基于IndRNN-Attention的用戶意圖分類
2019-07-15 12:13:26張志昌張珍文張治滿
計算機研究與發展 2019年7期
張志昌 張珍文 張治滿
(西北師范大學計算機科學與工程學院 蘭州 730070)
人機對話作為智能場景中的關鍵技術,近年來引起了學術界和產業界的廣泛關注,相關方法已經在不少產品(如蘋果Siri[注]https://en.wikipedia.org/wiki/Siri、Google Now[注]https://en.wikipedia.org/wiki/Google_Now、微軟Cortana[注]https://en.wikipedia.org/wiki/Cortana和阿里小蜜[注]http://alixiaomi.com等)中得到了廣泛應用.人機對話系統運行時,首要的任務就是在用戶輸入消息(文本或者語音)后,準確理解用戶對話意圖[1],例如判斷用戶是想和系統閑聊,還是希望系統完成特定的任務(如預定機票、訂外賣、查詢天氣等);然后再根據用戶意圖做出正確的回應,讓對話順利進行.精準的用戶意圖理解能有效提高人機交互的自然度[2-3],提升用戶體驗.因此,用戶意圖分類在人機對話系統研究中具有重要的研究意義.表1為常見用戶意圖舉例:

Table 1 Examples of User Intent表1 用戶意圖舉例
針對人機對話中的用戶意圖分類問題目前已有不少研究,但依然存在很多需要深入解決的問題,如萬能回復、回復相關性差及對聊天文本語義理解不夠深入,無法從較短的用戶聊天文本中理解用戶意圖等問題.如當用戶輸入“我的ThinkPad已經用了5年了”時,可能是稱贊這個筆記本電腦性能很好,也可能是表達想換新筆記本電腦的一種意愿.在這種情況下,對話系統很難準確判斷用戶的真實意圖到底是哪一種.現有的用戶意圖分類方法存在對聊天文本語義理解不夠深入、難以有效表達用戶聊天文本的真實語義信息等問題.
針對上述問題,本文提出了基于獨立循環神經網絡(independently recurrent neural network, IndRNN)和詞級別注意力機制(word-level attention mechanism)的用戶意圖分類方法.通過多層IndRNN[4]網絡作為編碼器對用戶聊天文本編碼,有效改善了傳統循環神經網絡(recurrent neural network, RNN)結構在序列任務處理中出現的“梯度消失”和“梯度爆炸”等問題,而詞級別注意力機制[5]則顯著地增強了領域詞匯對意圖分類的突出貢獻.通過在第六屆全國社會媒體處理大會中文人機對話技術評測[6](SMP2017-ECDT)用戶意圖領域分類語料上實驗發現,本文提出的方法相比其他已有的幾種分類方法,取得了更好的分類效果.
1 相關工作
對用戶意圖分類方面已有的研究方法進行總結,可以劃分為3類:
1) 基于規則的方法.這種方法主要是根據知識工程師或領域專家的經驗和知識歸納總結出相關分類規則,然后構建相應的規則模板作為分類器分類.Yang等人[7]提出了人們日常生活中經常出現的12 種普遍需求,通過模板匹配方法獲得了購買產品的用戶,然后基于Twitter 中的Unigram特征、WordNet 中詞的語義特征和表達需求的動詞特征來訓練分類器完成對用戶消費意圖的識別.Fu等人[8]采用基于模板的匹配方法來檢測用戶微博消費意圖.基于規則的方法優點是分類準確率較高.缺點是:①規則之間的關系不透明,缺乏分層的知識表達;②不具備從經驗中學習的能力,維護困難;③覆蓋率低,規則制定需要專業人員參與,耗時耗力,可擴展性較差,很難在多領域推廣使用.
2) 基于傳統機器學習的方法.傳統機器學習方法基于特征工程[9],常用的方法有樸素貝葉斯(Naive Bayes, NB)、支持向量機(support vector machine, SVM)、最大熵等.用戶意圖分類任務需要獲取用戶輸入文本的語言特征,如詞法、句法等.大量相關研究證明模型所學習的語言學特征對于自然語言處理能夠提供十分重要的價值[10].Pang等人[11]提出使用N-gram特征可以有效地識別影評的極性,其中,Unigram特征的效果最佳;Wang等人[12]利用詞語Bigram特征訓練NB和SVM模型,在句子或文本主題分類問題中取得一致較好的效果;Huang等人[13]在用戶消費模式識別中提出了基于SVM的識別方法.基于傳統機器學習的分類方法,其優點是不需要手動編寫規則模板,能有效解決基于規則的方法中所存在的問題.缺點是:①提取特征耗時,其消耗往往隨著數據集規模的變大而增長,容易出現維度災難;②不容易構造有效的分類特征,且大部分的特征基于字或詞,難以表達句子較深層的語義信息.
3) 基于深度學習的方法.深度學習的出現極大降低了獲取文本特征的難度.Kim[14]首次將卷積神經網絡(CNN)應用到句子分類任務中,并提出了幾種變形;Gao等人[15]在句子分類任務中提出基于稀疏自學習卷積神經網絡對句子編碼,實現句子分類;Xu等人[16]提出利用神經網絡的方法評估書法練習者書法臨摹的質量;Bhardwaj等人[17]在搜索引擎查詢意圖識別任務中提出利用卷積神經網絡獲取查詢文本的向量表示作為查詢分類的特征;Bhardwaj等人[18]提出利用記憶網絡對用戶交互信息編碼以實現應用推薦任務中的意圖分類;Kim等人[19]在口語對話理解中提出利用Bi-LSTM方法對用戶交互文本編碼實現領域和意圖分類.端到端的深度學習方法使用詞向量表示,可不依賴于特定語言的句法關系,減少了人工設計和構造分類特征的負擔,還可以抓取到視覺上無法獲取的特征,從而提高了分類的精度.
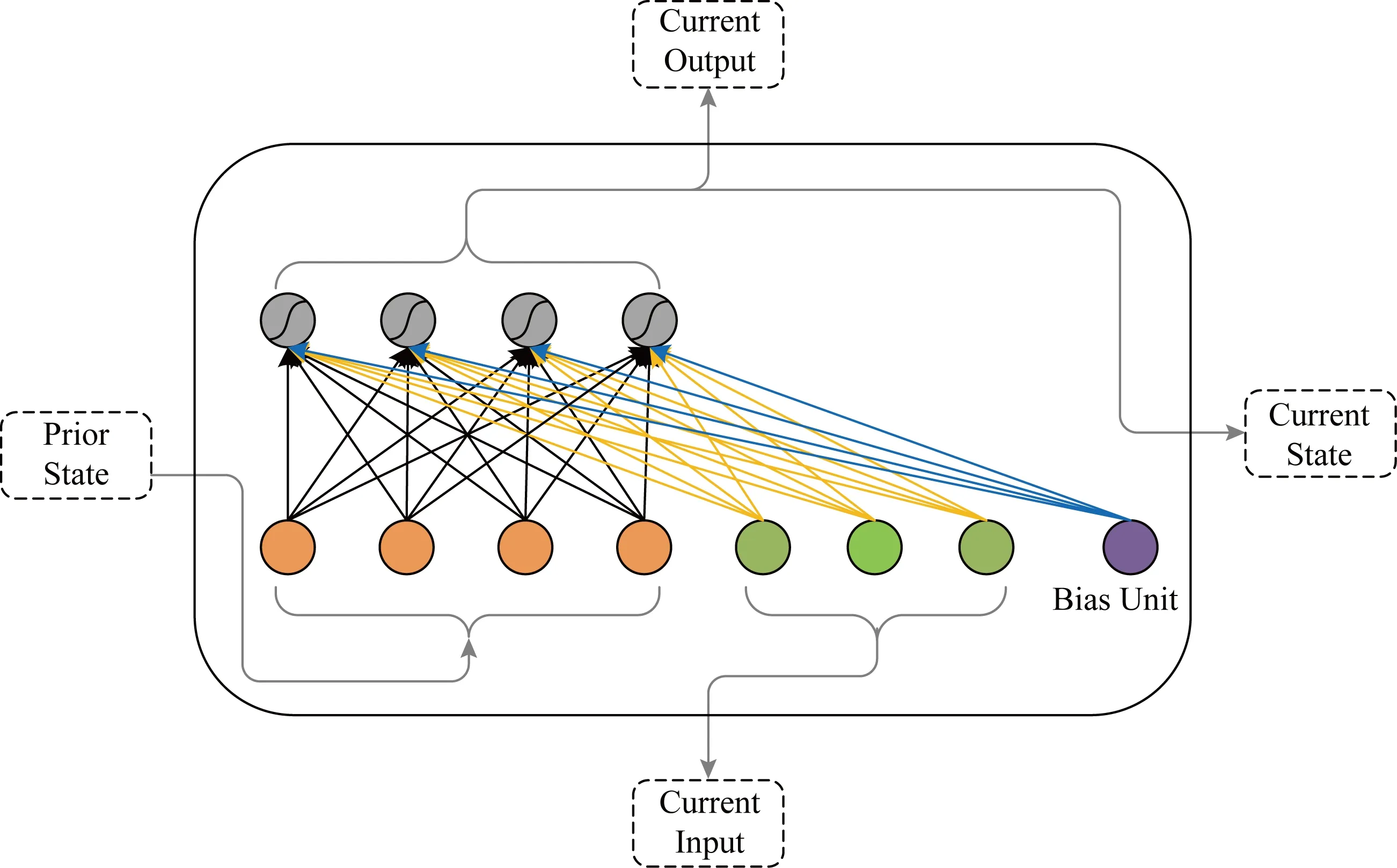
Fig. 2 Basic RNN unit structure圖2 基本RNN單元結構
2 基于IndRNN-Attention的用戶意圖分類方法
本文提出的基于IndRNN-Attention的用戶意圖分類方法模型結構如圖1所示,由輸入層、編碼層、注意力層和分類層組成.
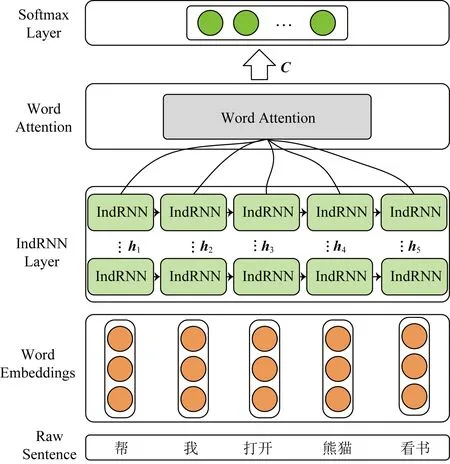
Fig. 1 Architecture of IndRNN-Attention圖1 IndRNN-Attention結構
2.1 輸入層
模型的輸入是用戶輸入的一個句子對應的詞向量矩陣,詞向量由預先訓練好的word2vec模型得到.對于數據集中的任意一個句子,將其分詞后參照數據集中句子的最大長度進行填充,并將句子中的每個詞轉換成對應的詞向量表示,便可得到該句子的詞向量矩陣.
2.2 IndRNN層
RNN被廣泛地應用在動作識別、場景標注和自然語言處理等領域.基本的RNN單元結構如圖2所示.
在RNN中每個神經元接收當前時刻的輸入和上一時刻的輸出作為輸入,時刻t的狀態更新為
ht=σ(Wxt+Uht-1+b),
(1)
其中xt∈RM和ht-1∈RN分別是時刻t的輸入和時刻t-1的隱藏狀態,W∈RN×M和U∈RN×N分別是神經元當前時刻的輸入和循環輸入的權重矩陣,b∈RN是偏置項,σ是神經元激活函數,N是每個RNN層神經元數量,M是輸入層的大小.
RNN在訓練過程中容易出現“梯度消失”和 “梯度爆炸”問題,這使得RNN學習長期依賴關系的能力比較差.為解決這些問題,研究人員提出了長短時記憶網絡[20](long short-term memory, LSTM)和門控循環單元[21](gated recurrent unit, GRU).雖然這2種網絡結構在一定程度上改善了這些梯度問題,但是由于LSTM和GRU使用tanh函數和sigmoid函數作為激活函數,會導致層與層之間的梯度衰減,因此要構建和訓練一個深層的循環神經網絡實際上較困難.
通過使用IndRNN可以有效地解決上述問題.IndRNN單元結構如圖3所示.
IndRNN狀態更新如式(2)所示:
ht=σ(Wxt+U⊙ht-1+b),
(2)
其中,xt∈RM和ht-1∈RN分別是時刻t的輸入和時刻t-1的隱藏狀態,其中W∈RN×M表示輸入層到隱層的權重,U∈RN表示上一時刻隱層到當前隱層的權重,⊙表示哈達馬積(hadamard product).IndRNN中每一層的每個神經元之間都是獨立的,神經元之間的連接可以通過堆疊2層或者多層IndRNN單元實現.對于第n個神經元,時刻t的隱藏狀態可通過計算得到:
hn,t=σ(wnxt+unhn,t-1+bn),
(3)
其中,wn和un分別表示第n行神經元的輸入權重和隱層權重.
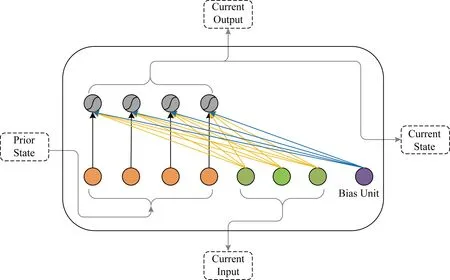
Fig. 3 IndRNN unit structure圖3 IndRNN單元結構
在IndRNN中,每個神經元只接收來自當前時刻的輸入和它本身在上一時刻的隱藏狀態信息,每個神經元獨立處理一種類型的時空模式.傳統的RNN通常被視為通過時間共享參數的多層感知機,而 IndRNN則展現了一種隨著時間步的延伸(通過u)獨立地聚集空間模式(通過w)的新視角.通過堆疊2層或多層神經元,下一層中的每個神經元獨立地處理前一層中所有神經元的輸出,降低了構建深度網絡結構的難度,增強了對更長序列的建模能力.同時,借助ReLU等非飽和激活函數,訓練之后的 IndRNN 魯棒性更高.
2.3 注意力機制層
獲取文本語義表示常用的方法是取編碼器最后時刻的隱藏狀態輸出向量作為最終的編碼向量,優點是一定程度上可以有效地涵蓋文本語義信息,缺點是這種辦法很難將輸入文本的所有信息編碼在一個固定長度的向量中.如果直接將每個時刻的輸出向量相加或者平均,那么可以認為每個輸入的字或詞對計算輸入文本的語義表示結果的貢獻是相等的,這種方法降低了那些對表達文本含義有重要作用的字或詞的貢獻度.
利用智能移動終端幫用戶完成訂機票、導航、訂酒店等是常會發生的情景.例如用戶輸入“上海回合肥怎么坐汽車?”,用戶意圖是查詢路線,屬于“bus”類,在分類過程中“汽車”這個詞對正確分類貢獻最大,所占的權重也應該最高.因此,我們引入詞級別注意力機制來提取對句子含義重要的詞的信息.
給定一個序列S=(w1,w2,…,wT),T表示序列長度.序列S中的第i個詞在時刻t的隱藏狀態hit可由式(3)計算得到,詞級別注意力機制可以通過3個步驟實現:
1) 使用多層感知機獲得hit的隱藏表示uit:
uit=tanh(Wwhit+bw);
(4)
2) 計算uit和詞級別上下文uw的相似性將其作為單詞的重要性度量,通過softmax函數計算歸一化權重αit:
(5)
單詞上下文向量uw是在訓練過程中隨機初始化和共同學習的.
3) 計算句子向量C:
(6)
2.4 分類層
將句子編碼結果C輸入到一個全連接層并使用全連接層的輸出作為句子最終的特征向量,將其輸入softmax層即可輸出各類別的概率.計算方法為
(7)
3 實驗與分析
3.1 數據集
本文實驗數據集來源于SMP2017-ECDT,該數據集覆蓋閑聊和垂直類2大類,其中垂直類細分為30個垂直領域,數據集統計結果如圖4所示:
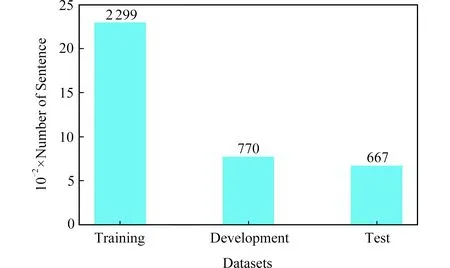
Fig. 4 Size of SMP2017-ECDT dataset圖4 SMP2017-ECDT數據集規模
3.2 評價指標
本文用戶意圖分類是一個多分類問題,我們使用精確率(precision,P)、召回率(recall,R)和F值作為每個類別的評價指標,使用宏平均值(macro-average)作為每種分類方法最終的評價指標,計算方法為
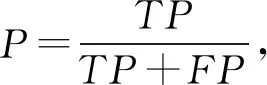
(8)
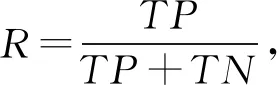
(9)
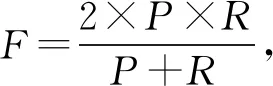
(10)
(11)
(12)
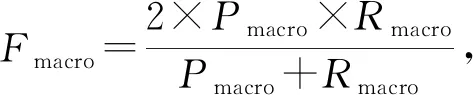
(13)
其中,TP表示將正類預測為正類數,TN表示將負類預測為負類數,FP表示將負類預測為正類數,FN表示將正類預測為負類數,n是類別總數.
3.3 實驗設置
在數據預處理過程中,我們使用結巴分詞工具對用戶聊天文本分詞,并去除了原始文本中包含的標點符號和特殊字符等.
在基于CNN的分類實驗中,設置卷積核大小為3,4,5的過濾器各100個;在基于LSTM的分類實驗中,采用了2層LSTM網絡結構;在基于IndRNN和IndRNN-Attention的分類實驗中,attention_size=128.上述4種實驗中隱藏層大小均設置為128,詞向量的維度設置為300,batch_size=64,Padding的最大長度參考訓練語料中最大文本長度設置為26,在倒數第2層與最后1層的softmax層之間設置dropout_rate=0.5,在softmax層中使用了值為1的l2正則化項.
3.4 結果與分析
3.4.1 實驗結果
5種分類方法在測試語料上的整體分類性能見表2,各個子類別上的F值如表3所示:
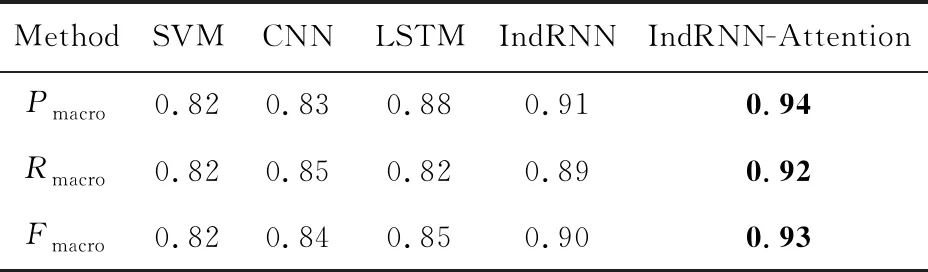
Table 2 Comparison of Overall Classification Result of Different Models表2 各種方法對比實驗結果
Notes: The bold values are the best results obtained by our method.
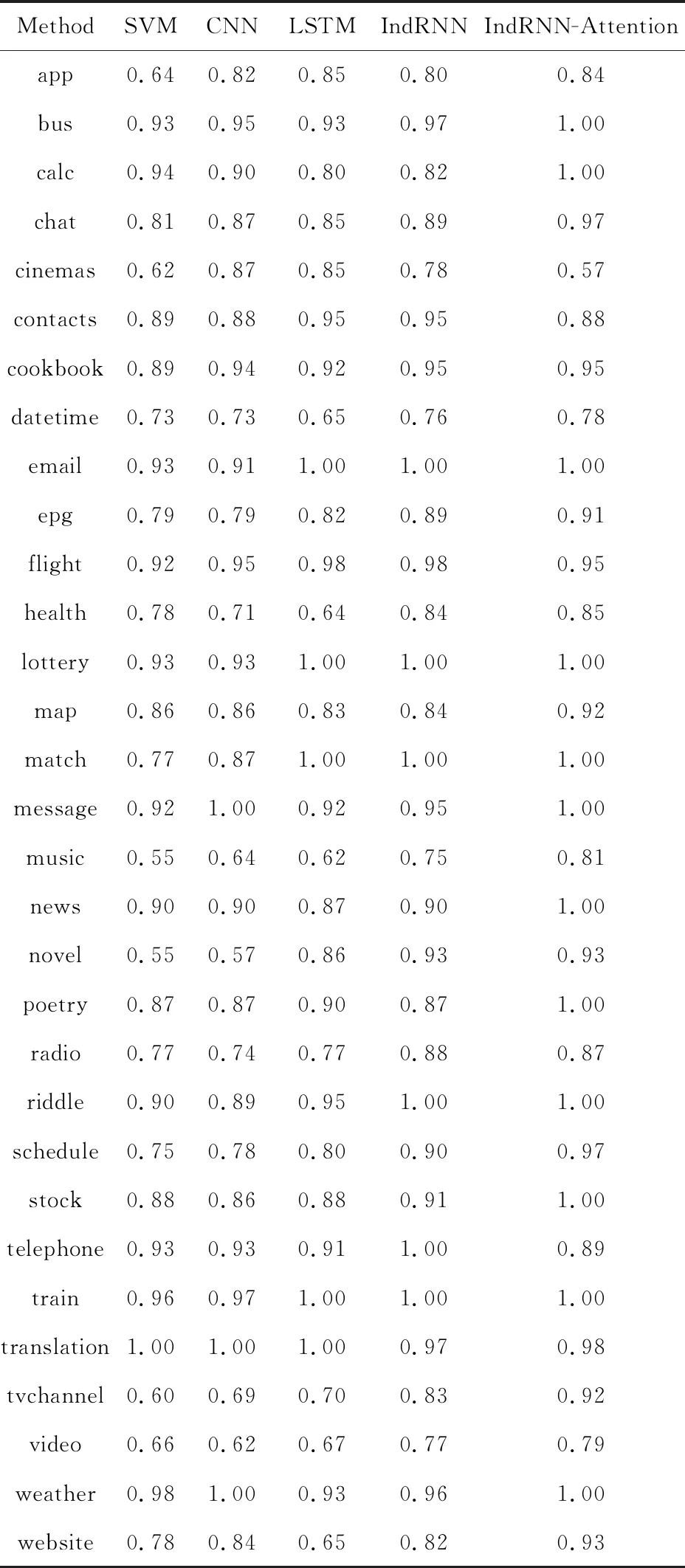
Table 3 F Score Comparison of Different Models onIndividual Category表3 不同方法在每個類別的F值比較
3.4.2 實驗分析
從表2中可以看出:相比其他4種方法(SVM,CNN,LSTM和IndRNN),本文基于IndRNN-Attention的方法取得了最好的分類效果,在Pmacro,Rmacro,Fmacro這3個指標上有顯著的提高.通過對不同方法與本文方法在31個類別上的F值進行統計t檢驗發現,本文方法在所有類別上顯著地(p<0.01)超過了SVM,CNN和LSTM這3種方法,而與IndRNN方法在統計上沒有顯著差異(p=0.067),但在19個類別上,本文方法相對于IndRNN方法有一定提高.
從表2中可以看出,基于SVM的分類方法分類結果最差.可能的原因有2點:
1) 傳統機器學習方法基于特征工程,以詞或者句法結構作為分類特征,難以考慮句子中詞之間的時序關系,也很難將句子表達的語義信息通過固定的分類特征來進行體現.如“上海到北京的火車”和“剛下火車,到上海了”,2句表達在用詞和結構上基本相似,但是表達的意圖不同,使用傳統的機器學習方法很難將其進行準確分類.
2) 驗證集和測試集中的部分句子(驗證集23條、測試集24條)分詞后的結果不在通過訓練集構造的詞典中,導致這些句子的特征表示結果是一個全零向量,影響了模型的訓練和測試.
在基于CNN的分類實驗中,本文采用Kim[14]提出CNN分類結構.CNN可以抽取句子中豐富的局部特征,提高文本表示質量,但是CNN對句子整體的語義結構和上下文時序信息表達不夠,對句子的語義表達不全面,因此分類結果較基于SVM的方法在性能上有所提高,但比其他3種方法(LSTM,IndRNN和IndRNN-Attention)要低.
利用LSTM網絡,不僅考慮到了用戶聊天文本的上下文時序關系對語義的影響,還可以在一定長度范圍內有效處理長期依賴問題.本文采用雙層LSTM網絡結構對用戶聊天文本進行編碼,取隱層最后的輸出作為句子的編碼表示并通過softmax層得到分類結果.
實驗結果表明:基于LSTM的分類方法比基于SVM和CNN的分類方法性能有所提高,但存在一定的問題.LSTM網絡需要依賴原始的詞向量輸入,無法從聊天文本中挖掘句子表達的深層隱含信息,同時存在“梯度消失”和“梯度爆炸”等問題.對比表3發現,基于LSTM的分類方法在部分類別上的性能提高不明顯,反而有所下降,如“calc”,“website”等類別.通過分析實驗結果,我們發現基于LSTM的分類方法將“你知不知道三十四加六十五等于多少”和“幫我算一算45的平方根”等表達錯分到“chat”類別中,而它們的真實標簽是“calc”.
針對這些已有分類方法中出現的問題,本文提出了多層獨立循環神經網絡和詞級別注意力機制融合的用戶意圖分類方法(即IndRNN-Attention),通過堆疊多層IndRNN網絡,構建了一個更深更長的網絡結構對用戶聊天文本編碼,有效地解決了語義信息獲取不足、梯度消失和梯度爆炸等問題;詞級別注意力機制的使用顯著地提高了對聊天文本的編碼質量,增加了對文本含義表達有重要貢獻的相關詞匯的貢獻度,提高了分類性能.圖5是attention權重的可視化示例.

Fig. 5 Attention based weighting sample for a sentence from SMP2017-ECDT dataset圖5 SMP2017-ECDT數據集中一條用戶輸入的注意力權重示例
3.4.3 分類錯誤原因分析
表4是本文提出方法在測試集上分類錯誤的代表性示例:
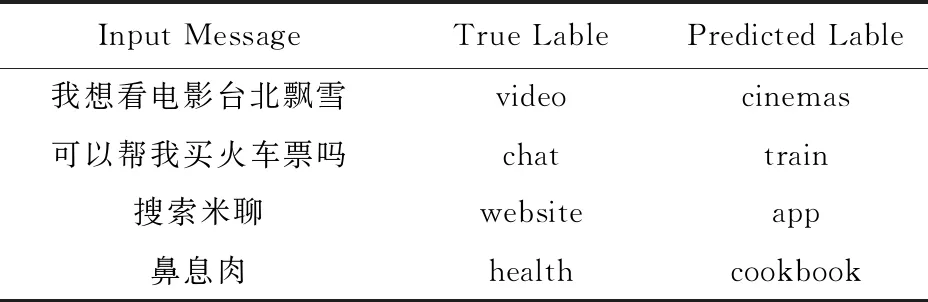
Table 4 Classification Error Samples表4 分類錯誤示例
分類錯誤的原因可歸納為3個方面:
1) 部分類別之間的領域相似度高,用戶輸入的上下文信息嚴重不足.通過對比實驗數據集發現,“website”和“app”,“video”和“cinemas”等類別之間的領域差異較小.對于用戶輸入“搜索米聊”,其中的上下文信息較少,用戶的確切意圖難以區分,表達的意思有可能是想查找手機中安裝的“米聊”軟件,也有可能是想在瀏覽器中搜索“米聊”軟件的信息.在這種情況下,僅根據已有的文本信息無法做出正確的分類,需要結合額外的場景信息或上下文信息來做出判斷.
2) 訓練數據類別分布不平衡.訓練集整體的規模較小,但類別偏多,訓練集在各類別上的數據分布嚴重不平衡,如“chat”,“cookbook”,“video”等類別的訓練數據有幾百條,而“bus”,“calc”,“datetime”等類別僅包含十幾條.在這種情況下,對某些類別或者領域來說,給定的訓練數據遠遠無法覆蓋領域所包含的大量專業術語,如“health”類中的術語“鼻息肉”在該類別的訓練數據集中不存在,從而在測試時模型將“鼻息肉”錯分到“cookbook”類別.
3) 數據集中存在噪聲數據.數據集中存在部分如“瓷我要上QQ”、“天最新新聞”和“你是不是”等表達錯誤或表達不規范的句子,這樣的句子影響模型的訓練效果,也影響測試性能.
4 結 論
本文提出了一種基于獨立循環神經網絡和注意力機制的用戶意圖分類方法,通過構造一個多層獨立循環神經網絡模型和融合詞級別注意力機制的網絡結構實現對用戶聊天文本的編碼,解決了傳統循環神經網絡中出現的“梯度消失”和“梯度爆炸”等問題,提高了領域相關詞匯對用戶聊天文本編碼的貢獻度,增強了句子表示能力.在SMP2017-ECDT評測數據上的實驗表明,本文方法取得了最好的分類效果,Fmacro值達到0.93,與本文實驗中其他4種方法相比顯著提高了用戶意圖分類的效果.
在后續工作中,我們將嘗試在神經網絡結構中引入各類外部語義知識庫來進一步提高用戶意圖分類的性能.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
