基于神經網絡的詞義消歧
2019-10-08 09:03:43王子牛陳婭先高建瓴
軟件 2019年2期
王子牛 陳婭先 高建瓴


摘? 要: 在計算機語言學中,詞義消歧是自然語言處理的一個重要問題,詞義消歧即指根據上下文確定對象語義的過程,在詞義、句義、篇章中都會出現這種詞語在上下文的語義環境中有不同的含義的現象。本文提出一種基于神經網絡的模型實現詞義消歧,將詞向量輸入神經網絡,通過分類的方式實現消歧的目的。實驗表明,基于神經網絡的詞義消歧比傳統的統計方法消歧具有更高的準確度。
關鍵詞: 詞義消歧;自然語言處理;詞向量;神經網絡
中圖分類號: TP391.1? ? 文獻標識碼: A? ? DOI:10.3969/j.issn.1003-6970.2019.02.003
【Abstract】: In computer linguistics, word sense disambiguation is an important issue in natural language processing. Word sense disambiguation refers to the process of determining object semantics according to context. In words, sentences, and chapters, such words appear in context. There are different meanings in the semantic environment. This paper proposes a neural network-based model to achieve word sense disambiguation, input word vector into neural network, and achieve the purpose of disambiguation through classification. Experiments show that neural network disambiguation has higher accuracy than traditional statistical method disambiguation.
【Key words】: Word sense disambiguation; Natural language processing; Word vector; Neural network
0? 引言
詞義消歧(WSD)即根據多義詞所在的上下文環境所確定語義的過程,解決這個問題對于自然語言處理的相關研究和應用具有很重要的意義。機器翻譯、語音識別、文本分類和自動摘要等各種自然語言處理系統都涵蓋了消除歧義這項工作,為了使這些系統更高效,提高消歧的準確度就顯得尤為重要[1]。
多義詞消歧方法主要有三種:第一,基于規則方式來進行詞義消歧,使用該方法需要一個具有完備性、一致性和對開放領域適應的語料庫,該方法存在很多瓶頸問題[2]。第二,基于統計的消歧方法,利用統計學方法自動在訓練語料中獲取消歧所需的語言學知識,根據訓練數據的差異選擇又分為有監督機器學習、無監督機器學習和半監督機器[3]學習三種方法,無監督的消歧方法就是運用聚類算法對相似的語義環境或樣本示例進行聚類,最典型的就是Lesk算法[4];有監督的消歧方法就是運用標注好的語料庫,提取與歧義詞有關的語義關系作為特征進行消歧,這種方法具有較好的消歧效果,但是難點在于需要大量人工標注的語料庫[5];結合有監督和無監督兩種方法的優點推敲出的半監督消歧方法就是根據少量有標注的訓練語料,結合未標注語料資源構建消歧分類器[6];第三,基于知識庫的消歧方法,該方法計算詞匯在詞典中的不同義項和語言環境中的語義的共現率,選擇出共現率最高的分類作為歧義詞在當前語義環境下的語義,但由于現有詞典的覆蓋范圍相對狹窄,不具備擴充能力,因而該方法逐漸受到冷落。
2005年謝芳[7]等人利用BP神經網絡模型和統計待消歧詞的上下文信息來進行詞義消歧。2014年張婷婷[8]提出基于WordNet現存的詞義結構以及詞義對用的上下文語義關系,詞義消歧之后通過語義選擇完成消歧工作。2016年張國清[9]進行了有導的利用神經網絡進行的詞義消歧方法,還介紹了無導的利用Hownet義原同現頻率信息進行的消歧方法。2016年張春祥[10]等人將語義信息引入詞義消歧模型之中。在漢語句子中,以歧義詞匯為中心定位其左右詞匯單元,以左右詞匯單元的語義類別為基礎,使用貝葉斯模型來判斷歧義詞匯的真實語義。隨著神經網絡的興起,神經網絡在自然語言處理也被廣泛應用[11-13]。Bengio[14]等借助語言模型的思想,使用句子中的詞作為神經網絡的輸入和神經網絡的輸出,利用語言模型的思想和神經網絡反向傳播算法,對詞向量進行學習,大大縮短了訓練時間[15]。結合矩陣分解和上下文窗口,能利用更多的統計信息,在越大的語料上越具有優勢,深度學習獲得的詞向量中包含大量的語義信息[16],這些語義信息能否用于以及如何用于詞義消歧領域成為了最新的問題。基于此,本文提出了一種基于神經網絡的有導詞義消歧方法, 利用神經網絡的泛化功能來解決傳統有導消歧中的問題,達到比較好的詞義消歧效果。為了驗證模型的有效性,本文采用人民日報數據集對模型進行實驗。實驗結果表明,該模型取得了較好的效果。
本文的主要工作如下:(1)提出利用神經網絡應用于中文詞義消歧,該方法可提高消歧的準確度;(2)利用詞向量的特點,結合神經網絡,將消歧過程轉變為簡單的分類過程;(3)充分利用《同義詞詞林》的詞典結構,進行編碼處理做為神經網絡的分類輸出。
本文組織結構:第一節介紹了詞義消歧的定義及其相關研究進度和成果;第二節介紹了神經網絡的模型;第三節介紹了詞義消歧的模型及消歧過程;第四節通過調整窗口參數做不同實驗獲取最佳參數,達到最佳消歧效果;最后一節是本文結論。
1? 神經網絡模型
從最簡單的神經網絡講起,這個神經網絡僅由一個“神經元”構成,該神經元有兩個部分,一部份為狀態值,另一個部分為激活值。一個神經元有一個或多個輸入,每一個輸入對應一個權值w,神經元內部將輸入的值與對應權值相乘相加后,再將結果與偏置值相加,最終將結果放入激活函數中,由激活函數給出最后的輸出,“神經元”如下圖1所示。
2? 基于神經網絡的詞義消歧算法
2.1? 方法描述
本文提出的基于神經網絡的詞義消歧方法主要思想是,將多義詞所在的語義環境通過截取一定的長度轉變為詞向量輸入神經網絡,通過神經網絡反復迭代計算,調整權值和偏置值將該多義詞進行準確分類,找出最合適的義項進行輸出。詞義消歧步驟如下:①數據預處理;②多義詞所在的上下文環境及其義項的向量表示;③搭建神經網絡并訓練網絡;④進行測試得出結論。
2.2? 文檔預處理
首先對需要進行消歧的文檔進行分詞,并將待消歧的詞語做標記,標記為《同義詞詞林》中的小類代碼,然后查找待消歧文本中的多義詞,并將多義詞整理統計分為一個義項、兩個義項及多個義項的詞典。由于本文使用的多義詞標記是《同義詞詞林》中的小類代碼,需要將這些小類代碼用One-Hot編碼方式表示為具體向量,最后將詞典的每個義項轉換為小類代碼的具體向量形式。
2.3? 神經網絡的輸入
由于多義詞的含義取決于多義詞所在的上下文環境,所以上下文顯得尤為重要,上下文的確定是在歧義詞前后一定大小的窗口內進行截取,窗口過大會引入更多噪聲,過小又會丟失信息會降低消歧的準確度,通過閱讀文獻的累計,本文取窗口大小為5,將包含該歧義詞在內的9個詞作為輸入。
將語料進行預處理后,需要把分詞和截取以后的句子表示為計算機能夠計算的形式,常用的表示模型分別是詞袋模型和詞向量。詞袋模型直接將每一個詞語或者符號統一放置在一個集合,然后按照計數的方式對出現的次數進行統計,TF-IDF是詞袋模型的一個經典用法;而詞向量是將字、詞語轉換為向量矩陣的計算模型,常用的有One-Hot(獨熱)編碼方式。自Google團隊的Word2vec的提出以及普及,Word2vec方式能很好地克服獨熱編碼方式的兩個缺點。該方法將一個詞映射到一個實數向量空間中,這種方法使得詞義之間的相似性可以用空間距離表示,兩個詞向量的空間距離越近,表示兩個詞的相似性越高。2013年開放了Word2vec可以訓練詞向量的工具。Word2vec以大量文本訓練語料作為輸入,通過訓練模型快速有效地將一個詞語表達成向量形式。
本文將該歧義詞所在的語句通過截取后利用Word2Vec進行詞向量訓練,獲得9*60維的詞向量作為神經網絡的輸入。基于神經網絡的詞義消歧模型主要有四層組成。基于神經網絡的詞義消歧模型如圖2所示。
(1)將文本分詞后,用詞向量作為神經網絡的輸入;
(2)利用神經網絡對詞向量的特征進行提取;
(3)最后利用softmax分類器進行多義詞分類,輸出小類代碼所指向的向量形式。
2.4? 神經網絡的輸出
經過神經網絡計算后,得到待消歧詞Wi 對應的輸出向量,而輸出向量是由同義詞詞林的小類編碼通過One-hot編碼得到的向量。例如,“我國人民特別愛花,所以牡丹自古有上市的傳統。”中“花”字是多義詞,它具有“花兒”和“積攢”這兩個義項,
3? 實驗
3.1? 數據集
為驗證本文模型的有效性,采取了在人民日報作為數據集,且此數據集是不平衡數據集。本次實驗從中挑選了常用的12個歧義詞,分別為“提高”,“系統”,“用”,“發表”,“隊伍”,“根本”,“左右”,“行動”,“花”,“保證”,“水”,“多少”。該預料包括800條句子。數據集分為兩部分,將百分之三十作為測試集,百分之七十作為訓練集:(1)訓練數據集;(2)測試集數據集。
使用神經網絡進行詞義消歧分為兩個階段:
(1)訓練學習階段:向神經網絡輸入數據,提供一組輸入與輸出對應的數據,神經網絡通過反復迭代計算,不斷的調整權值和偏置值,直到滿足給定的期望輸出值,結束參數值的調整,或者已經達到循環的次數而結束迭代計算,可能沒有調整到合適的參數。代價函數如式(4)所示:
3.2? 實驗參數設置
本文的實驗硬件環境的主要參數CPU:Intel(R) Xeon(R) X5690 @3.47 GHz,CPU內存(RAM)為32 GB,GPU:NVIDIA 2080Ti 11G操作系統為openSUSE 15.0。本文實驗軟件環境如表1所示。
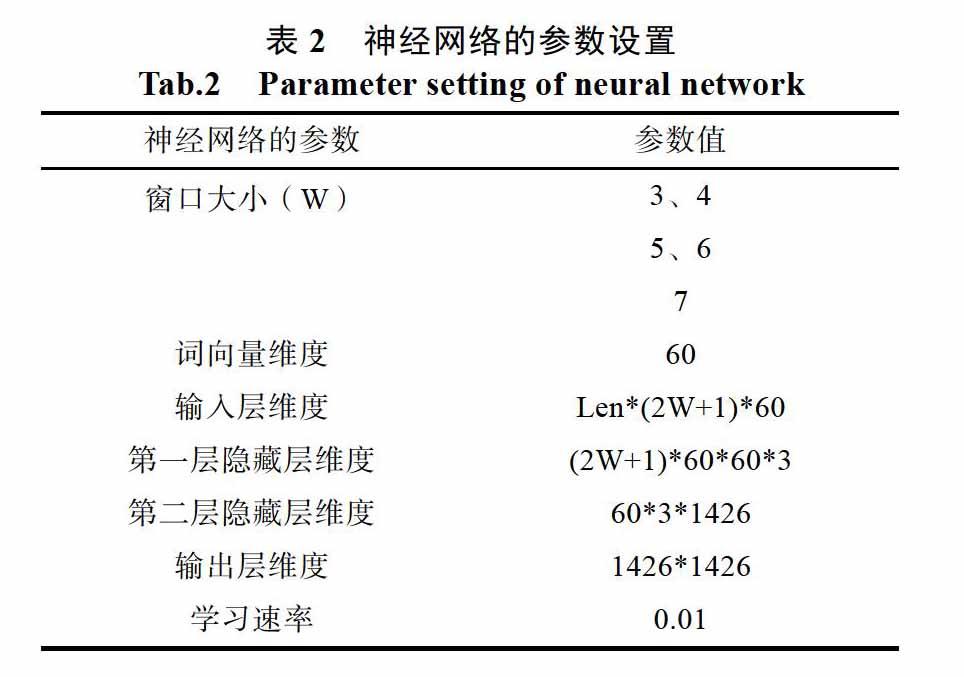
對于神經網絡來說參數的設置十分重要,它會影響神經網絡的性能。本文中主要參數設置為:神經網絡由四層構成,神經網絡輸入層的維度為所需消歧的句子數目Len乘以以窗口大小為W的維度乘以詞向量維度,輸出層為小類編碼的類別數,中間的隱藏層可以調整,權值和偏置值初始化值為0.1,則神經網絡輸出的維度為Len*1426,隱藏層的激活函數使用relue函數,輸出層的激活函數使用Softmax函數進行實驗,其他參數設置如表2所示。
3.3? 實驗結果
本文設置了五組實驗進行中文消歧,第一、二組實驗設置窗口大小為3、4,將分詞后長度為5、7的詞向量作為神經網絡的輸入,第三、四組實驗設置窗口大小為5、6,將分詞后長度為9、11的詞向量作為輸入,第五組實驗設置窗口大小為7,將長度為13的詞向量作為輸入,而每一組又分別用12個不同的歧義詞訓練模型,由于數據集的數量有限,本實驗采取交叉驗證的方式進行實驗,根據五組不同的窗口參數設置,對系統的正確率影響如圖4所示。從圖3.1可以看出,當窗口大小為3、4、7時,系統的正確率普遍偏低,當窗口大小為6時,系統的正確率最大為94.20%,最小為72.86%,系統穩定性較差,但是當窗口大小為5時,系統的穩定性好,正確率較高,因此本文選取窗口大小為5進行實驗。
當窗口大小為5時,使用挑選的12個歧義詞進行實驗,實驗結果如表3所示。
表4中給出了BP神經網絡模型、動態規則方法、義原同現頻率方法、半監督[10]方法和本文的模型在測試集上得到的結果,具體評價指標包括正確率的最大值、最小值和平均值。
通過表3和表4可以看出預測的結果平均正確率為86.55%與之前的研究者做的消歧正確率高,文獻[7]中利用BP神經網絡模型和統計待消歧詞的上下文信息來進行詞義消歧正確率平均正確率為84.54%,最高達到88.9%,但最低只有72.72%說明系統不穩定;在文獻[8]中使用動態規則法最高正確率達到83.9%;在文獻[9]中使用的神經網絡詞義消歧正確率達到82.5%,本文正確率達到86.55%;利用義原同現頻率進行多義詞消歧正確率只有75%;在文獻[10]中使用13個不同的歧義詞測試最高正確率達到85.0%,最低達到27.8%。通過此次實驗證明本文模型比文獻[7]的模型提高正確率2.01個百分點,比文獻[8]高16.05個百分點,比文獻[10]高1.55個百分點,說明本文使用神經網絡進行消歧正確率還是比其他的消歧方式高,因此利用神經網絡在詞義消歧方面具有很好的前景。
4? 結論
本文提出了一種基于神經網絡的詞義消歧模型,利用word2vec模型訓練的詞向量作為輸入,結合神經網絡模型對多義詞進行詞義消歧。實驗表明,該方法比基于知識的詞義消歧算法有更高的正確率。同時,利用詞向量能夠更好的保存文本序列的上下文信息。由于實驗數據的規模有限,若要提高消歧的效果,還需要大規模實驗數據,還可以對神經網絡進行調整,這些問題將在下一步研究中解決。
參考文獻
MincaA, Diaconescu S. An approach to knowledgebased word sense disambiguation using semantic trees built on a WordNet lexicon network[C]// The 6 th Conference on Speech Technology and Human_Computer Dialogue, 2011: 1-6.
Suvitha D S, Janarthanan R.Enriched semantic information Processing using WordNet based on semantic relation network[C]// Internation Conference on Computing, Electronics and Electrical Technologies, 2012: 846-851.
孫鵬, 馮翔. 一種基于集成學習的健壯性半監督SVM[J]. 軟件, 2018, 39(11): 182-186.
王永生. 基于改進的Lesk算法的詞義排歧算法[J]. 微型機與應用, 2013(24): 69-71.
蔣振超, 李麗雙, 黃德根. 基于詞語關系的詞向量模型[J]. 中文信息學報, 2017, 31(3): 25-31.
LE A C, SHIMAZU A, HUYNH V N. Semi-supervised Learning Integrated with Classifier Combination for Word Sense Disambiguation[J]. Computer Speech & Language, 2008, 22(4): 330-345.
謝芳, 胡泉. 基于BP神經網絡的詞義消歧模型[J]. 計算機工程與應用, 2006, 12: 187-189.
張婷婷. 基于語義規則的詞義消歧方法的研究[J]. 數碼世界, 2018: 131-132.
張國清. 兩種詞義消歧方法分析與比較[J]. 信息與電腦, 2017(19): 47-52.
張春祥, 徐志峰, 高雪瑤, 等. 一種半監督的漢語詞義消歧方法[J]. 西南交通大學學報.
張曉明, 尹鴻峰. 基于卷積神經網絡和語義信息的場景分類[J]. 軟件, 2018, 39(01): 29-34.
張玉環, 錢江. 基于兩種LSTM結構的文本情感分析[J]. 軟件, 2018, 39(1): 116-120.
劉騰飛, 于雙飛, 張洪濤, 等. 基于循環和卷積神經網絡的文本分類研究[J]. 軟件, 2018, 39(01): 64-69.
BengioY, DucharmeR, VicebtP, et al. A Neural Probabilistic Language Model[J]. The Journal of Machine Learning Research. 2003, 3: 1137-1155.
王紅斌, 郜洪奎. 基于word2vec和依存分析的事件識別研究[J]. 軟件, 2017, 38(6): 62-65.
Mikolov Tomas, Yih Wen-tau, Zweig Geoffrey. Linguistic regularities in continuous space word representations[C]. The Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), 2013: 746-75.
