基于概率矩陣分解的組推薦系統(tǒng)研究
2020-02-03 05:48:20宋玉龍馬文明劉彤彤
電子技術(shù)與軟件工程 2020年11期
宋玉龍 馬文明 劉彤彤
(煙臺(tái)大學(xué) 山東省煙臺(tái)市 264005)
1 引言
近些年,互聯(lián)網(wǎng)技術(shù)的不斷發(fā)展,讓人們可以很容易地獲取大量的各種信息。隨之造成的是信息爆炸與過(guò)載,這讓我們很難從海量的信息里面獲取自己真正想得到的部分。為了緩解這些窘?jīng)r,推薦系統(tǒng)通過(guò)對(duì)海量數(shù)據(jù)的分析,為用戶選擇合適的推薦物品,提供個(gè)性化的推薦結(jié)果,此類(lèi)方法通常可以滿足許多用戶的推薦需求。又由于實(shí)際生活中存在大量由多個(gè)用戶組成的群組參與的活動(dòng)(如健身房給鍛煉的用戶進(jìn)行的音樂(lè)廣播或給一個(gè)家庭推薦一部電影),這些活動(dòng)往往更偏向一個(gè)權(quán)威的人或者算法對(duì)群組進(jìn)行指導(dǎo),這就需要面向群組的個(gè)性化推薦,組推薦系統(tǒng)于是應(yīng)運(yùn)而生。
2 相關(guān)工作
組推薦系統(tǒng)的面向受眾是由多個(gè)用戶組成的一個(gè)個(gè)群組,與傳統(tǒng)推薦相比會(huì)考慮到更多的影響因素,其中一個(gè)關(guān)鍵部分是對(duì)群組中的成員融合策略。融合策略通常可以分為用戶偏好融合和推薦結(jié)果融合。用戶偏好融合是指將組內(nèi)用戶的偏好模型融合成為一個(gè)群組模型,根據(jù)結(jié)果模型獲得群組對(duì)物品的評(píng)分或者推薦列表。推薦結(jié)果融合是指給組內(nèi)所有成員分別進(jìn)行推薦,將他們的推薦評(píng)分或者列表進(jìn)行合并,獲得該組對(duì)物品的推薦結(jié)果。
2.1 偏好融合策略
表1 列舉了組推薦系統(tǒng)中常見(jiàn)的5 種評(píng)分融合策略。其中較為常用的是平均值策略和最小痛苦策略。
2.2 概率矩陣分解
Salakhutdinov R 在零八年提出概率矩陣分解算法(Probabilistic Matrix Factorization),是近些年比較流行的推薦算法。假設(shè)有N個(gè)用戶和M 個(gè)物品,對(duì)應(yīng)的評(píng)分可以形成一個(gè)M×N 矩陣R,Rij表示用戶i 對(duì)物品j 的評(píng)分。通常R 非常稀疏,只有很少的元素是已知的,而我們要估計(jì)出缺失元素的值。

圖1:PMF 的概率模型圖
傳統(tǒng)矩陣分解將矩陣RM×N分解為兩個(gè)維度更低的矩陣的乘積其中K 表示潛在向量的維度。通過(guò)不斷學(xué)習(xí)迭代來(lái)使逼近評(píng)分矩陣RM×N,同時(shí)也將得到未評(píng)分項(xiàng)目的預(yù)測(cè)評(píng)分。
概率矩陣分解假設(shè)由用戶偏好向量和物品潛在向量的內(nèi)積來(lái)決定評(píng)分矩陣R,且評(píng)分服從高斯分布,即:

其中N 表示高斯分布。概率模型圖如圖1 所示。
則觀察到的評(píng)分矩陣的條件概率為:
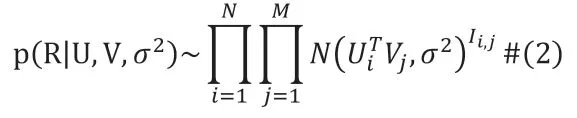

表1:組推薦系統(tǒng)常見(jiàn)融合策略
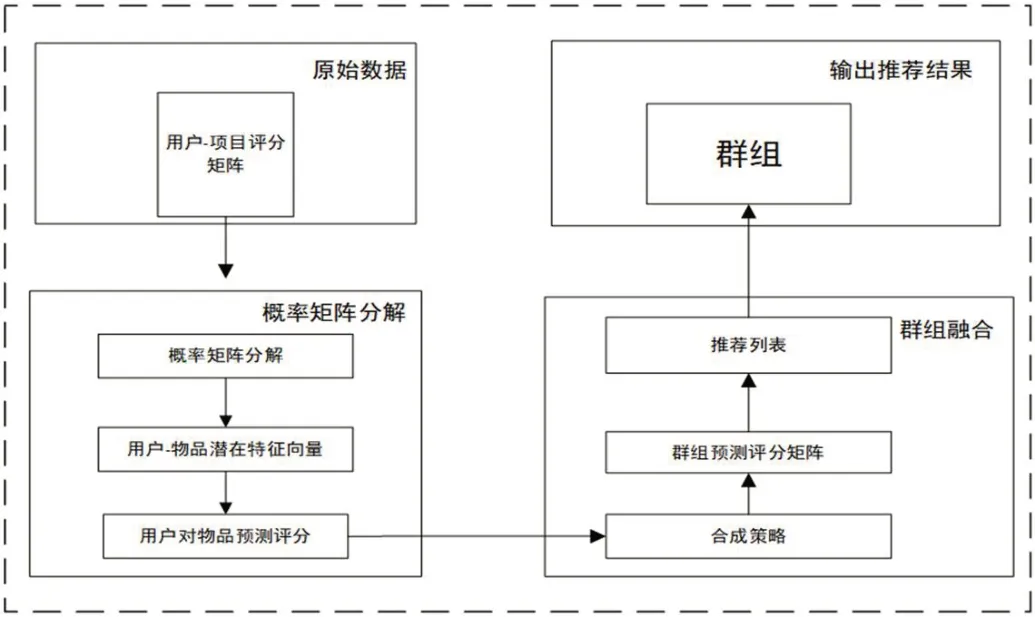
圖2:基于概率矩陣分解的群組推薦方法框架
Ii,j為指示函數(shù),如果用戶i 已對(duì)物品j 進(jìn)行了評(píng)分,則為1,否則為0。
再假設(shè)用戶潛在特征向量和物品的潛在特征向量都服從均值為0 的高斯先驗(yàn)分布,即:

其中的I 不是指示函數(shù),表示一個(gè)對(duì)角陣。
然后計(jì)算U 和V 的后驗(yàn)概率為:

兩邊取對(duì)數(shù)得到:
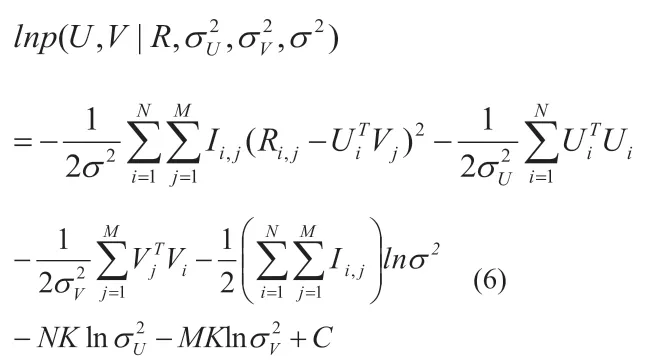
其中K 是潛在變量的維度,C 是無(wú)關(guān)常數(shù)。
于是我們可以通過(guò)最小化以下目標(biāo)函數(shù)來(lái)最大化后驗(yàn)概率:
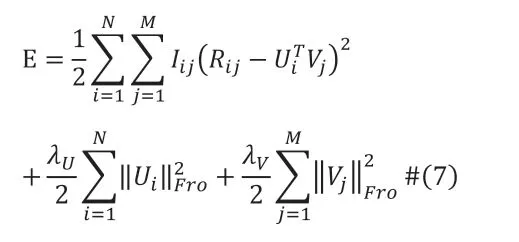

然后用隨機(jī)梯度下降法(SGD)更新Ui和Vj:
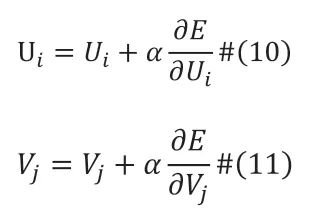
直到收斂或到達(dá)最大迭代次數(shù)。
3 群組推薦系統(tǒng)設(shè)計(jì)
本文提出的方法框架如圖2 所示。
根據(jù)圖2 可以看出,本文所用框架主要包括以下步驟:
獲取用戶-項(xiàng)目評(píng)分矩陣,進(jìn)行概率矩陣分解,得到用戶對(duì)未評(píng)分項(xiàng)目的預(yù)測(cè)評(píng)分。
(2)將用戶的預(yù)測(cè)評(píng)分用恰當(dāng)?shù)娜诤喜呗赃M(jìn)行融合,獲得該群組的評(píng)分。根據(jù)評(píng)分生成給該群組的推薦列表。
以上,基于概率矩陣分解的組推薦系統(tǒng),輸入數(shù)據(jù)為每個(gè)用戶的評(píng)分,輸出每個(gè)群組的推薦列表。
4 結(jié)束語(yǔ)
隨著以多個(gè)用戶組成的群體為單位的活動(dòng)不斷增多,傳統(tǒng)推薦方興未艾,漸漸滲入到千家萬(wàn)戶,成為日常生活中不可缺少的一部分。群組推薦也開(kāi)始逐漸得到越來(lái)越多的關(guān)注,給我們帶來(lái)了更多的機(jī)遇和挑戰(zhàn)。
傳統(tǒng)的協(xié)同過(guò)濾方法能夠共用大眾經(jīng)驗(yàn)過(guò)濾機(jī)器難以識(shí)別的信息,但在面對(duì)體積過(guò)大的數(shù)據(jù)量與評(píng)分太稀疏的矩陣時(shí)都顯得有心無(wú)力。而概率矩陣分解算法在大型、稀疏、不平衡的數(shù)據(jù)集上都有很不錯(cuò)的表現(xiàn),能夠提高個(gè)性化推薦的效率。我們未來(lái)可以嘗試在概率矩陣分解中融入用戶間的社交信息,期望進(jìn)一步提高系統(tǒng)性能。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學(xué)生作文(低年級(jí)適用)(2019年9期)2019-10-08 08:37:10
數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
商用汽車(chē)(2016年11期)2016-12-19 01:20:16
商用汽車(chē)(2016年6期)2016-06-29 09:18:54
商用汽車(chē)(2016年4期)2016-05-09 01:23:12
