基于深度學習的水質預測模型研究
2019-07-11 07:09:40涂吉昌陳超波王景成葉強強
自動化與儀表 2019年6期
涂吉昌,陳超波,王景成,2,王 召,葉強強
(1.西安工業大學 電子信息工程學院,西安710021;2.上海交通大學 自動化系,上海200240)
水質預測是水環境綜合管理的重要一環。近年來,我國經濟高速發展,工業及生活用水量劇增,水資源的短缺和水資源污染成為我國經濟社會發展面臨的重大問題[1]。研究水源地高精度水質預測模型,能夠提前預測出水環境水質污染的可能性,有助于及時地發現區域內的水環境問題,積極地保護好水源地水質環境,為管理和維護當前水源地的水質狀況提供重要依據。
目前,對于水質預測領域,國內外學者做了大量的研究。傳統的水質預測模型主要有時間序列模型[2]、回歸分析模型[3]、灰色系統理論模型[4]以及神經網絡模型[5]等。傳統的預測模型往往只關注數據本身的特點,而沒有充分考慮到數據之間的相互關聯性,預測精度普遍不高,難以對水環境水質參數進行精確的預測監控。隨著智能硬件的計算性能不斷提升,深度學習以及人工智能得到高速的發展,人工智能不斷地滲透到國民生活以及工業控制的方方面面,深度學習也積極地應用于工業領域。循環神經網絡等作為深度學習領域的重要組成成分,由于其充分考慮時序數據的長期依賴關系,能夠很好地處理時序數據,如今在語音識別、機器翻譯、推薦系統以及數據預測等方面都有了很好地應用[6]。
綜上可知,深度學習的不斷發展,為水質預測領域發展提供了新的預測思路以及巨大的機遇。但總體而言,在水質預測領域,深度學習方法的應用仍處于初步探索階段。本文提出了一種基于深度學習的門控型循環神經網絡水質預測模型,為精確地預測水質參數提供了新的方法與模型。
1 模型介紹
1.1 循環神經網絡
循環神經網絡RNN(recurrent neural network)是一種前饋型神經網絡[7],通過引入狀態變量,實現對時序數據中過去信息的存儲。其隱含層的輸入由兩部分組成,既包括了本時刻上一網絡層的輸出,也包含了上一時刻隱含層的輸出,即隱含層節點之間是相互連接的,當前隱含層輸出受上一層影響,通過隱含層的存儲單元,可實現對前面信息的記憶。因此,循環神經網絡能夠很好地對時序數據進行處理,循環神經網絡的結構如圖1所示。
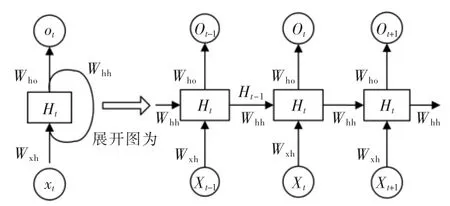
圖1 循環神經網絡結構圖Fig.1 Recurrent neural network structure
循環神經網絡(RNN)的訓練時前向傳播的過程,如下式所示:
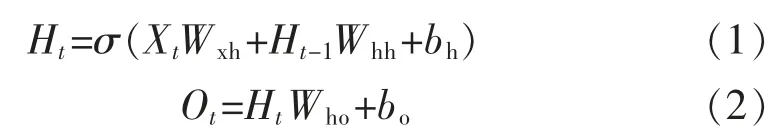
式中:Ht、Ot分別為隱含層和輸出層的輸出值;Wxh、Whh、Who分別為輸入層到隱含層、上一隱含層到當前隱含層以及隱含層到輸出層的連接權值;bh為隱含層偏置;bo為輸出層偏置。
由式(1)可知,循環神經網絡(RNN)的隱含層輸出主要由相鄰時間步的隱含狀態變量Ht和Ht-1組成,與多層感知機(MLP)相比增加了Ht-1Whh一項,其隱含狀態變量Ht捕捉存儲了截至當前時間步的時序數據中的歷史信息,對時序數據的相互依賴性有了很好的處理。
RNN 網絡隱含層的結構特點使得RNN 網絡能夠對歷史時刻信息進行“記憶”并影響本時刻的輸出,有效地解決了時序數據存在的長期依賴的問題。但在訓練過程中,RNN 網絡利用隨機梯度下降算法基于時間反向傳播迭代優化參數時,如果時間步數較大或較小時,RNN 的梯度較容易出現衰減或爆炸的問題[8]。
1.2 門控型循環神經網絡
門控型循環神經網絡(gate recurrent neural network)是一種新型RNN 優化網絡模型[9],它比當前流行的LSTM 網絡缺少一個遺忘門,因此更容易收斂,目前也有了廣泛的應用[10-12]。它通過3 個特殊的門結構來控制數據信息的流動,有效地解決了RNN 容易出現的梯度衰減或爆炸的問題。隱含層中的門控循環單元GRU(gate recurrent unit)通過引入重置門(reset gate)和更新門(update gate),來改變循環神經網絡中隱含層狀態變量的計算方式,實現對傳統RNN 網絡的優化。門控循環單元結構如圖2所示。
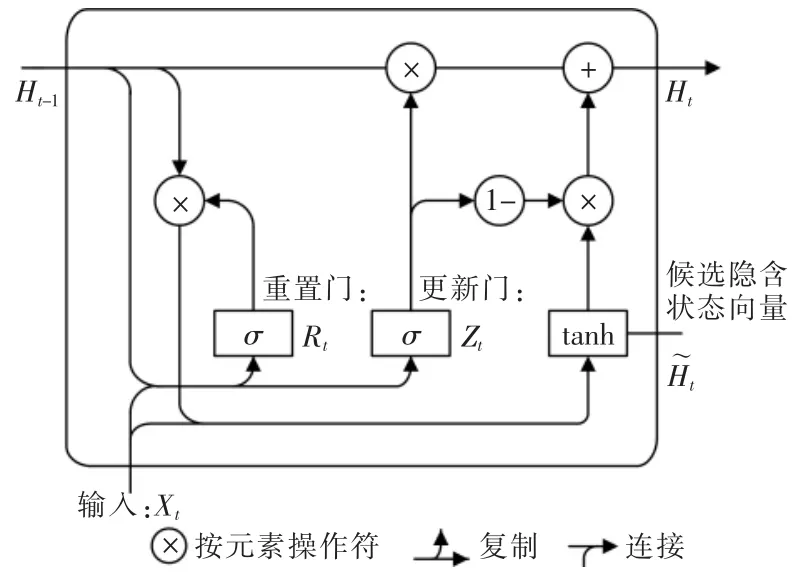
圖2 門控循環單元結構圖Fig.2 Structure of the gated recurrent unit
其中,重置門Rt實現了對上一時刻狀態信息的忽略程度的控制,其值越小則代表對上一時刻忽略的越多。更新門Zt實現了對上一時刻狀態信息傳遞到當前時刻的程度的控制。其值越大則代表上一時刻的狀態信息帶入的越多。重置門用于捕捉時序數據中存在的短期依賴關系。更新門用于捕捉時序數據中存在的長期依賴關系。
GRU 循環網絡訓練時前向傳播的計算步驟如下:
步驟一計算重置門的輸出值,上一時刻隱含狀態向量Ht-1和當前時刻輸入值Xt一起輸入到重置門,得到一個0~1 的重置門輸出值,值越大,信息保留的越多。計算公式如式(3)所示;
步驟二計算更新門的輸出值以及候選隱藏狀態變量,當前輸入Xt和上一時刻隱含狀態Ht-1進入更新門的輸出0~1 的數值,同時通過tanh 層創建一個候選隱含狀態,計算公式如式(4)、式(5)所示;
步驟三計算當前時刻的隱含狀態向量,將更新門輸出值作為權重向量,候選隱含狀態向量和上一時刻隱含狀態向量通過加權平均得到當前時刻的隱含狀態向量Ht,計算公式如式(6)所示;
步驟四計算網絡輸出值,將當前時刻隱含狀態向量加權與輸出層偏置相加,再共同輸出最終值Yt,計算公式如式(7)所示。
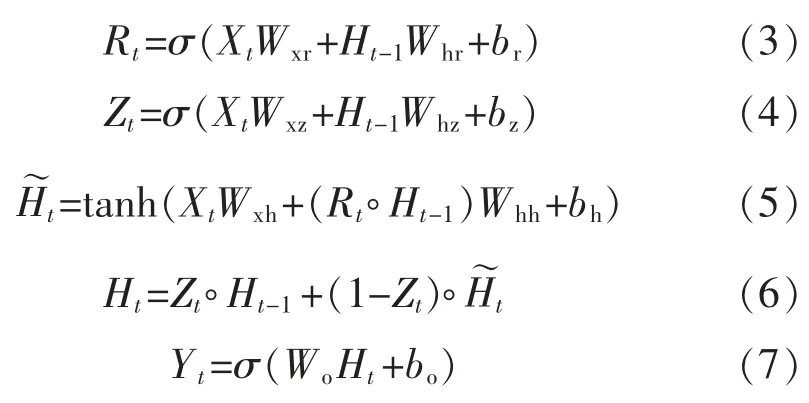
式 中:σ 為激活函數;Wxr、Whr、Wxz、Whz分別為輸入層到重置門、隱含層到重置門、輸入層到重置門、隱含層到更新門的連接權值;br、bz分別為重置門和更新門的偏置;“?”為矩陣按位相乘。從GRU 網絡的前向傳播過程可以看出,訓練網絡需要學習的參數主要有重置門、更新門以及輸出層的連接權值及其偏置。
GRU 網絡的訓練過程,主要是結合實際情況,確定GRU 網絡的最佳網絡結構(即:輸入神經元個數和隱含層神經元個數,以及隱含層層數),選擇合適的激活函數和恰當的優化算法;根據誤差損失函數,通過隨機梯度下降算法,依次迭代更新直到誤差損失收斂,獲得最優參數;最后根據最優參數建立GRU 網絡模型。流程如圖3所示。
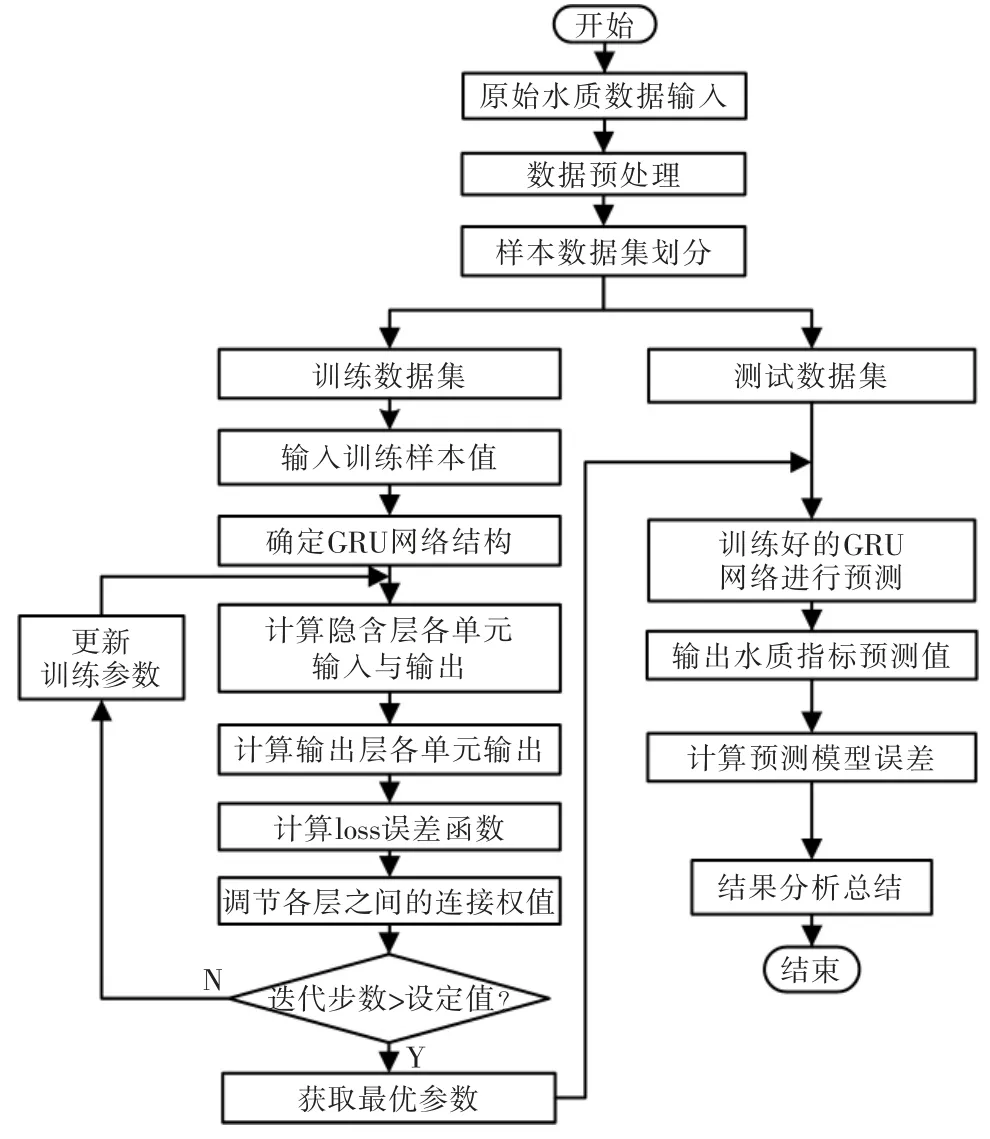
圖3 GRU 網絡訓練流程Fig.3 GRU network training flow chart
2 水質預測
2.1 數據描述
本次實驗仿真的水質數據,來自于上海市主要水源地上海金澤水庫的2017年5月31日至2017年12月30日主要水質指標化學需氧量(COD)的真實監測數據,并按每分鐘采集221 天的COD 水質數據,共有300520 個監測值數據。將數據集中前210天的監測值數據作為訓練集,后3 天的監測值數據定義為測試集,通過訓練集訓練預測模型,利用測試集測試模型的性能。
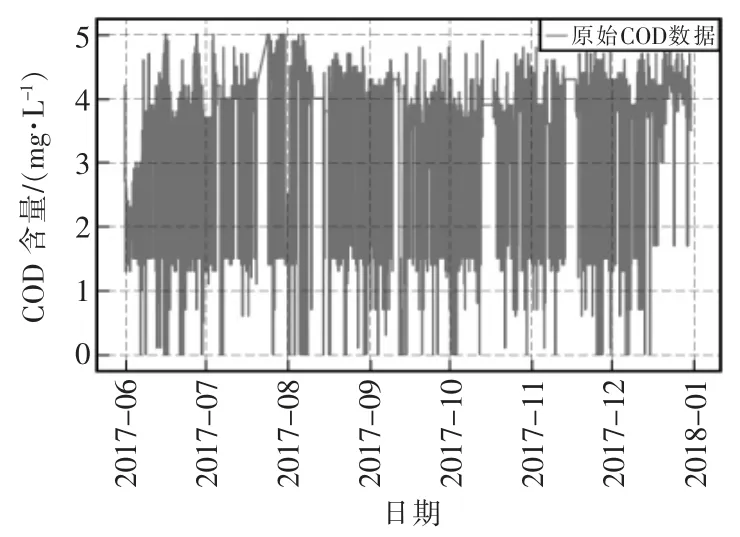
圖4 原始COD 數據測量值圖Fig.4 Original COD data measurement value map
2.2 數據處理
由于本次實驗仿真的數據直接來源于上海市金澤水庫現場傳感器采集的實測數據,因此會受到測量環境因素以及測量儀器的影響,如果直接進行實驗仿真,可能存在較大的誤差。為了保證實驗仿真的科學性和預測模型的精確性,所以必須對原始監測數據進行一系列的處理,再利用處理后的數據進行模型訓練以及實驗仿真。
2.2.1 缺失值處理
為了保證數據集的連續性,減小不確定性,增強模型輸出的可靠性,本文利用K 最近距離鄰法對缺失值進行填充。
2.2.2 異常值處理
為了減小模型預測誤差,增強模型預測精度,對于異常的水質數據,先利用閾值篩選法檢測異常值的位置,再利用K 最近距離鄰法對異常值進行替換清洗。
2.2.3 數據標準化
為了使得循環神經網絡反向傳播更容易收斂,對原始水質數據進行離差標準化,使數據映射到[0,1]區間,計算公式如下:

式中:xs為原始水質數據標準化后的數據值;x 為原始水質數據;xmax和xmin分別為原始水質數據中的最大值和最小值。
2.3 評價指標
本文采用平均絕對百分比誤差MAPE、均方根誤差RMSE 2 個指標來衡量與評估各種水質預測模型的性能,其計算公式如下:

式中:n 代表水質數據個數;xi代表第i 個水質數據的真實值;pi代表第i 個水質數據的預測值;MAPE、RMSE 代表水質預測模型的預測精度,其值越小,模型預測精度越高,預測模型性能越好。
2.4 實驗仿真
本次實驗基于Python 語言,在Python 庫函數statsmodels、sklearn、thensorflow 以及keras 等的基礎上,分別搭建并訓練經典水質4 種預測模型。其中有基于統計理論的自回歸移動平均模型(ARIMA)、基于傳統機器學習的支持向量回歸模型(SVR)、基于深度學習的傳統循環神經網絡模型(RNN)以及門控型循環神經網絡(GRU)4 種水質預測模型,實現對水質數據的預測,通過交叉驗證以及不斷地試錯,探究這幾種預測模型的最佳參數,同時對比驗證這幾種預測模型在水質預測領域不同的性能表現。
基于統計理論的ARIMA 預測模型中,由于原始數據集時間間隔為1 min,數據集過大可能造成模型處理效率低,對原始數據進行每3 h 的重采樣形成1707 個數據點,最終通過ACF、PACF 圖確定模型的最佳參數,自回歸項數p 為1,差分階數d 為1,移動平均項數q 為1,預測結果如圖5所示。
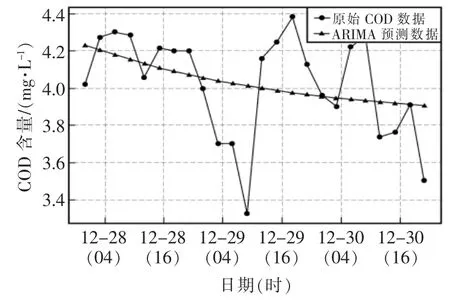
圖5 基于ARIMA 模型的COD 預測結果圖Fig.5 COD prediction results based on ARIMA model
基于傳統機器學習的SVR 預測模型中,模型輸入同樣選擇時間間隔為3 h 的數據進行輸入訓練,核函數選為徑向基函數,懲罰因子C 為1,核函數參數gama 為0.1,預測結果如圖6所示。
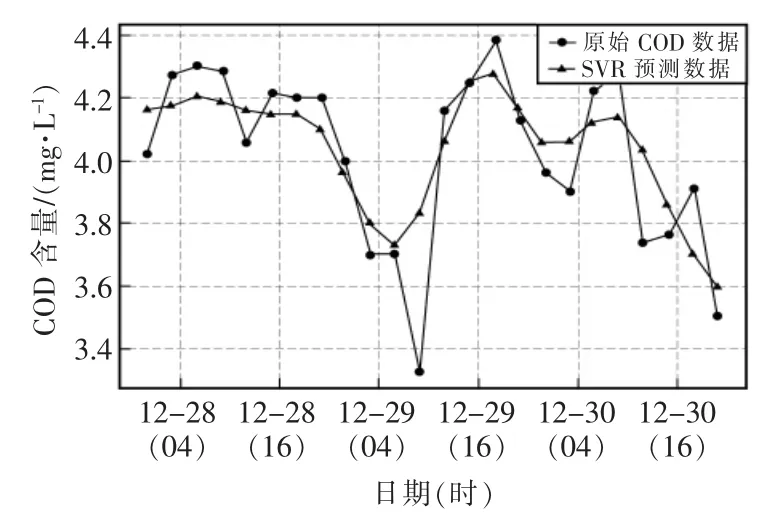
圖6 基于SVR 模型的COD 預測結果圖Fig.6 COD prediction results based on SVR model
基于深度學習的RNN和GRU 網絡模型中,模型訓練集的輸入形式為滯后10 個數據點組成的10維向量,輸出形式為1 維標量,網絡包含1 個輸入層、1 個輸出層以及2 個隱含層,2 個隱含層存儲單元個數為分別為50和100,激活函數為tanh 函數。兩種模型的水質預測結果圖分別如圖7、圖8所示。
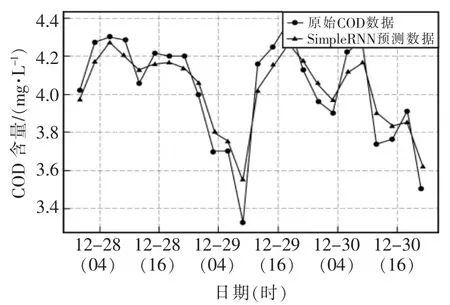
圖7 基于SimpeRNN 模型的COD 預測結果圖Fig.7 COD prediction results based on SimpeRNN model
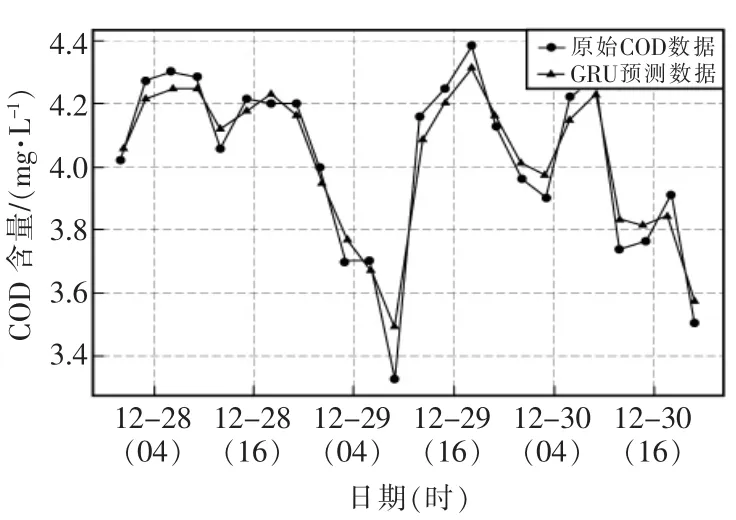
圖8 基于GRU 模型的COD 預測結果圖Fig.8 COD prediction results based on GRU model

表1 四種模型預測結果性能指標Tab.1 Performance index of prediction results of four models
通過對比4 種模型對COD 水質數據不同的預測結果,可以看出,基于統計理論的時間序列預測法ARIMA(1,1,1)模型的預測精度最差,RSME 達到了0.2522,MAPE 也達到了0.73%,只能粗略地估算出COD 水質數據具有稍微下降的趨勢,在水質預測方面性能較差;基于傳統機器學習的SVR 預測模型在本次水質預測方面性能也不是很高,RSME 僅為0.155,MAPE 也為0.58%,能夠大體的擬合真實數據。兩種基于深度學習的RNN 模型以及GRU 模型在水質預測方面都有較好的表現,RNN 模型的RSME 僅為0.098,MAPE 也只有0.26%,GRU 模型表現更好,RMSE 為0.0641,MAPE 為0.18%,具有更好的水質預測精度,可以很好地逼近水質數據真實值,是一種性能較高的水質預測模型。
3 結語
針對水環境水質參數具有非線性、隨機性以及依賴性等特點,本文提出了一種基于深度學習的門控型循環神經網絡的水質預測模型。通過構建最佳網絡結構,探尋最佳網絡參數,建立了基于GRU 網絡的水質預測模型,很好地將深度學習理論引入到水質預測管理領域中。實驗仿真表明,與傳統的ARIMA 模型和SVR 模型相比,基于GRU 網絡的水質預測模型具有更小的RSME 與MAPE 值,能夠顯著的提高水質預測的精確度,可以很好地逼近水質數據真實值,是一種新型的高精度水質預測模型。
根據目前的工作,對于水質預測領域,筆者認為可以進一步考慮建立結合多種因素指標共同影響下的水質參數預測,進一步提高模型的預測精度;同時也可以尋求更有效參數優化算法對GRU網絡進行優化,提高模型的預測性能,也可以將GRU模型進行改進推廣以適用于更多數據預測領域。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電腦愛好者(2019年17期)2019-10-30 03:34:48
快樂作文(5.6年級)(2019年5期)2019-09-10 05:59:05
當代水產(2019年1期)2019-05-16 02:42:04
山西教育·招考(2018年4期)2018-05-30 10:48:04
光學精密工程(2016年6期)2016-11-07 09:07:19
河南科技(2014年23期)2014-02-27 14:19:07
