基于機器學習的毫米波大規模MIMO混合預編碼技術
2019-10-18 09:43:57劉斌任歡李立欣
移動通信 2019年8期
關鍵詞:機器學習
劉斌 任歡 李立欣


【摘? 要】毫米波大規模多輸入多輸出技術是提高5G移動通信容量的核心技術之一,其中混合預編碼技術作為大規模MIMO系統中最關鍵的技術而被廣泛研究。采用傳統的迭代算法解決混合預編碼問題通常導致較高的計算復雜度和嚴重的系統性能損失。機器學習方法由于其具有自適應學習和決策的優勢而被應用于混合預編碼器的設計工作中。在機器學習的基礎理論上提出了一種采用交叉熵優化策略的混合預編碼算法,通過迭代更新具有穩健誤差的交叉熵損失函數得到最佳的混合預編碼器組合,該組合被證明可以實現理想的傳輸總和速率,可以顯著提高系統的能量效率。
【關鍵詞】機器學習;交叉熵;混合預編碼;大規模MIMO
doi:10.3969/j.issn.1006-1010.2019.08.002? ? ? 中圖分類號:TN929.5
文獻標志碼:A? ? ? 文章編號:1006-1010(2019)08-0008-06
引用格式:劉斌,任歡,李立欣. 基于機器學習的毫米波大規模MIMO混合預編碼技術[J]. 移動通信, 2019,43(8): 8-13.
Millimeter wave (mmWave) massive multi-input and multi-output (MIMO) is one of the key technologies to improve the capacity of 5G mobile communications, where hybrid precoding has been widely studied as the most critical problem in massive MIMO systems. The traditional iterative algorithms for hybrid precoding problems usually lead to high computational complexity and severe system performance loss. Machine learning is adopted in the design of hybrid precoders due to its advantages of adaptive learning and decision making. Based on the fundamental theory of machine learning, a hybrid precoding algorithm using cross-entropy optimization strategy is proposed. By iteratively updating the cross-entropy loss function with robust error, the optimal hybrid precoder combination is obtained. The combination has been shown to achieve an ideal transmission sum rate and significantly increase the energy efficiency of the system.
machine learning; cross-entropy; hybrid precoding;? massive MIMO
1? ?引言
大規模多輸入多輸出(MIMO)通信技術將在第五代移動通信系統中得到廣泛的應用,MIMO天線的數量可以是成千上百個,理論上可以實現無限的通信容量。與此同時,該技術的實現需要理想的低功耗射頻組件,并要求所有的復雜處理運算在基站處進行,例如信道估計、預編碼和權值計算等。具體而言,基站作為發射端通常包含預編碼器,該編碼器能夠進行復雜的混合預編碼,利用信道狀態信息(Channel State Information, CSI)生成預編碼矩陣,也就是對發射信號進行預處理操作。因此,高效而準確地建模并求解傳統的混合預編碼問題受到了業界的廣泛關注。
機器學習作為自適應學習和決策的人工智能工具之一,已經在圖像/音頻處理、社會行為分析和項目管理等方面得到廣泛應用[1]。近年來,機器學習與無線移動通信領域的結合不僅僅停留在理論的研究階段,高速和強大計算能力的硬件技術的出現,使得機器學習理論已經成為現實。智能基站和移動終端可以模仿人類的復雜學習和決策能力,對耗時和計算密集的多樣化問題迅速做出最優決策。通過對毫米波大規模MIMO系統中的混合預編碼問題進行嚴格建模,可以采用機器學習的方法訓練出最優的預編碼矩陣。在機器學習領域中的交叉熵[2]方法被應用于解決組合優化問題,這啟發了將其應用于毫米波大規模MIMO系統中的復雜混合預編碼方法的研究。
交叉熵方法來源于Kulback-Leibler距離,最早是在1997年由Rubinstein在估計隨機網絡稀有事件概率的自適應方法最小化算法中提出的。交叉熵理論是一種測量兩個隨機向量之間信息差異的計算方法,本質上是一種基于數學統計的全局隨機優化算法。到目前為止,交叉熵方法已經被成功應用于建模為組合優化的各種問題中,包括緩沖區分配、電信系統的排隊模型、神經計算、控制和導航、DNA序列比對、信號處理、調度、車輛路線、項目管理和可靠性系統[3]等。
本文在機器學習的基礎理論上提出了一種采用交叉熵優化策略的混合預編碼算法,通過迭代更新具有穩健誤差的交叉熵損失函數得到最佳的混合預編碼器組合,可以實現理想的傳輸總和速率,顯著提高系統的能量效率。
2? ?研究背景
2.1? 混合預編碼
模數混合預編碼是一項目前為止用于毫米波大規模MIMO系統中最有前景的混合預編碼技術,旨在設計出低維的數字預編碼器和高維的模擬預編碼器,從而實現高效節能的混合預編碼。混合預編碼技術通過在數字預編碼部分使用少量的射頻鏈,在模擬預編碼部分設計低成本的模擬電路從而實現接近全數字預編碼的最優系統性能。
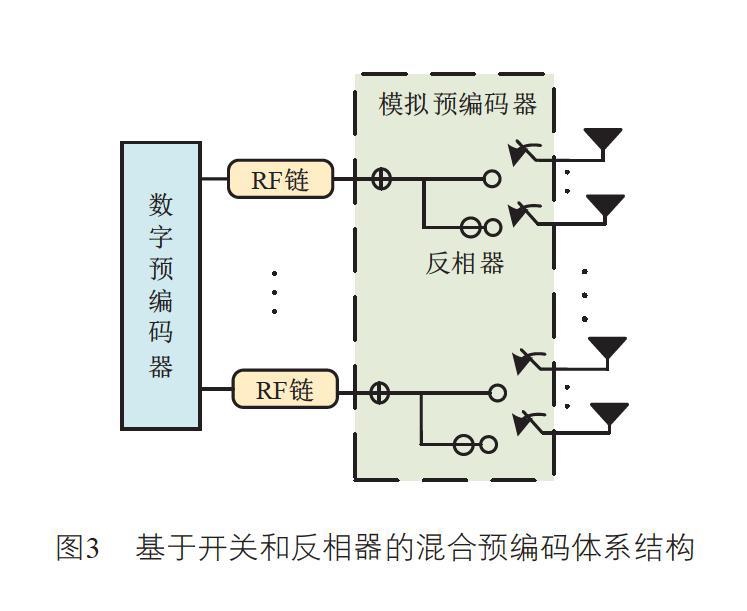
傳統的混合預編碼器中,模擬預編碼部分可以使用移相器網絡[6](如圖1所示)或者開關選擇網絡[7](如圖2所示),但是這兩種方案分別在系統成本和性能上存在明顯的缺陷。在大多數現有的文獻中,移相器的能量消耗被證明是相對較高的(例如,4位移相器的能耗高達40 mW),而開關的能量消耗是很理想的(開關的能耗低至5 mW),但是圖2所示的體系結構不能完全實現毫米波大規模MIMO陣列增益,導致了嚴重的系統性能損失。現如今,已有在無人機毫米波大規模MIMO場景中采用基于透鏡陣列天線的混合預編碼方案的研究[8],由此啟發本文采用一種折中的混合預編碼體系結構,模擬預編碼部分由開關和反相器實現(圖3所示)。事實證明,該體系結構的能量消耗遠遠低于移相器網絡,同時,隨著大規模MIMO中所有天線被使用,該體系結構還可以實現毫米波大規模MIMO陣列增益。
2.2? 組合優化問題建模
交叉熵方法可以解決一般性的組合優化問題,其主要思想是通過構造隨機序列,使其以一定的概率收斂到最優或次優的結果。設χ是一組有限的狀態,S是χ上的實值性函數,實值函數S(x)的定義域為{x|x∈χ},若S(x)的最大值為γ*,則要使得下式取得最大值,本質在于尋找其對應的最佳狀態,如公式(1)和(2)所示:
S(x*) γ*=S(x) ? ?(1)
其中,x*表示最佳的狀態,在集合χ中尋找最佳的狀態最大化實值函數S(x)。
首先,定義指示函數I{S(χi)}和參考概率密度函數族{f(.;v),v∈V},對于給定的實數γ,得到下面的關聯估計表達式為:
其中,Pu是隨機狀態X 具有概率密度函數{f(.;v),v∈V}的概率度量,Eu表示相對應的期望算子,u 是某已知初始化概率分布的參數。如公式(2)所示,實值函數的最小化問題就轉化為隨機優化問題。
實際中應用交叉熵方法的應用主要有兩個關鍵階段:第一是根據一定的隨機性或概率分布構造一個隨機序列樣本;第二是更新概率分布的參數,從而在下一輪迭代計算中產生更優的隨機序列樣本。
2.3? 交叉熵方法
交叉熵量化信息量之間的“距離”——Kullback-leible距離[9],描述了兩個概率分布之間的差異。當兩個模型的概率分布保持一致時,交叉熵值更小,并且這兩個模型之間的接近程度更大。更直觀地講,交叉熵的表達式為:
D(g,h)=Egln=∫g(x)lnh(x)-∫h(x)lng(x)
∫g(x)dx=1? (5)
∫h(x)dx=1? ? ? ? ? ? ? ? (6)
交叉熵方法解決了四個基本特征的問題:首先,根據優化目標建立概率密度函數,形成交叉熵目標函數;其次,根據概率分布函數生成樣本集,并且參考目標函數的影響更新概率密度函數;然后,新概率分布函數用于生成一組新的樣本,迭代重復目標函數;最后,當目標函數達到最優時,概率密度功能也達到了最佳解決方案。
交叉熵算法具有全局優化。它根據參數的概率分布密度函數生成樣本解,在已經搭建好的組合優化問題模型中,概率分布和參數的形式決定了樣本解決方案的整體質量。與其他智能算法相比,它避免了陷入局部最優和計算速度太慢的缺點。在優化過程中,交叉熵算法不要求每個生成的解決方案都優于樣本解決方案的先前迭代的解決方案,但是在整個迭代過程中,預測結果往往越來越靠近理想中的標簽樣本。
3? ?基于機器學習的交叉熵混合預編碼算法
3.1? 混合預編碼優化問題建模
本文采用如圖3所示的基于開關和反相器的混合預編碼架構,優化目標是設計出模擬波束形成器和數字預編碼器的最優組合,使得系統可實現的總和速率達到最大,該優化問題可以表示為:
其中,表示滿足由于圖3的混合預編碼體系結構帶來的約束的所有模擬預編碼器的集合,||FRFFBB||2F=ρ表示功率約束,η n 表示用戶n 接收到的信干噪比。
在圖3所示的體系結構中,每根射頻鏈通過反相器和開關選擇網絡連接到天線子集,該連接方式導致模擬預編碼矩陣成為塊對角矩陣,如公式(8)所示。同時,由于反相器和開關被使用,模擬預編碼矩陣中的元素取值有限,如公式(9)所示:
其中,表示第n個天線陣列上的模擬波束形成器。
第n個用戶接受到的SINR可以表示為:
其中,hnFRF fBBnFHRFhHn表示用戶n接收到的有用信號功率,hnFRF fBBiFHRFhHn表示用戶n接收到的來自其他用戶的干擾功率,σ2表示噪聲功率。
因為公式(8)和(9)的存在,問題(7)成為一個模擬預編碼矩陣FRF和數字預編碼矩陣FBB的組合優化問題,本文要采用交叉熵方法得到最優的預編碼矩陣組合,從而實現最大的系統總和速率。
3.2? 具有穩健誤差的交叉熵混合預編碼算法
將交叉熵方法應用于上述組合優化問題,本文對傳統的交叉熵方法加以改進,提出一種具有穩健誤差的交叉熵混合預編碼算法,與傳統交叉熵方法類似,主要關注兩個關鍵問題:第一:根據一定的隨機性或概率分布構造一個隨機序列樣本;第二:更新概率分布的參數,從而在下一輪迭代計算中產生更優的隨機序列樣本。
本文所提出的具有穩健誤差的高效節能混合預編碼方案,步驟詳細解釋如下:
在算法具體實施之前,必要的準備工作有:將FRF中對角線的非零元素表示為N×1向量組,其中表示FRF矩陣中對角線的非零元素。FRF中元素的分布概率參數表示為N×1向量組u=[u1,u2,…,uN]T,其中un表示fn=的概率,fn是 f的第n個元素。
(1)對算法中的變量進行初始化,對于概率分布初始化u(0)=×1N×1,給迭代次數i賦初值i=0。
(2)基于概率模型(FRF;u(i))隨機生成S個模擬波束形成器{FsRF}sS=1,其中概率模型即模擬預編碼矩陣中元素的取值{-1,+1}的概率分布容易得到,該取值遵循伯努利概率分布。
(3)通過經典迫零數字預編碼方法計算數字預編碼矩陣{FsBB}sS=1,根據有效信道矩陣和模擬預編碼矩陣之間的關系表達式Heq=HFRF,計算出有效信道矩陣Hseq,基帶預處理之后的數字預編碼矩陣可以表示為:
FsBB=(Hseq)H(Hseq(Hseq)H)-1? ? ? ? (11)
對數字預編碼矩陣FBB的每一列進行功率歸一化處理,即||FsRFFsBB||2F=1,確定生成最終的數字預編碼矩陣FBB。
(4)計算經過迭代更新的預編碼矩陣所實現的系統總和速率{R(FsRF)}Ss=1(由公式(7)和公式(10)計算可得),并且根據計算所得的總和速率對其排序R(F[1]? ?RF)≥
R(F[2]? RF)≥…≥R(F[s]RF)。
(5)計算FsRF的權重,通過公式(12)估計每個模擬預編碼矩陣中元素的權重:
(6)更新FRF中元素的概率分布,也是交叉熵方法中最為關鍵的一步。
參考相對誤差估計公式得到更新概率分布元素的公式(13):
最后,重復上述步驟,直到達到最大的迭代次數I,最終,模擬波束形成器FRF[1]將由接近最優概率分布的元素構成,從而得到數字預編碼矩陣FBB[1]。
該程序中γ為可變參數,當γ>0時,γ為控制魯棒程度的參數;當γ=0時,對應目標函數為負對數似然函數,并且隨著γ增加,程序對于異常值的魯棒程度增強。在實際中,可以通過基于γ-交叉熵的交叉驗證來選擇γ的值。該程序對異常值具有魯棒性,該程序基于γ-交叉熵函數,已有仿真結果表明,該程序在預測精度方面比普通相對誤差估計程序更加精確。
4? ?仿真結果
4.1? 信道模型
本文采用幾何信道模型獲取毫米波MIMO信道的特征,信道矩陣如公式(22)所示:
4.2? 仿真結果
這一部分提供了算法的仿真結果,如圖4和圖5所示。信道帶寬設置為1 MHz;射頻鏈的數量和數據流的數量是相等的,即NS=NRF=4;基站和射頻鏈同時服務的單天線用戶數為K=4;接收端的天線數目設置為N=64。信道矩陣中具體的參數設置如下:損失路徑數目L=3,路徑增益遵循標準正態分布αln~CN(0,1),方位角和到達角遵循均勻分布φnl ~U(0,2π)和θnl ~U(0,2π)(1≤l≤L)。實驗設置參數如下:S=250,I=20。另外,在本文中,根據現有方法[10]的模擬結果,取γ值為0.5。
本文分別比較了全數字預編碼方案、兩階段混合預編碼方案、天線選擇混合預編碼方案以及本文所改進的具有穩健誤差的混合預編碼方案所能實現的系統總和速率和能量效率。
實驗比較了不同算法所能實現的系統總和速率,結果如圖4所示。在圖4中,全數字預編碼和兩階段預編碼算法獲得了良好的總和速率性能,天線選擇預編碼的總和速率性能最差,這是因為開關選擇網絡無法實現毫米波大規模MIMO系統潛在的陣列增益。而本文所提的具有穩健誤差的交叉熵混合預編碼可以達到遠遠高于天線選擇預編碼所能達到的系統總和速率。
另外,實驗對比了系統的能耗隨著用戶數量(1~16)變化的性能,結果如圖5所示。在圖5中,隨著用戶數量的增加,兩階段混合預編碼和本文所提的具有穩健誤差的交叉熵混合預編碼可以獲得比其他兩種預編碼方案更高的能量效率。這是因為在前兩種方案中低能耗的開關和其他少量耗能元件(反相器和移相器等)被使用,而在天線選擇混合預編碼中,僅由開關實現模擬預編碼,導致系統的總和速率很低(如圖4所示),從而無法實現理想的能量效率。而全數字預編碼中復雜的移相器存在巨大的能量消耗,所以該方案下系統的能量效率是不理想的,在實際中,不建議采用此方案。
綜合上述的實驗結果,本文所提出的具有穩健誤差的混合預編碼算法可以取得預期的系統總和速率和理想的能量效率,驗證了基于開關和反相器的混合預編碼體系結構和本文所提算法的有效性。
5? ?結束語
本文提出了一種應用機器學習方法解決實際中毫米波大規模MIMO中的混合預編碼器設計問題的方案,具體闡述了機器學習中交叉熵方法的應用原理和關鍵步驟,并將此方法應用于毫米波大規模MIMO場景中,解決可以構建為組合優化問題的混合預編碼器設計問題,并通過實驗解釋驗證了該方法的高效性和可行性。未來機器學習與無線通信結合的理論研究將是人工智能時代的重點,本文旨在為今后的研究工作提供思路和參考。
參考文獻:
[1] M J Er, Y Zhou. Theory and Novel Applications of Machine Learning[M]. InTech, 2009.
[2] R Y Rubinstein, D P Kroese. The Cross-Entropy Method: A Unified Approach to Combinatorial Optimization, Monte-Carlo Simulation, and Machine Learning[J]. Technometrics, 2006,48(1): 147-148.
[3] X Huang, W Xu, G Xie, et al. Learning Oriented Cross-Entropy Approach to User Association in Load-Balanced HetNet[J]. IEEE Wireless Communications Letters, 2018,7(6): 1014-1017.
[4] G Alon, D P Kroese, T Raviv, et al. Application of the Cross-Entropy Method to the Buffer Allocation Problem in a Simulation-Based Environment[J]. Annals of Operations Research, 2005(1): 137-151.
[5] H Xie, F Gao, S Jin. An Overview of Low-Rank Channel Estimation for Massive MIMO Systems[J]. IEEE Access, 2016(4): 7313-7321.
[6] A Alkhateeb, Y H Nam, J Zhang, et al. Massive MIMO Combining with Switches[J]. IEEE Wireless Communications Letters, 2016,5(3): 232-235.
[7] J Gu, W L Liu, S J Jang, et al. Cross-Entropy Based Spectrum Sensing[C]//2010 IEEE International Conference on Communication Technology, 2010: 373-376.
[8] H Ren, L Li, W Xu, et al. Machine Learning-Based Hybrid Precoding with Robust Error for UAV mmWave Massive MIMO[C]//2019 IEEE International Conference on Communications (ICC). Shanghai, China, 2019: 1-6.
[9] S Buzzi, C D Andrea. Doubly Massive mmWave MIMO Systems: Using Very Large Antenna Arrays at Both Transmitter and Receiver[C]//2016 IEEE Global Communications Conference (GLOBECOM). 2016: 1-6.
[10] K Hirose, H Hirose. Robust Relative Error Estimation[J]. Entropy, 2018,20(9).★
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
