連續漢語語音切分技術研究?
2019-07-31 09:54:46曹冠彬張二華王凱龍
計算機與數字工程 2019年7期
關鍵詞:檢測
曹冠彬 張二華 王凱龍
(南京理工大學計算機科學與工程學院 南京 210094)
1 引言
漢字為單音節[1],語音切分技術就是將一段連續完整的語音,切分為一個個獨立的音節。在連續語音識別系統中,不可能對整個短語進行訓練和識別,因為詞組或者短語的數量太大,必須將輸入的語音流切分為更小的組成部分如單個字或詞。
現有的連續語音自動切分技術雖然能實現對連續語音的切分,但大多存在穩定性差,易受噪聲影響等缺點,例如基于時域參數或者頻域參數的切分方法[2~6]存在穩定性差、易受環境噪聲影響等缺點;基于模型的切分方法,如基于隱馬爾可夫模型的切分方法[7~8]需要進行模型訓練,訓練時需要輸入人工切分好的數據,不易實現自動切分。本文結合聲學、語音學、語言學、信號處理和圖像處理等知識,研究了漢語語音的多級切分方法,利用相干分析、多尺度分析和基音周期軌跡檢測等技術實現了漢語連續語音切分。
2 語音切分技術基礎
2.1 時域特征分析
對于語音信號x(m),短時能量的定義如下:

其中,En表示第n幀語音信號的短時能量,N代表每幀語音包含的采樣點數。
短時平均過零率是指語音信號波形穿過時間軸的次數。為了減少隨機信道噪聲影響,將過零率修改為跨過正負門限T和-T的次數,如式(2)所示。

2.2 頻域特征分析
2.2.1 語譜圖
語譜圖[9]反映語音的時頻特性,語譜圖的橫軸表示時間(幀序號),縱軸表示語音信號的頻率。語譜圖中像素點顏色深表示該點的語音能量較強。語譜圖的繪制步驟如下:
1)對語音信號進行預處理,再根據式(3)求快速傅里葉變換。
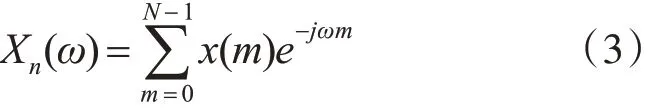
2)根據式(4)將Xn(ω)轉換為振幅譜,R 表示Xn(ω)的實部,I表示Xn(ω)的虛部。

3)將振幅轉換為灰度圖像數據。振幅越大,像素點的灰度越深;反之越淺。
4)繪制語譜圖,因為實數的振幅譜為偶函數,關于中心對稱,所以繪制語譜圖時只需在每一幀的起始點位置的垂直方向上繪出前一半的點即可。
2.2.2 繪制基音周期軌跡
發音過程中伴有聲帶振動的音稱為濁音;不伴有聲帶振動的音稱為清音。基音周期是指發濁音時聲帶振動頻率的倒數。基音周期軌跡的繪制步驟如下。
1)對語音信號進行預處理,根據式(3)求其頻譜,再求對數振幅譜lnH(ω)。再對對數振幅譜進行一次逆傅里葉變換得到倒譜,倒譜的計算公式如式(5):
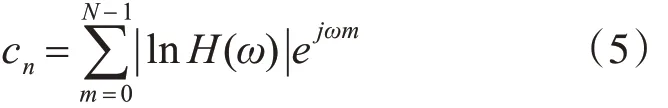
2)將倒譜數據從小到大排序,對前50%數據進行低截止置為1,對高位1%倒譜數據進行高截止置為0,取余下49%的數據的最小值h1和最大值h2,利用式(6)設置閾值T 將這49%的倒譜數據二值化,大于T置為0,小于等于T置為1。
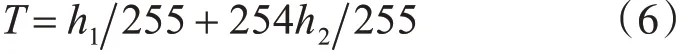
3)與語譜圖類似,在每一幀的起始點位置的垂直方向上繪出前一半的點。
3 傳統語音切分技術
3.1 雙門限端點檢測技術
雙門限端點檢測技術[10~12]的基本思想就是利用短時能量和短時平均過零率這兩個時域特征參數對語音信號進行切分。先統計濁音部分的短時能量,設定一個較高的門限參數EH,使得語音信號的能量包絡大部分都在此門限之上,根據背景噪聲能量確定一個較低的閾值參數EL;再統計清音和無聲段的短時平均過零率,確定短時平均過零率門限ZS。雙門限端點檢測技術的步驟如下:
1)對語音信號進行預處理,求語音信號的短時能量E和短時平均過零率Z。
2)尋找符合E>EH的語音段記為N1N2,N1、N2表示初判語音段的起始和終止位置。
3)從N1往左搜索,尋找E>EL的語音段,確定左側的起始位置N3;同理確定右側的終止位置N4。
4)從N3往左和N4往右搜索,找到Z>ZS的語音段,確定新的起始點N5和終止點N6,N5N6就是檢測到的語音段。
3.2 基于倒譜的端點檢測技術
基于倒譜的端點檢測技術[13~14]就是利用語音信號倒譜中的最大波峰的倒譜值與次大波峰的倒譜值的比值確定語音信號是否為元音段。基于倒譜的端點檢測算法的步驟如下:
1)對語音信號進行預處理。
2)通過短時傅里葉變換獲得短時譜Xn(ω),對頻譜的模取對數再求其傅里葉逆變換得到倒譜c(n)。
3)計算最大波峰倒譜值與次大波峰倒譜值的比值,確定該幀是否為元音段,本文的閾值設定為2.25。當比值大于等于設定的閾值時認為該幀為元音幀。
3.3 基于雙門限和倒譜的綜合端點檢測技術
本文將雙門限端點檢測技術和基于倒譜的端點檢測技術相結合,對連續漢語語音進行切分。具體步驟如下:
1)對語音信號進行雙門限端點檢測。
2)再用基于倒譜的端點檢測技術對元音段進行檢測。
3)從1)的結果中先選出一段有聲段,尋找有聲段的起始和結束幀之間是否含有元音段,元音段的結束位置可以作為切分依據。
從圖1(a)可以看出對于含輔音的連續漢語音節,結合雙門限和倒譜端點檢測技術能實現準確的切分結果;但是對于不含明顯輔音音節的連續漢語音節,該方法仍然不能實現準確的切分,如圖1(b),“師恩難忘”被分成了“師”和“恩難忘”兩個部分。
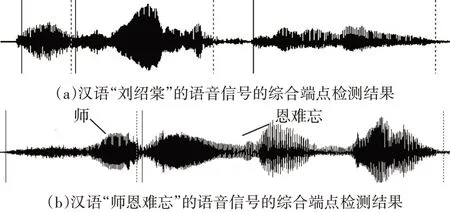
圖1 基于雙門限和倒譜的綜合端點檢測結果示例
4 漢語連續語音的多級切分算法
4.1 多級切分基礎
4.1.1 相干分析
共振峰指的是聲腔的共鳴頻率,對相同音節的漢字,其共振峰較穩定或者緩慢變化,語譜圖較相似。當語義發生變化時,漢字的共振峰也會發生變化,這種變化從語譜圖上可以明顯看出,例如從圖2 可以看出相鄰兩個漢字的語譜圖在界限處有明顯的變化。在觀察大量的語譜圖后,發現在相鄰兩個不同語義的語音段之間,其語譜圖在兩個字的界限處會呈現明顯的不相似。可以利用這種明顯的不相似性來檢測漢字音節的分界線。
相干分析法是計算數據相似性的一種方法。Gersztenkon[15]提出了一個基于協方差矩陣特征值的方法,具有抗噪能力強,分辨率高的優點。相干分析的步驟如下:
1)對于m×n維矩陣A,求其n維協方差矩陣B。2)求協方差矩陣B的特征值λ1、λ2…λn。
3)根據式(7)計算相干系數,k 值越大,表示數據越不相似。
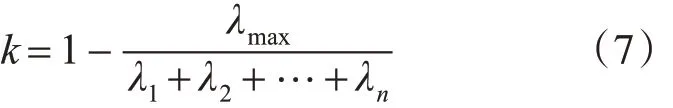
對語譜圖進行相干分析的步驟如下:
1)繪制語音信號的語譜圖,獲取語譜圖的灰度值矩陣。
2)獲取語譜圖的灰度值矩陣后選擇m×n 大小的窗口進行相干分析,m 表示每一幀選擇m 個頻譜樣點數據,n表示幀數。求該窗口數據的相干系數λ。
3)將窗口右移一幀,求當前窗口的相干系數。依次計算,直到窗口到達語譜圖的最右端。
4)將(J-n+1)個相干系數中相鄰的系數連接起來得到相干系數曲線。
從圖2 可以看出在兩個元音的分界處相干系數較高。在相鄰字的語譜圖的界限處,相干系數有時出現明顯的極大峰值,可以作為切分的依據。圖2 顯示在圖1(b)的結果上加入相干分析后的端點檢測結果,明顯看出將“師恩難忘”四個字的語音信號分成了四個獨立的音節。

圖2 漢語“師恩難忘”的相干系數曲線和切分結果
4.1.2 多尺度分析
語譜圖上,語音信號的共振峰特征在不同頻率范圍內的分布是不均勻的,導致提取特征信息的最佳位置不一致,因此需要用多個初始位置不同或者大小不同的窗口來進行相干分析,以便適應不同頻率范圍的變化。
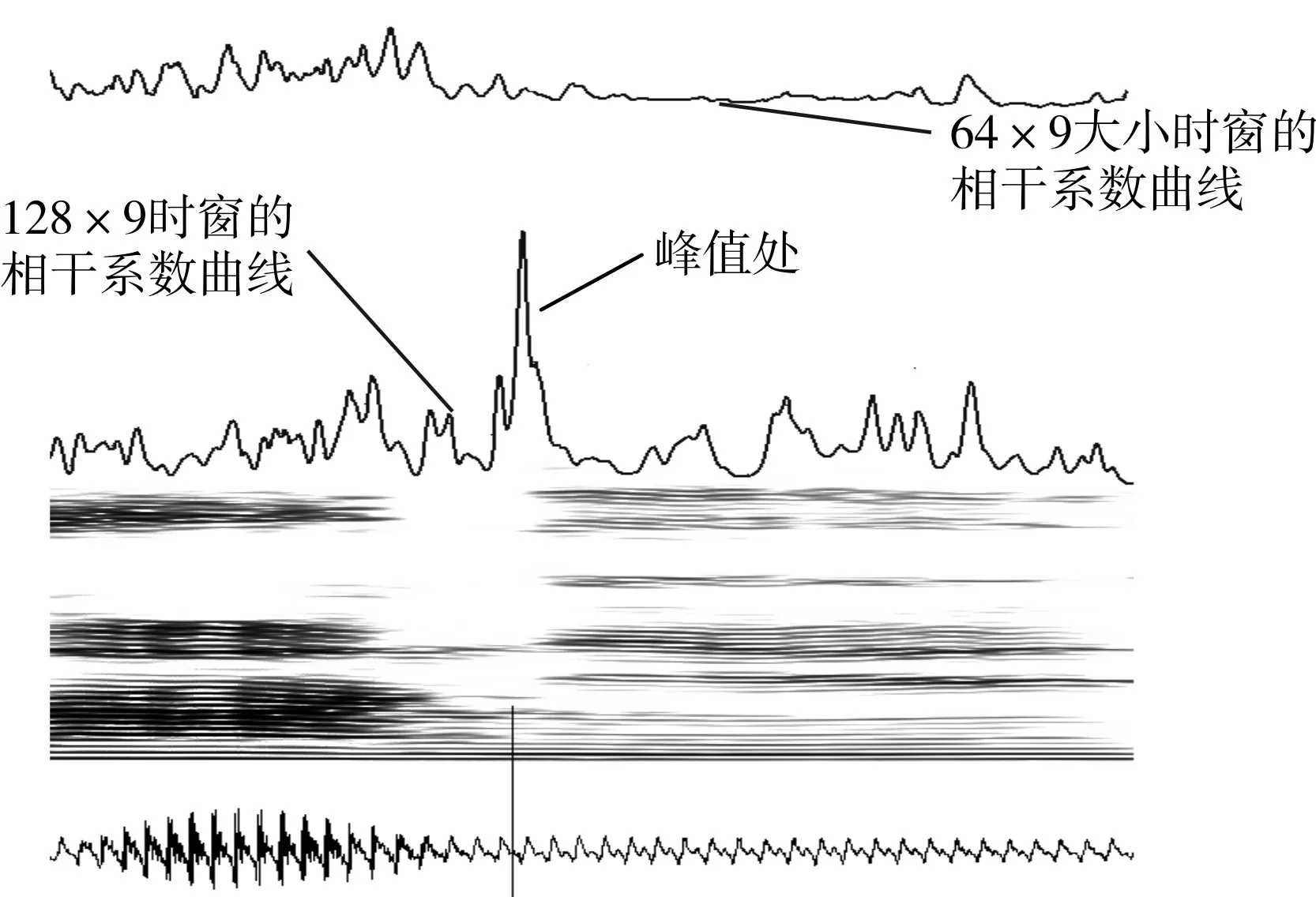
圖3 漢語“那年”的語音信號的多尺度相干分析結果
本文的實驗中我們選擇64×9(頻點范圍0~64,頻帶范圍0~2kHz)和128×9(頻點范圍0~128,頻帶范圍0~4kHz)兩個不同大小的窗口對語譜圖進行相干分析。如圖3 所示,對比分析兩條曲線可以看出在“那”和“年”之間的連接處,64×9 的窗口無法表現出較高頻率的語譜圖的差異;128×9 的窗口因為包含了中高頻的頻譜差異,所以在相干系數曲線上有較明顯的波峰。
對于不同大小的窗口需要設置不同的閾值,本文的實驗中,對64×9 的窗口設置的閾值為0.2;對128×9 大小的窗口,設置的閾值為0.15。當相干系數大于設定的閾值時認為該位置存在音節界限。對不同大小窗口的相干分析結果需要進行綜合分析確定切分位置。綜合分析的基本思想:若兩條相干系數曲線中任意一條曲線在某一位置超過設置的閾值,就認為該位置是兩個音節的分界線;若兩條相干系數曲線在同一大致位置都超過對應的閾值,則取兩點的中間位置作為音節的分界線。
4.1.3 基音周期軌跡檢測
基音周期軌跡可以用來判斷元音段的位置,由于倒譜易受周期性復合噪聲的影響,有時會出現虛假的倒譜峰值,基音周期軌跡比基于倒譜的端點檢測結果更可靠。利用基音周期軌跡的檢測元音段的步驟如下:
1)獲取基音周期軌跡圖的像素值矩陣A(m×n),其中m表示幀長的1/2,n為語音幀數。
2)找出矩陣A 中含0(黑色像素點)的行區間[a11,a12]…[an1,an2],如圖4 所示,其中[an1,an2]表示一組數據,含義為第an1行到第an2行每行都含有值為0 的點,元音段的基音周期軌跡肯定包含在某一個行區間內。
3)對2)求出的行區間進行篩選,找出平均含0值點大于5 的行區間,減少孤立像素點的干擾,例如圖 4 中的行段[a21,a22]明顯是孤立的像素點區間,需要除去。
4)用3)求出的行區間,例如圖6中的行段[a11,a12],組成新的矩陣 B,找出矩陣 B 中含 0 值的列區間[b11,b12]…[bn1,bn2]。
5)對步驟4)的列區間進行合并,若相鄰列區間間隔小于一幀則合并為一個區間。
6)再次遍歷列區間,找出bi2-bi1≥l 的列區間,l為設定的閾值(l 需要根據完整元音段至少包含的幀數確定)。將列號轉為對應的幀號即為所求基音周期軌跡區間。
基音周期軌跡檢測與基于倒譜的端點檢測的結果可以相互進行校正。如圖4所示。

圖4 漢語“鄉村小學”的基音周期軌跡檢測
基音周期軌跡檢測到的元音段為[A,B]、[C,D]、[E,F]和[G,H],基于倒譜的端點檢測的結果為[I,J]、[K,L]、[M,N]和[O,P]。從圖4 可以看出兩種方法對“鄉”、“村”、“學”三個字的元音段的檢測結果相差不大,但是在“小”的元音段的檢測上,基于倒譜的端點檢測結果明顯沒有基音周期軌跡檢測結果準確。
4.1.4 語譜圖灰度均值變化分析
漢語中輔音信號的能量一般集中在高頻部分,元音信號的能量集中在中低頻部分。通過觀察大量實驗發現,當音節變化時,部分相鄰音節的界限處的像素點灰度分布會出現明顯變化,可以利用語譜圖上像素點灰度值的變化來尋找切分點。
具體實現方法:求時窗內像素點的灰度均值,然后將時窗向右滑動,依次計算,直至語譜圖最右端,求相鄰窗口灰度均值的差值,然后歸一化處理。
語譜圖灰度均值變化曲線繪制步驟:
1)繪制語音信號的語譜圖,獲取灰度值矩陣。
2)選取m×n大小的時窗,m 表示窗口包含的頻率點數,n表示幀數。求窗口內像素點的灰度均值。
3)窗口水平右移,每次移動n-1 幀的距離直至語譜圖最右端,獲取 k 個灰度均值 v1,v2…vk-1,vk,求相鄰兩個灰度均值之間差值的絕對值,然后歸一化得到k-1個數據。
4)將歸一化后的k-1 個數據中相鄰數據連接起來得到灰度均值變化曲線。
對“師恩難忘”的語音信號的語譜圖用128×9的窗口進行分析后得到圖5 的灰度均值變化曲線,其中128 表示每一幀的第33~160 個數據點。因為在語譜圖上,0~1000Hz 頻帶范圍內的像素點的灰度值分布較為均衡,無法體現灰度均值的變化;在1000Hz~5000Hz 頻帶范圍內的像素點(第 33~160個數據點)的灰度值隨語義變化較明顯,可以用來分析灰度均值的變化;當頻率超過5000Hz時,像素點的灰度值分布較為雜亂,會影響結果的準確性。從圖5 可以明顯地看到在“恩”和“難”的界限處,灰度均值變化曲線出現了較高的極值,可以作為切分的依據。本文在大量觀察分析實驗后,設定閾值0.15,當灰度變化值大于0.15 時可以認為對應位置存在切分點。
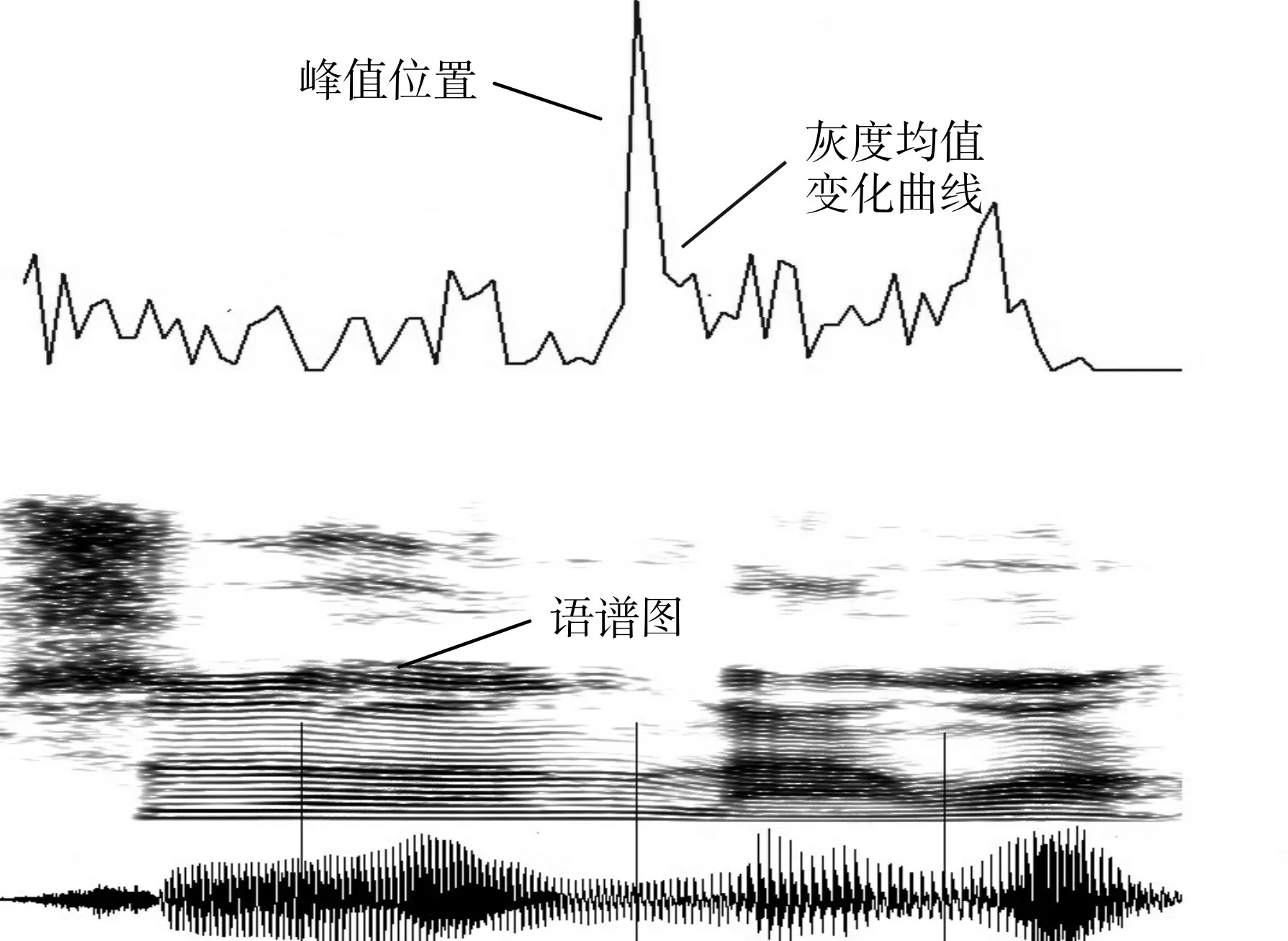
圖5 漢語“師恩難忘”的灰度均值變化曲線
4.2 多級切分算法
在4.1 節介紹了四種尋找切分點的思路,為了實現連續漢語語音切分,將4.1節的方法綜合起來,研究了多級切分方法,主要步驟如下:
1)利用雙門限端點檢測技術檢測到語音段[tn1,tn2]。
2)對1)的語音段利用基于倒譜的端點檢測技術找出元音段[l11,l12]…[lm1,lm2]。
3)利用基音周期軌跡檢測算法對2)的結果進行校正得到校正后的元音段
4)元音段的末幀可以看作是一個切分點,對于檢測到的最后一個元音段應該與有聲段的結束幀tn2相吻合。獲得初步的切分結果
5)遍歷4)的切分結果,對連續元音幀數大于T的語音段(T 需要根據完整元音段一般包含的幀數m 來確定,T設置2m),利用多尺度相干分析檢測相干系數大于設定閾值的語音幀作為切分點。
6)遍歷5)的結果,對連續元音幀數大于T的語音段,利用語譜圖灰度均值分析找出灰度均值大于設定閾值的語音幀作為切分依據。
利用多級切分方法,通過相干分析、多尺度分析、基音周期軌跡檢測和語譜圖灰度分析將連續漢語語音切分為獨立的音節。通過對實驗語音庫的語音文件進行切分實驗,得到表1 的對比結果。從

表1 可以看出,對相同測試樣本,多級切分方法準確率更高,比基于雙門限和倒譜的端點檢測技術和基于頻帶方差的切分方法分別高出33%和26%。
其中南京理工大學NJUST603 語音庫含男生210人,女生213人,T4語音文件為作家劉紹棠的文章《師恩難忘》,含593個漢字,本文的實驗選取了5名男生,5名女生的T4語音進行統計。
5 結語
多級切分方法綜合了聲學、語音學、語言學的知識,在分析漢語語音特征的基礎上利用雙門限端點檢測技術、基于倒譜的端點檢測技術、相干分析和基音周期軌跡檢測等方法對連續漢語語音進行切分,獲得了較高的準確率。實驗中也發現一些問題需要去解決,例如對有些快速并且不清晰的發音如何確定音節的界限,這將是本文下一步的主要研究方向。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
