無線傳感器網絡中基于節點連通性的機會路由
2019-12-04 03:33:36楊桂松梁聽聽何杏宇
小型微型計算機系統 2019年11期
楊桂松,梁聽聽,何杏宇
1(上海理工大學 光電信息與計算機工程學院,上海 200093)2(上海理工大學 公共實驗中心,上海 200093)
1 引 言
無線傳感器網絡(Wireless Sensor Networks,WSNs)是由隨機部署在監測區域并通過無線網絡連接的大量傳感器節點組成,因其低功耗、低成本、分布式和自組織的特點使得其在軍事、環境、醫療與空間探索等領域得到了廣泛的應用[1].
在無線傳感器網絡通信中,路由算法不僅決定著數據傳輸的路徑,同時也影響著網絡性能[2].然而,傳感器節點通信能力、能量受限和應用環境不穩定等因素的存在,使得實際網絡中的通信鏈路不可靠,因此經常出現節點故障導致網絡不可達和鏈路不可靠導致數據丟失等問題[3,4].例如,文獻[5]對無線鏈路時延和可靠性的模糊性、隨機性以及時變性進行統一建模,來反映真實的鏈路狀態.文獻[6]提出了一種基于全局和局部可靠性的無線傳感器網絡路由協議,該協議中,通過定義節點的中介度和依賴度來分別反映節點的全局可靠性和局部可靠性,其中節點依賴度的定義與相鄰節點之間的鏈路質量有關,在考慮節點的全局可靠性與局部可靠性的同時,保證了數據傳輸的網絡可靠性.
而機會路由也是無線傳感器網絡中數據傳輸可靠性的一種常用的方法,它是由Biswas S和Morris R首次提出的[7],其主要思想是在源節點向目的節點發送數據包的過程中選擇一系列候選轉發節點集,并且為其中的每個節點分配優先級.源節點首先將數據包發送給第一跳候選轉發節點集,在轉發節點集中收到數據包且具有最有優先級的節點將轉發到下一跳候選轉發集,如果數據包已由較高優先級的節點轉發,則較低優先級的節點將丟棄該數據包,按此重復,直到目的節點收到數據包.
目前已有大量的文獻對機會路由進行了研究,比如文獻[8]提出機會路由通過充分利用無線信道的廣播特性,通過多個潛在中繼競爭、自主智能判斷進行下一跳選擇,進而提高吞吐量和傳輸可靠性.文獻[9]利用機會路由算法,中間節點協作以完成分組轉發,提高了傳輸可靠性和網絡吞吐量.文獻[10]提出了一種基于多跳最優位置的機會路由算法,源節點將選擇目標節點附近的鄰居作為候選轉發集,并選擇其間最短距離和最小跳數的路徑.文獻[11]提出節能機會路由,通過組合節點到匯聚節點的距離及其自身的剩余能量,在一維隊列的網絡模型中找到最優的中繼節點位置.
文獻[12]結合機會路由和網絡編碼各自的優勢,不僅在網絡中同時傳輸多個段的數據包,而且提高了網絡吞吐量.文獻[13]提出一種感知服務質量的機會路由協議來選擇轉發集并對其排序,通過實驗驗證該協議在能量效率、延遲和時間復雜度方面都適合于無線傳感器網絡.文獻[14]基于能耗最優傳輸距離和節點剩余能量,構建了聯合優化目標函數,并根據數據包的時間敏感性相應調整發射功率.在文獻[15]中,作者提出了一種基于連通性的節能機會魯棒路由協議,該協議中,在計算數據轉發的預期成本時,它強調高度的網絡連接,以確保網絡的正常運行.文獻[16]針對網絡中節點忙或失效造成的數據丟失,設計了一種基于多路徑的可靠路由協議,將失效路徑上正在轉發的數據轉移到另一條有效的路徑,以保證數據傳輸可靠性.文獻[17]針對傳統的基于地理位置的重傳代價大,節點能耗高等挑戰,提出了一種基于傳輸方向的機會路由算法,即一種新的候選集選擇算法來有效減小機會路由中候選轉發集的大小,進而減少網絡中的通信開銷.
與上述相關工作相比,本文強調節點在數據傳輸中的相鄰節點之間連通性的重要性,旨在選擇具有較大節點依賴指數的節點作為中繼以保證網絡可靠性.而大多數相關工作,例如文獻[10]和文獻[17],在做出路由決策時沒有考慮網絡中節點的連通性.另外,在本文的路由算法設計中,在選擇下一跳節點時,本文不僅考慮了候選轉發集中每個節點的節點依賴指數對網絡可靠性的影響,而且考慮了每個節點在作為候選中繼時對整體網絡可靠性的貢獻大小,最終選定了最優中繼以保證網絡可靠性.
在本文提出的基于節點連通性的機會路由算法中,首先,根據節點間的依賴程度定義了節點依賴指數來量化傳輸數據過程中節點的重要性[18],建立了網絡模型;然后,定義了節點連通性的計算公式,并找到節點的候選轉發集使其能滿足網絡可靠性的要求;最后,通過仿真實驗的性能分析可知,數據傳輸可靠性機會路由使其既能滿足目標可靠性又能降低網絡能耗.
本文的其余部分如下:第2小節描述了使用的網絡模型,第3小節給出了詳細的路由算法的設計思想,所提方案的性能分析在第4小節展示,第5小節總結了本文的工作.
2 網絡模型
本文的目標是利用機會路由的思想在無線傳感器網絡中設計可靠的機會路由算法,找到合適的候選轉發集并設定候選轉發集節點的優先級別.
源節點S把數據包以廣播方式發送后,可能有多個鄰居節點接收到數據包,只是因為節點間鏈路不可靠的因素導致了各節點間節點連通性的差異.為了計算任意兩點間的節點連通性,我們定義了節點依賴指數(Dependency Index,DI),以找出無線傳感器網絡中節點i與其鄰居j之間連通率P的關系.節點DI表示節點和其鄰居之間的依賴關系,以量化每個節點在轉發包的過程中對傳遞過程的重要性.當其他節點較多地依賴于該節點接收數據包時,此節點的重要性增加.
節點i與其鄰居j之間的依賴程度在其相應的節點連通性的影響下,與它們之間交換包的數量有關,則DIij的計算公式如下:
(1)
其中,Reci表示i擁有的所有數據包,Sendi表示i發送出去的數據包,SendS表示S發送出去的數據包,Recj表示j擁有的所有數據包.
基于上述定義,當鄰居j接收到節點i發出的所有數據包,并且j沒有接收到i未發送的數據包時,可以看出i和j之間有較高的依賴性.公式(1)的基本原理是,如果發送者對鄰居具有更高的依賴性,則表明發送者的其他鄰居不能以更高的概率轉發來自它的數據包.
針對節點i和其鄰居j之間的依賴指數DI的基本性質及三種可能情況,我們定義了其與網絡中節點連通性Pij相對應關系的三條規則,即網絡中所有節點及其鄰居均滿足以下三條規則:
規則1:若DIij=0,i和j之間的節點連通性Pij=0;
規則2:若DIij=1,i和j之間的節點連通性Pij=1;
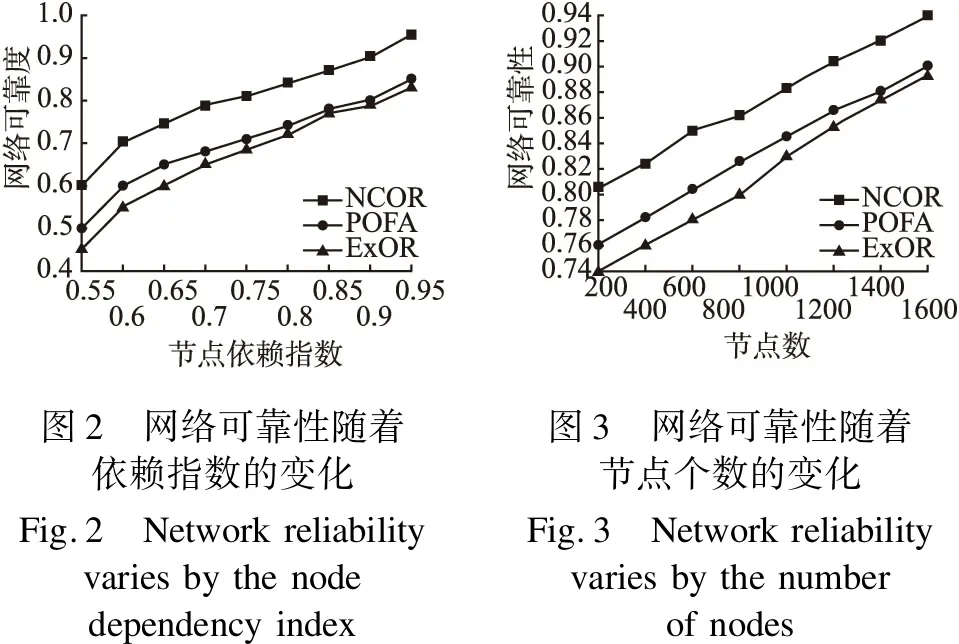
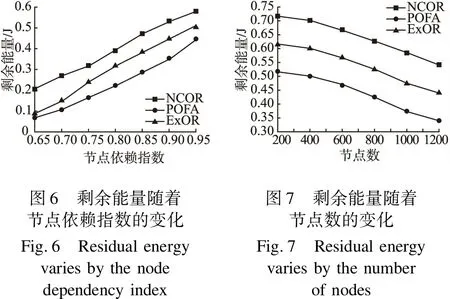
規則3:若0 Pij=αP0·DIij+(1-α)P0 (2) 其中α是權重系數. 根據以上規則,無線傳感器網絡的拓撲結構可以表示為基于節點依賴指數的加權圖,假設節點間兩兩通信且相互獨立,節點間依賴指數遵循其與節點連通性的三條規則. 通過以上網絡模型的建立及其相關定義,我們可以計算出模型中任意兩點間的節點連通性,之后利用其性質,進行節點候選轉發集的選擇以及優先級排序. 源節點S有數據包要發送到目的節點D,假設i為當前節點,記錄其所有鄰居jx及位置信息.首先將鄰居根據自身與目的節點的距離大小降序排列,記為Dist(jx,D),即節點jx與目的節點之間的距離,并且指定距離越小的節點優先進行判斷,有如下假設: Dist(j1,D)≥Dist(j2,D)≥… (3) 根據每對節點間節點連通性的計算,我們選擇候選轉發集的主要步驟如下. 步驟1.首先將i到jX的節點連通性記為PijX=pijX,將節點jX加入到i的候選轉發集listi中.從剩下的節點jx(x=1,2,3,…,X-1)中選出一個節點,按照距離優先的原則選定節點jX-1,此時從i經過jX-1到達jX的路徑連通性如下: PijX-1jX=pijX-1·pjX-1jX (4) 步驟2.若PijX≥PijX-1jX,則設定i與jX-1之間的直接鏈路不可靠,即進行如下操作: Pmax=PijX (5) 否則,則步驟3; 步驟3.則設定i與jX之間的直接鏈路不可靠,即進行如下操作: Pmax=PijX-1jX (6) 步驟4.按照距離優先的原則從剩下的鄰居jx(x=1,2,3,…,X-2)中選出節點jX-2,用同樣的方法判斷i經過jX-2到達jX的路徑連通性PijX-2jX,與之前選出的Pmax進行比較,同樣,較小的一方則設置所選中間節點與jX之間不可靠. 從i的所有鄰居節點jx(x=1,2,3,…,X)選出一個最大的路徑連通率的中間節點時,需要做(X-1)次判斷,假定找到的中間節點為jmax,即從節點i的鄰居集合中任選一個節點加入到點i到jX路徑中的情況下,選定節點jmax的路徑連通性PijmaxjX最大,并將其加入到候選轉發集Listi中,并將除jmax之外的其他鄰居節點與i之間的直接鏈路都設定為不可靠. 步驟5.若X=max,則說明從節點i到節點jX路徑上,在i的鄰居集合中沒有合適的節點可供選擇,則候選轉發集的選擇結束,為Listi={jX};否則,步驟6; 步驟6.令i=max(1≤max≤X-1),返回步驟1; 根據以上步驟,我們選定了節點i的候選轉發集Listi,此時i進行數據傳輸時,可實現的網絡可靠性如下: (7) 圖1中,節點i有4個鄰居節點j1,j2,j3,j4,任意兩點間的節點連通性已經給出,如圖1(a)所示.首先,將節點j4加入到候選轉發集Listi={j4}中,有pij4=0.4.按照距離優先的原則,將鄰居j3加入到路徑中,路徑連通性Pij3j4=0.3×0.9=0.27<0.4,則將j3與i之間的直接鏈路設定為不可靠.之后, 將節點j2加入到路徑中,路徑連通性有Pij2j4=0.8×0.6=0.48>0.4,故i與j4之間的直接鏈路設定為不可靠.將節點j1加入到路徑中,路徑連通性Pij1j4=0.7×0.5=0.35<0.4,故j1與i之間的直接鏈路設定為不可靠. 經過上述步驟,將節點j2加入到候選轉發集Listi={j4,j2},如圖1(b)所示.接下來需要在j2和j4之間找到連通性最大的路徑,有pj2j4=0.6.先將節點j3加入到j2與j4之間的路徑,路徑連通性Pj2j3j4=0.7×0.9=0.63>0.6,故將j2與j4之間的直接鏈路設定為不可靠.之后將j1加入,有路徑連通性Pj1j2j4=0.9×0.6=0.54<0.6,將j1與j2之間的直接鏈路設定為不可靠,選定節點j3加入到j2與j4之間的路徑,如圖1(c)所示. 節點j3加入到候選轉發集Listi={j4,j2,j3},需要判斷j3和j4之間連通性最大的路徑,有pj3j4=0.9,將節點j1加入到其路徑中有Pj1j3j4=0.6×0.9=0.54 < 0.9,令j1與j3之間的直接鏈路為不可靠,如圖1(d)所示.最后,i與j4之間連通性最大的路徑已經確定為i-j2-j3-j4,此時i的候選轉發集Listi={j4,j3,j2}.因此,根據公式(7),節點i進行數據傳輸時,可實現的網絡可靠性為Ri=1-(1-0.8)×(1-0.3)×(1-0.4). 基于節點連通性的機會路由算法偽代碼如下. 算法1.基于節點連通性的機會路由算法 1.輸入:節點i和鄰居jx(x=1,2,…,X); 2. 初始化:listi=null; 3. 按照鄰居與目的節點之間的距離大小降序排列,記為{j1,j2,j3,…,jX}; 4.for(n=1;n<=X;n++) 5. 計算pijX; 6.Pmax=PijX; 7.for(m=X-1;m<=1;m--) 8. 計算PijmjX=pijm·pjmjX;//公式(3) 9.if(PijmjX>Pmax) 10.Pmax=PijmjX;//公式(6) 11.endif 12.endfor 13. //選擇候選轉發集 14.listi=listi∪{jm}; 15.if(PijX==Pmax) 16. break; 17.else 18.i=jm; 19.endif 20. end for 21. 計算網絡可靠性Ri;//公式(7) 22.while(Nodeibroadcaststhepackets) 23. sort the listlistiin increasing order based on the distance node and the destination node; 24.for(k=1;k<=|listi|;n++) 25.if(Thekth node inlistireceived the packets from nodei) 26. Thekth node is selected as the next hop to forward the packets; 27. The other nodes inlistiwill drop the packets; 28.end 29.endfor 30.endwhile 我們的模擬實驗在MATLAB下進行.在該模擬中,傳感器節點在網絡區域中隨機部署.本文中,我們將提出的基于節點連通性的機會路由算法NCOR與POFA路由算法[19]和ExOR路由算法[7]進行比較,分別評估其在網絡可靠性和能耗方面的性能.部分參數選擇如表1所示. 表1 實驗室的網絡環境參數 參數取值檢測區域范圍(0,0)-(400,400)m節點通信半徑30m節點個數200,400,600,800,1000,1200初始化能量1J節點依賴指數0.55,0.6,0.65,0.7,0.75,0.8,0.85,0.9,0.95εamp0.0013Pj/bit/m4εfs10Pj/bit/m4數據包大小512bytes傳輸速率1MbpsMACIEEE802.11 在圖2中,所有算法的網絡可靠性均隨著節點依賴指數的增加而增加,且NCOR優于其他路由算法.原因是節點之間的依賴指數的增加說明節點之間包的交互增加,而包交互和鏈路質量緊密相關,這直接提高了節點之間的連通性,也因此提高了網絡可靠性.POFA僅使用預期的傳送概率度量來選擇一些能夠保證可靠性的節點作為下一跳以確保網絡可靠性. 圖3中,我們驗證了節點數的變化對網絡可靠性的影響,當節點數量在200到1600之間增加時,與POFA和ExOR算法相比,NCOR實現的網絡可靠性較高,而且隨著節點個數的增加,網絡可靠性曲線呈現上升趨勢.因為節點數量的增加,增加了節點間的連通性,提高了節點成功傳輸數據包的概率,進而改善了網絡可靠性.如圖3所示,隨著網絡中節點數的增加,POFA算法所實現的網絡可靠性總是優于ExOR算法.事實上,POFA是一種改進的泛洪算法,其主要思想就是在傳輸數據包的過程中,可以充分選擇收到數據包的節點作為中繼完成數據包的傳輸,而隨著網絡中節點個數的增加,參與數據包的傳輸的節點數也隨之增加,因此,相較于ExOR算法,POFA算法能獲得較高的網絡可靠性. 能耗是指網絡在數據傳輸過程中節點消耗的總能量,能耗越小,說明算法在綜合情況下的能量消耗越小. 圖4中,隨著節點依賴指數的增加,所有算法的能耗均呈現下降趨勢.從節點依賴指數的定義可知,它與相鄰之間數據包的交互有關,而包的交互受到節點間鏈路質量的影響,因此,節點依賴指數越大,說明鏈路質量較好,因此保證了數據包的可靠傳輸,降低了節點的能耗. 圖5說明的是網絡中能耗隨著節點個數的變化趨勢,NCOR的能耗相較POFA和ExOR較低,且POFA的能耗高于ExOR.ExOR算法的中繼是由候選轉發集中的節點的競爭產生,每個接收者依據它在列表里的位置在發送確認包之前延遲一段時間,各個節點查看收到的確認包集合來決定是否轉發包.在ExOR算法每一次路由中繼選擇的過程中,均會選擇一個最優的節點進行數據包的傳輸,而在POFA算法中,收到數據包的節點均可被中繼節點繼續數據包的傳輸過程,且隨著節點依賴指數或者網絡中節點數的增加,該過程造成了大量的冗余傳輸,產生大量的消耗.因此,相比于POFA算法,ExOR算法的能耗較低. 剩余能量對網絡生命周期有直接影響,如果具有較少剩余能量的節點總是被選為中繼節點,則它將很快耗盡,造成網絡壽命大幅度減少.因此,圖6和圖7分別驗證了節點依賴指數以及網絡中的節點數對節點的剩余能量的影響.在該實驗中,我們記錄了多輪源節點與目的節點之間所有中繼節點的剩余能量,并以所有節點在所有輪次中的剩余能量的平均值作為輸出結果,最終得到了剩余能量隨著節點依賴指數以及節點數的變化趨勢. 如圖6所示,隨著節點依賴指數的增加,三種算法中所呈現的剩余能量均為上升趨勢,其中,隨著節點依賴指數的增加,NCOR的剩余能量一直高于ExOR和POFA算法,而且POFA算法中節點的剩余能量要低于ExOR算法.根據公式(2)中的定義,我們可知,節點依賴指數越大,則相鄰節點間的連通性則越來越好,在該相鄰節點之間的數據包成功傳輸概率也越來越高,因此節省了冗余傳輸帶來的節點傳輸數據包所消耗的能量,即節點本身的剩余能量隨著節點依賴指數的增加而增加. 圖7中,隨著網絡中節點個數的增加,三種算法中的剩余能量均呈現下降趨勢,其中,隨著節點個數的增加,NCOR的剩余能量一直高于ExOR和POFA算法,而且POFA算法中節點的剩余能量要低于ExOR算法. 經驗證,隨著節點數的增加,相對于其他兩種算法,NCOR算法的性能一直保持最優狀態,受到網絡密度的影響較小,而且與經典的機會路由算法ExOR相比,NCOR算法的性能較優.POFA算法是對傳統泛洪算法的一種改進,其最大的缺點仍然是隨著節點個數的增加,參與數據包傳輸的節點也隨之增加,因此造成了網絡中大量冗余數據包的傳輸,因此其節點的剩余能量加速減少. 在本文中,我們提出了一種基于節點連通性的機會路由算法,該算法在選擇候選轉發節點時考慮了相鄰節點之間的節點連通性,以保證數據傳輸的可靠性.仿真結果表明,該算法在網絡可靠性和網絡能耗方面優于現有的經典路由算法.未來的研究工作是設計一種更可靠的路由算法,促進傳感器節點之間的協同工作,保證數據傳輸中更高的節點可靠性,如使用信譽補償將數據傳輸到其他更合格的節點[20].3 路由算法
≥Dist(jX-1,D)≥Dist(jX,D)4 性能分析
Table 1 Network environment parameters

5 總 結
