地震應(yīng)急信息自動(dòng)分類方法研究1
2019-07-28 18:22:06姜立新楊天青張維佳
震災(zāi)防御技術(shù) 2019年4期
王 琳 姜立新 楊天青 張維佳
1)中國(guó)地震局地震預(yù)測(cè)研究所,北京 100036
2)中國(guó)地震臺(tái)網(wǎng)中心,北京 100045
引言
管理者經(jīng)常面臨著與決策相關(guān)信息缺失和不相關(guān)信息泛濫的問(wèn)題,往往會(huì)對(duì)管理者的決策造成負(fù)面影響(Detrick,2002)。此情況在地震災(zāi)害應(yīng)對(duì)過(guò)程中尤為突出,信息缺失或冗余往往造成抗震救災(zāi)指揮決策的滯后,甚至導(dǎo)致救援力量和資源投放重點(diǎn)出現(xiàn)偏差。
近年來(lái),中國(guó)地震局在應(yīng)急救援領(lǐng)域先后開(kāi)展了“九五首都圈防震減災(zāi)示范項(xiàng)目”“十五中國(guó)數(shù)字地震觀測(cè)網(wǎng)絡(luò)項(xiàng)目”和“國(guó)家地震社會(huì)服務(wù)工程”。應(yīng)急觸發(fā)、災(zāi)情研判、快速響應(yīng)及輔助決策等應(yīng)急科技產(chǎn)出的日益豐富為國(guó)家及各省抗震救災(zāi)指揮部實(shí)施地震應(yīng)急救援提供有力的科學(xué)依據(jù)和技術(shù)支持。我國(guó)雖建成了較完整的應(yīng)急指揮體系及相應(yīng)的指揮技術(shù)系統(tǒng),但在應(yīng)急信息管理方面仍存在一些問(wèn)題,具體表現(xiàn)為:①技術(shù)產(chǎn)出較豐富,直接有效利用率較低;②內(nèi)容重復(fù),存放分散;③尚未建立有效的災(zāi)情管理技術(shù)。
為此國(guó)內(nèi)不少專家學(xué)者對(duì)地震應(yīng)急基礎(chǔ)信息及災(zāi)情信息的收集、整理與分類編碼進(jìn)行了大量研究。付繼華等(2009)、聶高眾等(2002)從建立數(shù)據(jù)庫(kù)的角度分別討論了地震應(yīng)急數(shù)據(jù)的分類。《地震學(xué)專業(yè)分類表》(梁凱利等,2011)嚴(yán)格按照《中國(guó)圖書(shū)館分類法》的要求,結(jié)合地震科技資料分類的自身特點(diǎn),對(duì)地震學(xué)專業(yè)進(jìn)行了分類;白仙富等(2010)按照信息內(nèi)容的本質(zhì)屬性,依據(jù)發(fā)生什么事件、產(chǎn)生什么影響、對(duì)產(chǎn)生的影響人們做出什么響應(yīng)、針對(duì)響應(yīng)有何成效的思路對(duì)地震應(yīng)急現(xiàn)場(chǎng)信息進(jìn)行分類;張翼等(2016)根據(jù)地 震應(yīng)急信息產(chǎn)品管理、更新及共享的需要,針對(duì)地震應(yīng)急信息產(chǎn)品屬性、服務(wù)、時(shí)間、傳遞等特性,在借鑒地震應(yīng)急基礎(chǔ)理論研究及相關(guān)行業(yè)分類標(biāo)準(zhǔn)的基礎(chǔ)上,研究地震應(yīng)急信息產(chǎn)品的分類方法。
但對(duì)于多渠道的上傳機(jī)制,加之震后大量的災(zāi)情及背景信息,使信息歸類難度較大。面對(duì)緊迫的時(shí)效性壓力和不同指揮決策部門對(duì)信息的不同需求,僅靠人工手動(dòng)進(jìn)行信息分類提取的方式難以達(dá)到令人滿意的效果,因此建立條理更為清晰、標(biāo)準(zhǔn)更具實(shí)踐應(yīng)用意義、信息自動(dòng)化程度更高的信息分類管理技術(shù)十分必要,以適應(yīng)應(yīng)急指揮決策部門對(duì)應(yīng)急救援信息的快速獲取要求。
林子雨等(2010)根據(jù)關(guān)系數(shù)據(jù)庫(kù)的關(guān)鍵詞查詢問(wèn)題研究背景,闡述解決該問(wèn)題的基于模式圖和數(shù)據(jù)圖的優(yōu)缺點(diǎn)、困難和挑戰(zhàn),提出利用排序函數(shù)解決關(guān)鍵詞查詢時(shí)匹配結(jié)果可能很多的情況,最終反饋給用戶一個(gè)最相關(guān)信息。張曉民(2017)設(shè)計(jì)了基于關(guān)鍵詞數(shù)據(jù)庫(kù)信息檢索方法及時(shí)態(tài)檢索算法,主要采用時(shí)間修剪策略,同時(shí)提出時(shí)態(tài)邊權(quán)重的計(jì)算方法,實(shí)現(xiàn)了基于關(guān)鍵詞的關(guān)系數(shù)據(jù)庫(kù)時(shí)態(tài)檢索原型系統(tǒng)。通過(guò)借鑒關(guān)鍵詞在信息檢索中的應(yīng)用,本文將關(guān)鍵詞分類法應(yīng)用于地震應(yīng)急信息管理中。
1 地震應(yīng)急信息分類方法
信息分類方法主要包括線分類法、面分類法、混合分類法(耿慶齋等,2014)。現(xiàn)有與地震信息分類有關(guān)的標(biāo)準(zhǔn)與研究多采用線分類法,其特點(diǎn)是層次較清晰,易于理解;缺點(diǎn)是結(jié)構(gòu)可塑性較差,一旦分類深度和每層級(jí)類目容量固定后,修改層級(jí)和插入新類將受限(劉若梅等,2004)。面分類法將選定的分類對(duì)象若干屬性或特征視為若干個(gè)“面”,每個(gè)“面”中又可分成彼此獨(dú)立的若干個(gè)類目,對(duì)于解決同種類型要素在不同應(yīng)用中分類的矛盾具有優(yōu)勢(shì)。
參考不同分類方法(楊天青等,2016;和銳等,2011),考慮自動(dòng)分類結(jié)果的時(shí)效性與實(shí)用性,本文采用線與面相結(jié)合的混合分類法,以信息服務(wù)的高效便捷為目的,按照應(yīng)急信息自身的特征屬性、地震發(fā)生時(shí)間線產(chǎn)生的直接與間接損失信息(即震前、震時(shí)與震后所造成的破壞與損失信息),針對(duì)產(chǎn)生的影響采取相應(yīng)的應(yīng)急救援信息,將地震應(yīng)急信息分為震前基礎(chǔ)背景信息、地震震情災(zāi)情信息、震后應(yīng)急救援信息,如表1 所示。

表1 地震應(yīng)急信息分類定義 Table 1 Definition of classification of seismic emergency information
2 地震應(yīng)急信息自動(dòng)分類方法的研究
(1)通過(guò)實(shí)地調(diào)研河北省、山西省、內(nèi)蒙古自治區(qū)、四川省的基本人文地理環(huán)境信息概況,本文選擇收集四川省4 次地震應(yīng)急資料的主要原因?yàn)椋?)對(duì)同一省份的地震應(yīng)急資料進(jìn)行文檔分詞處理時(shí),可直接忽略地名類固定性且不具實(shí)際區(qū)分意義的屬性詞,且同一省份文本文檔之間的語(yǔ)義描述差異性相對(duì)較小;2)相對(duì)于地震易發(fā)的其他3 個(gè)省來(lái)說(shuō),四川省地勢(shì)地形地貌相對(duì)較復(fù)雜,建筑物水庫(kù)大壩等公共基礎(chǔ)設(shè)施種類結(jié)構(gòu)相對(duì)復(fù)雜,且抗震救災(zāi)技術(shù)較成熟,從而使得到的信息更豐富和全面;3)四川省已建成一套獨(dú)立的信息上傳與協(xié)同管理體系,有助于提高資料分析和研究的準(zhǔn)確性。
(2)應(yīng)急信息資料分析統(tǒng)計(jì)
共收集2013 年4 月20 日蘆山7.0 級(jí)地震、2014 年11 月22 日康定6.3 級(jí)地震、2017 年8 月8 日九寨溝7 級(jí)地震、2017 年9 月30 日廣元青川5.4 級(jí)地震資料,由于收集到的數(shù)據(jù)較零散,且震級(jí)較小的數(shù)據(jù)資料較少,所以本文將4 次地震中相同類別的信息統(tǒng)計(jì)在同一文件夾下,如表2 所示。

表2 信息文檔分類統(tǒng)計(jì) Table2 Classification statistics of information documents
(3)應(yīng)急信息分類關(guān)鍵詞的選取
中文分詞(Chinese Word Segmentation)指將一個(gè)漢字序列切分成一個(gè)一個(gè)單獨(dú)的詞,作為文本挖掘的基礎(chǔ),對(duì)輸入的一段中文進(jìn)行中文分詞,可達(dá)到自動(dòng)識(shí)別語(yǔ)句含義的效果(趙小華,2010)。
TF 詞頻(Term Frequency)指某一個(gè)給定的詞語(yǔ)在該文件中出現(xiàn)的次數(shù)。IDF 反文檔頻率(Inverse Document Frequency)的主要思想是:如果包含詞條的文檔越少,IDF 越大,則說(shuō)明詞條具有很好的類別區(qū)分能力。TF-IDF 是一種用于信息搜索和信息挖掘的常用加權(quán)技術(shù),在搜索、文獻(xiàn)分類和其他相關(guān)領(lǐng)域中的應(yīng)用較為廣泛(施聰鶯等,2009)。
本文在對(duì)文本信息進(jìn)行分析處理時(shí),根據(jù)建立的分類標(biāo)準(zhǔn),對(duì)收集到的信息進(jìn)行分類,應(yīng)用TF-IDF 技術(shù),在Excel 表里對(duì)各類文本信息進(jìn)行分詞和詞頻統(tǒng)計(jì)。此種方法的局限是處理的文檔只能是文本文檔(.txt)格式。按名詞和動(dòng)詞的詞性,統(tǒng)計(jì)IDF 和詞頻數(shù)排名前20的詞,如圖1-3 所示。
由圖4 可知,地震、級(jí)地震、地震局、水庫(kù)4 個(gè)詞語(yǔ)的出現(xiàn)總頻數(shù)超過(guò)1000,其中地震出現(xiàn)頻數(shù)高達(dá)2439。各類別信息里的頻數(shù)具體為:震區(qū)背景信息119 次、震區(qū)震情災(zāi)情信息1105 次、災(zāi)區(qū)應(yīng)急救援信息914 次,占各類別信息前20 頻數(shù)的比例分別為9%、15%、13%,在總文檔里所占比例為16%,平均出現(xiàn)頻率占12.3%。 對(duì)未分類的所有初始文本進(jìn)行統(tǒng)計(jì),結(jié)果如表6 所示。
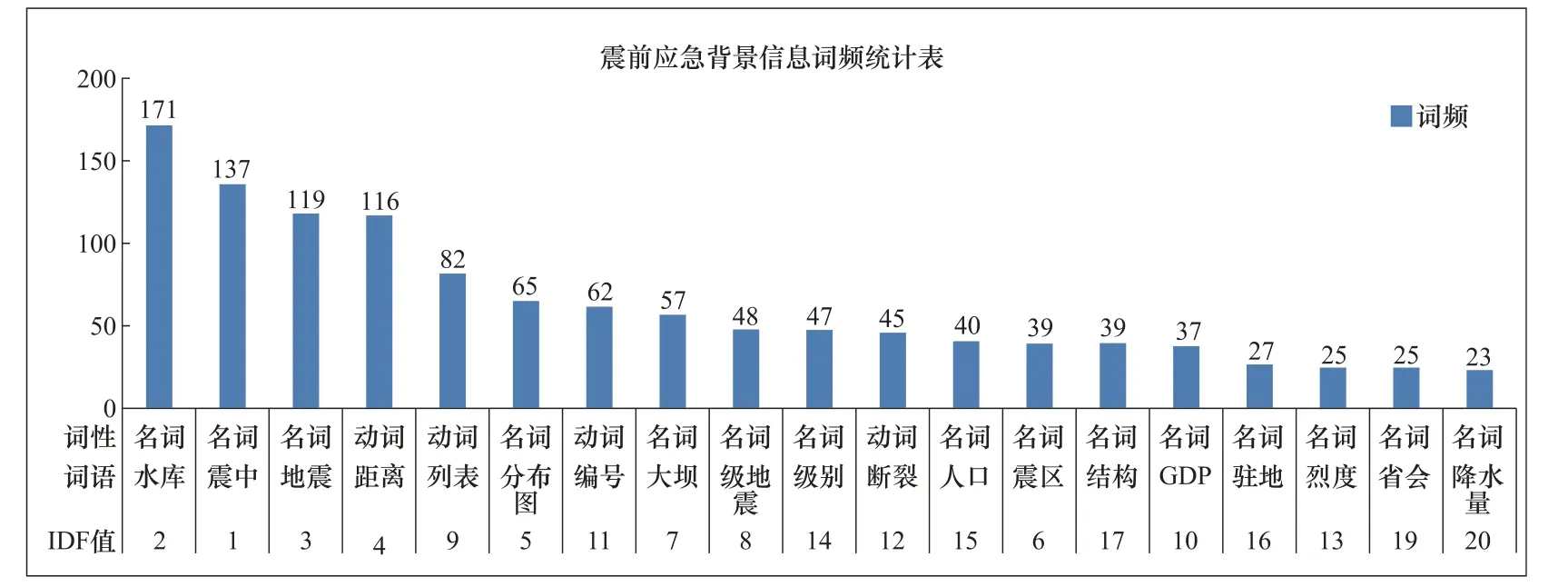
圖1 震前應(yīng)急背景信息詞頻統(tǒng)計(jì) Fig. 1 Frequency statistics of emergency background information before earthquake
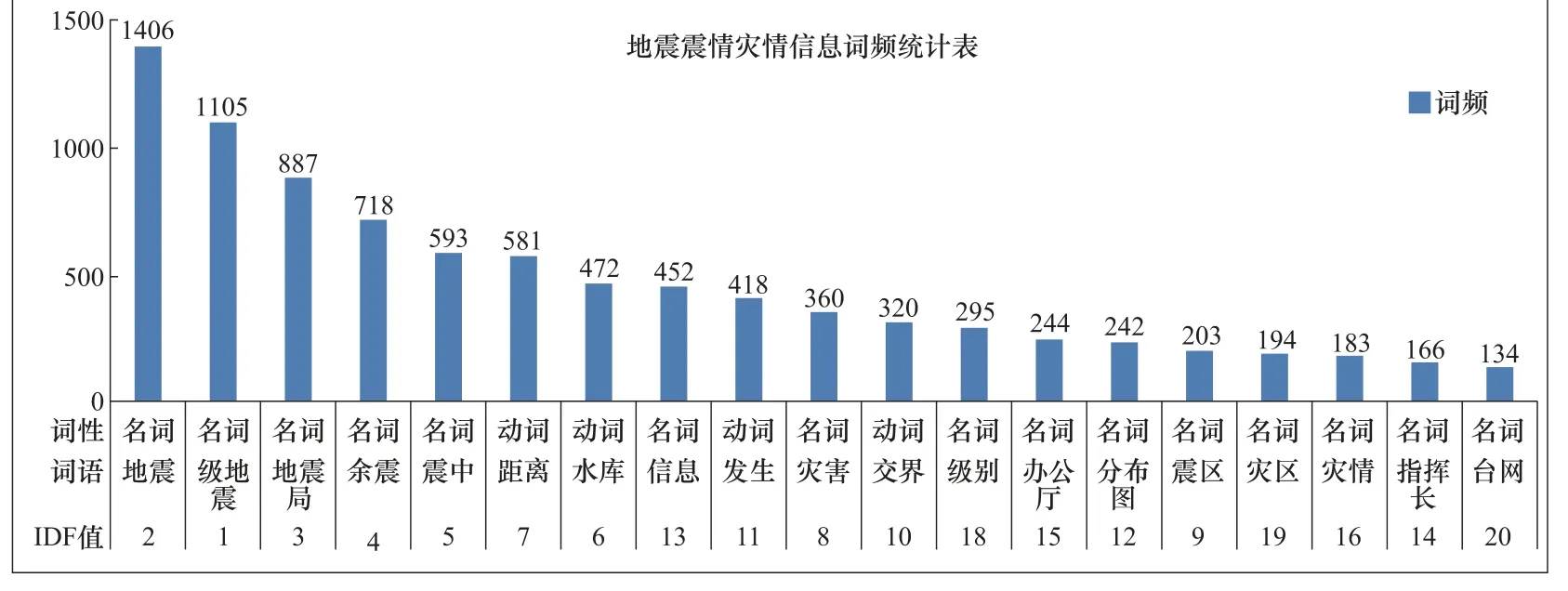
圖2 地震震情災(zāi)情信息統(tǒng)計(jì) Fig. 2 Statistical table of disaster information in earthquake area

圖3 震后應(yīng)急救援信息詞頻統(tǒng)計(jì) Fig. 3 Frequency statistics of emergency rescue information after earthquake

圖4 總文檔信息詞頻統(tǒng)計(jì) Fig. 4 Total Document Information frequency table
頻數(shù)為700—1000 的詞語(yǔ)共6 個(gè),分別為震中854 次、余震793 次、災(zāi)害784 次、發(fā)生782 次、距離773 次、破壞708 次,占所有詞頻的比例為4.7%—5.7%,其中發(fā)生和災(zāi)害2 個(gè)詞語(yǔ)的頻數(shù)相差2,在進(jìn)行詞語(yǔ)篩選時(shí),任選其一即可。
頻數(shù)為300—700 的詞語(yǔ)共8 個(gè),其中400 以上的有3 個(gè),分別為信息643 次、災(zāi)區(qū)606次、藥品540 次;其余5 個(gè)為分布圖、大壩、災(zāi)情、指揮長(zhǎng)、醫(yī)療器材,頻數(shù)為300—400。8 個(gè)詞語(yǔ)從分類屬性來(lái)看,主要屬于應(yīng)急救援信息,占總文檔詞語(yǔ)的比例為2%—4%。
整體來(lái)看,出現(xiàn)頻率越高的詞語(yǔ),在分類過(guò)程中起到的作用越低,即作為關(guān)鍵詞的代表性越不強(qiáng),本文最終選取的各類別信息關(guān)鍵詞是在各類信息詞語(yǔ)統(tǒng)計(jì)里頻率不高且在其他類別信息里頻率較低或沒(méi)有的詞語(yǔ)。根據(jù)頻數(shù)統(tǒng)計(jì)規(guī)律可知,本文關(guān)鍵詞的取舍主要按以下規(guī)則:①對(duì)4 個(gè)頻數(shù)數(shù)據(jù)按詞語(yǔ)詞頻占所有20 個(gè)詞語(yǔ)詞頻的比例,將頻率域劃分為2%以下、2%—4%、4%—6%、6%—8%、8%五個(gè)區(qū)間;②按各類信息的定義,每個(gè)區(qū)間選取一個(gè)詞(選取與本類信息最相關(guān)的詞語(yǔ))作為3 類信息的基礎(chǔ)關(guān)鍵詞。如第一區(qū)間地震局、第二區(qū)間水庫(kù)、第三區(qū)間破壞、第四區(qū)間災(zāi)情、第五區(qū)間震情,這個(gè)組合歸至震情災(zāi)情信息類;③每個(gè)區(qū)間選取2—4 個(gè)固有關(guān)鍵詞,與基礎(chǔ)關(guān)鍵詞重合的排除,低頻率區(qū)間的詞語(yǔ)多選,重復(fù)詞語(yǔ)與高頻詞語(yǔ)盡量不選,最終每類信息選出15 個(gè)關(guān)鍵詞,如表7 所示。
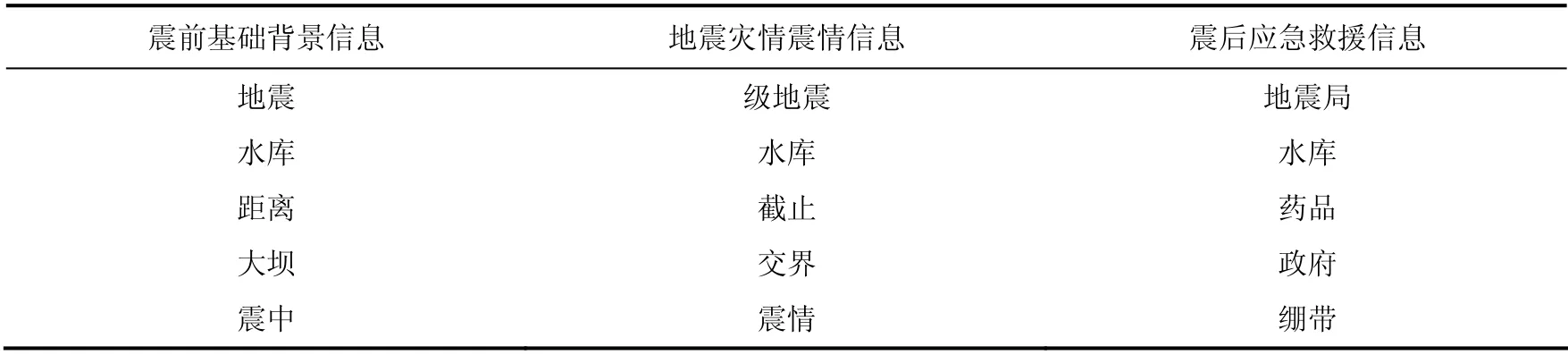
表3 關(guān)鍵詞選取結(jié)果 Table 3 Keyword selection results

續(xù)表
3 地震應(yīng)急信息的自動(dòng)分類
百度、谷歌等搜索引擎成功顯示出關(guān)鍵詞檢索的方式已被廣大用戶所接受(張曉民,2017)。本文為解決應(yīng)急信息的自動(dòng)分類,采用 “關(guān)鍵詞分類法”,根據(jù)分類標(biāo)準(zhǔn),對(duì)原始文本進(jìn)行結(jié)構(gòu)化處理,通過(guò)中文分詞、詞頻篩選與統(tǒng)計(jì)實(shí)現(xiàn)信息關(guān)鍵詞的提取,此階段中的中文分詞將一串連續(xù)漢字序列按動(dòng)詞、名詞的規(guī)范重新組合成詞語(yǔ)序列。詞頻統(tǒng)計(jì)與篩選即對(duì)分詞結(jié)果進(jìn)行統(tǒng)計(jì),去除一些無(wú)效詞后,生成關(guān)鍵詞詞庫(kù),用匹配詞庫(kù)的方法實(shí)現(xiàn)信息的自主分類,具體過(guò)程如下:①收集震后國(guó)家中心、各研究所、各省(自治區(qū))地震局上傳至應(yīng)急信息共享平臺(tái)、評(píng)比FTP 站點(diǎn)、臺(tái)網(wǎng)中心臺(tái)網(wǎng)部FTP 站點(diǎn)的震后產(chǎn)出成果,建立相對(duì)完整的產(chǎn)出目錄;按照之前建立的地震應(yīng)急信息分類標(biāo)準(zhǔn),對(duì)收集到的條目進(jìn)行梳理歸類。②對(duì)所有文檔按詞性進(jìn)行詞頻統(tǒng)計(jì),將無(wú)效詞語(yǔ)去除后,對(duì)每個(gè)大類建立相應(yīng)的關(guān)鍵詞詞庫(kù)。由于高頻詞語(yǔ)的重合度較高,因此在建立關(guān)鍵詞詞庫(kù)時(shí),需綜合考慮詞頻和詞語(yǔ)含義,首選該分類獨(dú)有且出現(xiàn)頻率較高的詞語(yǔ)。③以提取的特征詞作為自動(dòng)分類程序中的詞庫(kù),進(jìn)行自動(dòng)分類處理,在計(jì)算機(jī)語(yǔ)言的基礎(chǔ)上,實(shí)現(xiàn)信息的自動(dòng)分類。要求程序在震后啟動(dòng),自動(dòng)完成當(dāng)前地震產(chǎn)生在各不同平臺(tái)上的信息分類,并將產(chǎn)出成果保存至本地服務(wù)器。根據(jù)已建立的分類類別和各應(yīng)急指揮部門需求,可進(jìn)一步實(shí)現(xiàn)對(duì)產(chǎn)出成果的重命名(非必要)和重新分發(fā)。分類流程如圖5 所示。
以九寨溝7.0 級(jí)地震產(chǎn)出為例:
報(bào)告及圖件總數(shù)如表8 所示。分類文件夾包括震前背景信息文件夾、震區(qū)災(zāi)情震情信息文件夾、震后應(yīng)急救援信息文件夾和其他文件夾。
建立的分類詞庫(kù)較簡(jiǎn)單,結(jié)果與表3 的關(guān)鍵詞庫(kù)高度匹配。震前背景信息特征詞包括構(gòu)造、交通、居民點(diǎn)、GDP、人口等,地震震情災(zāi)情信息特征詞包括截止、余震、熱力圖、震動(dòng)、態(tài)勢(shì)、數(shù)據(jù)、精密、水準(zhǔn)、傷亡、災(zāi)害、中央電視臺(tái)、設(shè)防、展開(kāi)、遇難等,震后應(yīng)急救援信息特征詞包括救援、救援隊(duì)、搜救等。
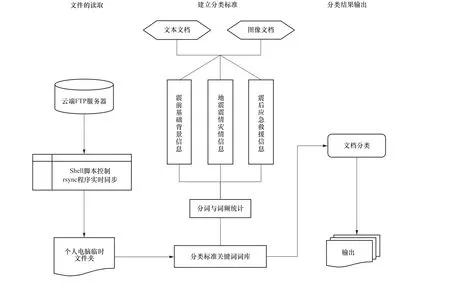
圖5 分類流程 Fig. 5 Classification flowchart

表4 報(bào)告及圖件總數(shù) Table 4 Total number of reports and artworks
分類標(biāo)準(zhǔn)建成后,以提取的關(guān)鍵詞作為自動(dòng)分類程序中的詞庫(kù),進(jìn)行自動(dòng)分類,流程如圖6 所示。分類過(guò)程中各環(huán)節(jié)為:①將所有格式文檔轉(zhuǎn)為.txt 格式文件,并輸出至原始文件 夾;②搭建主程序運(yùn)行環(huán)境(Python2.7 環(huán)境、jieba 程序庫(kù));③運(yùn)行shell 主程序,調(diào)用Python 子程序模塊,將原始文件夾下的所有文件進(jìn)行分類處理。模塊1(cut):獲得文件對(duì)文件進(jìn)行分詞,并將其存至臨時(shí)文件夾;模塊2(count):對(duì)原文件進(jìn)行詞頻統(tǒng)計(jì),并對(duì)統(tǒng)計(jì)結(jié)果進(jìn)行排序;模塊3(order):分詞詞頻統(tǒng)計(jì)排序前15 的詞進(jìn)行排序;模塊4(set):根據(jù)各類關(guān)鍵詞篩選結(jié)果,得到關(guān)鍵詞庫(kù);模塊5(classify):將初始文檔進(jìn)行結(jié)構(gòu)化處理后得到的前15 詞頻作為該文檔的關(guān)鍵詞,將其與關(guān)鍵詞庫(kù)進(jìn)行對(duì)比,通過(guò)文檔關(guān)鍵詞在所劃分的5 個(gè)頻率域區(qū)間的關(guān)鍵詞庫(kù)匹配率決定文檔的歸屬類別,將文檔劃分至匹配率最高的類別。判斷該關(guān)鍵詞屬于哪個(gè)分類,按照文件歸屬,把文件歸類至該目錄下。某個(gè)文件可能屬于多個(gè)類別,如果沒(méi)有對(duì)應(yīng)的目錄,則把文件拷貝至其他文件夾。
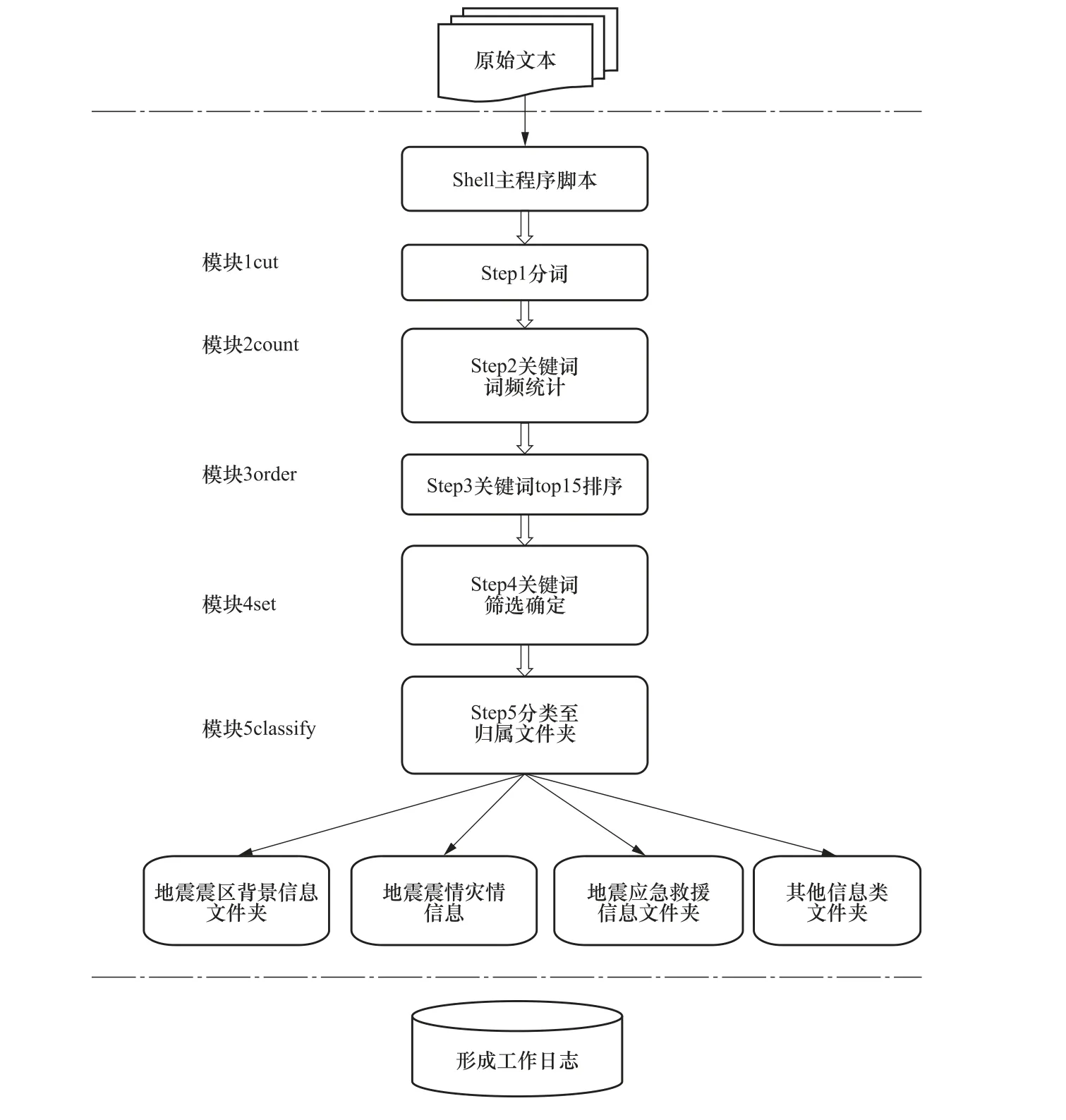
圖6 自動(dòng)分類流程 Fig. 6 Flowchart of automatic classification
4 總結(jié)和應(yīng)用探討
目前我國(guó)地震應(yīng)急信息是通過(guò)各省、市已建立的信息匯總渠道直接上傳至相關(guān)服務(wù)平臺(tái),供指揮部及相關(guān)領(lǐng)導(dǎo)專家參閱,但大地震發(fā)生后面對(duì)的是大量災(zāi)情震情救援及背景信息,僅靠上述傳輸和提取方式不能達(dá)到令人滿意的程度。本文的研究成果可實(shí)現(xiàn)多渠道應(yīng)急信息的自動(dòng)分類,輔助地震應(yīng)急指揮控制與決策等。
(1)參考以往學(xué)者在地震應(yīng)急信息分類與編號(hào)方面的研究,考慮分類信息的服務(wù)實(shí)用性,根據(jù)地震事件發(fā)生的時(shí)間軸,將地震應(yīng)急信息分為震前應(yīng)急背景信息、地震應(yīng)急震情災(zāi)情信息和震后應(yīng)急救援信息。
(2)為實(shí)現(xiàn)地震應(yīng)急信息的自動(dòng)分類,研究采用 “關(guān)鍵詞分類法”,以實(shí)現(xiàn)地震應(yīng)急信息的自動(dòng)分類,提高信息處理的目標(biāo)性、針對(duì)性和有效性。
(3)通過(guò)分析,本文對(duì)應(yīng)急信息進(jìn)行分類、分詞、詞頻統(tǒng)計(jì),由前15 位關(guān)鍵詞信息統(tǒng)計(jì)結(jié)果可知,各不同類別應(yīng)急信息關(guān)鍵詞之間存在較大差異,可見(jiàn)與傳統(tǒng)信息直接上傳法相比,“關(guān)鍵詞分類法”能使信息條理性更強(qiáng),分析處理時(shí)更方便直接。
(4)在大數(shù)據(jù)的背景下,相比于傳統(tǒng)的信息分類方法,實(shí)現(xiàn)地震應(yīng)急信息的自動(dòng)分類,將大大提高信息利用率,并推動(dòng)地震應(yīng)急救援相關(guān)技術(shù)走向智能成熟化、自動(dòng)服務(wù)化。
但對(duì)于有效應(yīng)用關(guān)鍵詞分類法實(shí)現(xiàn)應(yīng)急信息的自動(dòng)分類、降低某個(gè)文件可能屬于多個(gè)類別的交叉情況,仍存在以下問(wèn)題:
(1)如何建立關(guān)鍵詞之間的語(yǔ)義關(guān)系和邏輯關(guān)聯(lián)關(guān)系,處理并不斷豐富分類關(guān)系樹(shù),還需對(duì)信息自身與信息相互之間更深層次的關(guān)聯(lián)關(guān)系進(jìn)行探討,如時(shí)態(tài)上或語(yǔ)義上。
(2)對(duì)于關(guān)鍵詞重復(fù)和冗余問(wèn)題,目前只有少數(shù)研究提出了初步解決方案,還需結(jié)合信息自身的屬性、信息之間的差異及用戶對(duì)信息的需求,由相關(guān)函數(shù)(如排序函數(shù))探索建立一個(gè)權(quán)衡的標(biāo)準(zhǔn)。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
少兒科學(xué)周刊·少年版(2015年3期)2015-07-07 21:00:00
中外會(huì)展(2014年4期)2014-11-27 07:46:46
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
