基于粗糙集理論的模糊聚類算法研究
2019-11-14 08:17:47張紅霞吳桐桐冷雪亮
軟件 2019年9期
張紅霞 吳桐桐 冷雪亮
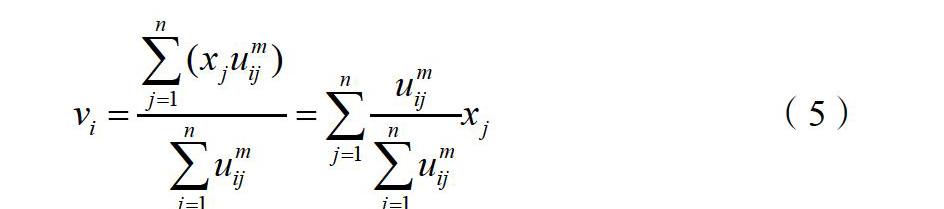

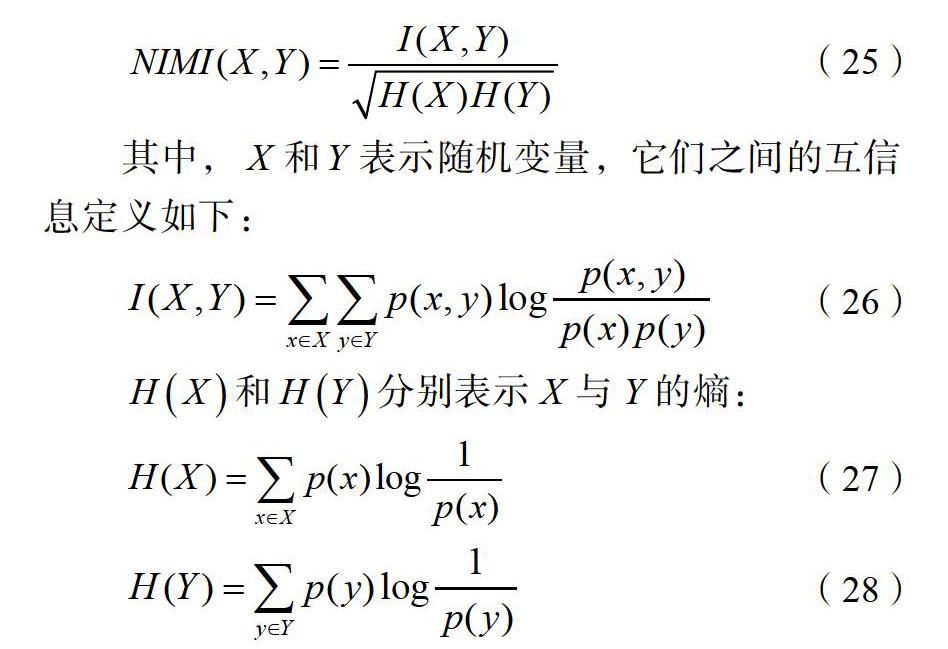
摘 ?要: 粗糙集理論是一種新型的處理含糊不確定知識的數學工具,善于分析隱藏在數據中的事實而不需要關于數據的任何附加知識,粗集理論不僅為信息科學和認知科學提供了新的科學邏輯和研究方法,而且為智能信息處理提供了有效的處理技術。聚類是作為數據挖掘系統中的一個模塊,既可以作為一個單獨的工具以發現數據庫中數據分布的深層信息,也可以作為其他數據挖掘分析算法的一個預處理步驟。模糊聚類算法忽略了聚類邊界不確定的問題和復雜數據問題從而導致聚類效果不理想。本文提出了將粗糙集和模糊聚類算法相結合,利用粗糙集中上近似集和下近似集的概念得到相似性度量來改進模糊聚類算法。實驗證明,改進的算法能夠得到更好的聚類效果。
關鍵詞:?粗糙集;模糊聚類;上近似;下近似
中圖分類號: TP301.6????文獻標識碼:?A????DOI:10.3969/j.issn.1003-6970.2019.09.036
本文著錄格式:張紅霞,吳桐桐,冷雪亮. 基于粗糙集理論的模糊聚類算法研究[J]. 軟件,2019,40(9):156-163
Research on Fuzzy Clustering Algorithm Based on Rough Set Theory
ZHANG Hong-xia,?WU Tong-tong,?LENG Xue-liang
(College of Computer and Information, Shandong University of Science and Technology, Qingdao?266000,?China)
【Abstract】: Rough set theory is a new mathematical tool for dealing with vague and uncertain knowledge. It is good at analyzing the facts hidden in the data without any additional knowledge about the data. Rough set theory not only provides new scientific logic and research methods for information science and cognitive science, but also provides effective processing technology for intelligent information processing. Clustering is a module in the data mining system. It can be used as a separate tool to discover the deep information of data distribution in the database, or as a pre-processing step of other data mining analysis algorithms. The fuzzy clustering algorithm ignores the problem of cluster boundary uncertainty and complex data problems, which leads to the unsatisfactory clustering effect. This paper proposes to combine the rough set and the fuzzy clustering algorithm, and use the concept of the approximate set and the lower approximation set on the rough set to obtain the similarity measure to improve the fuzzy clustering algorithm. Experiments show that the improved algorithm can get better clustering effect.
【Key words】: Rough set; Fuzzy clustering; Upper approximation; Lower approximation
0??引言
聚類分析按照不同的標準有不同的劃分,按照數據樣本隸屬度的取值范圍劃分,可以將聚類分析方法分為兩類,一類叫硬聚類分析,另一類叫軟聚類分析,也叫模糊聚類分析。硬聚類是一種嚴格地劃分,旨在將每一個數據樣本劃分到一個確定的簇中,劃分機制非常明確,其隸屬度只有兩個值0和1,也就是說,一個樣本只能完全屬于某一個類或者完全不屬于某一個類。例如,將小于或者等于40歲的人劃分為年輕,大于40歲的人劃分為不年輕,那么不管是39歲還是9歲,都屬于年輕類,這就是典型的“硬隸屬度”概念,這種聚類方法過于嚴格,對于一些位于邊界處的數據對象不是很友好,容易產生誤差。軟聚類對于數據對象的劃分比較寬容,它是依據數據樣本隸屬度的大小,將其劃分到不同的簇。比如30歲,可能屬于年輕這類的隸屬度值為0.7,而屬于不年輕這個類的值為0.3,這樣劃分就比較合理。另外,當隸屬度的值只取0或1時,模糊聚類就變成了硬聚類。通過介紹,可以看到模糊聚類獲得的聚類結果具有不確定性,它將聚類結果進行了模糊化,這樣就能夠對現實世界中的數據劃分問題進行更加客觀的描述,因此模糊聚類分析已成為聚類研究的主流方向之一。
本文算法結合了粗糙集[1-3]等理論,提出了基于粗糙集理論的模糊聚類算法。該算法是通過粗糙集理論最終得到一個隸屬值,然后,用表示的抑制率乘以非獲勝者所屬類簇的隸屬度值,以修改模糊隸屬度,從而在一定程度上增加獲勝者的隸屬度值。通過實驗表明該算法能夠解決原始算法中的缺點,并且還能提高聚類的準確率和減少花費的時間。
1 ?相關工作
1.1模糊C均值聚類算法原理
模糊C均值聚類算法是目前應用最廣泛的軟聚類[4-5]算法之一,該算法利用目標函數來解決數據樣本的聚類問題,把聚類的過程轉化成帶約束的優化問題,因此可以借助數學領域中經典的非線性規劃理論對其進行求解。
假設數據樣本集合![]() ,
,![]() 是樣本個數,已知該數據集共有
是樣本個數,已知該數據集共有![]() 類,聚類任務就是希望把
類,聚類任務就是希望把![]() 中的所有數據對象劃分到
中的所有數據對象劃分到![]() 個類
個類![]()
![]()
![]() 中,每個類都有一個唯一的聚類中心,聚類中心集合為
中,每個類都有一個唯一的聚類中心,聚類中心集合為![]() 。那么,模1糊C均值聚類算法可以表示為下面的數學規劃問題:
。那么,模1糊C均值聚類算法可以表示為下面的數學規劃問題:
![]() (1)
(1)
且滿足:
 (2)
(2)
其中,![]() 是數據樣本
是數據樣本![]() 屬于某一類
屬于某一類![]() 的隸屬度。隸屬度的值越大則說明數據樣本
的隸屬度。隸屬度的值越大則說明數據樣本![]() 屬于
屬于![]() 類的可能性越大,反之則可能性越小。
類的可能性越大,反之則可能性越小。![]() 是模糊劃分矩陣,從模糊劃分矩陣[6]-[8]中可以找到每個數據樣本相對于每個類簇的隸屬度值;樣本
是模糊劃分矩陣,從模糊劃分矩陣[6]-[8]中可以找到每個數據樣本相對于每個類簇的隸屬度值;樣本![]() 與第
與第![]() 個類類中心的相似性大小,用歐氏距離計算,記為
個類類中心的相似性大小,用歐氏距離計算,記為![]() ;
;![]() 是模糊權重指數,也稱為模糊因子,改變它的取值能對模糊類之間的分享程度進行調節。模糊聚類算法的聚類過程就是目標函數公式(1)的求解過程。目標函數中有兩個未知的量,分別是
是模糊權重指數,也稱為模糊因子,改變它的取值能對模糊類之間的分享程度進行調節。模糊聚類算法的聚類過程就是目標函數公式(1)的求解過程。目標函數中有兩個未知的量,分別是![]() 和
和![]() ,采用拉格朗日乘數法和求導公式對式(1)求解,可以得到下面的結果:
,采用拉格朗日乘數法和求導公式對式(1)求解,可以得到下面的結果:
 (3)
(3)
 (4)
(4)
觀察上式可以發現,![]() 與
與![]() 是相互關聯的,彼此包含對方。在模糊聚類算法開始的時候,通常人為賦值給
是相互關聯的,彼此包含對方。在模糊聚類算法開始的時候,通常人為賦值給![]() 或者
或者![]() 其中的一個,只要數值滿足約束條件即可,然后就可以根據公式開始迭代更新。例如,假設給
其中的一個,只要數值滿足約束條件即可,然后就可以根據公式開始迭代更新。例如,假設給![]() 賦值,有了
賦值,有了![]() 就可以計算
就可以計算![]() ,得到
,得到![]() 后又可以根據此
后又可以根據此![]() 去計算新的
去計算新的![]() ,如此反反復復。在這個過程中,目標函數J一直在變化,最后逐漸趨向穩定值。那么,當J不再變化的時候就認為算法收斂到一個比較好的結果。可以看到
,如此反反復復。在這個過程中,目標函數J一直在變化,最后逐漸趨向穩定值。那么,當J不再變化的時候就認為算法收斂到一個比較好的結果。可以看到![]() 和
和![]() 在目標函數J下構成了一個迭代更新的過程。
在目標函數J下構成了一個迭代更新的過程。
假設計算數據樣本中的樣本1到各個類中心的隸屬度,此時j=1,![]() ,在式(3)中,分母求和公式里的分子
,在式(3)中,分母求和公式里的分子![]() 表示的是數據樣本1相對于某一類
表示的是數據樣本1相對于某一類![]() 的類中心距離,而求和公式的分母
的類中心距離,而求和公式的分母![]() 是這個數據樣本1相對于所有類的類中心的距離的和,因此它們的商表示的就是數據樣本1到某個類中心
是這個數據樣本1相對于所有類的類中心的距離的和,因此它們的商表示的就是數據樣本1到某個類中心![]() 的距離,在樣本1到所有類中心的距離和的比重。當
的距離,在樣本1到所有類中心的距離和的比重。當![]() 越小,說明數據樣本屬于類
越小,說明數據樣本屬于類![]() 的可能性越大,公式1的值就越大,對應的
的可能性越大,公式1的值就越大,對應的![]() 就越大,數據樣本
就越大,數據樣本![]() 就越屬于這個類
就越屬于這個類![]() 。
。
通過上述分析可以知道,當類![]() 確定后,式4的分母求和是一個常數,根據式(4)可以得到聚類中心的更新公式:
確定后,式4的分母求和是一個常數,根據式(4)可以得到聚類中心的更新公式:
 (5)
(5)
對于式(5)通俗的解釋就是,類![]() 確定后,將所有數據樣本點到該類的隸屬度
確定后,將所有數據樣本點到該類的隸屬度![]() 求和,然后對每個點
求和,然后對每個點![]() ,用其隸屬度除以這個和再乘以
,用其隸屬度除以這個和再乘以![]() ,就是這個點對于這個類
,就是這個點對于這個類![]() 的貢獻值。
的貢獻值。
1.2模糊C均值聚類算法步驟
模糊C均值聚類算法首先需要事先確定聚類[9-11]中心,再計算每個數據樣本屬于每個聚類中心的隸屬程度,得到一個隸屬度矩陣;然后根據隸屬度的大小對所有數據樣本進行劃分,得到每個數據樣本的聚類情況,根據最新的劃分,再重新計算每個類的聚類中心。模糊C均值聚類的過程就是通過迭代聚類中心和隸屬度矩陣,直到算法收斂為止。
算法1-1??模糊C均值聚類算法
輸入:數據集![]()
輸出:隸屬度矩陣![]() 和聚類中心
和聚類中心![]()
Step1:對參數進行初始化。給定聚類數目![]() ;模糊因子m=2;隸屬度矩陣
;模糊因子m=2;隸屬度矩陣![]() ,并使其滿足式(2);
,并使其滿足式(2);![]() =0,用來記錄迭代次數;
=0,用來記錄迭代次數;
Step2:根據式(6)更新聚類中心![]()
![]() ;
;
 (6)
(6)
Step3:根據式(7)更新隸屬度矩陣![]()
![]() ;
;
定義3.2 ?給定一個論域![]() 和論域
和論域![]() 上的一個等價關系
上的一個等價關系![]() ,模糊聚類過程中 產生的聚類結果構成一個劃分
,模糊聚類過程中 產生的聚類結果構成一個劃分![]()
![]() ,
,![]() 是與聚類中心
是與聚類中心![]() 劃分為一類的數據樣本的集合,則集合
劃分為一類的數據樣本的集合,則集合![]() 的上近似集為:
的上近似集為:
![]() (10)
(10)
下近似集為:
![]() (11)
(11)
邊界域為:
![]() (12)
(12)
集合![]() 的下近似集為:
的下近似集為:
![]() (13)
(13)
上近似集為:
![]() (14)
(14)
邊界域為:
![]() (15)
(15)
假設數據樣本集合![]() ,數據樣本個數為n,模糊聚類算法要將
,數據樣本個數為n,模糊聚類算法要將![]() 中的所有數據對象劃分到c個類
中的所有數據對象劃分到c個類![]()
![]() 中,每個類都有一個唯一的聚類中心,c個聚類中心的集合為
中,每個類都有一個唯一的聚類中心,c個聚類中心的集合為![]() 。那么RS-SFC算法可以表示為下面的數學規劃問題:
。那么RS-SFC算法可以表示為下面的數學規劃問題:
 (16)
(16)
其中:
![]() (17)
(17)
![]() (18)
(18)
![]() 表示樣本
表示樣本![]() 屬于某一類i的隸屬度,參數
屬于某一類i的隸屬度,參數![]() 和
和![]() 分別表示第i個簇的近似精度和粗糙度,滿足
分別表示第i個簇的近似精度和粗糙度,滿足![]() 。
。
RS-SFC算法基于下近似集和邊界域的加權平均,定義了新的模糊質心更新公式,使其同時考慮模糊隸屬度和上近似集、下近似集的影響。通過對![]() 求解式(16),得到新的模糊聚類中心計算公式為:
求解式(16),得到新的模糊聚類中心計算公式為:
 (19)
(19)
其中:
![]() (20)
(20)
 (21)
(21)
為提高聚類的速度,本文借鑒文獻[75]中提出到的抑制因子![]() 來提高RS-SFC算法的速度,抑制因子
來提高RS-SFC算法的速度,抑制因子![]() 通過引入競爭機制,在保持良好的聚類精度的同時以提高收斂速度。RS-SFC算法在每次迭代更新隸屬度矩陣后,對對象進行抑制,步驟如下:
通過引入競爭機制,在保持良好的聚類精度的同時以提高收斂速度。RS-SFC算法在每次迭代更新隸屬度矩陣后,對對象進行抑制,步驟如下:
對于每個數據對象![]() ,在獲得其新的模糊隸屬度矩陣后,找到模糊隸屬度矩陣中最大的模糊隸屬度
,在獲得其新的模糊隸屬度矩陣后,找到模糊隸屬度矩陣中最大的模糊隸屬度![]() ,并宣布第k個類
,并宣布第k個類![]() 為獲勝者,獲得了數據對象
為獲勝者,獲得了數據對象![]() 。這樣,每個數據對象都有一個屬于自己的類簇,且不依賴任何其他數據點。然后,用
。這樣,每個數據對象都有一個屬于自己的類簇,且不依賴任何其他數據點。然后,用![]() 表示的抑制率乘以非獲勝者所屬類簇的隸屬度值,以修改模糊隸屬度,從而在一定程度上增加獲勝者的隸屬度值。因此,RS-SFC算法有以下隸屬度計算公式:
表示的抑制率乘以非獲勝者所屬類簇的隸屬度值,以修改模糊隸屬度,從而在一定程度上增加獲勝者的隸屬度值。因此,RS-SFC算法有以下隸屬度計算公式:
![]() (22)
(22)
這些修改后的隸屬度值被用來計算新的聚類 ?中心。
2.2算法步驟
RS-SFC算法的過程是迭代更新公式(19)和公式(3)的過程,直到式(16)趨于穩定,迭代停止。根據上述定義和分析,基于粗糙集的抑制模糊聚類算法的步驟如下:首先,隨機選擇C個數據對象作為C個簇的聚類中心,然后根據式(3)和(22)計算所有數據樣本的模糊隸屬度,根據每個樣本相對聚類中心的大小對數據樣本進行劃分。根據得到的新的劃分,用式(19)更新聚類中心,然后再根據新的聚類中心求解新的隸屬度矩陣,如此循環,當聚類結果趨于穩定后,該算法終止。
算法2-2 ?基于粗糙集的抑制模糊聚類算法
輸入:數據集![]()
輸出:隸屬度矩陣![]() 和聚類中心
和聚類中心![]()
Step 1:初始化相關參數。給定聚類中心的個數c,設置模糊因子m=2.0,停止閾值![]() ,迭代計數
,迭代計數![]() ,初始化隸屬度矩陣
,初始化隸屬度矩陣![]() ,使其滿足約束條件;設置抑制因子
,使其滿足約束條件;設置抑制因子![]() (0<
(0<![]() <1);
<1);
Step 2:根據隸屬度矩陣,使用式(4.19)計算聚類中心![]() ;
;
Step 3:根據式(4.3)、(4.22)更新隸屬度矩陣![]() ,迭代計數
,迭代計數![]() ;
;
Step 4:如果![]() ,則算法終止;否則轉至Step 2。
,則算法終止;否則轉至Step 2。
3 ?實驗結果與分析
本節將通過實驗對RS-SFC算法進行研究。首先對實驗中所用數據集進行描述,并對數據集進行預處理;然后將RS-SFC算法同其他兩個常用的聚類算法進行比較,以分析該算法的有效性。最后在對實驗結果進行分析的基礎上,總結RS-SFC算法的優缺點,為以后的研究指明方向。
本次實驗一共分為兩部分,一是測試本文提出RS-SFC算法的聚類效果。將該算法與模糊C均值聚類算法、K-means聚類算法同時應用在8個數據集上,并計算每個數據集的準確率、F1值和互信息,以對聚類效果進行對比;二是測試RS-SFC算法的收斂速度。分別記錄RS-SFC算法和模糊C均值聚類算法在對數據集進行聚類時的迭代次數。每個算法運行30次,最后取平均值。模糊C均值聚類算法在上文中已有介紹,K-means聚類算法是在現實生活中應用十分廣泛的聚類算法,它是一種基于距離的聚類方法,具體描述見參考文獻。
3.1數據集描述
由于本實驗需要計算聚類準確率,以對算法的聚類效果進行分析,因此實驗中采用帶有屬性標簽的數據集。實驗中所用到的數據集的信息如表1所示,其中包含經典的人工數據集和UCI上的真實數據集。這些數據集在屬性數量、類簇數量上有一定的區分度。
在進行聚類之前,先對數據進行預處理。使用本文第三章中提出的MIMR屬性約簡算法,對表1中的數據集進行屬性約簡,以剔除數據集中沒有用的列,減少數據集的規模。經過屬性約簡后,得到表2所示的實驗數據集。
3.2評價指標
本文通過計算聚類結果的準確率(Accuracy),F-measure和互信息(NMI),來評價聚類結果的質量,通過算法迭代次數評價收斂速度。
聚類結果的準確率類定義如下:
 (23)
(23)
其中,![]() 為數據集類簇的數量,
為數據集類簇的數量,![]() 表示正確分類到類
表示正確分類到類![]() 中的樣本數量,
中的樣本數量,![]() 為全體數據樣本。
為全體數據樣本。
F-measure又稱F-score:
![]() (24)
(24)
其中, ,
,![]() 表示屬于類簇
表示屬于類簇![]() 但被錯誤分類到其它簇的樣本數量。當參數
但被錯誤分類到其它簇的樣本數量。當參數![]() 取1時,就是常見的F1值。
取1時,就是常見的F1值。
標準化互信息是描述變量之間相互依賴性大小的度量。
![]() (25)
(25)
其中,![]() 和
和![]() 表示隨機變量,它們之間的互信息定義如下:
表示隨機變量,它們之間的互信息定義如下:
![]() (26)
(26)
![]() 和
和![]() 分別表示X與Y的熵:
分別表示X與Y的熵:
![]() (27)
(27)
![]() (28)
(28)
3.3實驗結果及分析
3.3.1??聚類效果比較
為了驗證本文提出的RS-SFC算法的有效性,將RS-SFC算法與模糊C均值算法和K-means聚類算法進行對比。為了評價算法的聚類效果,實驗對每個數據集在三個算法上取得的聚類結果的準確率、F1值和互信息進行了比較。每個算法在每個數據集上一共運行30次,最后取平均值。
(1)聚類準確率比較
表3是三種算法在數據集上取得的聚類結果準確率,每個表的最后一行是這8個數據集獲得的平均值。表中加黑的單元格數據表示這一行中的最 ?優值。
從準確率的平均值來看,本文的RS-SFC算法在這8個數據集上取得的準確率最高,比K-means算法和模糊C均值算法都有明顯的提高。為了更直觀的比較三個算法的優劣,將表3用折線圖進行展示,如圖2所示。
從單個數據集來看,K-MEANS聚類算法對于Dp1數據集的聚類結果最差,模糊C均值和RS-SFC算法在Dp1數據集上都取得了很高的聚類準確率;
對于wine數據集來說,K-means算法取得了最高的準確率,本文的RS-SFC算法雖然沒有取得最大值,但是比K-means算法的準確率僅低3.4%,并且仍然高于模糊C均值算法。在hepatitis數據集上,三個算法的準確率都不高,沒有超過80%。通過分析發現,hepatitis數據集是一個不平衡性數據集,準確率評價指標在數據劃分相對平衡的數據集上,能夠更好的說明聚類效果。在其他幾個數據集上,RS-SFC算法都能得到較高的準確率,尤其在類簇數量比較多的數據集上取得了不錯的表現,如glass數據集和Heart-disease數據集。綜上所述,RS-SFC算法的聚類準確率遠于其他兩個對比算法相比,具有明顯的優勢。
(2)F1值比較
表4和圖3展示的三個算法聚類結果的F1值。在表4中,最后一行是對每一列數據求均值得到的平均數。表中加黑的單元格數據表示這三個算法在同一個數據集上取得的最優值。F1值評價指標在評價聚類效果時更加全面,它不僅考慮了聚類結果的準確率,還考慮了召回率,因而能夠更好的描述不平衡數據的聚類效果。
由表4和圖3可發現,RS-SFC算法在數據集glass和heart-disease上得到的F1值要明顯的大于另外兩個算法,這個數據集的聚類數目分別是7和5,這說明RS-SFC算法在類簇數較多的數據集上也可以取得理想的效果。對于wine數據集來說,盡管K-means算法得到最高的F1值,但是在兩個軟聚類算法中,RS-SFC算法的F1值仍然高于模糊C均值算法。此外,在haberman數據集上,模糊C均值算法的F1值略高于其他兩個算法,但是相差不大。
整體上來看,RS-SFC算法在8個數據集上得到的平均F1值高于另外兩個算法,并且在四分之三的數據集中取得了最大值,這證明了RS-SFC算法的有效性和穩定性。
(3)標準互信息比較
標準互信息(NMI)可以衡量兩個變量的之間的相關性,是一種常見的評價聚類效果的指標。在本章的實驗里,用標準互信息來衡量數據樣本的實際類別與聚類結果是否一致。
標準互信息的值域是(0,1),對于聚類算法來說,聚類效果越好,其值越接近于1,否則越接近0。圖4是根據表5所作的三個算法在8個數據集上得到的互信息折線圖。
從圖4可以發現,RS-SFC算法求得的標準互信息的平均值要高于另外兩個算法。從單個數據集來看,在wine數據集上,與準確率和FI一樣,K-means算法的效果更好,但是在兩個軟聚類算法中,RS-SFC算法的標準互信息值較模糊C均值算法仍然有小幅度的提升。此外,在維度比較高的兩個數據集breast和Heart-disease上,本章的RS-SFC算法較另外兩個算法仍有較大幅度的提升。在其他數據集上,RS-SFC算法相對于另外兩個算法也有小幅度的提升。
綜合三個評價指標可以發現,本章提出的RS-SFC算法和模糊C均值算法在wine數據集上的表現較差,略遜色于K-means算法。這是由于K-means聚類算法屬于硬聚類算法,當一個數據集中,屬于同一個簇的數據樣本相似度很高,而屬于不同簇的數據樣本相似度明顯小的時候,這類算法具有明顯的優勢。但對于噪聲樣本比較多、簇與簇之間邊界不清晰的數據集來說,RS-SFC算法則更加適用。另外,通過實驗可知,?RS-SFC算法在實驗中的大多數數據集上聚類效果都優于對比算法,證明了RS-SFC算法的有效性。
3.3.2??迭代次數比較
在RS-SFC算法中,設置了一個抑制因子![]() 來加快算法的迭代速度。為了驗證該算法在收斂速度上是否有所提高,實驗中將RS-SFC算法和模糊C均值算法的最終迭代次數進行比較。實驗中為抑制因子
來加快算法的迭代速度。為了驗證該算法在收斂速度上是否有所提高,實驗中將RS-SFC算法和模糊C均值算法的最終迭代次數進行比較。實驗中為抑制因子![]() 設置了不同值,記錄了在不同的抑制因子
設置了不同值,記錄了在不同的抑制因子![]() 下,RS-SFC算法和模糊C均值算法的迭代次數。
下,RS-SFC算法和模糊C均值算法的迭代次數。
實驗結果如表6所示。
通過上表很明顯的可以看出,RS-SFC算法的迭代次數明顯少于模糊C均值聚類算法,且隨著抑制因子![]() 的增大,迭代次數也逐漸增多,驗證了RS-SFC算法在收斂速度上優于模糊C均值算法。
的增大,迭代次數也逐漸增多,驗證了RS-SFC算法在收斂速度上優于模糊C均值算法。
4??結束語
本章首先介紹了模糊聚類的有關概念,對模糊C均值聚類算法的原理進行了解釋,描述了模糊C均值算法的算法步驟;然后將粗糙集理論引入到模糊C均值算法中,根據粗糙集理論中上、下近似集的思想,將模糊C均值算法中的聚類中心更新公式進行了改進,降低了簇邊緣噪聲數據對聚類效果影響,同時設置了一個抑制因子以提高算法的收斂速度,提出了一種基于粗糙集的抑制模糊聚類算法;最后通過實驗,在多個數據集上對RS-SFC算法進行了驗證。
參考文獻
[1]?王國胤, 姚一豫, 于洪. 粗糙集理論與應用研究綜述[J]. 計算機學報, 2009, 32(07): 1229-1246.
[2]?苗奪謙, 張清華, 錢宇華, 梁吉業, 王國胤, 吳偉志, 高陽, 商琳, 顧沈明, 張紅云. 從人類智能到機器實現模型——粒計算理論與方法[J]. 智能系統學報, 2016, 11(06): 743-757.
- 王國胤, 苗奪謙, 吳偉志, 梁吉業. 不確定信息的粗糙集表示和處理[J]. 重慶郵電大學學報(自然科學版), 2010, 22(05): 541-544+550.
- 周濤, 陸惠玲. 數據挖掘中聚類算法研究進展[J]. 計算機工程與應用, 2012, 48(12): 100-111.
- 王駿, 王士同, 鄧趙紅. 聚類分析研究中的若干問題[J]. 控制與決策, 2012, 27(03): 321-328.
- 程溫鳴, 彭令, 牛瑞卿. 基于粗糙集理論的滑坡易發性評價——以三峽庫區秭歸縣境內為例[J]. 中南大學學報(自然科學版), 2013, 44(03): 1083-1090.
- 耿秀麗, 張在房, 褚學寧. 基于變精度粗糙集的產品配置規則提取及增量式更新[J]. 上海交通大學學報, 2010, 44(07): 878-882.
- 陳果, 宋蘭琪, 陳立波. 基于神經網絡規則提取的航空發動機磨損故障診斷知識獲取[J]. 航空動力學報, 2008, 23(12): 2170-2176.
- 雷小鋒, 謝昆青, 林帆等. 一種基于K-means局部最優性的高效聚類算法. 軟件學報, 2008, 19(7): 1683-1692.
- 謝娟英, 高紅超, 謝維信. K近鄰優化的密度峰值快速搜索聚類算法. 中國科學: 信息科學,2016, 46(2): 258-280.
- 呂學偉, 黃松, 王曄. 基于OPTICS算法的變異體約簡技術[J]. 解放軍理工大學學報: 自然科學版, 2016, 17(2): 101-104.
- 徐菲菲, 苗奪謙, 魏萊, 等. 基于互信息的模糊粗糙集屬性約簡[J]. 電子與信息學報, 2008, 30(6): 1372-1375.
- 張曉紅. 基于信息熵的粗糙集理論的研究和應用[D]. 安徽大學, 2011.
- 李玉超, 徐金華. 基于Vague粗糙集信息熵的屬性約簡算法[J]. 運籌與管理, 2017, 26(05): 1-5.
- 潘瑞林, 李園沁, 張洪亮, 伊長生, 樊楊龍, 楊庭圣. 基于α信息熵的模糊粗糙屬性約簡方法[J]. 控制與決策, 2017, 32(02): 340-348.
