深度學習與人臉識別算法研究
2019-11-14 08:17:47張卓群曹鐘淼王慧劉洪普
軟件 2019年9期
張卓群 曹鐘淼 王慧 劉洪普

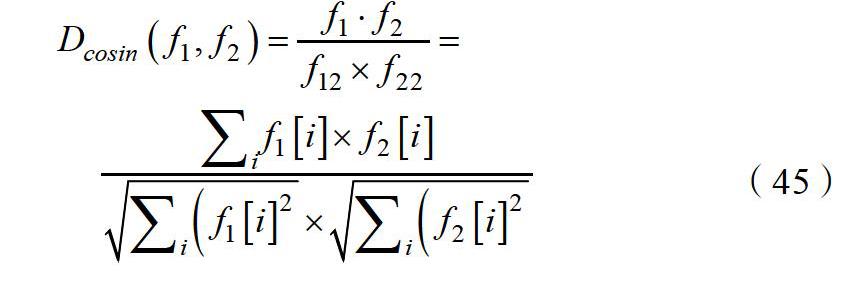

摘 ?要: 目前人臉識別技術已經得到了較多的應用,包括在安檢工作、金融工作以及交通等領域中,其穩定性強、識別精度高,市場應用前景廣闊,能夠為用戶信息的識別提供更便捷的服務。隨著對人臉識別研究的深入,出現了更多的算法,最初大多都是提取淺層特征來進行分析,并采用特征融合的方式識別,在最后的識別過程中主要利用了聯合貝葉斯分布等機器學習分類器進行處理。這種方法雖然能夠達到一定的識別效果,但是精度不高,容易受到多種外部因素(光照、遮蓋等)的影響,降低了識別結果的準確性。本文主要對人臉識別的框架進行了研究與分析,首先設計了人臉識別框架,然后對深度學習人臉識別算法的幾個重要組成部分進行了分析與研究,主要包括人臉對齊模塊、人臉特征提取、人臉識別驗證模塊等。
關鍵詞:?:人臉識別;人臉對齊; 人臉特征提取;深度學習
中圖分類號:?TB302.6????文獻標識碼:?A????DOI:10.3969/j.issn.1003-6970.2019.09.046
本文著錄格式:張卓群,曹鐘淼,王慧,等. 深度學習與人臉識別算法研究[J]. 軟件,2019,40(9):199-204+208
Research on Deep Learning and Face Recognition Algorithms
ZHANG Zhuo-qun, CAO Zhong-miao, WANG Hui, LIU Hong-pu*
(Hebei University of Technology, Tianjin 300000)
【Abstract】: At present, face recognition technology has been applied widely, including security, financial and transportation fields, which can provide convenient services for user information recognition for its strong stability, high recognition accuracy and broad market application prospects. With deepening research on face recognition, more and more algorithms have emerged. At first, most of them extract shallow features for analysis, and recognize based on feature fusion. During final recognition process, carry on process with machine learning classifiers such as Joint Bayesian Distribution. Although the method can achieve some certain recognition effect, it has less accuracy for being influenced by variety of external factors (illumination, occlusion, etc.). The paper studies and analyzes framework of face recognition. Firstly, it designs framework of face recognition. Secondly, its analyzes and studies several important parts of deep learning face recognition algorithm, including face alignment module, face feature extraction, face recognition verification module and etc.
【Key words】: Face recognition; Face alignment; Face feature extraction; Deep learning
0??引言
目前人臉識別技術已經得到了較多的應用,包括在安檢工作、金融工作以及交通等領域中,其穩定性強、識別精度高,市場應用前景廣闊,能夠為用戶信息的識別提供更便捷的服務。
隨著對人臉識別研究的深入,出現了更多的算法,最初大多都是提取淺層特征來進行分析,并采用特征融合的方式識別,在最后的識別過程中主要利用了聯合貝葉斯分布等機器學習分類器進行處理。這種方法雖然能夠達到一定的識別效果,但是精度不高,容易受到多種外部因素(光照、遮蓋等)的影響,降低了識別結果的準確性。
深度學習(Deep Learning,DL)最早來源于神經網絡的研究,但是目前仍沒有形成明確的定義。深度學習可以建立與人腦相似的神經網絡,便于按
照人腦的方式對不同類型的數據進行處理。深度學習采用簡單的表達形式來描述復雜問題,使得復雜的問題簡單化。隨著學者在機器學習算法研究方面的投入,深度學習算法得到了較大的發展,基于人腦工作方式進行分析,能夠實現對圖像、文本等數據類型的處理。深度學習需要逐步使用模型輸出逼近預期的結果。從這個角度來說可以對實際輸出結果與預期目標結果的偏差進行分析,并將其應用到對權重矩陣的更新中。除了在數據處理方面的應用,深度學習算法還在生物學、地理學以及油氣勘探等領域到獲得了較多的應用。尤其是隨著云計算技術以及深度學習理論的進一步發展,未來深度學習將會有更廣闊的應用前景,能夠為人們帶來更多高質量的計算服務[1]。深度學習算法逐步應用到了更多的領域中,特別是在圖像處理以及人臉識別方面,很多研究人員設計了不同的人臉識別算法,并利用LFW等數據集驗證了算法能夠達到的效果。深度學習算法的優勢在于能夠提升人臉識別過程中的抗干擾能力,其主要是提取圖像的高層次特征,從圖像全局來獲取最本質的特征信息,降低了人臉表情變化以及光線等因素的影響,提升了識別結果的準確性。從這個角度來說,人臉識別其實是一種特征提取問題,基于深度學習的人臉識別技術具有廣闊的應用前景。
1??深度學習算法相關研究
1.1神經網絡概述
神經元的具體結構即為圖1中所示,其是神經網絡內的最小單元,一個神經元內包括多個組成要素,例如有閾值、激活函數、權值以及輸入輸出等,利用突觸連接權值![]() 可以對各個神經元之間的連接強度進行表示,其值有正有負,如果是正值[2-5],則說明神經元的狀態是激活的,相反的說明神經元處于未激活狀態。利用加法器可以對各個輸入的總效果進行分析,由于不同的神經元在作用強度方面具有一定的差異性,可以將其對后一個神經元的總作用效果表示為神經元的線性加權之和。采用激活函數能夠有效地對神經元的輸出進行控制,使其保持在正常的范圍內,這個范圍一般是[-1,1]或者是[0,1]。具體結構如下。
可以對各個神經元之間的連接強度進行表示,其值有正有負,如果是正值[2-5],則說明神經元的狀態是激活的,相反的說明神經元處于未激活狀態。利用加法器可以對各個輸入的總效果進行分析,由于不同的神經元在作用強度方面具有一定的差異性,可以將其對后一個神經元的總作用效果表示為神經元的線性加權之和。采用激活函數能夠有效地對神經元的輸出進行控制,使其保持在正常的范圍內,這個范圍一般是[-1,1]或者是[0,1]。具體結構如下。
圖中![]() 表示神經元的輸入,
表示神經元的輸入,![]() 表示兩個神經元
表示兩個神經元![]() 的連接權值,,
的連接權值,,![]() 分別代表的是閾值與輸出,
分別代表的是閾值與輸出,![]() 代表激活函數。假定
代表激活函數。假定![]() 表示輸入信號的加權之和,可以將神經元結構表示為如下:
表示輸入信號的加權之和,可以將神經元結構表示為如下:
![]() (1)
(1)
![]() (2)
(2)
代入之后可以得到
 ? ?(3)
? ?(3)
假定![]() ,代入上述公式得到
,代入上述公式得到
 (4)
(4)
將![]() ,
,![]() 代入可以得到公式
代入可以得到公式
![]() ? (5)
? (5)
所以有
![]() ? (6)
? (6)
1.2 ?RBF神經網絡
RBF代表的是徑向基函數方法,這種方法最初主要用于對多變量的插值問題進行處理,即在輸入變量與輸出變量之間獲取一個滿足特定條件的非線性函數![]() ,輸入變量與輸出變量分別表示為
,輸入變量與輸出變量分別表示為![]() ?
?![]() 與
與![]() ,
,![]() 的形式如下所示:
的形式如下所示:
![]() ? (7)
? (7)
上述公式代表的是一個插值曲面,Lowe 等人利用徑向基函數方法對神經網絡進行了設計,并得到了RBF神經網絡,輸入與輸出之間的映射關系即為公式(7)中所描述。
已知空間點集合![]() ,點數目為N,
,點數目為N,![]() 表示n維向量,對應的實數集可以表示為
表示n維向量,對應的實數集可以表示為![]() ,二者的映射關系可以表示為如下公式:
,二者的映射關系可以表示為如下公式:
![]() ,
,![]() ? ?(8)
? ?(8)
在選取N個基函數之后,可以計算其線性加權之和,即得到![]()
![]() ??? (9)
??? (9)
公式中的![]() 代表基函數,
代表基函數,![]() 即為基函數j的中心,
即為基函數j的中心,![]() 表示X與
表示X與![]() 之間的距離。公式代入之后可以得到如下方程組:
之間的距離。公式代入之后可以得到如下方程組:
![]() (10)
(10)
根據![]() ,可以將上述公式表示成
,可以將上述公式表示成
 (11)
(11)
對上述矩陣進行簡化之后得到
![]() (12)
(12)
其中![]() 表示一個插值矩陣,其大小為
表示一個插值矩陣,其大小為![]() ,
,![]() 與
與![]() 分別表示權值矩陣與輸出矩陣。如果
分別表示權值矩陣與輸出矩陣。如果![]() 是可逆的,可以得到
是可逆的,可以得到
![]() (13)
(13)
根據Micchelli定理可知,當![]() 完全不同時,
完全不同時,![]() 滿足可逆條件。
滿足可逆條件。
1.3?BP神經網絡
反向傳播的詳細過程如下所示:第一步是對神經網絡進行構建,并任意設置各個神經元的權重;接著需要對輸入模式進行設置,并得到網絡的輸出值,然后將其與預期輸出值進行對比,分析其差值是否達到了預期的標準。根據其差值對權重進行調節,直到二者的差值足夠小,也就是實際輸出接近于預期輸出。按照這種方式開始從輸出層向輸入層逐層逆推,逆推到首個隱含層時結束。詳細的計算過程如下所示[6]。
首先設置輸入樣本數目為p,分別表示為![]()
![]() ,所有樣本輸入完成之后,可以得到輸出
,所有樣本輸入完成之后,可以得到輸出![]() ,此時的樣本誤差可以表示為
,此時的樣本誤差可以表示為
![]() (14)
(14)
其中![]() 代表的是期望輸出。根據這種方式可以得到網絡的全局誤差,其公式如下所示
代表的是期望輸出。根據這種方式可以得到網絡的全局誤差,其公式如下所示
![]() (15)
(15)
權值變化的計算公式如下所示
 (16)
(16)
信號誤差的計算公式如下所示
![]() (17)
(17)
將公式14代入上述公式可以得到
 ?(18)
?(18)
![]() ?? (19)
?? (19)
在公式17中代入18,19可以得到如下
![]() ?? ?(20)
?? ?(20)
 ?? (21)
?? (21)
輸出層神經元的權值調整公式如下所示
![]() ? (22)
? (22)
隱含層權值變化如下所示
 ?? (23)
?? (23)
誤差信號公式如下
![]() ?? ?(24)
?? ?(24)
 ? (25)
? (25)
其中
![]() ??? ?(26)
??? ?(26)
第二項是
![]() ?? (27)
?? (27)
因此可以得到
![]() ??? ?(28)
??? ?(28)
 ? (29)
? (29)
此時隱含層的權值調整公式如下
![]() (30)
(30)
2 ?人臉識別算法框架設計
人臉識別算法框架主要用于對人臉特征的提取,人臉識別算法框架模塊即為圖2中所示,其中含有多個模塊,例如有人臉對齊、特征提取以及特征運用等模塊。按照各個模塊的作用順序,首先是人臉對齊模塊,主要用于原始圖像的預處理工作,確定其中的人臉關鍵點,根據預期尺寸獲取對應大小的人臉圖像。其次是人臉特征提取模塊,此模塊主要用于特征提取的具體過程,包括模型的構建與訓練等過程。最后是人臉特征運用模塊,此模塊要考慮到具體的應用場景來設計具體的算法,例如有人臉身份識別以及驗證等。
在本文中主要研究基于深度學習的人臉識別算法,相對于其他的算法,主要是在特征提取方面存在一定的差異性,其能夠有效地提取人臉更本質的特征,通過此類特征的提取能夠降低表情以及遮蓋等因素的影響,而這也屬于其明顯的優勢之處。因此很多學者已經開始在基于深度學習的人臉識別算法方面進行了研究和改進,使得算法效果進一步優化[7]。
3??人臉識別算法
3.1 人臉對齊模塊的算法設計
首先對人臉對齊模塊算法進行設計,經過分析后本次研究中主要采用了Zhang設計的MTCNN人臉對齊算法,這種算法主要基于人臉檢測與人臉對齊過程中的關聯性,并設計了對應的卷積神經網絡,然后通過FDDB測試集以及WIDERFACE測試集進行了算法測試,最終得到了令人滿意的效果。
3.2 人臉特征提取模塊的算法設計
在人臉識別算法中的核心部分是特征提取模塊,也是影響最終識別效果的關鍵因素。在特征提取模塊中,核心部分是網絡模型與損失函數,通過對二者的合理設計能夠提升人臉特征的提取效果,并獲得更多高層本質特征,以降低外部干擾產生的影響。模型的訓練過程依賴于損失函數,因此必須對損失函數進行合理地設計,這是影響人臉特征提取效果的關鍵因素。在設計損失函數時應該考慮到人臉基本的特征向量特性,一個是相同類內的特征差異性小,相似度高;另一個是不同類的特征相似度小,差異性大[8]。
3.3 深度網絡模型的設計
首先需要設計合理的深度網絡模型,模型質量高低將會顯著影響到人臉識別的性能。為了能夠提取到高層的、本質的認證,則要保證特征提取模塊達到更高的要求,具體是在網絡模型設計與損失函數設計中保持較高的水準,由此才能降低光線、表情等因素對特征提取的影響。
經過分析,在本次研究中最終采用了選擇Inception-?ResNet模型,其應用的具體過程如下所示:首先對FaceID層的人臉特征維度進行設置,并得到Softmax層的神經元數目。在模型中主要含有15層,分布是卷積層、池化層、FaceID層、Softmax多分類層,其中其中卷積層、池化層主要為前13層,并交替出現,而最后兩層分別是FaceID層、Softmax多分類層。在本次研究中的前13層采用了Inception-?ResNet取代。
3.4模型損失函數的設計
損失函數是影響特征提取效果的重要因素,在模型訓練過程中,力求得到損失函數最大或者最小時的參數,以此作為最佳的參數。在網絡訓練前首先要選擇合適的損失函數,并將其應用到對類間、類內差異性的控制中。
為了描述特征的差異性,則一般采用距離度量的方式,即根據特征之間的距離來分析其相似度,最終在相同的類中都是相似度較高的特征,而不同類的特征相似度較小。常用的度量距離包括L2/L1范式距離、歐氏距離、馬氏距離、余弦距離等,其中L2范式距離已經較多的應用到了人臉識別以及聚類等領域中,因此在本次研究中直接采用了L2范式距離來提取人臉識別的特征。
對于類間差異最大化來說,能夠達到較高的人臉區分性,從而識別不同的人臉特征;類內差異最小化則指的是在相同環境中的特征相似度描述更準確,綜合兩種方法提升了人臉識別的精度。另外考慮到人臉特征匹配的效率問題,還應該具備緊湊性、稀疏性特征,所以必須保證損失函數的合理性,使其在特征提取中達到更佳的效果。目前常用的損失函數包括Softmax函數、Triplets Loss等。
對于Softmax多分類損失函數來說,將其應用到人臉特征提取時,能夠保證各個人臉圖像特征的差異性最大化,以此提高對不同人臉識別的準確性。在對人臉圖像進行判定時,可以通過人臉驗證方法分析各個人臉圖像是否屬于相同的人,在這個過程中需要通過人臉驗證監督信號來對網絡參數學習過程進行調節,添加驗證監督信號后有助于降低特征的類內差異性[9]。
3.4.1 ?Softmax損失
在本次研究中主要采用了SoftmaxLoss函數,即在網絡中添加一個新的Softmax分類器層,以此提升模型參數的訓練效果,有助于實現類間差異的最大化。
目前在多分類問題中已經普遍采用了Softmax Loss函數,多分類問題的類標簽y取值類型較多。已知訓練集的樣本數目為m,具體是![]()
![]() ,輸入特征
,輸入特征![]() ,特征向量x維度大小是n+1,其中x0=1時即為截距項,
,特征向量x維度大小是n+1,其中x0=1時即為截距項,![]() 。
。
如果已知輸入x,函數![]() 對于不同類別j的概率值表示為
對于不同類別j的概率值表示為![]() ,因此可以假定函數輸出屬于k維向量代表k個估計的概率值,對應的元素總和等于1。
,因此可以假定函數輸出屬于k維向量代表k個估計的概率值,對應的元素總和等于1。![]() 具體如下所示:
具體如下所示:
 (31)
(31)
公式中![]() 均為模型參數。考慮到計算的方便性,可以直接采用矩陣形式表示θ,其大小是K×(n+1),矩陣具體的形式如下所示:
均為模型參數。考慮到計算的方便性,可以直接采用矩陣形式表示θ,其大小是K×(n+1),矩陣具體的形式如下所示:
 (32)
(32)
根據![]() 函數,得到基于對數似然的損失函
函數,得到基于對數似然的損失函![]() ,其形式如下所示:
,其形式如下所示:
 (33)
(33)
在公式中,![]() 。
。
為了求解![]() 的最小化問題,選擇使用迭代方法求解,由此將其梯度公式表示為:
的最小化問題,選擇使用迭代方法求解,由此將其梯度公式表示為:
 (34)
(34)
迭代的方式如下所示:
![]() (35)
(35)
一般要將權重衰退添加到代價函數中,以此更好的解決冗余參數集的問題,此時的代價函數如下所示:
 (36)
(36)
添加權重衰退![]() 之后,能夠保證代價函數的解是唯一的。此時的梯度函數形式如下所示:
之后,能夠保證代價函數的解是唯一的。此時的梯度函數形式如下所示:
 (37)
(37)
3.4.2 ?驗證損失
在特征提取的過程中要利用到驗證信號,其主要用于對特征距離進行監督,具體是監督多個個體圖像特征間的最大距離,相同個體圖像特征間的最小距離,當前在度量特征間距離的方法有多種,例如有歐式距離、L2范式距離等,在本次研究中最終采用了L2范式距離。
這里主要使用了![]() 描述特征提取的過程,
描述特征提取的過程,![]() 代表的是特征提取函數,原始輸入圖像即為x,
代表的是特征提取函數,原始輸入圖像即為x,![]() 表示網絡參數,
表示網絡參數,![]() 表示人臉特征層輸出。
表示人臉特征層輸出。
所以可以將驗證信號![]() 表示為:
表示為:
 (38)
(38)
公式中![]() 、-1時分別代表
、-1時分別代表![]() 屬于相同個體與不同個體兩種情況。
屬于相同個體與不同個體兩種情況。![]() 表示學習參數,在設置時需要保證樣本達到最小的驗證誤差,只要個體間的特征向量距離不等于閾值m,
表示學習參數,在設置時需要保證樣本達到最小的驗證誤差,只要個體間的特征向量距離不等于閾值m,![]() 則不會形成損失值;而相同個體的特征向量距離都是損失值。
則不會形成損失值;而相同個體的特征向量距離都是損失值。
另外基于余弦距離的人臉驗證監督信號如下所示:
![]() (39)
(39)
公式中![]() ,
,![]() 表示學習參數,σ表示sigmoid激活函數。
表示學習參數,σ表示sigmoid激活函數。
4??人臉驗證算法設計
在提取特征之后需要繼續進行人臉驗證的過程,此過程依賴于合理的驗證算法,可以確定人臉圖像是否來自于相同的個體。但是在實際應用中,驗證算法并不是固定的,而是應該考慮到不同的人臉特征屬性進行設計,并形成適用性不同的驗證算法。在距離度量方面可以采用范式距離或者是其他距離,以此評價特征向量的差異性,此時可以直接設置對應距離的閾值,并完成人臉驗證的過程。目前常用的度量距離主要包括Ll范式距離、L2范式距離、余弦距離等類型,而在實際應用中應該綜合考慮到損失函數的形式等因素,據此選擇最合適的距離度量策略。在實際應用中通過需要先通過PCA實現降維,接著利用SVM或者是加權卡方距離等完成分類的過程[10]。
經過上述處理過程后,可以將人臉特征x劃分為兩部分,具體公式表示為:
![]() (40)
(40)
其中μ表示內部本質變量,并且有![]() ,ε代表外部的差異性變量,并且有
,ε代表外部的差異性變量,并且有![]() 。所以聯合貝葉斯的聯合概率分別表示為
。所以聯合貝葉斯的聯合概率分別表示為![]() 、
、![]() ,其高斯分布方差矩陣如下所示:
,其高斯分布方差矩陣如下所示:
![]() 和
和
![]() (41)
(41)
根據公式(41)可以計算出人臉驗證的概率值。
![]() (42)
(42)
加權卡方距離x2的公式如下所示
 (43)
(43)
公式中的![]() 代表權重值,一般利用線性SVM方法計算。
代表權重值,一般利用線性SVM方法計算。
另外還可以采用加權L1距離、余弦距離兩種計算策略,
在本文的人臉驗證中,主要采用了L2距離閾值的方法實現,其公式如下所示。
![]() (44)
(44)
5??結語
目前人臉識別技術已經得到了較多的應用,包括在安檢工作、金融工作以及交通等領域中,其穩定性強、識別精度高,市場應用前景廣闊,能夠為用戶信息的識別提供更便捷的服務。
參考文獻
- 陸化普. 智能交通系統主要技術的發展[J]. 科技導報, 2019, 37(06): 27-35.
- 田會娟, 劉歡, 郝甜甜, 張輝. 基于視覺舒適度的LED背光顯示器最優亮度控制模型[J]. 天津工業大學學報, 2019,
- 38(1): 83-88.
- 陳鳳萍, 齊建華. 旋轉不變紋理特征在圖像模式識別中應用仿真[J]. 計算機仿真, 2019, 36(2): 353-356.
- 翟正利, 梁振明, 周煒, 孫霞. 變分自編碼器模型綜述[J]. 計算機工程與應用, 2019, 55(3): 1-9.
- 劉建伯, 婁洪亮. 基于改進LeNet-5的油井井號識別方法[J]. 自動化技術與應用, 2019, 38(1): 75-80.
- 黃佳男. 機器人表情識別與模擬研究[D]. 浙江大學, 2019.
- 徐靜妹, 李雷. 基于稀疏表示和支持向量機的人臉識別算法[J]. 計算機技術與發展, 2018, 28(2): 59-63.
- Zhendong Wu, Zipeng Yu, Jie Yuan, Jianwu Zhang. A twice face recognition algorithm[J]. Soft Computing, 2016, 20(3).
- YILihamu YAErmaimaiti. A new Uyghur face recognition algorithm[J]. Journal of Interdisciplinary Mathematics, 2018, 21(5).
- 張嘉凱, 楊成, 劉里. 基于文本CNN的電影推薦系統的研究與實現[J]. 軟件, 2019, 40(3): 18-25.
- 邢益良. 一種基于SL4A的智能臥室門系統[J]. 軟件, 2019, 40(3): 34-37.
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
計算機工程(2015年8期)2015-07-03 12:19:07
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年23期)2014-02-27 14:19:15
