利用改進的MajorClust算法實現異常用戶行為定位
2019-12-04 03:33:36羅文華
小型微型計算機系統 2019年11期
羅文華,張 艷
(中國刑事警察學院 網絡犯罪偵查系,沈陽 110035)
1 引 言
檢測數據集中的異常是一項至關重要的任務,在安全、財務、司法等領域具有高影響力的應用.傳統入侵行為檢測的目的在于及時發現網絡或系統中存在的違反安全策略的行為和被攻擊的跡象,以便積極主動地進行安全防護.基于此類目的的入侵檢測技術更加側重于實踐通用性,強調利用模式特征通過統計分析、數據挖掘、機器學習等方法予以實現[1],通常并不針對特定類型的主機及網絡日志進行深入剖析.信息技術的飛速發展催生了層出不窮的新型犯罪,隨著涉網犯罪案件的逐年增多,很多情況下需要將行為痕跡轉化為電子證據.傳統檢測技術難以在發現入侵跡象的同時,精準定位嫌疑人的犯罪行為,無法完整重現犯罪過程并構建證據鏈條,在日漸增多的司法應用需求面前顯得力不從心.因此,將數據集的內容特征與語義情境納入證據考量范疇就顯得尤為必要.
聚類分析是常用的異常檢測方法,其實質是把整體數據集按照特定規則劃分為若干數據子集,劃分于同一子集中的數據擁有更多的相似性.以典型聚類算法K-Means為例,該算法首先會選定k作為最終確定的簇數目,先是隨機生成K個簇并選定各簇中心,之后將節點分配給離其最“近”的簇中心,通過迭代完善簇中心及簇中的節點,最終實現理想的分類效果.該算法的優勢在于實現簡單,并在處理大規模數據時展現出較高效率,成為目前應用最為廣泛的聚類算法之一[2].但也存在諸多缺陷,如K值需事先給定,但實踐中卻難以估計.另外,中心的選擇是隨機的,處理結果可能每次并不完全相同,確定最佳處理結果由此成為難題.K-Means過于注重針對節點進行考慮,卻忽略了對圖形自身屬性(如權重與規模)的考量,特別是在不同類別間不存在確切邊界的情況下,K-Means之類的算法無法取得理想的聚類效果.
MajorClust是1999年由Benno Stein與Oliver Niggemann發明的基于密度的聚類算法[3],目前已發展成為無監督文檔聚類中最有前途和最成功的算法之一.MajorClust能夠自動地對數據進行分類,不必像K-Means算法那樣事先給定簇的數目,而是通過計算簇間節點的聯結度,進而改變簇的形狀以提升聚類效率.該算法根據“最大吸引制勝”原則,以邊權重為量度將節點迭代傳到簇中.首先初始集中的每個點會被分配到其原始所屬的簇中;在重新標記步驟中,在其“鄰居的加權和最大值”范圍內的節點使用相同的簇標簽;如果存在多個滿足條件的簇,則隨機選擇其中一個;直到沒有節點再需要改變其簇成員資格,算法結束.其在聚類推導過程中,由于只考慮節點的鄰居,從而擁有了良好的運行時效率.
MajorClust也并非十全十美,由于其總是忽略諸如連通性之類的全局準則,因此并不能保證總是找到最優解.特別是應用于行為證據發現時,單次MajorClust的處理結果顯得較為粗糙,對于異常行為抽象出的規律不夠明顯,也無法快速準確定位核心關鍵節點.但MajorClust側重于對圖形自身屬性進行考量的特性卻為進行行為檢測提供了嶄新的思路.為此特意對原有的MajorClust算法進行了改進,實驗結果表明改進后的算法不僅能夠檢測數據對象中是否有異常行為的存在,同時還可以實現關鍵異常點的準確定位,從而滿足更為深入具體的司法取證需求.
Hudan Studiawan、Christian Payne等人改進了Majorcluter[4]:通過使用改進的Marjorcluter來實現聚類,并對聚類結果中的每個簇計算異常參數,引入閾值來檢測異常,但在判斷入侵行為存在的同時卻無法實現關鍵行為信息的定位.
本文對Marjorcluter算法進行了進一步改進,著重強調了如何在異常檢測的同時實現異常行為的定位.本文按如下結構進行組織,除“引言”部分外,在第1節將介紹基于取證需求的數據集處理方法與注意事項,并說明了數據節點相似度計算的具體步驟;第2節重點說明改進MajorClust算法的原因與具體方法;第3節描述如何通過閾值的設定進行異常行為的檢測;第4節依靠找尋簇中心點實現核心證據的定位;第5節總結了本文的主要工作,并提出了未來研究的方向.
2 數據集預處理與相似度計算
與傳統行為檢測強調功能通用性不同[5],司法取證強調的是對象針對性,需要結合具體的格式、內容甚至語義特征才能挖掘出真正有價值的信息.數據集的深入分析有助于提升聚類乃至異常入侵檢測的準確性,以Linux操作系統環境下的用戶認證日志auth.log1SecRepo.com: Security Data Samples Repository. URL:http://www.secrepo.com/.為例,其通常包含有日期(date)、時間(time)、進程名稱(process name)與ID(PID)、主機名稱(hostname)以及具體的事件(event)信息,異常入侵行為會在其中(特別是事件信息)表現出較強的特征.表1描述了當非法用戶嘗試越權登陸系統時其操作可能表現出的行為特征.
從表1可以看出事件信息會對行為予以充分描述,提供了更為充分的線索幫助在海量信息中進行行為檢測.同時因為事件信息中有的已經包含了日期、事件、用戶名等,因此考慮將數據集中每條記錄作為節點[6],并以節點中的事件內容作為聚類主要依據,進而實現異常行為檢測.
表1 auth.log中的異常行為特征
Table 1 Abnormal behavior characteristics in auth.log

特點說明事件信息示例用戶操作通常具有關聯性與順序性嫌疑人嘗試用戶認證,系統會記錄連接失敗Invaliduserxxxfromxxxinput_userauth_request:invaliduserxxxReceiveddisconnectfromxxx:ByeBye用戶操作多次重復且時間連續嫌疑人會嘗試通過不同的用戶登錄系統Dec2302:41:39ip-172-31-27-153sshd[7463]:InvaliduserPlcmSpIpfrom218.77.121.69Dec2302:41:48ip-172-31-27-153sshd[7465]:Invaliduservyattafrom218.77.121.69Dec2302:41:51ip-172-31-27-153sshd[7467]:Invaliduserubntfrom218.77.121.69服務器與用戶產生交互用戶多次無效登陸,服務器會反向檢查地址信息Invaliduserftpuserfrom211.72.198.126reversemappingcheckinggetaddrinfofor211-72-198-126.hinet-ip.hinet.net[211.72.198.126]failed-POSSIBLEBREAK-INATTEMPT!
傳統方式在預處理時會把字符串中出現的常見詞作為停用詞(Stopword)去掉.實驗發現,基于MajorClust算法的聚類分析[7]受停用詞的影響較大,需要針對特定的日志內容選擇其適合的停用詞.圖1所示即為處理auth.log數據集時是否將單詞“from”作為停用詞的處理結果比較.當“from”作為停用詞時,數據集的處理結果顯示只形成了一個由數目眾多的節點構成的聚類(圖1(a));但當“from”不作為停用詞時,數據集卻形成了兩個類似的聚類(圖1(b)),從而直接影響了后續的處理分析.因此在確定停用詞時,除傳統選擇外,對于不能認定效果的停用詞最好通過實驗驗證后再抉擇.本文所討論的預處理是將preauth、from、for、port、sshd、ssh、root作為停用詞并連同日期、時間一并去除.日期、時間等雖然信息暫時不在聚類的考慮范疇內,但在后續的異常檢測及閥值設定中會重新綜合曾經被忽略的信息.
之后使用TF-IDF算法計算每個節點的數字表征.對于特定詞w,其在記錄r中詞頻被定義為該詞在記錄中出現的次數與該記錄中所有詞出現的總次數之商,即tfw,r=tf/len(r).常規的逆文檔頻率定義為數據集中的記錄總數與微調后包含該詞的記錄數之商的對數,即idfw=log(N/dfw+1).此處分母之所以需要加1,目的在于規避特定詞不在語料庫內而出現的除數為0情況.基于收集證據與線索目的的聚類分析針對的是具體日志內容,不會出現特定詞存在于語料庫范圍之外的情況,在此將逆文檔頻率計算進行簡化,即idfw=log(N/dfw).分別計算完tfw,r與idfw之后,再依據公式TF-IDF=tfw,r*idfw計算每個節點的表征.
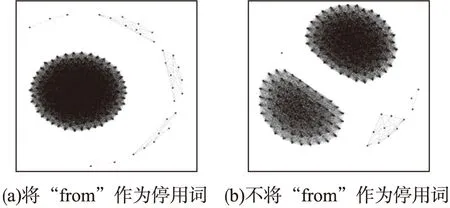
圖1 停用詞的不同造成處理結果的巨大差異Fig.1 Differences in stop words cause huge differences in processing results
鑒于節點事件信息中語句長度通常較短,由此采用cos相似度計算方法,依據節點表征得到節點間的相關系數[8].之后利用相關系數構造圖G=
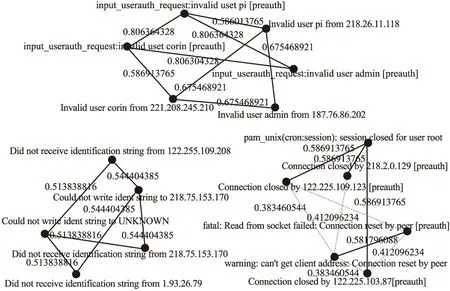
圖2 依據cos相似度算法計算事件節點間的相關系數Fig.2 Calculating the correlation coefficient between event nodes based on the cos similarity algorithm
3 MajorClust算法的逐步改進
傳統的MajorClust算法強調依靠權重實現節點聚合,逐次迭代篩選目標數據集中擁有最大權重和的節點,并將其與直接連接的節點形成聚類.但這種算法存在一個明顯缺陷就是,擁有最大權重和的節點往往可能是因為其個別連接邊的權重大,強制了其他與該節點關聯并不緊密的節點被聚類于該節點,由此對異常檢測的判斷造成嚴重干擾.為此需要通過提供額外的要求來改進MajorClust算法,即當前群集與最重的鄰居節點不同時,強制節點跟隨最重的群集.在找尋到權重和最大的節點之后,如果存在對權重和起絕對影響的邊,則將該邊對應的節點單獨聚類,其方程式如下:
(1)
其中s是考慮附加檢查的當前簇,h是具有最大邊權重的鄰居節點,并且s(h)是h的簇標簽,si是第i個簇,s*是具有最大權重的聚合.通過這樣部署,事件將僅跟隨最相似的事件,而不是跟隨其他那些并不非常相似但卻被強制關聯的事件.
經初步改進后,節點間的關系得到進一步明確,強關聯的事件被聚合成簇.但由此卻引發了另一問題,即聚類后的生成的簇中節點數量過少,往往只有2到3個,很難基于這樣的聚類挖掘行為模式.為此針對圖形進一步凝練,將簇抽象為單一節點,節點的事件內容為原有簇中節點事件內容的最長子句.比如原有簇由三個節點組成,事件信息分別為“Invalid user admin 221.208.245.210”、“Invalid user admin 187.12.80.202”、“Invalid user admin 122.205.109.208”,則其新抽象出的節點事件信息即為“Invalid user admin”;之后再對二次生成的圖形依據第1節算法做MajorClust處理,進而得到關于事件關系的新圖示.抽象的同時要保留原有節點的屬性信息,以便追溯使用;節點處理之后即被標記,之后便轉入其他節點的處理,從而保證了在有限步驟內完成圖形處理.
改進的MajorClust算法完整步驟描述如下:
輸入:日志記錄集L;
輸出:聚類處理之后生成的若干簇;
Step 1.根據日志記錄集的“事件”域進行去重,只取去重后的“事件”域生成新的記錄集Ln;
Step 2.依據TF-IDF算法計算數據集Ln中每個節點的數字表征;
Step 3.根據節點的數字表征計算節點間的cos相關系數,并將相關系數作為權重賦值給節點之間的連接邊;
Step 4.計算每個節點與其他節點的連接邊權重之和,并篩選出擁有最大權重和的節點;
Step 5.將該節點與其最大權重邊對應的節點聚類,如果存在多條邊的最大權重相等,則將這些節點一同聚類;
Step 6.將已完成聚類的節點從數據集Ln中去除,針對剩余的節點循環Step4與Step5直至目標函數收斂;
Step 7.生成的每一個聚類都使用一個節點來替代,節點的內容信息為聚類中“事件”信息的“最長子串”;
Step 8.針對抽象出的節點使用TF-IDF算法其數字表征;
Step 9.根據數字表征計算節點間的cos相關系數,將相關系數作為權重賦值給節點間的連接邊,生成最終的圖形.
圖3所示即為Security Repository數據集中2014年11月30日當天的日志記錄最終處理結果.基于事件信息處理后形成了多個簇,其中節點數量最多的簇由含有“invalid user”子串的日志記錄組成,含有“pam_unix(cron:session)”字樣的記錄構成的簇中節點數量是最少的,只有兩個節點.關聯度高的事件聚類之后,便可通過算法檢測與閾值設定判別事件中是否存在異常.
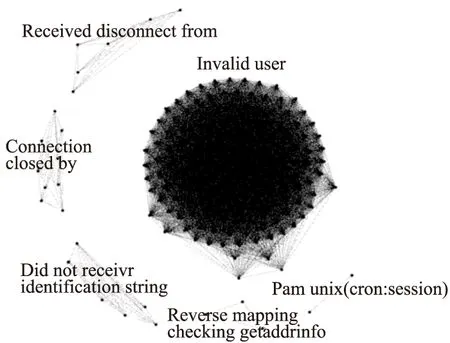
圖3 改進的MajorClust算法處理2014年11月30日當天日志記錄的最終結果Fig.3 Improved MajorClust algorithm to process the final results of the log on November 30,2014
4 異常檢測與閾值設定
聚類時只重點針對事件內容信息進行了考察,在確定是否存在異常時則需要將事件的時間間隔、頻度納入考量范疇.有的檢測方法依靠聚類中節點的數量推斷是否有異常存在[9],但這種方法能夠適用的現實場景較少,并且未涉及至關重要的時間因素.異常行為事件組成的簇總是在特定方面體現出與正常行為簇的不同,傳統觀點認為異常簇中節點的數量一定會小于正常的簇,但實驗發現并非如此.因此不能單純依靠節點數量判斷是否存在異常,節點數目過多或過少都有可能是異常行為造成的結果[10].
為更準確地進行異常檢測,需要針對兩次MajorClust聚類處理后生成簇的頻率進行深度分析.簇中每個節點在原始數據集中的出現頻度是易得的(即出現次數之和除以總記錄數),將簇的頻度μc定義為簇中節點頻度之和與節點對應事件之和的商,這樣定義的μc在一定程度上表現出該簇整體上的頻度特征.鑒于μc未將時間因素納入考量,由此定義簇的到達區間(Inter-arrival)比率Ic為簇中節點頻度之和與簇的整體時間間隔(即末次事件發生時間與首次事件發生時間之差,以秒計)之商.在μc與Ic的基礎上將簇的異常參數定義為:
(2)
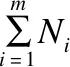
?′=(?-Min?)/(Max?-Min?)
(3)
依照前述計算步驟,針對Security Repository數據集中前20天的日志記錄運用改進的MajorClust算法進行了處理,得到當日每個簇的異常參數值.實驗發現,invalid user 、received disconnect from 以及reverse mapping checking getaddrinfo for failed-possible break-in attempt!這三類事件的異常參數大于其他事件的概率較大;connection closed和pam_unix(cron:session):session for user root這兩類事件的異常參數通常很小.事實上,這也符合日常經驗的認知,非法用戶往往通過不斷地連接與登陸嘗試實現系統入侵[11].
表2 異常參數最高與次高的事件類型及具體參數值
Table 2 Highest and second highest event type and specific parameter value of the abnormal parameter
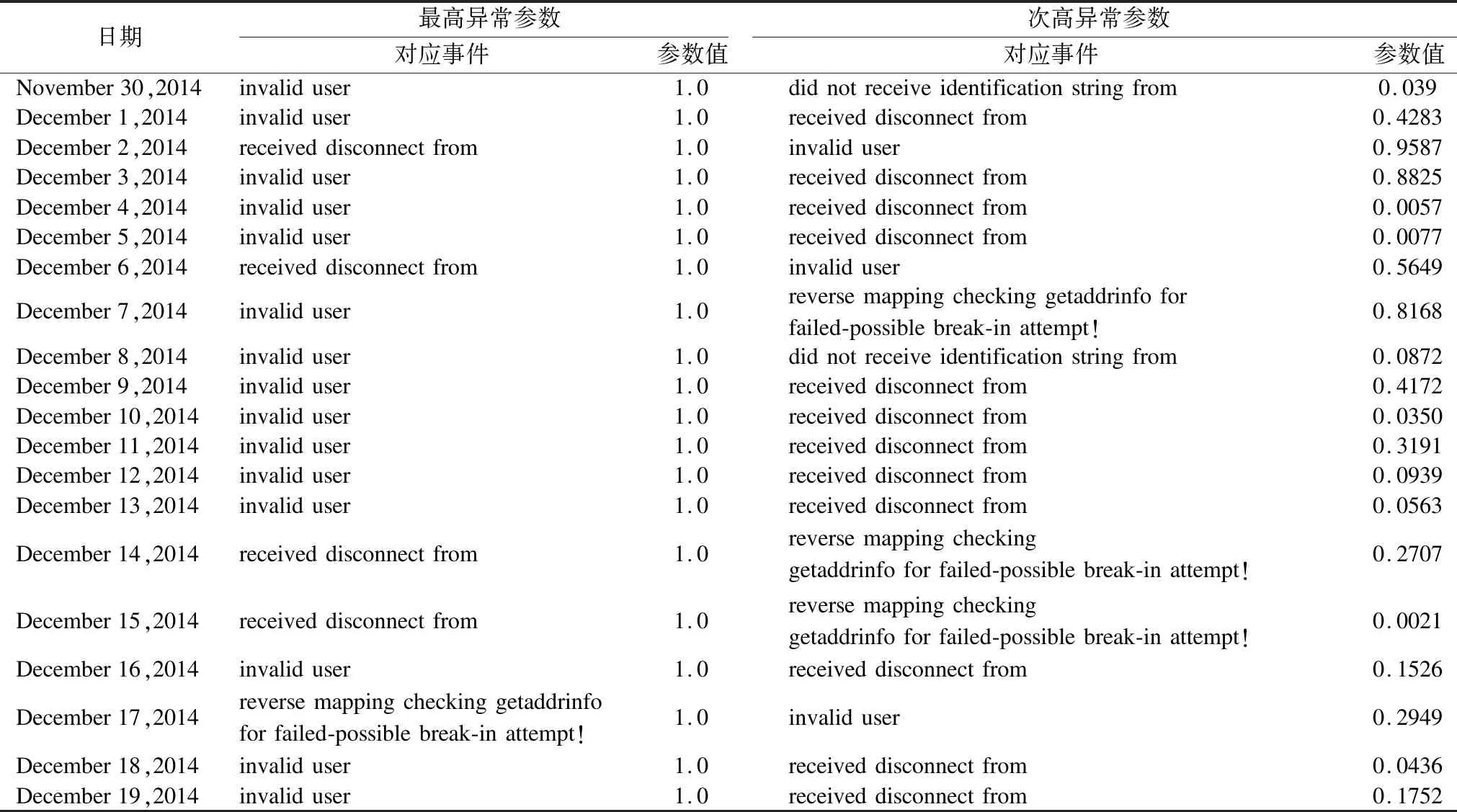
日期最高異常參數次高異常參數對應事件參數值對應事件參數值November30,2014invaliduser1.0didnotreceiveidentificationstringfrom0.039December1,2014invaliduser1.0receiveddisconnectfrom0.4283December2,2014receiveddisconnectfrom1.0invaliduser0.9587December3,2014invaliduser1.0receiveddisconnectfrom0.8825December4,2014invaliduser1.0receiveddisconnectfrom0.0057December5,2014invaliduser1.0receiveddisconnectfrom0.0077December6,2014receiveddisconnectfrom1.0invaliduser0.5649December7,2014invaliduser1.0reversemappingcheckinggetaddrinfoforfailed-possiblebreak-inattempt!0.8168December8,2014invaliduser1.0didnotreceiveidentificationstringfrom0.0872December9,2014invaliduser1.0receiveddisconnectfrom0.4172December10,2014invaliduser1.0receiveddisconnectfrom0.0350December11,2014invaliduser1.0receiveddisconnectfrom0.3191December12,2014invaliduser1.0receiveddisconnectfrom0.0939December13,2014invaliduser1.0receiveddisconnectfrom0.0563December14,2014receiveddisconnectfrom1.0reversemappingcheckinggetaddrinfoforfailed-possiblebreak-inattempt!0.2707December15,2014receiveddisconnectfrom1.0reversemappingcheckinggetaddrinfoforfailed-possiblebreak-inattempt!0.0021December16,2014invaliduser1.0receiveddisconnectfrom0.1526December17,2014reversemappingcheckinggetaddrinfoforfailed-possiblebreak-inattempt!1.0invaliduser0.2949December18,2014invaliduser1.0receiveddisconnectfrom0.0436December19,2014invaliduser1.0receiveddisconnectfrom0.1752
表2列出了20天記錄中異常參數最高與次高的事件類型及其對應的異常參數(因為已對異常參數做了標準化處理,所以最高異常參數值總為1).從表2可以看出,擁有最高異常參數的事件多為“invalid user”,之后是“received disconnect from”和“reverse mapping checking getaddrinfo for failed-possible break-in attempt!”;另外,次高的異常參數變動幅度較大,從0.0021跨越到0.9587.傳統異常檢測只是考量單一事件的異常參數是否超過預設閾值,但事實上異常行為所催生的事件往往是相互關聯的,真正有威脅的事件產生時必然會引發多個事件的.因此綜合考慮多個事件的異常參數將更有利于提升檢測的準確度.如果某日的次高異常參數大于0.5,則該日出現異常入侵行為的概率是極大的.
5 通過簇中心點定位關鍵證據
判斷出存在異常行為之后,需要挖掘出重點異常事件與核心證據線索.雖然根據閾值可以推測哪個簇存在異常行為的可能[12],但異常簇往往由多個節點構成,很多情況下節點數量會超出人工分析所能承受的范圍.為此需要進一步確定簇的中心點以實現快速準確定位關鍵證據或線索的目的[13].選擇三種類型的節點作為簇中心點的備選,分別是簇中頻率最高的節點、到達率最高的節點以及MajorClust算法核心處理的節點(即鄰邊權重之和最大的節點).在Security Repository數據集的30天記錄中共出現了6次次高異常參數大于0.5的情況,表3梳理出了這6天記錄形成的“invalid user”簇中三種類型節點的分布情況.
實驗發現,雖然頻率最高的節點與鄰邊權重之和最大的節點(即改進MajorClust算法核心處理節點)的計算依據完全不同,但算出的節點指向卻出現了重合,由此可以把此類節點當作簇的中心點予以著重關注.在改進MajorClust算法進行處理時已經保留了鄰邊權重之和最大的節點信息,因此無需再另行計算頻率最高的節點,即可實現關鍵證據的定位.
表3 三種類型節點在“invalid user”簇中的分布情況
Table 3 Distribution of three types of nodes in the "invalid user" cluster

日期頻率最高達到率最高鄰邊權重之和最大December 2,2014input_userauth_request:invalidusertest[preauth]invalidusernagiosfrom218.25.17.234input_userauth_request:invaliduseruser[preauth]December 3,2014input_userauth_request:invaliduseradmin[preauth]input_userauth_request:invaliduseradmin[preauth]input_userauth_request:invaliduseradmin[preauth]December 6,2014input_userauth_request:invalidusertest[preauth]invalidusertestfrom61.197.203.243input_userauth_request:invalidusertest[preauth]December 7,2014input_userauth_request:invaliduseradmin[preauth]input_userauth_request:invaliduserftp_user[preauth]input_userauth_request:invaliduseradmin[preauth]December20,2014input_userauth_request:invaliduseradmin[preauth]invaliduserxbmcfrom211.25.49.250input_userauth_request:invaliduseradmin[preauth]December21,2014input_userauth_request:invaliduseradmin[preauth]input_userauth_request:invaliduserpostgres[preauth]input_userauth_request:invaliduseradmin[preauth]
表4 異常參數最高與異常參數次高簇的核心節點的信息相互印證
Table 4 Information of the cluster core node with the highest abnormal parameter and the second highest abnormal parameter is mutually confirmed
異常參數最高與異常參數次高簇的核心節點還可以實現相互印證關系,如在invalid user簇中確定出的具體用戶名信息也會體現在其他簇的核心節點中,同時其他記錄內容的獨立性還會輔助提供IP等重要信息.具體情況如表4所示.
6 總結與展望
異常行為檢測一旦涉及特定的記錄內容分析挖掘,勢必會增添大量的額外工作量[14],以至于目前并未得到廣泛的現實應用.但本文的實驗結果充分說明在面向司法應用的取證分析中,針對內容與語境的分析至關重要,有助于快速準確地定位關鍵證據或線索.傳統步驟往往是在探測到異常行為之后,再針對可疑數據集進行深度分析,以發現核心異常點.使用改進后的MajorClust算法不僅可以判斷出異常行為是否存在,并在處理過程中能夠自動篩選出最核心的證據與線索,以滿足司法應用需求.在關聯度計算的基礎上,經過兩次MajorClust算法處理更精準地挖掘出了記錄間的關系,綜合多個簇的異常參數實現了異常行為的檢測,并通過簇核心點的定位,在海量記錄中挖掘出最有價值的信息.同時,本論文提出的方法并沒有沿襲傳統的以單一異常參數進行判定的思路,而是基于異常行為之間的關聯特性連帶次高異常參數予以綜合判斷,進一步提升了檢測結果的可信度.
本論文雖然以Auth日志為處理分析對象,但所描述的方法也適用于多種操作系統環境下的其他類型日志.論文實驗則主要依托自編的Python腳本實現,使用了Python自帶的函數及插件功能[15].處理時間主要消耗在計算事件記錄相似度、第一次MajorClust抽象、基于“最長子句”生成新節點、第二次MajorClust抽象等四個步驟.實驗證明這些步驟的計算時長與數據增長呈線性關系,其中“第一次MajorClust抽象”這個環節最為耗時,在Intel Core I7-6500U及8GB RAM的硬件條件下處理10萬條以上的記錄消耗時間需要以小時計,未來需要進一步完善數據結構與優化算法,以提升處理效率.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
