近紅外光譜法檢測芝麻油中摻假大豆油
2019-09-10 06:10:45董馳靜劉嘉豪段朝陽靳皓
糧食科技與經濟 2019年5期
董馳靜 劉嘉豪 段朝陽 靳皓
[摘要]使用芝麻油和大豆油調和成不同比例的試驗樣品,在4 000~10 000cm-1的近紅外光譜來采集樣品,通過The Unscrambler 9.7軟件對試驗數據進行建模,建模集的Correlation和RMSEC分別為0.998 749和1.410 906,預測集的Correlation和RMSEP分別為0.837 732和20.375 10。為了選出最優波段進而利用MATLAB再次建模,分別采用IPLS和SIPLS對波長進行篩選,得到IPLS建模集的Correlation為0.998 465和RMSEC為1.562 843,預測集的Correlation為0.993 737和RMSEP為3.001 852;得到SIPLS建模集的Correlation為0.999 674和RMSEC為0.760 642,預測集的Correlation為0.998 937和RMSEP為1.076 967。研究結果表明,采用近紅外光譜法可以對芝麻油中摻假大豆油做定量檢測。
[關鍵詞]近紅外光譜;芝麻油摻假;大豆油
中圖分類號:S565.3? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A? ? ? ? ? ? ? ? ? DOI:10.16465/j.gste.cn431252ts.20190515
食用油作為膳食的主要成分之一,伴隨著經濟的發展和人們生活水平的提高,我國食用油的消費量處于穩步上升狀態。目前市場上銷售的食用油種類眾多,食用油的種類、產量、營養價值的差別,導致其價格相差很大,一些不法商家為了尋求高額利潤不惜在食用油中進行摻假來牟取暴利。目前食用油的摻假一般分為兩種情況,一種是在食用油中摻入非食用油,比如在其中摻入桐油、青油、大麻油,甚至礦物油等;另一種是食用油之間的相互摻假[1]。食用油之間的相互摻假又細分為同種食用油之間的摻假和不同種類的食用油摻假,主要是在高價食用油中摻入低價食用油,例如常常將棕櫚油、大豆油等兌入花生油、芝麻油中,目前市面上最為普遍的是將廉價、量大的食用油摻入優質價高的油脂中。雖然國家已經發布了關于食用油市場準入制度和新的食用油標準,但目前對于食用油產品種類、調和油的組成和比例依舊缺乏直接、方便、準確的檢測手段。因此,食用油種類、調和油的組成和比例的定性定量只能從源頭上來控制。
常見的摻假檢測方法有多種,如紫外可見法、熒光光譜法、高效液相色譜法、氣相色譜法、差示掃描量熱法等,但與傅里葉變換紅外光譜相比,這些方法不但價值昂貴而且費時費力。傅里葉變換紅外光譜作為一種快速檢測摻假的方法,具有不需要樣品預處理、分析快速、極少使用有毒溶劑等優良特點[2]。通過采集食用油的近紅外光譜,建立調和油的定量分析模型來研究食用調和油的組成,使用近紅外光譜做定量分析具有可行性[3-5]。目前,關于食用油摻假的定量分析相對來說較少[6]。
1? 材料與方法
1.1? 儀器與分析條件
采用美國Perkin Elmer公司傅里葉變換近紅外光譜儀,掃描范圍為4 000~10 000 cm-1,分辨率為4 cm-1,掃描次數為32。以大豆油和芝麻油為試驗材料,設計出這兩種植物油在0%到100%摻雜濃度的定量檢測模型。采集芝麻油和大豆油兩種植物油的22個樣品的近紅外光譜,再使用MATLAB選擇出合適波段,通過The Unscrambler 9.7對試驗數據進行建模,并對芝麻油摻假進行定量檢測[7-8]。近紅外光譜分析具有易于制樣,便于測量,儀器設備簡單、可靠等特點[9]。
1.2? 試劑和樣品處理
試驗中,使用市場購買的100%純芝麻油,使用不同比例的大豆油來摻假設置試驗組,摻假比例的控制方法是采用質量分數,即加入大豆油占摻假后芝麻油的質量百分比。取6 mL的大豆油、94 mL的芝麻油進行充分混合,配制出摻假6%的芝麻油摻假樣品。依此方法,按質量分數配制出6%~98%摻假芝麻油樣品20份,加上純芝麻油和純大豆油,共22個樣品。選出15個樣品作為校正集,余下7個作為預測集。
1.3? 數據處理
通過The Unscrambler 9.7確定出模型的最佳主成分數,利用iToolbox工具包在MATLAB R2014a中選擇出波數的最優建模區間。利用校正相關系數,校正標準偏差,預測相關系數和預測標準偏差等指標來評定模型的質量,并完成驗證集驗證。
2? 結果與分析
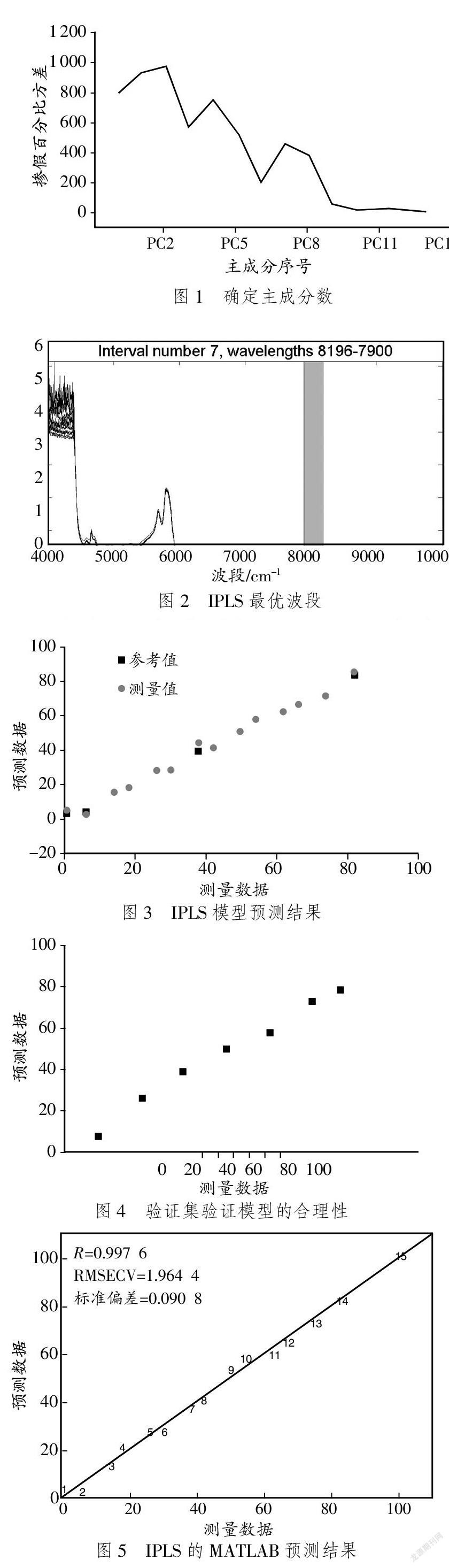
通過The Unscrambler 9.7軟件對15個樣品的全譜數據、結合交互驗證的方法建模并確定主成分數,結果見圖1。
通過觀察主成分序號的百分比方差,可以直觀觀察到有用主成分序號為PC0~PC8。主成分序列的選取結合最優波段的選取以達到數據的可靠性與高效性。
2.1? 基于IPLS進行數據處理
將波長數據集分割成20個區間變量,計算每個區間的PLS模型并在其中給出結果。
2.1.1? 選取最佳建模波段
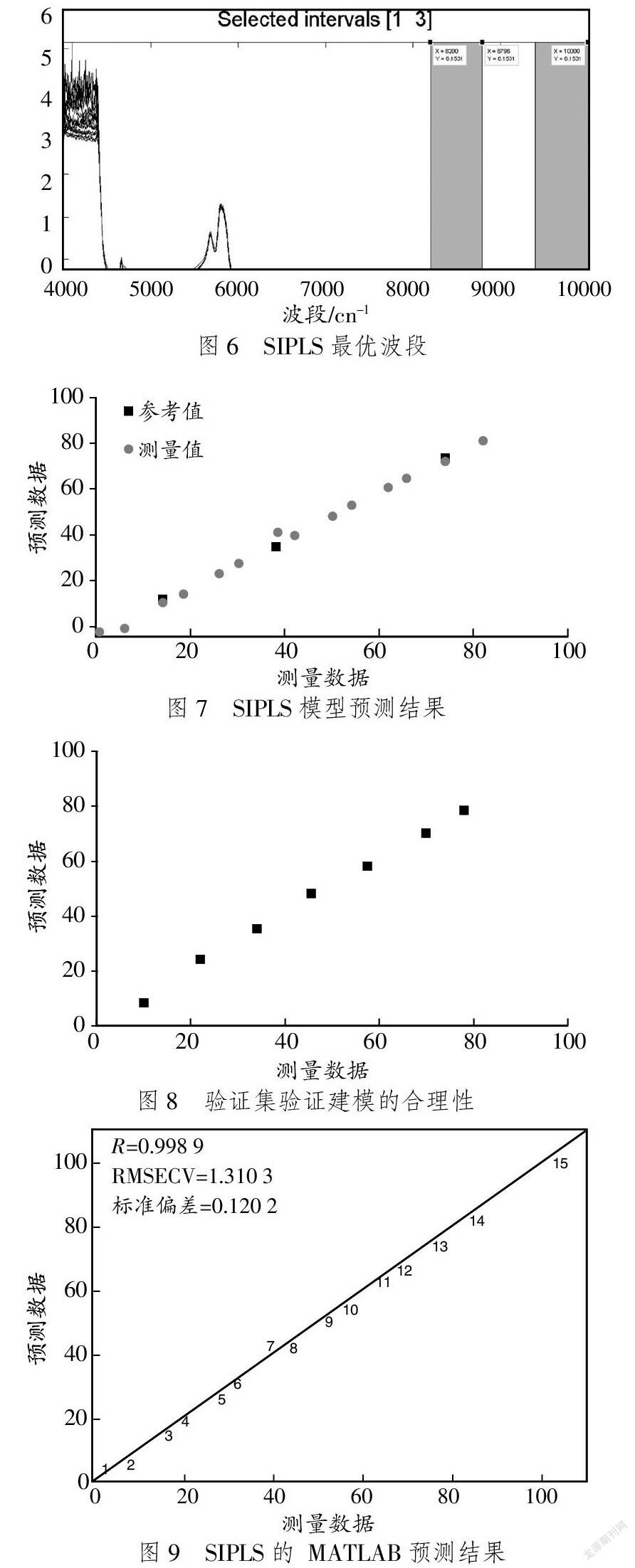
通過MATLAB篩選出最優建模波段(校正標準偏差最小波段),結果見圖2。
據圖2可知,最佳建模的光譜波段為7 900~? ? ?8 196 cm-1。
2.1.2? 使用The Unscrambler9.7軟件進行建模及驗證
基于IPLS數據處理下通過The Unscrambler 9.7軟件進行建模及驗證,IPLS模型預測結果見圖3,驗證集驗證模型的合理性見圖4,IPLS的MATLAB預測結果見圖5。
使用MATLAB R2014a IPLS處理,在光譜區間7 900~8 196cm-1建模,得到R值為0.997 6,RMSECV值為1.964 4。在該區間使用The Unscrambler 9.7進行校正集建模,得到與MATLAB一樣的建模效果。之后通過預測集來驗證模型,得到驗證集的預測相關系數為0.993 737,預測標準偏差為3.001 852。
2.2? 基于SIPLS進行數據處理
2.2.1? ?選取最佳建模波段
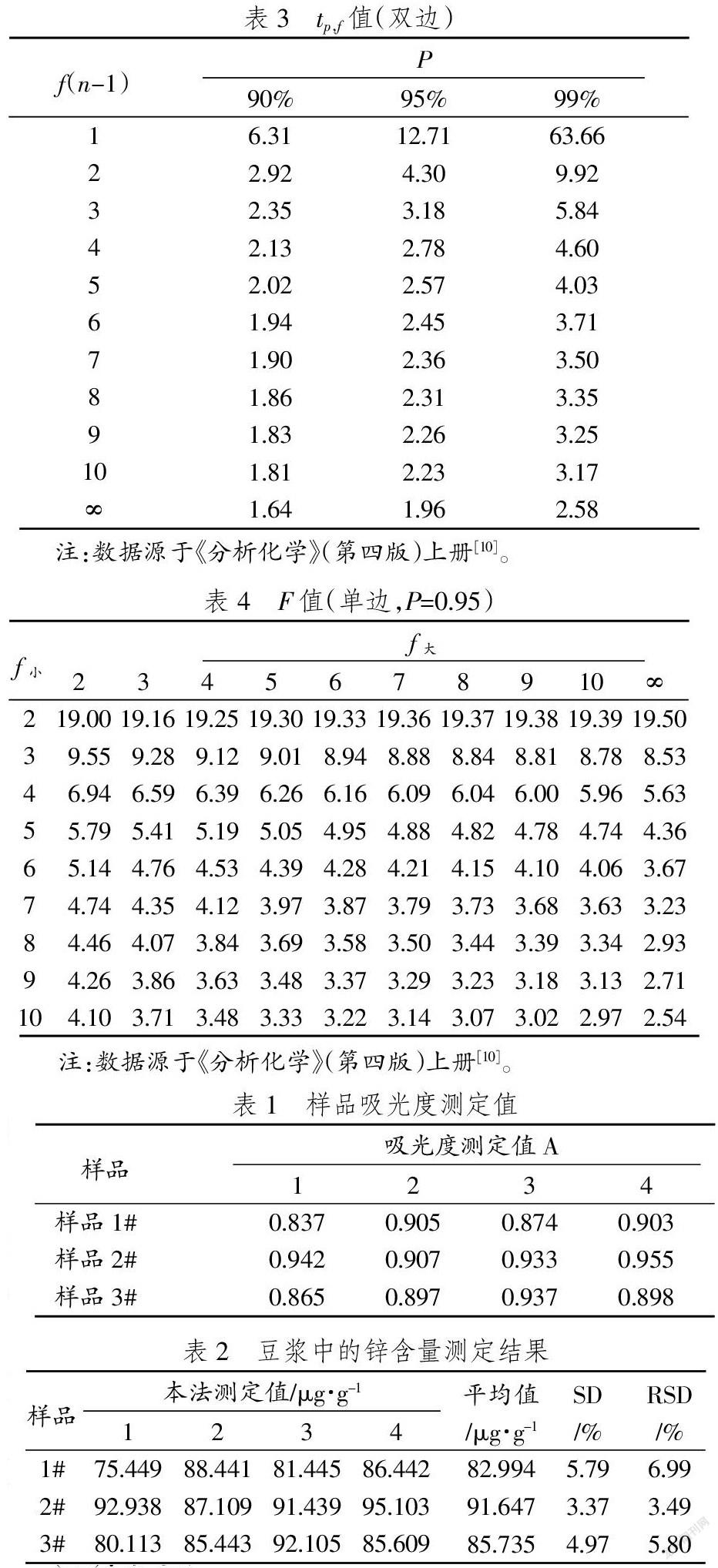
選取最佳建模波段,結果見圖6。
2.2.2? ? 使用The Unscrambler 9.7光譜分析軟件進行建模及驗證
通過The Unscrambler 9.7光譜分析軟件進行建模及驗證,SIPLS模型預測結果見圖7,驗證集驗證建模的合理性見圖8,SIPLS的 MATLAB預測結果見圖9。
使用MATLAB R2014a SIPLS處理,在光譜區間8 200~8 796 cm-1和9 400~10 000 cm-1建模,得到R值為0.998 9,RMSECV值為1.310 3。在該區間使用The Unscrambler 9.7進行校正集建模,得到與MATLAB一樣的建模效果。然后通過預測集來驗證,得到驗證集的預測相關系數為0.998 937,預測標準偏差為1.076 967。
3? ? 結? ? 論
本試驗數據共為22組,15組選為校正集,分別為1組、2組、4組、5組、7組、8組、10組、11組、13組、14組、16組、17組、19組、21組、22組,7組選為驗證集,分別為3組、6組、9組、12組、15組、18組、20組。由以上試驗數據的處理和分析可以得出,全譜主成分數共有14個,經過主成分分析使主成分從14降為8,使得模型更加穩健、可靠。近紅外光譜法的檢測結果非常依賴建模樣本基礎數據和數學模型的準確性,本試驗所建立的模型后續應采集更廣泛的樣本,及時添加到校正模型里,以保證模型的穩定性、可靠性和準確性。
利用近紅外光譜分析技術可鑒別食用油的摻假比例,試驗結果既為近紅外光譜分析技術應用于食用油摻假檢測提供了可靠的試驗依據,又為食用油生產管理及品質評價體系建立方面提供了重要的技術支持,具有簡單高效且易于推廣等優點。
參考文獻
[1]歐志葵.國標缺位調和油被曝勾兌比例隨意[N].南方日報,2012-08-25(8).
[2]孫曉丹.基于化學計量學方法和FT-IR光譜的橄欖油品質分析[D].鄭州:鄭州大學,2015.
[3]王龍,朱榮光,段宏偉,等.光學快速分析技術在食用油摻假檢測中的應用[J].食品與機械,2016(3):235-238.
[4]陳華才,王志嵐,劉福莉.二組分食用調和油組成的近紅外光譜檢測定量分析[J].中國糧油學報,2008(5):180-182.
[5]劉燕德,靳曇曇,王海陽.基于拉曼光譜的三組分食用調和油快速定量檢測[J].光學精密工程,2015(9):2490-2495.
[6]張嚴.近紅外光譜技術快速鑒別與檢測食用油摻偽研究[D].鄭州:河南工業大學,2015.
[7]靳皓,黃沛遵.近紅外漫反射法檢測雪梨中的可溶性固形物[J].食品工業,2017(9):285-287.
[8]吳憲.近紅外光譜技術在食用植物油脂檢測中的實踐研究[J].糧食科技與經濟,2019(1):34-37.
[9]楊佳.傅里葉變換紅外光譜技術在芝麻油真偽鑒別?摻偽與品質分析中的應用[D].北京:北京林業大學,2013.
收稿日期:2019-05-09
基金項目:天津市高等學校大學生創新創業訓練計劃項目(201810 061130)。
作者簡介:董馳靜,女,本科,研究方向為測控技術與儀器。
通信作者:靳皓,男,碩士,講師,研究方向為農產品檢測。
