算法自動化決策風險的法律規制研究
2019-09-10 11:50:33孫建麗
法治研究 2019年4期
關鍵詞:信息
孫建麗
摘要:隨著自動化決策算法的廣泛運用,民事主體因受“信息繭房”裹挾正在喪失信息獲取自主權。同時隨著算法預測性使用功能的不斷強化,民事主體隱私安全和發展平等權也日益面臨著被損害和被剝奪的風險。規制這些算法問題,一方面需要以歐美為鑒,從大數據規范收集和利用著手進行源頭治理;另一方面需要結合我國具體國情,及時增設數據被遺忘權、更改權,并創設算法安全委員會,由其集中負責計算機源代碼披露和算法解釋、審核、監管工作。此外,為全面防范、懲戒算法侵權行為,還需通過立法確立算法侵權責任機制。
關鍵詞:算法侵權大數據被遺忘權算法監管侵權責任
近年來,隨著強人工智能技術的不斷進步以及機器學習理論的不斷深入,算法自動化決策被普遍運用于各領域。然而,算法自動化決策在節約時間和提升工作效率的同時,也引發了諸多問題,如“信息繭房”效應以及“算法殺熟”現象等,其不僅壟斷了個人視域,還損害了社會公平。如何通過法律規制保證算法自動化決策的合理性、正當性和公平性,減少自動化算法在各領域決策中觸發的“信息繭房”風險、隱私泄露風險以及歧視風險,抑制由算法自動化決策促成的群體極化現象,理應成為當前法律關注的焦點。這不僅需要我們對算法自動化決策引發的現實危害進行深度剖析,也需要我們在具體法律制度闕如的當下,及時借鑒歐美人工智能治理的有效經驗,結合國內算法自動化決策適用的情況。積極探索出能夠切實規制算法自動化決策風險的法律路徑。
一、算法自動化決策的現實危害剖析
人工智能成為國際競爭新焦點之際,算法已然備受各國重視。然而,在對算法自動化決策技術加緊研發、利用的同時,人們普遍忽略了算法自動化決策所帶來的負面影響,以致在“技術中立”思潮的遮蔽下,對算法自動化決策造成的現實危害關注力度不足。近來隨著算法自動化決策在各領域的廣泛應用,由算法自動化決策引發的弊端不斷凸顯:
(一)算法自動化決策導致“信息繭房”風險
“信息繭房”最早由哈佛大學法學院桑斯坦教授提出,意指公眾在海量信息傳播中,因非對信息存有全方位需求,而只關注自己選擇的或能使自己愉悅的訊息,長此以往,將自己束縛在如蠶織就的信息“繭房”中的現象。“信息繭房”效應一旦形成,無形風險便隨之產生。在“信息繭房”效應中,自動化決策算法對定制化信息的不斷精準推送看似滿足了用戶的主觀需求,但實則將用戶引入了“井蛙”困境。因為短時間內在注意力有限的情況下,用戶僅能被鎖定在由自動化算法推送的某類固定信息中,當用戶對此類固定信息形成穩定的閱讀習慣后,便再難以關注其他領域的信息或即時熱點,久而久之,造成用戶思維固化、盲目自信,認知結構單一,甚至模糊或淡化對現實社會的真實感知,間接地剝奪了用戶對其他信息的“知情權”。
另外,自動化算法鑄就的“信息繭房”還會進一步引發回聲室效應和同質化效應。“信息繭房”中,封閉的信息空間使得同類型信息不斷循環顯現,用戶碎片化的算法經驗認知使其誤以為這些信息就是事實全部,進而影響用戶對真實信息的全面獲取和對問題的正確判斷,回聲室效應形成后,信息多元化和信息獲取自由原則的適用空間將會受到嚴重擠壓;此外,封閉的輿論場域還極易促使用戶產生求同心理,用戶通常傾向接受與自己觀點、思想相似的信息,進而組合成各種由線下分化個體聚合而成的線上群組,形成信息同質化效應。這些群組通常取消關注、不關注甚或排斥載有與自己觀點相異的信息,直至形成群內同質、群際異質的局面。這種現象不僅致使群體信息極化、群際關聯松散,還使得相異觀點下沉、言論自由受到侵蝕。
由自動化決策算法推薦的定制化信息雖能暫時滿足用戶的個性化消費需求,但其長期鑄就的“信息繭房”所帶來的潛在社會危害不容忽視。自動化算法定制化的信息推薦使得用戶個體極易忽視電視新聞、日報頭版、宣傳海報等所載信息的全面引導,致其主動捕獲、接收信息的能力弱化。再加上以個人為中心、以推送關聯內容為主題的自媒體時代下,有效網絡監管力量的缺失,若任由用戶被動包裹在由自動化算法持續推送的不良信息繭房中,釀成的后果將不堪設想。同時,長期的信息繭房束縛也嚴重限制了用戶個體視野的拓展,不利于形成廣泛而全面的社會公共認知。
(二)算法自動化決策引發隱私泄露風險
隱私泄露風險不僅發生在用戶數據收集階段,隨著自動化算法的進一步智能化,還將發生在算法預測階段。這就意味著之前未向網絡平臺披露過的個人信息有可能經過深度學習算法的預測被推斷、披露出來。例如,美國研究者曾對“Facebook Likes”58000名志愿者提供的準確率高達80%-90%的個人信息,如性取向、種族、智力情況、宗教及政治觀點、性格特征、幸福指數、癮品使用、父母離異、年齡和性別信息進行數學建模,自動化算法在未獲取志愿者其他任何信息和個性特征的情況下,可以相當準確地預測出該Facebook用戶是否為同性戀者。實踐中,抓取用戶數據后啟用自動化算法對未來趨勢進行預測已不罕見,例如知道用戶分別是全國步槍協會成員和計劃生育支持者,自動化算法將會通過貝葉斯定理相應地預測出二者未來支持共和黨和民主黨的概率,進而將用戶的政治選舉意愿和傾向揭示出來,盡管這樣的預測結果可能會與未來用戶的真實決定存有一定偏差,但通過自動化算法深度挖掘并披露用戶潛在隱私信息已是不爭的事實。
大數據挖掘技術的進步為自動化算法的強智能化提供了有力的技術支撐,當更多數據被輸入到算法模型中時,算法模型又一次得以完善和改進。與以往簡單人口統計信息不同,當前自動化算法通過分析已輸入的海量個性化數據點來為用戶進行深度畫像,其不僅能夠知悉用戶的性別、民族、收入等基本信息,還可以全面預測用戶的心理特征和心理狀態等。因為通過合并在線和離線數據,用戶每一次網頁瀏覽、人際交互等由網絡行為生成的結構化和非結構化數據都能被收集、存儲,而后經由SQL、SAS、R或者Python、C++等數據挖掘工具將隱藏的預測性信息抽取出來,通過運行自動化算法揭示出用戶的潛在隱私。正如《紐約時報》所報道的零售巨頭Target根據自動化算法分析向限制民事行為能力人郵寄嬰兒用品手冊,而法定監護人卻不知悉其懷孕的信息一樣,自動化算法已經遠遠超越當前人類個體對自我信息的認知范圍而對個人隱私保護形成強烈沖擊。
然而,自動化算法越來越智能化的同時,大數據背景下有關隱私保護的法律規定并沒能同步跟進,以致對主體隱私保護不盡周全。網絡時代,如何將因自動化算法導致的隱私泄露所引發的損害風險降至最低,而又不過度阻礙自動化算法帶來的技術進步,是時代賦予立法者的義務,也是當前法律首要關注的焦點。沒有相應的法律規制,每位網絡用戶均為透明的個體,毫無隱私可言,在使其失去心理安全保障的同時,也縱容了算法使用者利用他人隱私進行營利投機的行為,不利于營造網絡合理秩序和公平競爭環境。
(三)算法自動化決策助推歧視風險
歧視風險不僅存在于現實生活中,其還以大數據為媒介滲透到自動化算法決策中,近來消費者反映強烈的“算法殺熟”現象即是算法歧視的典型例證。“算法殺熟”是指服務或商品提供者根據消費者在其網站上的消費次數,收集、分析該消費者對商品或服務的消費信息,當消費者頻繁進行消費時,算法將會自行記錄并向該消費者發起高價要約,從而使其以高于首次或低頻次購買該服務或商品的消費者的價格獲得該服務或商品。事實上,除卻含有價格歧視因素的“算法殺熟”現象外,自動化算法歧視還有多種表現,如房屋租賃歧視、教學質量評估結果淘汰機制歧視、金融信貸與保險歧視、刑事犯罪與刑罰預測歧視、人格測試與就業歧視等。自動化算法帶來的以上種種歧視不僅極易導致個體錯失獲取資源和實現自我發展的機會,損害個體公平,還容易造成“強者愈強、弱者愈弱”的群體極化現象,損害群體發展公平。
自動化算法帶來的歧視風險一方面源自使用者或設計者自身的偏見,這種偏見會被后者以替代變量的形式編人計算機程序中,然后隨著算法自身的不斷學習而被逐漸放大。例如,使用者為縮短員工通勤用時以提高工作出勤率,自動篩除長距離通勤者的網上求職申請。根據這一要求,設計者在建模階段將會增設“住址距離”這一與職位申請無關的替代變量,從而將長距離通勤群體一概排除在外。自動化算法歧視風險另一方面還源于大數據收集的非準確性。實踐中,自動化算法賴以存在的大數據收集來源主要有購買和自行抓取兩種,無論哪種形式收集到的數據,只要初始收集階段的原始數據存有錯誤且未得以改正,那么未來訓練數據與學習算法都將會進一步放大歧視現象,從而形成永久性歧視。如經濟實力雄厚的企業原始信息被顯示為嚴重資不抵債,當銀行放貸算法抓取這一錯誤信息并作出決策時,如若未來不加改正,該企業可能將永遠無法正常獲取該銀行貸款。
自動化算法固然是幫助人類實現進步的工具,但任由程式化的算法進行自主決策而不施以任何人類干預,自動化算法帶來的種種歧視風險都將成為影響社會穩定的巨大隱患,屆時將不僅涉及算法智能化技術問題,還將涉及法律、道德甚或經貿問題,治理難度更加艱難。然而,技術的進步在促使代碼自動生成的同時,智能化算法的黑箱性質也增加了人類目前對它們的認知和治理難度。究竟該如何降低或者消解自動化算法帶來的歧視風險,理應成為當前法律關注的又一重點。
二、歐美規制算法自動化決策的經驗研究
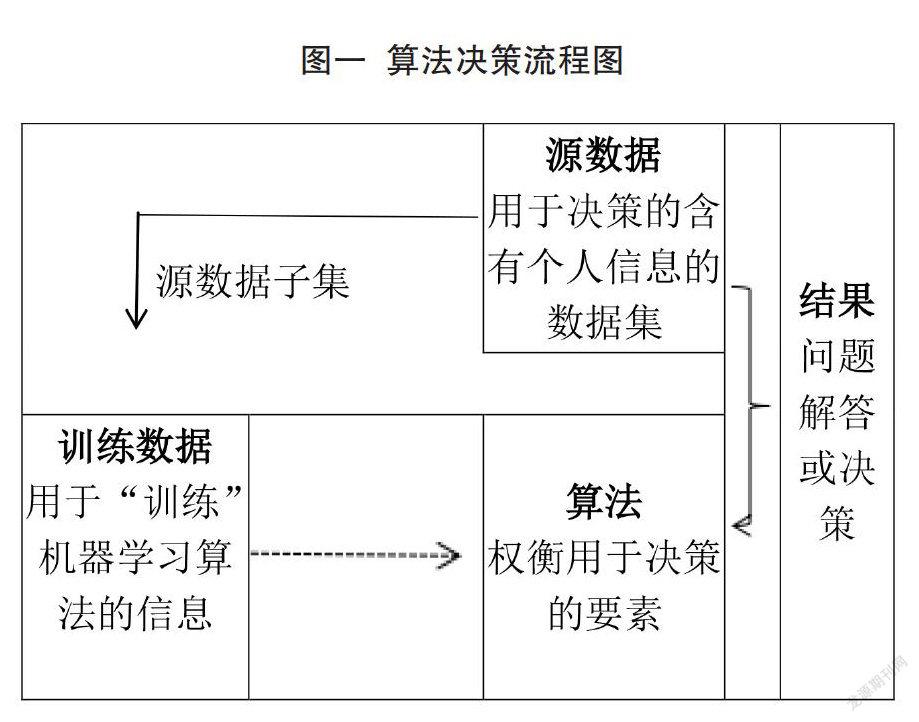
自動化算法被運用在各領域后滋生了諸多問題,人工智能技術較為發達的歐美國家已經對自動化算法帶來的風險規制問題進行了立法探討。縱觀算法運作的整個流程可知(見圖一),源數據是算法演進的基礎,訓練數據是學習算法自主決策的直接依據。源數據負載著民事主體的諸多隱私信息,一旦源數據收集不準確或利用不規范,訓練數據對有效信息的提取就會發生錯誤,進而干擾學習算法對決策要素的正當權衡,致其最終作出錯誤決策。正因如此,歐美當前立法多以數據收集和利用為切人點對算法決策風險進行源頭規制。事實上,歐美當前對算法的立法規制僅限于數據收集和利用領域,還未通過立法方式延及算法本身。因此,本部分將結合歐美數據立法規制的現實狀況以及算法規制的前沿學術理論對算法風險規制問題進行詳細探討。
(一)歐美數據收集與利用的法律規制
人工智能時代,不管算法如何向智能化階段演進,均不能脫離大數據而單獨存在。因此,防御算法風險的首要舉措即是對大數據的收集與利用進行立法規制。只有對大數據收集與利用環節進行有力規制,算法決策環節才有可能降低以上風險的發生。在數據收集與利用規制方面,《歐盟數據保護指南》與《通用數據保護條例》堪稱典范。其中《歐盟數據保護指南》確立了數據收集最小化原則、數據保密和安全存儲原則、數據使用目的限制原則、數據處理透明原則、禁止數據二次使用原則。除通過確立以上原則對數據收集和利用行為進行規范引導外,《歐盟數據保護指南》還對數據主體明示同意、數據收集準確性、數據匿名化使用、敏感數據合理使用、數據更新和移除、違法使用數據處罰機制等具體問題進行了詳細規定。隨后《通用數據保護條例》對數據主體明示同意條款和違法使用數據處罰機制進行了重述,同時亦對數據主體和數據使用者分別創設了新的權利和義務,即數據被遺忘權、訪問和攜帶數據權以及數據泄露通知義務。另外,為處理數據跨境問題,《通用數據保護條例》還單獨增設了一站式數據處理機制條款。從《歐盟數據保護指南》和《通用數據保護條例》詳盡的規定內容可知,歐盟有關收集、利用、保護個人數據的規范已經自成體系。
與歐盟類似,美國也通過立法方式對個人數據收集和利用問題進行了相應規定。美國聯邦貿易委員會在《公平信用報告法》中規定,消費者報告機構、數據經紀人、雇主需要為消費者提供接觸信息的渠道,以及更改錯誤信息的機會,否則需要承擔民事責任和接受行政處罰。進一步而言,上述主體只有在消費者知情同意的情況下才可利用消費者數據進行決策。美國聯邦政府頒布的《消費者隱私權法案》也明確確認了消費者對個人數據享有控制權、更改權等7種權利。另外,為規范數據使用行為,減少算法滋生的隱私泄露和歧視風險,美國HIPPA隱私規則對信息去識別化進行了特別規定,其不僅要求信息去識別化只能由專家進行判定,還要求專家必須就信息去識別化判定過程進行記錄。隨后衛生部在《信息去識別化技術指南》中明確提出了原始信息編校、泛化和干擾技術,認為應當對數據主體的姓名、地址、數字碼號等18種易于識別的信息進行模糊處理。除此之外,為防止去識別化信息被重新識別和濫用,美國學者極力建議在HIPPA中增設禁止信息被重新識別條款。通過分析可知,美國對收集、利用個人數據的規定雖然分散,但內容相對周全,實用性較強。
為應對算法風險挑戰,歐美對個人數據的收集和利用行為均給予了高度重視。其中歐盟采用原則與規則并舉的專門立法方式,對利用個人數據的行為進行全面規定,在立法上實現了指導性和可實施性的有機統一,進而從源頭上實現了抑制數據過度挖掘和算法過度預測的目的。然而,過于細致和僵硬的規定也有其天然弊端,如數據每一次挖掘和輸入若有不慎都極有可能違反現行法律規定,進而引發耗時持久的紛爭訴訟,阻礙大數據挖掘技術的進步和抑制算法模型的完善更新。通過立法保護個人數據固然重要,但需要把握好與科技進步之間的平衡關系。相比歐盟體系化的立法機制,美國數據立法相對簡化和自由,注重采用技術手段對數據進行加工處理再利用,更側重數據主體對個人信息的管理和處置。這種立法規定既不會過度束縛數據挖掘技術的發展,也保障了民事主體的數據安全和處分自由,還有利于算法模型的及時改進。總之,采用立法方式對個人數據進行規范只能在部分程度上解決算法決策風險問題,若要進一步化解算法風險,還需要加強對算法本身的規制研究。
(二)歐美化解算法決策風險的理論探究
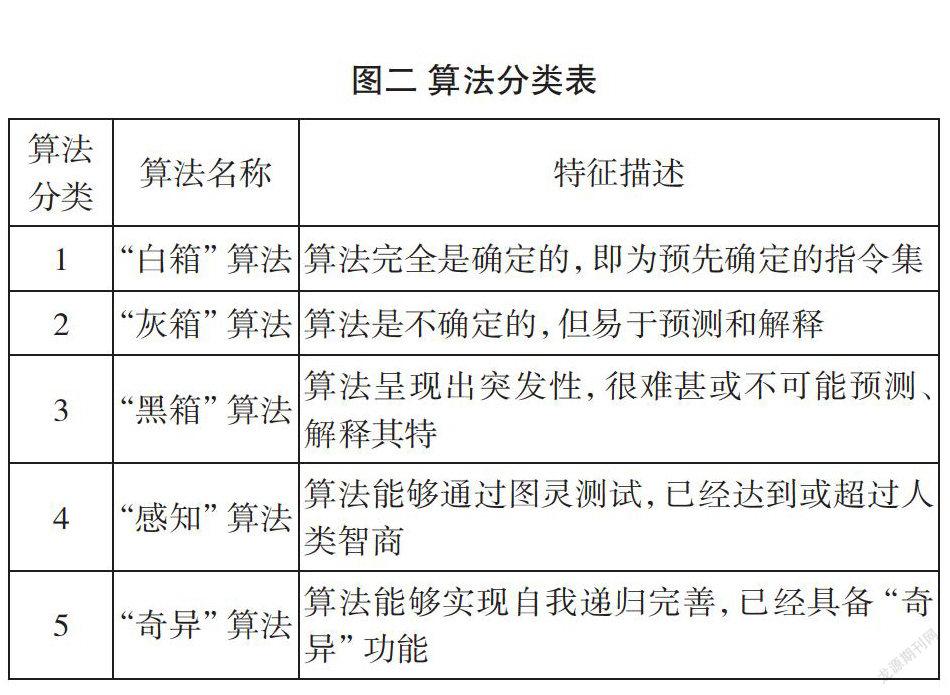
歐美雖未通過立法直接對算法作出規制,但學術界已經以算法為切入點進行了積極探討。事實上,立法技術并非歐美出臺規制算法風險規則的最大障礙,算法演進的階段性尤其是高階算法的不可預測性和難以解釋性才是影響算法立法的最大難題(見圖二)。因此,在算法立法闕如的當前,本部分將結合歐美已有學術研究成果和司法實務經驗對算法風險的規制問題及其可行性進行相應探討。
歐美部分學者認為,披露計算機源代碼增強算法決策程序透明度是降低算法風險的最佳措施。然而,這種觀點在實踐中究竟能否可行,有待商榷。首先,從理論上來看,通常只有專業人員才能熟知計算機基本編程知識,而非專業人員一般難以對其形成準確認知。這就意味著受害人作為非專業人員極有可能無法成為披露計算機源代碼的適格受眾,其需要尋求專業代理人對計算機源代碼作出正確解讀,并由其代替接受來自代碼編寫人員或使用人員的解釋。受害人和適格受眾兩相分離的局面不僅使受害人徒增經濟開支,還使得披露計算機源代碼行為存有流于形式的可能性。其次,披露計算機源代碼只能展現出機器學習所運用的相關方法,并不能揭示出訓練數據驅動算法決策的規則。算法學習日益深入,專業人員只能看到輸入的數據和輸出的結果,一旦學習算法出現錯誤,專業人員也難以對算法所遵循的指令作出有效審核,并對算法決策規則和結果作出清晰解釋。再次,披露計算機源代碼可能會引發一系列不良后果,如導致商業秘密泄露、侵犯他人隱私、妨礙正常執法,甚至會誘使違法分子對算法決策進行鉆營活動,滋生二次侵權風險。最后,通過披露計算機源代碼來降低算法決策風險在歐美司法實踐中已被證明不具有可行性。如在Viacom v.You Tube案中,原告要求被告披露控制You Tube.com搜索功能和谷歌Google.com網絡搜索工具的計算機源代碼,法院以保護商業秘密為由駁回了原告的此種請求。據此,披露計算機源代碼并非解決算法風險問題的最佳方案。
披露計算機源代碼受阻后,歐美學者又提出了以下建議,增設算法解釋權和對算法進行外部審查。算法解釋權旨在對算法決策過程和決策結果進行解釋,然而這種建議能否實現,還有待深入分析。正如圖二所示,算法演進具有階段性,當算法處于“白箱”和“灰箱”階段時,研發者和使用者能夠對算法決策過程和決策結果進行預測和解釋。然而,當算法處于“黑箱”“感知”“智能”階段時,研發者和使用者因對算法失去了控制權,無法再對算法繼續進行預測,此時算法解釋權的設置便形同虛設。再者,算法侵權具有群體性,算法本身具有專業性,創設算法解釋權還需要解決向誰解釋和由誰解釋的問題,以及雙方不能就算法解釋理由達成一致意見時該如何處理的問題,設若這些問題得不到及時解決,算法解釋權就不能付諸實施。另外,與一般侵權所涉及的因果關系不同,算法決策所依據的是相關關系,即使法院判決被告對算法作出詳盡解釋,極值的存在未必能使原告獲得勝訴。正因算法解釋權面臨著諸多難以克服的問題,部分學者進一步提出引入隨機性原理和零知識證明方法以檢驗算法是否存在隱性損害。前者在驗證方式上比較靈活,但需逐一進行,零散耗時;后者則需要雙方進行認知博弈,在不向對方透露任何信息的情況下使對方信服是否存有損害,這種方法因證明難度大而不易被普及。
披露計算機源代碼和增設算法解釋權均存有各種弊端,對算法實行外部審查能否規范算法運作過程和降低算法決策風險,還有賴于算法審查機構和審查方式的確定。根據學者建議,對算法進行外部審查既包括第三方審查也包括行政審查。第三方審查屬于同行審查,這種審查機制允許第三方對計算機代碼和決策標準進行審查,審查方式、審查時間比較靈活,本質上屬于同行監督。算法的行政審查實則是對算法的集中監管,這種審查方式程式化痕跡比較鮮明,需要設置算法安全委員會等專門機構負責對算法進行實質性審查。為強化算法行政監管和保障算法規范運行,學者認為算法安全委員會應當對算法進行使用前批準審查和定期審查。算法使用前批準審查可將未標注用途的且含有損害風險的算法以及未通過批準的營銷算法予以剔除,進而保證投入運行的算法都能夠符合執行標準;而定期審查則有助于及時發現算法存在的隱性風險,減少算法對現實造成的損害。同時這種定期審查淘汰機制也有助于激發設計者和使用者改進和完善算法模型的積極性,進而從內部瓦解算法風險。另外,為使算法安全委員會在算法故意侵權發生后能夠迅速行使監督和處罰權,學者建議應當對此專門機構進行廣泛授權。
從本質上看,算法實為通過計算機系列清晰指令解決問題的一種策略機制,是對人類解決問題思路的代碼轉化。無論低階算法還是高階算法都須以大數據為基礎,并通過執行系列計算機指令運行結束。從圖二算法分類表可知,低階算法基本上是對已有指令的完全遵循,設計者和使用者可據此對其作出確定預測和解釋。然而,高階算法則較為復雜,除需要已有指令引導外,還可以根據訓練數據進行自主學習和自行決策,已經超越原有指令既定的路線,脫離了人類的有效控制。高階算法的不可預測性使得算法立法出現了極度盲點,嚴重遲滯了算法的立法步伐。誠如上文所述,算法以大數據為基礎,以訓練數據為直接依據,并非不受約束和限制,歐美通過規制數據立法從源頭上對算法風險進行治理的思路是正確的,也是有效的,這就為我國未來規制算法風險提供了正確的方向指引。另外,歐美學者以算法本身為切入點提出了以上極具建設性的建議,雖然在可行性上不盡完善,但目前為止依然是最能解決算法風險問題的對策。事實上,我國對算法進行立法規制時,對以上學術建議進行相應整改后,能夠提高其可執行性。
三、我國對算法自動化決策的具體規制進路
算法被廣泛運用以來對各領域造成的風險已經備受學者關注,目前我國還未有規制算法風險的專門立法。國內學者對算法風險規制的研究成果并不多見,算法規制對策更是匱缺。因此,我國未來對算法進行立法規制時,可仿效歐美從數據規制和算法檢測、監督兩方面著手,結合我國現行法制體系和機構設置現狀,積極探索出符合我國國情的法律規制路徑。
(一)增設數據被遺忘權和更改權
統觀我國歷次立法過程,短時間內制定出一部完善的算法法律可能性不大。我國人工智能技術研究起步晚,人工智能技術立法經驗極度匱乏,再加上實務中算法帶來的風險矛盾不像歐美國家那樣凸顯,導致我國當前系統規制算法的立法條件相對欠缺。為防患于未然,我國依舊有必要通過立法方式對算法風險進行規制。誠如圖一和歐美立法經驗所示,以規制大數據為切入點是治理算法風險的必經之路。無論歐美通過何種立法方式對數據收集、利用、處理問題作出何種規定,歸根結底都是數據規范化使用問題。從法律規范的可行性上而言,復雜繁瑣的立法規定未必能夠得以真正執行,散亂無章的法律法規有可能導致適用上的混亂。近期內我國既不能立刻出臺類似《歐盟數據保護指南》和《通用數據保護條例》這樣的系統性法律規范文件,也不能像美國那樣將數據保護分散規定在多部法律中,只能通過小范圍立法的方式對數據規范利用進行集中規定。
從立法緊迫性上來看,我國當前最宜為民事主體創設數據被遺忘權和更改權,并在未來逐漸加強對這兩種權利的保護。數據被遺忘權的創設使得主體有權決定是否刪除在網絡上公開過的個人信息,以及是否排除他人不合理的利用行為,進而主動界定和控制個人隱私邊界。數據被遺忘權具有積極性、主動性,可與隱私權消極性、防御性相互契合,在互聯網時代共同為民事主體的數據保護筑起嚴密的防護墻。數據被遺忘權和隱私權并行規定的情況下,即使個人數據被網絡爬蟲爬取,民事主體一經發現可立即通知數據使用者予以刪除,無需事后再提起隱私侵權訴訟。當前正值民法典各分編編纂匯總之際,可借此契機將數據被遺忘權與隱私權做一并規定,在隱私愈發彌足珍貴的網絡時代,以強化對個人信息和數據的保護。
當今大數據挖掘技術的飛速發展和廉價存儲器的普遍運用,使得個人數據極易被挖掘和存儲。正因如此,數據主體正以數字化的形式被永久記憶。當記憶成為常態,遺忘將變得更加稀缺和困難,為民事主體創設數據被遺忘權可有效改變數字“記憶”格局。設若個人數據不能被遺忘,數字化記憶于人類而言即是束縛和限制。因為主體的“被數字化”會將其變成數據的表征,進而貶低數據主體在決策中的主導作用,直至被淪為數據奴役的對象,而創設數據被遺忘權可及時消除算法數據對個體的數字化記憶,使個體不再受特定信息和錯誤數據的裹挾,從而恢復個體主動塑造自我認同的原有局面。
值得注意的是,數據主體對數據的刪除可能會降低算法相關關系的強度,影響算法決策的準確性。若要從根本上解決解決這一問題,還需要使民事主體對個人數據保有更改權。誠如上文所述,大數據是算法演進的基礎,數據過少或不準確將會進一步放大算法決策風險,而民事主體對數據保有更改權可有效減少因主體行使被遺忘權造成的數據貧乏現象和提高算法決策的準確性。另外,每收集一條數據均需征得相關民事主體的同意,在龐大的人口基數面前顯然不可能實施@,再加上各大互聯網企業對消費者“不同意,禁止使用”條款的設置,使得數據收集更加困難,在“信息孤島”困境無法破解的當下,若不允許為民事主體積極創設數據更改權,就無法為完善算法模型提供海量精確數據,并將數據主體從算法霸權中及時抽離出來,使其免受算法錯誤決策的干擾。由此,適度的數據遺忘與合理的數據更改能夠保障算法決策的準確性,降低算法決策風險,同時也利于尊重數據主體的主觀意愿和保障數據主體的隱私杈。
(二)設立算法安全委員會全面負責算法審查和解釋工作
歐美學者認為,若以算法為切入點解決算法決策帶來的風險問題,需要披露計算機源代碼、增設算法解釋權和對算法進行外部監督。然而,這些學術建議若要在我國付諸實施,除需要進行再次完善外,還需要設置專門機構全面負責算法審查和解釋工作。一方面,與歐美相比,我國人工智能前沿理論總體上還處在“跟跑”階段,創新方面偏重技術應用,基礎研究、技術生態、基礎平臺、標準規范、頂尖人才等方面還存有明顯差距。另一方面,我國每年大數據分析和人工智能人才缺口高達150萬的具體國情,固以及算法決策損害的群體性、廣泛性特征,決定了披露計算機源代碼和解釋算法等極具專業性、技術性的工作只能交由專業機構和專業人員負責。算法安全委員會的設置,不僅能夠全面應對計算機源代碼披露和算法解釋工作,還可全面承擔算法審查和監督工作。
第一,設置算法安全委員有助于計算機源代碼披露工作的順利開展。誠如上文所述,披露計算機源代碼面臨著諸多問題,如計算機源代碼無法向非專業人員披露、披露過程中可能引發決策鉆營、商業秘密泄露、侵犯他人隱私等非法行為發生。正因如此,美國司法實務中有法院以保護商業秘密為由禁止對計算機源代碼予以披露。然而,這種因噎廢食的做法不宜為我國借鑒。因為截至目前還沒出現能夠完全解決算法決策風險的有效策略,披露計算機源代碼在一定程度上確實可以遏制算法侵權現象,假若僅以商業秘密為由一味拒絕,對解決現實問題并無助益。因此,我國若要解決計算機源代碼披露與后續算法侵權之間的矛盾問題,必須設置算法安全委員會,由其代表受害群體接受設計者或使用者對計算機源代碼的解讀。如此不僅可免去非專業人員對算法認知盲點的困擾,還可阻斷非相關人員對計算機源代碼的接觸,避免違法行為發生。
第二,創設算法安全委員會有助于解決算法解釋權問題。除高階算法不可預測和難易控制外,算法解釋權創設的障礙還在于算法解釋主體和解釋對象具有模糊性。我國若通過增設算法解釋權來降低算法決策風險,必須先對算法“由誰解釋和向誰解釋”的問題予以明確。當前來看,宜由算法設計者或使用者作為解釋主體,由算法安全委員會作為接受解釋的對象。首先,算法本質上是由設計者或使用者提出的解決問題的一種策略,算法要解決什么問題、建模階段設置了哪些參數、使用了哪些替代變量、建模數據是否存有污染、極值等,只能由設計者和使用者進行說明,其他人員無從知悉也不可能代其作出解釋。其次,算法侵權具有群體性、廣泛性,解釋者不可能向每位受害者進行一一解釋,由算法安全委員會代表受害群體統一接受解釋,利于提高解釋工作效率和增強算法解釋的可行性。再次,算法解釋與驗證涉及隨機性原理和零知識證明等專業知識,由算法安全委員會代表受害群體統一參與算法驗證過程,可及時維護受害者合法權益。
第三,創設算法安全委員會有助于對算法安全問題進行集中審查和監管。歐美學者認為,算法審查工作既可由第三方進行,亦可由行政機關負責。考慮到當前我國民間組織力量培育不充分,算法同業審查組織嚴重奇缺的現狀,算法審查和監督工作暫時宜由行政機構——算法安全委員會集中負責。算法安全委員會既可以對算法進行使用前批準審查,還可對算法進行定期審查,全面保障算法質量安全,督促其健康運行。另外,為應對高階算法決策風險的不可預測性和難以控制性,靈活處理各類突發算法問題,可通過立法對算法安全委員會進行廣泛、集中授權。如算法安全委員會可按照侵權獲利數額或營業額的一定比例對惡意利用算法進行侵權的行為人實施行政處罰。由算法安全委員會全面負責算法審查和監督工作,利于算法技術中立屬性的復歸,也有助于激發研發人員遵循倫理和技術規范的積極性。
(三)及時確立算法侵權責任機制以遏制算法侵權
人工智能時代,算法技術并非完全中立。誠如本文第一部分所述,部分群體可能在無形之中就成為算法“信息繭房”的包裹對象,以及算法歧視和隱私泄露的受害者。通過分析可知,算法雖是解決問題的一種策略,但其在運用過程中會觸發各種侵權現象。目前來看,通過立法確立算法侵權責任十分必要。算法侵權責任確立時需要著重考慮以下幾方面:
第一,算法侵權相關關系的判定。司法實務中判定被侵權人所受損害與算法決策之間是否存有某種關系是算法侵權成立與否的前提。與一般侵權不同,算法侵權不適用必然性因果關系和蓋然性因果關系,算法決策所依據的是相關關系固。相關關系彈性空間較大,極值之間差異顯著,嚴重干擾了算法決策的準確性。在算法模型中,變量之間相關系數的大小決定著相關關系的強弱,筆者認為,只有確定變量之間存在較強的相關性,即變量之間相關系數達到0.8以上時,才能確認算法模型設計具有合理性,而后才可判定算法決策具有可信性。設若變量之間相關性較弱或不存在相關性,那么算法模型的設計就是失敗的,算法作出的決策就是錯誤的,由此對第三人合法權益造成損害的,應當承擔侵權責任。
第二,算法侵權責任主體的確定。如果算法錯誤決策給受害人造成了實際或精神損害,相關責任人應當承擔侵權損害賠償等責任。具體言之,算法侵權發生之際,相關法律責任應當首先由算法最終使用者承擔,算法設計者存有過錯的,最終使用者有權向其追償。需要注意的是,對算法設計者有無過錯的判定需要根據具體算法情形進行區分:如果算法設計者未遵循相應的技術操作規范,故意違反倫理道德甚或法律,主動設置了算法中的不當規則,對第三人合法權益造成損害的,應當承擔相應的侵權責任。但如果算法基于自主學習主動探索并形成自我規則的,設計者因對算法風險控制程度較低,主觀惡性和過錯較小,可以進行免責。
第三,算法侵權責任方式的確定。算法決策也可能會出現錯誤,給受害人帶來嚴重人身和財產損害。如優步自動駕駛汽車在舊金山擅闖紅燈,谷歌圖像處理軟件將黑人識別為大猩猩,馬薩諸塞州機動車人臉識別算法將司機視作犯罪分子并將其駕照吊銷,微軟機器人Tay言語污穢并宣揚種族至上論等。當算法決策給受害人造成人身、財產損害時,設計者或使用者應當及時停止使用,并積極采取警示和召回措施,主動向受害人進行經濟損害賠償。對因算法決策錯誤而遭受精神損害的受害人,設計者和使用者還應當進行賠禮道歉,積極消除算法給其帶來的不良影響并為其恢復名譽。
由此,我國未來對算法侵權進行規制時,可進行如下規定:設計者、使用者因過錯造成算法缺陷,對他人造成損害的,設計者、使用者應當承擔侵權責任。被侵權人可向設計者、使用者請求損害賠償,使用者存有過錯的,設計者賠償后可向使用者追償,反之亦然。因算法缺陷損害他人人身、財產安全的,被侵權人有權請求設計者、使用者承擔損害賠償、賠禮道歉、恢復名譽、消除影響等侵權責任。算法投入使用后發現存在缺陷的,設計者、使用者應當及時采取警示等補救措施。未及時采取補救措施或補救措施不力造成損害的,應當承擔侵權責任。明知算法存在缺陷仍然設計、使用,造成他人財產、精神健康嚴重損害的,被侵權人有權請求相應的懲罰性賠償。學習算法自主作出決策致人損害的,設計者不存有過錯的,可進行免責。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
