遷移學習在食用油光譜模型轉移中的應用
2019-08-27 09:23:26劉翠玲周子彥李天瑞徐瑩瑩孫曉榮吳靜珠
食品科學技術學報 2019年4期
關鍵詞:模型
劉翠玲, 周子彥, 李天瑞, 徐瑩瑩, 孫曉榮, 吳靜珠
(北京工商大學 計算機與信息工程學院/北京市食品安全與大數據重點實驗室, 北京 100048)
在光譜測量中,會遇到模型失效問題,如利用一臺儀器上采集的數據(稱為源域數據)建立的校正模型,應用于另一臺儀器采集的數據(稱為目標域數據)上的預測結果有較大偏差,甚至無法使用,這極大地阻礙了光譜儀器的大規模應用,以及光譜現場快速檢測。有研究表明,可以采用模型轉移解決模型失效[1-2]。傳統的模型轉移方法有直接校正法(direct standardization,DS)[3-4]、分段直接校正法[5-6]、Shenk’s算法[7-8]、斜率偏差校正法[9-10]、典型相關性分析[11],這些算法的發展比較成熟,都得到廣泛應用。隨著現今分析技術在農業、石化、制藥行業的快速發展[12-14],光譜間的模型傳遞問題再次成為制約該技術發展的主要因素。由于傳遞光譜對象間經常出現吸光度偏差、波長偏移以及譜峰寬度不一致等問題,儀器間很可能存在非線性關系,需要新的模型轉移方法來更好地解決模型轉移中遇到的難題。近年來,計算機技術的快速發展,一些機器學習方法被用于解決這一問題。遷移學習是機器學習的一大分支,現階段遷移學習主要用于圖片、文本、語義等方面,在光譜方面的應用比較少,在光譜模型轉移方面的應用則更加稀少。例如Ntalampiras提出了一種遷移學習框架,利用鳥類對不同音樂類型的親和程度來識別鳥類的聲學相似度[15];岳學軍等[16]基于高光譜和深度遷移學習實現了柑橘葉片鉀素含量的精準預測;Hirtz等[17]利用遷移學習研究顱內電流對軀體感覺的影響。Durbha等[18]提出一種圖像信息挖掘(IIM)系統,主要使用遷移學習解決空間數據庫的標注問題。這些對于遷移學習的應用本質上都是挖掘分析不同形式數據的特征值并加以分析研究,尤其是圖像本質上就是數組的形式,這一點與光譜分析不謀而合,而且通過提取特征分析規避了不同光譜儀器間非線性的差異和光譜數據之間存在波長偏移等問題。本文嘗試應用遷移學習的方法用于近紅外光譜的模型轉移研究。
遷移學習有很多實現方法,其中數據分布自適應方法是最常用的一種方法。采用遷移學習中數據分布自適應方法,針對3組實驗儀器的近紅外光譜模型食用油理化指標(酸值、過氧化值),結合偏最小二乘法(partial least squares, PLS),建立定量分析模型,進行模型轉移研究。
1 原理及算法
數據分布自適應基本思想是:由于源域和目標域的數據概率分布不同,通過對源域和目標域數據進行一些變換,從而將源域和目標域的數據分布拉近,使得源域數據建立的模型也可以應用于目標域數據。
根據數據分布的性質,數據分布自適應方法又可以分為邊緣分布自適應、條件分布自適應以及聯合分布自適應。本文采取的是邊緣分布自適應方法,其目的是減小源域和目標域的邊緣概率分布距離,從而完成遷移學習。從形式上來說,邊緣分布自適應方法是用源域數據概率分布P(Xs)和目標域數據概率分布P(Xt)之間的距離來近似兩個領域之間的差異。實現邊緣分布自適應方法的名稱是遷移學習成分分析(transfer component analysis,TCA)。
文中設計的遷移算法模型轉移流程如圖1,該程序運行于Windows系統下,編寫軟件為Matlab 2016b版本。

圖1 遷移算法模型轉移流程Fig.1 Transfer flow chart of migration algorithm model
2 實驗方案及光譜采集
2.1 實驗儀器與方法
傅里葉紅外光譜儀VERTEX70(簡稱V70),Bruker公司;傅里葉近紅外光譜儀Antaris Ⅱ(簡稱A Ⅱ),Thermo Scientific公司。技術參數如表1。

表1 光譜檢測儀器的指標參數
實驗包括3組,第1組以Antaris Ⅱ近紅外光譜儀(利用透射探頭)采集的數據為源域數據,Antaris Ⅱ近紅外光譜儀(利用光纖探頭)采集的數據為目標域數據;第2組以VERTEX70紅外光譜儀采集的數據為源域數據, Antaris Ⅱ近紅外光譜儀(利用光纖探頭)采集的數據為目標域數據;第3組以Antaris Ⅱ近紅外光譜儀(利用透射探頭)采集的數據為源域數據,以VERTEX70紅外光譜儀采集的數據為目標域數據。
2臺儀器的具體參數設置:分辨率為16 cm-1;樣本掃描次數為32次;背景掃描次數為32次;光譜的采集范圍為12 000~4 000 cm-1;光闌設置6 mm;掃描速度10 kHz。
調查發現食用油的特征譜區分布在5 000~5 500 cm-1,但為了避免光譜信息的丟失,本次實驗利用的是5 000~9 000 cm-1的光譜數據,共520個波數點,兩種儀器采集的50個食用油樣本的近紅外譜圖如圖2。

圖2 食用油近紅外光譜圖Fig.2 Near-infrared spectrum of edible oil
2.2 模型傳遞評價參數
模型的評價參數選擇相關系數(correlation coefficient of cross-validation,R2),預測均方根誤差(root mean square error of prediction,RMSEP)。R2越大表明光譜信息與分析組分的相關性越好,RMSEP越小,表明預測性能越好,模型傳遞的效果越好。

圖3 食用油酸值模型轉移前的預測結果Fig.3 Predicted results of acid value model before transfer
3 實驗與分析
3.1 預處理
原始光譜包含50條樣本光譜,每條光譜包含520個數據點,其中包含了大量的無用信息,故提前使用主成分分析(Principal component analysis,PCA)處理原始光譜數據。經過PCA處理后,原本每條光譜的520個數據點僅留存49個數據點,其余數據點貢獻度為0,故處理后的每條光譜數據包含49個光譜點。
3.2 食用油酸值模型轉移結果與分析
3.2.1酸值無模型轉移前建模結果
將源域數據和目標域數據以同樣的分布策略劃分為建模集和預測集,其中建模集包含40個樣本,預測集包含10個樣本。
利用源域數據的建模集,結合PLS算法建立校正模型,利用該模型驗證源域數據的預測集樣本。再利用該模型驗證目標域數據的預測集樣本,3組實驗結果如圖3。
3.2.2酸值模型轉移后建模結果
將源域數據和目標域數據通過遷移學習TCA算法使其具有相似的分布,核函數選擇線性核函數。將經過變換后的源域數據和目標域數據以轉移前同樣的分布策略劃分為建模集和預測集。
再利用源域的40個建模集樣本數據,結合PLS算法建立校正模型,利用該模型預測源域的10個預測集樣本數據。再利用該模型預測目標域的10個預測集樣本數據,3組實驗結果如圖4。

圖4 食用油酸值模型轉移后的預測結果Fig.4 Prediction results of acid value model after transfer
3.2.3實驗結果說明
在遷移學習轉移前,由于不同儀器之間、同一儀器不同光譜探頭之間存在很大的硬件差異和環境差異,由這些差異而導致的光譜數據的不同,使得一種儀器采集的光譜數據所建立的模型不能直接用于預測另一種儀器采集的光譜數據。但是經過遷移學習轉移后3組實驗的預測結果有了很大程度的改善,其中R2的數值顯著提升,而RMSEP的數值顯著下降。綜合兩個模型參數,說明經過遷移學習后,食用油的酸值定量模型預測的準確性和模型回歸的表現均優于遷移學習前的模型。統計實驗結果如表2。根據同樣的數據,采用直接校正法進行模型轉移,得到經過模型轉移后的結果如表3。
由表2、表3數據可知,遷移學習較DS算法有一定的優勢,但效果不明顯。經過分析,主要原因是進行掃描所用儀器的分辨率參數均為16 cm-1,導致得到的樣本光譜數據沒有出現明顯的波長偏移現象,傳統的模型轉移算法仍然有一定的優勢。然而,在實際的操作中,不同儀器采集的光譜數據普遍存在比較明顯的波長偏移現象,遷移學習在模型轉移中的優勢將進一步擴大。次要原因是樣本的個數偏少,影響模型穩定性。

表2 遷移學習前后酸值建模結果統計

表3 DS運算后酸值建模結果統計
3.3 食用油過氧化值模型轉移結果與分析
3.3.1過氧化值無模型轉移前建模結果
將源域數據和目標域數據以同樣的分布策略劃分為建模集和預測集,其中建模集包含40個樣本,預測集包含10個樣本。
利用源域數據的建模集,結合PLS算法建立校正模型,利用該模型驗證源域數據的預測集樣本。再利用該模型驗證目標域數據的預測集樣本,3組實驗結果如圖5。

圖5 食用油過氧化值模型轉移前的預測結果Fig.5 Predicted results of model of edible oil peroxide value before transfer
3.3.2過氧化值模型轉移后建模結果
TCA算法的設置和結果與酸值模型轉移實驗相同。利用源域的40個建模集樣本數據,結合PLS算法建立校正模型,利用該模型預測源域的10個預測集樣本數據。再利用該模型預測目標域的10個預測集樣本數據,3組實驗結果如圖6,統計實驗結果如表4。
由表4可知,經過遷移學習轉移后3組實驗的預測結果有了很大程度的改善,其中R2的數值顯著提升,而RMSEP的數值顯著下降。綜合兩個模型參數,說明經過遷移學習后,食用油的過氧化值定量模型預測的準確性和模型回歸的表現均優于遷移學習前的模型。根據同樣的數據,采用直接校正法DS進行模型轉移,得到經過模型轉移后的結果如表5。
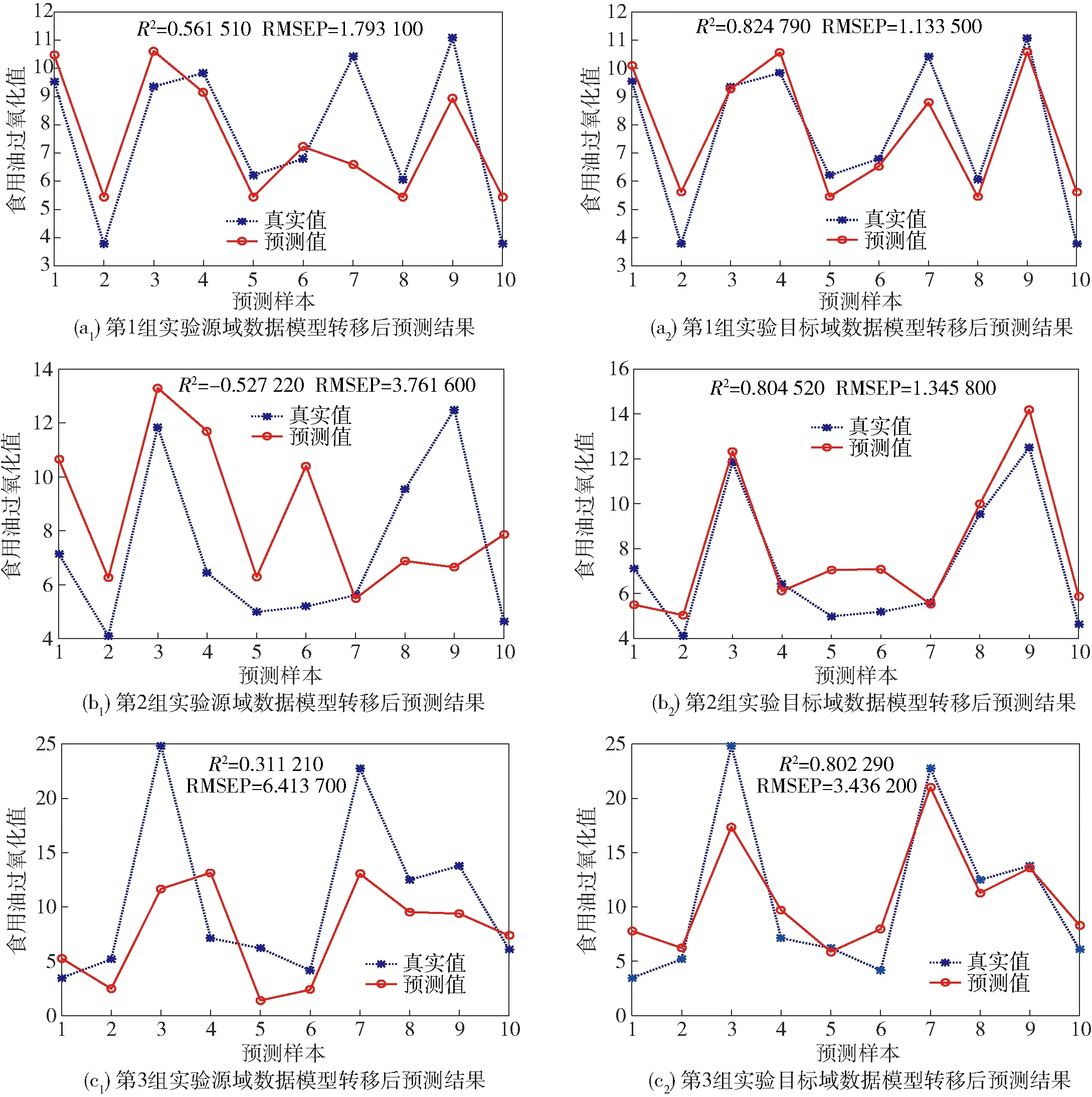
圖6 食用油過氧化值模型轉移后的預測結果Fig.6 Predicted results of model of edible oil peroxide value after transfer

實驗組遷移學習前模型參數R2遷移學習前模型參數RMSEP遷移學習后模型參數R2遷移學習后模型參數RMSEP主機:A Ⅱ(透射)從機:A Ⅱ(光纖)-0.2589803.0384000.8247901.133500主機:VERTEX 70從機:A Ⅱ(光纖)-0.5097003.7400000.8045201.345800主機:A Ⅱ(透射)從機:VERTEX 70-0.0319707.8505000.8022903.436200

表5 DS運算后過氧化值建模結果統計
由表5數據可知,DS算法與遷移學習在過氧化值的建模結果基本與酸值建模結果一致。
4 結 論
研究表明,經過遷移學習算法轉移后,模型預測結果都有了不同程度的改善。隨著光譜檢測儀器的不斷發展,針對每一種每一臺儀器去建立相應樣本的模型顯然是不現實的,實驗驗證了遷移學習的確可以在一定程度上解決模型轉移的問題,是一個比較可行的解決方案。但是,在本次實驗中,遷移學習算法轉移后的模型預測結果與理想結果仍存在一定的差距。產生差距的原因:一方面可能是由于樣本的個數及種類仍然不夠豐富,使模型結果不具備確實的可靠性;另一方面遷移學習的具體實施辦法有很多角度,不同的實施辦法可能適用于不同種類的樣本。綜上,下一步將從增加食用油樣本的種類和數量,以及嘗試其他遷移學習方法兩個角度進行進一步的實驗研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
