AI安防芯片的發展現狀與前景分析
2019-10-23 03:37:20北京比特大陸科技有限公司湯煒偉李曉松
中國安全防范技術與應用 2019年5期
關鍵詞:智能
■ 文/北京比特大陸科技有限公司 湯煒偉 李曉松
關鍵字:ASIC NPU CNN RNN DNN

1 引言
從2015年以來,隨著深度學習而掀起的人工智能的第三次浪潮是由技術驅動。但進行到現在,人工智能的產業發展關鍵在于商業化。商業化僅僅依靠技術本身是無以為繼的,AI市場容量、應用的深度、數據的規模決定了人工智能在某個具體行業的發展速度。就這一點而言,得益于平安城市十幾年的建設,安防行業的智能化走在了前面。
根據美國信息服務社的數字,截至 2015 年末,全球已安裝了超過 2.45 億個視頻監控攝像頭,我國已安裝的監控攝像頭也已超過 3000 萬個,而同時全球和國內監控攝像頭銷售市場仍在逐年擴張,每年僅僅我國就產生數萬PB的數據量。與數據量同步增長的,是巨大的市場規模。國內安防市場在近十年來飛速發展,市場總產值從2012年的3240億,增長到了2017年的6480億,研究機構預計到2022年會達到萬億規模。
海量數據決定了智能化的發展速度,市場規模決定了商業化的潛力。人工智能+安防成為各大公司追逐的“香餑餑”,則是必然的。本文將從市場格局、技術方案、AI芯片三個方面,由大到小分析AI安防芯片的行業面貌,及其發展現狀與前景。
2 市場格局
根據相關調研報告,從產業構成來看,在安防行業總收入中,2016年中國安防工程產值約3100億元,安防產品產值約1900億元,報警運營服務及其他產值約410億元。按照產品分類來看,視頻監控市場占比最大,占所有安防產品的三分之二,市場規模已達1000億元以上,其次為安檢排爆、防盜報警、出入口控制和實體防護市場。從安防應用角度分析,2016年安防產品行業應用中,平安城市、智能交通和智能樓宇所占比例最高,分別達到24%、18%和16%,占據整個應用市場份額過半。此外,安防產品還應用在文教衛、金融和能源、司法等多個領域,應用范圍十分廣泛。
目前,我國各類安防企業達到2.34萬家,從業人數達166萬人。安防企業中,集成與工程類企業約1.19萬家,占比51%,安防產品類企業近1萬家,占比41%,運營和其他類企業近2000家,占比約8%。各類企業的所占比例近三年呈現出一定規律,其中安防設備類企業占比呈逐年下滑趨勢,與此同時,安防工程類企業和運營服務類企業占比小幅增加。AI技術火爆之后,在近幾年又冒出了眾多基于人工智能的軟硬件提供商,例如依圖、商湯、曠視、云從、比特大陸等。
安防行業中企業集中度大幅提高,行業競爭加劇,資源向龍頭企業集中趨勢愈發明顯。隨著安防龍頭企業快速崛起,大型企業與中小企業之間的差距逐漸拉大,再加上產業鏈延伸、橫向跨界、行業深耕方面的優勢,強者越強、贏者通吃的趨勢已經顯現。國內安防行業價格競爭日趨激烈,導致傳統產品毛利率略有下滑,具有技術壁壘的安防龍頭公司占據優勢。行業長尾效應明顯,洗牌加劇,龍頭企業依托技術、資源和規模優勢仍能保持高速增長,而位于長尾尾端的眾多中小企業已逐漸處于盈虧平衡狀態,生存艱難。
安防行業發展多年,企業在規模上明顯形成了梯度,海康威視、大華、宇視等公司占據了絕大部分市場份額,并且都在積極擁抱AI技術。國內安防領域整體的集中程度也逐年攀升,形成了“兩超多強”的格局,海康威視和大華股份領跑市場,東方網力、佳都、蘇州科達、漢王等第二梯隊企業奮起直追。當有了新技術的支持,尤其在AI應用正式落地安防之后,投資或收購AI技術公司成為傳統安防企業最有效創新升級的方式。
3 技術方案
多年的發展,使得安防行業不僅形成了比較完整的市場格局和產業鏈。在市場格局方面,視頻監控占據了近50% 的市場份額,這其中又分為前端(攝像頭)和后端(主控/云端)兩部分。
前端產品的核心功能是為后端提供高質量、初步結構化的圖像數據,其主要作用有兩點:提升部分智能分析應用的實時性;節省帶寬和后端計算資源。
典型的前端智能攝像頭內置深度學習算法,一方面可以在前端完成人臉定位檢測和質量判斷,有效解決漏抓誤報問題,同時擁有較好的圖像效果,即使周圍環境光線不佳,人員戴帽子或一定角度下低頭、側臉,仍然可以做到準確檢測,并自動截取視頻中的人臉輸出給后端;另一方面可以輸出編碼后的網絡視頻,還支持輸出非壓縮、無損無延時的視頻流圖像,這樣可以為大型用戶節省服務器成本和帶寬,在同等服務器數量和計算能力的情況下能夠接入更多路攝像頭。
后端產品的核心功能是利用計算能力對視頻數據進行結構化分析,一般包括智能 NVR、高密度 GPU服務器。前者是基于深度學習算法推出的智能存儲和分析產品,兼顧傳統 NVR 優勢的同時增加了視頻結構化分析功能;后者集成了基于深度學習的智能算法,每秒可實現數百張人臉圖片的分析、建模,可支持數十萬人臉黑名單布控,人臉 1V1 比對、以臉搜臉等多項實用功能,滿足各行業的人臉智能分析需求。
從前后端智能化模塊來看,目前的解決方案有兩種思路,一種是智能前置,一種是后置智能,這一直是行業備受爭議的兩個方向。
由于前端設備內的空間有限,再加上功耗、成本等因素的限制,智能前置會受硬件計算資源限制,只能運行相對簡單的、對實時性要求很高的算法,但算法升級、運維較難;后端智能分析通常可以根據需求配置足夠強大的硬件資源,能夠運行更復雜的、允許有一定延時的算法,另外,在后端算法升級、運維都會比較方便。
前后端產品不是對立與競爭的關系,根據實際應用的不同,將長期同時存在。
4 AI芯片的發展前景
無論是前端產品,還是后端產品,其底層能力都是芯片賦予的。對于智能前端產品目前有兩種芯片解決方案。
一種是較為通用的視覺處理器(半定制芯片),如movidius 、英偉達的 Jetson 系列芯片,NVIDIA 的Jetson TX 芯片,主要針對終端市場。此外,海康、大華、宇視科技、蘇州科達、格靈深瞳、商湯科技等大部分公司的前端智能產品在 2016 年正式推出。另一種是將較為通用的智能識別類算法直接固化為 IP ,嵌入到視頻監控 SOC 芯片中(全定制芯片),優點是量產后功耗、價格等都極具優勢,但功能拓展性有限。
在后端芯片方面,英偉達的GPU被采用最多,應用場景通用,但是昂貴,相比而言專用定制的、高性價比的ASIC 芯片的優勢越來越明顯。
行業內廠商之所以寄希望于 ASIC 芯片,主要原因還在于 GPU 芯片的弱點。不得不承認,在安防監控領域,GPU依然是最主流的深度學習方案,但GPU在成本、效率、功耗三方面存在明顯缺陷:
(1)成本方面,嵌入式端GPU為數百美金,后端高性能GPU高達數千美金。在嵌入式端,市場上已量產的IPC Soc 芯片價格已經降到幾美金,可以說是很好的替代品,但后端需要做大規模數據處理時,還是離不開GPU。高昂的芯片成本,推高了前后端設備的價格,阻礙了大范圍應用。
(2)效率方面,GPU擅長深度學習算法訓練,但卻拙于推理。在推理階段,一次只能處理一張輸入圖像,并行優勢不能完全發揮。
(3)功耗方面,GPU在深度學習計算上,比CPU節省10倍能耗,但作為通用型芯片,在處理大量視頻數據時功耗依然不容小覷,用電及散熱成本也是一個大問題。
而經過專門設計優化的ASIC 芯片,則有著更高性價比、更容易大規模部署的優勢。相比 GPU 的通用性,ASIC 芯片是一種為實現特定要求設計的集成電路,這意味著該芯片無法擴展,但除此之外,無論功耗、可靠性,還是體積、成本均遠低于GPU。
鑒于 ASIC 芯片的諸多特質,業界普遍認為將會成為未來人工智能領域的核心,越來越多的算法企業也在基于ASIC 優化算法,而安防也成為主要的應用場景。
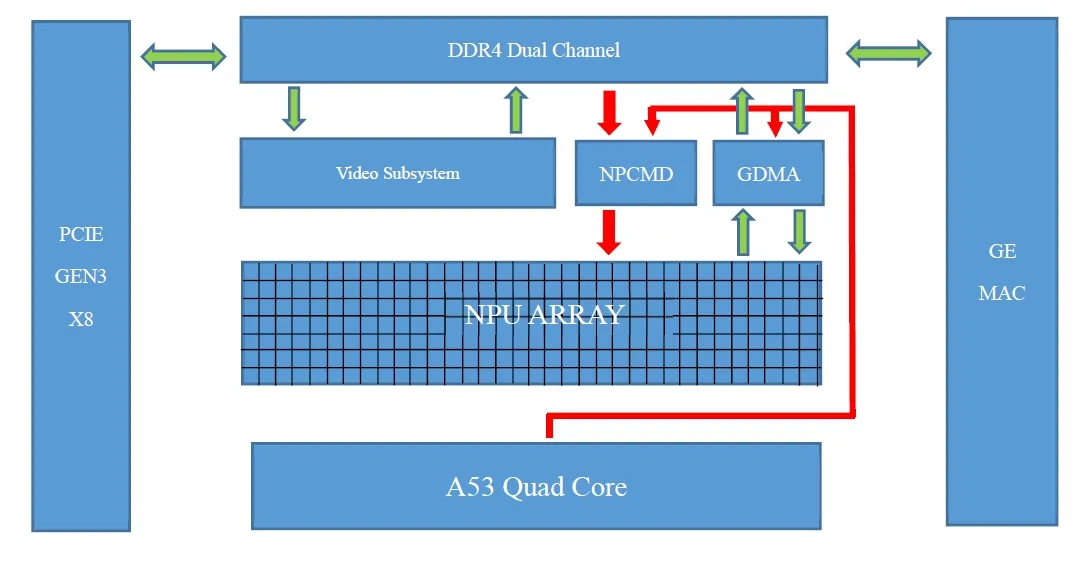
圖1 ASIC芯片架構圖
ASIC芯片架構如圖1所示,典型ASIC芯片的基本業務流程如下:
應用程序運行于主機ARM上,通過NPU操作指令模塊(NPCMD)和數據訪問通道(GDMA)以及對DDR4內存單元的數據搬運操作,來對驅動NPU矩陣進行卷積運算。
來自文件或者網絡的視頻流通過FFMPEG傳輸到Video System進行解碼,解碼結果存放于DDR內存內。
DDR內存里的視頻解碼結果作為CV的輸入進行圖像處理,處理后的數據同樣存放于DDR內。
經過CV處理后的數據經過編譯器編譯后的神經網絡模型文件做上下文處理,處理結果放到DDR內存中,作為NPU的輸入,系統加載后進行網絡卷積等計算。
計算結果通過PCIE接口或者GE接口讀取回應用程序進行結果展示或者上報。
所有數據都在DDR內存中處理和交換,并且DDR內存和NPU矩陣有專門的DMA通道,這樣設計的好處是大幅提高數據處理效率。
例如BM 1680、BM1682、BM1684系列SoC芯片 ,就是一系列面向深度學習應用的 ASIC 芯片,其加速核采用改造型脈動陣列架構技術,具備多個并行執行單元,適用于CNN/RNN/DNN 等神經網絡的預測和訓練。第四代芯片BM1686將于2020年推出。
基于以上系列芯片,針對視頻和圖像分析,還可研發智能視頻分析服務器、深度學習加速卡和人工智能迷你機等產品,預裝Linux操作系統,預裝包括固件、驅動、BMDNN計算庫、Runtime庫等軟件環境,以及目標檢測和目標識別的樣例模型和測試程序,適用于人臉檢測、人體檢測、人臉識別、機非人檢測分類等安防場景。
Sophon SA3系列AI加速計算服務器,采用低功耗的ARM CPU作為主控制芯片,在提供超強算力的同時,降低了整機的功耗,提供了更高能效比的服務器產品;主要面向數據中心及中小型局/所邊緣節點,提供超強的視頻結構化處理能力,滿足中小站點的智能化改造訴求及數據中心的分布式部署要求。
5 BM1682芯片技術
BM1682芯片可脫離 X86 CPU 單獨存在,其架構圖如圖2所示。支持客戶二次開發,擁有單芯片八路H.264/H.265解碼能力,支持視頻圖像后處理硬件加速,相比第一代擁有更低功耗、更高密度的特點,實際性能提升5倍以上。此外支持以太網,PCIE的多芯片互聯,易于橫向擴展,支持大規模數據中心。
BM1682高達3TFLOPs的FP32浮點運算能力,16MB片內SRAM,可以極大的減少模型運算時的數據搬運,提升性能;推理加速性能相當于同等算力GPU的160%。
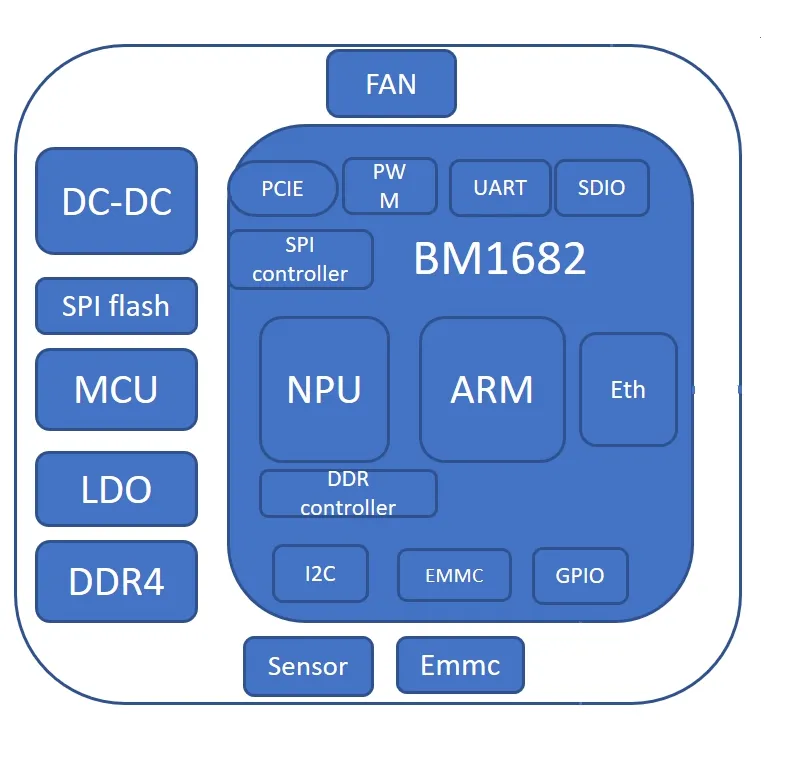
圖2 BM1682架構圖
完善易用的SDK支持:完善的神經網絡編譯器,支持多種網絡;接口豐富,方便快速遷移,支持各類圖像算法。
在高密度服務器中,BM1682運行在SoC模式,每顆芯片包含4核Cortex-A53處理器,運行獨立的Linux操作系統,提供SDK控制NPU神經網絡加速單元,H.264/H.265/Jpeg硬件解碼單元和視頻后處理硬件單元,芯片間通過網絡連接形成集群。
每顆BM1682的NPU矩陣包含64顆NPU單元,每顆NPU包含32個EU單元,每個EU單元在每個時鐘周期可做2次運算(1次乘和1次加),如果NPU的頻率是750MHz,則此款芯片的額定算力=64*32*2*750=3072000M=3TFLOPS。
應用程序運行于主機CPU上,鏈接BMDNN(深度學習層layer級別的加速庫接口)和BMCV(使用TPU和VPU進行CV處理的加速庫接口)以及FFMPEG動態庫,運行時通過PCIE驅動訪問BM1682。
BMCVSDK(BITMAIN Computer Vision SDK)是基于自主研發的BM1682芯片所定制的視頻加速工具包,涵蓋了定制版本的FFMPEG和用戶開發接口以及基于NPU的圖像處理加速API,用于高效處理視頻數據,提升基于神經網絡視頻應用的圖像處理速度。
BMCVSDK由驅動、用戶態SDK以及FFMPEG定制版開源軟件組成,典型場景下的框架關系如圖3所示。
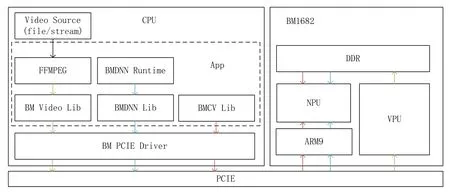
圖3 BM1682業務流程圖(PCIE模式)
來自文件或者網絡的視頻流通過FFMPEG傳輸到VPU(視頻處理單元)進行解碼,解碼結果存放于PCIE板卡上的DDR內存內。
視頻解碼結果作為BMCV(使用TPU和VPU進行CV處理的加速庫接口)的輸入進行圖像處理,結果存放于PCIE板卡的DDR內。
經過BMNETC(面向Caffe model的BMCompiler前端)或者BMNETT(面向TensorFlow model的BMCompiler前端)等編譯器編譯的神經網絡文件上下文經過BMRUNTIME和BMLIB通過驅動加載到PCIE板卡的DDR內存中,并將BMCV處理過的數據作為NPU的輸入,進行網絡計算。
計算結果通過PCIE讀取回應用程序進行結果展示或者上報。
從以上典型的應用場景可以看到,BMCV庫和FFMPEG提供了對視頻的流水線式處理,以源視頻流的形式傳輸到BM1682 PCIE板卡上進行解碼后,每幀圖像數據將留存于PCIE板卡的內存中,在后續圖像處理和神經網絡計算中復用,達到零拷貝的效果,在計算機/服務器安裝多塊板卡的高密度計算場景中可以充分利用板卡的硬件資源,大大減少PCIE總線上的數據吞吐量。
6 結語
相信在未來,AI 勢必將徹底改造安防這個傳統的行業,賦予安防系統以人工智能,自動化的處理視頻、圖片等非結構化數據和結構化數據,提升信息搜索的精準程度,極大提高警務效率,讓整個社會更安全、更有秩序,而這有賴于行業上下游的通力配合。
但需要注意的是,在這個耗資巨大、耗時很長的行業中,尋找具有創新性的、性價比高、可大規模部署的方案,是最務實也最接近成功的道路。在產業鏈方面,處在上游的芯片行業的產品和方案在很大程度上決定著安防系統的整體功能、技術、成本等核心指標,同時也是影響安防行業未來的關鍵因素。
猜你喜歡
開放教育研究(2021年3期)2021-05-25 02:41:06
小學科學(學生版)(2020年12期)2021-01-08 09:28:04
裝備制造技術(2020年4期)2020-12-25 05:26:24
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
能源(2018年4期)2018-05-19 01:53:44
