三維激光掃描點(diǎn)云數(shù)據(jù)盲區(qū)邊界識別與應(yīng)用
2019-10-25 08:58:32張?jiān)?/span>
有色金屬(礦山部分) 2019年5期
關(guān)鍵詞:礦山
陳 凱,張 達(dá),張?jiān)?/p>
(1.北京礦冶科技集團(tuán)有限公司,北京 100160;2.北京科技大學(xué) 機(jī)械工程學(xué)院,北京 100083;3.金屬礦山智能開采技術(shù)北京市重點(diǎn)實(shí)驗(yàn)室,北京 102628)
在地下開采礦山,通過三維激光掃描測量獲取高精度的井下三維空間信息,對于采礦作業(yè)的超爆欠爆評價(jià)、井巷工程及采場驗(yàn)收、礦石資源的損失貧化分析、保有資源計(jì)算、礦山采空區(qū)調(diào)查與安全分析、采礦溜井及井巷工程治理及礦山工程數(shù)字化建設(shè)等具有十分重要的意義。北京礦冶科技集團(tuán)有限公司研制了國內(nèi)首套礦用三維激光掃描測量系統(tǒng),并實(shí)現(xiàn)了產(chǎn)業(yè)化推廣應(yīng)用,打破了國外技術(shù)壟斷,填補(bǔ)了國內(nèi)空白,可為后續(xù)礦山安全生產(chǎn)提供數(shù)據(jù)基礎(chǔ)[1-4]。
但是,礦用三維激光掃描測量系統(tǒng)測量的采場、溜井等區(qū)域形態(tài)復(fù)雜,內(nèi)部存在礦石點(diǎn)柱、垮塌、超爆、欠爆等情況,使礦用三維激光掃描測量系統(tǒng)工作時(shí)由于遮擋導(dǎo)致點(diǎn)云數(shù)據(jù)存在很多盲區(qū),同時(shí)由于人員難于進(jìn)入這些區(qū)域,肉眼通常無法直接獲知哪些區(qū)域存在遮擋,這將使準(zhǔn)確識別盲區(qū)邊界存在很大困難,為后續(xù)數(shù)據(jù)分析帶來一系列麻煩。為解決盲區(qū)定位困難的問題,需提供一種高效的點(diǎn)云數(shù)據(jù)預(yù)處理方法,須在雜亂無章的點(diǎn)云數(shù)據(jù)基礎(chǔ)上,對點(diǎn)云數(shù)據(jù)特征進(jìn)行分析研究,準(zhǔn)確判斷盲區(qū)邊界,為后續(xù)盲區(qū)數(shù)據(jù)處理提供判斷依據(jù)。
1 構(gòu)建點(diǎn)云空間拓?fù)潢P(guān)系
KD-Tree廣泛應(yīng)用于數(shù)據(jù)庫索引中,從概念的角度講,它是一種高緯數(shù)據(jù)的快速查詢結(jié)構(gòu)。KD-Tree是一種二叉樹,它繼承二叉查找樹的優(yōu)點(diǎn),平均查找長度只為1+4logn,表示對k維空間的一個(gè)劃分,構(gòu)造KD-Tree相當(dāng)于不斷地用垂直于坐標(biāo)軸的超平面對k維空間進(jìn)行切分,構(gòu)成一系列的k維超矩形區(qū)域,KD-Tree的每個(gè)結(jié)點(diǎn)對應(yīng)于一個(gè)k維超矩形區(qū)域。由于點(diǎn)云數(shù)據(jù)分布不規(guī)則,所以不能采用規(guī)則劃分的方式來劃分點(diǎn)云空間,但是KD-Tree是一種非常適合管理點(diǎn)云的索引方法,建立空間點(diǎn)云的拓?fù)潢P(guān)系,快速查找點(diǎn)云的鄰域[5-8]。KD-Tree構(gòu)建過程如圖1所示。
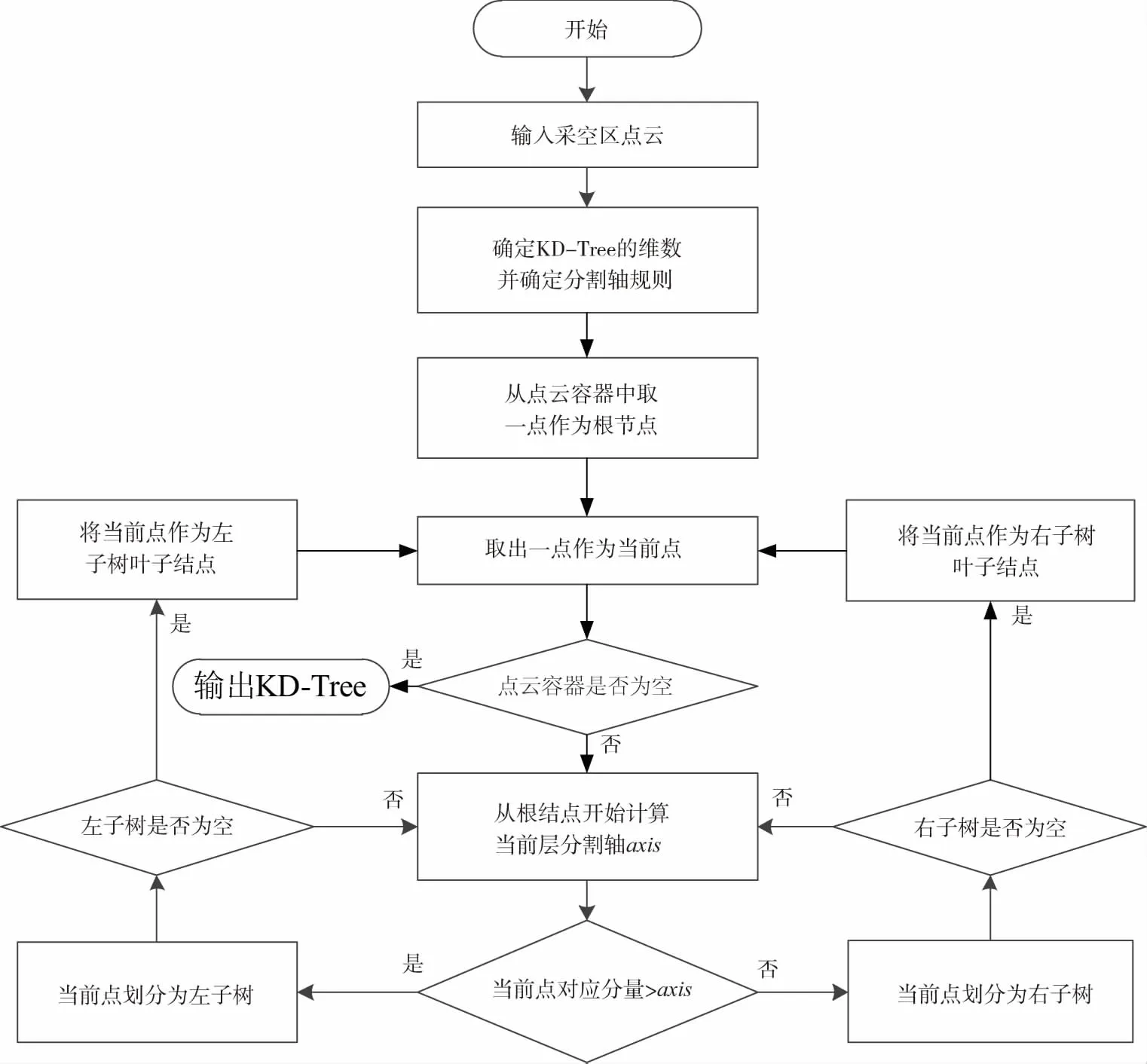
圖1 構(gòu)建KD-Tree數(shù)據(jù)結(jié)構(gòu)流程圖Fig.1 The flow chart of building KD-Tree data structure
2 點(diǎn)云數(shù)據(jù)領(lǐng)域法向矢量計(jì)算
點(diǎn)云數(shù)據(jù)法向矢量的計(jì)算是判斷點(diǎn)云數(shù)據(jù)的K-近鄰點(diǎn)是否分布均勻的前提。通過KD-Tree構(gòu)建的點(diǎn)云拓?fù)潢P(guān)系,構(gòu)造點(diǎn)云中各點(diǎn)的最小二乘平面,計(jì)算該平面的法向矢量,并將該法向矢量作為數(shù)據(jù)點(diǎn)的法向矢量計(jì)算結(jié)果。其中K值的選取很重要,在曲率變化大的地方需要慎重考慮K值的選取,以保證單凸或單凹,這樣得到的最小二乘平面才能更好地逼近原始點(diǎn)云,也使得投影點(diǎn)在局部型面的參數(shù)化更好地反映點(diǎn)云的參數(shù)化。

ax+by+cz=d
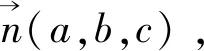
輸入:點(diǎn)云數(shù)據(jù)集S
如果點(diǎn)云數(shù)據(jù)集S為空,則算法將結(jié)束;否則從點(diǎn)云數(shù)據(jù)集S中順序提取數(shù)據(jù)點(diǎn)P作為當(dāng)前處理數(shù)據(jù);
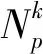
計(jì)算矩陣A的特征值;
計(jì)算最小特征值對應(yīng)的特征向量。
3 點(diǎn)云數(shù)據(jù)盲區(qū)邊界提取
K-近鄰的創(chuàng)建可為特征邊界的提取提供好的基礎(chǔ)[9]。假設(shè)點(diǎn)云數(shù)據(jù)中點(diǎn)P是特征邊界點(diǎn),K-近鄰點(diǎn)的分布將偏向某一側(cè);如果是內(nèi)部點(diǎn),則其K鄰域點(diǎn)將均勻地分布在該點(diǎn)的周圍(如圖2所示)。基于該思路,本文利用了數(shù)據(jù)點(diǎn)及其K-近鄰點(diǎn)的均勻分布特性來判斷特征邊界點(diǎn)。
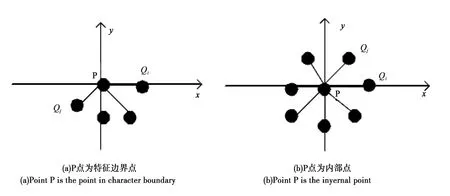
圖2 邊界特征點(diǎn)識別原理Fig.2 The recognition principle of character boundary point
假設(shè)輸入的點(diǎn)云數(shù)據(jù)集為S,輸出的邊界特征集合為F(S),基于上述思想,邊界檢測的算法流程如下:
1)如果點(diǎn)云數(shù)據(jù)集S為空,則算法將直接結(jié)束;否則從點(diǎn)云數(shù)據(jù)集S中按照先后秩序提取數(shù)據(jù)點(diǎn)P作為當(dāng)前需處理數(shù)據(jù);
2)將數(shù)據(jù)點(diǎn)P的K-近鄰點(diǎn)投影到對應(yīng)的法向矢量平面內(nèi),連接數(shù)據(jù)點(diǎn)P和鄰域的投影點(diǎn)形成一個(gè)向量集;
3)計(jì)算向量集對應(yīng)的所有向量與基準(zhǔn)向量間的夾角,計(jì)算結(jié)果按照升序進(jìn)行排序,得到了夾角集S’。計(jì)算S’的夾角差然后得到向量集中相鄰向量的夾角集A;
4)若夾角集A的最大角度差A(yù)max>u(一般情況,閾值u取值大小為π/2),則將數(shù)據(jù)點(diǎn)P放入集合F(S)中;如果完成點(diǎn)云數(shù)據(jù)集S中的所有數(shù)據(jù)處理,則算法結(jié)束,否則轉(zhuǎn)向1)。
4 現(xiàn)場掃描點(diǎn)云數(shù)據(jù)驗(yàn)證
為驗(yàn)證本文提出的盲區(qū)邊界識別算法效果,選擇兩組礦山的采空區(qū)掃描點(diǎn)云數(shù)據(jù)進(jìn)行驗(yàn)證,第一組采空區(qū)點(diǎn)云數(shù)據(jù)數(shù)量為208 786個(gè),使用該算法耗時(shí)5 s準(zhǔn)確識別出盲區(qū)邊界(如圖3所示),盲區(qū)邊界點(diǎn)云數(shù)量為305個(gè);第二組采空區(qū)點(diǎn)云數(shù)據(jù)數(shù)量為158 756個(gè),使用該算法耗時(shí)3.5 s準(zhǔn)確識別出盲區(qū)邊界(如圖4所示),盲區(qū)邊界點(diǎn)云數(shù)量為158個(gè)。通過現(xiàn)場兩組采空區(qū)點(diǎn)云數(shù)據(jù)驗(yàn)證結(jié)果表明該算法可有效獲取點(diǎn)云數(shù)據(jù)盲區(qū)邊界。
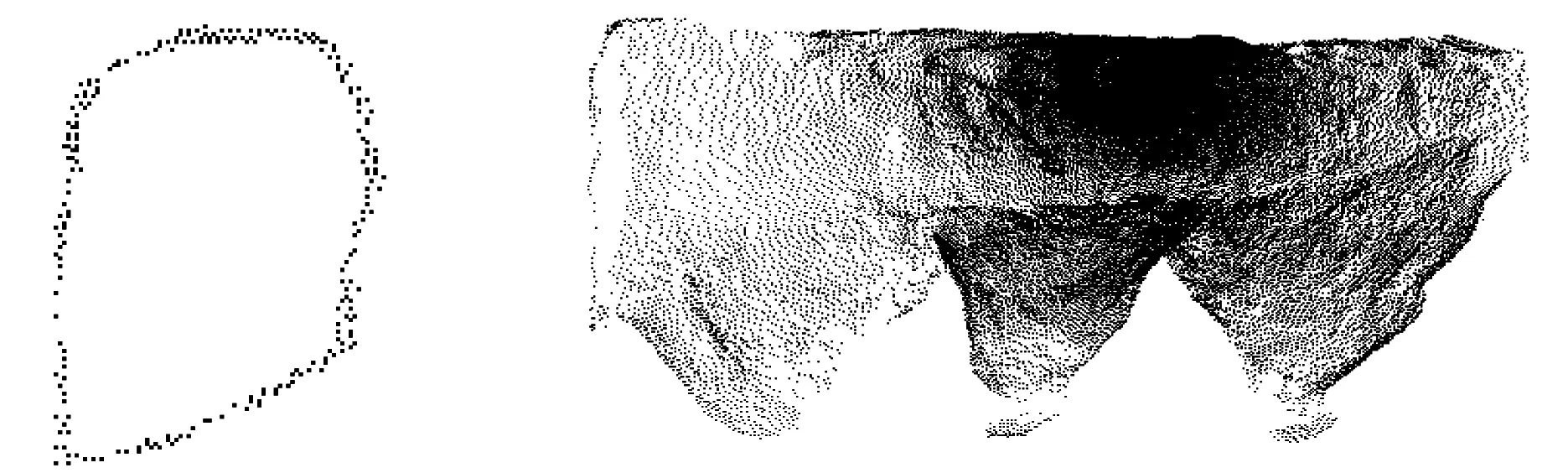
圖3 第一組點(diǎn)云數(shù)據(jù)盲區(qū)邊界識別結(jié)果Fig.3 The blind area recognition result of the first-group point cloud data
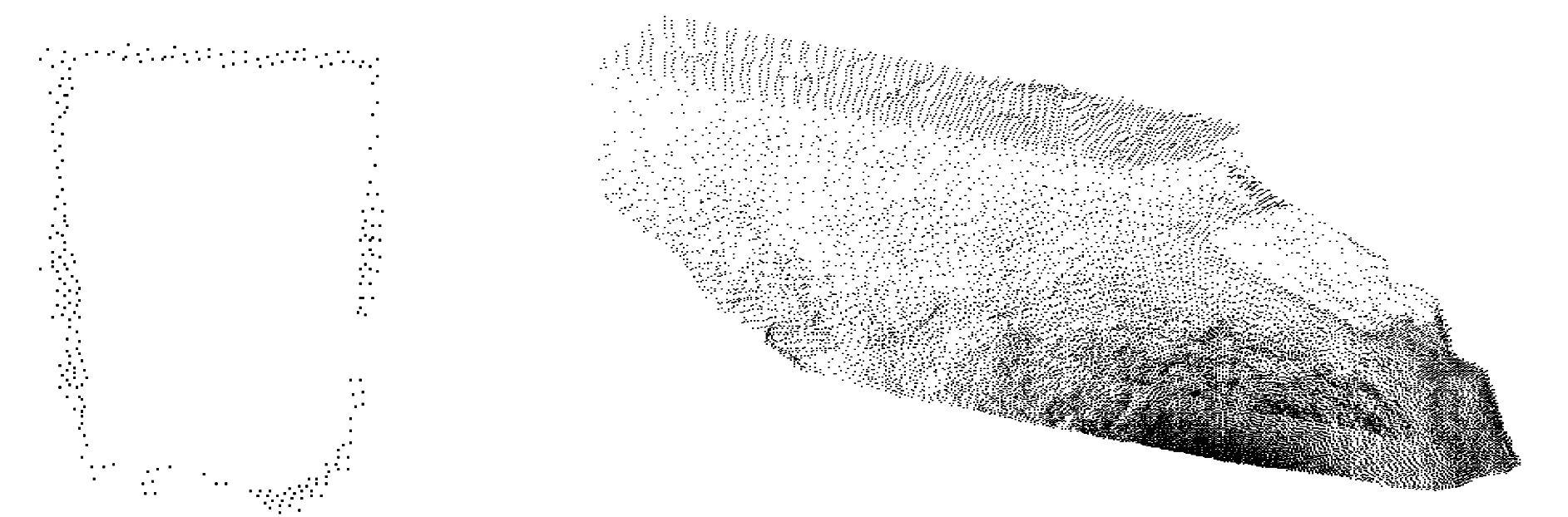
圖4 第二組點(diǎn)云數(shù)據(jù)盲區(qū)邊界識別結(jié)果Fig.4 The blind area recognition result of the second-group point cloud data
5 結(jié)論
本文應(yīng)用的盲區(qū)識別算法利用KD-Tree構(gòu)建點(diǎn)云的空間拓?fù)潢P(guān)系,快速、準(zhǔn)確地獲取局部型面參考點(diǎn)集,然后利用KD-Tree計(jì)算出點(diǎn)云中各數(shù)據(jù)點(diǎn)的K-近鄰點(diǎn),通過判斷K-近鄰域點(diǎn)分布的均勻性來提取出邊界特征點(diǎn),最后利用估計(jì)邊界的走向來提取特征邊界點(diǎn)并形成邊界線,最后達(dá)到識別出內(nèi)外邊界的目的,為后續(xù)點(diǎn)云數(shù)據(jù)修復(fù)和補(bǔ)洞提供了數(shù)據(jù)基礎(chǔ)。
猜你喜歡
資源節(jié)約與環(huán)保(2022年8期)2022-09-20 02:24:38
現(xiàn)代礦業(yè)(2021年12期)2022-01-17 07:30:32
河北地質(zhì)(2021年2期)2021-08-21 02:43:50
神劍(2021年3期)2021-08-14 02:30:08
昆鋼科技(2021年2期)2021-07-22 07:47:06
石材(2020年11期)2021-01-08 09:21:48
礦產(chǎn)勘查(2020年7期)2020-12-25 02:43:42
陽光(2020年6期)2020-06-01 07:48:36
當(dāng)代工人·精品C(2020年1期)2020-05-20 07:54:37
建材發(fā)展導(dǎo)向(2019年11期)2019-08-24 06:35:46
