404 Not Found
404 Not Found
基于FPGA動態重構的快速車牌識別系統*
訾 晶, 張旭欣, 金 婕
(上海工程技術大學 電子電氣工程學院,上海 201600)
0 引 言
在卷積神經網絡(convolutional neural network,CNN)出現之前,視頻圖像處理任務效果都不盡如人意,很難實現大規模的商業應用,直到2012年,Krizhevsky A等人提出了一種新的深度神經網絡模型AlexNet CNN[1],此后,更大更深的CNN模型被陸續提出,如GoogLeNet[2]。
CNN在計算機視覺領域的應用大都是在軟件平臺實現的,隨著硬件設備的更新迭代,計算能力的提升,使得在硬件平臺開發CNN成為了可能,尤其是現場可編程門陣列(field programmable gate array,FPGA)的快速發展[3]。
硬件加速網絡的設計側重于網絡并行化的實現,快速算法的應用等方面,但針對FPGA自身重構特性的研究較少。Kaestner F等人的研究[4]充分展現了FPGA部分重構的優勢,利用有限的硬件資源,通過部分重構實現卷積,采用軟硬件結合的實現形式,有效提高神經網絡執行速度。
本文將采用FPGA動態部分重構技術和高層次綜合工具,完成快速車牌識別的系統設計。設計CNN模型,利用Caffe深度學習框架訓練相關數據[5];按照動態部分重構(dynamic partial reconfiguration,DPR)實現流程[6],生成完整及部分比特流,完成CNN的兩種軟硬件方案設計;基于PYNQ-Z1開發板,完成車牌識別系統設計。
1 卷積神經網絡
針對車牌字符的特點,設計CNN模型。該網絡包含卷積層,修正線性單元(rectified linear unit,ReLU),最大池化層以及全連接層。結構信息如表1所示。
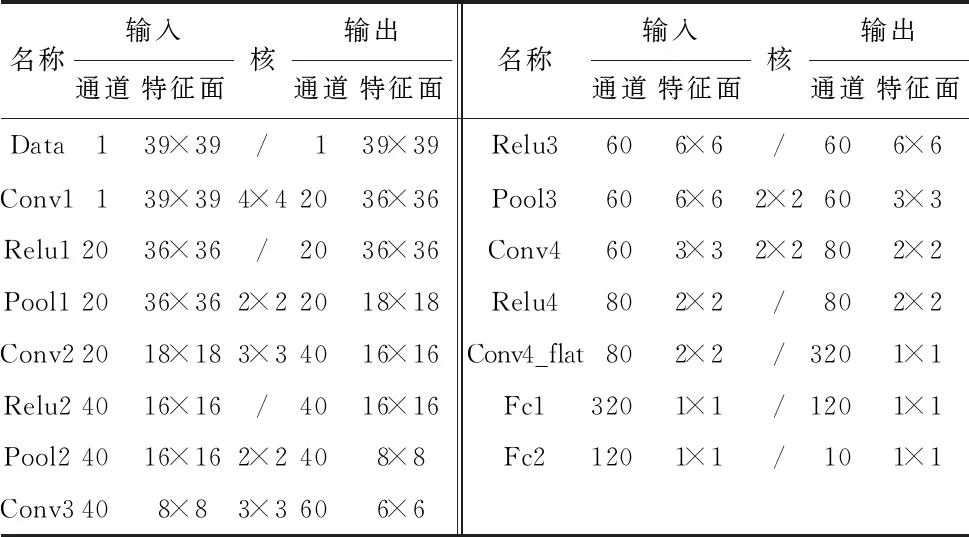
表1 CNN結構信息
卷積后加ReLU作為激活函數,一方面減少反向傳播(back propagation,BP)求誤差梯度的計算量,另一方面稀疏網絡,減少參數的相互依賴性,緩解過擬合;此外,最大池化層,壓縮了卷積后的特征面,提取主要特征,進一步簡化網絡計算復雜度。
2 車牌識別系統結構設計
2.1 系統結構
車牌識別系統的結構設計如圖1所示。在Xilinx PYNQ-Z1上實現FPGA的部分重構,開發板包含一個ZC7020芯片,該芯片有一個雙核ARM A9處理器,配備各種外圍設備,作為一個處理系統(processing system,PS);此外,還有一個可編程邏輯(programmable logic,PL)XC7Z020。異構FPGA本身內嵌了處理器,因此使得軟硬件設計更加靈活。
計算密集型且模塊化較強的部分,利用FPGA的PL實現,即所有硬件接口和部分卷積神經網絡模塊;圖片的預處理由PS實現。該系統優點是采用軟硬件結合的形式,以及FPGA的部分重構特性,對硬件資源重復利用,節省資源,提高識別效率。
2.2 硬件設計
該系統通過高清多媒體接口(high definition multimedia interface,HDMI)接收、輸出圖片,利用動態局部重配置(dynamic partial reconfiguration,DPR)技術,實現對CNN計算密集的卷積層重構,因此硬件設計主要包括HDMI接口調用以及卷積的重構。
HDMI是PYNQ-Z1上的外設,可以直接調用相關IP(即Overlay)和接口IP來驅動HDMI。所以硬件設計的重點即實現卷積的重構,包括卷積IP設計與優化。
2.2.1 卷積IP設計
CNN中最為密集的計算是卷積,利用FPGA來實現可以有效地提高卷積計算效率,并降低功耗。在FPGA上實現卷積,首先設計實現卷積的硬件電路并生成相應的IP,在片上系統(system on chip,SoC)設計時進行調用。
盡管使用Verilog語言進行RTL(register transfer level)級設計,效率更高,但對于網絡和FPGA器件來說,由于考慮到后期調整結構和充分發揮FPGA器件的靈活性需要,本文利用Xilinx Vivado HLS 2017.3軟件,采用高層次綜合(high-level synthesis,HLS)工具和C++作為設計語言,通過綜合自動產生RTL級電路,并生成IP,減少重復設計工作量并提高設計效率。
默認情況下,卷積的所有嵌套循環都是按順序執行的,在卷積過程中,Vivado HLS提供了不同的編譯指令(pragma)來影響循環調度和FPGA資源分配。用于優化的兩個最重要的指令是unrolling和pipelining[7],因此,根據每一層卷積的特點,以并行或流水線方式處理嵌套循環,優化IP。卷積的嵌套循環在整個輸入深度、高度和寬度上進行,還要考慮卷積的輸出深度以及卷積核,整個卷積有6層嵌套循環,可以對這些循環進行優化,然而性能的線性增長取決于硬件資源利用率,所以要在每個卷積層的資源利用和性能之間找到最佳的平衡點。
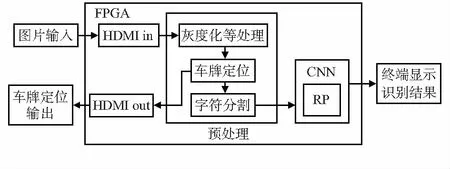
圖1 車牌識別系統模塊框圖
2.2.2 部分重構流程
FPGA的部分重構,在FPGA上開辟一塊可重構分區(reconfigurable partition,RP),重構RP邏輯,如圖2所示。
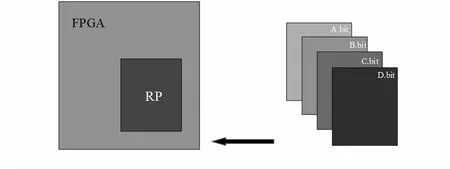
圖2 部分重構
FPGA設計中的邏輯分為可重構邏輯和靜態邏輯,圖2中FPGA的灰色區域表示靜態邏輯,RP部分表示可重構邏輯,通過加載幾個比特流(bitstream)中的一個來修改RP中的功能,完成部分重構,而靜態邏輯保持運行,不受部分比特流加載的影響。
本文針對4層卷積實現重構,因此要進行4次重構循環,生成4組可用的完整及部分比特流。
第一次循環,綜合后畫出RP,并設置重構屬性,優化、布局、布線后保存可共享靜態邏輯,供后續循環調用,同時第一次生成比特流;后續循環,替換卷積IP,綜合后只要將卷積部分的設計檢查點(design check point,DCP)加載到共享靜態邏輯,同樣優化、布局、布線后直接生成比特流。
2.3 軟件設計
軟件的設計主要是實現圖片的預處理,根據圖1所示,圖片預處理主要包括車牌定位及字符分割,這一部分通過軟件來設計。
首先,從HDMI幀緩沖區提取接收的圖片,調用OpenCV的圖像處理庫進行預處理,根據顏色先定位車牌的大致區域,在處理顏色信息時,須變換通道,車牌圖片是3通道的RGB圖,經過HDMI輸入FPGA后,變成GBR通道,而Opencv是BGR通道。之后,調用Opencv的輪廓提取函數,提取所有檢測到的輪廓,根據輪廓的長寬比及大小,篩選掉干擾輪廓。字符分割也利用輪廓提取的方式。
3 實 現
3.1 硬件實現
在Xilinx Vivado 2017.3軟件上,利用卷積IP以及其他一些必要IP和接口IP,完成SoC的塊設計(block design),即原理圖設計。主要包括1個AXI Interconnect IP和3個功能模塊:AXI Interconnect IP實現將一個或多個AXI(advanced extensible interface)存儲器映射的主器件連接到一個或多個存儲器映射的從器件;hdmi模塊實現圖片接收與輸出,并用VDMA(video direct memory access)IP作為幀緩沖區,緩存數據;proc模塊實現卷積操作;ps模塊包含兩個ARM A9的硬核,實現各IP初始化與配置。
Proc模塊中的卷積IP,在部分重構過程是可替換的,卷積IP每次替換后都需要復位,這里通過一個簡單的通用輸入/輸出(GPIO)IP來實現重構復位。此外,輸入到卷積IP的數據通過一個簡單的DMA(direct memory access)IP連接。
由于FPGA可重構區域的有限性,分配RP時要考慮最大區域限制和時序要求,RP區最多占用29 %BRAM,37 %DSP48E,36 %FF以及36 % LUT。RP和各卷積層的資源占用如表2。
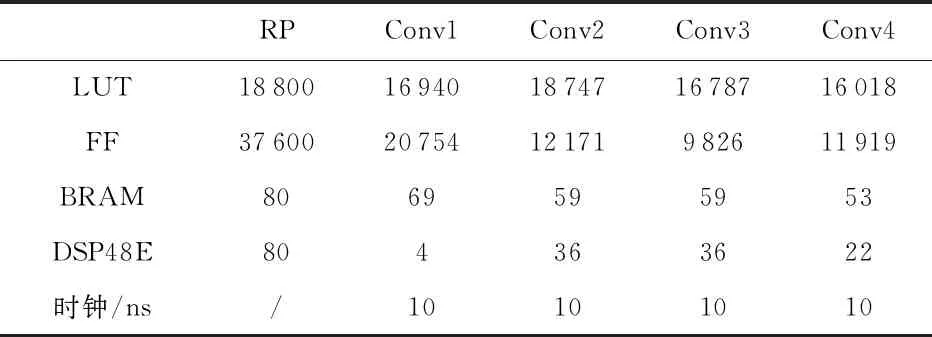
表2 卷積資源占用
當FPGA的可編程邏輯資源和存儲資源較少時,FPGA不能同時實現所有的卷積層,所以本設計采用部分重構,以及軟硬件結合的方式。采用軟硬件組合的方案,實現4層卷積,如表3。

表3 軟硬件組合方案
3.2 軟件實現
在Xilinx SDK 2017.3軟件上,借助開發板HDMI接口,獲取外部圖片,首先處理顏色信息,調用C++圖像類Mat中的通道函數channels分離圖片的3個通道,根據2.3節中的設計,重組通道順序,通過顏色鎖定車牌的大致區域。之后利用C++調用Opencv圖像處理庫,對圖片灰度化、去噪等處理,調用輪廓提取函數,提取檢測到的所有可能輪廓,經過篩選、定位,由HDMI輸出到顯示器。然后分割車牌字符,將字符處理成39×39的二值圖,完成圖片的預處理。預處理效果如圖3所示。

圖3 系統預處理
3.3 數據訓練
利用Caffe深度學習框架,搭建CNN模型,網絡訓練主要針對車牌字符。眾所周知國內的家用車車牌大部分是藍底白字,有3類字符,31個漢字(不包括港澳臺)、24個大寫英文字母(不包括I和O)以及10個阿拉伯數字。
考慮到已有MNIST手寫數字數據集,所以嘗試以MNIST格式來制作字符數據集,字符統一采用39×39的二值圖。通過實地拍攝大量車牌,并對車牌字符分割、分類,最后取3類漢字(滬、浙、蘇)、10類數字以及24類字母的圖片來制作,每類字符2 500張,每類再取250張用于測試。
根據不同的數據集,相應改變表1中最后的全連接層的輸出通道即分類數,結果為MNIST和自制數據集的分類數分別為10和37,準確率分別為99.08 %和99.45 %。
4 結 果
在Ubuntu16.04操作系統下,系統的軟件開發基于 Xilinx SDK 2017.3軟件,硬件開發基于系統開發板PYNQ—Z1。數據訓練利用NVIDIA Quadro P2000 GPU實現加速。
系統預處理部分實現結果如圖3所示,車牌被成功定位,并通過HDMI輸出顯示,字符也成功分割并二值化,說明軟件的預處理設計可行。由于FPGA的重配置需要耗費一定的時間,因此重構的次數不是越多越好。為了比較表3所列2種方案的優劣,本文進行了10次測試,并與純軟件執行方式進行比較,結果如表4。
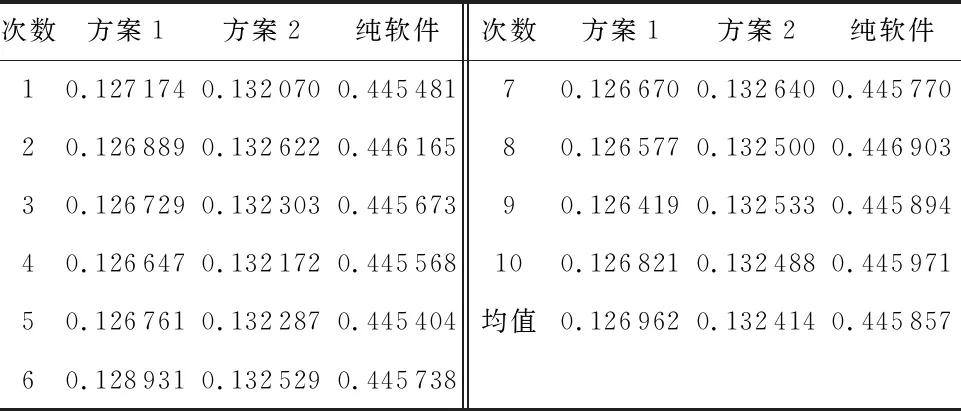
表4 10次實驗的執行時間 s
方案1和方案2的執行速度均比純軟件的方式快,速度都提高了3倍以上,通過軟硬件聯合的方式,有效提高了速度,方案1執行速度最大提升了3.51倍。
實驗中為了驗證所設計的系統對車牌識別的效果,隨機取5張車牌,最終識別結果在開發板的終端顯示,如圖4。
對比輸入圖片,隨機的5張車牌字符都能被正確識別,字符識別率與訓練結果相當,證明所設計的車牌識別系統可行。
本設計的實現方法不僅能得到99 %以上的字符識別精度,同時相比純軟件方式,提高了執行速度,通過FPGA加速,有效解決了傳統網絡精度與速度不可兼顧的問題。
5 結束語
本文充分利用FPGA動態部分重構技術和HLS工具,實現了快速車牌識別。但還有進一步優化的空間,比如改進神經網絡的結構和字符二值化后的降噪,改進預處理方法,減少預處理時間等。神經網絡的應用有很多,如目標追蹤、車輛檢測等[8],未來,將本系統與微型機器人相結合,可以實現對高速公路、住宅區或停車場車輛的靈活管理。
