不平衡數(shù)據(jù)軟子空間聚類算法在臨床醫(yī)學(xué)中的應(yīng)用與研究
2019-12-19 02:07:13程鈴鈁陳黎飛賴曉燕
軟件
2019年11期
程鈴鈁 陳黎飛 賴曉燕


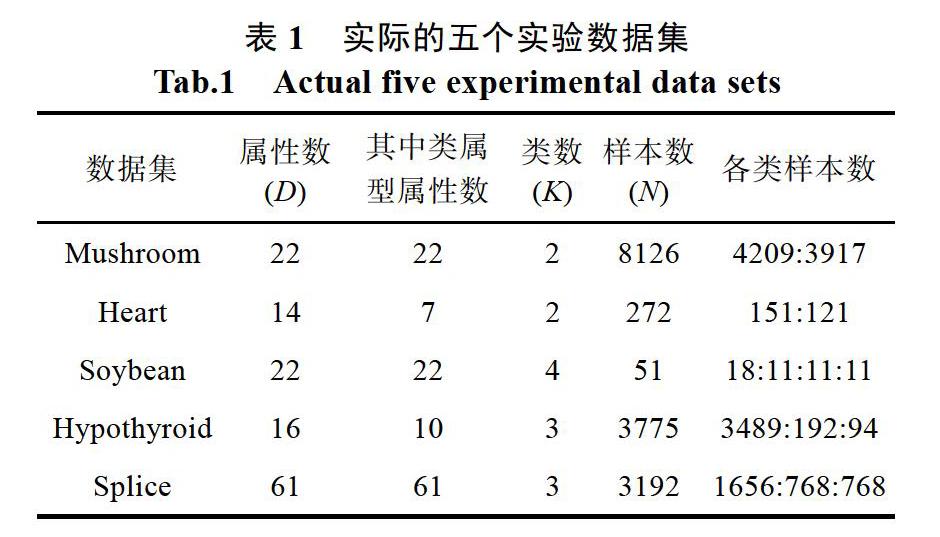
摘? 要: 聚類分析是數(shù)據(jù)挖掘中重要的研究課題,在信息過濾、生物信息學(xué),醫(yī)學(xué)等領(lǐng)域得到廣泛應(yīng)用。本課題著重于自上而下的子空間聚類方法,主要原因是當(dāng)前主要的此型算法都是以K-means或K-modes為基礎(chǔ)的,在均勻效應(yīng)的影響下,不平衡數(shù)據(jù)的問題是現(xiàn)有的軟子空間算法不能有效聚類的,所以提出了一種基于劃分的不平衡數(shù)據(jù)軟子空間聚類新算法。所提算法提高了不平衡數(shù)據(jù)的聚類精度,在生物信息學(xué)和臨床醫(yī)學(xué)等領(lǐng)域具有一定的理論意義和實際應(yīng)用價值。
關(guān)鍵詞: 聚類分析;子空間聚類;不平衡數(shù)據(jù);聚類精度
【Abstract】: Cluster analysis is an important research topic in data mining. It is widely used in information filtering, bioinformatics, medicine and other fields. This topic focuses on the top-down subspace clustering method. The main reason is that the current major algorithms are based on K-means or K-modes. Under the influence of uniform effects, the problem of unbalanced data The existing soft subspace algorithm cannot be effectively clustered, so a new algorithm based on partitioning unbalanced data soft subspace clustering is proposed. The proposed algorithm improves the clustering accuracy of unbalanced data, and has certain theoretical significance and practical application value in the fields of bioinformatics and clinical medicine.
【Key words】: Cluster analysis; Subspace clustering; Unbalanced data; Clustering accuracy
0? 引言
數(shù)據(jù)挖掘領(lǐng)域的重要研究方法之一是聚類,由于聚類分析具有無監(jiān)督學(xué)習(xí)性,所以在眾多領(lǐng)域的得到應(yīng)用,包括醫(yī)學(xué)、生物信息、Web日志分析以及金融交易等等。本文是針對在臨床上的應(yīng)用,我們通常要在手術(shù)后最快的預(yù)測該病人是否可以正常愈合以便為后續(xù)的護(hù)理工作提供更好的決策支持。然而,許多臨床藥物產(chǎn)生的數(shù)據(jù)通常是不平衡的。顯然這些數(shù)據(jù)是混合數(shù)據(jù),這是我們面臨的第一個問題。同時我們還發(fā)現(xiàn)在采集的這些混合數(shù)據(jù)中,不是每個特征對我們最后進(jìn)行區(qū)分病人是否能夠正常愈合都是重要的,其中有的特征是不重要的,這樣一來,我們面對的第二個問題就是特征如何選擇的問題。最后,在實際的臨床應(yīng)用中,大多數(shù)病人都是可以正常愈合的,只有少數(shù)的病人不能夠正常愈合,在數(shù)據(jù)挖掘中,我們將大部分可以正常愈合的人群看做一個類,不能正常愈合的看做另外一個類,很明顯兩大類的數(shù)量上具有較大差異,所以我們面對的第三個問題就是類不平衡的問題。……
登錄APP查看全文
