基于LMT模型的特征工程分析
——以泰坦尼克號為例的船舶安全管理實踐
2019-08-28 02:12:02周峙泓范培華
上海管理科學 2019年4期
周峙泓 沈 克 范培華
(上海外國語大學 國際工商管理學院,上海 200083)
RMS Titanic沉船事件是歷史上著名的災難事件。1912年4月15日,泰坦尼克號從英國南安普敦出發,途經法國瑟堡-奧克特維爾以及愛爾蘭昆士敦,駛向美國紐約。其在此處女航中與冰山相撞后沉沒,2224名乘客和機組人員中有1502人喪生,事發時正是泰坦尼克號從英國南安普敦港至美國紐約港首航的第5天。該船當時是世界上最大的郵輪,1912年4月14日星期天23時40分與一座冰山擦撞前,已經收到6次海冰警告,但當瞭望員看到冰山時,該船的行駛速度正接近最高速。由于無法快速轉向,該船右舷側面遭受了一次撞擊,部分船體出現縫隙,使16個水密隔艙中的5個進水。泰坦尼克號的設計僅能夠承受4個水密隔艙進水,因此沉沒。
通過分析幸存者名單,本文發現,雖然最終幸存有一些運氣因素,但是的確有一些人比其他人更有可能幸存,比如婦女、兒童和上層階級。是否從上船伊始,生死已定?所謂“運氣”是否能夠在關鍵時刻決定生死?是否存在某些特征因素可預測或影響乘客的存活?
因此,本文通過建立LMT模型,運用機器學習算法Weka和Python對泰坦尼克號的幸存者數據進行特征工程分析,探究乘客特征因素對幸存率的影響,以期為后世沉船事件提供船舶安全管理實踐參考。
1 研究方法
1.1 數據挖掘算法
首先,通過定性分析對各屬性對預測變量的影響方向和程度進行初步判定,避免由于對屬性的不了解造成對數據處理時的主觀臆斷;同時進行初期特征工程,從難以處理的屬性(Name、Ticket、Cabin)著手,初步析出屬性并判定冗余變量,以便選擇算法后對數據進行再次處理和調參。
隨后進行定量分析,利用Pearson Correlation Heatma方法理清各屬性間的相關關系,生成特征相關圖,量化一個特征和另一個特征的相關程度,以進行冗余變量的剔除工作。同時,避免在模型融合的過程中,如將決策樹算法與Regression算法進行融合,造成由于 multicollinearity導致的測試集準確率低。
1.2 數據挖掘過程
選擇Weka-Classifier-Trees算法——Random Forest、LMT、J48、REP Tree四種算法,比較優劣。
基本思路:
(1)對數據進行分類再處理(共分六個dataset,參考之前對屬性的定性及定量分析;分析辦法:控制變量法)。
train_1: 本著Simplicity First原則,刪去屬性Name和Ticket。
train_2: Name分類原則①:按性別及年齡混合信息 [Mr.(包含Master., Jonkheer.等其他前綴), Miss.(Mlle.), Mrs. (Ms., Mme.)], (0, 1, 2); Age:取整體Mean對缺失值進行填充;Ticket:按length個數進行賦值;Fare: (0, 1-10, 10-20, 20-30, 30-40, 40-50, 50-60, 60-70, 70-80, 80-90, 90-100, 100-200, 200-300, 300-), (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13) 對處理過的人均票價再次進行分段。
train_3: Age:分段處理(0-1, 1-9, 10-19, 20-29, 30-39, 40-49, 50-59, 60-69, 70-79, 80-89), (0, 1, 2, 3, 4, 5, 6, 7, 8, 9),其余屬性處理方式同train_2,刪去Ticket,試析該屬性對模型擬合度影響;→結果:非常小,Remove屬性Ticket。該結果與定性分析設想基本一致,Ticket為冗余變量,其特征工程析出屬性基本涵蓋在Pclass(數字首位),Parch、SibSp(重復數值),Embarked(字母)中。
train_4: Cabin:(A, B, C, D, E, F, G, T), (1, 2, 3, 4, 5, 6, 7, 8)(不允許缺失值,將Cabin缺失值默認設為0),其余屬性處理方式同train_3。
train_5: Name分類原則②:按性別及社會地位混合信息 [Sir.(Capt., Don., Major., Col., Sir.), Lady. (Dona., Lady., the Countess.)], (3,4,5) ;Cabin按有無數據分類,(String,null), (1, 0) ;其余屬性處理方式同train_3。
train_6: Name分類原則②,Age分段,Cabin分段;其余屬性處理方式同train_3。
(2)用相關算法對進行特征分析后的數據進行擬合
2 數據分析
2.1 樣本數據
Titanic數據中共有兩個數據集——訓練集和測試集,其中訓練集共有12個屬性,891條樣例,測試集有11個屬性,418條樣例。表1給出屬性變量的介紹。
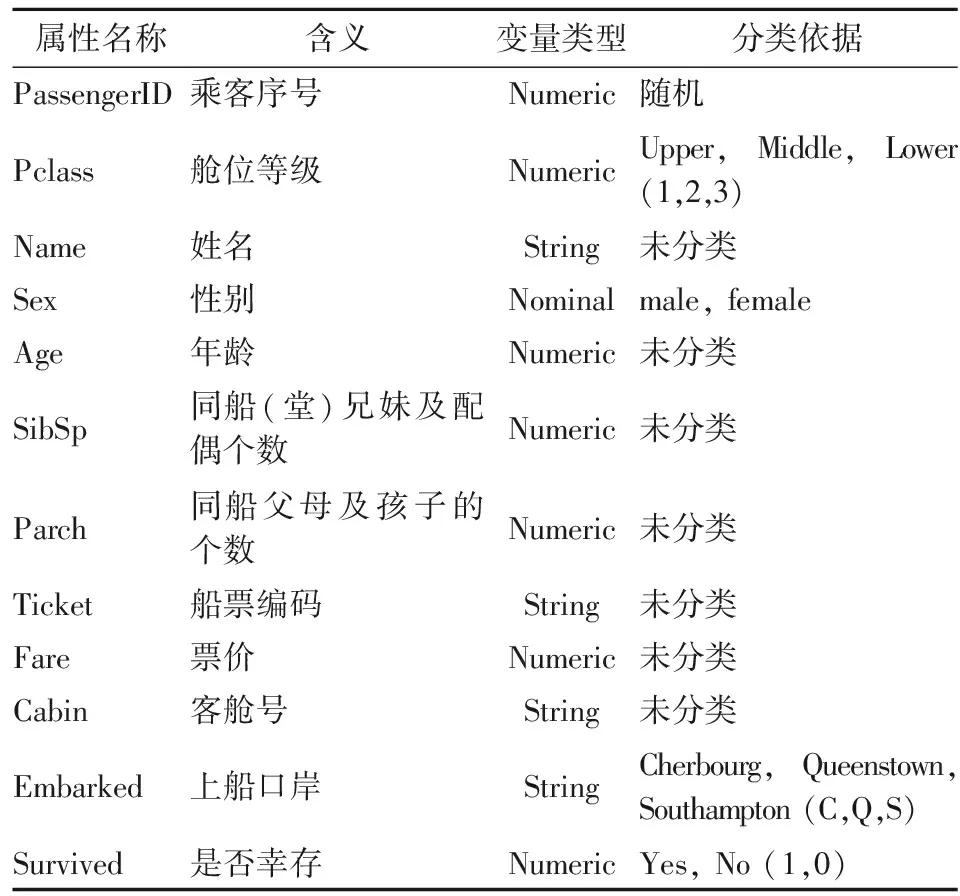
表1 屬性總覽
由于數據本身具有其含義,避免由于數據可能偶然的高度相關造成訓練集擬合度高、測試集準確性低,即模型未抓取重要特征造成預測結果的不準確,分別對具體屬性進行定性分析和定量分析。
2.2 定性分析
(1)Pclass。案例中已經將乘客的社會地位分為Upper、Middle、Lower三類,分別賦值為1、2、3。試分析屬性變量社會地位。1912年Titanic建造、下水、最終分崩離析究竟是在什么時代呢?20世紀初期,第二次工業革命進行得如火如荼,資本主義經濟高度發展,世界分工早已形成,社會拜金思想盛行,發展高度不平衡,貧富差距巨大。社會階層這一屬性,從金錢角度看,他們擁有更好的艙位(一等艙),在危機到來時能夠第一時刻預警逃生;從社會心理角度,逃難時,更易獲得尊重的地位或者更能給出的利益可能會使得他們有更大的概率獲得救生艇,得以存活。因而,Pclass應該和Survived高度相關。但需要注意的是,如需使用Linear Regression及其相關混合算法,應注意Pclass和Ticket、Fare、Cabin的相關性,避免因多重共線性造成的模型不準確。
(2)Name。從語言本身或詞源學角度而言,姓名包含極多信息,主要可以分為兩類。其一為性別和年齡的混合信息,通過前綴Mr.(男)、Mrs. (已婚女)、Miss.(未婚女),可以簡單判定性別和粗略的年齡信息。當樣例使用其他前綴(比如Rev.、Don.等),可以通過姓名單詞本身進行查詢,男女姓名在英文語境中有明顯差異,可通過單詞本身判定其性別;女性在婚后會冠以夫姓,其family name(姓)為男名還是女名可以得出婚姻狀況,從而簡單推斷出女性年齡。其二,通過Name中的前綴(prefix),可以劃分社會地位,prefix共有18類,具體信息如表2所示。
Name看似繁雜無從下手,實際根據prefix發現Name可以通過分類類別的信息增益方法來選取特征進行擬合,此步驟為初步預處理。為避免因為nominal變量過多導致使用算法產生分支過多,產生過擬合和過多剪枝步驟(unpruned)或者反復調節minNumObj(葉子節點個數),將類似屬性合并。經分類篩選,發現Name派生屬性可按照兩種分類方式,其一通過性別和年齡的混合信息如[Mr.(包含Master., Jonkheer.等其他前綴), Miss.(Mlle.), Mrs.( Ms., Mme.)], (0, 1, 2);其二通過社會地位和性別的混合信息如[Sir.(Capt., Don., Major., Col. ,Sir.), Lady.( Dona., Lady., the Countess.)], (3,4,5)。
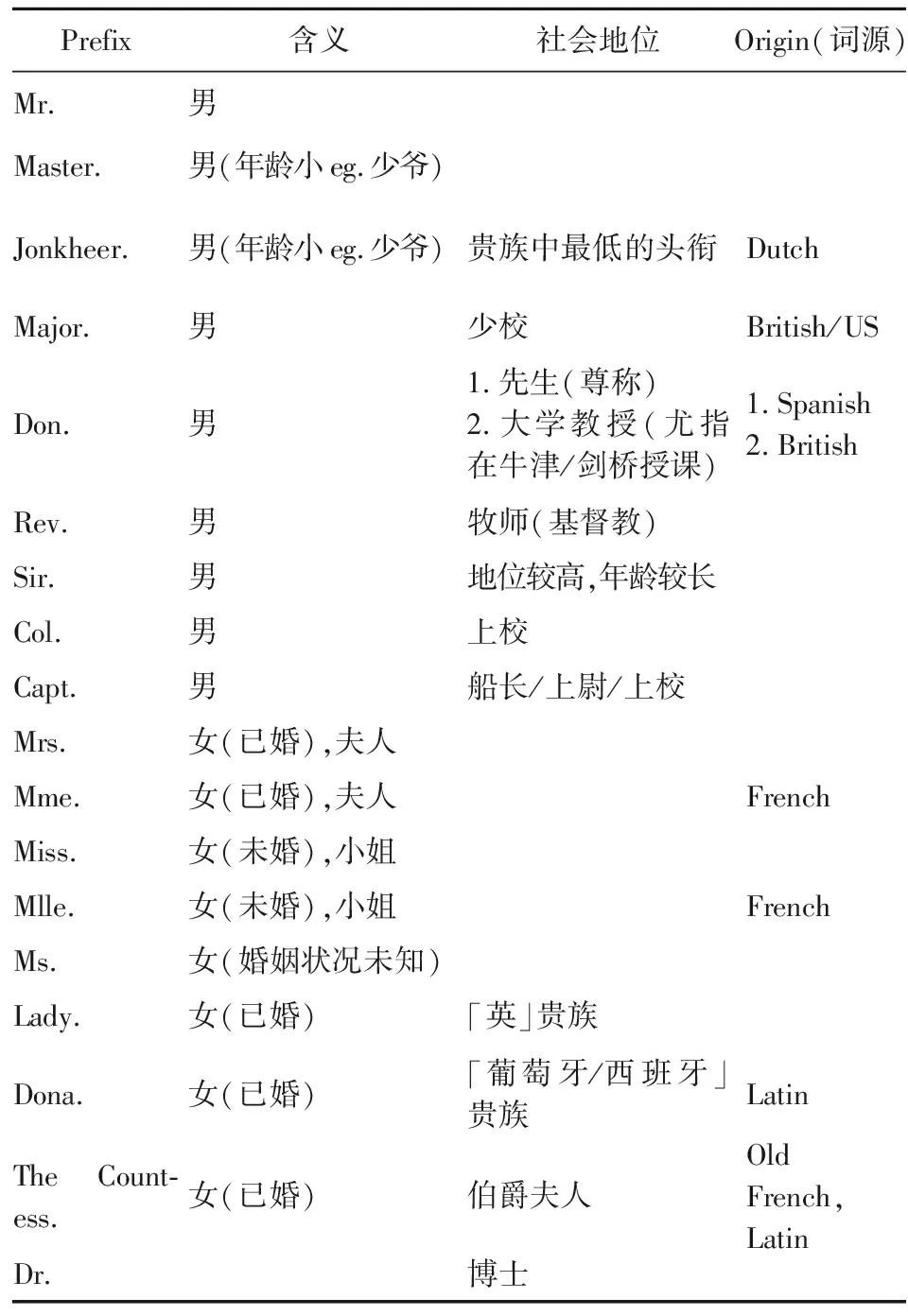
表2 Name屬性詳解
(3)Sex。在時代背景和西方一貫秉持的“女士優先”原則下,存活率定性來看顯然與性別高度相關,女性存活率應當顯著高于男性。
(4)Age。定性來看,由于先讓婦女和小孩逃生的觀念根植于西方傳統,年齡較小的孩子相較于其他存活率應較高,年齡較大的老人可能因為行動不便、反應問題、運動能力、身體機能等原因難以存活。
(5)SibSp。同船(堂)兄妹及配偶個數,由于事發時正值深夜,當同船有(堂)兄妹或配偶時,可以及時通知,互幫互助,一起逃生。但當親屬個數過多時,可能由于船艙位置距離、通知時間等顧此失彼,導致一起喪生,因而SibSp數值跟生存率有較大相關性,且開始為正相關,超過一定量時為顯著負相關。
(6)Parch。同船父母及孩子個數,由于孩子在逃生中優先,父母因為需要照顧孩子會得到更多的幫助和救援。而與SibSp屬性類似,如個數過多,常常適得其反。但需要注意的是,由于是將父母和孩子的個數一起統計,當成年人帶著父母時,由于需要照顧老年人,成年人可能存活率更低。因而,該屬性從定性方面對預測變量Survived的影響和其影響程度難以斷定。
(7)Ticket。船票編碼,String型變量,有全數值,也有字母和數字的組合集合。進一步對數據分析發現約25%的數據有前綴,前綴共45種,其中由于“,”和“/”兩種字符導致結果看似復雜。簡要列舉:SOTON/OQ,C.A.,非常明顯,以字母開頭的船票記錄的是地點,SOTON為Southampton英格蘭南安普頓(泰坦尼克號起航地),C.A.為California美國加利福尼亞州,綜合Embarked屬性信息和泰坦尼克號航線(從英國南安普敦出發,途經法國瑟堡-奧克特維爾以及愛爾蘭昆士敦,駛向美國紐約),字母簡稱代表的地點應為船票出售地,定性來說,跟預測變量Survived相關性不大。數字部分經過查詢現存文獻和歷史背景信息,經分析可知以1、2、3開頭的大多為一、二、三等艙,4~9開頭的大都為三等艙。
另外,值得注意的是,Ticket數字編碼中的部分數據完全相同,應為套票(如家庭票),通過統計分析可以了解家庭成員個數。由于析出屬性和Parch、SibSp高度一致,目前設想應為冗余變量。但在做定量分析之前,先將Ticket按照首位數字進行分類(1,2,3~9)賦值為(1,2,3)。
(8)Fare。票價,票價越高,艙位會更好(一等艙),擁有更好的時機及時收到訊息,同時擁有更多的資源如救生艇,因而應與預測變量Survived相關性高。但是需要注意的是,簡單處理發現Fare屬性標準差(StdDev)很大,接近56,均值和最大值值差也很大。結合對Ticket數據的分析,部分船票編碼數字數據有重復,結合Parch、SibSp屬性和和票價船艙等級,已知購買的票為套票(如家庭票),因而需將團體票的票價進行數據處理,得到人均票價,使得數據科學、合理。
(9)Cabin。數據為字母和數字的組合,圖1為艙位詳解。
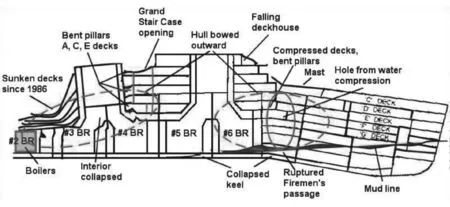
圖1 Titanic 艙位圖
從艙位可以分析出Pclass信息。除此之外,由于當災難發生時,冰山造成右舷船艏至船中部破裂,五間水密艙進水。因而Cabin數據能展現的相對甲板的位置對預測變量Survived也非常重要。如靠近冰山撞擊漏水處生還率更低,或旁邊是配電室的房間,由于漏水導致漏電使得住在配電室周圍的乘客身亡,難以幸存。但是,Cabin缺失值687個,缺失率高達77%,在應用某些不允許有缺失值的算法時應當注意處理。
(10)Embarked。上船口岸,分別為Cherbourg、Queenstown、Southampton (C,Q,S),泰坦尼克的航線為從英國南安普敦S出發,途經法國瑟堡奧克特維爾C以及愛爾蘭昆士敦Q,駛向美國紐約。圖2為主要航線圖。
由于泰坦尼克從S出發,途經C地、Q地,人們有選擇下船的機會,或者本身就不需要到終點站紐約,因而有很大的概率不經歷海難;在C地,人們只能選擇在Q地下船,或是到紐約;在Q地上船的乘客必定經歷海難,因而按照存活率從高到低排序應為:S>C>Q。
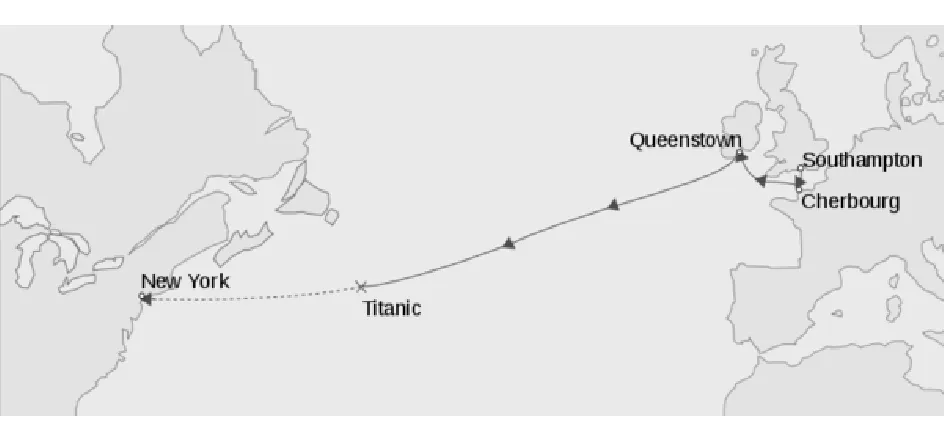
圖2 Titanic 航線圖
2.3 定量分析
總的概括一下數據特征,有缺失值、數據離散、部分屬性經過特征工程處理可析出信息,直觀的想法是利用決策樹模型,尤其是Random Forest,可自動填補缺失值,避免由于手動填補造成數據噪聲大。為了更好地運用多種算法比較優劣,進行皮爾孫相關熱圖(Pearson Correlation Heatma)分析,編程方式如下:將String數據類型轉化為float,處理變量Sex (male, female) (0,1); Name按照性別和年齡的混合信息分類 [Mr.(包含Master., Jonkheer.等其他前綴), Miss.(Mlle.), Mrs.( Ms., Mme.)], (0, 1, 2); Embarked:(S,C,Q) (0, 1,2)。
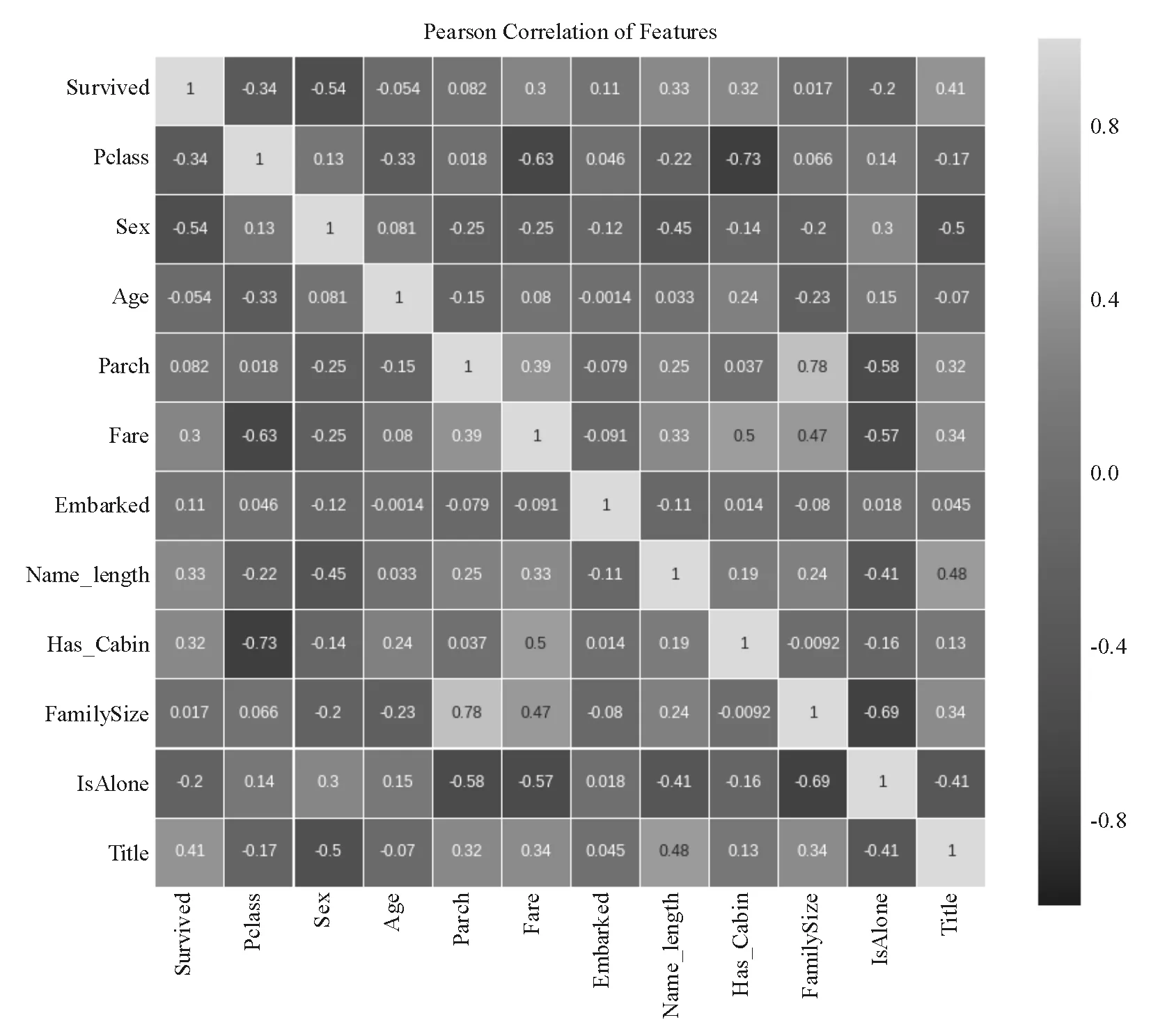
圖3 皮爾孫相關熱圖
從圖3皮爾孫相關熱圖中可看出沒有太多的特征高度相關。因此,該數據集中沒有太多冗余數據,每個屬性都相對較為獨立,用給出的屬性特征訓練模型使得模型更具有實踐意義。同時,可以看到不同屬性對預測變量Survived的相關系數,為進一步選擇算法、處理數據,創造了條件。
使用Seaborn,生成配對圖觀察特征的數據分布,發現屬性特征清晰,有利于模型擬合。
從該案例給出的數據出發,數據有缺失。其中:Embarked缺失量為2,缺失比例為0.22%;Age缺失量為177,缺失比例為19.87%;Cabin缺失量為687,缺失比例為77.10%;Embarked缺失量少,對模型擬合度影響不大;Age可以通過進一步分段求均值填補的方式手動填補;但是Cabin缺失量過多,人工填補可能造成數據噪聲大。因此,優先考慮適合離散型變量的Random Forest,可自動填補缺失值。但是為了比較算法優劣,在應用其他需補齊缺失值的算法時,將Cabin缺失值默認為0。
3 研究結果
測試基線精確度(baseline accuracy)即ZeroR最大可能性分類,準確率(Correctly Classified Instances)為61.62%。從準確率百分比來看,挑選的四種算法顯然表現不錯(遠高于基線精確度)。其中,綜合決策樹和Logistic的LMT表現相比其他算法好,準確率在6次擬合中相比其他三種算法都處于較高的位置;Random Forest由于較為適合案例數據,對缺失值處理較好,也有著不錯的表現。簡單來說,LMT六次擬合準確率均值最高為81.78,且標準差較小,為0.94。
考慮到過擬合問題,當訓練模型準確率很高時,可能由于過擬合使得模型未抓住特征屬性分析,導致測試集準確率低。根據Learning Curve判定模型所在狀態,選取train_3嘗試調節參數debug、minNumInstances,調節葉子節點樣例個數,發現調節參數時準確率普遍在82.72%左右,在默認值為15時,LMT模型達到準確率最優值83.28%。
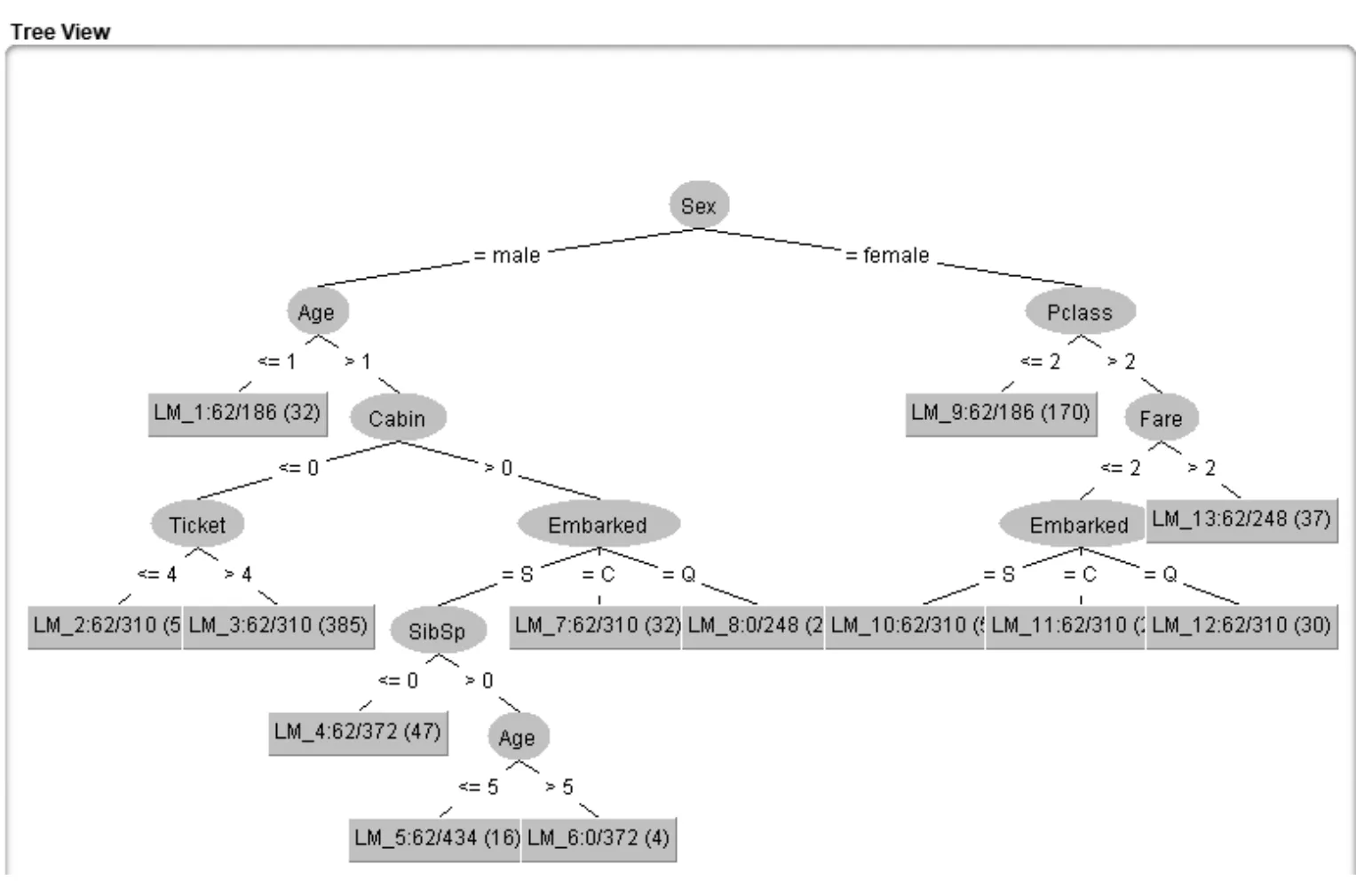
圖4 LMT模型可視化展示
綜合Kappa值為0.6354,MCC=0.641,ROC Area=0.864,PRC Area=0.858,該模型擬合度較好,Supplied Test Set得到準確率為85.65%。
通過Weka一級模型訓練,選用dataset train_3.、LMT算法,如圖4所示,模型擬合度最優。基于數據分析結果,分析得出:乘客在泰坦尼克海難中的幸存率與屬性Name、Sex、Pclass、Age、SibSp、Parch、Fare、Cabin、Embarked高度相關。總的來說,身份為貴族,且船艙遠離船體漏水位置,登船地點在Southampton的一等艙女性和小孩更容易成為幸存者,而這些因素實際上都是乘船者的客觀因素。
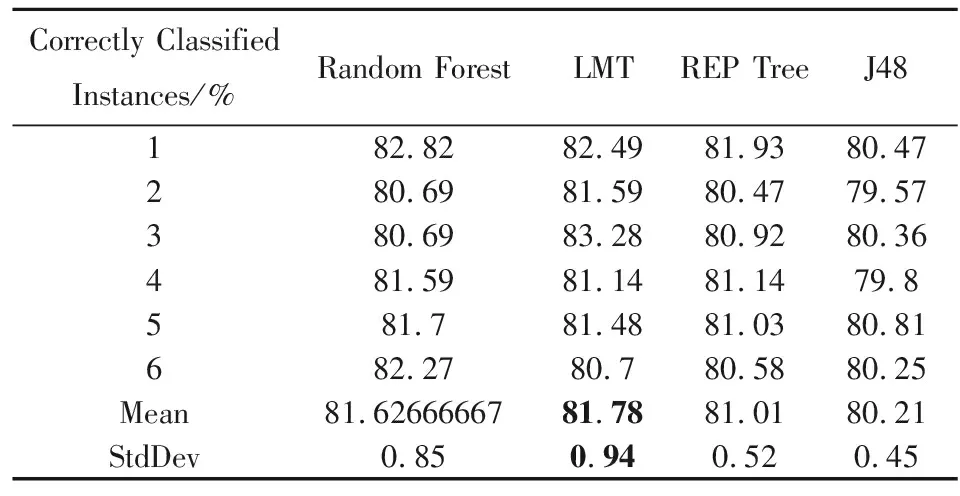
表3 算法的優度比較
4 結語
本文以泰坦尼克幸存者數據作為樣本,構建了LMT模型,從定性和定量兩個方面分析了乘客屬性對幸存可能性的影響。研究發現乘客在泰坦尼克海難中的幸存率與屬性Name、Sex、Pclass、Age、SibSp、Parch、Fare、Cabin、Embarked高度相關。模型擬合的準確率達到85.65%。換言之,基于LMT模型,如果該模型擬合度越低,船舶安全管理的可靠性應該越高,因為管理作為可變因素對幸存率造成了可觀的影響。本研究對于海難等類似案例和目前船舶安全管理有一定參考意義。在未來的研究中,可以加入客觀環境和管理情境,進一步探究影響海難事件中影響幸存率的因素。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
