基于國產GPU的GLSL編譯器設計?
2019-07-10 08:18:30彭獲然熊庭剛胡艷明
計算機與數字工程 2019年6期
彭獲然 熊庭剛 胡艷明 黃 亮
(武漢數字工程研究所 武漢 430205)
1 引言
在圖形處理器不斷發展的過程中,圖形應用對可編程能力的需求日益增長,高級著色語言應運而生。開發者通過使用高級著色語言編寫著色器來自定義發生在圖形處理流程中關鍵處的處理過程,利用底層的圖形硬件實現更多樣復雜的渲染效果[1]。圖形驅動中的著色語言編譯器便承擔起編譯著色器的任務,并在圖形渲染管線中扮演重要角色,其生成的機器代碼的質量會直接影響圖形渲染的效果和效率。
2 GLSL和OpenGL中的著色器
GLSL 是OpenGL 規范中用來編寫著色器的高級著色語言,其語法源于C 語言,二者的源碼非常相似,這使得著色器的編寫和閱讀對于有C 語言基礎的開發者來說更加容易。在OpenGL 2.0中,開發者可使用GLSL version1.10 編寫頂點著色器和片段著色器程序。圖1 展示了應用程序中OpenGL 著色器的執行模型,應用程序通過OpenGL API 中的函數調用編譯器對著色器源碼字符串進行處理,得到可執行機器碼。
3 GLSL編譯器設計
本文的GLSL 編譯器的流程如圖2 所示。其前端包含預處理、詞法分析、語法及語義分析和中間代碼生成;其后端包含代碼優化和鏈接,最終生成目標機器代碼。編譯器前后端之間使用一種標準的中間表示形式進行過渡,便于使用相對成熟的機器無關的優化技術[2]。
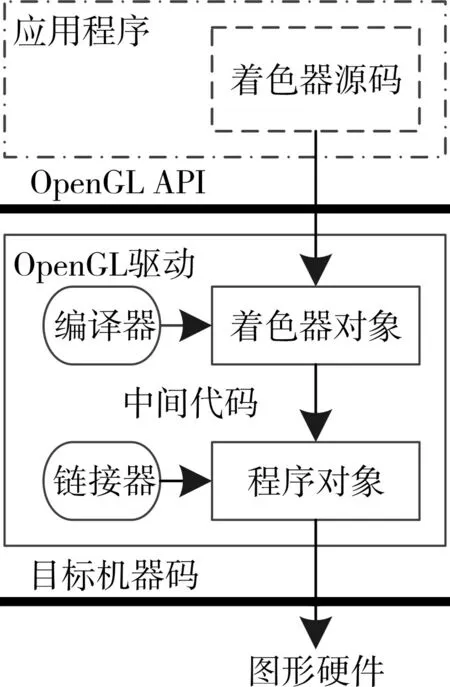
圖1 OpenGL著色器執行模型
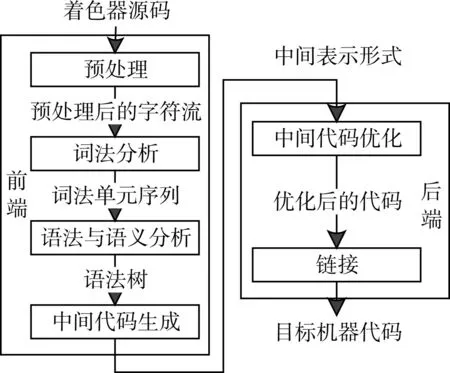
圖2 GLSL編譯器流程
3.1 GLSL編譯器前端設計
GLSL編譯器前端負責讀入著色器源碼并生成基于中間表示形式的中間代碼。首先前端根據GLSL 的預處理指令對著色器源碼進行預處理,包括宏定義的替換和條件編譯部分源碼的刪減等。GLSL 的預處理指令的功能和使用方法與C 語言類似,存在少量區別(如沒有#include 指令等),在GLSL的官方文檔中有詳細說明[3]。
3.1.1 詞法分析
GLSL編譯器前端的核心部分包含詞法分析和語法語義分析。詞法分析器讀入預處理后生成的字符流,剔除其中的注釋部分并組織成有意義的詞素序列;對于每個詞素,詞法分析器產生詞法單元作為輸出,包含行號信息、詞素類型及詞素的值,詞素類型有標識符、操作符、關鍵字、常量以及空白符。其中標識符、操作符和關鍵字的值為其字符串,常量的值即為其本身的值,空白符沒有值。本文使用開源的Flex工具根據GLSL的詞法規則生成詞法分析器,其工作流程如圖3所示。
使用Flex來生成詞法分析器時,需要用正則表達式(Regular Expression,RE)這一強大的符號表示法來描述目標語言的字符模式[4]。描述GLSL 的標識符的代碼如下所示,標識符由字母、下劃線和數字組成且開頭不能是數字:
identifier{nodigit}({nodigit}{|digit})*
nodigit [_A-Za-z]
digit [0-9]
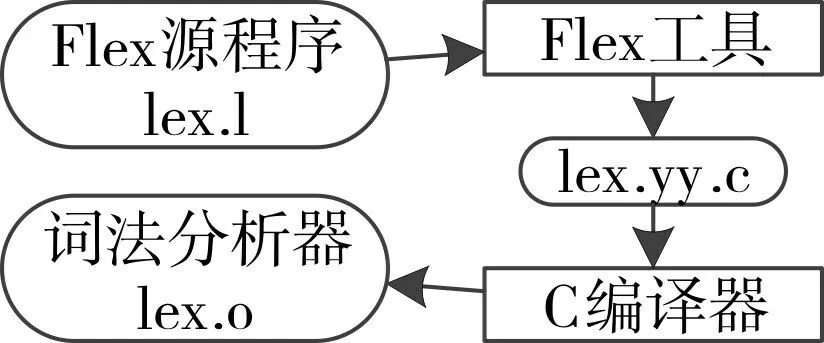
圖3 Flex和詞法分析器
常量(包括八進制、十進制、十六進制的整數和浮點數)也用類似的方法描述其模式,空白字符和操作符采用逐個列舉的方式,關鍵字則使用關鍵字列表從標識符中區分出來。
以圖4 中這段頂點著色器源碼example.vert 為例,經詞法分析會生成如下詞法單元序列(行號信息在此省略):(關鍵字 ,“attribute”),(關鍵字,“vec4”),(標 識 符 ,“my_Vertex”),(操 作 符 ,“;”)……(標識符,“gl_Position”),(操作符,“=”),(標識符,“my_TransformMatrix”),(操作符,“*”),(標識符,“my_Vertex”),(操作符,“;”),(操作符,“}”)。

圖4 頂點著色器源碼示例example.vert
3.1.2 語法分析與語義分析
在詞法分析完成后,語法分析器獲得一個詞法單元序列,根據GLSL的語法識別其中的語法成分,并驗證其結構可以由GLSL 的語法生成,否則進行錯誤處理。此外,語法分析器還需要檢查前述序列是否符合GLSL的語義,例如類型是否匹配,被使用的變量是否已定義等;若著色器語法語義正確,語法分析器將根據著色器中的語句構造語法樹,語法樹中的每個內部節點表示一個運算,而該節點的子節點表示該運算的分量[5]。本文所述編譯器的語法分析器采用開源的Bison 工具生成,其工作流程如圖5所示。

圖5 Bison和語法分析器
使用Bison 生成語法分析器時,在Bison 源程序中使用LALR(1)語法來描述目標語言的語法規則[6]。圖6 是Bison 源程序中描述語法規則的部分片段,包括動作函數的參數類型定義,終結符定義,變量標識符的模式和相應動作。著色器的詞法單元序列會在語法分析器中匹配到具體的語法范式,并執行該范式對應的動作函數,完成著色語言程序語法樹的創建。

圖6 Bison程序片段
以example.vert為例,經過語法分析后得到圖7所示的語法樹,同時生成名字信息表(部分名字信息表見表1)。

表1 部分名字信息
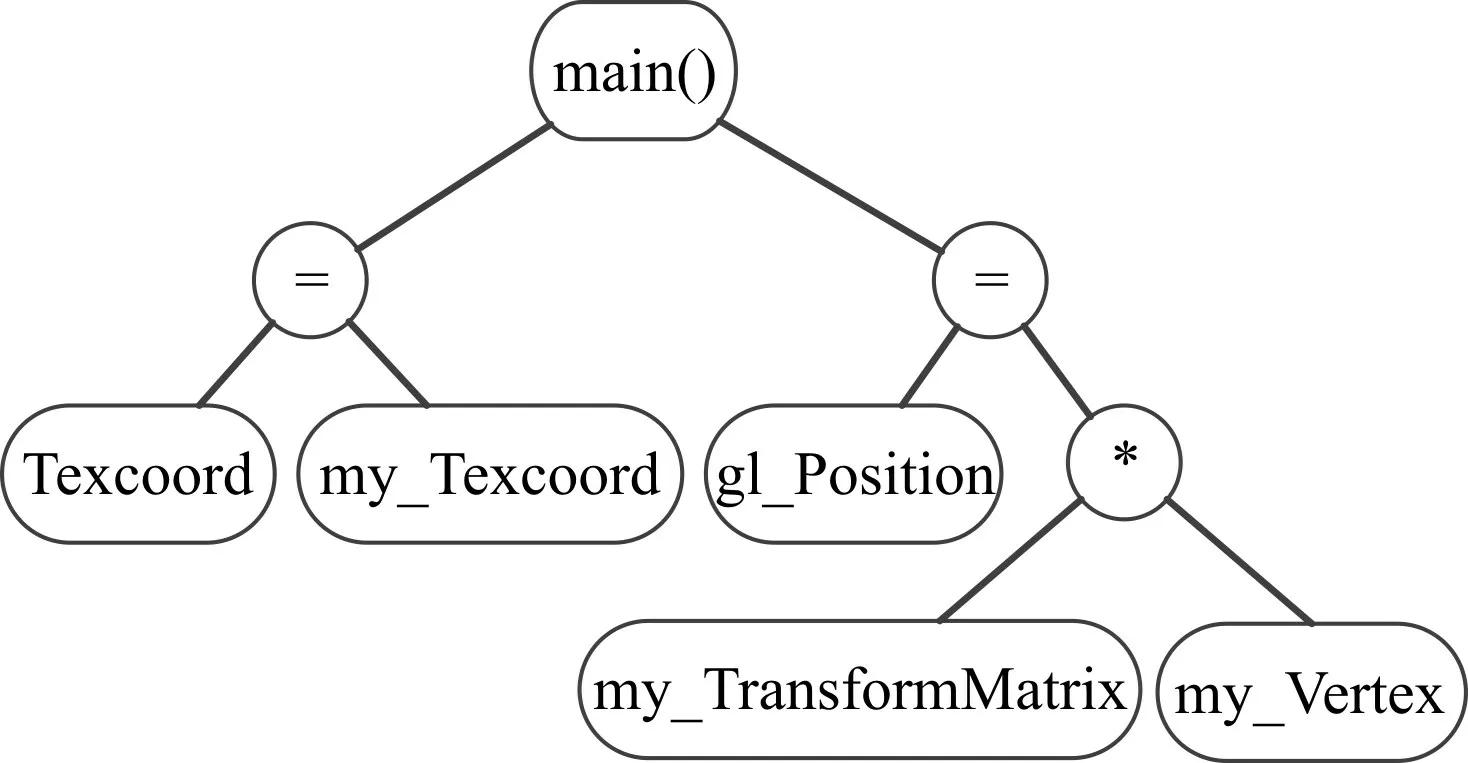
圖7 example.vert的語法樹
由于三地址代碼拆分了多運算符算術表達式以及控制流語句的嵌套結構,比較適用于目標代碼的生成和優化,故本文所述編譯器采用三地址碼作為中間表示形式。對于GLSL,三地址代碼中的地址可以是屬性(Attribute)、一致變量(Uniform)、著色器中明確定義的變量、輸出變量(Output)、臨時變量和常數。
首先將語法分析器輸出的語法樹轉換為三地址代碼語法樹,轉換的過程中需要根據目標GPU平臺的指令集作一些變換。以圖7 語法樹為例,由于目標GPU 平臺的乘法指令只支持標量或四分量向量作操作數,故將矩陣乘法拆分為多條向量乘法和加法指令,得到如圖8所示三地址代碼語法樹。
接下來通過深度優先遍歷三地址代碼語法樹可得到如表2 所示的三地址代碼中間表示形式,中間表示可輸出到文本文件中方便調試(注:表2 中OP 代表操作符,DST 代表目的操作數,SRC 代表源操作數)。
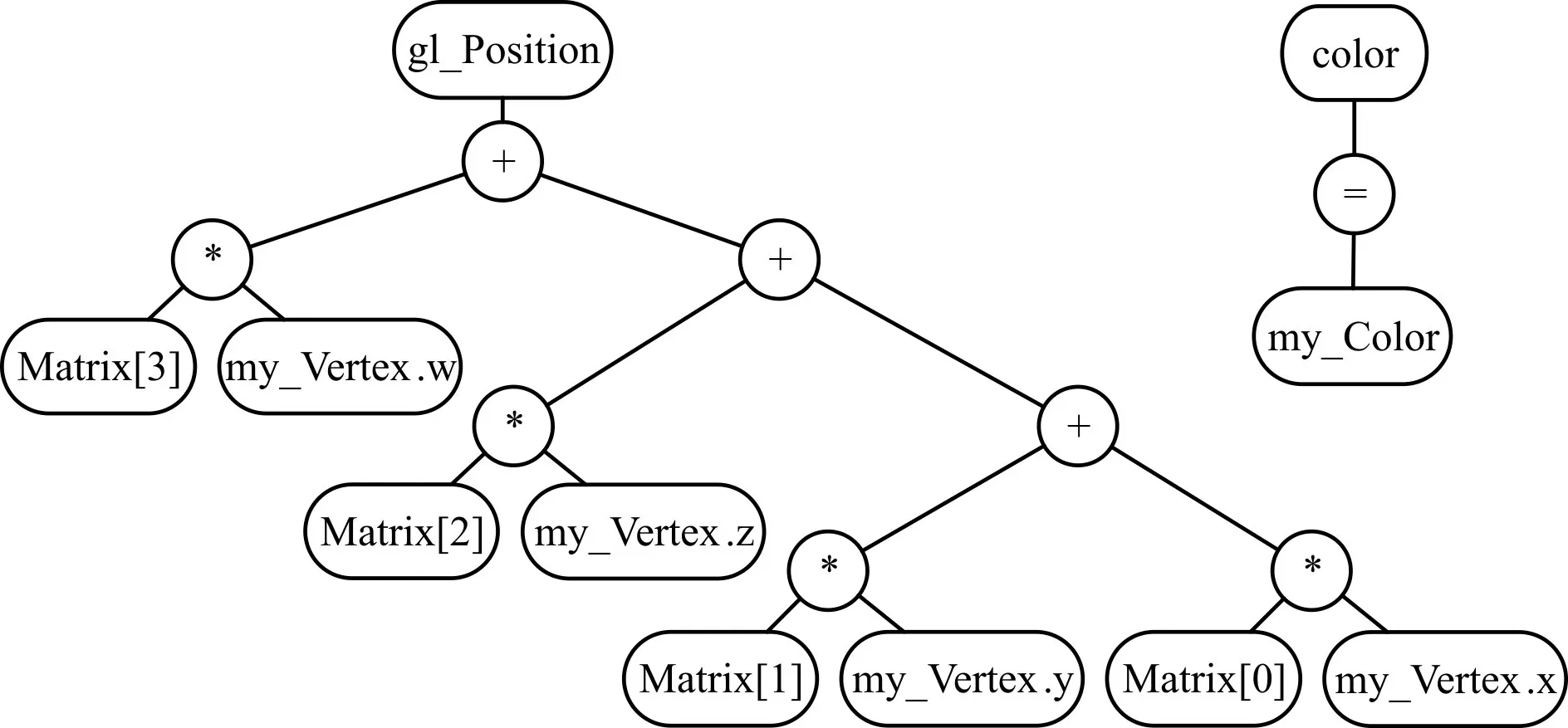
圖8 三地址代碼語法樹
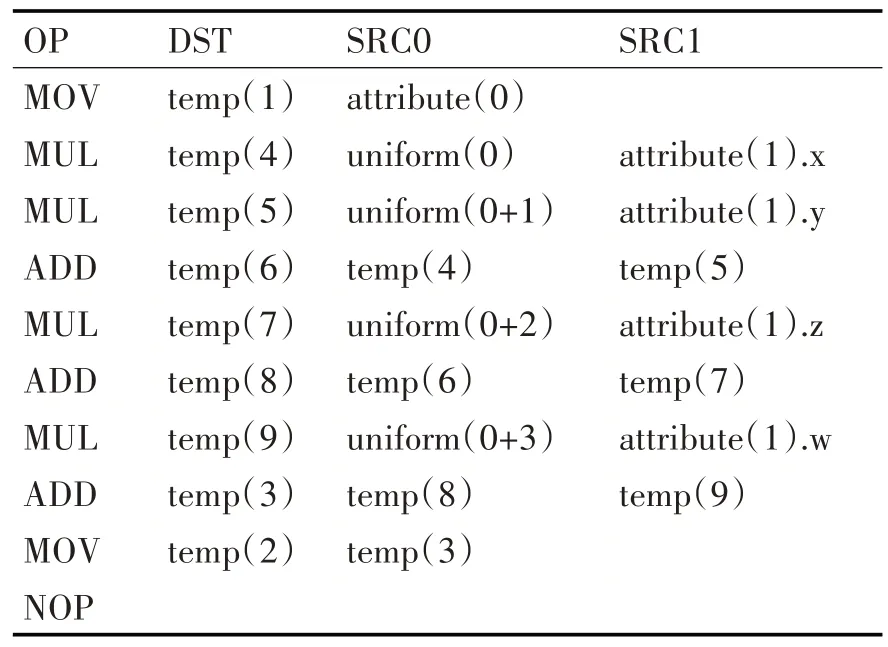
表2 三地址代碼中間表示形式
3.2 GLSL編譯器后端設計
GLSL 編譯器后端讀入中間代碼,由代碼優化模塊負責對其優化,通過改進中間代碼,以達到生成更好的目標代碼的目的。鏈接模塊則要完成鏈接樹的創建,并根據鏈接樹來分配物理寄存器資源并設置相應寄存器模式,最終生成符合GPU 指令集的目標機器代碼。
3.2.1 優化
優化部分分為機器無關的優化和機器相關的優化。本文所述編譯器采取的機器無關代碼優化方式包含:死代碼消除,函數展開,常量傳播,冗余判斷消除,公共子表達式消除,循環展開和代碼移動等較為成熟的中間代碼優化技術[7~10]。
而針對所用國產GPU 的SIMD 指令集架構,本文采取的機器相關代碼優化包含乘加指令優化和向量指令合并。具體如下。
1)乘加指令優化:由于目標機器的指令集包含乘加指令,且著色器一般包含大量乘法和加法運算,乘加指令優化將大大提高程序的性能;如果一條加法指令只依賴之前的一條乘法指令,且乘法指令的目標使能與加法指令一致,相應的乘法指令和加法指令可以被合并成一條乘加指令。
例如MUL R0 R1 R2
//R0 ←R1*R2
ADD R3 R4 R0
//R3 ←R4+R0
兩條指令若滿足條件可優化為
MAD R3 R1 R2 R4
//R3 ←R4+(R1*R2)
2)合并向量指令:目標機器的指令集基于向量指令,提高向量指令的利用效率是代碼優化的重要目標;對于多條具備相同指令碼的指令,如果其相應操作數可分配到同一向量寄存器上而不影響運算結果,便可合并為一條向量指令,向量指令合并可降低代碼長度同時減少寄存器使用量[11]。
例如:[x,y,0,0]←[a,b,0,0]+[c,d,0,0]
[0,0,z,w]←[0,0,e,f]+[0,0,g,h]
兩條語句可以合并為:
[x,y,z,w]←[a,b,e,f]+[c,d,g,h]
example.vert 的三地址代碼經過優化之后,用偽代碼表示如表3 所示,指令數量得到明顯的精簡。
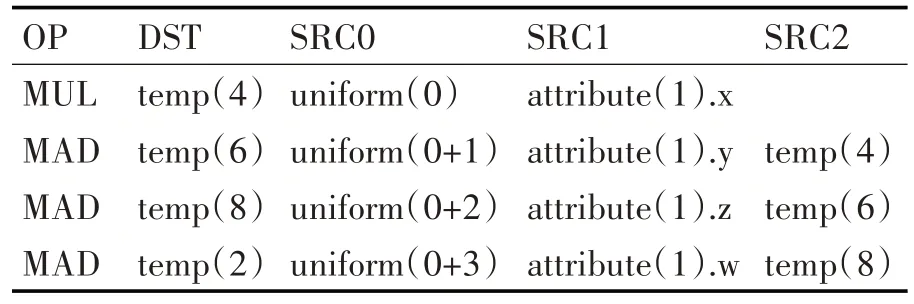
表3 優化之后得到的代碼
3.2.2 鏈接
目標機器碼的鏈接由鏈接器完成,鏈接器負責鏈接樹的創建,并根據鏈接樹來分配國產GPU 中的物理寄存器資源并設置相應寄存器模式,最終生成符合國產GPU 指令集的目標機器代碼。鏈接器的工作主要有兩方面要求:生成高效率的目標機器代碼和有效地利用目標機器上的可用資源。
由于只涉及寄存器運算分量的指令要比那些涉及內存運算分量的指令運行快得多,而GPU 的寄存器資源又非常有限,因此如何提升寄存器資源的利用效率成為鏈接階段的一個重要工作內容。如果一個變量的值存放在寄存器中,而之后一直不會被使用,那么這個寄存器就應該被分配給另外一個變量[12]。表4 簡單地展示了寄存器分配的這一基本思路(其中uniform(0)為矩陣,由連續四個寄存器按順序分別存儲一列元素,各列使用相對尋址訪問),相對于表3 減少了三個臨時寄存器占用而不影響程序結果。
為了有效利用寄存器資源,需要綜合考慮函數調用及循環嵌套,記錄屬性、變量和輸出的使用信息以及各條指令代碼的啟示性信息,包括當前代碼屬于哪個函數體,當前代碼調用者,當前代碼最深的函數嵌套層次,當前代碼對應的臨時寄存器的后續使用信息[13~14]。

表4 example.vert程序寄存器分配示意
鏈接器最后需要輸出目標機器代碼。國產GPU 的指令集包括常用算術運算,超越函數計算,流程控制和紋理操作等。指令集支持一個目的操作數和三個源操作數。源操作數可以任意取反或取絕對值;指令支持源操作數和目的操作數的任意分量選擇;目的操作數可設置飽和操作;指令支持相對尋址模式。為了更好地契合國產GPU 的指令集架構,且保證代碼轉化的靈活性,本文采取模式匹配的方法生成機器代碼[15],具體步驟如下:
第一步,將指令指針IP 設置到中間代碼起始位置;
第二步,模式指針PP 設置到目標模式起始位置;
第三步,判斷模式對應指令數是否大于剩余未轉換的中間代碼,若是,進入第四步;否則進入第五步;
第四步,模式指針PP 設為下一模式起始位置并重復第三步;
第五步,從模式指針PP和指令指針IP開始,逐條判斷各指令是否匹配,若模式得到完整匹配便生成該模式對應的機器指令代碼并進入下一步,否則執行第四步;
第六步,指令指針增加已匹配模式對應指令數,若所有中間代碼已完成匹配,結束流程,否則執行第二步。
4 實驗與結果
本文使用如圖9 所示的頂點和片段著色器對編譯器進行基本功能測試。
頂點著色器經編譯器處理得到如表5 所示偽代碼。
片段著色器經編譯器處理得到偽代碼如表6所示。
應用程序輸出渲染效果如圖10 所示,說明著色器經編譯器編譯可正常工作,驗證了編譯器的基本功能。

圖9 測試用著色器

表5 實驗頂點著色器優化后偽代碼

表6 實驗片段著色器偽代碼

圖10 渲染效果
5 結語
本文根據GLSLv1.10的特點,借助Flex與Bison工具設計了GLSL 編譯器的前端;以三地址碼作為中間表示使后端可以應用多種成熟的機器無關代碼優化技術,并針對國產GPU 平臺的SIMD 指令集架構應用乘加指令優化和向量指令合并進一步優化代碼;最終鏈接生成目標機器代碼。該編譯器可將GLSLv1.10 編寫的著色器編譯成該國產GPU 平臺上可執行的代碼,為國產GPU 對OpenGL 規范的支持做出了一定的貢獻,由于對應的版本相對落后,與今天商用平臺的仍有很大差距,今后仍需進一步拓展編譯器功能,以支持更高版本的GLSL,同時繼續深入研究編譯過程中的優化技術,以提高輸出機器碼質量。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
現代企業(2015年2期)2015-02-28 18:45:09
