基于GA-SVR的蘋果可溶性固形物質量分數的高光譜檢測
2019-10-30 09:35:42查啟明顧寶興姬長英
食品與生物技術學報 2019年9期
關鍵詞:模型
查啟明, 顧寶興, 姬長英
(南京農業大學 工學院,江蘇 南京 210031)
中國是蘋果的生產大國,每年蘋果的種植面積和總產量均為世界第一,但是中國卻不是蘋果貿易強國,國產蘋果的價格及質量遠遠不及進口蘋果,主要原因就是我國蘋果的采后分級技術落后,不僅在國際市場上缺乏競爭力,而且不能滿足國內高端市場的需求。人們在選用蘋果時,會比較看重蘋果的甜度,也就是蘋果內部可溶性固形物的質量分數。高光譜成像技術既能夠反映蘋果的外部特征,例如顏色、表明缺陷等肉眼可以看見的特征,又能反映蘋果內部的物質結構和化學成分等。
由于高光譜成像技術的優越性,近年來國內外在采用高光譜成像技術檢測農產品方面展開了很多的研究。其中,黃文倩等基于400~1 000 nm的蘋果高光譜圖像采用不同的降維方法提取特征波長,然后建立最小二乘支撐向量機(LS-SVM)建模定量預測蘋果的可溶性固形物質量分數(SSC)。Lu等對蘋果的硬度進行高光譜圖像技術檢測,利用PCA和ANN相結合的方法對兩種產地的蘋果建立模型,模型的相關系數分別為0.76和0.55。侯寶路等利用連續投影算法(SPA)和多元線性回歸算法(MLR)對梨的高光譜圖像進行建模分析,來預測梨的可溶性固形物含量(SSC)和硬度。羅霞等利用高光譜成像技術對火龍果進行可溶性固形物質量分數檢測,采用PLS和BP神經網絡分別建立預測模型。
上述研究中大部分是在整個高光譜波段內進行特征波長提取,部分是通過經驗判斷優選波段后再采用算法提取特征波長,導致輸入數據精度不足。作者將預處理后的高光譜數據先進行一階微分后優選出噪聲小的波段,再通過連續投影算法提取特征波長,以此提高模型的預測精度。
1 材料與方法
1.1 實驗材料
以山東煙富、洛川元帥、洛川富士為研究對象,在實驗中所使用的蘋果均為2016年7月份在南京浦口水果批發市場購買。挑選的蘋果表面沒有缺陷、直徑范圍為65~85 mm,大小形狀均勻,共計198個。購買來的蘋果放置在冰柜中保存,實驗前分批拿出,待其恢復至室溫后開始實驗。實驗中隨機選取150個樣本作為建模校正集,其余48個樣本作為建模預測集。
1.2 高光譜圖像采集與校正
實驗中所用的高光譜系統包括:Imspector型光譜儀 (芬蘭Specim公司產品)、CCD相機 (美國Imperx公司產品)、鏡頭、21V/150W線性鹵素燈(美國Illumination公司產品)、暗箱、電控移動平臺以及計算機等部件。高光譜成像波長范圍為358~1 021 nm。參數設置如下:曝光時間52 ms,樣本與鏡頭的距離為330 mm,傳送帶移動速度為0.7 mm/s。每個樣本均在赤道部位標記3點(間隔約為)采集3張高光譜圖像,198個樣本共計594幅高光譜圖像。

圖1 高光譜系統組成圖Fig.1 Composition diagram of hyperspectral system
為了減少部分噪聲的影響,使用樣本采集相同的參數條件,經行黑白校正,公式為:
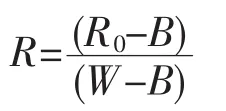
式中:R0為采集的樣本原始圖像,B為蓋住鏡頭采集到的圖像,W為反射率為1的校正白板的采集圖像,R為黑白校正后的圖像
1.3 可溶性固形物質量分數的測定
使用日本ATAGO公司的PAL-1型糖度儀(誤差在±0.2%之內)進行可溶性固形物(SSC)的測定,每個樣本測量赤道面均勻間隔的3處,挖取適量的果肉,壓成汁液后進行測量,3個數值的平均值作為該樣本的SSC值。
1.4 感興趣區域(ROI)的選取
使用ENVI軟件提取蘋果的不同波段反射率,提取之前要先確認高光譜圖像的感興趣區域(ROI)。從圖2可以看出同一樣本,相同像素中心區域的不同像素大小的反射率存在明顯差異,因此在選取ROI時,像素的形狀及大小的選擇顯得尤為重要。郭志明等的研究結果表明當采用圓形150像素點的ROI時,模型效果最佳。因此本文在選取ROI時,在蘋果高光譜圖像的赤道部位,間隔取3處圓形150像素的ROI。以上述3處的平均反射光譜作為該樣本的最終光譜。
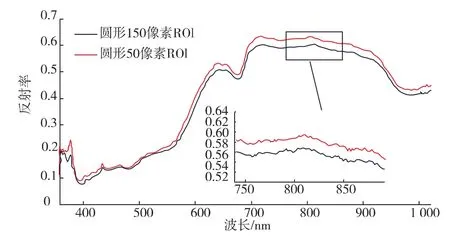
圖2 不同像素ROI的反射光譜Fig.2 Reflectance spectra of ROI in different pixel
1.5 連續投影算法
連續投影算法(SPA)是一種選擇波長變量的方法,能夠在大量的波長變量中找出共線性最小的變量組合,從而降低模型輸入變量的復雜性,提高模型的精度。樣本數M和波長數N組成的矩陣是原始光譜變量,AM*N為原始光譜變量矩陣,L為最佳波長個數(L<M-1),連續投影算法的步驟如下:
(1)初始化:n-1(第一次迭代)在AM*N中任選一個列向量(第j列),記為aK(0)(即K(0)=j);
(2)定義一個集合S:S={j,1≤j≤N,j?{k(0),…,k(n-1)}},這個集合包含未被選中的列向量的位置,分別計算aj對所有未被選中向量的投影:
Paj=aj-(aTjak(n-1))*ak(n-1)*(aTk(n-1)ak(n-1))-1,(j∈S,P是投影算子)
(3)把步驟(2)中計算的投影值最大的記為k(n):
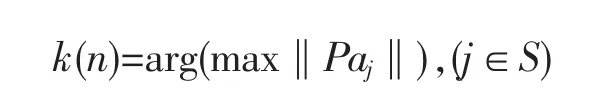
(4)把步驟(3)中求得的最大投影值作為下一個迭代過程中的初始值,即:
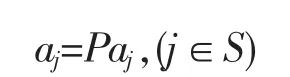
(5)進行下一次迭代:即令n=n+1,如果n<L,返回步驟(2)。
上述循環結束后,即得到選取出的特征波長:{k(n),n=0,1,…,N-1}。這樣總共可以得到L*N對波長組合,將預測均方根誤差作為所建模型的優劣依據,以此選擇出最佳波段。
1.6 建模方法和評價標準
1.6.1 BP神經網絡BP神經網絡是一種多層前饋網絡,它通過誤差逆向傳播算法進行訓練,在當前科學研究中得到了廣泛的應用,該網絡模型共包含3個部分,分別為輸入層、隱含層和輸出層。BP網絡能夠保存大量的輸入輸出映射關系,并且具有自主學習的能力,并且使用者不用提前掌握這種映射關系的數學方程。它通過不斷調整網絡內部的權值和閾值來達到降低網絡誤差平方和的目的。
圖3 BP神經網絡結構示意圖Fig.3 Schematic of BP neural network
BP神經網絡的學習過程如下:
(1)輸入模式由輸入層經隱含層向輸出層傳播計算
(2)輸出的誤差由輸出層經隱含層傳遞給輸入層
(3)按照上述步驟反復運行
(4)判別全局誤差是否趨向極小值
1.6.2 GA-SVR模型遺傳算法(Genetic algorithm,GA)是通過模擬自然界生物進化過程構造出來的一種全局自適應搜索方法,根據適應度值的大小對個體進行選擇、交叉、變異及復制等遺傳操作步驟。在操作中去除適應度低的個體,產生比前代適應度高的種群。SVR是一種基于統計學習理論的機器學習算法,能夠用來處理非線性回歸問題等問題。它的主要思想是通過將向量投映到高維空間,構建最大間隔的分類超平面,以此解決龐雜數據的回歸問題。在SVR模型中,核函數的類型、懲罰參數和核函數參數在一定程度上影響著模型的泛化能力及預測精度。作者采用徑向基函數作為核函數,采用GA搜索確定全局最佳的參數和。
使用GA算法優化SVR模型參數的過程如下:
(1)設置初始參數,即遺傳算法種群規模、進化代數、交叉概率和變異概率
(2)初始化種群,隨機產生一個給定規模的二進制代碼種群
(3)對種群的每個個體進行運算,采用SVR計算模型的預測值,并分別分析群體每個個體的適應度
(4)以遺傳適應度為導向,對種群進行復制、交叉和變異操作,并以此生產下一代
(5)判別是否滿足GA的停止條件,即訓練誤差和迭代次數是否滿足條件,從而選擇是折回步驟(3)還是繼續向下執行
(6)得到最優的SVR懲罰參數和核函數參數,建立GA-SVR參數
1.6.3 評價標準采集到的高光譜圖像經ENVI提取數據后,采用S-G平滑、SNV和小波降噪進行預處理,再利用SPA算法提取出特征波長,分別建立BP神經網絡和GA-SVR模型。通過模型的校正集相關系數(Rc)、預測集相關系數(Rp)、校正集均方根誤差(RMSEC)、預測集均方根誤差(RMSEP)和交叉驗證均方根誤差(RMSECV)來評價模型的性能。其中,Rc、Rp的值越接近 1,RMSEP、RMSECV 的值越小,則模型的性能越好。
2 結果與分析
2.1 樣本劃分
在所有樣本中隨機選取150個蘋果樣本作為建模校正集,其余48個樣本作為建模預測集。校正集及預測集樣本可溶性固形物質量分數真實值的統計結果如表1。
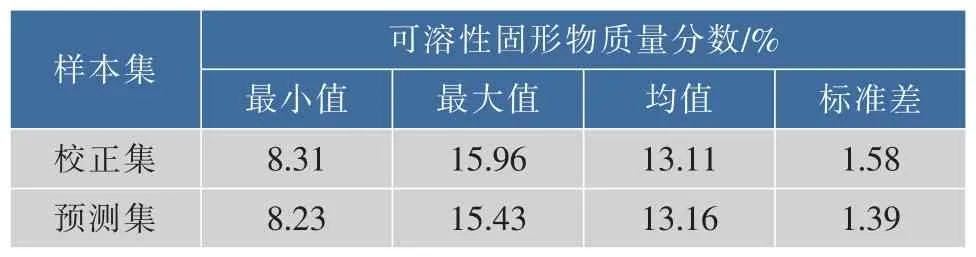
表1 蘋果可溶性固形物的統計結果Tablle 1 Statistical results of soluble solid content in apples
2.2 高光譜數據預處理
采集到的高光譜數據存在噪聲信號,這些噪聲信號會降低模型的預測性能。所以需要對采集的數據經行預處理,作者采用的預處理方法有Savitzky-Golay平滑(S-G)、標準正態變量變換(SNV)和小波降噪(Wavelet-Denoising),結果如表2所示。
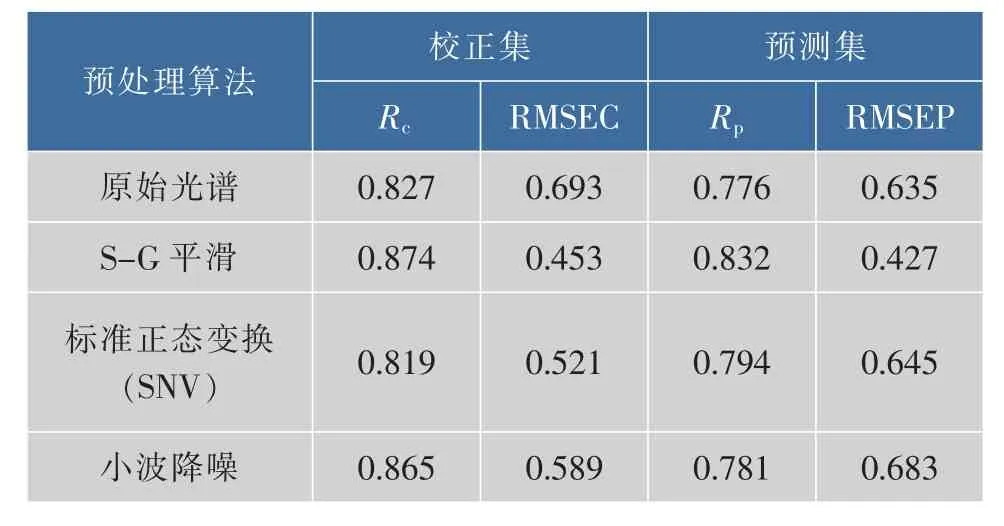
表2 不同預處理方法的預測結果Table2 Prediction resultsofdifferentpretreatment methods
由表2可以看到,采用不同預處理算法后,有的算法可以提升模型的性能,而有的算法卻降低了模型的性能。采用SNV預處理后 ,相較于原始光譜而言,模型的校正集吻合度有了提升,但預測集的預測精度基本無改善。采用小波降噪預處理后,校正集和預測集改善均不明顯。而采用S-G平滑處理后建立的模型相較于原始光譜而言具備較強的預測分析能力。
所有樣本在圓形150像素ROI內的平均反射光譜如圖4所示,通過S-G一階微分處理后的反射光譜圖5可以看到,720~1 010 nm范圍內的數據較為平滑,故選取該范圍內的數據用于建立糖度分析的模型。
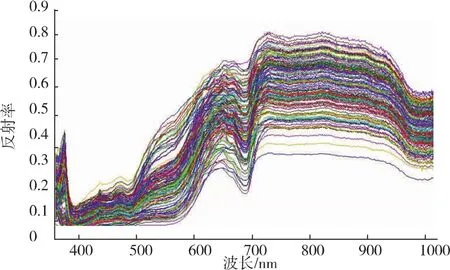
圖4 所有樣本ROI區域原始光譜Fig.4 Original spectra of all samples in ROI region
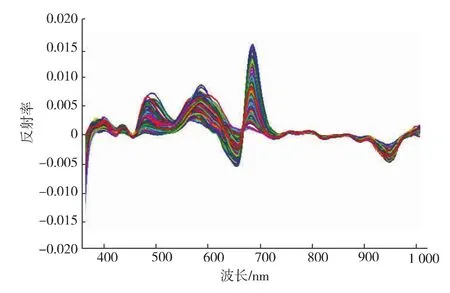
圖5 S-G一階微分處理光譜Fig.5 Spectra of S-G first derivative processing
2.3 特征波長變量的選取
通過高光譜儀采集到的蘋果數據,含有數目巨大的變量,即便通過上述處理后,仍舊保留數百個變量。大量的變量數會降低模型的運行時間,不便于今后的平臺移植,也不利于降低蘋果無損檢測的速度和精度。
通過比較各種降維算法后,選擇使用SPA進行特征波長的選取,因為SPA選取出的特征波長數目相對較少,且建立的模型的性能較好。先按照隨機樣本劃分法,將樣本分成150個校正集和48個預測集。利用SPA對720~1 010 nm范圍內的光譜特征進行變量選擇,根據樣本內部的交叉驗證均方根誤差RMSECV值來確定最佳的變量數。如圖6(a)所示,隨著選取波長數目的增加,RMSECV逐漸降低,波長數目為12后,RMSECV降低不顯著,且隨著波長數的增加,模型的復雜度則變大,所以綜合考慮,選擇12個有效波長作為模型的輸入變量如圖 6 (b), 他 們 是 740.86、752.95、785.99、800.34、813.59、835.70、842.34、860.05、883.30、897.71、938.70和950.89 nm。
2.4 模型的建立與結果分析
2.4.1 BP神經網絡模型結果分析BP神經網絡模型的輸入層為經SPA篩選出的12個特征波長變量。隱含層采用logsig型傳遞函數,訓練函數使用trainlm函數。輸出層就是預測的蘋果SSC含量,傳遞函數為pureline,學習函數為learngdm。另外,網絡的初始參數設置如下:訓練次數epochs為1 000,學習率lr為0.05,訓練精度 goal為0.000 4,測試集48個樣本的實驗結果如圖7,BP神經網絡模型的預測相關系數=0.743 0,預測均方根誤差RMSEP=0.797 7。
左圖為預測值與實際值的對比圖,右圖為真實值與預測值的95%置信區間的散點圖,中間的斜線為線性擬合線。從左圖可以看出,BP神經網絡模型的預測結果可以預測出真實值的大致趨勢,僅在部分點位上存在一定誤差。從右圖可以看出真實值和預測值的散點圖分布較為離散化。
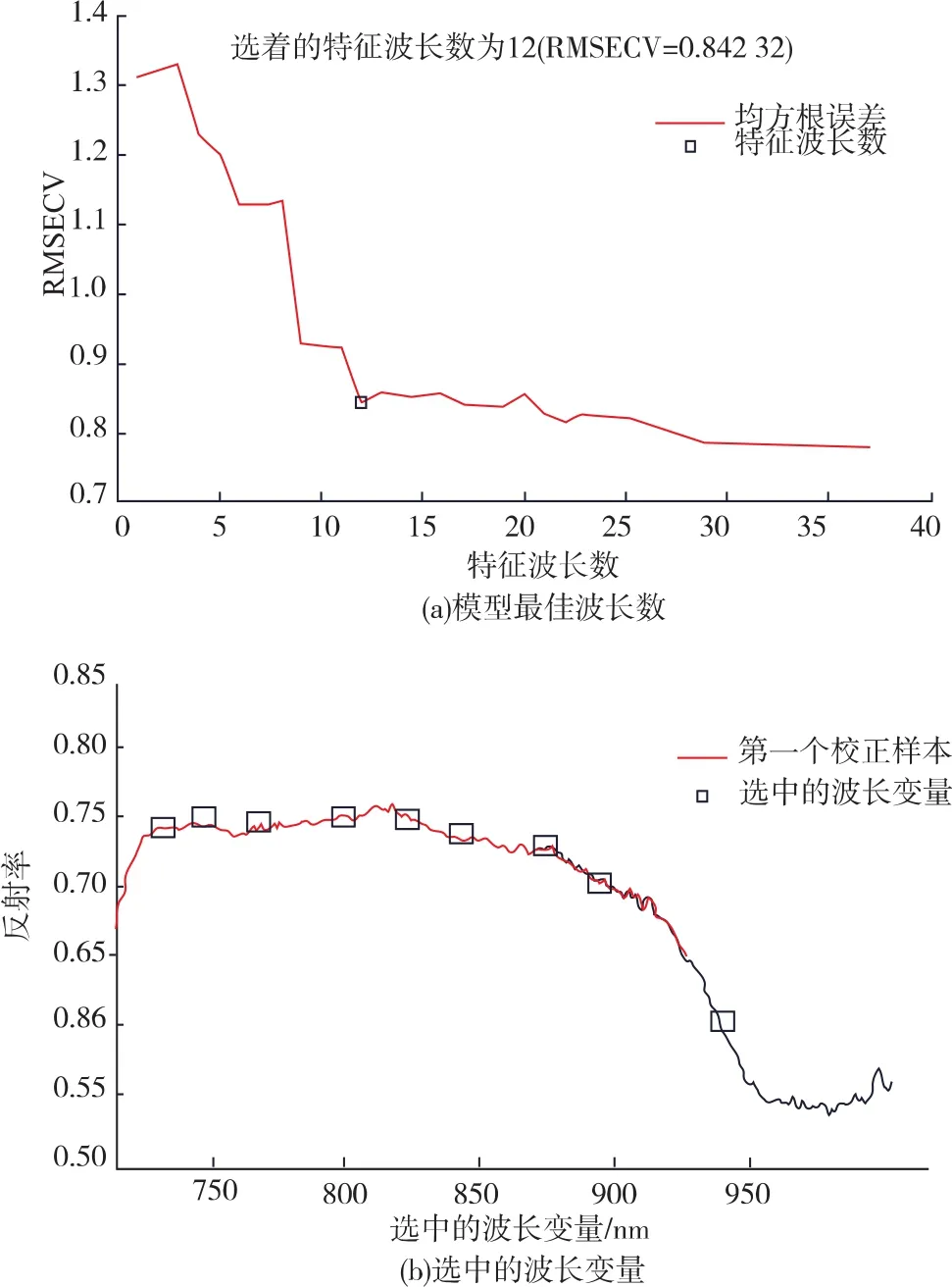
圖6 SPA選取特征波長結果Fig.6 Characteristic wavelength results of SPA
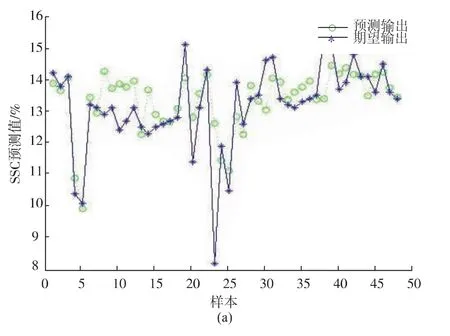
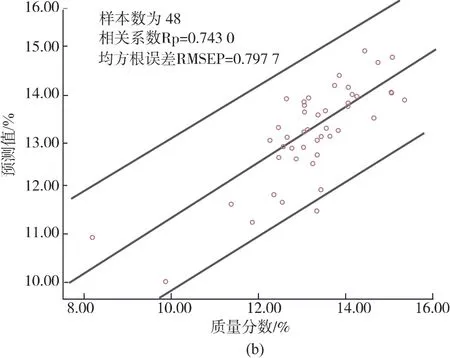
圖7 BP模型結果Fig.7 Results of BP model
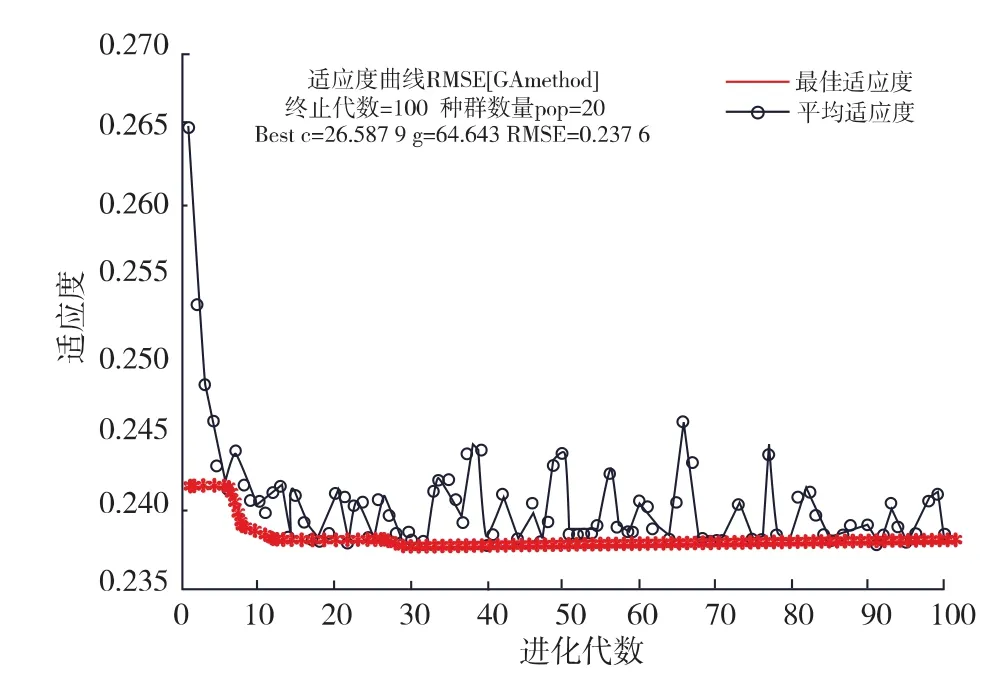
圖8 GA優化SVR參數迭代過程Fig.8 SVR parameters optimized by GA
2.4.2 GA-SVR模型結果分析遺傳算法的初始設置為,種群規模為20,進化次數為100,交叉概率為0.5,變異概率為0.01,獨立運行多次,選取出現頻率較高的結果作為SVR模型的和參數。如圖8所示,大約迭代20次時,適應度值趨于穩定,達到最佳參數值,分別為c=26.587 9和g=64.643。使用GA算法優選出來的參數值作為SVR模型的輸入參數,對48個預測集樣本進行預測分析,實驗結果如圖9所示。左圖中橫坐標為樣本數量,縱坐標為可溶性固形物的質量分數,右圖為使用SPSS做的預測集散點圖,橫坐標為預測集可溶性固形物的真實值,縱坐標為預測值,其中斜線是線性擬合線。模型的相關系數Rc=0.880 6,Rp=0.850 5,均方根誤差 RMSEC=0.260 7,RMSEP=0.303 1。

圖9 GA-SVR模型結果Fig.9 Results of GA-SVR model
從左圖可以看出預測結果和真實值在趨勢上基本吻合,在部分點位上存在些許誤差。從右圖可以看出,真實值和模型預測值的散點分布集中在擬合線的兩側,在SPSS中做回歸分析得出的調整后的判定系數R2=0.847,擬合優度高,預測效果好。
3 結語
1)在ENVI中,通過圓形150像素ROI提取出的數據,經由S-G平滑處理后,篩選出720~1 010 nm范圍內的數據作為模型的輸入變量,此范圍的數據平滑性較好。
2)在利用SPA算法提取輸入數據的特征變量時,在參考模型均方根誤差的同時兼顧模型的復雜度, 選取出的特征波長位:740.86、752.95、785.99、800.34、813.59、835.70、842.34、860.05、883.30、897.71 、938.70和950.89 nm共計12個。降低了模型的復雜度,提高了模型的預測性能。
3)通過GA算法優化SVR模型的懲罰參數和核函數參數,遺傳算法的初始設置為:種群規模為20,進化次數為100,交叉概率為0.5,變異概率為0.01。 優化得到c=26.587 9、g=64.643,此時 SVR 模型的性能最佳。
4)BP神經網絡模型的預測相關系數Rp=0.743 0,預測均方根誤差RMSEP=0.797 7;GA-SVR模型的預測相關系數Rp=0.850 5,預測均方根誤差RMSEP=0.3031。結果表明基于SPA算法優選出的波長建立的模型預測精度更高,模型復雜度得到明顯降低。從GA-SVR模型的散點圖得到調整后的判斷系數為0.847,擬合優度較高,不被解釋的變量較少,擬合效果較好。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
