基于生成矩陣變換的跨數據中心糾刪碼寫入方法
2020-02-19 03:35:50王意潔許方亮
計算機研究與發展 2020年2期
包 涵 王意潔 許方亮
1(并行與分布處理國家重點實驗室(國防科技大學) 長沙 410073)2(國防科技大學計算機學院 長沙 410073)
近年來,數據中心(datacenter, DC)故障屢見不鮮[1-8].因此,存放在單數據中心存儲系統里的數據面臨著永久丟失的風險.為了確保在數據中心故障時仍能恢復其中的數據,各大機構通常選擇采用容錯技術(糾刪碼和多副本)將數據存儲在跨數據中心存儲系統中.
在單數據中心存儲系統中,糾刪碼因其高容錯性和低冗余度而得到了廣泛應用[9-12].然而,在跨數據中心存儲系統中,由于下列原因,糾刪碼的寫入速度較低以至于難以適應于大數據時代日益增長的數據產生速度[13-14]:
1) 糾刪碼寫入數據時,源節點需要向若干節點傳輸大量的數據塊或編碼塊,因此數據傳輸量較大.此外,在跨數據中心存儲系統中,糾刪碼寫入數據時需要頻繁地在數據中心間進行數據傳輸,因而數據的平均傳輸距離(跳數)較長[15-16].因此,跨數據中心糾刪碼寫入數據時的網絡資源消耗量(數據傳輸量與平均傳輸距離之積)較大.當網絡資源消耗量較大時,有較大概率需要在低帶寬的物理鏈路上傳輸較多的數據,這將形成傳輸瓶頸,導致寫入速度低的問題[17].
2) 糾刪碼寫入數據的過程中涉及較多的編碼操作,并需要在位于多個數據中心的多個節點間進行頻繁的數據傳輸操作,若無法有效保證編碼效率和傳輸效率,極易造成編碼計算瓶頸或傳輸瓶頸,進而導致寫入速度低的問題.
由于跨數據中心糾刪碼較低的寫入速度大大限制了其可用性,本文聚焦于提高跨數據中心糾刪碼的寫入速度.
現有的糾刪碼寫入方法分為集中式寫入方法[18-19]和分布式寫入方法[20-22]2類:
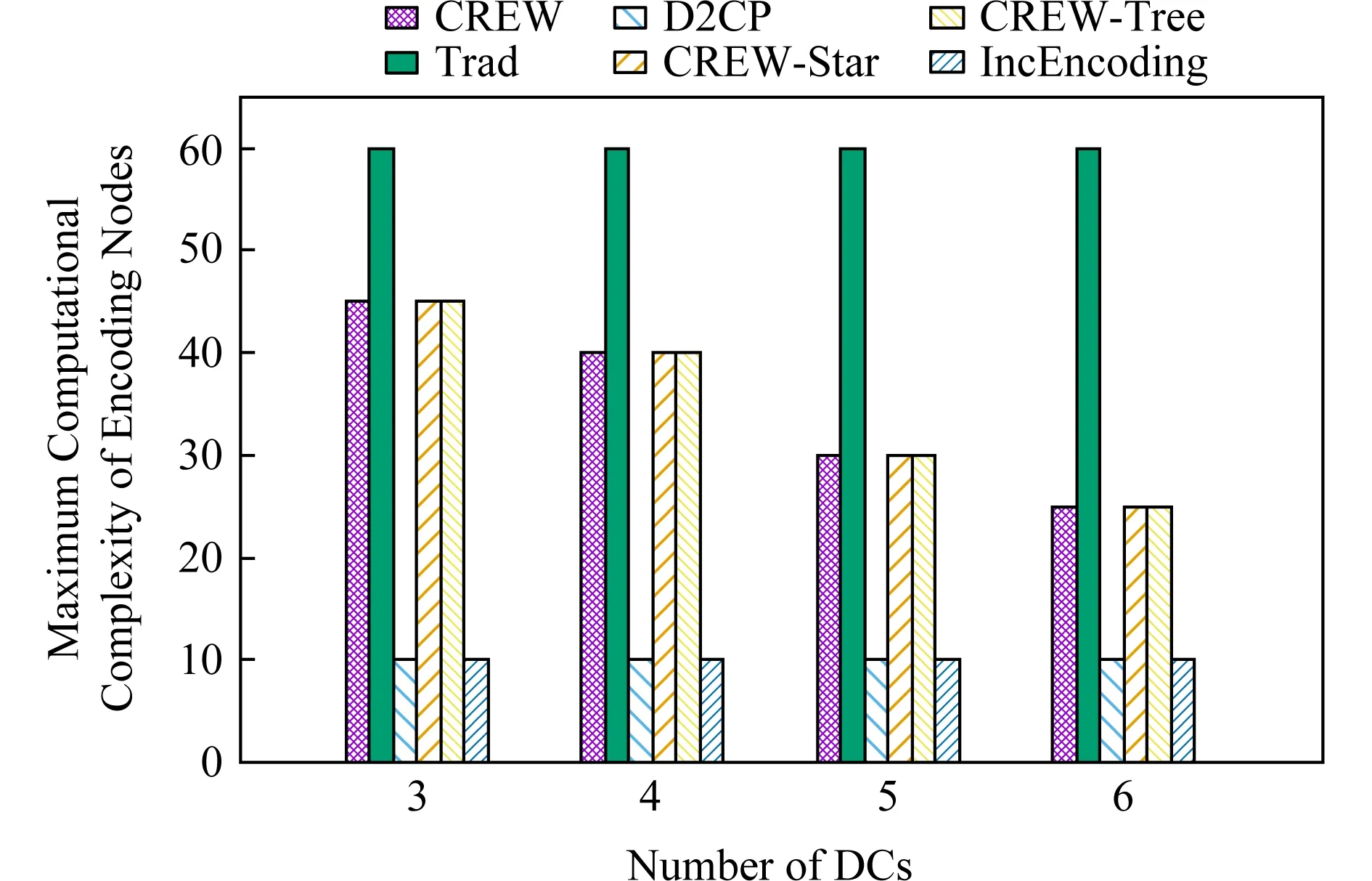
已有的集中式寫入方法主要是面向單數據中心糾刪碼的.在這類寫入方法中,中心編碼節點將單獨負責完成一個條帶中所有編碼塊的編碼生成任務,這將形成嚴重的編碼瓶頸.如圖1(a)所示,在我們的實際測試中,集中式寫入方法Trad[19]的單個節點最大計算復雜度是2種分布式寫入方法D2CP[22]和IncEncoding[23]的4.3~8.8倍.因此,集中式寫入方法的整體編碼效率較低,這會對寫入速度產生不利影響.
為了提高糾刪碼寫入數據時的編碼效率,研究者們提出了分布式寫入方法(包括面向單數據中心糾刪碼的分布式寫入方法[20-22]的和面向跨數據中心糾刪碼的分布式寫入方法[23]).通過將編碼操作分散到多個編碼節點上并行執行,分布式寫入方法能夠提高編碼效率.然而,這類方法通常會引入較大的網絡資源消耗量,從而對寫入速度產生不利影響.尤其是在跨數據中心存儲系統中,這一問題更加突出.如圖1(b)所示,2種分布式寫入方法D2CP和IncEncoding的網絡資源消耗量是集中式寫入方法Trad的2.1~2.5倍.此外,在涉及節點較多時,分布式寫入方法需要在多個節點間多次轉發同一數據塊.如圖1(c)所示,2種分布式寫入方法D2CP和IncEncoding的單個數據塊最大轉發次數為集中式寫入方法Trad的6~11倍.由于數據塊在節點間進行轉發時需要進行額外的磁盤讀寫操作和排隊等待操作[23],因而數據塊的轉發次數越多,傳輸效率越低,這將對寫入速度產生不利影響.
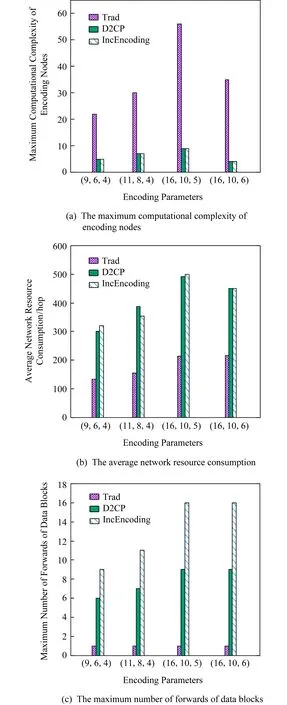
Fig. 1 Comparison between the centralized writing method of erasure code and the distributed writing method of erasure code圖1 分布式糾刪碼寫入方法和集中式糾刪碼寫入方法的對比
總而言之,在跨數據中心存儲中,現有糾刪碼寫入方法由于無法兼顧網絡資源消耗量、編碼效率和傳輸效率,使得它們難以達到較高的寫入速度.為此,本文提出了一種基于生成矩陣變換的跨數據中心糾刪碼寫入方法(cross-datacenter erasure code writing method based on generator matrix trans-formation, CREW).具體而言,CREW包含以下3個算法:
1) 一種基于貪心策略的傳輸拓撲構造算法(greedy strategy-based transmission topology con-struction algorithm, GBTC).可構造一種自頂向下邊權(網絡距離)遞增的數據中心級傳輸樹來組織數據中心間的數據傳輸.同時,GBTC還將構造一種星型拓撲來組織各數據中心內部的數據傳輸.
2) 一種生成矩陣變形算法(generator matrix transformation algorithm, GMT).可在不改變各編碼塊間的線性關系的前提下對編碼塊生成矩陣進行變形,使得需要存儲在位于GBTC構造的傳輸樹下端的數據中心里的編碼塊的生成過程依賴于盡可能少的數據塊.因為GBTC構造的傳輸樹自頂向下邊權遞增,所以使用GMT對生成矩陣進行變形可使寫入過程中需要長距離傳輸的數據塊盡可能地少,進而可以降低網絡資源消耗量.
3) 一種分布式流水線寫入算法(distributed pipelined writing algorithm, DPW).可協調各節點間的數據傳輸操作和編碼操作.為了避免節點的計算能力成為編碼瓶頸, DPW在數據中心間進行分布式的數據編碼和數據傳輸.為了避免因數據轉發次數過多造成傳輸瓶頸,DPW在數據中心內部進行集中式的數據編碼和數據傳輸.
1 相關工作
在采用編碼參數為(n,k,d)的糾刪碼的存儲系統中寫入數據時,原始數據首先將被源節點Src拆分為多個數據塊,每k個數據塊組成一個條帶.接著每個條帶的k個數據塊X=(x1,x2,…,xk)將被編碼節點編碼為n個編碼塊Y=(y1,y2,…,yn),編碼過程如式(1)所示:
Y=XG,
(1)
其中滿秩矩陣G被稱為糾刪碼的生成矩陣.對應于每個生成矩陣,存在一個(n-k)×n的滿秩矩陣H,使得GHT=0,H被稱為糾刪碼的校驗矩陣[24-26].
當編碼節點完成編碼后,n個編碼塊將被存儲在n個不同的存儲節點中,以確保在一個條帶中任意d-1個編碼塊所在的存儲節點失效時,系統可以通過其他n-k-d+1個存儲節點的編碼塊來恢復原始數據.
糾刪碼的寫入模式可以分為2類:先副本后編碼模式和直接編碼模式.與先副本后編碼模式相比,直接編碼模式對系統的計算資源和存儲資源的消耗更低,但對糾刪碼寫入速度的要求更高.因此,本文主要關注于如何提高直接寫入模式下的糾刪碼寫入速度.在直接寫入模式下,糾刪碼的寫入方法可分為集中式寫入方法和分布式寫入方法2類.
1.1 集中式寫入方法
已有的集中式寫入方法Trad主要是面向單數據中心存儲的.Trad寫入數據時,源節點首先將所有的數據塊傳送給中心編碼節點,然后由中心編碼節點將這些數據塊編碼為若干編碼塊后分發到若干個存儲節點中.由于集中式寫入方法簡單易實現且便于維護,WAS[27]和Atlas[28]等分布式存儲系統均采用集中式寫入方法.但是,由于集中式寫入方法將所有編碼計算負載集中在中心編碼節點上,這種方法的編碼效率較低,極易造成性能瓶頸.
此外,Fan等人[19]提出了一種新的集中式數據寫入方法Trad-MR.在寫入數據時,Trad-MR首先會將不同的數據對象發送到不同的MapReduce節點中,然后由不同的MapReduce節點來負責不同數據對象的編碼和分發.這種方法可以在一定程度上緩解糾刪碼寫入數據時的性能瓶頸問題,但隨著寫入數據量的不斷增加,MapReduce節點的計算能力仍然可能成為寫入過程的瓶頸.
總而言之,集中式寫入方法的優點是簡單易實現,其缺點是編碼效率較低,從而對糾刪碼寫入速度造成不利影響.
1.2 分布式寫入方法
分布式寫入方法在進行數據寫入時,會將數據編碼任務分散到多個編碼節點上并行執行以提高編碼效率.已有的分布式寫入方法分為面向單數據中心糾刪碼的分布式寫入方法和面向跨數據中心糾刪碼的分布式寫入方法2類.
1) 面向單數據中心糾刪碼的分布式寫入方法
Lluis等人[21]提出一種網內分布式寫入方法In-Network.In-Network在寫入數據時首先由源節點將原始數據條帶劃分為k個數據塊.然后,源節點將劃分好的k個數據塊分發到k個存儲節點中.這些存儲節點在接收到數據塊后將同時進行數據塊的存儲操作和轉發操作.接收到這些存儲節點轉發的數據塊的編碼節點將使用這些數據塊完成編碼塊的編碼生成任務,同時將一部分編碼塊(中間編碼塊)發送到其編碼節點中參與其他編碼塊的編碼生成過程.最后,所有編碼節點都將接收到編碼所需的中間編碼塊或數據塊.總而言之,In-Network通過將數據寫入時的編碼任務分散到多個節點來提高編碼效率.然而,In-Network僅僅適用于局部性碼并且對編碼參數具有較為嚴格的要求.因此,In-Network的通用性較差.
針對In-Network通用性差的問題,我們在文獻[22]中提出了一種通用性更高的分布式寫入方法D2CP,適用于所有的局部性碼.在D2CP中,源節點將數據對象分塊后先完成部分的編碼操作,然后將編碼生成的中間編碼塊發送到相應的編碼節點中,這些編碼節點在接收到源節點發送的中間編碼塊后通過相互協作的方式完成剩余的編碼操作以得到最終的編碼塊.與In-Network類似,D2CP通過將編碼操作分散到多個節點并行執行的方式提高了編碼效率,并且具有比In-Network更高的通用性.
2) 面向跨數據中心糾刪碼的寫入方法
我們在文獻[23]中提出了一種面向跨數據中心糾刪碼的分布式寫入方法IncEncoding.在IncEncoding中,所有存儲節點都是編碼節點,源節點和存儲節點以線性拓撲組織,源節點將數據對象分塊后沿著線性拓撲以流水的方式依次發送各個數據塊,各個存儲節點接收到一個數據塊后就使用其進行編碼得到中間編碼塊,同時將該數據塊轉發給下一存儲節點.最終,每個存儲節點都將收到自己所需的所有數據塊,并編碼生成最終的編碼塊.
以上分布式寫入方法都能夠將編碼操作分散到多個節點上并行執行,因而能夠有效提高寫入時的編碼效率.但是,由于通常需要在多個節點間傳輸數據塊和中間編碼塊,分布式寫入方法也帶來了較大的網絡資源消耗量.此外,在涉及節點較多時,已有的分布式寫入方法中數據塊在存儲節點間的轉發次數較多.由于存儲節點轉發數據時通常會帶來額外的磁盤讀寫耗時和排隊耗時[23],因而數據塊的轉發次數越多,傳輸效率較低,進而導致寫入速度越低.
2 基于生成矩陣變換的跨數據中心糾刪碼寫入方法(CREW)
已有糾刪碼寫入方法在跨數據中心存儲系統中寫入數據時面臨著寫入速度較低的問題.在本節中,我們提出了一種基于生成矩陣變換的分布式流水線跨數據中心糾刪碼寫入方法,可以通過降低數據寫入時的網絡資源消耗量、提高編碼效率和傳輸效率來提高寫入速度,其主要思想是:通過對傳輸拓撲和生成矩陣同時進行優化達到降低網絡資源消耗量的目的;同時,通過將編碼操作和傳輸操作分散到多個節點上并行執行并控制數據塊的轉發次數達到提高編碼效率和傳輸效率的目的.
在本節中,我們首先通過一個實例來介紹CREW的主要思想.接著,分別介紹CREW包含的3個主要算法:一種基于貪心策略的傳輸拓撲構造算法GBTC、一種生成矩陣變形算法GMT和一種分布式流水線寫入算法DPW.最后給出CREW的整體算法流程.
2.1 主要思想
首先,我們通過一個實例來介紹CREW的主要思想.假設某編碼參數為(6,4,2)的糾刪碼的原始生成矩陣為式(2)中的G.

(2)
存儲節點和源節點位于UCloud[29]的6個數據中心中(分別用TPE,PEK1,PEK2,SHA,CAN,LA表示),這6個數據中心間的網絡距離如表1所示.詳細數據放置方案為:源節點位于PEK1,存放編碼塊y4,y5,y6的存儲節點位于PEK2,存放編碼塊y2和y3的存儲節點位于TPE, 存放編碼塊y1的存儲節點位于SHA.
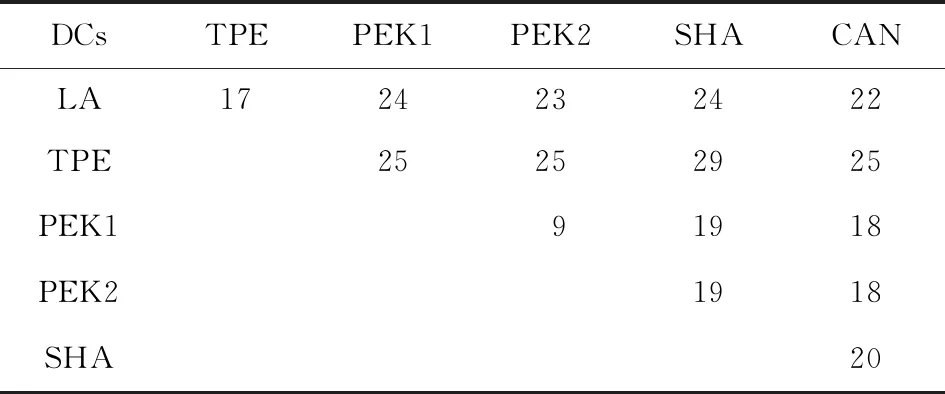
Table 1 Network Distances Between 6 DCs of UCloud表1 UCloud的6個數據中心間的網絡距離 hop
CREW首先使用GBTC構造一個如圖2所示的數據傳輸拓撲,其中:各個數據中心由一個樹形拓撲來組織,該樹形拓撲中自頂向下邊的權值(網絡距離,即跳數)遞增;數據中心內部的各節點由一個星型拓撲來組織.
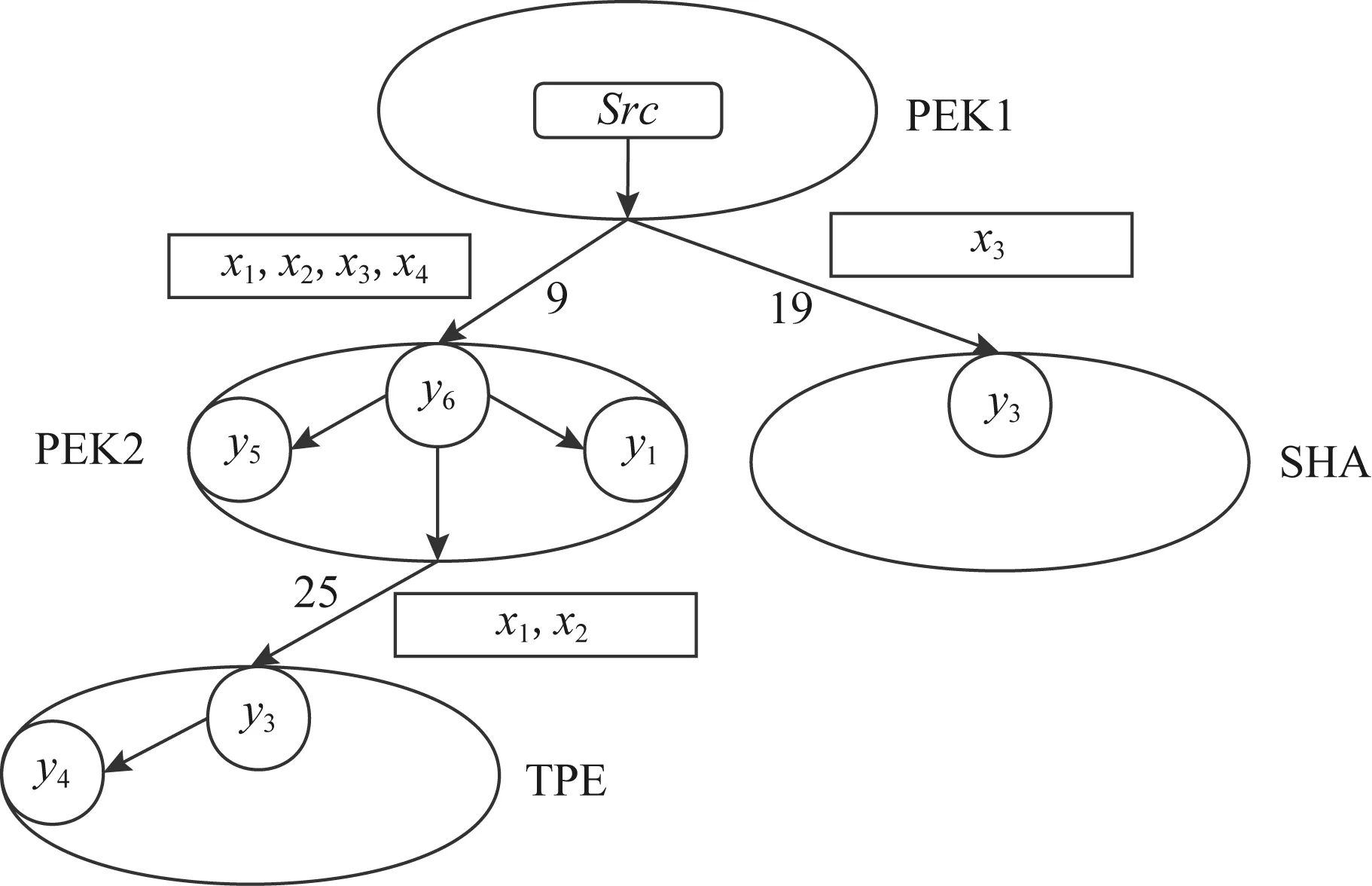
Fig. 2 Transmission topology of CREW圖2 CREW的傳輸拓撲
接著,CREW使用GMT對原生成矩陣G進行初等行變換得到式(3)中的實際生成矩陣G′.

(3)
使用G′對數據進行編碼后,樹形拓撲中越下端的數據中心要存儲的編碼塊與越少的數據塊線性相關(即G′中相應列的非零行越少).
最后,如圖2所示,CREW使用DPW按以下方式組織各條帶中數據的編碼和傳輸:1)源節點Src先將原數據拆分為4個數據塊x1,x2,x3,x4;2)源節點向PEK2中的一個節點(編碼節點)發送x1,x2,x3,x4,并向SHA中的一個節點(編碼節點)發送x3;3)PEK2中的編碼節點收到4個數據塊后使用G′對其進行編碼得到y6,y5,y4,將y6存儲在本地,并將y5和y4發送到PEK2中的另外2個節點中存儲;4)SHA中的編碼節點接收到x3后使用G′對其進行編碼得到y3=x3并將y3存儲到本地;5)PEK2在使用x1,x2,x3,x4編碼生成y6,y5,y4的同時,將x1,x2轉發到TPE中的一個節點(編碼節點)中;6)TPE中的編碼節點收到x1,x2后使用G′對其進行編碼得到y1=x1和y2=x2,將y2存儲到本地并將y1發送到TPE中的另一個節點中存儲.需要強調的是,各個節點是按流水并行的方式執行各項編碼、傳輸任務的,即同一時間內有多個條帶的數據在這些節點中進行編碼和傳輸.
在CREW寫入數據的過程中,由于需要長距離傳輸的數據塊較少,所以網絡資源消耗量較低.與面向跨數據中心糾刪碼的分布式寫入方法IncEncoding相比,CREW可將寫入數據時的網絡資源消耗量降低59.4%.此外,由于在數據中心內部采用了集中式的數據編碼和傳輸,CREW的傳輸效率較高,可將數據塊的最大轉發次數降低50%.
與集中式寫入方法Trad相比,CREW的網絡資源消耗量高了12.5%.但由于CREW的數據編碼任務是分散到多個節點上以流水并行的方式進行的,與Trad相比CREW的編碼效率較高,可將單個節點的最大乘法運算次數降低50%.此外,在集中式寫入方法Trad中,中心編碼節點除了要負責完成所有的編碼操作外,還需要負責完成所有的編碼塊分發操作,進一步降低了其編碼效率.因此,CREW的編碼效率遠高于Trad.
此外,在計算實際生成矩陣G′時,我們僅僅對原始生成矩陣G進行了初等行變換,所以使用G′編碼得到的各編碼塊間的線性關系與使用G進行編碼時相同.也就是說,對生成矩陣進行變換并不改變糾刪碼原有的修復過程.
2.2 基于貪心策略的傳輸拓撲構造算法(GBTC)
糾刪碼數據寫入時的傳輸拓撲可以用一個有向圖D=V,E表示.其中,點集合V包含源節點和所有用于存儲編碼塊的存儲節點,邊集合E中的邊e=v1,v2∈E表示寫入過程中節點v1將向節點v2傳輸編碼塊或數據塊.e=v1,v2的權值weight(e)設為節點v1和節點v2之間的網絡距離.因此,傳輸拓撲D的總網絡距離為其中,傳輸拓撲D的數據中心間網絡距離定義為為E中連接屬于不同數據中心的節點的邊的集合).
由于糾刪碼寫入過程中既涉及數據中心間的數據傳輸又涉及數據中心內的數據傳輸,因此傳輸拓撲可以分為2部分:
1) 數據中心間傳輸拓撲.在CREW構建數據中心間傳輸拓撲時,首先要求使用一種樹形傳輸拓撲組織數據傳輸以分散數據的編碼任務,從而保證編碼效率.其次,要求NDDin盡可能小以降低網絡資源消耗量.此外,因為在CREW中越靠近源節點的邊上需要傳輸的數據塊數越多,所以要求越靠近源節點的邊的權值越小,從而達到充分降低網絡資源消耗量的目的.
2) 數據中心內傳輸拓撲.由于在各個數據中心內只需編碼并存儲部分編碼塊,所以在數據中心內編碼時的計算量較小.因此,在構建數據中心內傳輸拓撲時,出于控制數據塊的轉發次數的目的,CREW將在數據中心內采用集中式編碼方法進行編碼并使用一種以編碼節點為中心的星型拓撲結構來組織數據傳輸.
為了構造滿足以上要求的傳輸拓撲,我們提出了一種基于貪心策略的傳輸拓撲構造算法(GBTC),如算法1所示:
算法1.基于貪心策略的傳輸拓撲構造算法GBTC.
輸入:源節點Src、 存放編碼塊的存儲節點集合N、N中節點所在的數據中心的集合DC、各節點間的網絡距離矩陣DIS;
輸出:傳輸拓撲D=V,E.
① for eachDCiinDC
②Venc,i←selectRandomly(N,DCi);*從
N中隨機選擇一個屬于DCi的節點*
③ for eachvjinDCi
④ ifvj≠Venc,i
⑤E.add(vj,Venc,i);
⑥ end if
⑦ end for
⑧ end for
⑨Vt.add(Src);
⑩Venc.add(Src);
Nenc-Venc);*Nenc-Venc中選出2個離nd最近的節點*
第1步. GBTC從每個數據中心中隨機選擇一個存儲節點作為該數據中心的編碼節點(算法1第①②行).同時,GBTC以各數據中心的編碼節點為中心,以星型拓撲結構(數據中心內傳輸拓撲)組織各個中心的所有節點,具體步驟為:GBTC將各數據中心編碼節點與該數據中心的所有非編碼節點相連產生若干條邊,并將這些邊添加到傳輸拓撲的邊集E中(算法1第③~⑦行).
第2步. GBTC將源節點Src添加到一個臨時點集Vt和數據中心間傳輸拓撲的點集Venc中(算法1第⑨⑩行).
第3步. GBTC構造一個以源節點Src為根、自頂向下邊權遞增的樹形拓撲(數據中心間傳輸拓撲)來組織所有的編碼節點和源節點Src.具體步驟如下:對于Vt中的每個節點vt,首先選中所有不在Venc中的2個距離vt最近的2個編碼節點tmpN1和tmpN2;然后將tmpN1和tmpN2加入Venc和Vt中;接著將vt與tmpN1和tmpN2分別相連產生2條邊,并將這2條邊添加到傳輸拓撲的邊集E中;最后將vt從Vt中刪除.當Vt中不含有任何節點時,E為傳輸拓撲的邊集,源節點Src與所有存儲節點的集合N的并集為傳輸拓撲的點集V(算法1第~行).
第4步. GBTC將返回傳輸拓撲D=V,E(算法1第行).
在GBTC構造數據中心間傳輸拓撲時,由于每次向E中添加邊時都是選擇權值最小的2條邊,所以構造的樹形拓撲能夠滿足NDDin較小且自頂向下邊權遞減的要求.此外,GBTC的計算復雜度為O(|DC|2).
2.3 生成矩陣變形算法(GMT)
在2.2節中,我們提出一種基于貪心策略的傳輸拓撲構造算法GBTC.在GBTC構造的數據中心間傳輸拓撲中,越遠離源節點的邊的權值越大(網絡距離越長).與之相適應地,本節將提出一種生成矩陣變形算法GMT,通過對任意線性糾刪碼的生成矩陣進行變形使得寫入過程中需要在遠離源節點的邊上傳輸的數據塊數盡可能地少,從而達到降低網絡資源消耗量的目標.與此同時,GMT可以保持各編碼塊的線性關系,因而對糾刪碼原有的修復過程沒有任何影響.此外,GMT可以保持編碼的系統性,因而不會降低讀取效率.
GMT對生成矩陣進行變形的過程如算法2:
算法2.生成矩陣變形算法GMT.
輸入:原始生成矩陣G、傳輸拓撲D、放置方案P=Y,N;
輸出:變形后的生成矩陣G′.
①Y←sortY(D,P);*根據放置方案P和傳輸拓撲D對所有的編碼塊進行排序*
②EX←exchangeScheme(Y,G);
③G1←columnExchange(G,EX);*對G進行列交換操作,得到G1*
④G2←RREF(G1);*使用RREF算法對將G1化為行最簡形矩陣G2*
⑤EX′←revert(EX);
⑥G′←columnExchange(G2,EX′).*對G2進行列交換操作,得到G′*
第1步. GMT按各編碼塊所在數據中心在GBTC構建的傳輸拓撲中與源節點Src的距離對這些編碼塊進行排序(算法2第①行).編碼塊所在數據中心與源節點Src的距離越遠,相應的編碼塊排序越靠前.
第2步. 設編碼塊的排序為yi1,yi2,…,yin,GMT將接著對生成矩陣G=(g*1,g*2,…,g*n)進行列交換操作(g*i表示G的第i個列向量),得到如下矩陣G1=(g*i1,g*i2,…,g*in)(算法2第②③行).
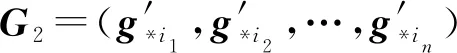
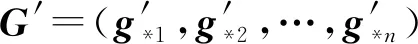
定理1.在GMT算法中,G與G′的校驗矩陣相同,即用它們編碼得到的編碼塊之間的線性關系相同.
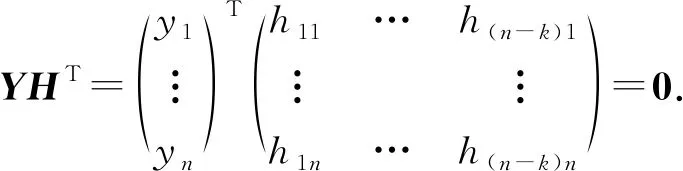
假設G的校驗矩陣為H.若將G轉換為G1的列交換操作為EX={e1,e2,e2,e3,…,ex,ex+1},其中e1,e2表示交換矩陣的第e1列和第e2列.那么,我們定義對H進行EX列交換操作得到的矩陣為H1.因為GHT=0,所以G1H1T=0.
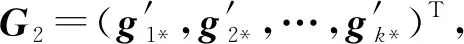
因為G′是通過對G2進行EX′={ex,ex+1,…,e1,e2}操作得到,H是通過對H1進行EX′={ex,ex+1,…,e1,e2}操作得到,所以有G′HT=0,H也是G′的校驗矩陣.因此用G′編碼得到的編碼塊之間的線性關系與用G編碼得到的編碼塊之間的線性關系相同.
證畢.
定理2.在GMT算法中,若G為系統碼的生成矩陣,則G′也為系統碼的生成矩陣.
證明. 因為矩陣G是行滿秩的,所以G1也是行滿秩的.由于矩陣的秩等于其行最簡形矩陣非零行的數量,所以G1的行最簡形(G2)一定可以通過列交換操作轉化為
[EA],
(4)
其中E為單位矩陣.
所以,G2為系統碼的生成矩陣,進而有G′為系統碼的生成矩陣.
證畢.
由定理1有,GMT并不會改變糾刪碼原有的修復過程.由定理2有,若G為系統碼的生成矩陣,則G′也為系統碼的生成矩陣,所以GMT不會改變原有糾刪碼的讀取性能.此外,由于GMT的輸入可以是任意線性糾刪碼的生成矩陣,所以GMT的適用范圍較廣.最后,GMT中的主要計算任務為執行RREF算法,其復雜度為O(k2).由于實際應用中k的值較小,因此GMT的計算用時較低.
2.4 分布式流水線寫入算法(DPW)
在2.2節和2.3節中,我們分別提出了基于貪心策略的傳輸拓撲構造算法GBTC和生成矩陣轉換算法GMT,對傳輸拓撲和生成矩陣進行了優化,從而達到效降低寫入數據時的網絡資源消耗量的目的,進而提高了寫入速度.
然而,寫入速度不僅受到網絡資源消耗量的影響,也受到寫入過程中的傳輸效率和編碼效率的影響.傳統的集中式寫入方法將所有編碼操作都集中到了中心編碼節點上,導致編碼效率低下,進而導致寫入速度較低的問題.而在已有的分布式寫入方法中,數據塊往往需要被多次轉發,帶來額外的磁盤讀寫耗時和排隊耗時,使得傳輸效率低下,同樣導致了寫入速度較低的問題.因此,為了兼顧糾刪碼寫入數據時的編碼效率和傳輸效率,我們在本節提出了一種分布式流水線寫入算法DPW.
算法3.分布式流水線寫入算法DPM.
輸入:數據塊向量X、生成矩陣G′、傳輸拓撲D.
①Src.send(X,D);
② for eachvtinD.V
③ ifvt.isEncodingNode()
④codedblocks←vt.enc(receivedBlocks);*使用G′對接收到的數據塊進行編碼,得到編碼塊*
⑤vt.storing(codedblocks);*將編碼塊存儲到本地*
⑥vo←vt.getOffspring;
⑦vt.send(vo,codedblocks);*將編碼塊轉發到下一級節點*
⑧ else
⑨vt.storing(receivedBlocks);
⑩ end if
為了避免節點的計算能力成為編碼瓶頸,DPW在數據中心間進行分布式的數據編碼和數據傳輸以將計算任務分散到多個節點并行執行.因為實際應用中用來存儲一個條帶的數據中心數較小,所以數據中心間的傳輸拓撲的選擇對數據在存儲節點間轉發的次數的影響較小.因此,在數據中心間進行分布式的數據傳輸和數據編碼既可以提高編碼效率又不會對傳輸效率造成過大影響.
此外,為了避免因數據轉發次數過多造成的傳輸瓶頸,DPW在數據中心內部進行集中式的數據編碼和數據傳輸以降低數據塊的轉發次數.因為DPW在數據中心間采用的是分布式的數據編碼,各個數據中心只負責條帶中一部分編碼塊的編碼任務,所以各數據中心中需要進行的編碼運算量較小.因此,在數據中心內部采用集中式的數據編碼和數據傳輸既可以提高傳輸效率,又不會導致編碼瓶頸.
DPW中涉及的節點有3類:源節點Src、編碼節點和普通存儲節點.DPW根據GBTC構造的數據中心間傳輸拓撲向各個編碼節點發送該編碼節點所需的數據塊(算法3第①行).各個編碼節點在接收到其所需的數據塊后將同時進行2個操作.一方面,各編碼節點向它在數據中心間傳輸拓撲中的子節點(子數據中心)里的編碼節點發送這些子節點需要的數據塊.由于越遠離源節點Src的數據中心需要的數據塊越少,傳輸的數據量是遞減的.另一方面,編碼節點用自己收到的數據塊編碼生成本數據中心各個存儲節點所需存儲的編碼塊,并以星型拓撲將這些編碼塊發送到相應的存儲節點中(算法3第③~⑦行).由于編碼操作對網絡資源占用少,而傳輸操作對計算資源占用小,編碼節點能夠以較高的效率同時進行這2項操作.為了提高寫入效率,以上過程中的數據傳輸和編碼過程都以流水并行的方式進行的.顯然,GMT的計算復雜度為O(kn).
2.5 CREW的算法描述
基于生成矩陣變換的分布式流水線跨數據中心糾刪碼寫入方法的算法描述如算法4所示:
算法4.基于生成矩陣變換的跨數據中心糾刪碼寫入方法CREW.
輸入:原始數據O、原始生成矩陣G、源節點Src、Src所在的數據中心dcc、數據塊數k、數據塊大小Sb、存放編碼塊的存儲節點集合N、N中節點所在的數據中心的集合DC、節點間的網絡距離矩陣DIS.
①m←O.size()kSb;
②D←Src.GBTC(dcc,N,DC,DIS);
③G′←Src.GMT(G);
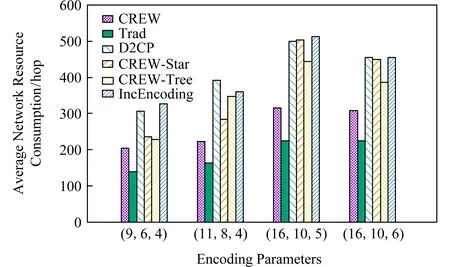
④ fori ⑤X←Src.splite(O); ⑥Src.DPW(X,D,G′); ⑦i←i+1; ⑧ end for 首先,源節點Src調用GBTC得到傳輸拓撲D并調用GMT對生成矩陣進行變形得到G′(算法4第①~③行);接著,源節點Src將原始數據劃分為若干個條帶,每個條帶含有k個數據塊(算法4第⑤行);最后,源節點Src不斷調用DPW以并行流水的方式完成所有條帶的寫入任務(算法4第⑥行). 在CREW中,GBTC的計算復雜度為O(|DC|2),GMT的計算復雜度為O(k2),DPW的計算復雜度O(kn).其中,GBTC與CMT只執行2次,DPW的執行次數由原始數據的大小決定.所以,CREW的計算復雜度為O(knm).實際應用中,k和n較小,因此CREW的計算復雜度為O(m). 為了評估CREW的性能,我們基于Hadoop 3.0.3的HDFS實現了CREW.Hadoop 3.0.3的HDFS中主要有3類節點:Client(即源節點)、NameNode和DataNode.其中,Client負責數據的寫入;NameNode負責存儲源節點Client寫入的元數據、檢測編碼塊失效、選擇DataNode來完成失效編碼塊的修復工作;DataNode則負責存儲Client寫入的數據并運行ECWorker任務對失效的編碼塊進行修復. 在實現CREW時,我們主要對Client和Data-Node進行了修改:在Client中添加了拓撲構造模塊和生成矩陣變形模塊,使其在寫入數據前可以運行GBTC來確定傳輸拓撲并可以運行GMT來對生成矩陣進行變形操作;在DataNode添加了編碼模塊,使其在寫入數據過程中可以進行部分編碼操作,從而能夠支持DPW的運行. 此外,我們同樣基于Hadoop 3.0.3的HDFS實現了一種集中式寫入方法Trad[19]、一種分布式寫入方法D2CP[22]、一種面向跨數據中心糾刪碼的分布式寫入方法IncEncoding[23]、CREW的2種變形CREW-Star和CREW-Tree. 在Trad中,源節點即為中心編碼節點,源節點先將數據對象分塊,然后對數據塊進行編碼得到編碼塊,最后將編碼塊分發到各個存儲節點中. 在D2CP中,源節點將數據對象分塊后完成部分的數據編碼操作,然后將編碼生成的中間編碼塊發送到相應的存儲節點中,存儲節點在接收到源節點的數據后通過相互協作的方式完成剩余的編碼操作. 在CREW-Star中,源節點將數據對象分塊后以星型拓撲發送給各個數據中心中的編碼節點,編碼節點在接收到所有需要的數據塊后對其進行編碼,然后將編碼得到的編碼塊以星型拓撲發送給同數據中心里的其他存儲節點. 在CREW-Tree中,源節點將數據對象分塊后以樹型拓撲(最小網絡距離生成樹)發送給各個數據中心中的編碼節點,編碼節點在接收到所有需要的數據塊后對其進行編碼,然后將編碼后的編碼塊以星型拓撲發送給同數據中心里的其他存儲節點. 在IncEncoding中,所有源節點和存儲節點以線性拓撲組織,源節點將數據對象分塊后沿著線性拓撲以流水的方式依次發送各個數據塊,各個存儲節點接收到一個數據塊就使用其進行編碼得到中間編碼塊,同時將該數據塊轉發給下一存儲節點.最終,每個存儲節點都將接收到自己所需的所有數據塊,并編碼生成最終的編碼塊. 我們的實驗環境為UCloud[29]的6個數據中心,其中2個位于北京(記為PEK1和PEK2)、一個位于上海(記為SHA)、一個位于廣州(記為CAN)、一個位于洛杉磯(記為LA)、一個位于臺北(記為TPE).我們測試了這6個數據中心間的網絡距離,如表1所示.實驗用到了每個數據中心的10個節點,每個節點配備了2個6核Intel Xeon-2640 2.5 GHz處理器、6 GB內存和20 GB磁盤. 在實驗中,我們首先使用Hadoop源碼中提供的ErasureCodeBenchmarkThroughput類來生成不同大小的文件,然后比較了不同寫入方法在不同參數下寫入這些文件時的各項性能指標.實驗中的參數如表2所示.其中,第1列為表示參數的符號,第2列為參數的定義,第3列為參數的取值范圍,第4列為參數的默認值. Table 2 Parameters in Experiments表2 實驗參數 由于糾刪碼寫入方法的寫入速度受到網絡資源消耗量、編碼效率和傳輸效率的影響.因此,我們首先比較了不同寫入方法的網絡資源消耗量;然后,我們分別用數據塊的最大轉發次數和節點的最大編碼復雜度來量化對比不同寫入方法的傳輸效率和編碼效率;最后,我們還直接比較了不同寫入方法的寫入速度. 1) 平均網絡資源消耗量.平均網絡資源消耗量定義為M·NavgSd(單位為hop).其中,M為數據寫入過程中的各節點間的數據傳輸總量,Navg為數據的平均傳輸網絡距離,Sd為數據對象的大小. 2) 數據塊最大轉發次數.由于數據的傳輸是流水并行的,理想情況下總傳輸時間由所有數據塊的最長傳輸時間決定.又因為數據塊在存儲節點上進行轉發時會帶來額外的磁盤讀寫耗時和排隊等待耗時,所以數據塊的最長傳輸時間受最長轉發次數的影響較大.因此可以使用數據塊的最大轉發次數來衡量傳輸效率.最大轉發次數越短,傳輸效率越高. 3) 節點最大計算復雜度.各個節點的編碼復雜度定義為該節點需要完成的乘法運算次數.由于數據的編碼可以分散到不同的節點同步進行,理想情況下總的編碼用時由所有節點的最長編碼用時決定,而節點的最長編碼用時受節點最大計算復雜度的影響較大.因此,節點最大計算復雜度決定了編碼效率.節點最大計算復雜度越小,編碼效率越高. 4) 寫入速度.寫入速度定義為SdT(單位為MBps),其中,T為寫入用時,Sd為數據對象的大小.寫入速度受到網絡資源消耗量、編碼效率、傳輸效率的共同影響,能夠綜合評估寫入方法的優劣. 3.3.1 平均網絡資源消耗量與編碼參數的關系 圖3顯示了使用不同編碼參數和不同寫入方法時的平均網絡資源消耗量.隨著編碼塊數n的增加,所有寫入方法的平均資源消耗量都增加了,這是由于數據傳輸量會隨著n的增加而增加.在所有寫入方法中,由于Trad在中心編碼節點中完成全部編碼塊的編碼后只需直接將編碼塊傳輸到對應的存儲節點中即可,所以其網絡資源銷量最小.但是,Trad的低網絡資源消耗量是通過犧牲編碼效率獲得的.由于Trad將全部的編碼負載集中到了中心編碼節點上,其編碼效率明顯低于其他寫入方法.在其他5種寫入方法中,CREW具有最小的平均網絡資源消耗量,這是因為CREW可以通過同時對傳輸拓撲和生成矩陣進行優化充分減少寫入過程中需要遠距離傳輸的數據塊. Fig. 3 Comparison of the average network resource consumption under different encoding parameters圖3 不同的編碼參數下的平均網絡資源消耗量對比 3.3.2 平均網絡資源消耗量與數據中心數的關系 圖4表明所有寫入方法的平均網絡資源消耗量都會隨著使用的數據中心數的增加而增加.這是由于使用的數據中心數越多,需要跨數據中心傳輸的數據越多.此外,在只使用3個數據中心進行數據存儲時,CREW的平均網絡資源消耗量甚至少于Trad,這是因為CREW此時將需要使用較多數據塊編碼得到的編碼塊存放在源節點所在的數據中心中,從而大大減少了需要跨數據中心傳輸的數據塊的數目. Fig. 4 Comparison of the average network resource consumption when different numbers of DCs are used圖4 不同的數據中心數下的平均網絡資源消耗量對比 3.4.1 數據塊最大轉發次數與編碼參數的關系 Fig. 5 Comparison of the maximum number of forwards of data blocks under different encoding parameters圖5 不同的編碼參數下的數據塊最大轉發次數對比 圖5顯示了選擇不同的編碼參數時CREW,CREW-Tree,CREW-Star,Trad的數據塊最大轉發次數沒有明顯變化.這是由于這些寫入方法在數據中心內采用的是集中式的數據傳輸和數據編碼,因而其數據塊最大轉發次數只受到數據中心間傳輸拓撲的影響,而數據中心間傳輸拓撲只受到使用的數據中心數的影響.此外,由于D2CP和IncEncoding在數據中心間和數據中心內部均采用分布式的數據傳輸和數據編碼,因而它們的數據塊最大轉發次數隨著編碼塊數n的增加而增加,并且明顯高于其他方法.最后,由于Trad和CREW-Star在數據中心間使用了無需轉發數據的星型傳輸拓撲,它們的數據塊最大轉發次數最小.但是,由于實際應用中數據中心的數目通常較小,所以數據中心間傳輸拓撲對數據塊的最大轉發次數影響較小.因此,CREW和CREW-Star的數據塊最大轉發次數在各種編碼參數下均只比Trad和CREW-Star多1~2次. 3.4.2 數據塊最大轉發次數與數據中心數的關系 圖6顯示了使用不同糾刪碼寫入方法時,數據塊最大轉發次數隨著數據中心數的增長而緩慢增長.這是由于隨著數據中心數的增多,各種方法的傳輸拓撲的深度均逐漸加深.此外,由于D2CP和IncEncoding在數據中心間和數據中心內部均采用分布式的數據傳輸和數據編碼,因而它們的數據塊最大轉發次數明顯高于其他方法.最后,由于Trad和CREW-Star在數據中心間使用了無需轉發數據的星型傳輸拓撲,所以它們的數據塊最大轉發次數最小.但是,由于數據中心的數目通常較小,所以數據中心間傳輸拓撲對數據塊的最大轉發次數影響較小.因此,實驗中CREW和CREW-Star的數據塊最大轉發次數僅比Trad和CREW-Star多1~2次. Fig. 6 Comparison of the maximum number of forwards of data blocks when different numbers of DCs are used圖6 不同的數據中心數下的數據塊最大轉發次數對比 3.5.1 節點最大計算復雜度與編碼參數的關系 圖7顯示了不同編碼參數對節點最大計算復雜度的影響.可以看到,隨著編碼塊數和數據塊數的增加,節點最大計算復雜度逐漸增加.這是由于越多的編碼塊和數據塊意味著越多的乘法計算.此外,由于IncEncoding和D2CP在數據中心間和數據中心內部均采用分布式的數據傳輸和數據編碼,所以它們的節點最大計算復雜度最低.但是,這2種方法的低節點最大計算復雜度是通過犧牲傳輸效率獲得的.如圖5所示,在不同的編碼參數下,IncEncoding和D2CP的數據塊最大轉發次數均明顯多于其他方法,因而它們傳輸效率明顯低于其他方法.在其他寫入方法中,CREW具有最低的節點最大計算復雜度,這是由于CREW在數據中心間采用分布式的數據編碼和數據傳輸,起到了分散計算負載的作用. Fig. 7 Comparison of the maximum computational complexity of encoding nodes under different encoding parameters圖7 不同的編碼參數下的節點最大計算復雜度對比 3.5.2 節點最大計算復雜度與數據中心數的關系 Fig. 8 Comparison of the maximum computational complexity of encoding nodes when different numbers of DCs are used圖8 不同的數據中心數下的節點最大計算復雜度對比 圖8顯示了不同數據中心數對節點最大計算復雜度的影響.可以看到,隨著數據中心數的增加,節點最大計算復雜度逐漸降低.這是由于越多的數據中心意味著編碼計算越分散.此外,由于IncEncoding和D2CP在數據中心間和數據中心內部均采用分布式的數據傳輸和數據編碼,所以它們的節點最大計算復雜度最低.但是,這2種方法的低節點最大計算復雜度是通過犧牲傳輸效率獲得的.如圖6所示,在不同的數據中心數下,IncEncoding和D2CP的數據塊最大轉發次數明顯多于其他方法,因而它們傳輸效率明顯低于其他方法.在其他寫入方法中,CREW具有最低的節點最大計算復雜度,這是由于CREW在數據中心間采用分布式的數據編碼和數據傳輸,起到了分散計算負載的作用. 3.6.1 寫入速度與數據包大小的關系 如圖9所示,隨著數據包大小的不斷增大,6種寫入方法的寫入速度都在不斷提高.這是因為更大的數據包能夠減少數據包的數量,從而提高傳輸速度.值得注意的是,當數據包大小從48 KB增大到64 KB時,數據傳輸速度又略微降低.這是由于超過一定大小的數據包在通過TCP傳輸時會被分為多個包,從而增加了數據包的數據量.此外,在不同的數據包大小下,CREW均能取得最高的寫入速度,這是因為CREW可在網絡資源消耗量、編碼效率和傳輸效率之間取得較好的權衡. Fig. 9 Comparison of the writing rate when different data package sizes are used圖9 不同的數據包大小下的寫入速度對比 3.6.2 寫入速度與線程數目的關系 如圖10所示,隨著線程數目的增加,6種寫入方法的寫入速度都得到提高.這是由于線程的增加提高了編碼的效率.特別的是,隨著線程數的增加,Trad的寫入速度的增加較為明顯.這是因為Trad的寫入瓶頸在于編碼效率,而提高線程數能夠有效提高編碼效率.此外,在不同的線程數目下,CREW均能取得最高的寫入速度,這是因為CREW可在網絡資源消耗量、編碼效率和傳輸效率之間取得較好的權衡. 3.6.3 寫入速度與編碼參數的關系 圖11顯示了不同編碼參數對寫入速度的影響.可以看到,隨著編碼塊數的增加,編碼速度降低.這是因為編碼塊數的增加同時增大了網絡資源消耗量和節點最大計算復雜度.此外,在不同的編碼參數下,CREW均能取得最高的寫入速度,這是因為CREW可在網絡資源消耗量、編碼效率和傳輸效率之間取得較好的權衡. 3.6.4 寫入速度與數據中心數的關系 圖12顯示了數據中心數對寫入速度的影響.可以看到,隨著數據中心數的增加,寫入速度降低.這是因為數據中心數的增加同時增大了網絡資源消耗量和數據塊最大傳輸距離.此外,在不同的數據中心數下,CREW均能取得最高的寫入速度,這是因為CREW可在網絡資源消耗量、編碼效率和傳輸效率之間取得較好的權衡. 總體而言,Trad的網絡資源消耗量少且數據塊最長傳輸網絡距離短,但其節點最大計算復雜度最高.D2CP和IncEncoding的節點最大計算復雜度低,但其數據塊最長傳輸網絡距離長且網絡資源消耗量大.CREW-Star的網絡資源消耗量大,CREW-Tree的數據塊最長傳輸網絡距離長.而CREW能在網絡資源消耗量、數據塊最大轉發次數(傳輸效率)和節點最大計算復雜度(編碼效率)間取得較好的權衡.因此,平均而言,CREW的寫入速度比IncEncoding,Trad,D2CP,CREW-Tree,CREW-Star分別提高了32.4%, 57.9%,36.3%,33.3%,35.2%. 在跨數據中心存儲系統中,已有糾刪碼寫入方法面臨網絡資源消耗量較大、編碼效率和傳輸效率低等問題,使得跨數據中心糾刪碼的寫入速度較低以至于難以適應于日益增長的數據生成速度.為此,本文提出了一種基于生成矩陣變換的跨數據中心糾刪碼寫入方法CREW.具體而言,CREW包含以下3個主要算法:基于貪心策略的傳輸拓撲構造算法GBTC和生成矩陣變形算法GMT,二者相互協作可降低數據寫入時需要遠距離傳輸的數據量,從而達到降低網絡資源消耗量的目的.以及分布式流水線寫入算法DPW來協調各節點間的數據傳輸操作和編碼操作.為了避免節點的計算能力成為編碼瓶頸, DPW在數據中心間進行分布式的數據編碼和數據傳輸.為了避免因數據轉發次數過多造成的傳輸瓶頸,DPW在數據中心內部進行集中式的數據編碼和數據傳輸.在跨數據中心環境下的實驗表明,CREW能在網絡資源消耗量、編碼效率和傳輸效率之間取得較好的權衡,從而能夠有效提高寫入速度.3 實驗與結果
3.1 實驗設置

3.2 評價指標
3.3 平均網絡資源消耗量
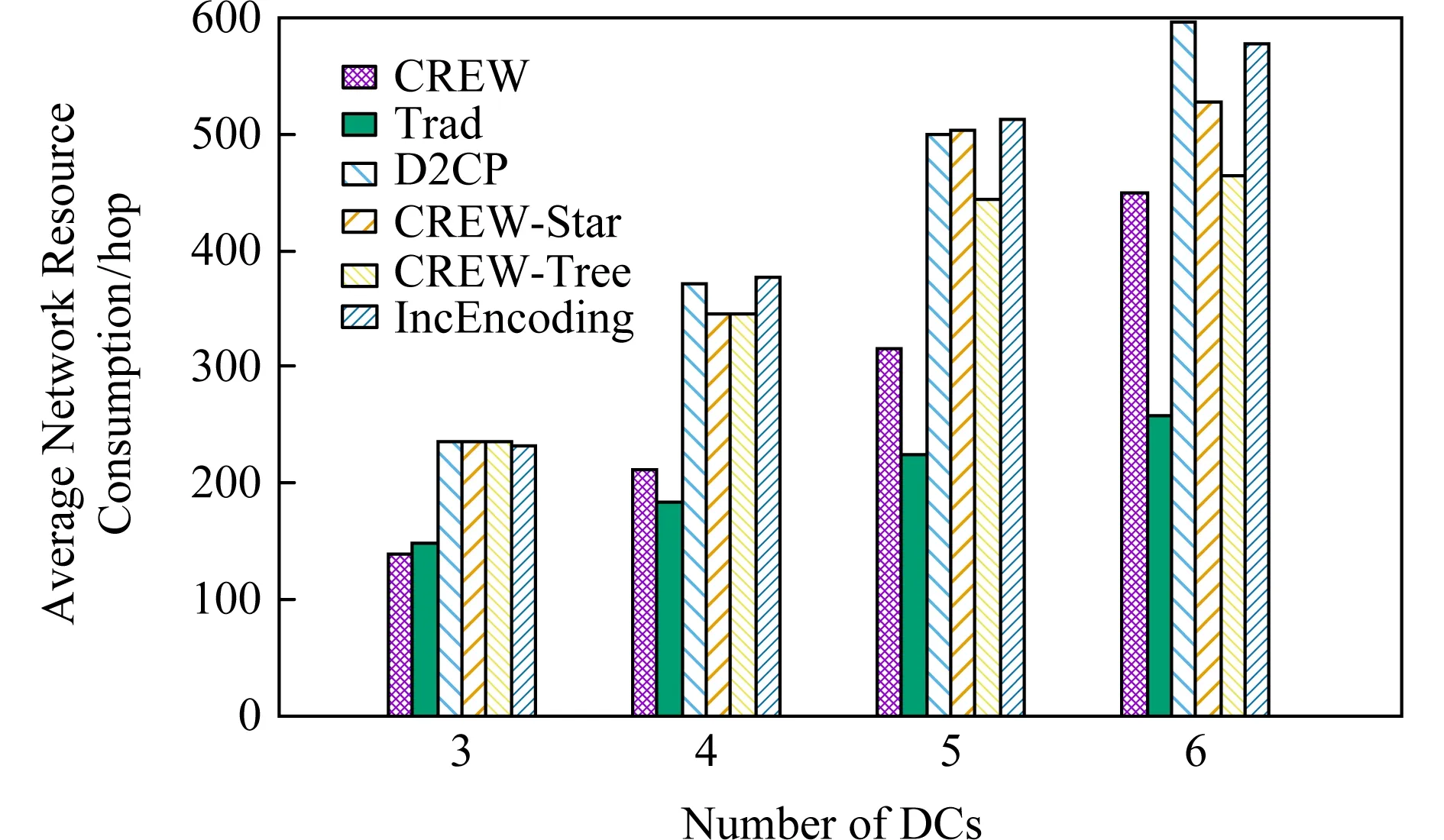
3.4 數據塊最大轉發次數
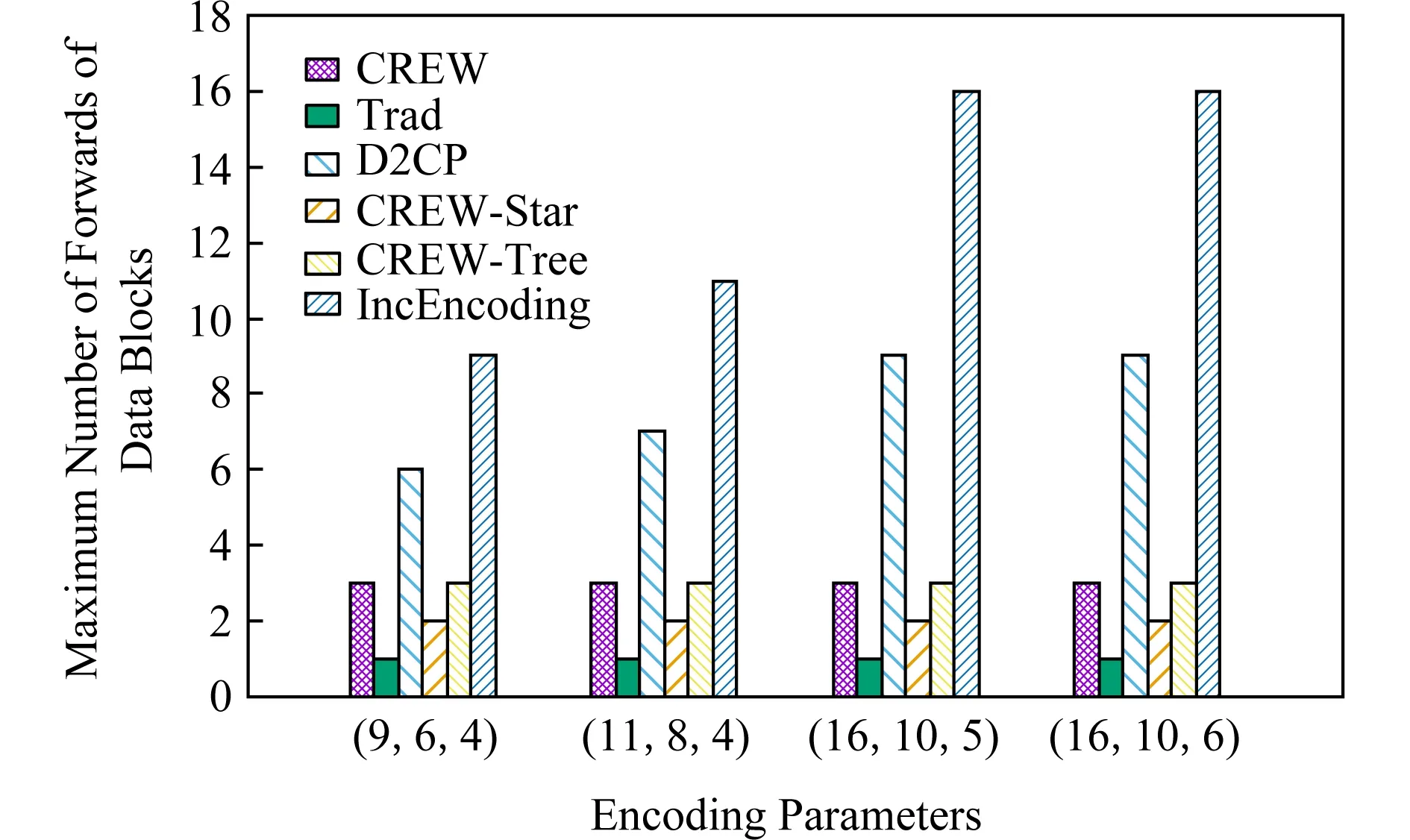
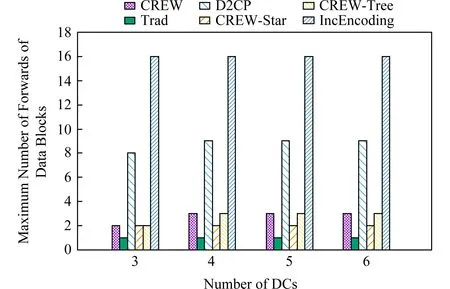
3.5 節點最大計算復雜度
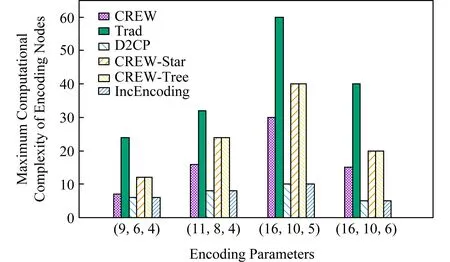
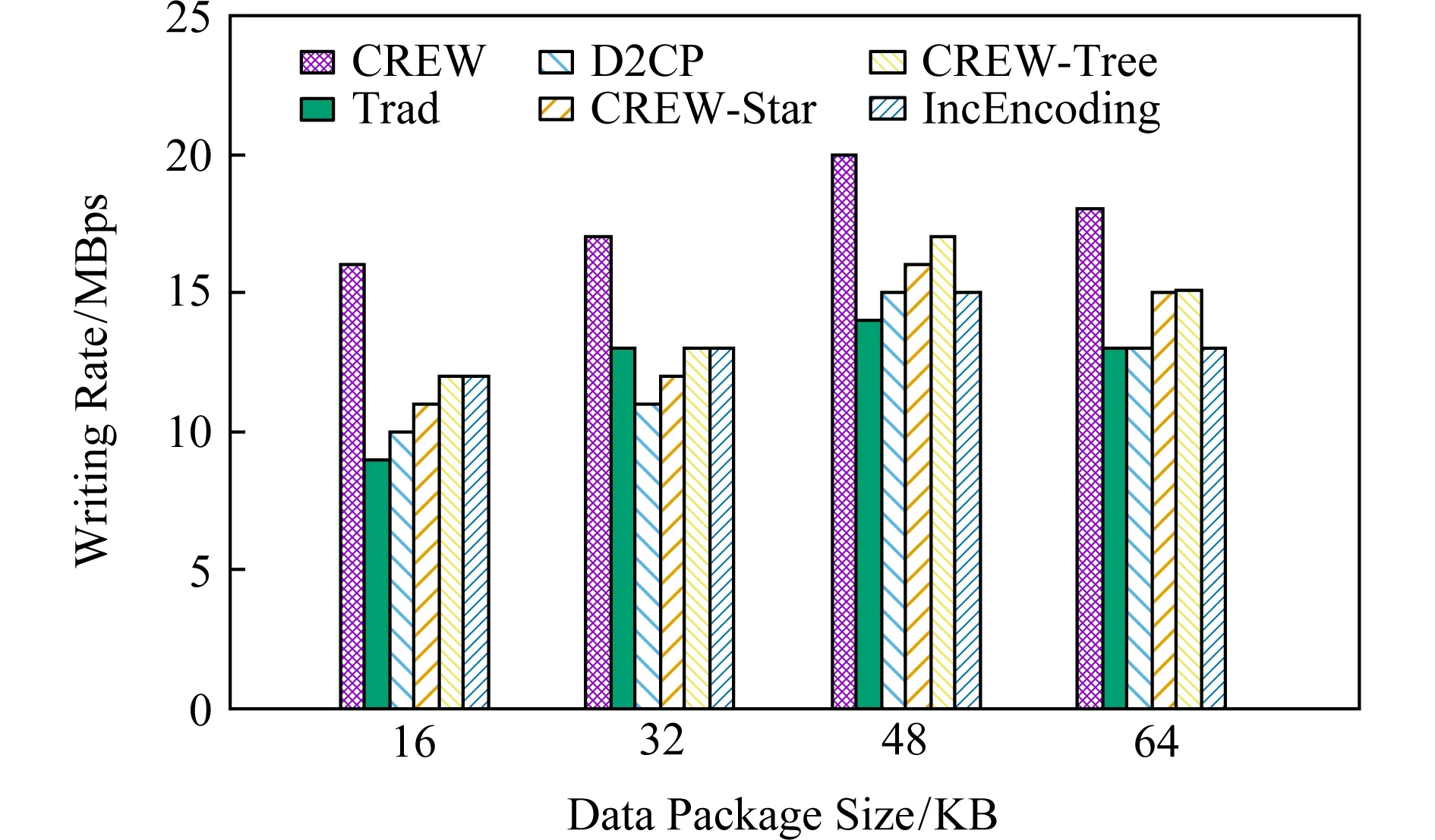
3.6 寫入速度
4 總 結
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
語言與文化論壇(2019年4期)2019-03-29 06:01:56
電子測試(2018年15期)2018-09-26 06:01:36
商周刊(2017年9期)2017-08-22 02:57:49
中國教育技術裝備(2016年15期)2016-03-01 02:46:18
新教育時代電子雜志(學生版)(2015年31期)2015-12-20 08:29:22
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛生(2014年11期)2014-11-12 13:11:32
電子設計工程(2014年18期)2014-02-27 12:00:25
