基于深度學習的商品評論情感分類
2019-12-19 02:07:13嚴鵬
軟件
2019年11期
關鍵詞:深度學習
嚴鵬
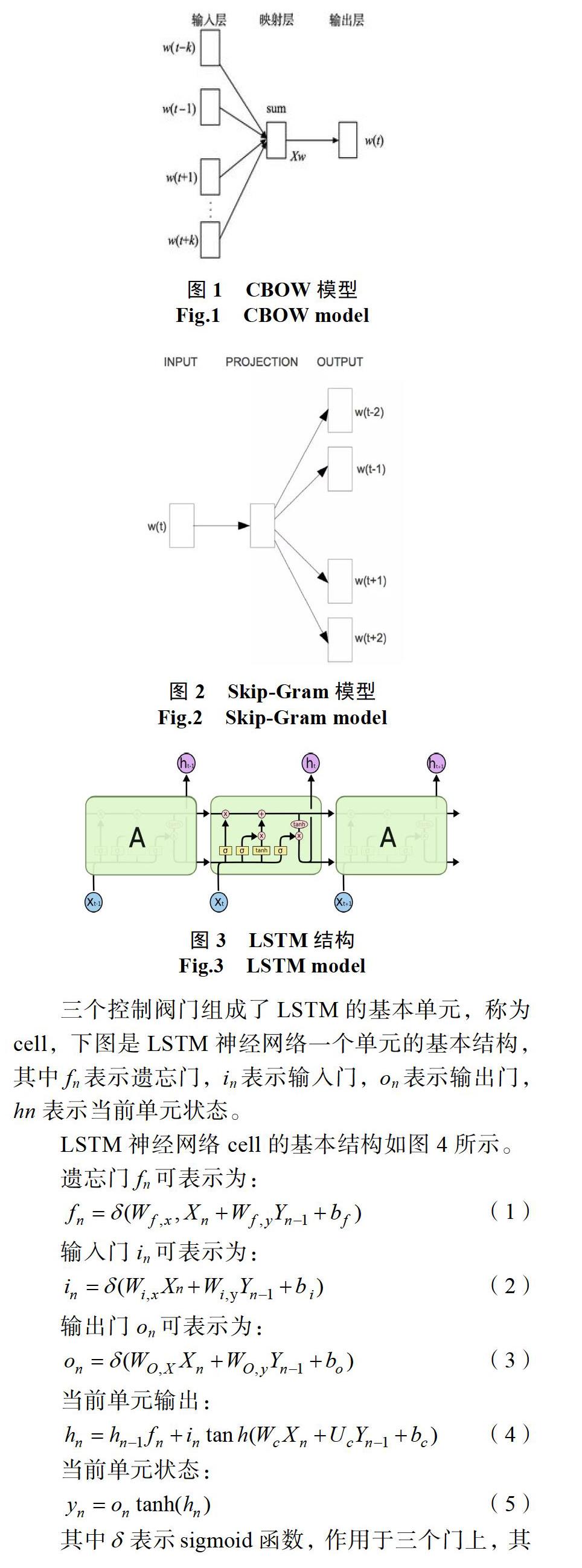


摘? 要: 近年來,隨著互聯網技術的進步,我國電子商務也有了快速的發展,越來越多的人選擇網絡購物,顧客利用互聯網平臺對所購產品進行文字評價或數字評分已成為一種常態。商品評論的情感分類是獲取顧客對該商品直接反饋的一個重要方式。現階段,在情感分類研究中最常用的是基于機器學習和情感詞典的傳統方法,但這些方法都存在一些不足之處。因此,本文主要采用深度學習中的LSTM網絡對某品牌電視的評論進行模型構建與數據分析,并與基于機器學習的SVM方法進行對比分析。
關鍵詞: 情感分類;商品評論;深度學習;LSTM;Word Embedding
【Abstract】: In recent years, with the progress of Internet technology, China's e-commerce has also had a rapid development, more and more people choose shopping network, customers using the Internet platform to buy products for text evaluation or digital score has become a normal. Emotional classification of product reviews is an important way to obtain customers' direct feedback on the product. At present, the traditional methods based on machine learning and emotion dictionary are most commonly used in the research of emotion classification, but these methods have some shortcomings. Therefore, this paper mainly USES LSTM network in deep learning to conduct model construction and data analysis on the comments of a certain brand of TV, and conducts comparative analysis with SVM method based on machine learning.
【Key words】: Emotional classification; Product reviews; Deep learning; LSTM; Word embedding
0? 引言
情感分類又稱做觀點挖掘,其研究目標就是分析文本中人們對所評論事物(如產品,服務,時事話題等)的情感、觀點或者具體態度。情感分類在成為自然語言處理中的一個研究主題后,迅速成為了熱點研究領域[1-3]。情感分類作為一種特殊的分類問題,既有一般模式分類的共性問題,也有其特殊性,如情感信息表達的隱蔽性、多義性和極性不明顯等。針對這些問題人們做了大量研究,提出了很多分類方法。這些方法主要按機器學習方法歸類與按情感詞典方法劃分[4]。
基于機器學習的方法[5]中,根據所使用訓練樣本的標注情況,情感文本分類可以大致分為有監督學習方法、半監督學習方法和無監督學習方法三類。基于有監督學習的情感分類方法使用機器學習方法來訓練大量標注樣本。基于半監督學習的情感分類方法是通過在少量標注樣本上訓練,并在大量未標注樣本上進行學習的方式構建分類模型。……
登錄APP查看全文
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
