新型災變自適應遺傳算法及其應用①
2019-09-24 06:22:38董兆偉孫立輝姜軍強史振杰武曉婧
計算機系統應用 2019年9期
王 策,董兆偉,孫立輝,姜軍強,史振杰,武曉婧
(河北經貿大學 信息技術學院,石家莊 453000)
當前解決工業生產當中最優化問題較為熱門的算法就是以遺傳算法為代表的智能優化算法.遺傳算法以“優勝劣汰”的自然選擇和基因階段的遺傳變異原理作為基礎,是一種具有很強的隨機搜索能力的智能算法[1].在解決多種復雜約束條件的尋優問題時,可以取得很好的搜索效果.但是在工業生產當中,對算法的運行時間要求較為苛刻,算法當中的種群數目較少,在隨機生成種群時個體很難遍布所有極值范圍附近.在前期的全局搜索過程中,該算法很容易陷入局部最優,從而無法對其他優秀解集區域進行搜索,并且隨著遺傳操作的不斷進行,種群中的個體多樣性將會不斷降低.因此解決遺傳算法的“早熟”現象成為算法改進的主要方向.
為了解決“早熟”問題,在遺傳算法當中添加了災變操作,利用了災變作用提高種群在遺傳操作過程中全局搜索性能[2].利用自適應遺傳算法中交叉概率和變異概率隨進化代數自適應調整的原理,將交叉操作和變異操作隨災變周期進行自適應調整[3],在災變完成之后,提高個體的變異能力,增強了算法的局部尋優能力.將該算法應用于燒結配礦系統的建立,利用生產數據進行檢驗,證明了該算法可以搜尋到極為穩定且成本最優的配礦方案.
1 算法改進措施
通過大量的實驗分析可得,在解決具有多變量的最優化問題時,遺傳算法很容易因為遺傳算法的特性造成“早熟”現象.為了降低種群“早熟”現象的發生,該模型在傳統遺傳操作過程當中添加了災變操作.災變主要是模擬生物進化過程中導致大量物種滅絕而個別物種生存的現象[4].在本算法中災變操作周期性地強行對大部分個體進行初始化,保留一定量的舊種群個體指導種群的搜索趨勢,并且在遺傳操作中配合災變操作的周期性變化進行自適應調整,增強算法在后期種群個體相似度較高的時候搜索能力.
(1) 災變操作
初始遺傳種群的獲得是通過未知量范圍內的隨機產生獲得的,假設一個種群遺傳操作的代數為M時會使種群個體穩定,當遺傳操作到m(m<M)代之后,大多數個體與最優個體相似度較高,只有適應度較高的個體與最優個體相似度較低,此時將當前種群狀態和最優個體及其適應度進行保存,將種群中大多數適應度優秀的個體進行刪除,隨機產生新的個體進行補充,只保留數量較少的原種群中適應度最差的個體保留之前的優秀種群特征組成新種群,進行新一輪的搜索,以此增大種群的多樣性和搜索范圍,而災變之后保留的舊種群個體由于本身處于較為優秀的尋優范圍內會對新種群個體的搜索提供收斂趨勢的引導.本次尋優算法主要進行多次災變操作,并且當前一代災變操作未能產生更為優秀個體時增大隨機個體對進行災變操作的種群個體的取代數量.將種群重復m代的遺傳操作,當災變操作完成時,種群替換為n次災變效果中取得最優秀個體的種群,繼續完成剩下的遺傳操作,災變操作具體步驟如下所示.
① 對第i代種群進行判斷,如果為第一代種群,即初始種群,將該種群作為災變保留種群進行保存,將該種群中的適應度最優個體作為災變最佳個體進行保存,然后進行遺傳操作.判斷代數i是否處于災變截止代數N×m內,如果是則進入步驟②,如果進化代數i不處于災變截止代數內則繼續進行遺傳操作.
② 判斷種群進化代數i是否為設定的災變操作代數,如果是則進入步驟③,否則繼續進行遺傳操作.
③ 當判斷為災變操作代數時,將當前進化過m代之后的種群中的全局最佳適應度與災變最佳個體的適應度進行比較,如果全局最佳適應度更加優秀,則將該全局最佳個體作為新的災變最佳個體進行保存,該進化種群作為新的災變最佳種群進行保存,然后將進化種群中根據適應度排序后的前pop個個體進行初始化處理,然后將處理過的種群進行一定代數的遺傳操作.
(2) 災變周期自適應遺傳操作
為了與災變的周期性重復進行良好的配合,該算法對交叉操作和變異操作進行改進,令其隨災變過程周期性自適應變化,增強算法從災變開始到所有災變操作完成過程當中對搜索范圍的尋優能力.在所有災變操作完成之后,種群個體已分布于各個極值的附近,為了尋找到這些范圍中的最優極值,需要對這些優秀個體所處的局部范圍進一步搜索.本算法在災變期間的尋優過程中跟隨代數逐漸增大交叉、變異概率,增大優秀個體間基因交流的可能性,在災變操作完成之后,通過非線性函數的特點快速增大交叉、變異概率,同時利用變異操作中變異范圍的自適應縮小,對每個個體的附近范圍進行探索,增強局部搜索能力.
① 災變周期自適應交叉操作
通過對交叉概率進行自適應變化提高種群變異的全局搜索能力,具體調整情況如下所示:

Pc是交叉概率,上式當中Num為當前已發生的災變次數.種群每次進行m代遺傳操作之后就進行一次災變操作,交叉概率K1為小于1 的定值.當i≥w時,交叉概率進行自適應變化.K2為一整數,調節交叉概率的變化范圍.
② 災變周期自適應變異操作
變異操作是提高種群多樣性的重要手段,為了使種群在遺傳操作后期,收斂程度較高的時候增強種群的搜索能力,提高種群基因多樣性,在改進算法當中對變異概率進行了關于迭代代數的自適應調整[5],使變異概率在完成災變操作以后逐漸增大,具體調整情況如下:

式中,Pm是變異概率,w為m的N倍,為停止所有災變操作的截止代數,N為總災變次數.當i<w時,種群每次進行m代遺傳操作之后就進行一次災變操作,此時變異概率為小于1 的定值K3.當i≥w時,變異概率進行自適應變化,并且不再進行災變操作.當執行了w代遺傳操作之后,將替換后的種群繼續執行V-w代遺傳操作,對變異概率進行自適應調整,V為實際的總的迭代代數,K4為一整數,調節變異概率的變化范圍.
變異操作方法是隨機選擇個體中的基因位置,對被選中的基因xj進行如下自適應操作,變異結果為x′j:

式中,r′,r為0~1 之間的隨機產生數,Num為發生變異操作時已經發生過的災變操作的次數,m為災變周期,M為遺傳操作中種群的穩定周期,xj,min和xj,max代表一個配礦方案中第j個變量的配比范圍下限和上限.
2 算法仿真應用
為了檢測改進算法的有效性,本文利用鋼廠的燒結配礦數據進行分析,將尋找最低成本配礦方案為目的解析為最優化問題建立尋優模型.所以此次尋優問題的目標就是在指定的約束條件下,利用工人經驗約束配比范圍,尋找成本最低的配礦方案.該問題作為工業生產問題,具有多變量、多約束條件、解集區域分布復雜等特點,十分符合對改進算法的性能進行檢測.
(1) 模型建立
當配料所使用的原料有n種時,目標函數主要目的是計算每噸混合原料的成本cost元.計算方式可以如下表示.
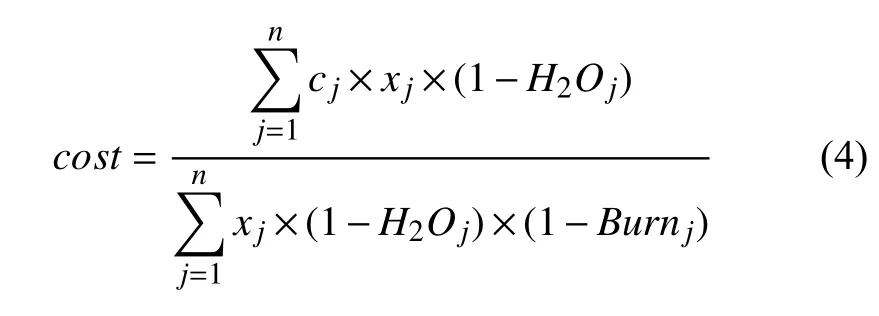
式中,cj表示的是第j種原料的噸單價(元);xj表示第j種原料的配比,%,成本cost,元.H2Oj為第j 種燒結原料的水含量的百分比,%,Burnj為第j種燒結原料的燒損比,%.
配料的過程當中,配料工作人員主要通過各種原料的庫存量,價格等因素配合自己在實際生產過程中積累到的經驗對每種原料的配比進行范圍約束,同時保證所有的原料配比之和為1.該約束條件的表達式如下所示:
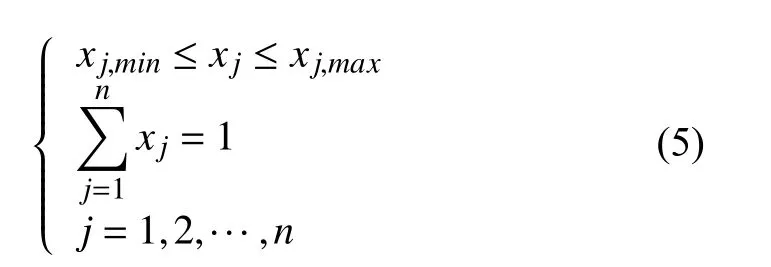
式中,xj,min,xj,max表示第j種原料配比范圍的上下限,%.每種原料的配比xj范圍主要通過初始化模型時對所有原料進行約束,在執行遺傳操作時始終保持種群中所有個體包含的配比處于各自的約束范圍內.為了降低算法的計算量,配比和為1 的約束條件將會以懲罰項的形式添加到最終的適應度函數當中,該懲罰項的建立形式如下所示.
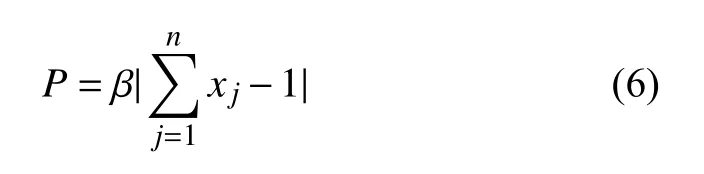
式中,以 β作為懲罰因子,是一個正整數,P為懲罰函數.
燒結礦當中各種化學成分和堿度是衡量燒結礦好壞的重要質量指標,如果超出該范圍會對鋼鐵質量和燒結設備造成嚴重影響.第q種化學成分和堿度的約束條件如下所示:
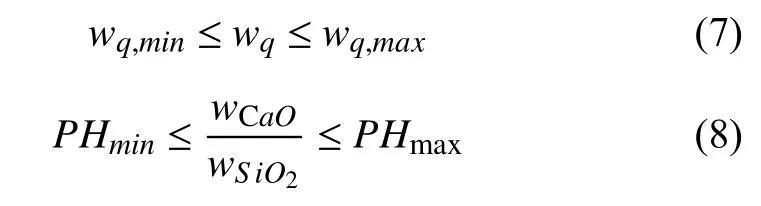
式中,wq為計算出的燒結礦中第q種元素的含量(%).同時PHmin,PHmax是堿度的上下限(%),堿度定義為燒結礦中氧化鈣和二氧化硅的含量之比.化學成分和堿度的約束條件也將以懲罰項的形式添加到最終的適應度函數當中,懲罰項建立方法如下:
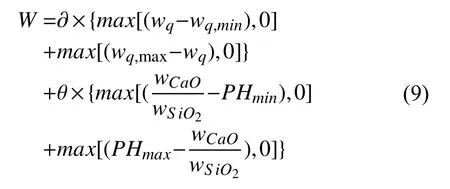
式中,的兩個懲罰因子?、θ為正整數,W為懲罰項.
最佳個體將會成為通過搜索遺傳過程中所有個體當中適應度最小的個體.適應度函數的建立如下所示,當一個配礦方案的各項約束超出范圍情況越嚴重時懲罰程度就會越大,適應度就越大.

(2) 編碼方案
基于燒結原料的種類十分豐富,每次生產前所需配料的種類有十幾種,所以為了降低計算量,節省計算時間,算法中采用實數編碼方式,以多個實數組成種群中的個體.
(3) 選擇方法
隨機產生的初始種群的個體適應度差別不大,難以通過輪盤選擇等方法對個體進行選擇.該遺傳算法通過此特點對選擇方法進行改進,使其更好的選取優秀個體,引導收斂方向,具體選擇方法如下:
先將所有個體按照適應度由小到大的順序進行排序,對前25%個體數量翻倍,組成新種群前50%的個體,前25%到50%的個體直接放入新種群中.計算種群中所有個體與當前全局最佳個體的相似度,對個體基于相似度由大到小排序,選擇與當前最優個體相似度高的個體對種群進行補全,相似度計算采用歐氏距離計算方法[6],計算公式如下所示:
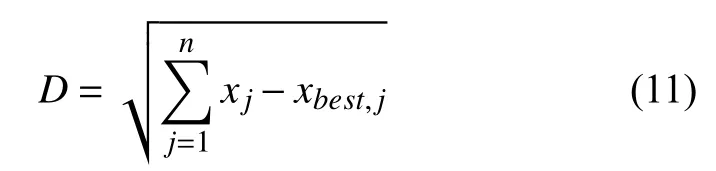
式中,D表示相似度,n表示個體中所有的基因個數,xbest,j是當前搜索到的最佳方案中第j種原料的配比(%).
(4) 交叉操作
需要配比的原料有十幾種,所以該問題是一種多維求解的問題,而且通過大量實驗發現優秀解集都處于一個相對較小的范圍當中.種群中每個個體含有多種變量,和采用二進制編碼的種群個體具有一定的相似性.該算法通過對不同個體進行隨機選擇多個位置,交換相同位置上的基因實現交叉操作[7].這種方法可以利用現有的種群基因增強種群的多樣性,同時又不會使種群中的個體逃離當前的最優解集范圍,在該問題的研究當中取得了很好的效果,具體的交叉方式如下圖所示,兩個被隨機選擇出的個體S和個體K,在給兩個個體中隨機選擇出若干個基因位置,將兩個個體相同基因位置上的基因進行交換.結果見圖1.

圖1 個體交叉結果
改進的遺傳算法的主要執行步驟如圖2所示.
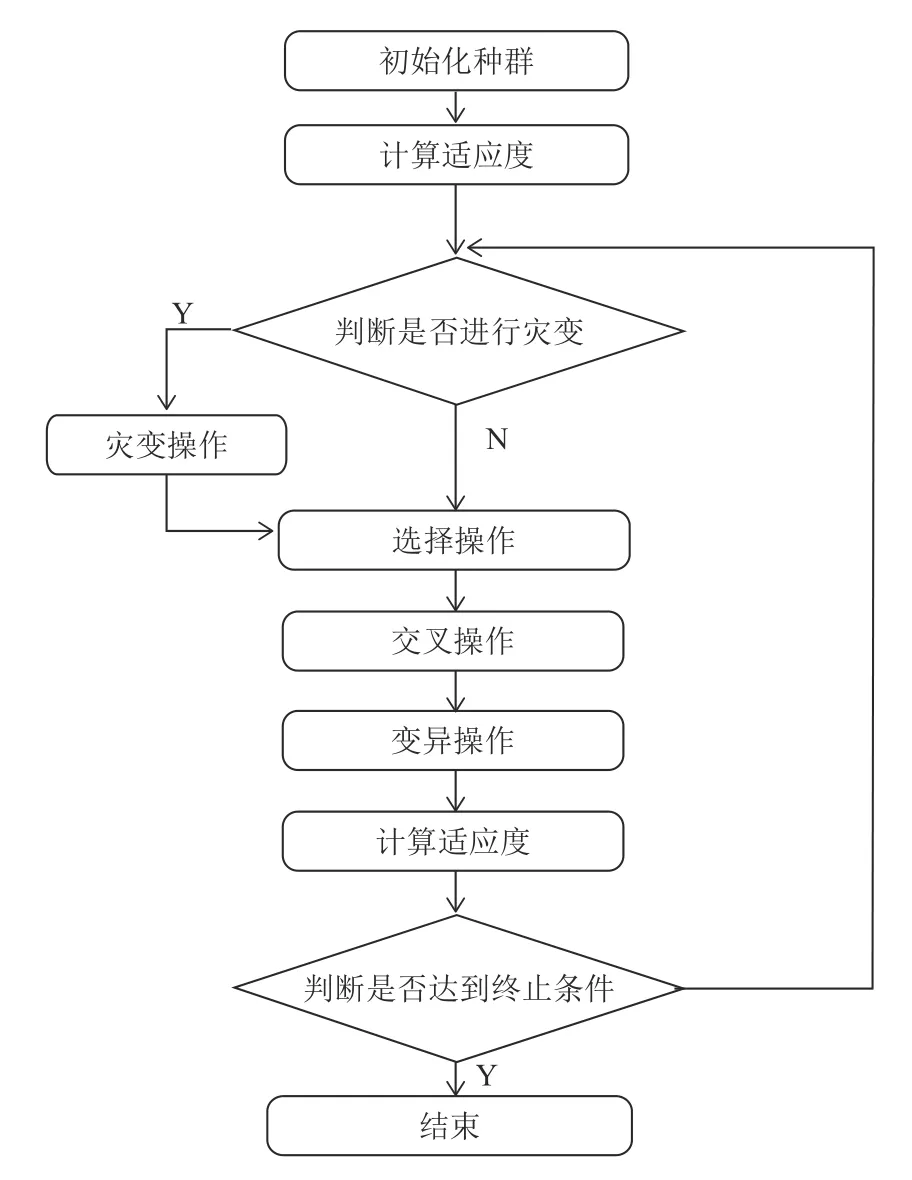
圖2 改進遺傳算法步驟
3 仿真結果對比
在解決這種非線性尋優問題時,遺傳算法、蟻群算法、差分算法、粒子群算法是最為常用的幾種智能進化算法.為了驗證改進的遺傳算法的尋優效果,本文以河北某鋼廠的實際生產數據作為試驗數據進行測試,設置算法種群個體數為200,迭代代數為250,每進行50 代遺傳操作之后進行一次災變操作,直到完成250 代的所有遺傳操作為止,交叉概率設為0.5,變異概率設為0.4.表1為鋼廠工程師總結出的燒結礦成分范圍作為約束條件,分別使用災變自適應遺傳算法和自適應遺傳算法[8,9]、蟻群算法、差分算法、粒子群算法進行尋優測試,進行仿真對比[10].

表1 質量指標
以某一日期數據進行試驗為例,多種算法的實際尋優效果如圖3-圖7所示,縱軸代表成本(元),橫軸代表迭代代數.
通過圖3與圖4至圖6相比較,自適應遺傳算法在最優方案的搜索效果上要優于蟻群算法、差分算法和粒子群算法,但是在執行了130 代遺傳操作之后,尋優結果基本穩定在544.75(元)附近,此時種群趨于“成熟”無法搜索到更加優秀的個體.而與圖7的災變遺傳算法相比較,可以明顯的看到,在前200 代遺傳操作中因為添加了災變操作,根據災變周期自適應調整的遺傳算略可以增強遺傳算法的全局搜索效果,實際搜索范圍覆蓋的更加完整,比自適應遺傳算法更高效地搜索優秀個體區域,獲得更優個體,充分說明了全局搜索效果更佳,搜索結果更優秀.完成所有的災變操作之后,在200 代到250 代遺傳操作過程中,配合交叉和變異操作的自適應調整,搜索范圍快速收斂,在種群個體相似度較高的情況下隨代數增多個體間的基因交流,逐步降低變異范圍,增大了個體在局部范圍的搜索能力,進一步優化搜索結果,如圖7所示取得了更加優秀的效果.

圖3 自適應遺傳算法
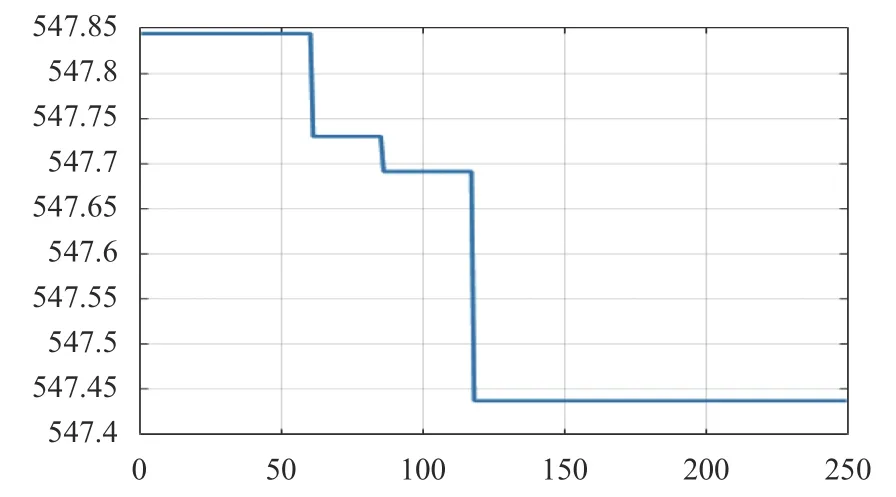
圖4 蟻群算法

圖5 差分算法

圖6 粒子群算法
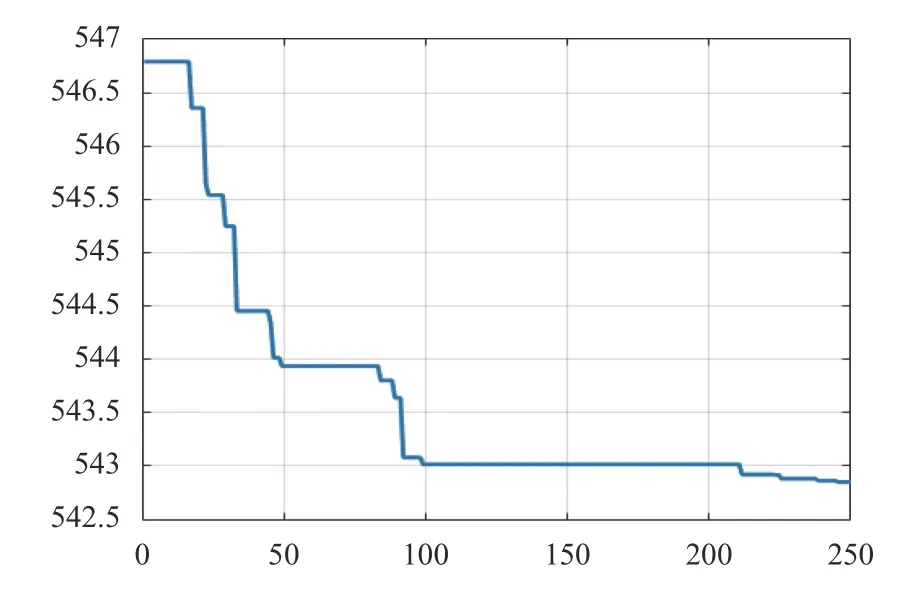
圖7 災變自適應遺傳算法
同時將各個算法的尋優結果當中燒結礦的化學成份進行對比,結果如表2所示,可以看到,災變自適應遺傳算法遺傳算法可以在保證燒結礦質量指標的前提下,有效地降低原料成本.
如表3所示的最優配礦方案與鋼廠企業的生產方案計算數據相比較,可以看到基于災變的自適應遺傳算法可以在有效的經驗配比范圍內得到成本優于企業人工配比的方案.
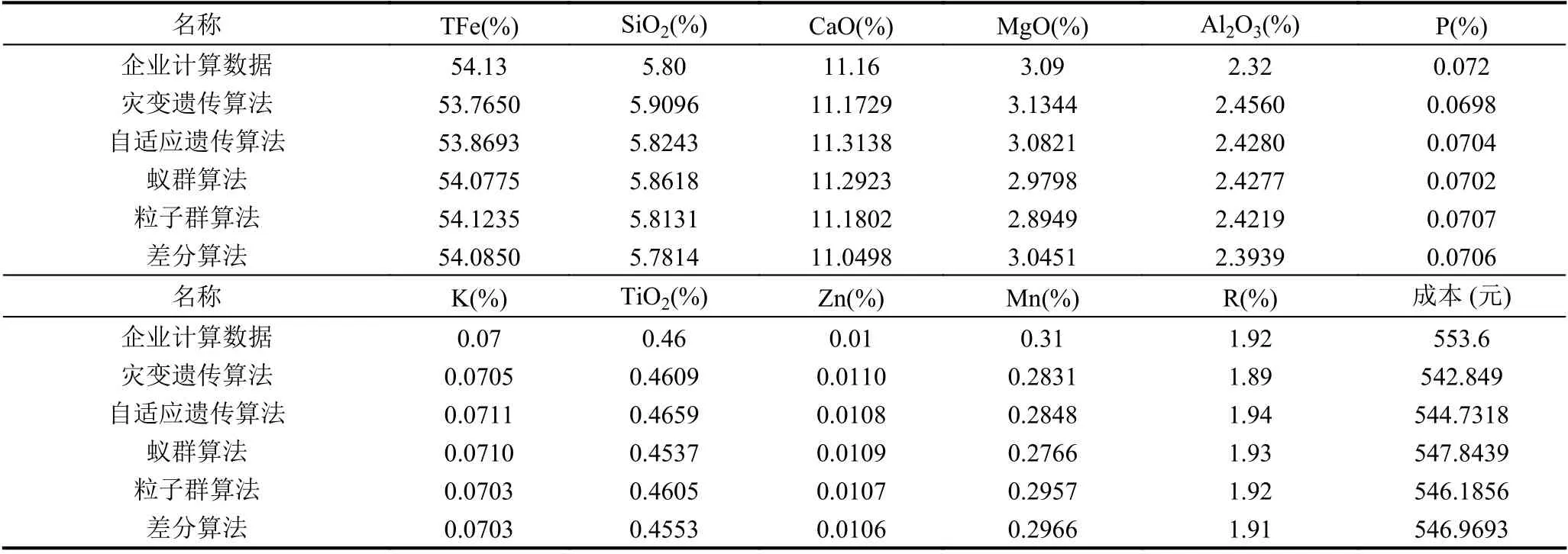
表2 燒結礦成份對比
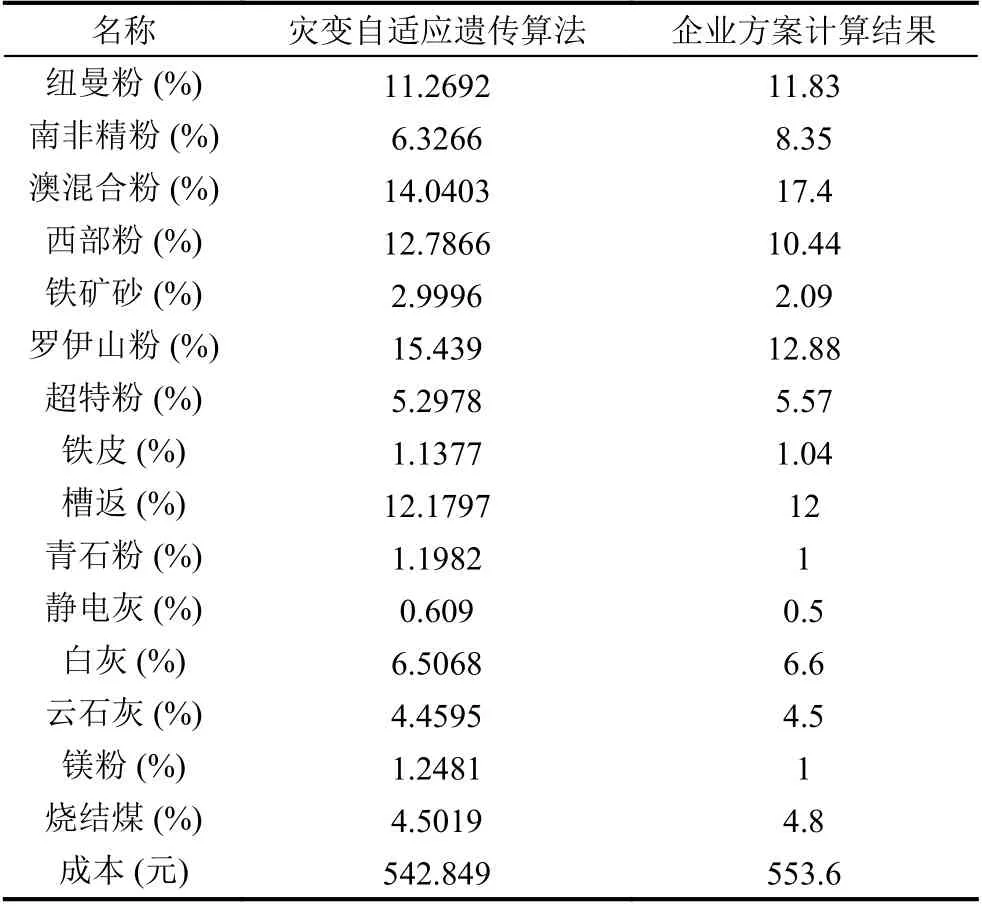
表3 原料配比對照
4 結束語
該改進遺傳算法通過特殊的選擇方法和交叉方法將搜索范圍不斷向優秀搜索區域靠攏,同時通過變異概率的后期自適應變化,增強了局部搜索能力,為優秀解的選擇奠定了基礎,而災變操作的加入,增強了算法的全局搜索能力,解決了傳統遺傳算法的“早熟”問題,很好的在全區域內進行搜索,有利于全局最優解的確定.針對燒結配礦的成本最低問題,結合燒結礦的各種非線性的質量指標約束,該改進算法的尋優結果十分穩定.通過上述數據對比結果可知,該算法可以明顯的改善配料方法,而且尋優配礦方案經鋼鐵企業驗證可以在滿足企業生產的情況下降低原料成本,為鋼鐵企業帶來很好的經濟效益.
