基于深度卷積神經網絡的高分辨率遙感影像場景分類
2019-08-07 02:04:36孟慶祥
測繪通報 2019年7期
孟慶祥,吳 玄
(武漢大學遙感信息工程學院,湖北 武漢 430072)
隨著高分辨率遙感衛星的迅速發展,高分影像商業用途越來越廣。高分影像具有分辨率高、信息量大、細節特征豐富等優點,傳統的影像解譯方法很難有效地從高分影像上提取知識。如今高分影像信息提取已逐步從基于像元、紋理的解譯向面向對象、語義識別和場景理解的方向發展[1]。因此,研究高層次特征的抽象方法成為高分影像理解的一個重要方向。
場景分類的關鍵是圖像特征的提取。目前,場景分類方法大致可分為3類:基于紋理、顏色特征等低層特征的場景分類,基于中層語義特征的場景分類和基于高層視覺信息的深度網絡模型場景分類[2]。文獻[3]提出了空間包絡面的方法,不用對整幅圖像進行分割,使用多維低層次特征組合,實現了對自然場景的分類。文獻[4]提出了一種高效的區域檢測算法,使用SIFT特征對局部特征進行描述,由于SIFT特征對旋轉、尺度縮放、亮度變化等均保持不變性,因此被廣泛地運用到場景分類中。文獻[5]將視覺詞包方法引入到場景分類的研究中,首先對SIFT、Gist特征進行提取,并用K-means聚類方法進行聚類形成視覺詞包,最后使用支持向量機分類器進行訓練,取得了良好的分類效果。
近年來,深度學習在圖像領域得到了廣泛的運用[6-7]。文獻[8]使用基于卷積神經網絡的模型Alex-net,利用多層卷積提取特征,利用全連接層融合特征,利用Dropout層提高網絡的泛化能力,防止模型的過擬合。該模型有效地實現了圖像分類,比支持向量機算法精度提高了15%。由于卷積神經網絡在圖像識別領域上的出色表現,越來越多的學者將其運用到高分影像的場景分類中。文獻[9]利用多層感知機分類器對影像進行場景分類,但是網絡過淺,無法學習到高層特征。文獻[10]提出了一種卷積神經網絡和支持向量機組合模型,分類精度雖然有所提升,但是未解決過擬合問題。為了解決過擬合問題,文獻[11]使用了遷移學習的方法,利用ImageNet比賽的預訓練模型Inception-v3提取特征,最后用單層全連接層進行分類輸出。該網絡雖然在一定程度上提高了模型的泛化能力,但是只用單層全連接并未從根本上解決網絡的過擬合問題。因此,本文提出一種基于深度卷積神經網絡(deep convolution neural network,DCNN)的高分影像分類模型,通過鏡像、旋轉、亮度變化等方法對數據集進行增廣,利用正則化和drought[12-13]層調整模型參數,運用卷積神經網絡實現對高分影像進行分類。
1 原理和方法
誤差的反向傳播是深度學習的基礎,深度網絡通過反向傳播求解梯度,根據梯度進行學習得到模型,利用模型完成分類任務。卷積神經網絡是目前圖像處理領域使用最多的模型,該網絡能夠自動提取出高層語義特征。
1.1 卷積神經網絡
卷積神經網絡模型是一種基于反向傳播的模型,主要用于圖像識別領域。遙感影像也是一種圖像,影像場景可以看作是不同語義特征的組合,如住宅可以看作是房屋、道路、樹木的組合。這些語義特征具有不同的紋理和結構信息,而卷積神經網絡的優點恰好是對特征的提取。卷積神經網絡一般可以分為4層(如圖1所示):①卷積層:卷積層通過卷積核提取特征。卷積核不斷在輸入影像上滑動進行局部感知,計算出下一層的特征圖。假設輸入的是w×w×d圖像,其中w是影像尺寸,d代表通道數,利用一個尺寸為r×r×d的卷積核在圖像上滑動,如不用全0填充,最后得到的是一個大小為[(w-r+1)/s]×[(w-r+1)/s]的特征圖,其中s是滑動步長。②池化層:池化層的作用是將卷積層得到的特征圖進行過濾。假設用2×2的過濾器,以2為步長對特征圖進行過濾,最后得到原圖1/4大小的特征圖。通過以上的操作,可以使網絡參數大大減少,池化后的特征維度的下降也很好地避免了過擬合的問題。③激活函數[14]:當網絡通過多個卷積和池化層疊加后,其本質上是矩陣的相乘,因此構成的還是線性模型。激活函數引入了非線性因素,使模型能夠解決更為復雜的問題。常用的激活函數包括Sigmoid、Tanh、Relu等,本文采用Relu函數。④全連接層:卷積層和池化層都是對圖像局部特征的提取,而全連接層則是對特征的高度綜合,方便將結果交給最后的分類器。一般最后一層全連接輸出維數是分類的類別數,對應概率最大的即為最后結果。
1.2 基于DCNN的場景分類
1.2.1 DCNN的網絡結構
本文使用的DCNN模型共計8層,如圖2所示,其中5層卷積層,3層全連接層。卷積層包括4個階段:卷積、池化、激活和局部歸一化響應。卷積階段采用3×3的卷積核和1的步長對影像進行特征提取,由于使用了全0填充,卷積所得到的特征圖大小不會變化。池化階段使用2×2的過濾器,以2為步長對特征圖進行過濾,得到1/4大小的過濾特征圖。激活階段使用Relu(rectified linear unit)函數對過濾特征圖進行激活,加快訓練的收斂速度,縮短模型的訓練時間,并將模型變為非線性模型。局部歸一化響應階段作用是使反饋較大的神經元反饋更大,并抑制反饋較小的神經元,提高模型的泛化能力。全連接層將卷積層提取到的特征拉成一個一維向量,以便將分類結果交給最后的分類器。這里以3×3的卷積核闡述模型運行過程,輸入影像大小為256×256×3,經過第1層3×3×3×16卷積核后(前兩個3代表卷積核尺寸,第3個3表示3通道,16表示下一層輸入通道),大小變為256×256×16,經過池化后,大小變為128×128×16。第2層卷積核為3×3×16×32,經過池化后,特征圖再次縮小,變為64×64×32。前5層卷積層重復以上操作,最后得到大小為8×8×256的特征圖。第1層全連接將8×8×256的特征圖拉成一個16 384維的向量,輸出一個4096的向量,如此重復,最后得到一個與類別維數相同的向量,最后將其輸入到Softmax分類器,得到最終的分類結果。
1.2.2 激活函數、Dropout和正則化
Relu函數的公式如式(1)所示,當輸入值非負時,Relu函數返回原值,當輸入值為負時,返回0。相比于Sigmoid、Tanh激活函數,Relu函數免去了復雜的計算量,并且對其求導時Relu函數大于0的部分導數恒為1,而Sigmoid、Tanh函數導數會逐漸趨近于0。因此Relu函數能夠有效地避免梯度消失的現象,并且大幅度提高了模型收斂速度。
Relu(x)=max(0,x)
(1)
在每個全連接層后,筆者都加入了Dropout函數,Dropout函數能夠隨機刪除網絡中的一些隱藏神經元,將修改后的網絡進行前向傳播和反向傳播,如此反復迭代,可以有效地避免過擬合問題。
關于大學生創業及相關問題,從中國知網檢索的文獻梳理來看,學術界已進行了大量探索并取得了一定的研究成果。但是,以“大學生返鄉就業創業”視角所做的研究顯得不足,特別是如何構建促進大學生返鄉就業創業的社會支持體系的研究更為匱乏。基于此,本文在前人研究的基礎上,嘗試厘清大學生返鄉就業創業社會支持要素的內涵及外延,并著重探討社會支持要素在大學生返鄉就業創業過程中的作用發揮情況。
在損失函數中,筆者加入了正則化。正則化是在損失函數的基礎上加入正則項,其作用是在參數數量不變的情況下,減小某些參數的值,從而解決數據的噪聲問題。
1.2.3 數據增廣
本文使用了6種算法對數據進行增廣,分別是水平鏡像變換、轉置變換、隨機亮度變換、隨機對比度變換、隨機色相變換和隨機飽和度變換。
(1) 水平鏡像變換算法公式為
f(x1,y1)=f(w-x0,y0)
(2)
式中,(x1,y1)為變換后圖像像素坐標;(x0,y0)為變化前圖像像素坐標;w為圖像寬度。
(2) 轉置變換算法公式為
f(x1,y1)=f(y0,x0)
(3)
式中,(x1,y1)為變換后圖像像素坐標;(x0,y0)為變化前圖像像素坐標。
2 結果與討論
2.1 數據集
UC Merced-21數據集一共21類場景,每類100張,共計2100張影像,每張影像大小為256×256。此數據集相同類間差距大,不同類間相似性高,可用于場景分類。由于數據集每類影像較少,為了提高模型的泛化能力,使用了數據增廣,擴充后每類影像700張,其中600張作為訓練數據,100張作為測試數據。具體類別如圖3所示。
本文對UC Merced-21數據集進行了鏡像變換、轉置變換、亮度變換、對比度變換、色相調整及飽和度調整,調整后的結果如圖4所示。
2.2 結果分析
本文在UC Merced-21數據集上進行了試驗。表1描述了3個尺寸卷積核在21類數據集上的分類精度。從表1中可以看出,本文模型在機場、沙灘、灌木叢、密集住宅、林地、高速公路、高爾夫球場、海港、交叉口、中等住宅、立交橋、停車場、鐵路、稀疏住宅14個類別取得了很好的分類效果,平均精度為95.36%,在其余的7個類別中表現一般,平均精度為83.29%。
表2為21類場景的混淆矩陣。從表2中可看出,每種類別都有一種以上的類別干擾分類結果,這些類別由于紋理、顏色等特征存在一定的相似性,如網球場與高爾夫球場、農田與灌木、棒球場與高爾夫球場、建筑物與密集住宅等,因此最終分類精度受到了一定的影響。而對于一些有明顯特征的場景,如機場、港口、灌木叢、鐵路等都有很高的識別度。
2.3 結果討論
傳統方法一般由紋理和顏色等特征描述場景,然而這些低階特征無法描述復雜的大型數據集。經過國內外學者的探索,原本用于描述文檔的視覺詞袋方法被引入場景分類,這種方法使用中層語義特征建模,將特征抽象成對象,使用對象來描述場景能夠有效地提高分類精度[15-16]。深度學習興起后,學者們發現卷積神經網絡在圖像識別與分類中表現卓越,于是各種不同的模型被用到場景分類,分類精度在不斷提高。本文將DCNN方法與其他文獻在UC Merced-21數據集上的分類精度與方法進行了對比,對比結果見表3。
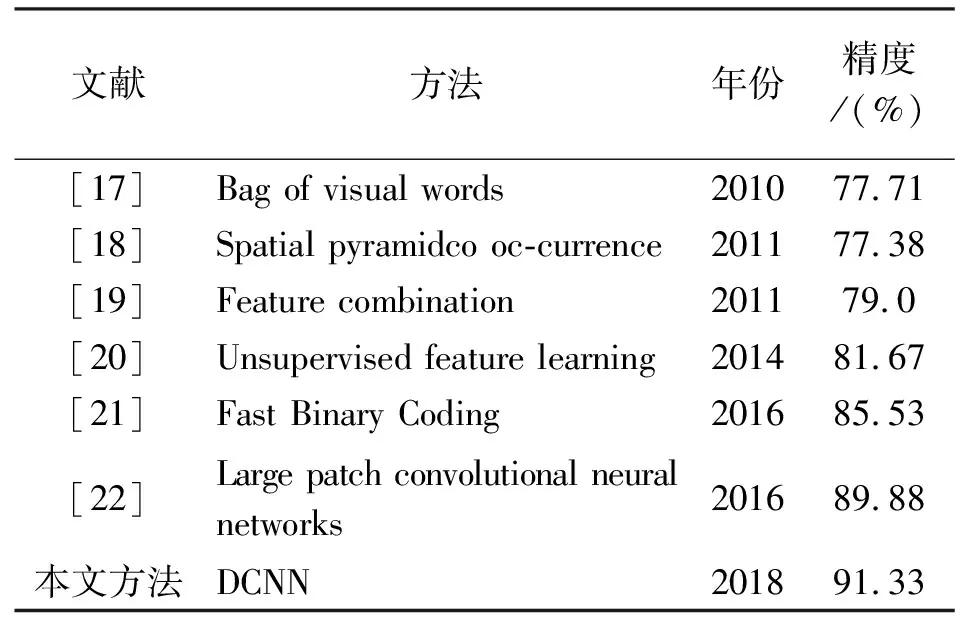
表3 各種方法分類精度
3 結 語
本文利用深度卷積網絡對UC Merced-21數據集進行場景分類,對數據不足的數據集進行了數據增廣,并采用正則化和Dropout算法解決了深度學習模型的過擬合問題。從試驗結果可以看出,深度卷積神經網絡可以有效地對高分影像進行場景分類,并且其分類精度要優于傳統算法。同時,筆者發現不同尺寸的卷積核對于不同類別場景有一定影響,選取合適的卷積核尺寸可以有效地提高分類精度。場景分類是遙感影像處理的方向之一,利用深度學習模型對遙感影像進行處理是將來研究的熱點。本文驗證了深度學習模型在影像場景分類任務中的有效性,下一步會將深度卷積神經網絡運用到中高分辨率影像的分類。但是,深度的卷積網絡參數較多,結構復雜,訓練時間過長,如何進一步提高特征提取效率,也是未來研究的重點之一。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
