多匹配器自動聚合的知識圖譜融合系統(tǒng)構(gòu)建
2020-01-06 08:01:20
中華醫(yī)學(xué)圖書情報(bào)雜志 2019年9期
作為一種新型、實(shí)用的知識組織工具,知識圖譜旨在描述真實(shí)世界中的各種實(shí)體、概念及其關(guān)系,已廣泛應(yīng)用于互聯(lián)網(wǎng)搜素引擎、電子商務(wù)等方面。它在實(shí)現(xiàn)海量信息資源的深度挖掘、廣泛融合、理解利用方面發(fā)揮了重要作用。知識圖譜本質(zhì)是一種基于圖數(shù)據(jù)結(jié)構(gòu)的語義網(wǎng)絡(luò),由節(jié)點(diǎn)和邊組成,節(jié)點(diǎn)表示現(xiàn)實(shí)世界的實(shí)體,邊表示實(shí)體與實(shí)體之間的語義關(guān)系。
隨著各領(lǐng)域圖譜數(shù)量的不斷增加,解決概念體系異構(gòu)、消除知識實(shí)體之間的互操作障礙已成為圖譜應(yīng)用面臨的關(guān)鍵問題。圖譜匹配技術(shù)旨在建立概念體系和知識實(shí)體之間的語義關(guān)系,架起異構(gòu)圖譜間的橋梁。由于圖譜異構(gòu)類型的復(fù)雜性和多樣性,以及單匹配技術(shù)的局限性,知識圖譜融合系統(tǒng)需要組合多種匹配方法才能具有較好的通用性和較為理想的映射結(jié)果。如何有效聚合不同匹配器得出的相似度值是圖譜融合亟待解決的問題,是制約多匹配器融合算法自動化的瓶頸。
本文首先通過調(diào)研、比較分析幾個典型的知識融合系統(tǒng),總結(jié)知識圖譜融合框架,并將其作為系統(tǒng)設(shè)計(jì)的參考模型;然后重點(diǎn)研究多匹配器的自動優(yōu)化、聚合器的自適應(yīng)聚合參數(shù)調(diào)節(jié)等核心組件的設(shè)計(jì),減少在映射參數(shù)設(shè)置上的人工干預(yù),提高融合系統(tǒng)的自動化程度。在這些工作的基礎(chǔ)上構(gòu)建一種基于多匹配器自適應(yīng)聚合的知識圖譜融合系統(tǒng)原型,并進(jìn)行初步實(shí)驗(yàn)。
1 知識圖譜融合研究現(xiàn)狀
知識圖譜融合的任務(wù)是對不同來源、不同結(jié)構(gòu)的知識或知識片段進(jìn)行融合。通過對多個相關(guān)知識圖譜的對齊、關(guān)聯(lián)和合并,從而對已有知識進(jìn)行補(bǔ)充、更新和去重,使其成為一個有機(jī)整體,以提供更全面知識的共享[1]。知識融合需要解決概念體系的融合和知識實(shí)體的融合兩個問題。
概念體系的融合是兩個或多個異構(gòu)概念體系的融合,是對概念、屬性、關(guān)系等知識描述體系進(jìn)行映射和融合,可以解決知識體系之間的異構(gòu)性,也稱為本體對齊[2]。知識實(shí)體級別的融合即實(shí)體對齊,是對兩個不同知識圖譜中的實(shí)體(實(shí)體本身、屬性等)進(jìn)行融合。實(shí)體對齊的核心是計(jì)算兩個知識圖譜中節(jié)點(diǎn)或邊之間的語義關(guān)系,主要通過實(shí)體名稱及屬性相似度映射的方式。目前知識融合普遍的做法是通過相似度計(jì)算(如基于字符串、詞典、詞向量、結(jié)構(gòu)信息以及混合方法等),對于大于指定相似度閾值的候選對,會提示用戶進(jìn)行干預(yù)或編輯確認(rèn),從而實(shí)現(xiàn)知識圖譜的融合。如YAGO將Wikipedia中的類別標(biāo)簽與WordNet的同義詞集進(jìn)行關(guān)聯(lián),同時將Wikipedia中的條目掛接到WordNet的概念體系下,使WordNet能提供較高層的概念體系,使Wikipedia可提供具體的實(shí)例信息[3]。
AgreementMakerLight(AML)[4]是一種可擴(kuò)展的自動化知識融合框架,主要針對大規(guī)模的生物醫(yī)學(xué)領(lǐng)域知識的對齊問題,是AgreementMaker[5]的升級版。AML實(shí)現(xiàn)了基于字符特征(編輯距離、最長公共字符串等)或利用背景知識庫的多種匹配器,并根據(jù)映射效率的不同將其組合為主要匹配器和次要匹配器兩類,用于不同需求的融合場景。最后通過過濾器剔出低于給定相似性閾值以及相互沖突的候選對,從而得到最終期望的對齊結(jié)果。
WikiMatch[6]是一個將Wikipedia作為外部背景知識庫的融合系統(tǒng),通過維基百科搜索引擎提取每個知識節(jié)點(diǎn)在維基中的片段、標(biāo)簽和注釋,知識節(jié)點(diǎn)之間的相似度就轉(zhuǎn)化為對應(yīng)維基片段、標(biāo)簽和注釋的相似度計(jì)算。由于維基百科文章存在多語言版本,并且這些文章彼此是相互鏈接的,因此WikiMatch解決了跨語言知識的融合問題。
S-Match[7]是用于匹配輕量級知識庫的開源融合框架,實(shí)現(xiàn)了多個語義匹配器,同時提供多種接口,能夠添加自定義背景知識。S-Match的匹配器分為元素級匹配器和結(jié)構(gòu)級匹配器兩類。映射結(jié)果通過預(yù)定義的冗余結(jié)果過濾器進(jìn)行過濾和選擇。
SiGMa[8]是一種使用迭代傳播的大規(guī)模知識庫實(shí)體對齊系統(tǒng),利用關(guān)系圖中的結(jié)構(gòu)信息及貪婪搜索方式計(jì)算實(shí)體屬性之間的相似性,以解決大規(guī)模的知識對齊問題。SiGMa充分利用了實(shí)體屬性定義的相似度和實(shí)體周圍節(jié)點(diǎn)的信息。
2 知識圖譜融合框架設(shè)計(jì)
筆者以上述4個知識融合系統(tǒng)為代表,詳細(xì)剖析了這些系統(tǒng)的組成、融合過程及特點(diǎn),提出了一種知識圖譜融合系統(tǒng)框架(圖1)。

圖1 知識圖譜融合系統(tǒng)框架
知識圖譜融合系統(tǒng)一般由6部分組成,各部分通過預(yù)先定義的接口完成數(shù)據(jù)傳遞。
預(yù)處理器:待匹配知識圖譜導(dǎo)入系統(tǒng)后,進(jìn)行知識節(jié)點(diǎn)(概念節(jié)點(diǎn)、實(shí)體節(jié)點(diǎn))及特征屬性的提取。
匹配策略選擇器:通過用戶交互或者特征分析,選擇與組合合適的匹配策略,其實(shí)質(zhì)是不同匹配器的選擇與組合。
匹配器:是知識圖譜融合系統(tǒng)的核心部分。本文將執(zhí)行知識節(jié)點(diǎn)相似度計(jì)算的簡單匹配器稱為原子匹配器,將綜合使用多種匹配算法的匹配器稱為混合匹配器。
聚合器:通過某種數(shù)學(xué)方法或規(guī)則將多個匹配器計(jì)算的相似度結(jié)果值整合為單一相似度的過程。
結(jié)果優(yōu)化器:根據(jù)預(yù)先設(shè)定的優(yōu)化規(guī)則篩查不正確的映射關(guān)系或低于某一閾值的映射關(guān)系,進(jìn)行最終結(jié)果的確認(rèn)。
用戶交互器:實(shí)現(xiàn)知識圖譜的輸入與輸出,以及結(jié)果的確認(rèn)和保存等多項(xiàng)功能。
3 多匹配器自動聚合算法設(shè)計(jì)
3.1 多匹配器設(shè)計(jì)
單個匹配技術(shù)自身的局限性以及圖譜異構(gòu)類型的復(fù)雜性和多樣性,決定了不會存在某種匹配技術(shù)適用于所有異構(gòu)的圖譜資源,并能夠有效解決各種映射問題。知識圖譜融合系統(tǒng)需要組合多種匹配方法,才能具有較好的通用性和較為理想的映射結(jié)果。本文設(shè)計(jì)了Edit-WordNet、I-sub和Context(語境)3個單獨(dú)運(yùn)行的匹配器。
3.1.1 Edit-WordNet匹配器設(shè)計(jì)
基于計(jì)算編輯距離的相似度能夠發(fā)現(xiàn)知識節(jié)點(diǎn)詞形特征的相似性,而基于WordNet的相似度能夠發(fā)掘其語義上的相似性。由于側(cè)重點(diǎn)不同,本文設(shè)計(jì)的Edit-WordNet混合匹配器可以互補(bǔ)兩者的優(yōu)勢。
定義1:編輯距離相似度算法的計(jì)算公式為:
(1)
式中,max(|s1|,|s2|)指較長詞條的字母數(shù)目,LD(s1,s2)表示詞條s1、s2之間的編輯距離。
定義2:基于WordNet相似度算法公式為:
Sim(s,t)=2×depth(c)/[depth(s)+depth(t)]=2×depth(c)/[2×depth(c)+n1+n2]
(2)
該公式是Wu Zhibiao和Palmer Martha[9]提出的算法,使用知識節(jié)點(diǎn)間的“IS-A”關(guān)系來尋找兩個概念s和t的最近公共上位詞c,最近公共上位詞c是與概念詞s和t間以最少的“IS-A”關(guān)系邊相關(guān)聯(lián)的公共上位詞。公式2中,n1和n2分別表示概念詞s、t與最近公共上位詞c間的最短相對路徑長度。Edit-WordNet算法的主要實(shí)現(xiàn)步驟如下。
第一步:分別建立源圖譜和目標(biāo)圖譜所有單詞符號的上位(is-a)關(guān)系矩陣word_1[m][wordPOS.Length](m為源圖譜知識節(jié)點(diǎn)數(shù)組KGSource[]長度)和word_2[n][wordPOS.Length]。其中,行是知識節(jié)點(diǎn)預(yù)處理后的單詞符號,列為詞性。上位關(guān)系矩陣用于保存單詞符號在某一詞性下(名詞、動詞)的所有synset節(jié)點(diǎn)到獨(dú)立起始概念(沒有上位概念的節(jié)點(diǎn))的路徑節(jié)點(diǎn)的信息,包括上位關(guān)系節(jié)點(diǎn)的名稱、相對于該synset節(jié)點(diǎn)的相對路徑長度、路徑深度等。
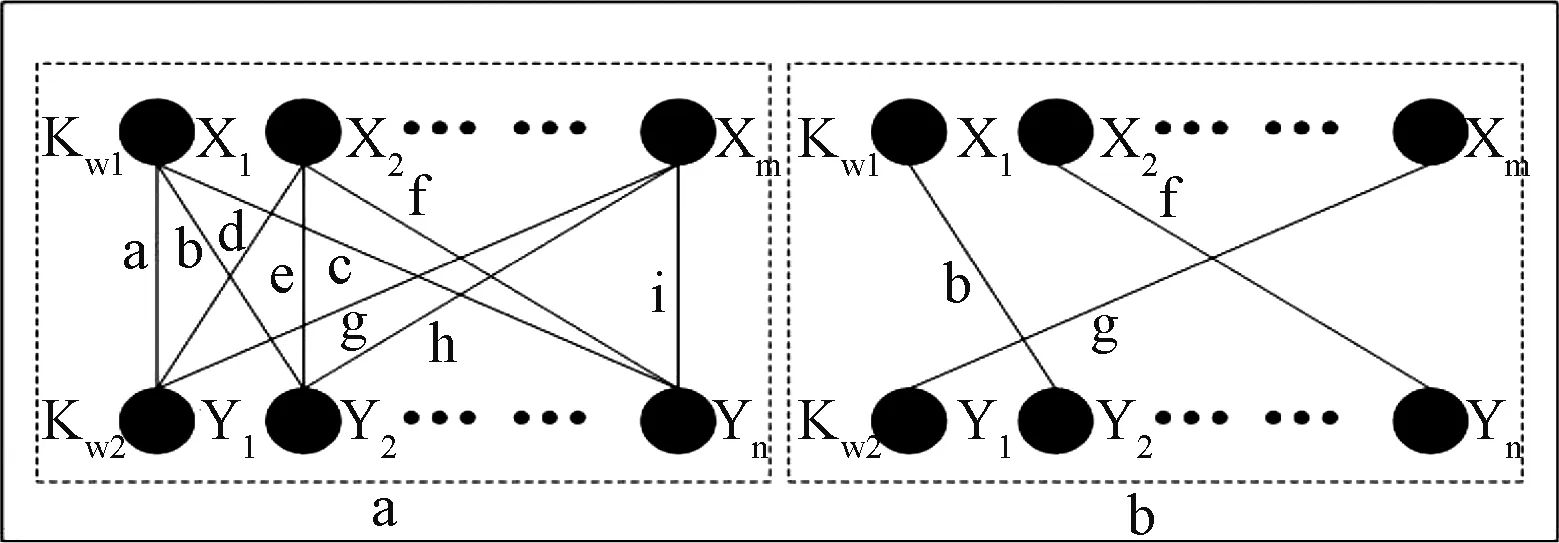
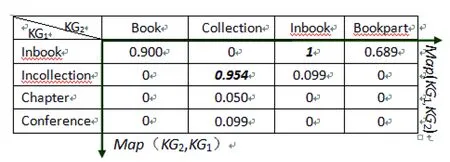
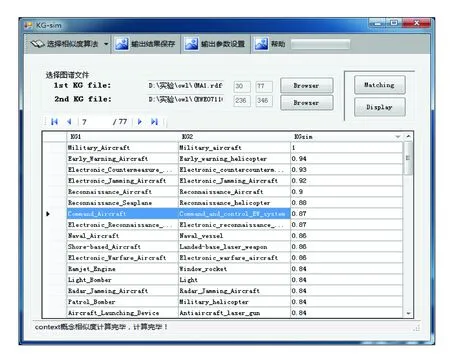
第二步:計(jì)算單詞符號之間的相似度:
for(int i=0;i for(int j=0;j { float synDist=LDsim(KGSource[i],KGTarget[j]);//調(diào)用編輯距離相似度 ①令semDist=Math.Max(Sim(word_1[i][noun],word_2[j][noun]),……,Sim(word_1[i][adverb],word_2[j][adverb]))。其中Sim()的計(jì)算方法是根據(jù)上位關(guān)系矩陣中的節(jié)點(diǎn)名稱和路徑等信息,循環(huán)查找其最近的公共上位詞,通過公式1計(jì)算相似度; ②simMatrix[i][j]=Math.Max(semDist,synDist); //對完整度的考慮 } 第三步:歸一化相似度矩陣,通過公式SimWordNet=(sumSim_i+sumSim_j)/(m+n)得到最終相似度值。其中sumSim_i為行最大值之和,sumSim_j為列最大值之和。 3.1.2 I-sub匹配器設(shè)計(jì) I-Sub算法是希臘雅典理工大學(xué)的Giorgos Stoilos等人從術(shù)語學(xué)的角度提出的術(shù)語映射方法。與同類算法比較,I-Sub具有更好的魯棒性。這種方法計(jì)算的相似度由3部分組成: sim(s1,s2)=comm(s1,s2)-diff(s1,s2)+winkler(s1,s2) 其中,comm(s1,s2)代表兩個字符串的相同點(diǎn),diff(s1,s2)代表兩個字符串的不同點(diǎn),winkler(s1,s2)是由winkler提出的一種改善相似度結(jié)果的算法[10]。 3.1.3 Context(語境)匹配器設(shè)計(jì) Context(語境)匹配器的主要思想是利用知識節(jié)點(diǎn)周圍的多種描述數(shù)據(jù)為每一個節(jié)點(diǎn)建立一個語境的描述,然后通過向量空間模型方法計(jì)算語境之間的相似度,從而得到知識節(jié)點(diǎn)之間的相似度。 知識節(jié)點(diǎn)語境由結(jié)構(gòu)面、屬性面等分面語境構(gòu)成。結(jié)構(gòu)面語境由知識節(jié)點(diǎn)本身的定義信息(名稱、標(biāo)簽、注釋)及其所有上位概念、下位概念和同位概念信息構(gòu)成,用ConS表示;屬性面語境由概念屬性的集合及其屬性的注釋、限制(定義域、值域)等信息構(gòu)成,用ConA表示;實(shí)例面語境由概念的實(shí)例集合構(gòu)成,由ConI表示。結(jié)合上述定義,知識節(jié)點(diǎn)cn的語境ConC(cn)可表示為{ConS(cn),ConA(cn),ConI(cn)}。圖2所示的書目概念圖譜,Book的語境可以粗略表示為:ConC(Book)={ConS(Book),ConA(Book),ConI(Book)}={ Book,book,monograph,collection,written,texts,Entry,Monography,Compilation,Conrerence,Minutes,heading,volume,issue,publishedBy}。 圖2 書目概念圖譜片段 基于知識節(jié)點(diǎn)語境的相似度算法重點(diǎn)在于通過語境建立向量空間模型,通過計(jì)算向量之間的相似度(如向量的內(nèi)積)計(jì)算知識節(jié)點(diǎn)之間的相似度。核心算法如下。 第一步:逐一計(jì)算每個關(guān)鍵詞在每個知識節(jié)點(diǎn)語境中的權(quán)重值。 for(int i=0;i<關(guān)鍵詞個數(shù)numTerms;i++) for(int j=0;j<概念語境的個數(shù)numDocs;j++) { 關(guān)鍵詞i在語境j中出現(xiàn)的頻率freq=termFreq[i][j]; 語境j中所有關(guān)鍵詞出現(xiàn)次數(shù)最大值maxfreq=maxTermFreq[j]; 計(jì)算文檔頻率tf=freq/maxfreq; 語境空間中含有關(guān)鍵詞i的語境數(shù)目df=docFreq[i]; 計(jì)算逆文檔頻率idf=Log(numDocs/df); 計(jì)算關(guān)鍵詞i在語境j中的權(quán)重值termWeight[i][j]=tf×idf; } 第二步:計(jì)算每對知識節(jié)點(diǎn)基于語境的相似度值。 for(i=0;i for(j=m;l { 通過termWeight矩陣,生成權(quán)重向量vector(i),vector(j); sim(vector(i),vector(j))=(vector(i)·vector(j))/|vector(i)|×|vector(j)| } 單獨(dú)匹配器在圖譜映射的計(jì)算過程中,需考慮每一對知識節(jié)點(diǎn)之間的相似性。假設(shè)源KG1中含有m個元素,目標(biāo)KG2中含有n個元素,則要進(jìn)行m×n次相似度計(jì)算,形成一個m×n維的相似度矩陣。對于1∶1映射,現(xiàn)有的映射方法大多從相似度矩陣中依次挑選出一一對應(yīng)的、具有高相似性的元素對作為候選映射。因此對于該m×n維的矩陣來說,存在大量毫無意義的相似度值只會增加后續(xù)(如相似度合并)運(yùn)算的復(fù)雜程度,有必要對匹配基數(shù)為1∶1的映射采用優(yōu)化策略,對相似度矩陣的規(guī)模進(jìn)行調(diào)節(jié)。 受Similarity Flooding和AgreementMaker系統(tǒng)的啟發(fā),將這個問題轉(zhuǎn)化為一個最優(yōu)化分配問題。筆者利用帶權(quán)二分圖的思想將匹配器的計(jì)算過程做如下建模:定義源圖譜1的所有元素為集合X={x1,x2,…,xm},目標(biāo)圖譜2的所有元素為集合Y={y1,y2,…,yn},然后把兩個集合元素對之間所有可能的m×n個映射關(guān)系表示為邊集E,各個元素對的相似度值為邊集E的權(quán)重值wij,將其處理后生成一個帶權(quán)的完全二分圖,計(jì)算出該完全二分圖的最大權(quán)匹配,其邊集所對應(yīng)的頂點(diǎn)元素對集合就是匹配器輸出的最優(yōu)候選映射對(圖3)。可以采用如匈牙利方法和最短增強(qiáng)路徑算法來解決算法設(shè)計(jì)問題,此處不再贅述。本文對上述3個匹配器進(jìn)行了二分圖的優(yōu)化,并作為下文中聚合器的輸入。 圖3 二分圖最大權(quán)優(yōu)化示意 聚合器旨在組合多個匹配器的映射結(jié)果,如何有效聚合不同匹配器得出的相似度值是制約多匹配器匹配算法的瓶頸。從具體實(shí)現(xiàn)上來看,基于函數(shù)聚合相似度的方法簡單易實(shí)現(xiàn)、易于理解、合并效率較高。然而在這些系統(tǒng)的具體權(quán)重值的設(shè)定方面,要么通過事前驗(yàn)算和模擬實(shí)驗(yàn)探索比較合理和滿意的經(jīng)驗(yàn)值參數(shù),要么通過用戶交互接口將權(quán)重設(shè)置權(quán)限交給用戶。這些做法無法根據(jù)不同的映射任務(wù)而靈活調(diào)整權(quán)重,盲目的聚合往往會削弱有效匹配器的映射效能,嚴(yán)重影響映射的發(fā)現(xiàn)。自動聚合的關(guān)鍵是能夠根據(jù)不同的融合場景自動設(shè)置各個匹配器的權(quán)重,而權(quán)重值的大小與其匹配質(zhì)量正相關(guān)。 理論上講,正確的等同關(guān)系映射應(yīng)該是從KG1到KG2的映射與KG2到KG1的映射所產(chǎn)生的映射關(guān)系一致,即在這兩個映射方向上計(jì)算的相似度值與其他候選元素對相比都是最高的(所在矩陣的行和列均為最大值)。筆者將這種映射關(guān)系稱為穩(wěn)定映射(Stable Match,SM),因此可以將穩(wěn)定映射的數(shù)量作為相似度聚合前粗略測度不同匹配器適用性大小的一個指標(biāo)。也就是說,哪種匹配算法得到的穩(wěn)定映射關(guān)系越多,就說明其適用性越好,在聚合的時候賦予的權(quán)重值就應(yīng)當(dāng)越高。 圖4是一個基于I-sub算法的相似度矩陣。圖中的加粗斜體數(shù)值表示2個映射方向均為最高的相似度值,因此產(chǎn)生了2個穩(wěn)定映射關(guān)系(“Inbook”,“Inbook”)和(“Incollection”,“Collection”);而(“Inbook”,“Book”)不是穩(wěn)定的,因?yàn)樵贙G1到KG2方向上不是最大值。 經(jīng)過上述步驟,我們將匹配器i的權(quán)重值定義為: 式中,counti(CM)表示匹配器i產(chǎn)生的穩(wěn)定映射關(guān)系的個數(shù),Sum(count(CM))表示所有匹配器產(chǎn)生的穩(wěn)定映射關(guān)系個數(shù)之和,由此得到的聚合器計(jì)算公式為: (3) 根據(jù)上述單獨(dú)匹配器的設(shè)計(jì)及優(yōu)化后的結(jié)果,將各個單獨(dú)匹配器產(chǎn)生的最優(yōu)候選映射對作為聚合器的輸入,然后將3組最優(yōu)候選映射的所有源圖譜節(jié)點(diǎn)元素重新組合為集合X′,目標(biāo)圖譜元素組合為Y′,最后將最優(yōu)候選映射對根據(jù)公式(3)進(jìn)行多相似度值的結(jié)果聚合,生成一個新的m′×n′的相似度矩陣。該矩陣可以進(jìn)一步通過二分圖優(yōu)化或通過閾值策略作為最終結(jié)果的輸出。 根據(jù)算法設(shè)計(jì)和分析初步構(gòu)建了實(shí)驗(yàn)原型系統(tǒng)。該系統(tǒng)運(yùn)行界面如圖5所示。為了驗(yàn)證算法的可行性,我們選用單位自建的飛機(jī)(KG1,77個知識節(jié)點(diǎn))與電子對抗裝備(KG2,346個知識節(jié)點(diǎn))2個領(lǐng)域的知識片段進(jìn)行了實(shí)驗(yàn)。由于系統(tǒng)采用1∶1的完全二分圖最大權(quán)匹配輸出,所以共產(chǎn)生了77對結(jié)果集。通過分析發(fā)現(xiàn),等同和包含關(guān)系的映射對集中于閾值>0.85的范圍內(nèi)(見表1,其中僅第9、第10兩個不相關(guān)),除了字形特征完全相同的所有映射對被發(fā)現(xiàn)外,通過Context或Edit-WordNet匹配器還發(fā)現(xiàn)了(Early_Warning_Aircraft,Early_warning_helicopter)等映射對。實(shí)驗(yàn)初步證明,該系統(tǒng)能夠較為有效地發(fā)現(xiàn)相關(guān)知識節(jié)點(diǎn)。 圖4基于雙向映射計(jì)算穩(wěn)定映射關(guān)系示例 圖5 實(shí)驗(yàn)原型系統(tǒng)運(yùn)行界面 表1 實(shí)驗(yàn)結(jié)果 本文的主要研究目的是設(shè)計(jì)一個自調(diào)節(jié)映射參數(shù)的知識圖譜融合算法,實(shí)現(xiàn)多匹配器的自動優(yōu)化、聚合參數(shù)的自動調(diào)節(jié)以及映射結(jié)果的自動輸出,并在此基礎(chǔ)上構(gòu)建了一個工具原型和進(jìn)行了初步實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果初步驗(yàn)證了融合算法在無人工干預(yù)的情況下能夠有效發(fā)現(xiàn)語義相關(guān)的知識節(jié)點(diǎn),為未來系統(tǒng)的構(gòu)建奠定了基礎(chǔ)。 由于受時間和條件的限制,本文研究仍存在以下一些問題,有待今后進(jìn)一步探討和解決。需進(jìn)一步研究結(jié)果修正方法,即擬針對單獨(dú)匹配器引入最小閾值參數(shù),排除不可能的映射對,進(jìn)一步提高算法的準(zhǔn)確性。最小閾值將通過大量實(shí)驗(yàn)進(jìn)行選擇。 鑒于WordNet語義相似度算法的缺陷,如何對多義詞進(jìn)行語義消歧、取出元素synset的正確位序是未來WordNet語義相似度算法改進(jìn)的重點(diǎn)。此外,圖匹配理論和結(jié)構(gòu)相似性傳播理論是多數(shù)先進(jìn)知識融合系統(tǒng)普遍采用的方法,今后將在后續(xù)版本中加以考慮。 實(shí)驗(yàn)結(jié)果有一定的局限性,下一步擬擴(kuò)大實(shí)驗(yàn)數(shù)據(jù)范圍,并采用多種性能評測標(biāo)準(zhǔn)進(jìn)行測試,為系統(tǒng)的進(jìn)一步優(yōu)化與改進(jìn)提供依據(jù)。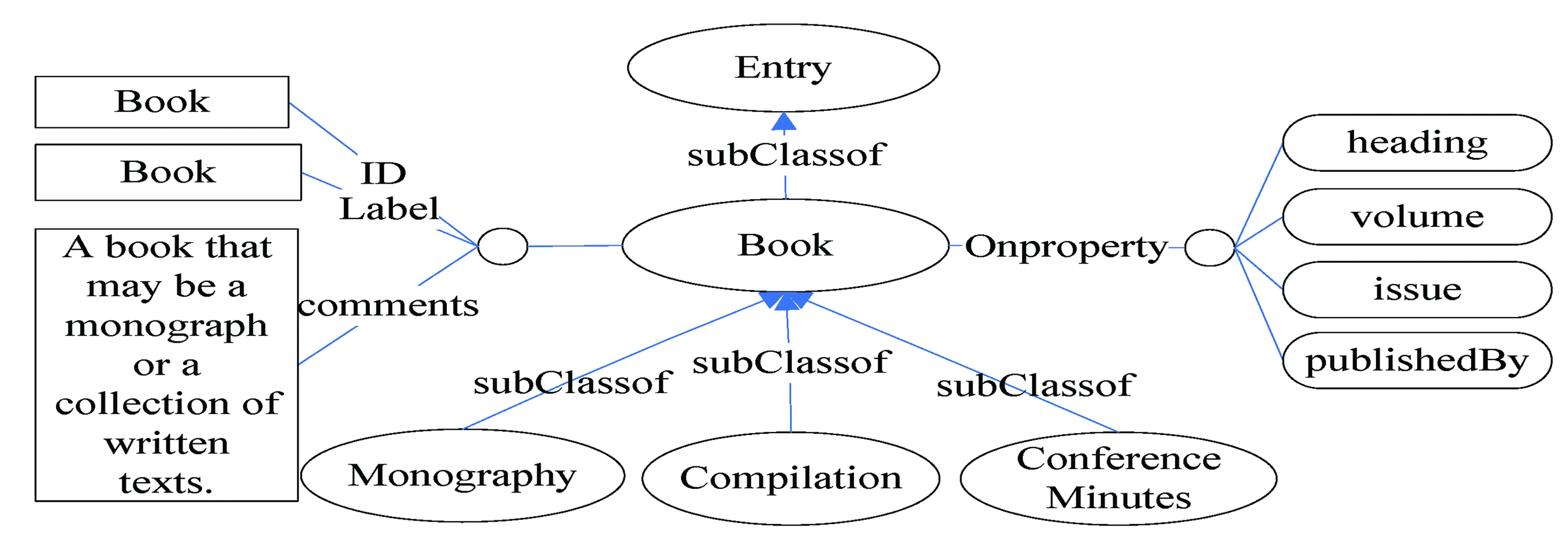
3.2 匹配器優(yōu)化設(shè)計(jì)
3.3 自適應(yīng)的聚合器設(shè)計(jì)
4 原型系統(tǒng)構(gòu)建和初步實(shí)驗(yàn)

5 總結(jié)與展望
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20現(xiàn)代裝飾(2022年1期)2022-04-19 13:47:32今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36中老年保健(2021年11期)2021-08-22 03:15:44中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30北京測繪(2020年12期)2020-12-29 01:33:58現(xiàn)代出版(2020年3期)2020-06-20 07:10:34現(xiàn)代裝飾(2020年2期)2020-03-03 13:37:44中學(xué)生數(shù)理化·高一版(2018年9期)2018-10-09 06:46:48
