知識圖譜系統研發
2019-10-21 09:15:38袁若瀛
現代信息科技 2019年5期


摘 ?要:本工程要實現一個關于“動物”的知識圖譜系統,用來描述“動物”的各種實體和概念,以及它們之間的強關系,我們用SPO三元組(Subject-Predicate-Object)去描述兩個實體間的關聯,簡單理解就是“實體-實體關系-實體”,例如,貓和貓科動物之間的關系是科,用“貓-科-貓科”來表示,把實體看作結點,實體關系看作一條邊,那么就可以構建一個龐大的關于“動物”的知識圖。構建“動物”知識圖譜需要動物的實體和實體間關系,這些數據需要通過網絡爬蟲技術從網上獲取,但網上獲取的數據是文本形式,不能直接使用,所以需要用到知識抽取技術,本文使用基于句法依存關系的方法,實現了提取文本中的實體及實體間關系,然后以三元組的形式將這種關系表現出來,最后將生成的SPO三元組存入Neo4j圖數據庫,形成一個“動物”知識圖譜。
關鍵詞:知識圖譜;網絡爬蟲;知識抽取;SPO三元組;NEO4J圖數據庫
中圖分類號:TP391.1 ? ? ?文獻標識碼:A 文章編號:2096-4706(2019)05-0013-05
Abstract:This project is to implement a knowledge atlas system about “animals” to describe the various entities and concepts of “animals” and the strong relationship between them. We use SPO triple (Subject-Predicate-Object) to describe the relationship between two entities. The simple understanding is that the relationship between (entity-entity relationship-entity) such as cats and catamount is science. We use “cat-family-cat family” to express it. We regard entities as nodes and entity relations as one side. Then we can construct a huge knowledge map about animals. Constructing the knowledge map of “animal” requires the relationship between animal entities and entities,and these data need to be obtained from the internet through web crawler technology,but the data obtained on the internet is in the form of text. It can't be used directly,so we need to use knowledge extraction technology. This paper uses the method based on the syntactic dependency relation to extract the relationship between entities in the text,and then express the relationship in the form of triples. Finally,the generated SPO triples need to be stored in Neo4j graph database to form an “animal” knowledge map.
Keywords:knowledge map;web crawler;knowledge extraction;SPO triple;NEO4J graph database
1 ?針對復雜工程問題的方案設計與實現
1.1 ?“動物”知識圖譜的方案設計
問題分析:關于“動物”的知識圖譜系統,知識圖譜的主要作用是描述“動物”的各種實體和概念及實體間關系,我們必須使用一種數據結構來描述這種聯系,于是我們采用SPO三元組(Subject-Predicate-Object)去描述兩個實體間的關聯,簡單理解就是“實體-實體關系-實體”,例如,貓和貓科動物之間的關系是科,我們就用“貓-科-貓科”來表示,把實體看作結點,實體關系看作一條邊,那么就可以構建一個龐大的關于“動物”的知識圖譜。
設計思路:構建“動物”知識圖譜需要動物的實體和實體間關系,而這些數據需要通過網絡爬蟲技術從網上獲取,但網上獲取的數據是非結構化數據的形式(如文本),不能直接使用,所以需要用到知識抽取技術。本文使用基于句法依存關系的方法實現了提取文本中的實體及實體間關系,然后以三元組的形式將這種關系表現出來,最后將生成的SPO三元組存入圖數據庫,形成一個“動物”知識圖譜。
在系統總體設計中,將本工程劃分為四個基本模塊,以實現知識圖譜系統。
首先在第一個模塊中,需要完成網絡爬蟲進行數據獲取工作,設計一個多源數據獲取系統。該模塊被分為兩個子模塊,分別從百度百科和互動百科中獲取動物分類中的詞條信息,對該詞條信息進行基本的文本處理,然后存入txt文件中。其中,詞條信息包含半結構化的基本信息和非結構化的簡介信息。
第二個模塊是基于句法依存關系的關系抽取模塊,主要功能是對多源數據獲取模塊輸出的文本通過關系抽取,提取詞語和依存關系等顯性特征,然后根據這些顯性特征,通過知識推理,得到隱性特征。由于此模塊功能復雜且內聚性低,所以應分為顯性特征提取模塊和隱形特征提取模塊,顯性特征提取模塊的輸出作為隱形特征提取模塊的輸入。這個過程用到了pyltp庫基于依存句法的關系三元組抽取。
第三個模塊是生成三元組模塊,這一階段的任務是將特征提取模塊得到的實體屬性和實體間的關系形成SPO三元組。
最后的模塊是存入數據庫模塊,即將生成的三元組存入Neo4j圖形數據庫。選擇Neo4j圖形數據庫是因為需要一個圖形數據庫。
1.2 ?針對“動物”知識圖譜問題的推理分析
知識抽取(實體關系抽取)是知識圖譜構建的核心環節,實體關系抽取作為一項基本技術,在自然語言處理應用中發揮著重要作用,也是本項目的關鍵步驟之一。關系抽取的方法非常多,有基于規則的方法和基于學習的方法等,由于基于學習的方法涉及到深度學習模型等非常復雜的算法,所以我們選擇了基于規則的方法。基于規則的方法中有諸如基于觸發詞的特征,但由于這種方法是基于模板的關系抽取方法,因此只適合小規模應用,而且模板的構建需要專業知識,并花費大量的時間,考慮到本工程要做整個“動物”的知識圖譜,數據量非常大,所以不適合本工程。綜合本工程的實際需求和實際情況,我們的初步設想是使用基于句法解析的關系抽取方法,雖然也是基于模板,但是因為本工程的文本信息全部出自百科動物類的基本詞條,所以模板的構建是切合實際的。
1.3 ?針對“動物”知識圖譜問題的方案實現
開發環境為Win10(x64)操作系統下python3.6.4,用到的工具庫有Beautiful Soup4(一個HTML/XML的解析器)、pyltp(中文自然語言處理)和Neo4j(圖數據庫)。
1.3.1 ?網絡爬蟲
網絡爬蟲實現了從互動百科、百度百科上爬取與“動物”相關的詞條信息,而爬蟲問題的關鍵在于如何只爬取與“動物”相關的網頁,我們采用的思路是先爬取“動物”分類下的一部分動物名字、類名、界名等詞語,作為爬蟲初始的url的關鍵字,然后在這些頁面中找出該頁面中所有的百科url。
links = soup.find_all('a', href=re.compile(r"/ ?item/"))#搜索所有滿足條件的url
這里需要用到Beautiful Soup4工具對網頁進行解析,具體過程是先通過調用Beautiful Soup4的庫函數Beautiful Soup將用utf-8編碼的網頁進行解析,處理成格式化后的字符串,然后調用find和find_all找到我們需要的標簽,可是詞條是帶有注釋的,而我們不需要注釋,所以要用正則表達式刪除注釋。
re_comment = re.compile('\[[0-9]+\]')#去掉的形式為中括號里面帶數字的結構
attributes_value = re_comment.sub('', attributes_value)
提取出來的信息包括基本詞條信息和簡介信息,基本詞條信息已經是結構化數據,即是現成的SPO三元組,如“貓{'科:'貓科}”,而簡介信息還是文本的形式,需要在接下來用關系抽取,從文本中抽取關系三元組。
1.3.2 ?關系抽取
關系抽取采用依存句法分析,其基本原理為:
(1)一個句子中,必須只有一個獨立成分,且該成分不依存于其他成分;
(2)在一個句子中,其他成分必須依存與某一成分;
(3)在一個句子中,無論對于任何成分而言,其依存的成分最高數量為1,不能超過這一數量,簡單地說,句子中的任意成分,其所依存的成分量不能大于等于2;
(4)假設句子中存在三個成分,分別為1、2和3,在三個成分當中,如果1直接依賴于2,而3在1與2中間,那么3既可以依存于1,又可以依存于2,但需要認識到的是,一定要堅持第三點公理,3必須單獨依賴于1或2。除此之外,成分3也可以既不依賴于1,也不依賴于2,而是依賴于兩者之間的某一成分N。
簡單來講,就是通過分析語言單位內成分之間的依存關系揭示其句法結構。依存句法分析識別句子中的“主謂賓”、“定狀補”這些語法成分,并分析各成分之間的關系。依存句法分析本質上可以轉換為分類問題,所以將依存句法作為序列標注任務進行解決也是可行的。
具體算法實現如下:
首先,我們導入了第三方分詞庫pyltp用于中文分詞處理和詞性(名詞、動詞等等)的分析,首先調用pyltp的庫函數進行句子的成分分析,得到句子的分詞結果,每個詞的詞性和每兩個詞之間的關系,例如,輸入的數據是“貓,屬于貓科動物,分家貓、野貓,是全世界家庭中較為廣泛的寵物。家貓的祖先據推測是起源于古埃及的沙漠貓,波斯的波斯貓,已經被人類馴化了3500年(但未像狗一樣完全地被馴化)。”這是百度百科貓的簡介,也是需要進行關系抽取的對象之一。
tags = soup.find('dd', {'id': 'open-tag-item'})
#調用pyltp庫得到分詞結果
words = list(self.segmentor.segment(sentence))
#得到每個詞的詞性
postags = list(self.postagger.postag(words))
#得到詞語之間的依存關系
arcs = self.parser.parse(words, postags)
#對arcs進行規范化,將其容易讀一點,并存入字典,方便使用
child_dict_list, format_parse_list = self.build_parse_child_dict(words, postags, arcs)
得到的標注關系很長,在此不一一羅列,這是其中的兩個例子:
['SBV', '貓', 0, 'n', '屬于', 2, 'v']
['ATT', '貓科', 3, 'n', '動物', 4, 'n']
第一個,SBV是指主謂關系,“貓”是主語,0是“貓”的索引值,因為“貓”是句子的第一個詞,n是“貓”的詞性,為名詞。因為“貓”和“屬于”間有個逗號,所以“屬于”的索引值為2,然后“屬于”是動詞。
第二個同理,ATT是指定中關系。
標注的關系有很多種,以下是12種依存句法分析標注關系,如表1所示。
由于關系抽取想要獲得的關系是用于進行知識圖譜的構建,SPO三元組中比較好處理的一種類型就是主謂賓的形式,所以利用語義關系標注,獲取所有的主謂賓三元組。
if 'SBV' in child_dict and 'VOB' in child_dict:
r = words[index]
e1 = self.complete_e(words, postags, child_dict_list, child_dict['SBV'][0])
e2 = self.complete_e(words, postags, child_dict_list, child_dict['VOB'][0])
svos.append([e1, r, e2])
提取得到三元組后,這個三元組的主語和賓語其實是不完整的,缺少對主語和賓語的修飾語,所以還需要對三元組中的主語和賓語進行擴展。我們用主語和賓語相關的定中關系,即加上名詞的修飾語。
if 'ATT' in child_dict:
for i in range(len(child_dict['ATT'])):
prefix += self.complete_e(words, postags, child_dict_list, child_dict['ATT'][i])
postfix = ''
if postags[word_index] == 'v':
if 'VOB' in child_dict:
postfix += self.complete_e(words, postags, child_dict_list, child_dict['VOB'][0])
if 'SBV' in child_dict:
prefix = self.complete_e(words, postags, child_dict_list, child_dict['SBV'][0]) + prefix
現在可以抽取得到剛才那段話中的三元組了:
['貓', '屬于', '貓科動物'], ['貓', '是', '全世界家庭中較為廣泛寵物'], ['家貓祖先', '是', '起源']
可以看到,前兩個三元組非常合理,證明句法依存確實能提取出有價值的三元組,但是,同時也出現了一些問題,第三個三元組缺少了“起源”修飾語。這也是本系統需要改進的地方。
1.3.4 ?生成知識圖譜
這一模塊的功能是將所有的三元組導入Neo4j圖形數據庫,利用圖形數據庫生成知識圖譜。這個過程包含知識庫的融合,需要將來自于不同數據源(百度百科、互動百科)、以不同方法(從半結構化數據中直接提取、基于句法依存關系的知識抽取)提取的三元組存儲到同一個數據庫中。在知識融合的過程中,需要去除沖突項、冗余項。
(1)Neo4j數據庫簡介。Neo4j數據庫是一種NOSQL圖形數據庫,與傳統關系數據庫相比,它將結構化數據存儲在網絡(圖)中,而不是表中。網絡或者圖是一種靈活的數據結構,它具有有靈活、敏捷的特點。
網絡由節點、邊、屬性構成。每一個節點代表一個實體;實體之間通過邊進行連接,邊代表實體之間的關系;無論是頂點或者邊都可以有任意多的屬性,以key:balue的形式進行存儲。
(2)py2ne模塊。py2ne模塊是一個面向Neo4j數據庫管理的python庫。py2ne封裝了大量的Neo4j的數據庫操作,包括連接Neo4j數據庫、創建節點、創建關系、通過節點/關系進行查詢等。
(3)導入三元組。這一步驟分兩步進行,首先將從半結構化的數據中提取的三元組導入數據庫,然后在此基礎上導入從文本中經過知識抽取得到的三元組,這個過程包括去除冗余項和沖突項。
導入三元組具體的操作步驟如下所示:
1)首先調用py2neo的Graph()方法,通過參數輸入賬號、密碼,連接數據庫;
2)調用Node()方法創建節點,創建節點時根據實體進行查詢,若圖中已經有該實體對應的節點,不再創建節點,反之,則創建節點,調用create()方法將節點存入數據庫;
3)調用Relationship()方法創建關系,調用create()方法將關系存入數據庫。
(4)Neo4j的Web控制臺。打開Neo4j數據庫的Web控制臺,在這里可以對數據庫進行增刪查改等基本操作,而這些操作通過Neo4j自帶的Cypher語言實現。
當三元組完全且正確地導入數據庫后,我們的知識圖譜基本上已經構建完成,但是需要以Graph的形式顯示出來。在Web控制臺頁面的左側,我們可以點擊Entity,進而查看一部分知識圖譜,點擊其中任一個節點,選擇展開Expand child relationships就可以得到更多的節點和關系,這樣一步步展開,可以顯示完整的知識圖譜,但這種方式無疑是很笨拙。如果要查看完整的知識圖譜,只需要修改查詢語句,設置Limit節點數足夠大,就可以顯示出完整的知識圖譜。需要注意的是,數據庫將最多顯示節點數初始值設置為300個,我們在使用時要將其值修改為一個足夠大的數,不然無論怎么修改查詢語句,也最多只能顯示300個節點。
為了更好地查看完整的知識圖譜,可以將其保存為svg圖片格式,再通過svg圖片查看器(例如Inkscape)進行查看。
2 ?系統測試
測試環境為Win10(x64)操作系統下python3.6.4,用到的工具庫有Beautiful Soup4(一個HTML/XML的解析器)、pyltp(中文自然語言處理)和Neo4j(圖數據庫)。
2.1 ?關系抽取測試
將百度百科簡介信息進行依句法依存關系完成關系抽取的結果。
處理前:
金眼鯛目(Beryciformes)是硬骨魚綱輻鰭魚亞綱的1目。化石始于白堊紀。現有3亞目14科約38屬164種。
角鯊目(Squaliformes),軟骨魚綱板鰓亞綱的一目。有3科21屬87種。背鰭2個,硬棘有或無;臀鰭消失。鰓孔5個,椎體環型或多環型。吻軟骨1個。主要分布于世界各溫水、冷水海區或深海。
鳥臀目(拉丁目名Ornithischia或Predentata)也稱為鳥盤目。是一類有喙(外觀類似鳥喙)的草食性恐龍。意思是“如鳥類般的臀部”。之所以有這種名字,是因為它們擁有與鳥類相似的骨盆結構。
海魴目(Zeiformes)是硬骨魚綱的1目。約有6科21屬36種,均為海產。體側極扁且高;上頜顯著突出,無輔上頜骨;鱗細小或僅有痕跡;背、臀鰭基部及胸腹部有棘狀骨板;后顳骨不分叉,與頭蓋骨連接;第一脊椎骨與頭蓋骨密切連接;背鰭鰭棘部發達,與鰭條部區分顯明;背鰭有5~10鰭條,棘間膜延長呈絲狀;臀鰭有1~4鰭棘;背、臀鰭及胸鰭條均不分枝;腹鰭胸位,通常有1鰭棘5~9鰭條;無目匡蝶骨;鰾無管,有或無牙。
燕鳥目是今鳥亞綱的一目,僅有1科1屬,即燕鳥科燕鳥。
處理后:
[['金眼鯛目', '是', '硬骨魚綱輻鰭魚亞綱1目'], ['化石', '始', '白堊紀'], ['現有', '屬', '164種']]
[['3科', '屬', '87']]
[['鳥臀目', '稱為', '鳥盤目'], ['意思', '是', '鳥類臀部'], ['它們', '擁有', '與鳥類相似骨盆結構']]
[['海魴目', '是', '硬骨魚綱1目'], ['6科', '屬', '36'], ['鱗', '有', '痕跡'], ['背臀鰭基部及胸腹部', '有', '棘狀骨板'], ['與鰭條部', '區分', '鰭棘部'], ['背鰭', '有', '510鰭條'], ['棘間膜', '延長', '呈絲狀'], ['臀鰭', '有', '14鰭棘'], ['背', '分', '枝'], ['腹鰭胸位', '有', '1鰭棘5條'], ['鰾', '無', '管'], ['鰾', '有', '牙'], ['鰾', '無', '牙']]
[['燕鳥目', '是', '今鳥亞綱一目'], ['燕鳥目', '有', '1科1屬']]
可以看出,“燕鳥目是今鳥亞綱一目”被分為了[['燕鳥目', '是', '今鳥亞綱一目']],成功提取了實體間關系并生成三元組,但是由于是通過句法依存分析得到的,所以會有很多不合理的三元組。
2.2 ?Neo4j圖數據庫測試
總體效果:共生成接近6000個結點,10000多個聯系。
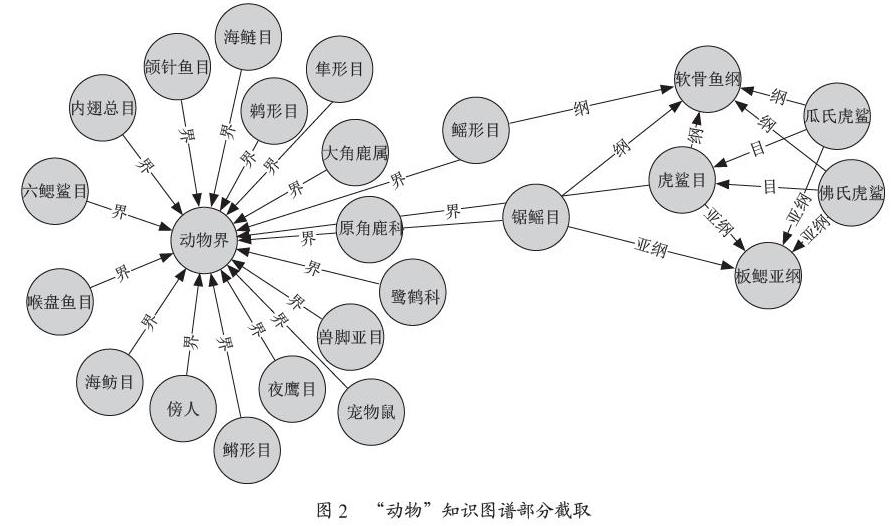
“動物”知識圖譜總體效果如圖1所示,結點之間的聯系非常多,且大部分結點都有相互關聯的結點,證明知識圖譜構建比較成功,但由于整體效果無法判斷知識圖譜是否準確,所以選擇了一小部分結點,測試效果如圖2所示。
可以看到,SPO三元組以圖的形式呈現出來(因為只取了一小部分結點和聯系,所以圖上很多結點沒有相互關聯,其實很多是有關聯的)。可以清楚地找到一個動物和與之相關的實體和實體間聯系。
參考文獻:
[1] 王延領.python 3.x 爬蟲基礎——Requersts,Beautiful-Soup4(bs4) [EB/OL].http://www.cnblogs.com/kmonkeywyl/ p/8482962.html,2018-04-03.
[2] Pelhans.知識圖譜入門(三)知識抽取 [EB/OL].https: //blog.csdn.net/pelhans/article/details/80020309,2018-04-20.
[3] MihaiWang.Python操作Neo4j的基本操作 [EB/OL].https://blog.csdn.net/wmh13262227870/article/details/77842 513,2017-09-04.
作者簡介:袁若瀛(1998.06-),男,漢族,山東菏澤人人,本科,主要研究方向:大數據、機器學習。
