基于Python爬蟲的大學校園公眾號開發
2019-07-10 07:11:54梁金龍鄒小林
珠江教育論壇 2019年1期
梁金龍,鄒小林
據統計,目前微信注冊用戶數量已接近10億[1]。由于微信用戶具有量大,關注度高、支持群發等特點,政府部門、企業、事業單位、協會、商家、學校,甚至個人都紛紛注冊使用公眾號。但很多公眾號被受眾關注得不多,主要原因是這些公眾號難以提供有質量的推文和服務。為了提高公眾號的關注度,一些高校教師進行了調查研究,有研究[2]認為用戶的期望確認、感知有用、感知娛樂、內容豐富度以及感知服務質量都顯著影響用戶對公眾號滿意度和持續使用意愿。也有研究[3]認為高校微信公眾號的使用意愿主要受到感知有用性、感知娛樂性與信息感知質量3 個因素影響。可見微信公眾號的有用性、娛樂性與有質量的信息是至關重要的。針對校園公眾號被關注較少這個問題,采用Python網絡爬蟲技術對公眾號進行二次開發,在注冊的公眾號中增加公眾號推文、網絡新聞、網絡笑話等信息自動推送,為學校校園文化建設提供可行方案。
一、公眾號的二次開發接口
微信公眾號與開發者的服務器搭建后,可以通過調用公眾號的接口實現公眾號二次開發。微信平臺提供的公眾號接口有“獲取access_token”接口、“接收事件推送”接口、“自動回復”接口、“自定義菜單”接口。
調用“獲取access_token”接口時,需要傳遞3 個參數:grant_type、appid和secret,其中授權類型參數grant_type是客戶端證書client_credential;參數appid 是公眾號開發識別碼ID;參數secret是開發者密碼。采用https的GET請求方式調用“獲取access_token”接口,請求的網頁地址是https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=APPID&secret=AppSecret。“自定義菜單”接口的傳輸參數為access_token和自定義菜單數據包。采用https請求的POST方式調用“自定義菜單”接口,請求的網頁地址是https://api.weixin.qq.com/cgi- bin/menu/create?access_token=ACCESS_TOKEN。自定義菜單數據包結構是Json 結構,Json 結構以“名稱值對”形式儲存信息,代碼類似為:{"button":[{"name":"網絡爬蟲", "sub_button": [{"type": "click", "name": "微信公眾號推文","key":"V1"}]}]}。其中名稱為"button"的值是一級菜單列表,可在里面創建3 個一級菜單;第一個"name"的值是一級菜單名;"sub_button"的值是二級菜單列表,可在里面創建5 個二級菜單;"type"的值是二級菜單的響應動作類型,有click 和view 等類型;第二個"name"的值是二級菜單名,"key"的值是二級菜單的KEY 值,可自定義。其中click是點擊推送事件,用戶點擊click類型按鈕后,微信服務器會通過“接收事件推送”接口推送XML 結構數據給開發者,并且帶上按鈕中開發者填寫的KEY 值,開發者可以通過KEY值與用戶進行交互。
“接收事件推送”接口是微信服務器把POST 消息的XML 類型數據包推送給開發者服務器,即微信用戶和公眾號產生交互的過程中,開發者可以通過接口獲取用戶的操作信息。XML 數據包中包含開發者微信號(ToUserName)、微信用戶帳號(FromUserName)、消息創建時間(CreateTime)、消息類型(MsgType)、事件類型(Event)和事件KEY 值(Event-Key)。開發者根據消息類型、事件類型和事件KEY 值對微信用戶的操作進行判斷和處理。
“自動回復”接口是開發者服務器把回復消息的XML結構數據包推送給微信服務器。“接收事件推送”接口與“自動回復”接口同時調用,實現公眾號自動接收并回復用戶消息,可以回復文本信息、圖片信息、圖文信息等。“自動回復”接口回復的消息類型不同,XML 結構數據包需要傳遞的參數也不同,但每個數據包都必須傳遞3 個參數:微信用戶帳號(ToUserName)、開發者微信號(ToUserName)和消息創建時間(CreateTime)。特別強調:“自動回復”接口傳輸的ToUser-Name 和FromUserName 與“接收事件推送”接口接收的相反,開發時要分清楚。“自動回復”接口采用https 請求POST方式調用。
二、網絡爬蟲相關原理
網絡爬蟲是一種按照特定規則,自動抓取網絡信息的程序或者腳本[4]。網絡爬蟲的結構如圖1 所示,一般包括初始URL、網頁爬取模塊、網頁分析模塊和數據庫,其中網頁爬取模塊和網頁分析模塊是核心模塊。
python爬蟲網頁爬取模塊的爬取方法通常有源碼爬取、抓包爬取。源碼爬取是用python 發起HTTP 請求直接獲取網頁的HTML源代碼;抓包爬取則是爬取HTTP請求中的傳輸數據包,通過對數據包url的直接訪問爬取數據包。
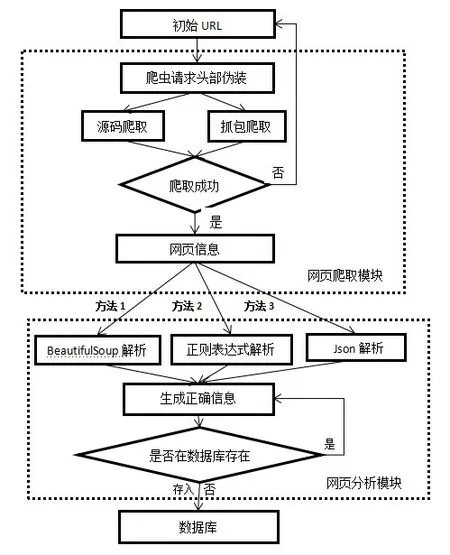
圖1 網絡爬蟲原理圖
網頁分析模塊解析方法包括正則表達式解析、Beautiful-Soup解析和Json解析。正則表達式是由一系列特殊字符和普通字符組成的字符集合[5],可匹配網頁源碼中特定字符串,提取相應信息;BeautifulSoup解析則是應用Python第三方庫Beautiful Soup 進行解析,Beautiful Soup 將復雜的HTML 網頁轉換成一個復雜的樹形結構,樹形結構每個節點都是Python 對象,所有對象可以歸納為4 種:Tag、BeautifulSoup、NavigableString、comment。Tag 對象與XML 或HTML 原生文檔中的tag 定義相同;NavigableString 類對象被Beautiful Soup用來包裝tag中的字符串,NavigableString 字符串與Python 中的Unicode 字符串定義相同;BeautifulSoup 對象表示的是一個文檔的全部內容,大部分時候,可以把它當作Tag對象;Comment 對象是一個特殊類型的NavigableString 對象。Beautiful Soup 庫支持最常用的CSS 選擇器,在Tag 或BeautifulSoup 對象的select()方法中傳入對象的字符串參數,即可使用CSS 選擇器的語法找到該Tag[6],通過getText()方法可獲取Tag 中字符串。Json 是一種輕量級的數據交換格式,以“名稱值對”形式儲存信息,易于機器解析和生成,所以網絡傳輸數據一般采用Json。Json 解析是應用Python 第三方庫“json”解析Json結構的數據包,根據Json數據包中的“名稱”獲取“值對”信息。Json 解析使用方法有dumps()和loads(),dumps()是將Python對象編碼成JSON 字符串,loads()是將字符串解碼為Python 對象。
三、工作思路
開發工作主要包括2部分:大學校園公眾號開發平臺搭建和大學校園公眾號二次開發。大學校園公眾號開發平臺搭建包括:公眾號驗證綁定服務器、用接口工具自定義公眾號的菜單;在云服務器上開發接收和處理微信信息的程序,搭建數據庫存放信息,封裝XML 數據包。大學校園公眾號二次開發包括:開發微信公眾號推文爬蟲,開發新聞爬蟲和開發段子爬蟲,將爬蟲部署到公眾號。
大學校園公眾號開發的技術思路如圖2 所示。用戶進行某個操作的消息會發到微信服務器;微信服務器發送消息的XML 數據包給開發者服務器;開發者服務器接收并解析數據包,判斷事件類型;如果消息不是自定義菜單事件,回復success,微信服務器確定開發者收到了粉絲消息,不會提示公眾號異常;如果是自定義菜單事件,根據事件KEY值判斷用戶點擊的爬蟲菜單,查詢該需求的爬蟲信息是否存在于數據庫;如果是,從數據庫提取信息,封裝成特定的XML 數據包,回復給微信服務器;如果否,運行相應的爬蟲爬取信息,存入數據庫再提取給微信服務器。
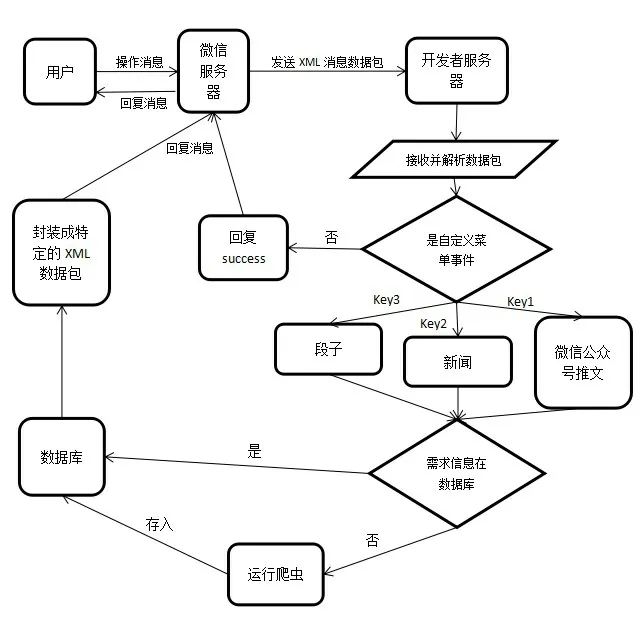
圖2 大學校園公眾號開發的技術思路圖
四、大學校園公眾號開發平臺搭建
(一)公眾號綁定開發者服務器
本文公眾號二次開發環境包括:web.py為網絡框架,python為開發語言和騰訊云服務器。運用web.py搭建網頁,復制微信公眾平臺技術文檔[7]中“搭建服務”的測試代碼main.py 到開發者服務器,用命令提示符執行命令:sudo python main.py 80,即可搭建能接收微信服務器信息的網頁。完成后,登錄公眾平臺官網,在菜單“基本設置”中開啟公眾號的開發者模式,在“服務器配置”中修改配置。需要修改的參數有url、Token,其中“url”填寫開發者服務器搭建的網頁地址,“Token”可以自主設置,只用于驗證開發者服務器。點擊提交按鈕,微信公眾平臺會對開發者服務器進行驗證,若token驗證成功,會自動返回基本配置的主頁面,點擊啟動按鈕,即可綁定開發者服務器。
(二)創建公眾號的菜單
創建公眾號的菜單需要調用“獲取access_token”接口獲得access_token,再調用“自定義菜單”接口創建菜單。開發者可使用微信公眾平臺中“開發者工具”的在線接口調試工具,調用這2 個接口獲得access_token 和創建菜單。使用在線接口調試工具獲得access_token 需要修改的參數有appid和secret,修改好參數后,點擊“檢查問題”按鈕,即可在返回結果中獲得access_token。使用在線接口調試工具創建菜單的方法是,在“接口類型”中選擇“自定義菜單”,在“接口列表”中選擇“自定義菜單創建窗口”,粘貼access_token和菜單的Json 結構代碼,點擊“檢查問題”按鈕,就可以創建菜單了[8]。本文設置3 個一級菜單網絡爬蟲、學習資源、學園活動;3個二級菜單:微信公眾號推文、新聞、段子;響應動作類型都是click;KEY值分別是“V1”“V2”“V3”。
(三)開發者服務器的消息處理
微信服務器通過“接收事件推送”接口把消息的XML類型數據包推送給開發者服務器。因本文以web.py 搭建網頁,可以用web.data()方法獲取微信服務器的XML 數據包。復制微信公眾平臺技術文檔[7]中“入門指引”的解析XML文檔receive.py,用以解析XML 數據包,獲取開發者微信號(ToUserName)、微信用戶帳號(FromUserName)等信息。根據XML 數據包中的消息類型(MsgType)、事件類型(Event)和事件KEY 值(EventKey)判斷用戶點擊的菜單。如果事件KEY值是“V1”,表明用戶點擊的菜單是“微信公眾號推文”,執行代碼根據微信用戶帳號查詢數據庫中用戶表的公眾號推文編號,如果編號小于數據庫中公眾號推文表的公眾號推文表,則說明數據庫存量充足,可直接從數據庫中提取信息,以圖文消息類型回復用戶;如果存量不足,則微信公眾號推文爬蟲爬取信息,存入數據庫,再回復消息。如果事件KEY值是“V2”,表明用戶點擊的菜單是“新聞”,如果事件KEY值是“V3”則是“段子”,處理邏輯與點擊“微信公眾號推文”的處理邏輯類似,不過“新聞”以圖文消息類型回復消息,“段子”以文本消息類型回復消息。
(四)數據庫的搭建
在服務器下載并安裝MySQL 數據庫,運用Python 的MySQLdb 庫連接和操作數據庫。用MySQLdb.Connect()的方法創建數據庫的連接“conn”,該方法可以指定數據庫的參數:用戶名,密碼,主機等信息;通過獲取到的數據庫連接“conn”下的cursor()方法來創建游標;通過游標操作execute()方法可以寫入純sql 語句;運用sql 語句創建、查詢和更新表格。本文創建的數據庫的表主要有學生用戶表user_info、段子爬蟲表jokes_spider、新聞爬蟲表new_spider和公眾號推文表article_spider。學生用戶表user_info 記錄著用戶名、段子爬蟲編號、新聞爬蟲編號、公眾號推文編號;段子爬蟲表jokes_spider 記錄著段子爬蟲編號、段子內容;新聞爬蟲表new_spider記錄著新聞爬蟲編號、新聞網址、新聞標題、新聞圖片地址、新聞簡介;公眾號推文表article_spider 記錄著公眾號推文編號、公眾號推文網址、公眾號推文標題、公眾號推文圖片地址、公眾號推文簡介。
(五)封裝特定的XML數據包
公眾號調用“自動回復”接口給用戶回復消息時,需要傳輸特定的XML數據包。開發者需封裝XML數據包,以在回復消息時調用。開發者根據用微信公眾平臺技術文檔[7]中“入門指引”的XML封裝文檔reply.py,把回復文本信息和圖文信息的XML 結構封裝成函數。例如,封裝文本信息的XML 數據包需要3 個參數:toUserName、fromUserName 和Content,Content 是回復消息的文本內容。以Python 的字典構造函數dict()建造一個空字典,在字典里建立映射關系。其中,用戶帳號toUserName 映射到ToUserName;開發者微信號fromUserName映射到FromUserName;數據庫提取的信息Content 映射到Content;運用Python 中time 庫的time()方法記錄消息創建的時間,并映射到CreateTime。根據微信公眾平臺技術文檔[7]中的回復文本信息的XML結構,運用Python的format()方法結構化文本信息的XML數據包,即可封裝完畢。
向用戶回復文本信息的XML 結構如下。
五、大學校園公眾號的二次開發
(一)開發微信公眾號推文爬蟲
微信公眾號的推文可通過搜狗搜索網站的微信搜索出,微信公眾號推文爬蟲可爬取微信搜索頁獲得推文信息。其工作流程是用源碼爬取微信搜索頁的url 獲取網頁源代碼;運用BeautifulSoup 的css 選擇器獲取推文標題和推文簡介;用正則表達式獲得推文的圖片地址和網頁地址,但是正則表達式解析出的網頁地址并不能直接打開網頁,需要把網頁地址中的字符“amp;”替換成空格,才能是正確的網頁地址;查詢已經在數據庫中的公眾號推文編號,給爬取的公眾號推文進行編號,最后存入數據庫。
微信公眾號推文爬蟲的核心程序如下:


圖3 是一個網上推文,圖4 是開發的爬蟲爬取該推文放到公眾號的界面。
圖3 網上推文

圖4 公眾號上爬取的網上推文
(二)開發新聞爬蟲
今日頭條有豐富的實時新聞,新聞爬蟲可爬取今日頭條的熱點新聞。其工作原理是運用抓包爬取模塊爬取今日頭條熱點的新聞數據傳輸包;應用json 解析庫解析新聞數據包,獲取新聞的標題、簡介、網頁部分地址、圖片地址;并將網頁部分網址生成完整的網頁網址;查詢已經在數據庫中的新聞爬蟲編號,給現爬取的新聞進行編號,最后存入數據庫。
微信公眾號新聞爬蟲的核心程序如下:

圖5 是今日頭條新聞,圖6 是開發的爬蟲爬取該新聞放到公眾號的界面。
圖5 今日頭條新聞
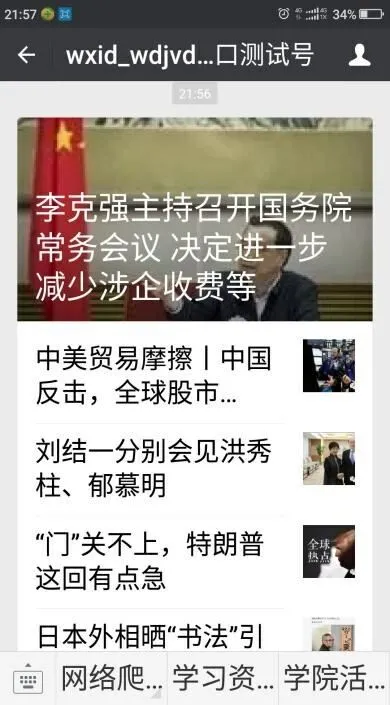
圖6 公眾號上爬取的新聞
(三)開發段子爬蟲
糗事百科的笑話中有非常豐富的搞笑素材,段子爬蟲可運用源碼爬取糗事百科網頁中的段子笑話。通過分析發現,糗事百科的笑話內容被標簽包裹,為避免使用css 選擇器時返回的數據格式不正確,用Python的分割函數split()將源代碼切割成n個分段,每個分段有一個笑話內容。段子爬蟲通過BeautifulSoup的css選擇器提取每個分段中的段子信息,查詢已經在數據庫中的段子爬蟲編號,給現爬取的段子進行編號,最后存入數據庫。圖7是糗事百科的笑話,圖8是開發的段子爬取該段子放到公眾號的界面。

圖7 糗事百科笑話

圖8 公眾號上爬取的笑話
微信公眾號段子爬蟲的核心程序如下:


六、小結
在當代,微信用戶很多。為了更便捷的發布消息或者為了給企業做廣告,很多單位甚至個人注冊并使用公眾號,但是很多公眾號被受眾關注得不多,主要原因是這些公眾號難以提供有質量的推文和服務。針對公眾號不能自動推送消息,本文采用Python網絡爬蟲技術對公眾號進行二次開發,實現了對公眾號推文、網絡新聞、網絡笑話等信息的自動推送,為校園文化建設提供了可行方案。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
中國信息化周報(2016年46期)2017-03-25 17:35:29
中國信息化周報(2016年47期)2017-03-25 17:33:41
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
中國信息化周報(2016年9期)2016-03-21 19:47:42
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中國信息化周報(2015年27期)2015-08-12 22:09:31
中國信息化周報(2015年28期)2015-08-06 22:08:50
