分布式空間Top-K頻繁關鍵字查詢系統
2019-09-10 07:22:44姚遠肖銳
現代信息科技 2019年19期
姚遠 肖銳




摘? 要:隨著地理數據量的不斷增大,傳統的空間數據庫已經無法滿足實際應用的需要。為此,該文圍繞矢量數據的Top-K頻繁關鍵字問題,設計了一個分布式空間數據庫系統。主要內容為分布式矢量數據存儲模型設計,基于Hilbert排列碼的矢量數據劃分策略,分布式空間數據的索引結構以及索引算法設計。
關鍵詞:分布式數據庫;矢量數據;關鍵字查詢
中圖分類號:TP393.04? ? ? ?文獻標識碼:A 文章編號:2096-4706(2019)19-0007-05
Abstract:With the increasing amount of geographic data,the traditional spatial database has been unable to meet the needs of practical application. For this reason,this paper designs a distributed spatial database system around Top-K frequent keyword of vector data. The main contents are the design of distributed vector data storage model,vector data partition strategy based on Hilbert permutation code,index structure of distributed spatial data and index algorithm design.
Keywords:distributed database;vector data;keyword query
1? 問題描述
空間Top-K頻繁關鍵字查詢定義。
輸入:
(1)數據:空間對象集合D={O1,O2,…,On},Oi=(loci,kwi,1,…,kwi,m)包含位置loci和一組關鍵字kwi,1,…,kwi,m。
(2)查詢:Q=(RQ,k),RQ是查詢范圍,k是正整數。
輸出:在查詢范圍RQ內的對象中出現頻率最大的k個關鍵字。
2? 系統設計
本文設計的系統是分布式的,即對于一個空間查詢Q,不再單單是在一個計算節點上的R樹中查找與查詢Q相交的或包含的范圍內的前k個關鍵字,而是針對整個分布式系統各個節點上存儲的所有數據進行查詢。系統的總體架構如圖1所示。
2.1? 數據存儲
2.1.1? 數據劃分
基于Hilbert空間排列碼的空間劃分策略進行劃分。空間數據劃分方法是多維數據分布式存儲的基礎,目的是通過一定的數據劃分規則,將多維數據集分割成多個獨立的數據分片,分布式存儲在集群中的計算節點上。
本系統采用的是一種空間填充曲線的劃分方法,主要思想是使用一條連續的曲線穿過空間中的每個離散單元,且只穿過一次,然后將每個空間數據按照填充曲線的規則進行編碼,然后將編碼值相近的空間數據對象劃分到同一數據塊中,以此來對空間數據進行降維。在空間上相鄰的離散單元,在填充曲線上依然是相鄰的。Hilbert曲線是目前比較常用的空間填充曲線,具有良好的空間連續性。由于每個對象包含的關鍵字個數不同,所以它們的數據量大小可能不同,但可以通過數據預處理,將一些數據大小過大的對象去除。在劃分空間數據集時,這里只考慮每個數據分片的空間對象個數,假設一個數據分片的總大小與其空間中對象個數成正比。
對于Hilbert空間編碼,確定合理的編碼階數是提高劃分效果的關鍵步驟。本系統采用雙層格網的Hilbert空間編碼構建數據劃分。基本思想是:根據初始設定的每個數據分片大小,對數據集進行初始格網劃分,然后統計每個格網的對象個數,對初始格網進行二次劃分。之后基于復雜平衡將所有數據分片平均分到各個計算節點。具體算法見第3節的關鍵算法部分。
2.1.2? 數據備份
采用的是類似Hadoop的同構熱備份方式對主節點進行備份,主節點有一個存儲相同數據的備用節點。當主節點出現故障時,快速使用備用節點,防止數據錯誤發生。系統中的計算節點采用的是異構熱備份方式,即在主節點將數據劃分成很多分片后,將每個分片備份到多個計算節點,一般選擇將一個分片存儲在3個不同的計算節點上。
主節點通過對各個計算節點進行心跳檢測,更新有效節點的個數,如果某個計算節點出現問題,需要根據其他計算節點的負載,將異常計算節點上的數據分片存儲在其他有效的計算節點上,保證每個分片至少有3個備份。
2.1.3? 新數據導入
在2.1.1節中,使用了算法將數據集劃分成數據分片,并且對每一個數據分片都有一個Hilbert空間編碼值。所以當有新數據導入時,先要計算一下新數據所對應的空間范圍的Hilbert空間編碼值,將該數據發送其Hilbert編碼值所對應的數據分片所在的計算節點中。如果某一個計算節點有溢出或崩潰的情況,那么就在新的全體數據集上運行2.1.1節中的算法,進行數據的重劃分。
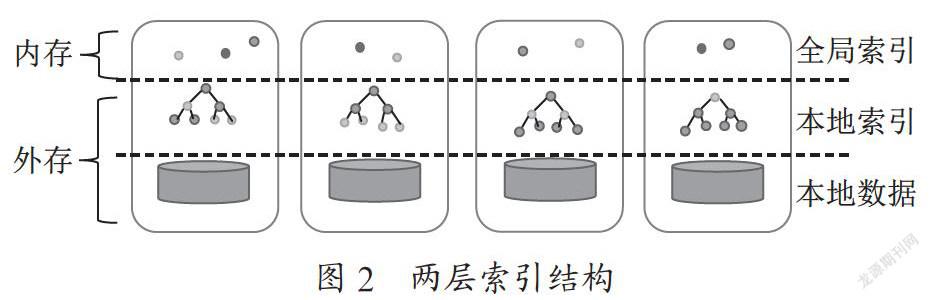
2.2? 索引結構
本系統采用一個兩層的索引結構,如圖2所示。
在計算節點的本地索引的R樹上選擇其中的一些節點作為全局索引,然后將全局索引發布到各個計算節點的內存中去,并且在內存中為全局索引創建一棵R樹,以便后續查詢快速找到全局索引。這里將這個兩層索引結構簡稱為R索引。
2.2.1? R索引結構概述
系統將原始的數據集劃分到計算節點中,然后計算節點Ni存儲分配給它的數據Di。對于每一個計算節點Ni,在其內存儲本地數據Di和本地索引的R樹Ti。節點Ni在本地上建立好一棵R樹之后,從中選取出一些節點作為全局索引,全局索引的格式為(ip,port,address,region)。其中,ip是該索引所在計算節點的ip地址,port是該索引所在節點的端口號,使用ip地址加上端口號就可以定位到全局索引所在的位置了。Address是全局索引所在R樹中的位置在計算節點外存中的地址。region是索引對應的R樹中節點的空間區域。
全局索引從本地索引中選擇出來并發布到計算節點中,在全局索引發布中,被選出的本地索引被添加ip和port等信息,然后再發給各個計算節點。然后,每一個計算節點接收到全局索引后,將其保存到自己的內存中,同時在內存中為全局索引維護一個R樹,便于后面的查詢快速地查找到相應的數據。
當使用R索引查找數據時,主要分為兩個階段(全局索引獲取和本地數據獲取)。首先,查詢在系統中的空間劃分找到滿足查詢空間條件的計算節點,然后從計算節點的內存中提取出在查詢范圍內的全局索引。然后,根據全局索引的ip和port找到全局索引所在的計算節點,找到后,根據address信息從該點的R樹中提取出相應的數據。后面2.2.3節將會具體闡述查詢過程的處理。
2.2.2? 全局索引到計算節點的映射
計算節點Ni從本地的R樹Ti中獲取一個全局索引的集合S(Ni),然后,計算節點將集合S發布到系統中的一部分計算節點中去,對于每一個接收到全局索引的計算節點,將該全局索引保存到自己的內存中,便于后續查詢的快速反應。首先,將當前的數據空間劃分到各個計算節點Ni上,即每一個計算節點Ni都會維護一個劃分空間Space(Ni)。
在這個R索引系統中,對于一個給定的全局索引gi(ip,port,address,region),一個計算節點集合N,將全局索引gi映射到那些計算節點中的Space(Ni)與全局索引gi中的region相交的計算節點。
全局索引映射的形式表述:
對于一個全局索引gi=(ip,port,address,region)和計算節點集合N,R索引將gi映射到Ns中,其中,Ns= {Ni|Ni∈N,Space(Ni)∩region≠?}。
本系統中,使用一個接口用于獲取節點中的劃分空間區域與給定的gi中的region相交的計算節點。該接口記為GetNs(region)。當系統要發布全局索引gi到系統中的各個計算節點中時,發布該索引的計算節點Ni調用GetNs(gi.region)接口函數,獲取要將gi發布到的計算節點集合Ns,然后對集合Ns中的節點,將gi插入到節點內存中的全局索引的R樹中。
2.2.3? R索引查詢處理
R索引的查詢處理分為兩個階段:全局索引搜索和本地數據獲取。當系統收到一個查詢Q(RQ,K)后,查詢Q被發送到所有與Q.RQ相交的計算節點上去。而對于每一個收到查詢Q的計算節點Ni,在Ni的內存R樹中的全局索引返回一個空間區域與Q.RQ相交的全局索引gi。然后計算節點Ni將查詢Q發送到全局索引gi所在的計算節點,而收到查詢Q的計算節點在本地的R樹上對于Q進行查詢。
如圖3所示,圖中有5個計算節點1,2,3,4,5,其中1包含全局索引A,2包含B,3和4都包含C,5節點包含D。查詢RQ與全局索引A,C相交。這樣就將查詢RQ發送到所有A的擁有者中,然后在擁有者本地R樹上對RQ做查詢。而對于全局索引C,由于其與多個計算節點相交,所以3,4節點都會向擁有C的節點發送消息,這樣就造成了通信代價,所以這里采取讓離RQ更近的節點向擁有C的節點發送RQ查詢。
查詢算法:
輸入:查詢Q(RQ,K),計算節點集合N。
輸出:所有與查詢空間相交的本地節點的STL。
(1)判斷與RQ相交的全局索引gi和gi所在的節點Ni;
(2)將查詢Q通過全局索引gi=(ip,port,address,region)利用節點Ni發送到位置信息為ip+port的計算節點上;
(3)在本地索引R樹上進行Q查詢,利用3.2節計算節點的Top-K頻繁關鍵字算法計算出每一個全局索引所在節點的所有STL;
(4)對于第3步中的STL,運用3.3節的FT算法進行查詢算法。
2.2.4? 全局索引的選擇策略
首先,全局索引的選擇需要滿足以下條件:第一,每一個計算節點的全局索引的數量要有一定的限制,因為該分布式系統各節點內的內存空間是有限的,如果全局索引的數量過多,就會造成內存裝不下的情況;第二,對于R樹中的每一個葉子節點n,或選擇n,或選擇包含節點n的父節點,保證選取的索引空間能夠覆蓋整個R樹,使查詢結果具有完整性;第三,R樹的節點n或n的祖先節點最多一個被選中為全局索引,這是因為重復選擇相互覆蓋的區域會造成不必要的全局索引的內存開銷,從而降低計算性能。
由于選擇全局索引的算法是一個NP問題,所以采用貪心算法去選擇R樹中的全局索引。首先,假設內存的全局索引限制大小為k1,取集合G作為選擇的全局索引的集合,當限制大小未到k1時,自根節點開始,一直沿R樹向下擴展,如果子節點加入集合G并且父節點從集合G被刪除后的大小仍然小于全局索引限制k1,就將全局索引向下擴展,并將當前遇到的子節點放入集合G。否則,不進行擴展,到此節點結束。
3? 關鍵算法
3.1? 基于Hilbert空間排列碼的空間劃分策略
Algorithm1 Hilbert-partition(M,B,λ):
輸入:空間對象集M,預期每個數據分片的大小B,閾值λ。
輸出:數據分片集合D。
(1)遍歷M,得到對象總數據量sum以及M的最小外接矩形空間R;
(2)第一次網格劃分的階數為n0=[log4sum/B];
(3)根據R,構造2n0*2n0的初始網格,然后M中每個元素映射到初始格網;
(4)遍歷空間格網單元,得到格網中單元最大數據量Gmax,如果存在數據量大于B*λ的單元,標記該單元,并且對初始格網進行階數為n1=[log4Gmax/B*λ]的二次優化。如果沒有,則n1=0;
(5)構造出n0+n1階的Hilbert填充曲線,對最終的空間格網進行編碼;
(6)初始i=0,對于標記單元,將該單元內的數據對象按照編碼從小到大的順序添加到當前數據塊di,若di的大小大于B,則i=i+1;對于未標記的單元,將整個單元的數據對象添加到當前數據分片di,若數據塊di的大小大于B,則i=i+1。即標記單元中的數據可以存在不同的數據分片中,但未標記的單元不可以。
3.2? 計算節點的Top-K頻繁關鍵字算法
節點存儲數據結構如下。
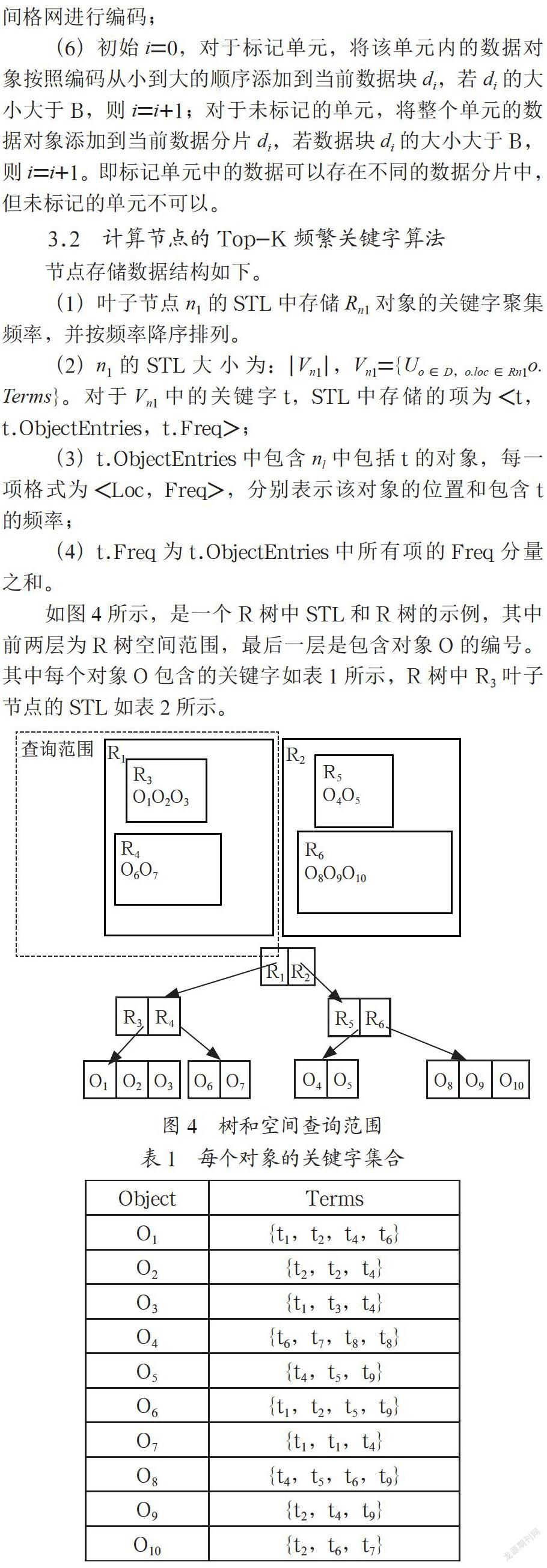
(1)葉子節點n1的STL中存儲Rn1對象的關鍵字聚集頻率,并按頻率降序排列。
(2)n1的STL大小為:|Vn1|,Vn1={Uo∈D,o.loc∈Rn1o.Terms}。對于Vn1中的關鍵字t,STL中存儲的項為<t,t.ObjectEntries,t.Freq>;
(3)t.ObjectEntries中包含nl中包括t的對象,每一項格式為<Loc,Freq>,分別表示該對象的位置和包含t的頻率;
(4)t.Freq為t.ObjectEntries中所有項的Freq分量之和。
如圖4所示,是一個R樹中STL和R樹的示例,其中前兩層為R樹空間范圍,最后一層是包含對象O的編號。其中每個對象O包含的關鍵字如表1所示,R樹中R3葉子節點的STL如表2所示。
Algorithm2計算節點Top-K查詢算法(RQ):
輸入:查詢空間RQ。
輸出:Top-K頻繁關鍵字以及他們的頻率值。
(1)從根節點開始,向下查找所有與RQ相交的葉子節點(n1,…,nm);
(2)如果葉子節點n1完全包含于RQ,則n1的STL全部用于后續計算;如果葉子節點n1部分相交于RQ,則n1的STL中與RQ相交的部分用于后續計算;
(3)對于每個<t,t.ObjectEntries,t.Freq>,利用ObjectEntries中的<Loc,Freq>計算RQ內的t.Freq;
(4) 為t在葉子節點與RQ相交部分出現的次數,利用所有參與計算的STL,使用RA或者NRA算法計算Top-K結果,Top-K計算函數為? 。
3.3? 基于FT算法的Top-K頻繁關鍵字的查詢算法
對于分布式系統來說,關鍵是如何將各個計算節點的結果整合到Master節點。
本系統選擇了FT算法作為分布式系統Top-K頻繁關鍵字的查詢算法。先介紹兩個概念,第一個是每個關鍵字的和(Ssum),關鍵t的和Ssum(t)=S1(t)+S2(t)+…Sk(t),如果第i個節點已經將它本地的關鍵詞t的頻率Pi(t)發到了中心節點則Si(t)=Pi(t),否則Si(t)=0。第二個是閾值Hi,其中Hi表示節點i中排名第k的關鍵字的出現次數,作為后續該節點排名k以后的關鍵詞出現次數的閾值。
Algorithm3 FT(RQ)算法如下。
(1)每個計算節點i將排名前k個關鍵詞、數值和Hi發送給Master,Master計算收到的所有關鍵字的Ssum,然后根據Ssum對關鍵字進行降序排序,取第k名的Ssum作為閾值P1。之后根據Hi計算第k后的關鍵字的上限值Usum(其中Ssum(t)=S1(t)+S2(t)+…Sk(t),Si(t)=Pi(t)或Hi),將Usum小于P1的關鍵字削減掉。
(2)Master將沒有被削減的關鍵字(包括排名前k)再次發送到計算節點,計算節點接收到關鍵字列表后,找到列表中還未發送給Master的關鍵字j,并將j和j的值發送給Master。中心節點對收到的所用關鍵字再次進行求和,然后取第k名的數值作為閾值P2。如果P2≥H1+H2+…Hm(假設有m個計算節點),那么算法就結束了。否則(可能存在某個關鍵字在所有節點中都不排在前k,但總和排在前k),繼續進行步驟(3)和步驟(4)。
(3)Master中令M=P2/m,循環比較所有Hi與M,如果Hi (4)類似第二階段,Master將沒有被削減的關鍵字(包括排名前k)再次發送到計算節點,計算節點接收到關鍵字列表后,找到列表中還未發送給Master的關鍵字j,并將j和j的值發送給Master。中心節點對收到的所用關鍵字再次進行求和,然后前k名的關鍵字即為精確解。 4? 系統流程 主要分成數據建立和數據查詢兩個過程。 建立過程:首先,對于給定的空間中的數據集D,分布式計算節點個數k,利用基于Hilbert空間排列碼的空間劃分策略,將數據集D中的點分配到k個計算節點上,每一個計算節點維護一個區域劃分。然后,在本地節點上利用本地數據建立一棵R樹,R樹的葉子節點上存儲STL。然后,從各個計算節點的本地索引R樹中取出一些點作為全局索引。再將全局索引分配到相應的計算節點的內存當中,其中內存中也為全局索引維護一個R樹。 查詢過程:以上的工作做完后,系統收到一個查詢Q (RQ,K),將Q發送到所有空間區域與Q.RQ相交的計算節點中。每一個收到Q.RQ的節點在自己的內存中搜索全局索引,再根據全局索引gi(ip,port,address,region)中的ip,port和address信息找到gi所在的計算節點中的外存中的地址,隨后在本地R樹中運行獲取當前查詢對應R樹的葉子的所有STL信息。最后,利用對各個計算節點上的STL進行全局的Top-K過程,得到目標的Top-K輸出,查詢過程如圖5所示。 5? 結? 論 在空間數據量越來越大的情況下,使用分布式框架可以有效節約計算資源,靈活存儲數據。本文設計了基于Hilbert兩層格網劃分方法的分布式空間數據庫集群,并且設計了兩層索引結構,在索引算法中充分將大量計算工作分給計算節點。目前給出的算法和系統框架在理論上可以解決空間數據庫Top-K頻繁關鍵字的問題,具體實現整個系統并且調優測試,還有待今后進一步研究。 參考文獻: [1] 王金寶.云計算系統中索引與查詢處理技術研究 [D].哈爾濱:哈爾濱工業大學,2013. [2] AHMED P,HASAN M,KASHYAP A,et al. Efficient Computation of Top-k Frequent Terms over Spatio-temporal Ranges [C]//Acm International Conference on Management of Data.New York,USA:ACM,2017. [3] 李雷,李曉東,劉欣陽.分布式網絡中的一種高效top-k求解方法研究 [J].計算機工程與應用,2010,46(18):89-92. [4] 余利峰.面向分布式空間數據庫的矢量數據存儲與查詢處理關鍵技術研究 [D].杭州:浙江大學,2018. 作者簡介:姚遠(1998.06-),男,漢族,黑龍江大慶人,就讀于計算機學院,本科在讀,主要研究方向:大數據科學。
