優化遞歸變分模態分解及其在非線性信號處理中的應用*
2019-12-16 11:39:24許子非岳敏楠李春
物理學報 2019年23期
許子非 岳敏楠 李春?
1) (上海理工大學能源與動力工程學院,上海 200093)
2) (上海市動力工程多相流動與傳熱重點實驗室,上海 200093)
經驗模態分解一類的遞歸算法所產生的模態混淆和端點效應將導致所獲物理信息失真,變分模態分解可改善這些問題.但因其需預設參數,對信號分解精度影響顯著,為此,提出采用目標信號功率譜峰值所對應的頻率以初始化變分模態分解所需中心頻率,借鑒經驗模態分解遞歸模型,基于能量截止法將變分模態分解改進為遞歸模式算法,并采用粒子群優化算法對具有帶寬約束能力的懲罰因子進行最優取值,構成優化遞歸變分模態分解.通過對比分析經驗模態分解,集成經驗模態分解及優化遞歸變分模態分解在分解信號時的計算精度;研究傳統變分模態分解與優化遞歸變分模態分解在處理實際振動信號時計算速率.結果表明:優化遞歸變分模態分解在處理目標信號時精度最高,與原分量相關性達99.9%;與集成經驗模態分解對比,可由低至高將信號分解至不同頻段,物理意義更加清晰且不產生虛假模態;處理實際非線性信號時,優化遞歸變分模態分解無需預設分解模態個數,相比于傳統變分模態分解,計算速率高12.5%—18.5%.
1 引 言
非平穩信號具有隨機性強、穩定性差與物理信息混疊等特點[1].為探尋非穩定信號中所含信息,在結構分析、故障診斷乃至醫學領域[2-5],相關學者對信號(時間序列)分解技術已展開諸多研究.其中,應用較為廣泛的有小波分解(wavelet transform,WT)、經驗模態分解(empirical mode decomposition,EMD)、集合經驗模態分解(ensemble empirical mode decomposition,EEMD)和局部均值分解(local mean decomposition,LMD)等[6-9].WT方法采用縮放、平移窗函數將原信號分解為若干小波疊加的形式,但易產生無物理意義的虛假諧波,影響結果分析[10].EMD與EEMD均屬于遞歸模式分解,EEMD在處理信號時,通過對信號加入高斯噪聲以抑制EMD處理信號時易產生的模態混淆的問題,可有效處理非線性、非平穩信號分解;但在EEMD迭代過程中,由于包絡線估計誤差的疊加,導致引發端點效應及模態混淆[11].LMD作為遞歸算法,可自適應分解無規則信號至多個含物理意義的乘積函數分量,較小波分析有更好的自適應性,但無法分離頻率相近的信號.以上方法因求解本質屬于遞歸分解,均存在包絡線估計誤差隨迭代而累計,從而導致模態混淆及端點效應,影響對物理信息的提取及分析.
為此,Dragomiretskiy和Zosso[12]提出基于Hilbert變換、Wiener濾波及頻率混合等概念的新型分解方法—變分模態分解(viriational mode decomposition,VMD),該方法因具有完備的數學理論基礎,通過求解約束變分模型代替原有的遞歸模式,從而抑制模態混淆、避免端點效應及解決相近頻率難分離的問題[13].
采用VMD對信號進行求解時,涉及模態分解數、懲罰因子、保真系數及收斂條件等參數的預設.研究表明,其中懲罰因子α與模態分解數K對信號分解精度影響最為顯著[14].已有學者針對懲罰因子α與模態分解數K的何種取值對分解效果如何影響做了相關研究.文獻[15]以VMD分解所獲分量間的相關系數作為約束,從而確定模態分解數K的取值,并將改進VMD與深度置信網絡相結合,實現故障預警.文獻[16]以包絡熵作為VMD參數優化的目標函數進行尋優取值,結果具有良好的分解精度,并將其應用于滾動軸承故障診斷中.文獻[17]將VMD與多尺度排列熵相結合,在生物組織變性識別中獲得較優的聚類效果與分類性能.Baldini等[18]比較VMD與EMD在分解無線電信號的準確性,并采用機器學習對信號進行分類,得出基于VMD分解的信號具有更高的準確性.Chen等[19]分別采用VMD與EMD對軸承振動信號進行分解,以能量熵作為特征值構建特征向量,并采用支持向量機對特征向量進行分類,結果表明以VMD-能量熵構建的特征樣本,使得分類結果具有更高的準確性,但未考慮VMD分解時預設參數對VMD分解精度的影響.為此,Cui等[20]基于目標信號瞬時頻率,對VMD算法K值設定進行改進,指出該方法可提升VMD分解精度,并成功用于智能負載建模與去噪,但忽略了VMD分解時以約束帶寬的參數—懲罰因子對結果的影響.
以上研究采用VMD處理信號時,或考慮模態分解數對分解效果的影響,而忽略了懲罰因子對帶寬約束,致使分解效果不佳;或采用局部尋優的方法對懲罰因子與模態分解數進行選擇,未考慮預設參數間的互交性;又或基于分量特征值作為分解效果判別標準,以獲取全局優化的參數組合,但缺乏一定的物理意義.
因此,本文針對VMD處理信號前需預設懲罰因子α與模態分解數K,且α與K取值組合對分解精度有顯著影響的問題,提出一種優化遞歸VMD算法(optimized recursive variational mode decomposition,ORVMD),該算法借鑒EMD遞歸分解時可自適應獲取模態分解數K的優點,以目標信號功率譜最大值對應的頻率作為初始頻率,并基于能量差追蹤法將傳統VMD改進為遞歸VMD,并采用粒子群優化算法獲取懲罰因子α的最優取值,得到最佳α,K組合,以保證分解所得分量具有更多的物理信息.對比EMD,EEMD及ORVMD在分解信號時的精確性,分析EEMD與ORVMD在處理非線性調制信號時的可靠性,研究傳統VMD與ORVMD解決實際振動信號時的時效性,發現ORVMD具有更高的計算精度與效率,亦可保留更多的物理信息,以期為信號處理、結構分析及故障診斷等方面奠定理論基礎,提供處理方法.
2 VMD算法
VMD算法是基于Wiener濾波、Hilbert變換與外差解調所形成的一種分解算法,因其具有完備的數學基礎,采用VMD處理信號時可有效避免EMD類算法導致的模態混淆及端點效應.與屬遞歸性質的EMD類算法不同,VMD屬約束變分性問題,通過假設模態分量的中心頻率,將約束模態帶寬的過程轉化為約束變分問題,求解變分模型以實現模態分解.VMD算法中涉及的約束變分模型為

式中 {uk}={u1,u2,···,uk}與{ωk}={ω1,ω2,···,ωk}分別為第k 個模態分量及其相應中心頻率,共K個模態;δ(t) 為單位脈沖函數;j表示虛數單位;* 表示卷積運算;?t為偏導運算;f為目標信號.
引入懲罰因子α和Lagrange乘子Λ以求解變分約束問題.所得增廣Lagrange表達式如下:

采用交替方向乘子算法(alternate direction method of multiplers,ADMM)更新迭代求解(2)式的鞍點,在頻域內迭代更新 uk,ωk及Λ.
VMD將信號分解為K個模態分量,步驟如下:
2) uk和 ωk分別由(3)式和(4)式迭代更新,

式中τ為保真系數;∧表示傅里葉變換;n 為迭代次數;
3) 通過(5)式更新Λ,
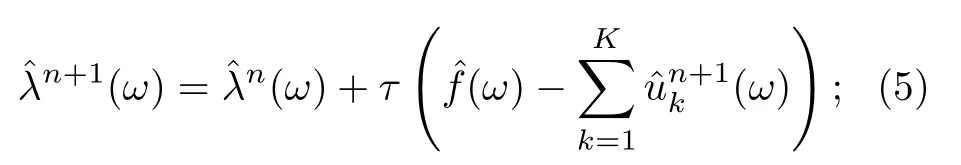
4) 重復步驟2和3,至滿足迭代終止條件,終止條件由(6)式給出,
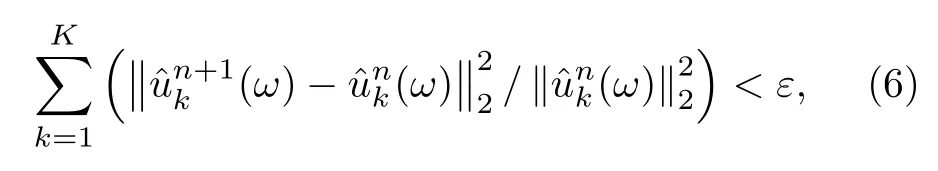
式中ε為判別精度,且 ε> 0;上標n 為迭代步數,下標k 表示當前模態數;
5) 輸出K個模態分量.
3 優化遞歸VMD算法
與EMD等遞歸分解算法相比,VMD具有較高的準確性與穩定性.但VMD算法需給出預設模態分解數K,且K的取值影響分解精度.因此,借鑒EMD遞歸思想,提出一種遞歸VMD算法.借鑒能量差追蹤法以設定停止條件,實現遞歸VMD算法.該方法既擁有VMD算法中可抑制求解包絡線迭達誤差而導致失真的優點,也可實現自適應分解,無需預設模態分解數K.
3.1 遞歸算法
3.1.1 改進變分模型
基于傳統VMD算法,給定初始模態分解數K=1的約束變分模型,獲得有限帶寬本征模態函數(bandwidth intrinsic mode function,BIMF),將(1)式轉化為(7)式.
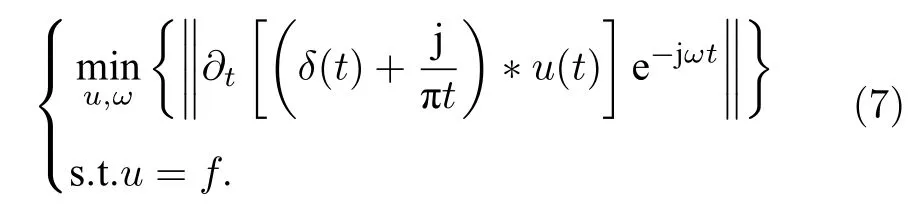
引入懲罰因子α和Lagrange乘子Λ后,(2)式將變為(8)式,(5)式和(6)式被轉換為(9)式和(10)式,其余步驟與傳統VMD算法相同.
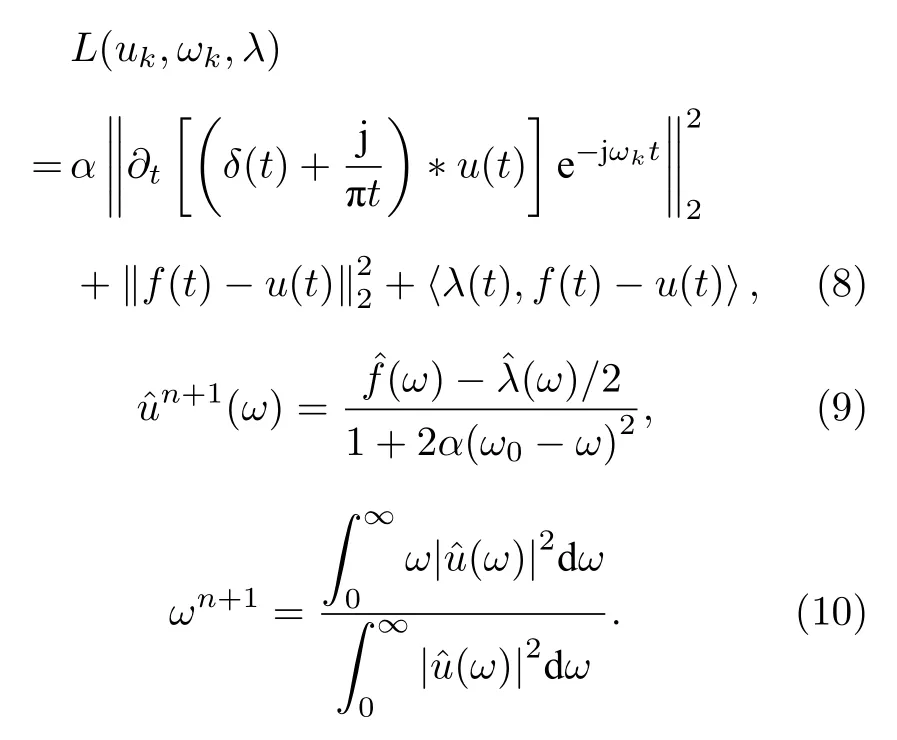
采用ADMM算法時,中心頻率 ωk需預計算.而Dragomiretskiy等[12]所提出三種初始化中心頻率的方法(分別為:賦予初值零、線性化及隨機初值化)均有一定的局限性.其中線性化以獲取初值具有較好的準確性與穩定性,但當 K=1 時,中心頻率 ωk=0 ,與賦予初值零情況相同,從而導致線性化失敗.因此,提出以目標信號功率密度譜(power density spectrum,PSD)最大值所對應的頻率作為 ωk初值.
3.1.2 停止準則
Huang等[21]與Damerval等[22]所提出的停止準則均不適用于VMD算法,故采用Cheng等[23]所提出的能量差追蹤法應用于本文所提出的改進變分模型.基于能量差追蹤法的VMD停止準則如下.
假設目標信號 f (t) 分解后所得BIMF分量uk(t)具有正交性,由(11)式給出,其總能量表達式由(12)式給出.
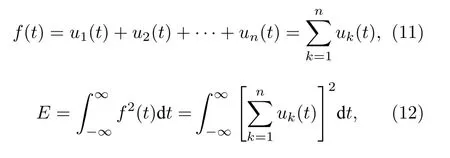
式中E為原信號能量.
因各BIMF的正交性,(12)式可表示為
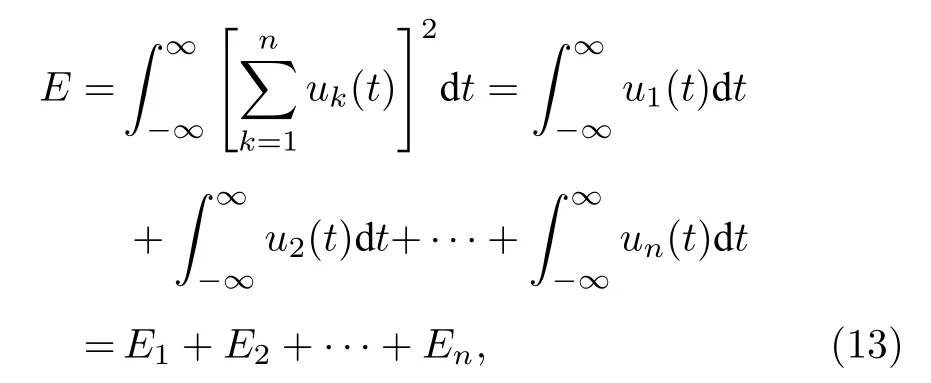
式中 E1+E2+···+En為各BIMF分量的能量.
當BIMF分量完全正交時,各BIMF能量之和 Etotal應與原信號能量E相等,

但當BIMF分量不完全正交時,Etotal與E之間存在誤差 Eerr,
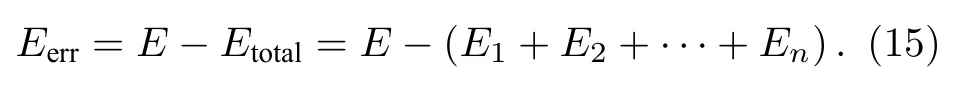
能量誤差 Eerr越接近零,表明分解效果越好,與原分量符合度更高,所得模態分量頗含物理意義.因此,令 Eerr的絕對值 |Eerr|為停止準則,當|Eerr|小于收斂閾值時停止迭代,以獲取最佳模態分解數K.
3.1.3 遞歸VMD算法
基于以上提出的改進變分模型,結合能量差追蹤法確定收斂條件,遞歸VMD算法流程圖如圖1所示,具體計算步驟如下:
1) 輸入目標信號,通過計算目標信號的PSD,以PSD最大值對應的頻率最為中心頻率 ωinitial;
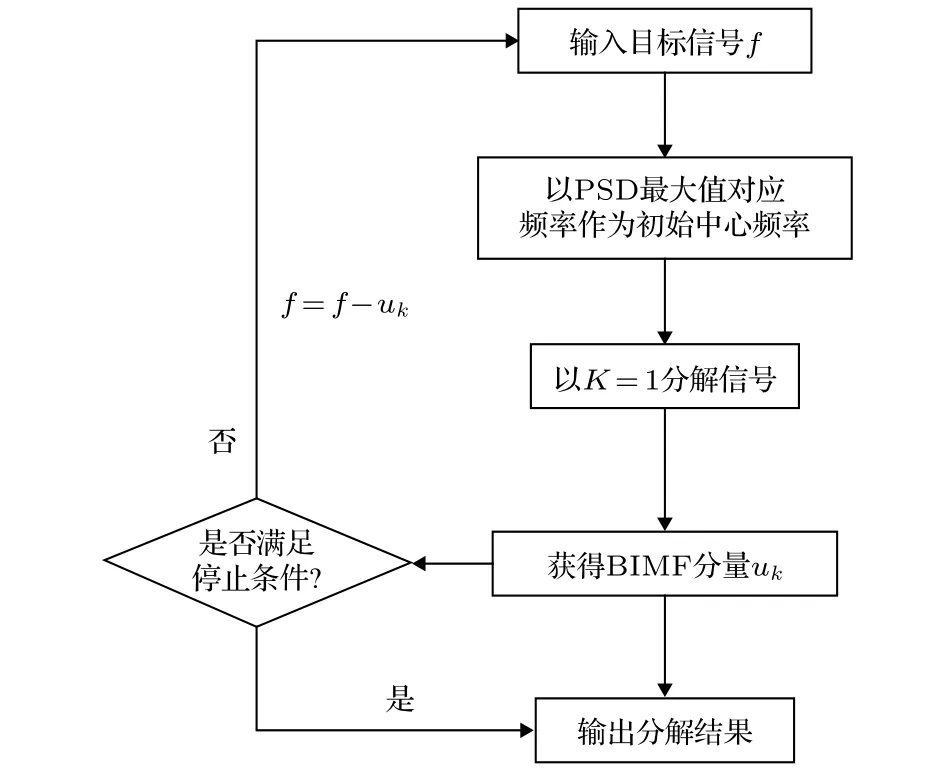
圖1 遞歸VMD流程Fig.1.The recursive VMD diagram.
2) 采用步驟1獲取的中心頻率進行迭代,并預設模態分解數 K=1 ,獲取(7)式的變分模型,通過(9)式和(10)式分別獲取 uk與 ωk;
3) 采用步驟2獲取的 uk作為BIMF分量,將f-uk作為新目標信號并重復步驟1與2;
4)對于分解所得BIMF分量,通過(15)式計算能量誤差 |Eerr|,當 |Eerr|小于收斂閾值時停止分解并獲取全部BIMF分量.根據計算經驗,采用|Eerr|≤[(0.7~ 2.0)E]/100為收斂閾值;
5) 輸出全部BIMF分量.
3.2 PSO算法
粒子群優化算法(particle swarm optimization,PSO)是由Kennedy 和Eberhart[24]受鳥群覓食行為啟發所提出的.在PSO算法中,每個粒子具有相應的速度與位置以調整自身的狀態,粒子的位置代表待優化問題的潛在解.PSO算法的數學描述如下.
在D維空間中,存在由m 個粒子組成的種群,第i 個粒子在D維空間中的位置向量為Xi=(xi1,xi2,···,xiD)T,其速度向量為Vi=(vi1,vi2,···,viD)T,第i 個粒子的最佳位置由向量Pi=(pi1,pi2,···,piD)T表示,種群最佳位置由向量Pg=(pg1,pg2,···,pgD)T表示,速度與位置的更新由(16)式和(17)式所示.
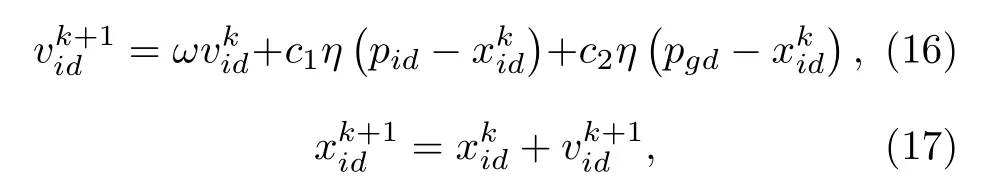
式中 i =1, 2,···,m ;d =1, 2,···,D;k 為當前進化代數;c1與 c2為學習因子;ω為慣性權重;η為[0,1]內隨機數.
3.3 ORVMD算法
以上所提出的遞歸VMD方法雖可自適應獲取分解模態數K,但懲罰因子α作為約束帶寬的參數,其取值也嚴重影響了信號處理的準確性.帶寬的變化影響分解所獲各模態能量的變化,從而進一步影響遞歸模態分解數K或信號分解失效[25].因此,以能量誤差 |Eerr|為尋優過程的適應度函數,將適應度函數最小取值作為尋優目標,基于PSO算法對改進遞歸VMD算法進行參數尋優,獲取最佳分解參數組合,其流程如圖2所示.
1) 初始化PSO算法各項變量并確定尋優過程中的適應度函數 |Eerr|,以懲罰因子α及模態分解數K作為粒子位置,并隨機初始化粒子移動速度;
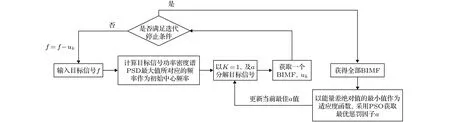
圖2 基于PSO優化改進遞歸VMD參數流程Fig.2.The process of using PSO to optimize recursive VMD parameter.
2) 在不同粒子位置條件下對信號進行遞歸VMD處理,獲該位置下信號能量誤差 |Eerr|,以此作為對應粒子的適應度函數;
3) 對比各粒子適應度函數大小(優劣),若有粒子的適應度函數 |Eerr|小于當前最小適應度函數,則對粒子進行更新;
4) 通過(16)式與(17)式更新粒子屬性;
5) 判斷粒子是否滿足種群進化停止條件,若不滿足則重復步驟2繼續尋優,直到滿足最大種群進化預設值,輸出最佳粒子,即為最優參數組合 [α,K].
基于PSO優化算法及改進迭代VMD算法,稱為優化遞歸VMD算法(optimized recursive variational mode decomposition,ORVMD),該改進算法能獲取較精確的懲罰因子α以約束帶寬,并自動獲得分解模態個數K,確定最佳參數組合 [α,K].
4 ORVMD算法驗證
為驗證ORVMD分解信號的可靠性及有效性,以兩個低頻信號與間斷高頻沖擊信號組成仿真復合信號.仿真復合信號 f (t) 與其分量表達式由(18)式所示:

各分量及其合成信號的波形圖如圖3所示.為驗證算法ORVMD的有效性,分別采用EMD,EEMD及ORVMD對信號 f (t) 進行分解,對比其結果.
首先采用EMD對仿真信號進行分解,分解結果如圖4所示.由圖4可知,EMD將信號分解為5個IMF分量及1個殘余分量,分解效果較差,IMF1與IMF2均出現模態混淆現象,IMF3勉強具有一定的物理意義.
EEMD引入白噪聲以克服EMD分解時易出現對極值點選判出錯的影響.選取噪聲幅值系數0.02,集合平均次數50,采用EEMD分解結果如圖5所示.
由圖5可知,EEMD分解出7個IMF分量及1個殘余分量.其中IMF1,IMF3與IMF4分別為原信號中的間斷高頻信號及兩個低頻信號,與原信號分量的相關系數分別為0.981,0.942和0.944,表明EEMD對分解信號的物理意義還原性較好,較EMD具有更好的準確性,但仍產生許多虛假模態不具有物理性.
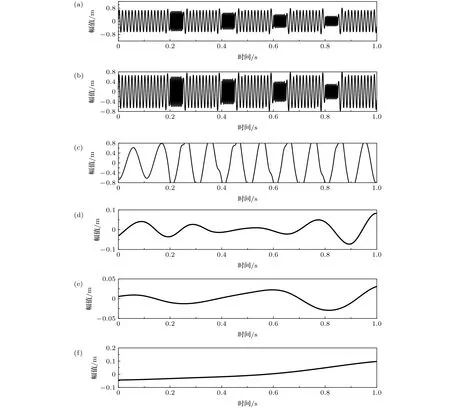
圖4 EMD分解結果 (a) IMF1;(b) IMF2;(c) IMF3;(d) IMF4;(e) IMF5;(f) resFig.4.The results of EMD:(a) IMF1;(b) IMF2;(c) IMF3;(d) IMF4;(e) IMF5;(f) res.
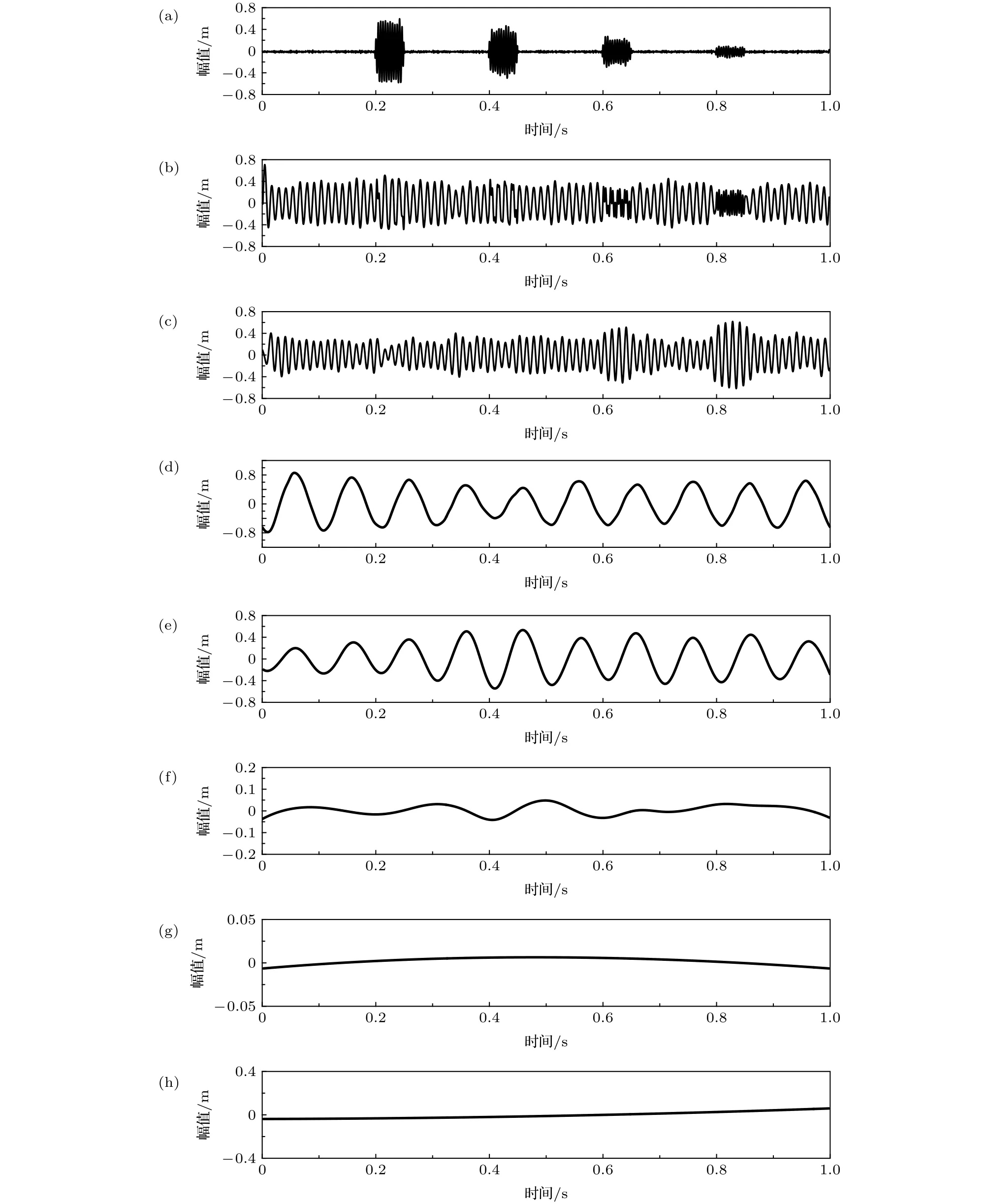
圖5 EEMD分解結果 (a) IMF1;(b) IMF2;(c) IMF3;(d) IMF4;(e) IMF5;(f) IMF6;(g) IMF7;(h) resFig.5.The results of EEMD:(a) IMF1;(b) IMF2;(c) IMF3;(d) IMF4;(e) IMF5;(f) IMF6;(g) IMF7;(h) res.
采用本文提出的ORVMD對信號進行分解,其中分解模態數 K=3,α=500 ,分解結果如圖6所示.
如圖6所示,原信號3個分量被較好地還原至3個IMF分量,其中IMF3為間斷高頻信號,兩個低頻信號分別為IMF1與IMF2.各IMF分量與對應原分量的相關系數分別為0.998,0.991與0.999,較EEMD具有更高的精度,可獲取更具物理意義的信號分量.

圖6 ORVMD分解結果 (a) IMF1;(b) IMF2;(c) IMF3Fig.6.The results of ORVMD:(a) IMF1;(b) IMF2;(c) IMF3.
5 非線性信號分解
處理實際信號時,目標信號多為調制信號,故為驗證ORVMD在處理實際信號也具有高效性與準確性,以如下數學模型模擬滾動軸承早期局部損傷信號 x (t)[26]:
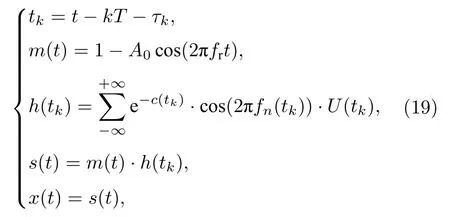
式中 s (t) 為周期性沖擊信號.信號衰減指數C=1000,系統共振頻率 fn=4000Hz.τk表示第k 次沖擊相對于特征周期的小波動,該隨機波動服從均值為零,標準差為0.5%轉頻的正態分布.特征頻率 fr=140Hz.U(tk) 為單位階躍函數.加入高斯噪聲信號后得信噪比為—5 dB的仿真信號.采樣頻率為16000 Hz,采樣點N= 4096.信號時域及頻譜如圖7所示.
5.1 EEMD分解
采用EEMD對信號 x (t) 進行分解,其分解所得時域與頻域如圖8所示,共11個IMF分量及1個殘余分量.
如圖8所示,IMF1—IMF6五個分解分量包含良好的物理信息,將重疊在全頻段的信號分解在不同頻段,但低頻信號仍互相重疊,無法體現軸承損傷的物理信息.且IMF7—IMF11基本屬于無效信息,蘊含的物理信息較少,這說明EEMD對非線性信號的分解效果不佳.

圖7 早期軸承內圈故障信號 (a) 時域;(b) 頻譜Fig.7.Early inner race fault diagnosis signal.
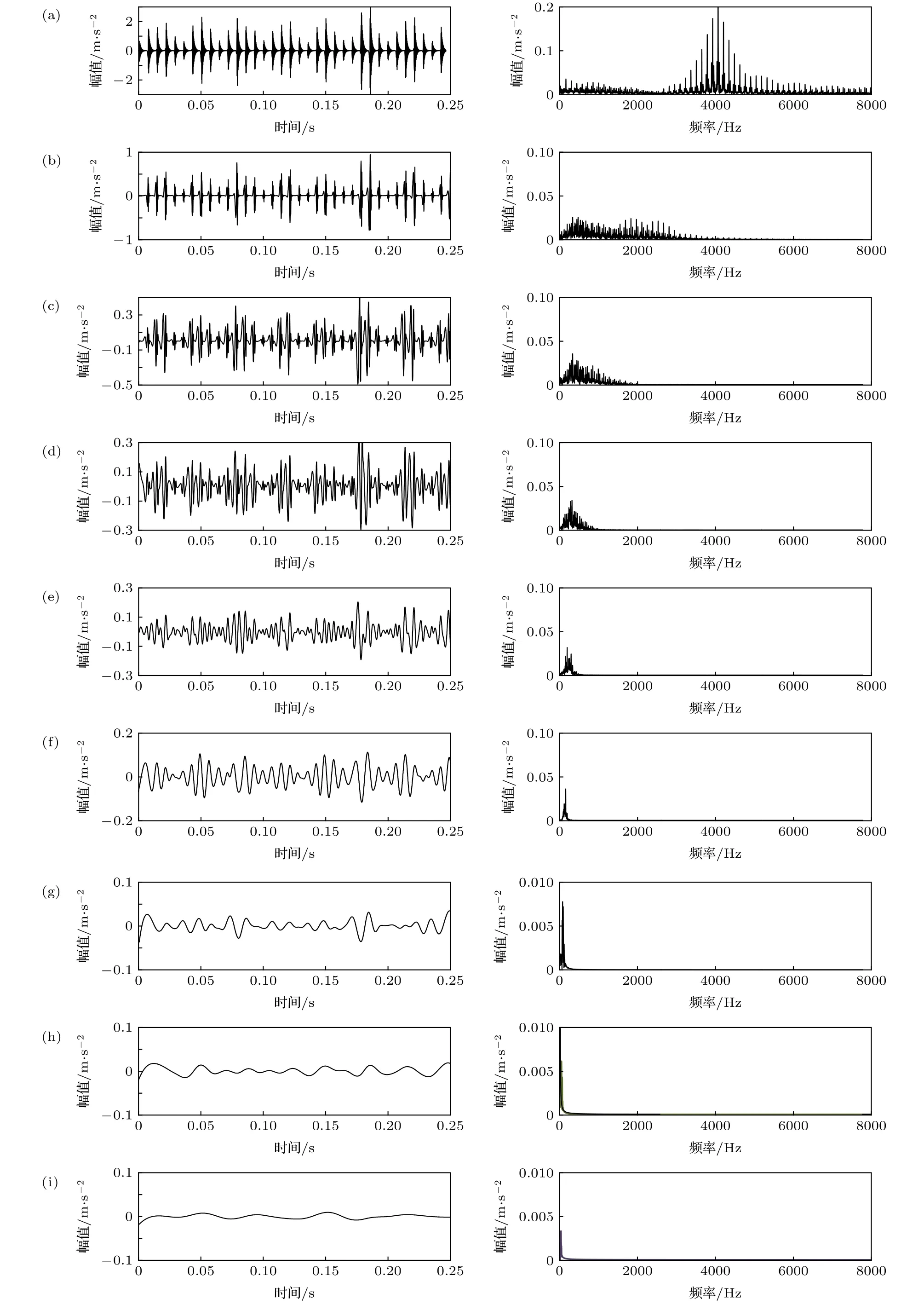

圖8 故障信號EEMD分解結果 (a) IMF1;(b) IMF2;(c) IMF3;(d) IMF4;(e) IMF5;(f) IMF6;(g) IMF7;(h) IMF8;(i) IMF9;(j) IMF10;(k) IMF11;(l) IMF12Fig.8.The results of EEMD for fault signal:(a) IMF1;(b) IMF2;(c) IMF3;(d) IMF4;(e) IMF5;(f) IMF6;(g) IMF7;(h) IMF8;(i) IMF9;(j) IMF10;(k) IMF11;(l) IMF12.
5.2 VMD分解
采用所提出的ORVMD方法對信號進行處理,其中模態分解數 K=9 ,優化懲罰因子α=16100,所得結果如圖9所示.
由圖9可知,每一階IMF都包含一定的物理意義,原本冗雜在各個頻段的信號已從低頻至高頻準確區分,且未出現過分解或者虛假模態.IMF1中蘊含內圈損傷特征頻率,IMF5因損傷導致軸承系統發生共振,主頻與諧波之間的頻段間隔清晰可見,包含一定的物理信息.相比于EEMD,ORVMD具有更高的精度,不存在虛假模態,且未分解出不具物理意義的IMF分量以干擾對信號的分析.
5.3 ORVMD與傳統VMD對比
因采用VMD分解時,已有研究表明模態分解數K與懲罰因子α對分解結果及精度有顯著影響,在此不做分析.除模態分解數K可自適應獲得外,配合PSO優化算法獲取最佳參數組合,較之于傳統VMD,本文所提出的ORVMD因改變模態分量的初始中心頻率獲取方式,以PSD最大值對應的頻率作為初始中心頻率,代替傳統VMD線性初始化的方法,可減少迭代次數以提升計算速度.
采用西儲大學軸承振動信號為例[27],對風扇端軸承內圈故障的25組信號分別進行ORVMD以及傳統VMD進行分解,其中實驗臺轉速為1730 rmp,采樣頻率12000 Hz,負載為3 Hp.為保證對比有意義,采用與ORVMD分解時所需參數[α,K]組合作為傳統VMD分解時的輸入參數.
采用ORVMD方法對25組信號進行分解,獲得25組α及K組合,采用PSO算法時,懲罰因子α尋優的取值范圍為[5000,20000],取值步長為100.ORVMD參數組合如表1所列.
由于實驗采集信號含有不同程度的噪聲,噪聲對分解產生一定的干擾,導致最優模態分解數會稍有波動.由表1可得,80%的模態分解數均為12,故選取模態分解數 K=12 為傳統VMD分解時的模態預設定.懲罰因子看似毫無規律,但對應實驗數據采樣頻率可知,懲罰因子作為約束帶寬的參數,均在12000附近波動,與采樣頻率相近(12000 Hz),ORVMD獲取的25個最優懲罰因子均值為12600,但其中7次為12000,6次為11900.因此,確定α= 12000為傳統VMD分解時的懲罰因子.
以 α=12000,K=12 作為傳統VMD分解預設參數,分別采用傳統VMD與ORVMD對上述25組實驗振動信號進行分解,兩種方法分解信號耗時如圖10所示.
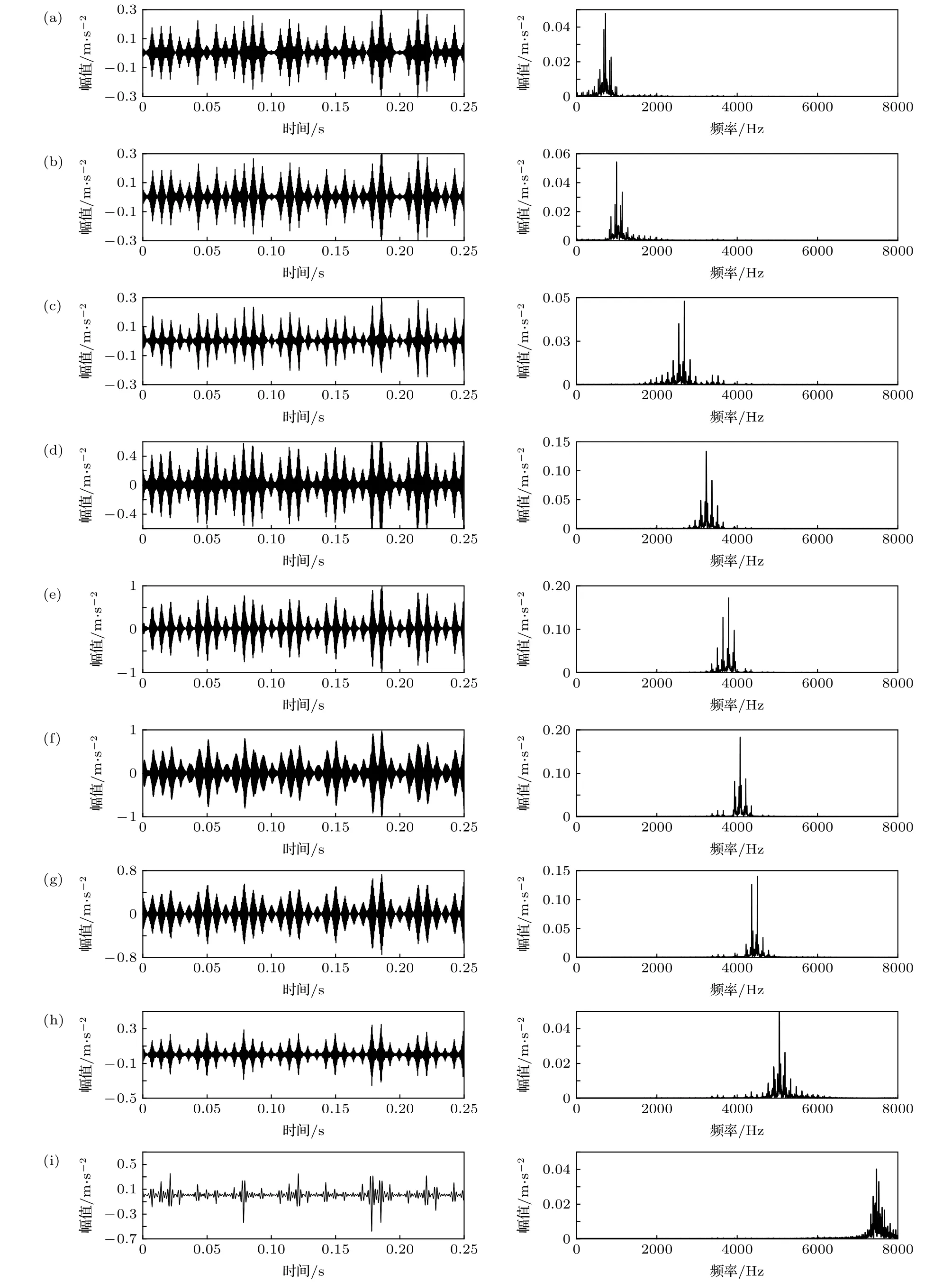
圖9 故障信號ORVMD分解結果 (a) IMF1;(b) IMF2;(c) IMF3;(d) IMF4;(e) IMF5;(f) IMF6;(g) IMF7;(h) IMF8;(i) IMF9Fig.9.The results of ORVMD for fault diagnosis:(a) IMF1;(b) IMF2;(c) IMF3;(d) IMF4;(e) IMF5;(f) IMF6;(g) IMF7;(h) IMF8;(i) IMF9.
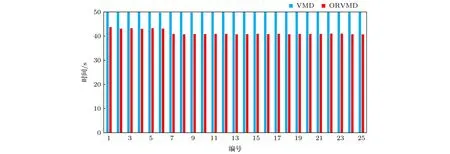
圖10 VMD與ORVMD計算耗時Fig.10.The duration of calculation for VMD and ORVMD.
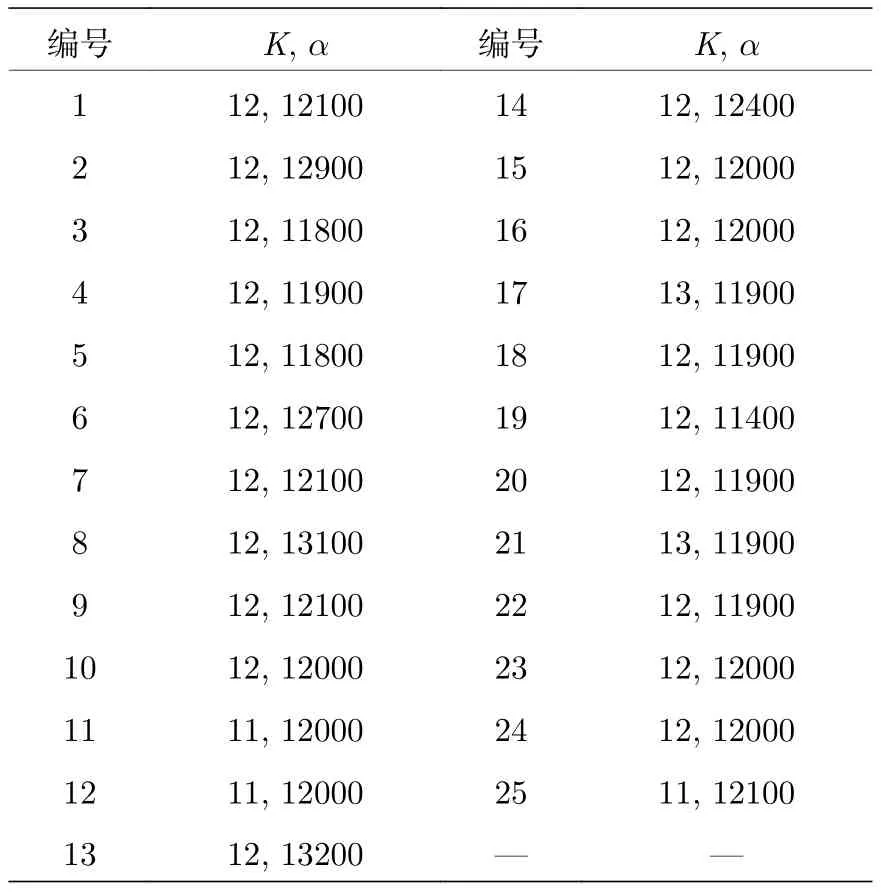
表1 ORVMD參數組合Table 1.Parameter set of ORVMD.
由圖10可知,改進的ORVMD算法在計算時間上比傳統VMD所需時間少,雖然平均耗時僅減少12.5%—18.5%,但由于ORVMD在處理信號時調用PSO算法以獲取最優懲罰因子的過程占用較大計算資源,因此,認為ORVMD比傳統VMD具有更高分解精度與計算效率.
6 結 論
對于傳統VMD算法需預設分解個數及懲罰因子,提出ORVMD算法,該算法可對目標信號遞歸并獲取確定模態分解數K,并基于PSO算法對懲罰因子α進行尋優取值,獲取最佳預設參數組合.同時,對比分析EMD,EEMD,VMD與ORVMD對非線性信號分解,表明所提出的ORVMD較EMD,EEMD具有更高的精準性.該方法可將物理信息分解至不同頻段,且不產生虛假模態,保證了信號分解的有效性及準確性.并且,與傳統VMD方法相比,ORVMD具有更高的計算效率,效率升幅在12.5%—18.5%之間.此外,還可開展以復信號、分布式信號[28-31]為研究對象的變分模態分解處理效果研究.
猜你喜歡
井岡教育(2022年2期)2022-10-14 03:11:44
小讀者(2020年2期)2020-03-12 10:34:06
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:00
趣味(語文)(2018年1期)2018-05-25 03:09:58
中學生數理化·中考版(2017年12期)2017-04-18 12:55:05
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
學苑創造·A版(2015年6期)2015-07-01 09:00:12
中學生(2015年2期)2015-03-01 03:43:33
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
