基于spark的協(xié)同過濾推薦算法的改進(jìn)
2019-10-08 09:03:43李淑敏夏茂輝趙志偉
軟件 2019年2期
李淑敏 夏茂輝 趙志偉

摘? 要: 在協(xié)同過濾推薦算法中,如果用戶-評(píng)價(jià)矩陣稀疏,共同評(píng)價(jià)的物品個(gè)數(shù)少,就很難準(zhǔn)確的計(jì)算出用戶相似度,加上其它實(shí)際因素,會(huì)使最終的推薦結(jié)果與實(shí)際結(jié)果有很大的差異,推薦效果不佳。本文旨在通過改進(jìn)算法的計(jì)算方式,融入更多實(shí)際因素,最終形成更準(zhǔn)確的推薦結(jié)果集。首先,對(duì)數(shù)據(jù)進(jìn)行預(yù)處理分類,降低冗余數(shù)據(jù)的計(jì)算和矩陣稀疏性。其次,考慮實(shí)際推薦中影響用戶相似度較大的因素,對(duì)用戶相似度計(jì)算做出改進(jìn)。然后,通過構(gòu)造混合推薦函數(shù),在spark分布式計(jì)算平臺(tái)上進(jìn)行離線和實(shí)時(shí)計(jì)算,減少了計(jì)算時(shí)間。通過最終的數(shù)據(jù)訓(xùn)練和結(jié)果集的對(duì)比,展示了改進(jìn)后的算法在效率和準(zhǔn)確率的提高程度。
關(guān)鍵詞: 協(xié)同過濾;聚類分析;用戶相似度;spark計(jì)算;MASE
【Abstract】: In the collaborative filtering recommendation algorithm, if the user-evaluation matrix is sparse and the number of items evaluated together is small, it is difficult to accurately calculate the user similarity. With the other practical factors, there will be very Big differences between recommendation result and the actual result. The purpose of this paper is to improve the calculation method of the algorithm and incorporate more practical factors to form a more accurate recommendation result set. First, the data is pre-processed to reduce the calculation of redundant data and matrix sparsity. Secondly, considering the factors that affect the user's similarity in the actual recommendation, the user similarity calculation is improved. Then, through the algorithm integration, the hybrid recommendation function is constructed, and the offline and real-time calculations are performed on the spark distributed computing platform, which reduces the time. Through the comparison of the final data training and the result set, the improvement of the efficiency and accuracy of the improved algorithm is demonstrated.
【Key words】: Collaborative filtering; Cluster analysis; User similarity; Spark calculation; MASE
0? 引言
隨著大數(shù)據(jù)時(shí)代的到來,網(wǎng)絡(luò)信息的快速膨脹讓人們從信息匱乏的時(shí)代不入流信息過載的時(shí)代。當(dāng)我們需要在海量信息中找到自己的個(gè)性化信息,我們可以借助于強(qiáng)大的搜索引擎。但是搜索引擎顯示內(nèi)容的前提是輸入關(guān)鍵字,而在現(xiàn)實(shí)中,很多時(shí)候沒有明確的需求,比如突然想聽最近的流行歌曲,當(dāng)前流行歌曲成百上千,用戶自己可能都不知道哪首歌符合自己的要求,沒有關(guān)鍵字輸入,搜索引擎也就變得無能為力。此時(shí),推薦系統(tǒng)應(yīng)運(yùn)而生[1]。
推薦系統(tǒng)通過分析用戶的歷史數(shù)據(jù),預(yù)測(cè)出的用戶感興趣的信息或者商品,幫助用戶從海量的數(shù)據(jù)中發(fā)掘自己的個(gè)性化需求。目前在電子商務(wù)、視頻音樂、網(wǎng)絡(luò)社交等各類網(wǎng)站和應(yīng)用中,推薦系統(tǒng)都扮演著不可替代的角色,所以對(duì)推薦系統(tǒng)的探索是非常有意義的。
1? 相關(guān)工作
推薦系統(tǒng)的核心是推薦算法,協(xié)同過濾推薦是推薦系統(tǒng)應(yīng)用最為成功的技術(shù)之一,所以本文將其作為研究的重點(diǎn)。協(xié)同過濾推薦算法包括UserCF算法和ItemCF算法。UserCF算法以用戶數(shù)據(jù)為中心,推薦結(jié)果集是與目標(biāo)用戶相似度較高的其他用戶評(píng)價(jià)較高的物品。ItemCF算法以物品數(shù)據(jù)為中心,推薦結(jié)果集是與目標(biāo)用戶歷史購買物品相似度最高的物品。在數(shù)據(jù)量豐富的情況下,各種推薦算法的大體都能取得較好的準(zhǔn)確率,但現(xiàn)實(shí)中,用戶的歷史數(shù)據(jù)和評(píng)價(jià)矩陣幾乎都是稀疏的,同時(shí),單臺(tái)服務(wù)器往往無法承受海量次數(shù)的數(shù)據(jù)計(jì)算,所以解決評(píng)分矩陣的稀疏性和算法的可擴(kuò)展性是協(xié)同過濾推薦需要解決的兩大問題[2]。
為了能盡可能使推薦結(jié)果的準(zhǔn)確度和計(jì)算速度達(dá)到最優(yōu)化,本文采用混合推薦算法。首先,先對(duì)數(shù)據(jù)進(jìn)行預(yù)處理,即聚類,通過降維,減少冗余計(jì)算降低運(yùn)行速度和增加服務(wù)器壓力。其次,采用混合推薦算法,動(dòng)態(tài)調(diào)節(jié)參數(shù),以期使算法的適用范圍更廣,同時(shí)盡可能小的影響結(jié)果集的準(zhǔn)確度。再者,算法的計(jì)算采用spark分布式計(jì)算,將海量數(shù)據(jù)的計(jì)算執(zhí)行部署在多臺(tái)服務(wù)器上,在增加算法可拓展性的基礎(chǔ)上,多條數(shù)據(jù)并行計(jì)算,計(jì)算效率明顯提高。最后,將通過混合算法計(jì)算出的推薦結(jié)果集持久化到數(shù)據(jù)庫,使用戶的推薦結(jié)果得到更快的反饋。
2? 算法詳細(xì)優(yōu)化流程
2.1? 算法優(yōu)化思路
在平臺(tái)方面,采用大數(shù)據(jù)平臺(tái),數(shù)據(jù)計(jì)算采用spark分布式計(jì)算,數(shù)據(jù)的存儲(chǔ)和計(jì)算分布式部署在多臺(tái)服務(wù)器上,無論是離線計(jì)算和實(shí)時(shí)計(jì)算,spark的流式處理數(shù)據(jù)的效率都是非常可觀的[4]。在詳細(xì)算法方面,對(duì)推薦算法的多個(gè)環(huán)節(jié)進(jìn)行優(yōu)化,以期得到準(zhǔn)確性和效率的最大化。首先,通過聚類分析先對(duì)用戶進(jìn)行模糊推薦。其次,考慮到物品的熱度和好評(píng)度,對(duì)余弦相似度和皮爾遜相似度進(jìn)行優(yōu)化,得到用戶間的相似度,然后再計(jì)算出預(yù)測(cè)評(píng)分結(jié)果集。最后,根據(jù)動(dòng)態(tài)參數(shù)進(jìn)行加權(quán),得到最終的推薦列表。
2.2? 推薦算法的執(zhí)行過程
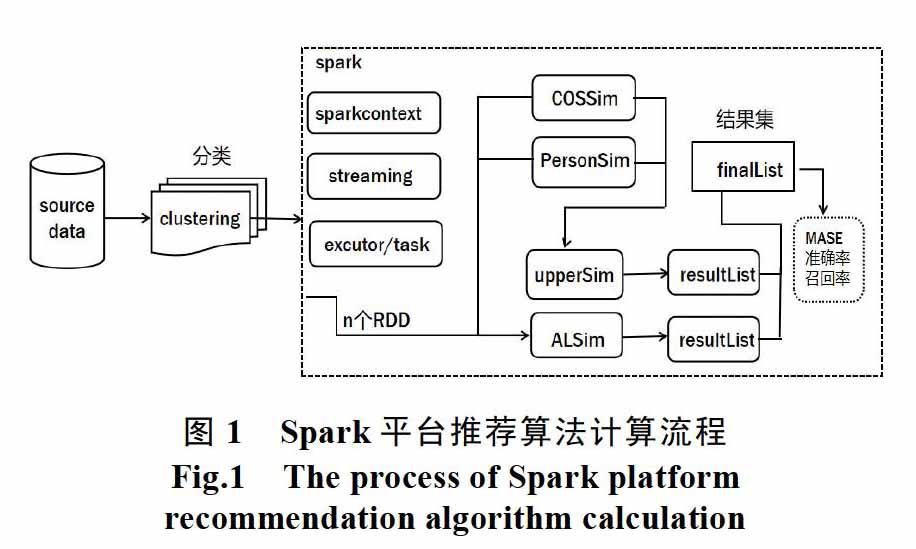
Flume從數(shù)據(jù)源收集數(shù)據(jù),經(jīng)過解析發(fā)送到kafka的topic中,spark程序啟動(dòng)后,加載驅(qū)動(dòng),從topic中讀取實(shí)時(shí)數(shù)據(jù),先進(jìn)行預(yù)分類,然后對(duì)用戶相似度、預(yù)測(cè)評(píng)分進(jìn)行計(jì)算,得到推薦列表。最后,通過調(diào)節(jié)自定義參數(shù),計(jì)算最終的預(yù)測(cè)推薦函數(shù),形成最終的推薦列表,持久化到數(shù)據(jù)庫中,推薦給用戶。總體流程如圖1所示。
2.3? 算法詳細(xì)優(yōu)化過程
2.3.1? 平臺(tái)優(yōu)化
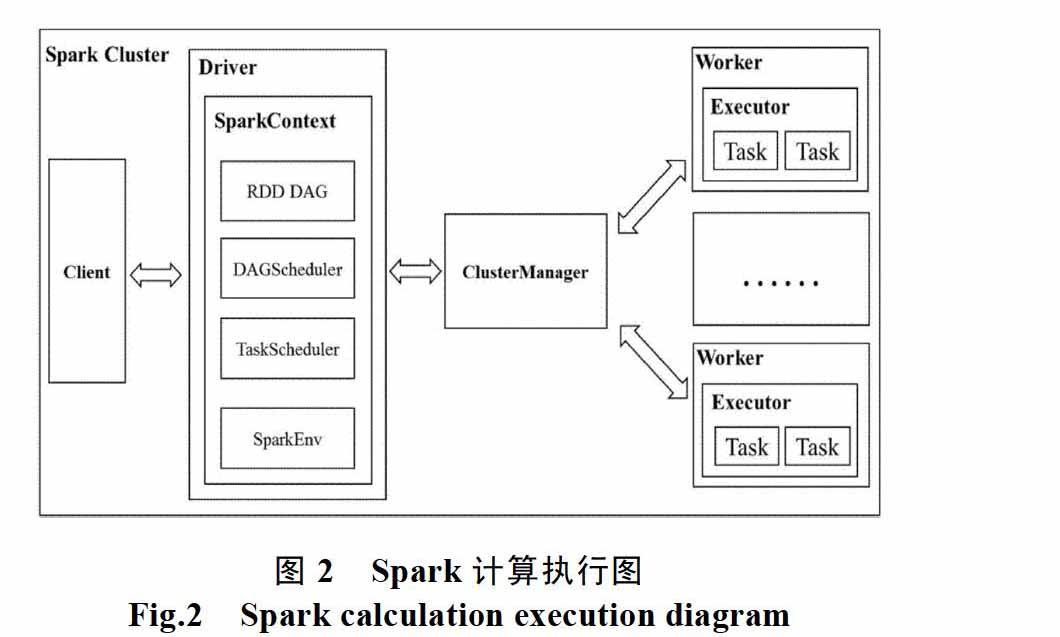
不同于傳統(tǒng)的推薦算法,大數(shù)據(jù)計(jì)算平臺(tái)采用分布式開源框架,可以將多臺(tái)PC機(jī)結(jié)合到一起,組成主從節(jié)點(diǎn)。主節(jié)點(diǎn)執(zhí)行管理功能,負(fù)責(zé)任務(wù)的分發(fā)和調(diào)度,從節(jié)點(diǎn)負(fù)責(zé)接收主節(jié)點(diǎn)的信息,進(jìn)行數(shù)據(jù)計(jì)算[6]。這種分布式結(jié)構(gòu)在可靠性和承受高并發(fā)性都有著突出的優(yōu)勢(shì)。
推薦系統(tǒng)通常需要處理龐大的數(shù)據(jù),每秒刷新千百條數(shù)據(jù)是很常見的。如果要考慮推薦結(jié)果的準(zhǔn)確性和計(jì)算時(shí)間,離線計(jì)算和實(shí)時(shí)計(jì)算都是有必要的。離線計(jì)算部分對(duì)于數(shù)據(jù)量、時(shí)間間隔要求等限制均較少,能夠得到較高的準(zhǔn)確率。在線計(jì)算在準(zhǔn)確度上不如離線,但能夠快速響應(yīng)用戶的請(qǐng)求[5]。所以通過實(shí)時(shí)計(jì)算和離線計(jì)算結(jié)合的形式能夠得到更準(zhǔn)確的結(jié)果。在大數(shù)據(jù)平臺(tái)下,離線計(jì)算部分以hadoop的組件HDFS作為本地源數(shù)據(jù)的存儲(chǔ)載體,通過spark sql和Mlib進(jìn)行模型構(gòu)建和函數(shù)計(jì)算,計(jì)算的結(jié)果存儲(chǔ)到HBase中或者再次存儲(chǔ)到HDFS中。在線計(jì)算部分通過flume進(jìn)行數(shù)據(jù)的收集,將收集到的數(shù)據(jù)解析后發(fā)送到kafka消息隊(duì)列中,然后啟動(dòng)spark進(jìn)行流式計(jì)算。
離線和實(shí)時(shí)計(jì)算結(jié)合流程圖3所示。
2.3.2? 數(shù)據(jù)分類預(yù)處理
由于用戶數(shù)據(jù)量非常龐大,在對(duì)用戶數(shù)據(jù)進(jìn)行計(jì)算時(shí)都需要對(duì)數(shù)據(jù)進(jìn)行預(yù)處理,不僅能夠減少冗余數(shù)據(jù)給計(jì)算機(jī)帶來的計(jì)算負(fù)擔(dān),還能夠通過初始篩選,提高計(jì)算結(jié)果的精度。在各類推薦算法中,一般都需要數(shù)據(jù)清洗,去燥等預(yù)處理,而聚類算法是此階段必不可少的環(huán)節(jié)之一。同時(shí),聚類分析的結(jié)果還可分析數(shù)據(jù)的稀疏性和關(guān)聯(lián)性[7]。本文中采用C-Means聚類對(duì)數(shù)據(jù)預(yù)處理,通過目標(biāo)函數(shù)來計(jì)算出樣本點(diǎn)和聚類中心的隸屬度從而對(duì)數(shù)據(jù)進(jìn)行自動(dòng)分類。該算法的流程是:
由圖7可看出在spark平臺(tái)下,海量數(shù)據(jù)的計(jì)算效率是非常可觀的。在實(shí)際的生產(chǎn)環(huán)境中,一般都是組合多臺(tái)高性能服務(wù)器構(gòu)成集群,進(jìn)行每日TB量級(jí)的數(shù)據(jù)計(jì)算,綜合實(shí)時(shí)計(jì)算和離線計(jì)算,為海量用戶提供更加準(zhǔn)確的推薦服務(wù)。
4? 結(jié)論
通過以上結(jié)果的的對(duì)比,改進(jìn)后的混合推薦算法,融入了更多的實(shí)際因素,能夠更準(zhǔn)確的計(jì)算用戶相似度,最終提高推薦的準(zhǔn)確度。同時(shí),基于spark平臺(tái)的分布計(jì)算,在執(zhí)行效率上有很大的提高。本文給出的基于用戶的混合過濾推薦算法以用戶為中心,通過用戶歷史數(shù)據(jù)挖掘用戶的興趣,并將計(jì)算結(jié)果持久化,能夠讓用戶在海量信息中更快速準(zhǔn)確地定位到自己的興趣商品。
參考文獻(xiàn)
林子雨. 大數(shù)據(jù)技術(shù)原理與應(yīng)用[M]. 人民郵電出版社. 2017, 242: 27-31.
史尤昭. 數(shù)據(jù)挖掘技術(shù)研究與應(yīng)用[J]. 軟件, 2015, 36(11): 38-42.
欒紅波, 文福安. 數(shù)據(jù)挖掘在大學(xué)英語成績預(yù)測(cè)中的應(yīng)用研究[J]. 軟件, 2016, 37(3): 67-69.
胡俊, 胡賢德, 程家興. 基于Spark 的大數(shù)據(jù)混合計(jì)算模型. 計(jì)算機(jī)系統(tǒng)應(yīng)用, 2015, 24(4).
譚云志. 基于用戶評(píng)分和評(píng)論信息的協(xié)同推薦框架[J]. 模式識(shí)別與人工能, 2016, 29(4): 359-366.
楊彬. 移動(dòng)云計(jì)算中分布式計(jì)算卸載框架的研究[J]. 軟件, 2015, 36(6): 129-133.
趙雪. 基于用戶興趣的個(gè)性化協(xié)同過濾推薦算法研究[D]. 2014, 17: 15-25.
王成. 基于用戶協(xié)同過濾推薦效率和個(gè)性化改進(jìn)[J]. 小型微型計(jì)算機(jī)系統(tǒng), 2016, 37(3): 428-432.
江周峰, 楊俊, 鄂海紅. 結(jié)合社會(huì)化標(biāo)簽的基于內(nèi)容的推薦算法[J]. 軟件, 2015, 36(1): 1-5.
Francesco ricci, etc. Recommender systemshandbook[M]. NewYork: Springer, 2011, 1(1): 39-184.
