基于HDFS+Spark的時空大數(shù)據(jù)存儲與處理
2019-12-19 02:07:13賈旖旎周新民曹芳
軟件
2019年11期
關鍵詞:數(shù)據(jù)挖掘
賈旖旎 周新民 曹芳
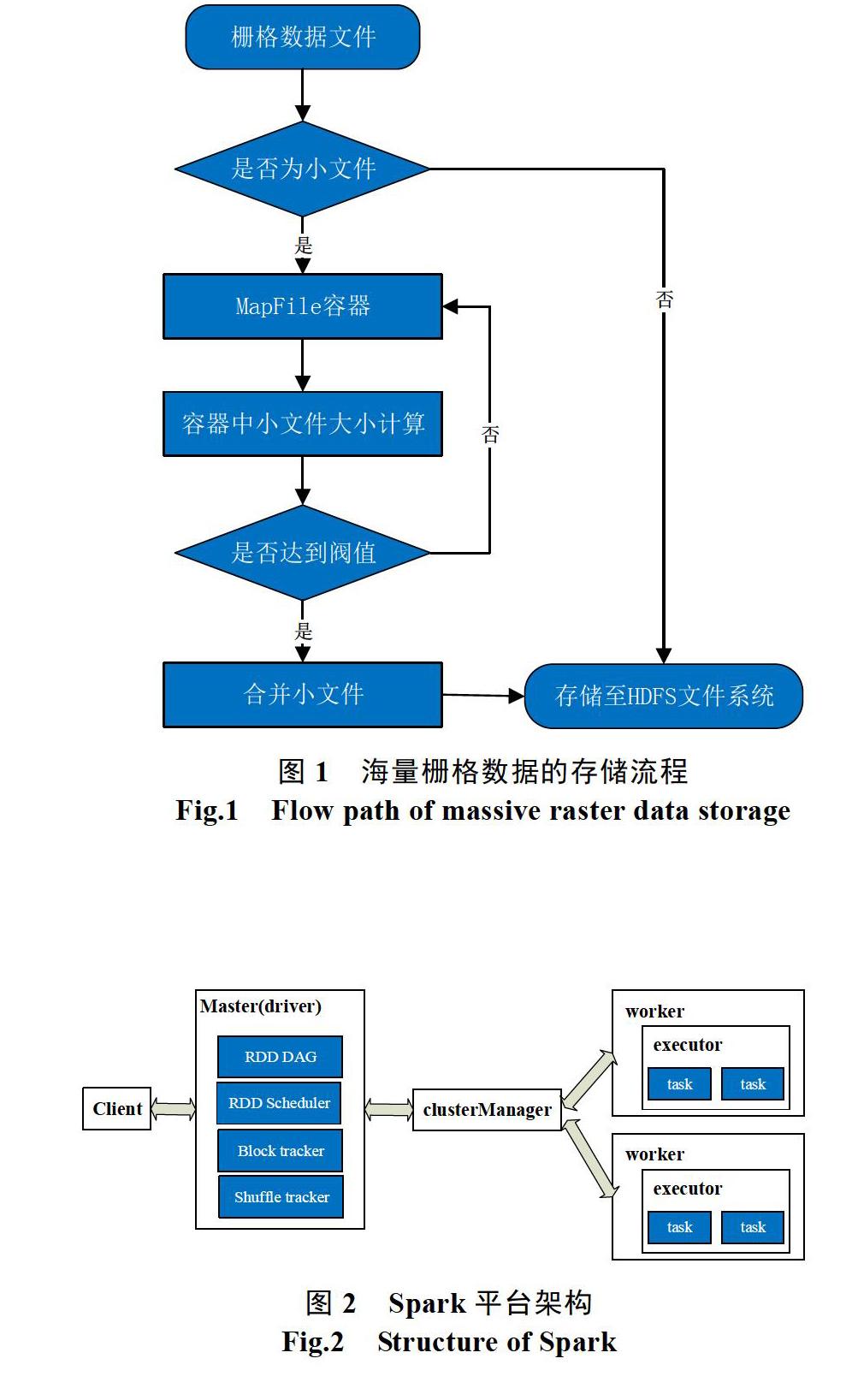
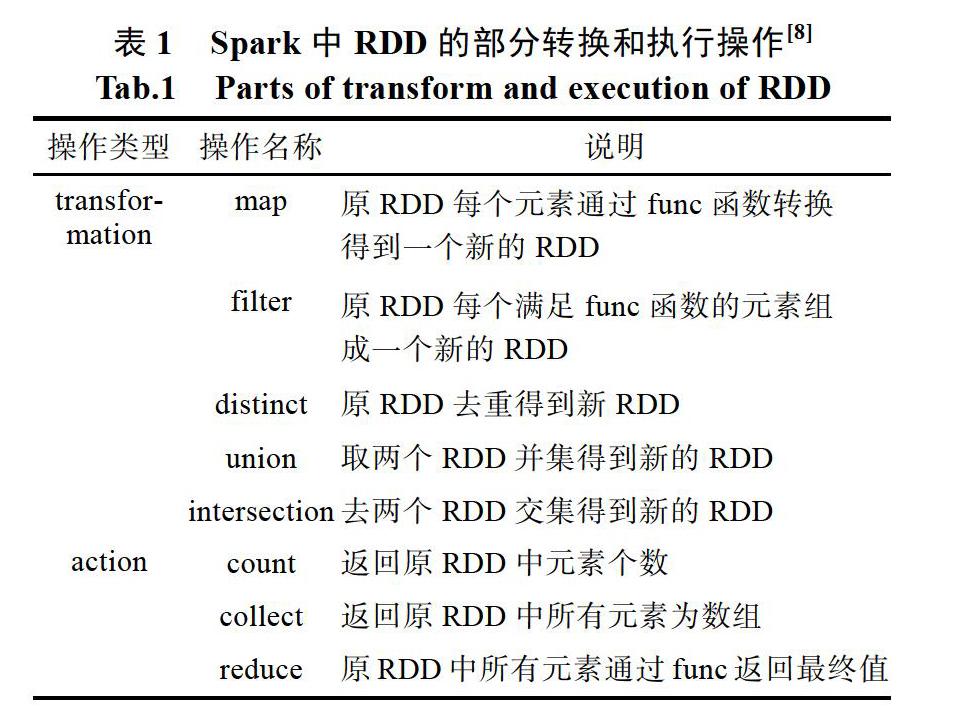
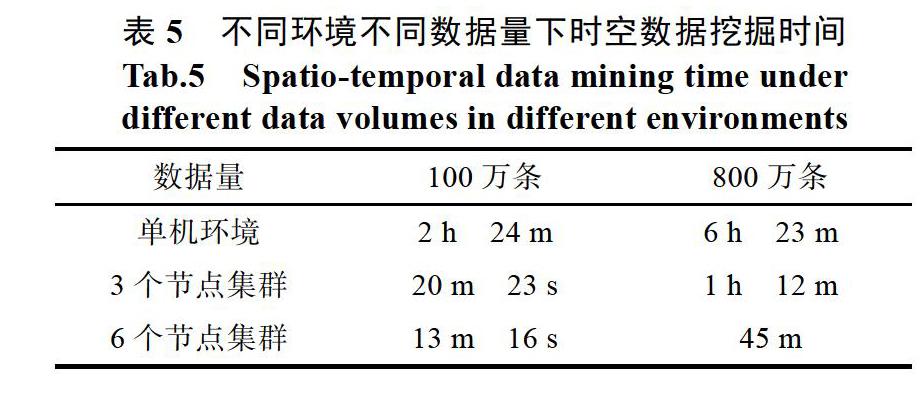
摘? 要: 海量時空數(shù)據(jù)的高效存儲、讀寫、處理與分析是當前地理信息科學領域的研究熱點。本文對目前主流大數(shù)據(jù)技術產(chǎn)品進行了選取和融合,開展了基于HDFS+Spark的時空大數(shù)據(jù)存儲、處理分析等方面的研究和探討,以智慧無錫時空信息云平臺為應用對象,搭建了一套時空大數(shù)據(jù)存儲處理的集群平臺,并通過具體應用實驗,得到了時空數(shù)據(jù)存儲、處理、挖掘的響應時間及可視化展示結果,證實了HDFS+Spark集群計算平臺在解決時空大數(shù)據(jù)存儲、處理、挖掘方面的有效性。
關鍵詞: 時空大數(shù)據(jù);集群計算;存儲處理;數(shù)據(jù)挖掘
【Abstract】: Efficient storage, reading, writing, processing and analysis of massive spatio-temporal data is a hot research topic in geographic information science. This paper chooses and integrates the mainstream big data technology production, investigates and studies the spatio-temporal big data storage and processing analysis based on HDFS+Spark ,and builds the Cluster platform. And also its applied in the experiment and the results of response time and visual display of storage, processing and mining of the spatio-temporal data are obtained, which proves the effectiveness of HDFS+Spark cluster computing platform in solving spatio-temporal big data storage, processing and mining.
【Key words】: Spatio-temporal big data; Cluster computing; Storage processing; Data mining
0? 引言
隨著測繪地理信息技術的發(fā)展和智慧城市建設的不斷推進,時空大數(shù)據(jù)的種類愈多、覆蓋愈廣、更新頻率愈快,數(shù)據(jù)量急劇增加,從MB、GB級逐步達到TB、PB級,使得海量時空數(shù)據(jù)在存儲管理、數(shù)據(jù)檢索、處理分析等方面的難度不斷提升。同時,大量以分布式存儲和并行計算為核心的大數(shù)據(jù)技術平臺及產(chǎn)品隨之涌現(xiàn),如Hadoop、MongoDB、Spark,
這些平臺及產(chǎn)品有望解決當前大數(shù)據(jù)在存儲和處理中存在的問題。本文圍繞如何應用主流大數(shù)據(jù)技術及產(chǎn)品更好地為時空大數(shù)據(jù)服務,結合智慧無錫時空大數(shù)據(jù)的應用需求,搭建了一套時空大數(shù)據(jù)存儲處理的集群平臺,并以實驗驗證了該平臺在時空大數(shù)據(jù)的存儲、處理與挖掘中的性能與效率。
1? 時空大數(shù)據(jù)集群計算平臺選型
HDFS分布式文件系統(tǒng)是Hadoop核心技術之一,提供了開源的存儲框架,是一個實現(xiàn)數(shù)據(jù)分布式存儲的文件系統(tǒng)[1]。……
登錄APP查看全文
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
