404 Not Found
404 Not Found
MySQL數據庫字符集的問題研究
石麗怡
(海南政法職業學院 海南省海口市 571100)
MySQL 數據庫是瑞典MySQL AB 公司開發的一個小型關系型數據庫管理系統。目前被廣泛地應用在Internet 加上的中小型網站。MySQL 數據庫是開源數據庫。開源數據庫的特點是速度快、易用性好、支持SQL、對網絡支持性好、可移植性好、費用低等。這些特點使得MySQL 成為“最受歡迎的開源數據庫”。在2020年4月份的DB-Engines 數據庫流行度排行榜[1]中My SQL 排名中排名第2 位。
1 MySQL字符集概述
字符集是指一種從二進制編碼到某類字符符號的映射,校對是指一組用于某個字符集的排序規則。并且每一類編碼字符都有其對應的字符集和校對規則。
只要涉及到中文的地方,就會存在字符集和編碼方式,MySQL可以支持很多種字符集,在同一臺服務器,同一個數據庫,甚至同一個表的不同字段都可以指定使用不同的字符集。相比其他數據庫管理系統,MySQL 要更加靈活些。正是因為MySQL 的字符集的靈活性,也體現了MySQL 的字符集負責性和繁瑣性,使得我們在實際得應用過程中,經常出現MySQL 數據庫中的文字不能正常顯示,會出現亂碼等情況。
2 支持中文的字符集
支持中文的字符集主流有三種:UTF-8 字符集、GBK 字符集和GB2312 字符集。
2.1 UTF-8字符集
是一種多字節的國際編碼,通用性強,它包含全世界所有國家需要用到的字符,英文用1 個字節(即8 位二進制),中文使用3個字節(24 位)來進行編碼, 其編碼的文字可以在各國支持utf-8字符集的瀏覽器上顯示。例如在utf-8 編碼下,英文的IE 也能顯示中文,無需再額外下載支持包。
2.2 GBK字符集
GBK 是國家標準編碼,通用性比較差,是GB2312 的擴展字符集,其文字編碼不論中文還是英文均采用雙字節表示,只對中文有區分,GBK 包含全部的中文字符。
2.3 GB2312字符集
GB2312 全稱是“信息交換用漢字編碼字符集”,由中華人民共和國國家標準總局于1980年發布,1981年5月1日起實施,是漢字字符集編碼,是最基本的漢字編碼集。它共有、收錄了7445個字節,其中簡化漢字6763 個,字母和符號682 個。只支持簡體中文。
2.4 字符集的選擇
這三中字符集都可以顯示中文字符,用于GB 是國標的意思,GB2312 和GBK 主要用于漢字的編碼,而utf-8 是全世界通用的。GBK 和UTF-8 功能一樣,但是編碼方式不一樣,GBK 的中文和英文編碼是雙字節,而UTF-8 是多字節編碼,英文使用1 個字節,中文使用3 個字節來編碼,所以,對于英文較多的網站則用UTF-8節省空間。如果開發的網站是不對外開放的中文網站,那么使用GB2312 和GBK 就夠了,如果開發的網站是全球通用就要設置稱UTF-8
3 MySQL數據庫的字符集問題
在使用MySQL 數據庫時,總結了以下幾種,MySQL 中出現中文亂碼的問題:①數據庫中的中文字符,亂碼顯示。②web 頁面顯示數據庫中文字符時出現亂碼。③不能儲存時下比較流行的emoji 表情。
分析產生亂碼原因:
(1)要了解MySQL 中字符集相關變量,首先了解其含義:
如表1 所示,默認的字符集可在3 個級別進行定義,分別是數據庫服務器(database sever)級別,數據庫(database)級別,數據表(table)級別以及字段(column)級。數據庫服務器(database sever)級別是在數據庫系統的配置文件my.ini(windows)或my.cnf(linux)上進行修改。可按以下步驟查詢配置文件my.ini 的位置:
①命令:select @@dasedir 查詢MySQL 在本機中的安裝目錄。
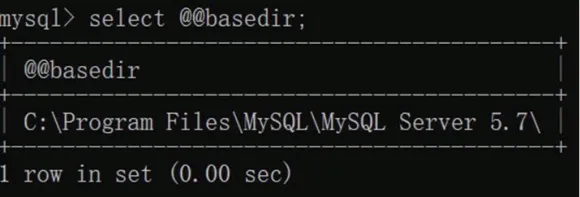
②命令:select @@datadir 查詢my.ini 所在的位置。
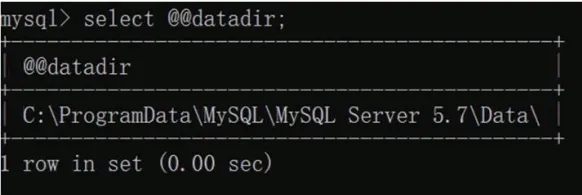
(2)了解完整的字符集流轉過程:
①mysql 服務器收到客戶端發送過來的請求時,從 character_set_client 轉換為character_set_connection。
②進行內部操作前將請求數據從character_set_connection轉換為內部操作字符集,方法如下:使用每個字段coulumn的CHARACTER SET 設定值;若未設置字段coulumn 的CHARACTER SET,則使用對應數據表的default_character_set 設定值;若Column、Table 均未設置Charater SET,則使用對應數據庫的DEFAULT CHARACTER SET 設定值;如Column、Table、Database 均未設地Charater SET,則使用服務器的character_set_server 設定值。
③最后將操作結果從內部操作字符集轉換為character_set_results。
4 針對以上問題的解決方法
4.1 數據庫中的中文字符,亂碼顯示
(1)假設在安裝MySQL 數據庫是默認安裝,那服務器默認的字符集一般是latin1。在建庫和建表時如果沒有指定其他的字符集,那么數據庫則沿用服務器默認的字符集latin1。latin1 字符集不能顯示中文字符,會提示如下所示錯誤。

表1

表2
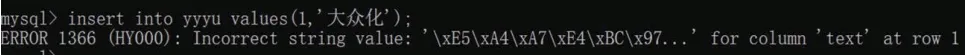
解決方法:將數據庫字符集修改為utf8 或者GBK 即可。
命令:alter database tty character set ‘utf8’;

(2)還有一種情況就是sever 為utf8,但是column 為latin1,也會提示錯誤。
解決方法:將數據表字符集修改為utf8 或者GBK。
命令:alter table yyyu convert to character set ‘utf8’.

4.2 Web頁面顯示數據庫中文字符時出現亂碼
(1)假設客戶端向MySQL 服務器發送了一組UTF-8 命令,而的此時服務器端字符集假設是latin1,即Character_set_client 為Latin1,那么存儲到數據庫中的文字信息就會變成亂碼。
(2)假設服務器端向客戶端發送了latin1 編碼數據,但是客戶端的編碼形式為UTF-8,那么現實在web 頁面上的中文信息也是亂碼。
以上兩種情況如表2 所示。
解決方法:將服務器端的Character_set_connection、Character_set_client、Character_set_results 三個系統變量的值設置為web 客戶端的字符集utf-8 即可解決亂碼問題。一可采用相關命令進行更改,最直接的方法是找到配置文件my.ini 進行如下修改:

4.3 不能存儲emoji表情
Emoji 是時下比較流行的表情符號,也數據一種數據。可保存在MySQL 數據庫中,在存儲時若操作不當會出現incorrect string value 這個錯誤。這是因為emoji 表情是4 個字節的,而大家普遍認為utf-8 就是萬能的字符集了,在筆者遇到這個問題時也是一直這么認為的,直到遇到emoji 表情。很明顯3 個字節的utf-8 不能容納4 個字節的emoji 表情。這個時候MySQL 數據庫為了解決這個問題,在5.3 版本之后新增了一個utf-8 字符集編碼utf8mb4 編碼,之前編碼一直是utf8 編碼,utf8mb4 是utf8 的超級,占4 個字節,能夠向下兼容utf8。
解決方法:
(1)修改三級編碼。
①修改數據庫編碼:ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
②修改數據表編碼:ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
③修改表字段編碼:ALTER TABLE table_name CHANGE column_name VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
(2)修改my.ini 配置文件。

MySQL 作為全世界最受歡迎的開源數據庫平臺,擁有越來越多的編程愛好者,在中文環境下編程的用戶越來多,而使用過程中出現亂碼或者數據不能存儲的問題進行了研究,經過反復操作實驗,提出了具體的解決方案。
