng)絡(luò)
問(wèn)答社區(qū)中的問(wèn)題通常都附有若干個(gè)標(biāo)簽,這些標(biāo)簽大多能正確反映出問(wèn)題的主題,但是它們非常稀疏,難以直接利用。如圖2所示,用戶回答了某個(gè)問(wèn)題,該問(wèn)題附有3個(gè)標(biāo)簽,筆者認(rèn)為其與該用戶有關(guān)聯(lián),因此,通過(guò)構(gòu)建用戶-標(biāo)簽異構(gòu)網(wǎng)絡(luò)對(duì)這些稀疏標(biāo)簽加以利用。
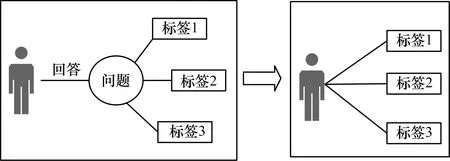
圖2 用戶與標(biāo)簽之間的聯(lián)系
設(shè)問(wèn)題集為Q={q1,q2,…,ql},用戶集為U={u1,u2,…,um},標(biāo)簽集為T={t1,t2,…,tn}。基于用戶集U和標(biāo)簽集T,本文構(gòu)建一個(gè)用戶-標(biāo)簽異構(gòu)網(wǎng)絡(luò),該網(wǎng)絡(luò)是一個(gè)無(wú)向圖,能反映出用戶與標(biāo)簽在網(wǎng)絡(luò)層面中的關(guān)系。設(shè)該異構(gòu)CQA網(wǎng)絡(luò)為G=(V,E),其中節(jié)點(diǎn)集V包含用戶集U和標(biāo)簽集T這兩種類型的節(jié)點(diǎn),邊集合E由用戶-標(biāo)簽關(guān)系和標(biāo)簽-標(biāo)簽關(guān)系組成,詳細(xì)描述如下:

圖3展示了用戶-標(biāo)簽異構(gòu)網(wǎng)絡(luò)結(jié)構(gòu),其中包含2種節(jié)點(diǎn),即用戶節(jié)點(diǎn)和標(biāo)簽節(jié)點(diǎn)。本文通過(guò)LINE方法[20]學(xué)習(xí)用戶在網(wǎng)絡(luò)中的向量表示U。
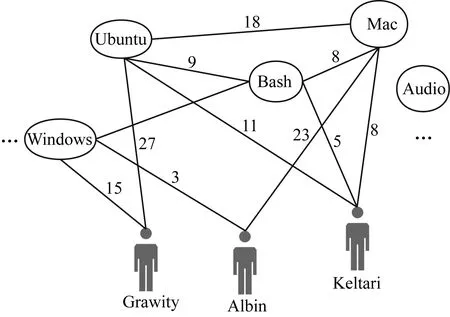
圖3 用戶-標(biāo)簽異構(gòu)網(wǎng)絡(luò)結(jié)構(gòu)
2.2 全連接神經(jīng)網(wǎng)絡(luò)
本文應(yīng)用DSSM模型來(lái)預(yù)測(cè)結(jié)果,如圖4所示,該模型包含2個(gè)共享結(jié)構(gòu)但參數(shù)不同的全連接深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN)。該神經(jīng)網(wǎng)絡(luò)的隱藏層有2層,每層含有300個(gè)神經(jīng)元,輸出層含有128個(gè)神經(jīng)元。第1個(gè)DNN輸入為用戶向量U,第2個(gè)DNN輸入為問(wèn)題文本向量Q。
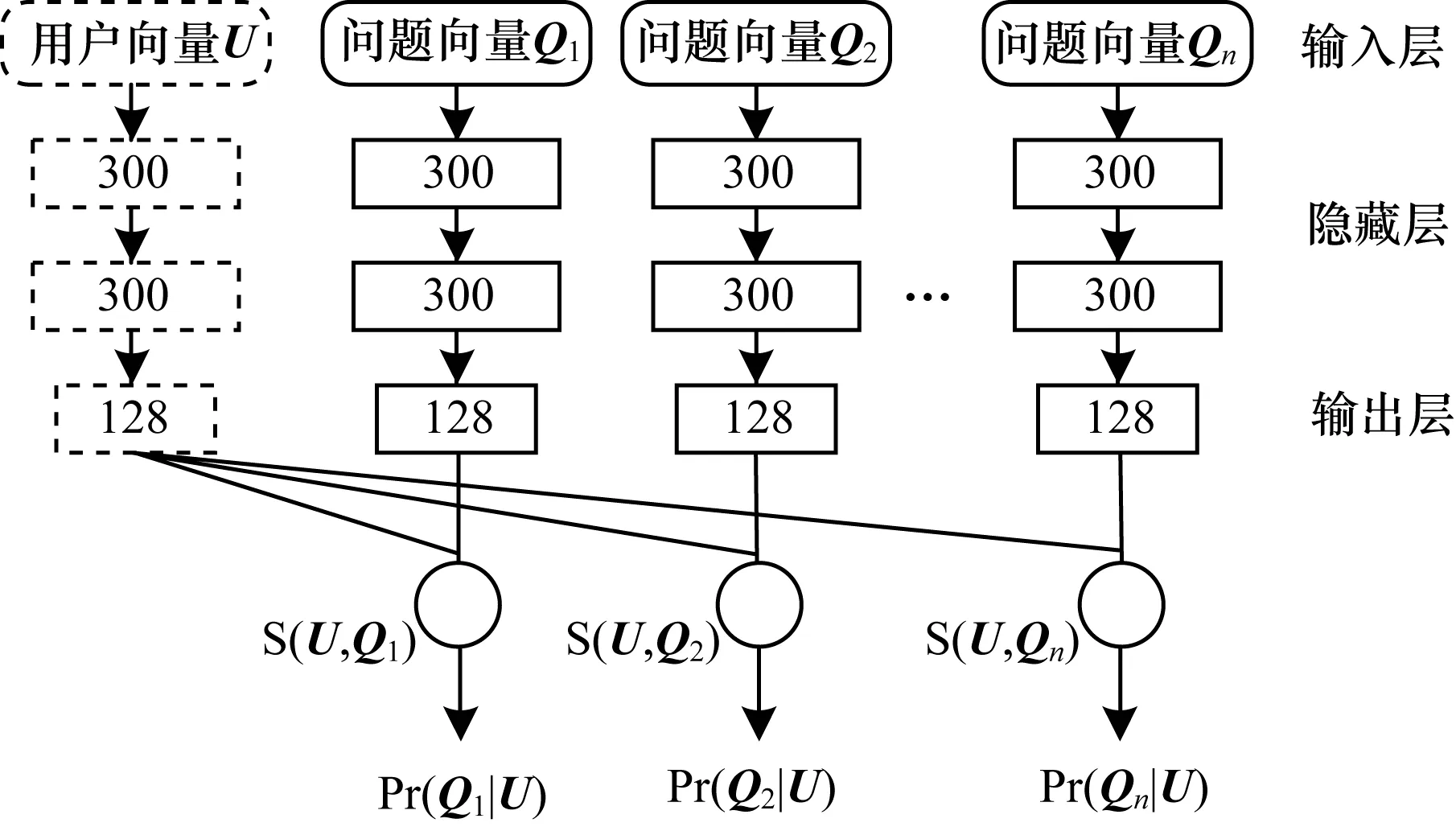
圖4 DSSM模型結(jié)構(gòu)
輸入用戶向量U和問(wèn)題向量Q后,經(jīng)過(guò)2個(gè)共享網(wǎng)絡(luò)結(jié)構(gòu)的DNN,但是這兩個(gè)DNN參數(shù)不共享,包括權(quán)值矩陣W和偏置向量b。隱藏層的定義如下:
h1(k)=W1(k)·x
(1)
hi(k)=F(Wi(k)·hi-1(k)+bi)
(2)
F(x)=ReLU(x)=max(0,x)
(3)
如式(1)和式(2)所示,首先使用W1乘以輸入向量x得到能被后續(xù)隱藏層接受的值h1,然后下一層接受上一層的輸出,Wi(k)為第i層的權(quán)值,bi是第i層的偏置向量,k為離散時(shí)間,i的取值范圍為2~m,式(3)定義了激活函數(shù)F。
輸出層含有128個(gè)神經(jīng)元,則輸出的特征維度為128。本文使用余弦函數(shù)來(lái)計(jì)算2個(gè)DNN分別輸出的用戶特征和問(wèn)題特征的相似度,計(jì)算公式如下:
(4)
一個(gè)用戶能在多個(gè)問(wèn)題下取得最佳回答,設(shè)K為用戶取得最佳回答的問(wèn)題總數(shù),r為從問(wèn)題集中隨機(jī)抽取的非該用戶回答的問(wèn)題數(shù)量。因此,每一組數(shù)據(jù)包含一個(gè)用戶、該用戶取得最佳回答的問(wèn)題集以及r個(gè)非該用戶回答的問(wèn)題。如式(5)所示,基于隨機(jī)抽取方法從問(wèn)題集中得到r個(gè)非該用戶回答的問(wèn)題,本文中r設(shè)為3。然后應(yīng)用Softmax函數(shù)處理問(wèn)題特征和每一個(gè)該用戶回答過(guò)的問(wèn)題特征的余弦相似度,確保總概率和為1。
(5)
本文定義損失函數(shù)fLoss來(lái)提高準(zhǔn)確率,K為用戶U取得最佳回答的問(wèn)題數(shù)量,在訓(xùn)練過(guò)程中使fLoss最小化。如式(6)所示,當(dāng)用戶取得最佳回答的問(wèn)題特征和用戶特征余弦相似度最大且非最佳回答問(wèn)題特征與用戶特征余弦相似度最小時(shí),fLoss為最小值。如果一個(gè)用戶回答了許多的問(wèn)題,可以令K=10,將一組數(shù)據(jù)拆分為多組數(shù)據(jù)以便于神經(jīng)網(wǎng)絡(luò)的訓(xùn)練。
(6)
3 實(shí)驗(yàn)與結(jié)果分析
3.1 數(shù)據(jù)集與數(shù)據(jù)預(yù)處理
StackExchange是一系列具有相同問(wèn)答模式的問(wèn)答網(wǎng)站集合,其中包含133個(gè)網(wǎng)站,每一個(gè)網(wǎng)站覆蓋不同領(lǐng)域,包括數(shù)學(xué)、園藝、物理、密碼學(xué)、天文學(xué)、數(shù)據(jù)科學(xué)、攝影、經(jīng)濟(jì)學(xué)等。經(jīng)過(guò)多年發(fā)展,StackExchange已經(jīng)成為一個(gè)巨大的知識(shí)圖書館,Stack Overflow是其中的第一個(gè)成員,其他的網(wǎng)站都根據(jù)Stack Overflow的模式而建立。在這種問(wèn)答模式下,用戶可以提出新問(wèn)題并將回答設(shè)置成“最佳回答”,可以瀏覽并回答其他人提出的問(wèn)題,也可以對(duì)其他問(wèn)題的答案表示贊成或者反對(duì)。由于提問(wèn)者在編寫問(wèn)題時(shí)需要輸入該問(wèn)題的標(biāo)簽,因此目前網(wǎng)站中包含大量的標(biāo)簽用以反映問(wèn)題的領(lǐng)域并且對(duì)問(wèn)題分類。
本文使用的是“Super User”和“Server Fault”這兩個(gè)站點(diǎn)的數(shù)據(jù)集,取其中2010年1月至2016年12月之間的數(shù)據(jù)作為訓(xùn)練集,2017年1月至2018年7月的數(shù)據(jù)作為測(cè)試集。
首先根據(jù)時(shí)間段以及類型(在數(shù)據(jù)源文件Post.xml中,問(wèn)題和回答的類型序號(hào)分別是1和2)得到問(wèn)題集。問(wèn)題由問(wèn)題標(biāo)題、問(wèn)題標(biāo)簽和問(wèn)題正文3個(gè)元素組成,因此,設(shè)問(wèn)題文本=問(wèn)題標(biāo)題+問(wèn)題標(biāo)簽+問(wèn)題正文。然后對(duì)問(wèn)題文本進(jìn)行數(shù)據(jù)清洗,包括以下4個(gè)步驟:
1)移除HTML標(biāo)簽。去除無(wú)用的標(biāo)簽,只保留含有有用信息的問(wèn)題正文。
2)停止詞過(guò)濾。使用的是標(biāo)準(zhǔn)的418個(gè)英文停止詞。
3)去除代碼段。移除被“”包圍的代碼段。移除代碼段產(chǎn)生的噪聲,能取得更好的結(jié)果[10]。
4)詞干提取。詞干提取是去除詞綴得到詞根的過(guò)程,比詞根提取的效率更高。例如,對(duì)單詞“fished”提取詞干后得到“fish”。
因此,本文得到僅由單詞詞干組成、含有重要詞匯的詞序列。為減少詞向量的維度,使用谷歌開源的詞向量工具Word2vec。經(jīng)過(guò)訓(xùn)練,得到低維度的詞向量,由于詞向量的加法運(yùn)算特性,因此能將問(wèn)題文本詞序列表示成計(jì)算機(jī)能識(shí)別的低維度向量。
沒(méi)有設(shè)置最佳回答的問(wèn)題也會(huì)被過(guò)濾掉,最后根據(jù)時(shí)間節(jié)點(diǎn)將數(shù)據(jù)集分成訓(xùn)練集和測(cè)試集。由于問(wèn)答社區(qū)中問(wèn)題的回答質(zhì)量良莠不齊,甚至存在惡意回答問(wèn)題的情況,因此筆者認(rèn)為“最佳回答”得到了提問(wèn)者的認(rèn)可,是正確答案。表1列出了這兩個(gè)數(shù)據(jù)集中的訓(xùn)練集問(wèn)題數(shù)量和測(cè)試集問(wèn)題總數(shù)。

表1 訓(xùn)練集和測(cè)試集的問(wèn)題總數(shù)
2種數(shù)據(jù)集下的訓(xùn)練集和測(cè)試集描述如表2所示,設(shè)N為用戶取得最佳回答的問(wèn)題數(shù),Nmin為N最小值。本文以Nmin=5,10,15,20構(gòu)造4個(gè)用戶集UN[13]。在數(shù)據(jù)集“Server Fault”中,最佳回答數(shù)至少為20的用戶有470位,這些用戶取得最佳回答的問(wèn)題在訓(xùn)練集中有34 655個(gè),在測(cè)試集中有1 875個(gè)。N越大,則用戶數(shù)顯著減少,但是該用戶集回答的問(wèn)題數(shù)卻沒(méi)有顯著減少。分析結(jié)果表明,數(shù)量?jī)H為0.5%的用戶回答了35%的問(wèn)題(有答案的問(wèn)題中)[3]。因此,本文通過(guò)N區(qū)分出專業(yè)度和活躍度不同的用戶。
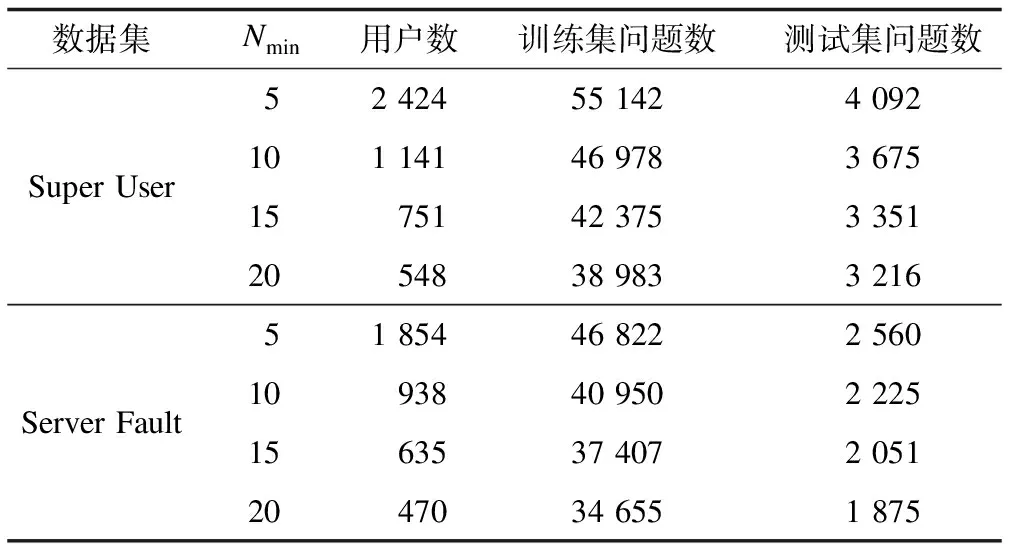
表2 2種數(shù)據(jù)集下的訓(xùn)練集和測(cè)試集
3.2 實(shí)驗(yàn)結(jié)果分析
為進(jìn)行公正評(píng)價(jià),本文使用MRR(Mean Reciprocal Rank)指標(biāo)評(píng)價(jià)算法。MRR經(jīng)常被用于對(duì)搜索算法進(jìn)行評(píng)價(jià):對(duì)于查出來(lái)的結(jié)果列表,如果第1個(gè)結(jié)果匹配,那么分?jǐn)?shù)為1,第2個(gè)匹配則分?jǐn)?shù)為0.5,……,第n個(gè)匹配則分?jǐn)?shù)為1/n。本文方法為測(cè)試集中所有問(wèn)題生成候選專家列表,如果該問(wèn)題的最佳回答者出現(xiàn)在候選專家列表的第n個(gè)位置,那么此次MRR分?jǐn)?shù)為1/n。
將本文方法與4種不同類型的方法在2個(gè)數(shù)據(jù)集Super User和Server Fault上進(jìn)行對(duì)比實(shí)驗(yàn),即基于LDA的專家發(fā)現(xiàn)方法LDA[3]、基于分段主題模型的方法STM[3]、RankingSVM模型[13]和QR-DSSM[10]。其中,LDA和STM從用戶文檔以及問(wèn)題文本中挖掘潛在主題信息,根據(jù)用戶的潛在主題信息估算其專業(yè)知識(shí),能夠判斷新提出問(wèn)題能否被該用戶回答。RankingSVM將排序問(wèn)題轉(zhuǎn)化成分類問(wèn)題,為新提出的問(wèn)題生成候選專家列表。QR-DSSM使用DSSM模型提取語(yǔ)義特征,即從用戶文本中提取用戶特征,從問(wèn)題文本中提取問(wèn)題特征,最后根據(jù)兩者的余弦相似度值從高到低得到候選專家列表,該方法首先建立用戶檔案,從用戶檔案和問(wèn)題文本中使用DSSM模型學(xué)習(xí)用戶特征和問(wèn)題特征。
本文實(shí)驗(yàn)的實(shí)驗(yàn)結(jié)果均在處理器為Inter(R)Core(TM)i7-6700HQ CPU@2.60 GHz的計(jì)算機(jī)上得到,實(shí)驗(yàn)數(shù)據(jù)如表3所示,MRR曲線如圖5、圖6所示。
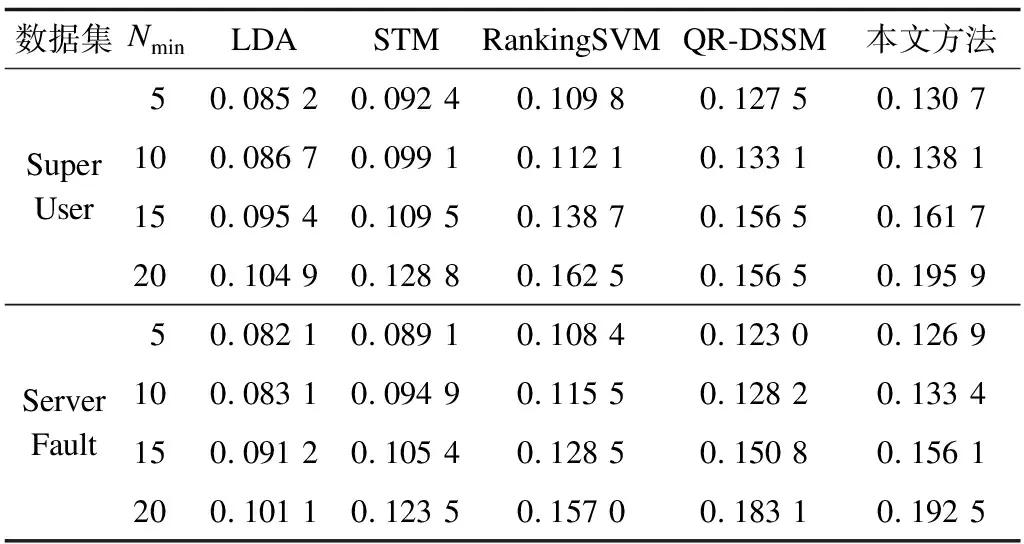
表3 5種方法的實(shí)驗(yàn)結(jié)果對(duì)比
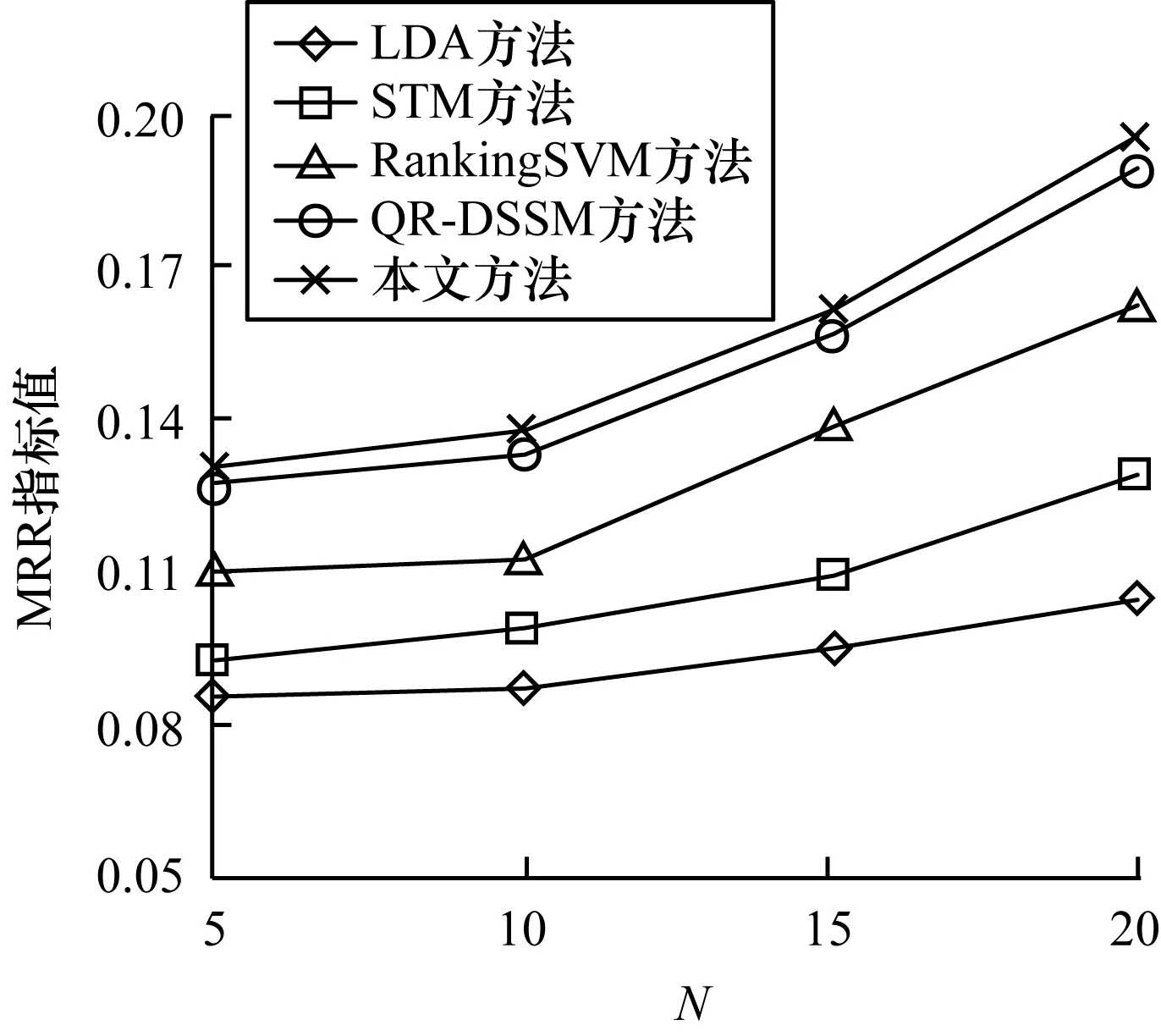
圖5 Super User數(shù)據(jù)集下的實(shí)驗(yàn)結(jié)果
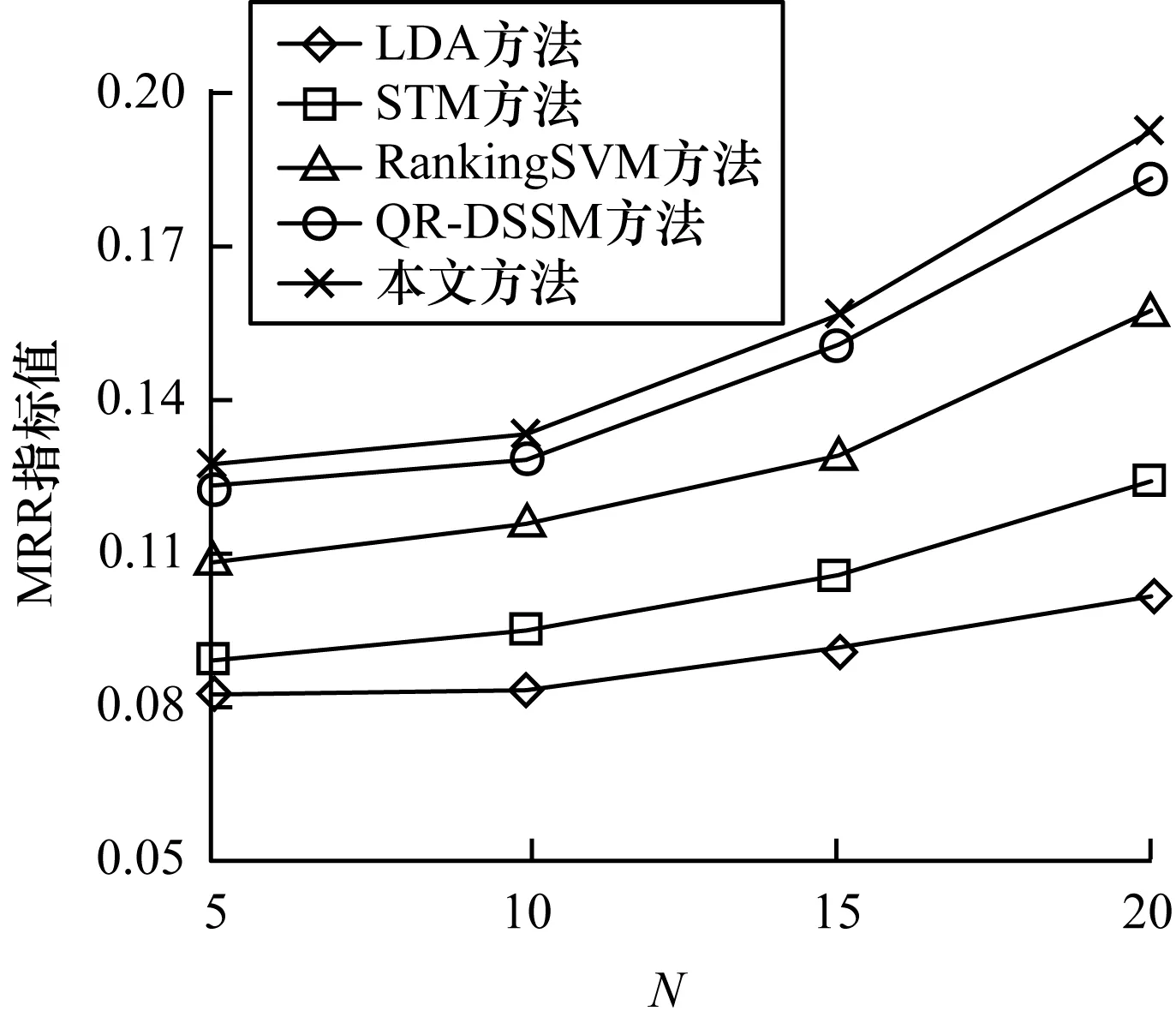
圖6 Server Fault數(shù)據(jù)集下的實(shí)驗(yàn)結(jié)果
從表3、圖5和圖6中可以看出,對(duì)Super User和Server Fault上的4個(gè)用戶集(Nmin=5,10,15,20),本文方法均取得了更好的效果。其中,數(shù)據(jù)集Super User的用戶量比數(shù)據(jù)集Server Fault要多18%~30%,各方法在Super User上的結(jié)果均優(yōu)于Server Fault,本文方法在Super User上取得了最高的MRR指標(biāo),為0.195 9。
與基于主題模型的方法LDA[3]和STM[3]相比,本文方法平均MRR指標(biāo)提高了67%和69%,比起效果更好的STM也提高了45%和46%,這表明傳統(tǒng)的主題模型在短文本上難以挖掘潛在主題信息,而本文方法從網(wǎng)絡(luò)中學(xué)習(xí)用戶信息的方式更優(yōu)。與基于分類模型的RankingSVM[13]方法相比,本文方法平均MRR指標(biāo)提高了19.8%和19.1%,與QR-DSSM[10]相比,本文方法在準(zhǔn)確率上也提高了2%~5%。QR-DSSM根據(jù)用戶歷史回答記錄建立用戶文檔,問(wèn)題附帶的標(biāo)簽被作為普通的文本處理,重要的標(biāo)簽信息經(jīng)過(guò)神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)逐漸被忽略。而本文方法則從用戶-標(biāo)簽網(wǎng)絡(luò)中學(xué)習(xí)用戶向量,使用戶向量包含網(wǎng)絡(luò)結(jié)構(gòu)信息以及標(biāo)簽信息,而使用DSSM模型則能更好地尋找用戶與問(wèn)題的映射關(guān)系。由此可以證明,本文方法能更準(zhǔn)確地尋找到可提供正確答案的候選專家。
4 結(jié)束語(yǔ)
本文以用戶和標(biāo)簽為節(jié)點(diǎn)構(gòu)建用戶-標(biāo)簽異構(gòu)網(wǎng)絡(luò),基于此提出一種社區(qū)問(wèn)答專家發(fā)現(xiàn)方法。使用網(wǎng)絡(luò)嵌入方法獲得用戶在網(wǎng)絡(luò)中的向量表示,通過(guò)Word2vec工具訓(xùn)練得到問(wèn)題文本的低緯度向量表示。在此基礎(chǔ)上,應(yīng)用DSSM模型提取用戶特征和問(wèn)題特征,根據(jù)兩者的余弦相似度生成專家列表。使用StackExchange站點(diǎn)的真實(shí)世界數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),結(jié)果表明,本文方法的專家發(fā)現(xiàn)性能優(yōu)于對(duì)比的問(wèn)答社區(qū)專家發(fā)現(xiàn)方法,能為問(wèn)題尋找到更合適的專家。下一步將對(duì)標(biāo)簽進(jìn)行聚類以減少網(wǎng)絡(luò)節(jié)點(diǎn),從而加快網(wǎng)絡(luò)嵌入訓(xùn)練的速度。
猜你喜歡
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
