圖概要技術研究進展
2019-06-26 10:05:14董一鴻施煒杰潘劍飛
計算機研究與發展 2019年6期
關鍵詞:結構
王 雄 董一鴻 施煒杰 潘劍飛,2
1(寧波大學信息科學與工程學院 浙江寧波 315211)2(百度在線網絡技術有限公司 北京 100085)
隨著數據量的爆發式增長[1],人們對數據的處理識別能力并沒有因為計算資源和存儲能力的提高而提升.圖結構數據[2]能夠在許多應用中表現實體對象之間復雜的關系,如用戶交互形成的社交網絡[3]、電話信息組成的通信網絡[4]、學者合作形成的研究網絡[5]、網頁瀏覽形成的Web網絡[6]、用戶產品和服務購買的交易網絡[7]、行程和道路組成的交通網絡[8]、垃圾噪音數據組成的過濾網路[9],以及化學化合物互相作用的生物網絡[10]等.圖數據隨處可見,在大數據背景下圖數據的規模日益增大,截至2017年6月Facebook的月活躍用戶數已達20億,Twitter的月活躍用戶數保持在3.2億,騰訊的QQ保持8.61億月活躍用戶,微信則超過9.6億[11-12],社交網絡已成為連接網絡信息空間和人類現實世界不可或缺的橋梁.
然而,這種連接關系所構成的大規模圖結構數據具有上億頂點和千億條邊,對于這樣的社交網絡圖是無法直接加載內存進行處理;現有的大多數算法對于這類大圖不能有效處理,尤其是涉及到圖流實時分析決策時,無法及時反饋給用戶需要的信息;現實生活中的數據往往含有很多隱藏的錯誤信息標簽,例如WEB網絡圖中錯誤的鏈接以及一些垃圾郵件的傳播[13]、病毒的擴散[14]等,這種噪音阻礙了用戶對原始圖真實結構特征的挖掘,增加了計算資源的消耗.大圖數據的這些缺陷使得用戶難以直接管理,給社會網絡分析和數據挖掘帶來了挑戰.
針對大規模圖數據的概要化是潛在的解決方案,圖的概要化(graph summarization)[15],簡稱圖概要,運用各種圖形操作技術,尋找一組簡潔的超圖或稀疏圖,闡明原始圖的主要結構信息或變化趨勢,代替原始大圖進行數據分析.它一般針對大規模的圖數據,在一定的應用背景下,考慮時間、空間和信息之間的權衡,量化頂點或邊緣的屬性相似性和鄰域相似性,縮小原始圖的規模,保留一些應用價值屬性,支持用戶的互動分析,或者濾除噪聲數據.一個優秀的概要圖涵蓋了原始圖中主要的結構特征,其頂點稱為超級頂點(簡稱超點),它代表原始圖中一組相近頂點的集合;其邊稱為超級邊(簡稱超邊),它代表2個頂點集合之間的聯系.圖概要既可以揭露實體之間隱藏的復雜關系,又可以保持原圖的性質,有效減少圖的存儲空間,提高圖計算的效率.
通常,圖概要概念的不同表述還有圖概括(graph synposis)[16]、圖聚集(graph aggregation)[17]、圖規約(graph simplification)[18-19]等,而圖采樣(graph sampling)[20-21]、圖聚類(graph clustering)[22-23]、圖壓縮(graph compression)[24-25]與圖概要有緊密的聯系,但最終的目標又不盡相同.
圖采樣與圖概要的目標都是創建一個原始圖的簡短表示[26],進行有效的算法分析.不同點在于圖采樣是通過局部子圖特征來估計原始圖的屬性,例如頂點采樣和邊采樣,進行圖的稀疏化以縮小圖的規模,如何進行有代表性、有普遍性的采樣是其研究的核心,但會導致圖結構特征大量丟失;而圖概要則從全局出發,合并高度相似的頂點減小圖的規模,能維持圖結構特征.
圖聚類和圖概要都通過頂點的分組合并得到子圖.不同點在于圖聚類是組合密集連接的頂點,側重尋找局部稠密的結構,圖聚類沒有特定的目標和任務;而圖概要立足于整體結構,側重尋找屬性和結構相似的集合,它不僅概括稠密的結構,還概括稀疏的結構,相較于圖聚類,圖概要一般都具有特定的任務,與實際應用聯系更為緊密.
圖概要和圖壓縮主要目的都是節省大量的空間開銷.但是圖壓縮旨在尋找輸入圖的最小空間存儲,忽視了圖結構和屬性隱藏的語義特征,可解釋性差;圖概要旨在尋找高質量的超圖代替原始圖進行分析.當然,圖概要中部分方法基于圖壓縮的理念尋找輸入圖的較小表示,兼顧了其結構特征的相似性.
總之,圖采樣通過局部結構評估整體特征,圖聚類合并局部稠密的頂點,圖壓縮尋找原始圖的最小表示模型,它們更注重處理大型數據時計算效率的提升和內存資源的利用,但往往忽略了圖數據的真實結構信息.而圖概要技術的根本目的在于通過小規模的超圖或稀疏圖替代原始圖進行特征分析,更注重挖掘用戶未知的結構模式和隱藏的信息特征,一個優秀的圖概要技術往往需要結合特定的應用背景和需求.因此當我們面對一個真實世界的大型網絡數據時,如何去發現一些有趣的結論或者未知的結構,圖概要技術是最佳的選擇.例如關于維基百科的編輯網絡概要圖,圖采樣只能評估其編輯網絡中各個話題的熱度級別;圖聚類將相近的話題進行分組;圖壓縮則將其轉化為無法解釋的最小存儲模型;而圖概要能描述了一些群體在對某些敏感問題上多次互相編輯,形成“沖突-戰爭”導致兩極分化的特殊結構,有助于人們尋找文化差異較大甚至對立的特殊社會群體.

Fig. 1 Cosum entity relationship summary[32]圖1 Cosum實體關系概要圖[32]
1 圖概要技術
本文從圖概要的解決方案及應用需求,將現有的概要技術分為:基于空間壓縮的圖概要、基于查詢優化的圖概要、基于模式可視化的圖概要和基于影響分析的圖概要.圖結構數據主要有靜態圖和動態圖,靜態圖的邊和頂點保持一致,動態圖由于其自身的邊或頂點不斷變化,具有時間維度屬性.
1.1 基于空間壓縮的圖概要
基于空間壓縮的圖概要方案,旨在減少輸入圖的規模,降低網絡的異構性[27],濾除噪音數據,保留原始圖的主要結構信息,用較小的、有代表性的超圖代替原始圖進行數據分析.主要采用圖壓縮和圖聚類2種方法.
1) 基于圖聚類的方法
圖聚類將每個密集連接的集群映射到超級頂點,確保不同集群的頂點性質不相同,生成的概要圖僅凸顯集群內部邊緣信息的頂點集合,以近似鄰接矩陣表示.聚類技術最初不能保證概要圖的質量,啟發式算法的出現,通過給定輸入圖和期望超點的數量k,重建誤差最小化,使得概要圖的質量得以提高.
文獻[28]提出的關于加權圖的概要化WGC(compression of weighted graphs),從“簡單”和“廣義”進行擴展,主要尋找實體關系結構相似的頂點合并,在保持最小化誤差的條件下追求壓縮最大化,關鍵在于合并一定跳數頂點的過程中保持邊權重或連接強度,以獲得壓縮圖.在簡單加權圖概要任務中,通過為每個邊分配其代表所有邊的平均權重,逼近原始圖使誤差最小化.在廣義加權圖壓縮任務中生成保持連通性的子圖,即任何2個頂點的最佳路徑在概要圖中與原始圖相等,但路徑不一定一樣.
文獻[29]提出的概要技術GRAC(graph clust-ering)采用多層次的聚類算法,主要分為粗化階段、初始聚類階段以及細化階段.當頂點合并成超點時,超邊的權重為包含的所有邊的權重之和.粗化階段首先隨機遍歷所有未標記的頂點,如果頂點v的所有鄰居頂點已標記,則標記此頂點;若該頂點存在未標記的鄰居頂點,則合并頂點v與某一鄰居頂點使其最大化:

(1)
其中,e(u,v)對應邊的權值,w(v)對應頂點的權值,直到所有頂點粗化完成.聚類階段則采用光譜算法[30]參數進行劃分.細化階段受核k-means[31]和譜聚類的啟發,采用增量式加權核k-means保證算法優化相應的圖聚類目標,采用本地搜索來提升批量細化的質量.
Cosum[32]將RDF(resource description frame-work)圖轉化為多類型圖,并將實體解析問題轉化為多類型圖概要問題.其關鍵方法是輸入k-型圖轉換為由超頂點組成的另一個k-型概要圖,使用不同類型的頂點集鏈接來提高頂點分辨率的準確性.Cosum將頂點聯合成超頂點,使得每個超級頂點是相干的(即頂點具有相同類型并且具有高相似性),并且根據其組成頂點之間的原始邊緣創建超級邊緣.已經表明:Cosum優于最先進的通用實體解決方法,特別是在具有缺失值和一對多或多對多關系的數據集中.如圖1所示,RDF圖被建模為多類型圖,輸入圖頂點表示不同對象,實線表示關系,虛線上方的權重w表示實體之間的相似度,相似度可通過鄰居頂點相似或者內容相似度(字符串)計算.概要圖顯示對于產品1,2而言,合并超頂點時制造商是更重要的特征,而對于產品3,4而言價格特征則更重要.
2) 基于圖壓縮的方法
壓縮是數據概要中的常用技術,其目標是通過壓縮技術最小化描述輸入圖,通常基于最小描述長度[33](minimum description length, MDL)原則,構造輸入圖的模型及模型規則下存儲的數據,辨別各種結構模式.問題在于如何利用MDL去選擇最合適的模型,一般應用相關的優化函數將頂點或邊緣遞歸合并到超級頂點中.關鍵策略是合并過程中保持邊緣權重或連接的強度,最小化誤差并最大化壓縮獲得壓縮圖.在屬性圖概要化中,壓縮技術也利用了頂點結構和屬性.初始的策略是優先選取一個維度(屬性信息)進行概要化壓縮,然后再根據拓撲結構進行修正,后期從信息論的角度統一度量結構和屬性的差異化.
文獻[34]是第1個基于MDL原則提出了全新的圖概要模型,該模型在可控有界誤差內生成概要圖,其概要圖由2部分組成:通過聚合頂點生成S和校正C.校正指精確重建G的邊緣校正列表.成本R是S和C的存儲成本總和:Cost(R)=E(S)+C.該模型在計算最大壓縮圖的同時生成了最佳概要圖,核心策略有2種:1)基于貪心策略遍歷所有頂點,尋找全局最佳頂點對,迭代合并成超點,最大限度地降低頂點的成本;2)隨機策略則是一種輕量級的隨機化方案,選擇頂點與附近的最佳頂點對合并.此模型針對概要圖的誤差進一步擴展研究,定義了誤差參數度量:
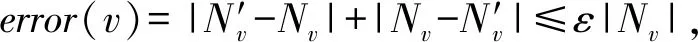
(2)

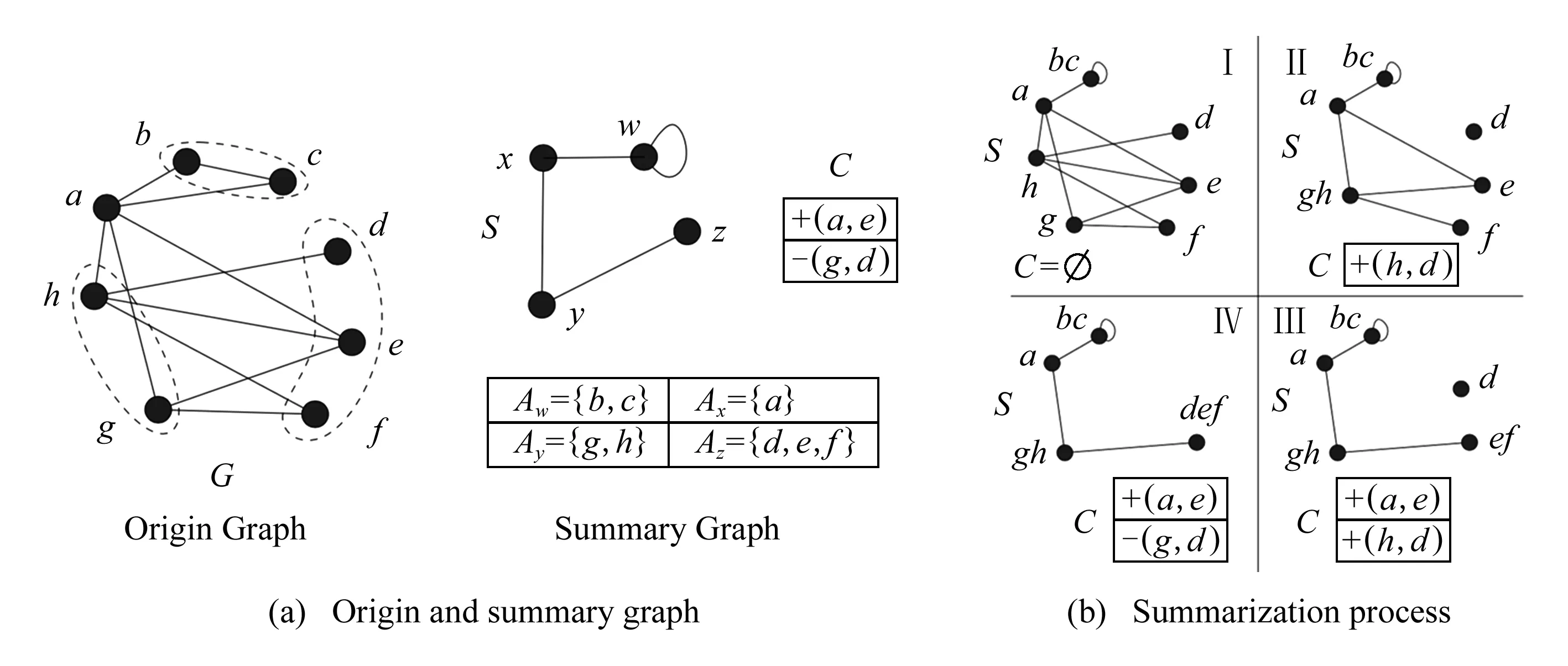
Fig. 2 MDL compression of origin graph[34]圖2 原始圖的MDL壓縮[34]
文獻[36]提出了概要化模型——SlashBurn.現實世界的圖很容易被高度頂點(集線器)斷開,可以通過尋找高度頂點和鄰居(輻條),對其頂點進行排序,遞歸地將一個圖分割成僅由集線器連接的超級集線器和超級輻條,快速地壓縮原始圖,以MDL的原則生成概要模型,該方法支持任何冪律圖上工作,而不需要任何領域特定的知識或者在圖上定義良好的自然排序以實現更好的排列.圖3是SlashBurn概要化1次之后的圖形,通過刪除集線器頂點創建許多較小的“輻條”和GCC(giant connected com-ponent),集線器頂點獲得最低的ID,輻條中的頂點按照它們所屬的連接組件大小遞減順序獲得最高的ID即(9,16),并且GCC獲得剩余的ID(2,8),下一次迭代從GCC開始.
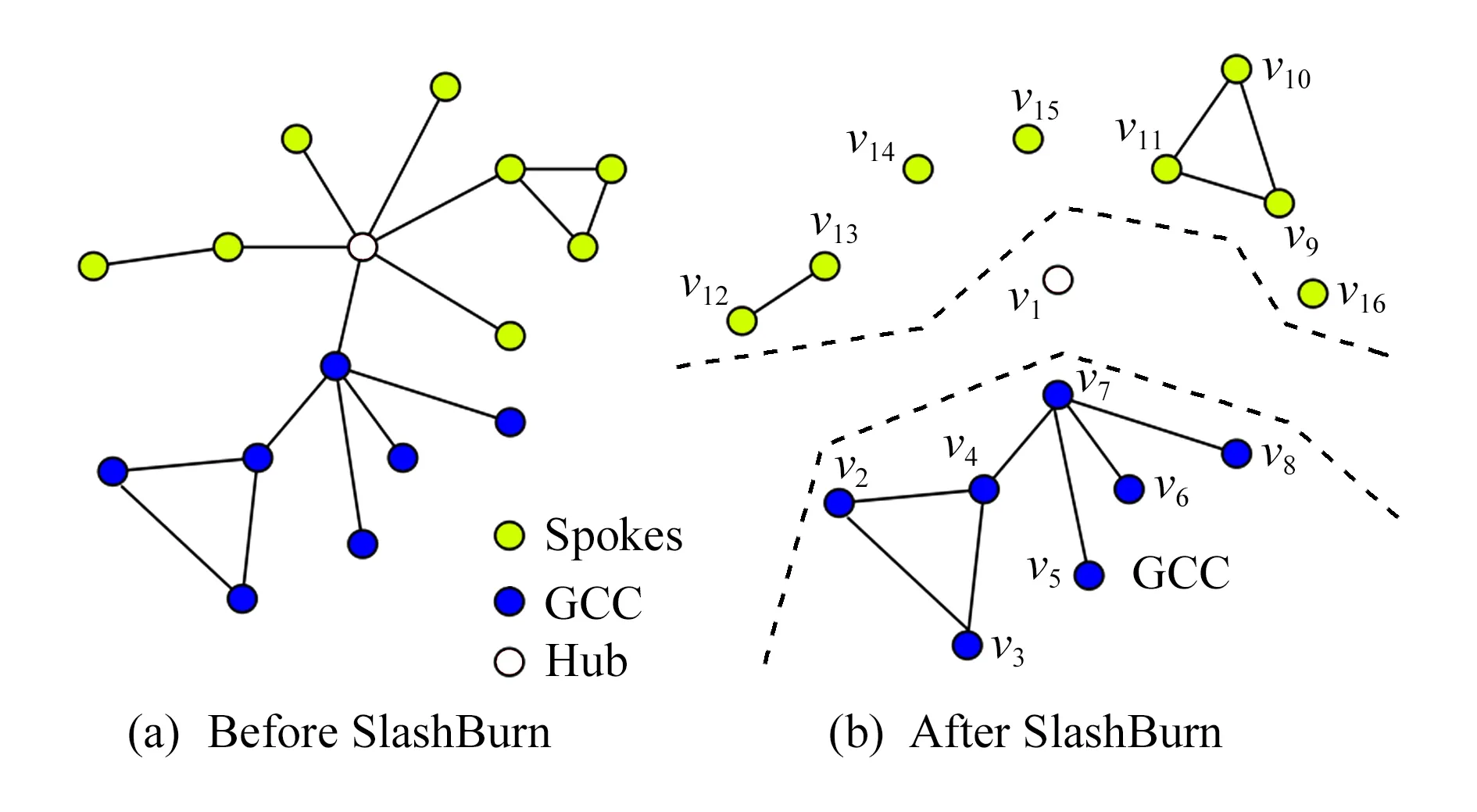
Fig. 3 Graph summary with hub model 圖3 集線器模型
與SlashBurn類似的有文獻[37],提出一種基于無損壓縮高度頂點的G-Dedensified方法,認為高度頂點附近存在大量的冗余信息,引入公共的壓縮頂點去除多余的邊緣,加速查詢處理,問題的關鍵在于如何尋找公共連接的高度頂點.通常情況下將所有高度頂點鄰居劃分為2個集合,遵循MDL的原則使高度頂點和輸入頂點分開,且確保輸入頂點包含所有高度頂點的輸出邊,稱之為“解密”操作.
SAGS(set-based approximate graph summariza-tion)[38]使用統一的局部敏感散列(unified locality sensitive Hash, ULSH)[39]和MDL來壓縮大型網絡,以進行內存處理,生成概要圖.在這項工作中,ULSH通過在頂點鄰域上執行一組minhash函數來處理圖形,計算散列碼,然后聚合基于多個散列函數輸出相同的頂點,添加新的虛擬頂點.
AGSUM(attribute graph summarization)[40]基于MDL最小化模型和模型數據,模型成本代價主要由3部分組成:頂點、屬性和頂點之間的鏈接.核心策略是通過貪心算法結合拓撲結構和屬性信息度量頂點相似性,結構信息相似度則根據2跳頂點對進行衡量,屬性相似度基于Jaccard相似度構建,初始化時通過屬性傳播算法對原始圖初始化,基于貪心策略反復迭代合并使成本最小化,如圖4所示.圖4(a)為原始圖,圖4(b)為概要圖,其中不同標簽的頂點分別被合并為超點,最后將原始圖劃分為3個子圖G1,G2,G3;圖4(c)為還原后的原始圖,由于概要化中可能導致結構信息的丟失,重構的原始圖具有一定的誤差率.
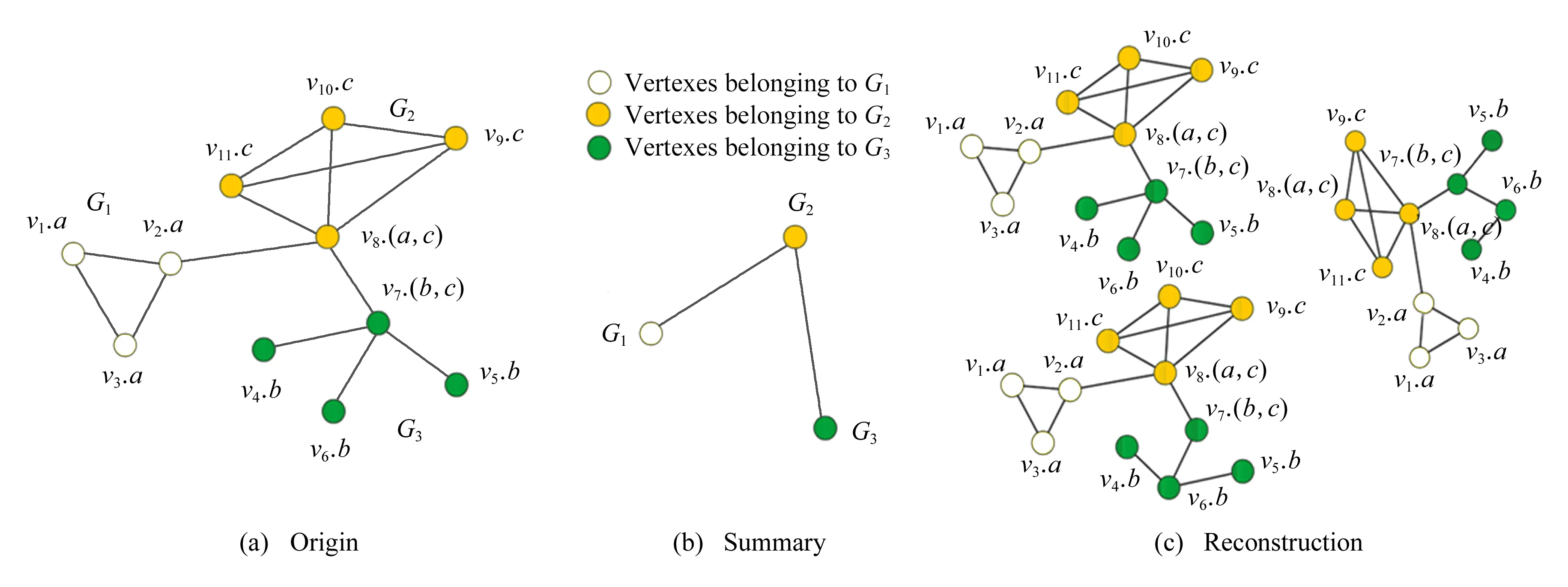
Fig. 4 AGSUM graph summary[40]圖4 AGSUM概要示意圖[40]
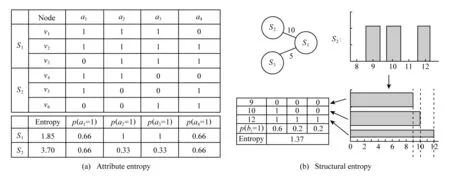
Fig. 5 Structural entropy and attribute entropy[41]圖5 結構熵與屬性熵[41]
文獻[41]由信息論啟發,提出了統一熵模型S-Entropy和分區同質性度量,核心思想是把屬性轉化為頂點,通過概率分布對其進行編碼計算分區之間的熵差,再基于標準放松,根據用戶自身偏好,轉化為加權熵,最終產生精確同質分區和近似同質分區.加權熵主要是由邊熵和頂點屬性熵組成,熵的計算方式為
(3)
圖5(a)表格表示了屬性熵的計算,超點S1內含頂點v1,v2,v3,頂點具有屬性a1,a2,a3,a4,則超點S1屬性熵為1.85,超點S2的屬性熵為3.7,即表明S1內部屬性相似度大于S2;右側則根據鄰居邊的頻數分布轉化為二進制表示,S2超點到S1超點的平均邊數為10,其中2個頂點9條邊、2個頂點10條邊、1個頂點12條邊,轉化為直方圖,基于直方圖的視覺將9,10,11轉化為全1的二進制向量,去除一樣的列,只關心其中的差異,計算結構熵.
文獻[42]在文獻[34]的基礎上提出了最新的成本定義,添加了新的壓縮成本,創建一個原始圖的概要圖,通過成本模型重復選擇最優頂點對合并.成本模型由概要成本和壓縮成本組成,基于貪心算法重復選擇最低總成本.成本模型為

(4)
其中,Costs(u)屬于概要成本,Costc(u)屬于壓縮成本,Costsc(u)選擇其中的最小值.如圖6所示,超點ID從90起標記,觀察到頂點對(27,2)具有最大的壓縮率,彼此共享所有的鄰居頂點,當超點90合并后,繼續根據成本模型選擇最優壓縮頂點對(51,60),此次壓縮新增了多余的邊(60,24),需要在較正列表中刪去此邊.

Fig. 6 Iterative steps of cost model[42]圖6 成本模型迭代步驟[42]
1.2 基于查詢優化的圖概要
基于查詢優化的圖概要以維持原始圖的特定結構信息為主要目的,解決超大規模圖下針對某些查詢任務的快速響應,支持現有或特定的圖形算法加速查詢,盡可能地減少磁盤的訪問,得到精確的結果,降低平均誤差.
文獻[43]提出的層次聚類GRASS(graph structure summarization)針對查詢效率,通過貪心法分組頂點,歸一化差異性,支持頂點的鄰接關系和特征向量中心查詢,并在誤差允許內重構原始圖:
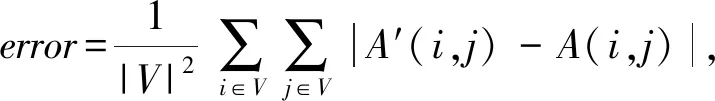
(5)
其中,A(i,j)表示原始圖頂點(i,j)存在的邊.
文獻[44]提出一種基于質量保證的超點合并策略S2A,給定期望的超點數量,使重建誤差最小化.這種針對如三角形或者子圖查詢計數進行優化的啟發式策略,可用于如Grass等概要化方法的改進.
SNAP和K-SNAP[45]是用于概要圖形的2種經典模型,其核心思想首先基于頂點屬性對所有頂點進行迭代分組,直到分組中的頂點屬性一樣,最終產生最大關系屬性圖,啟發式算法K-SNAP允許用戶控制概要化的精確度,通過不同層次的概要圖進行查詢優化,這2種圖形聚合與數據庫操作風格類似,引入了頂點分組的概念,并提供了2個啟發式算法(自上而下和自下而上)來評估SNAP.如圖7左側圖所示,每個頂點代表學生,學生具有性別、班級等屬性,學生之間包含朋友、同學的關系,SNAP操作生成右邊的概要圖,這個概要圖表明了4組學生及其關系,每個小組學生屬于同一性別且同一班級,直觀上說,SNAP根據用戶選擇的屬性和頂點生成一個滿足以下條件的概要圖:該概要圖的頂點對應于最大的兼容分組,該概要圖的邊緣關系滿足從原始圖R中推導出的群組關系.圖7右側圖顯示了根據屬性分組構建的概要圖,但該方法在結構一致性上缺乏更好的表現.

Fig. 7 SNAP-graph summary[45]圖7 SNAP-概要化[45]
CANAL[46]在K-SNAP的基礎上,針對頂點屬性為連續值時,利用鏈接結構和隱藏的信息實現自動化分類,評估概要圖的興趣度,幫助用戶自動找出有意義的概要圖,而這一行為在K-SNAP中可能需要用戶對多個分辨率的概要圖進行匯總.
存在一些特殊應用背景的概要技術,查詢優化只是其次要任務,例如關于隱私保護的概要化,一個零知識隱私框架(zero knowledge private, ZKP).文獻[47]在圖概要中使用ZKP保護用戶的個人隱私,引入了合成屬性,將拉普拉斯噪聲[48]標度λ設置為與靈敏度和采樣誤差之和成正比,并且與ZKP隱私級別成反比,簡化圖概要中ZKP機制的構建和分析,生成概率圖.概率圖[49]將具有相同屬性值的頂點分組一起,提出一個概率圖概要化框架,當中涉及復雜的概率推理,通過計算每個分組之間的期望值(所有鏈接邊的概率值之和)生成一個概要圖.其核心操作可使用R-DBMS中的關系運算符來實現.因為關系數據庫是一個已經被證明可以擴展到非常大的數據的完善和成熟的技術,這是其自身優勢之一.概率圖定義了一組可能的實例PI.將概率圖G的所有可能實例的集合表示為E(PI).每個PI是從概率圖導出的正則圖,其中每個邊或者存在或者不存在.每個PI的存在概率計算為

Fig. 9 Topological model of incremental sketch[55]圖9 增量概要圖的拓撲模型[55]
(6)
其中對于給定邊存在所有實例集合的概率和為1.
查詢隨時間動態變化的大型復雜圖形數據面臨更多的挑戰,例如通過電話或社交網絡與其他人的通信模式、網絡服務器之間的連接、信息流動、新聞傳播、信息在智能家居環境中的設備之間傳輸.目前,動態圖的概要技術研究剛剛起步,采用的方案往往是將數據線性投影到保持數據顯著特征低維空間.
頻率動態圖概要具有3個特征:更小的次線性空間、線性構建時間以及邊緣更新時恒定的維護成本,以便提升查詢效率性能.廣泛的做法是基于散列[50]或基于樣本的方法獨立處理每個流元素,而不用維護元素之間的連接.現有的算法假設查詢存在,建立索引加速,但只能解決臨時問題,而不支持對圖流進行多樣化和復雜的分析,例如CountMin[51]和Bottom-k[52]等工作受限于查詢數據假設存在,G-sketch[53]通過假設存在更好的劃分輸入圖流數據進一步改善了CountMin.
由Tang等人[54]提出的TCM模型則適用于眾多圖流數據,其采用多個獨立的散列函數對流圖生成多個草圖,并滿足4個條件:1)概要圖S的尺寸遠小于G;2)在線性時間內構造S;3)S的更新成本是恒定的;4)S滿足原始圖的結構特征.如圖8所示,S1和S2是由2個獨立的散列函數生成的概要圖,當執行查詢頂點g到頂點b的權重時,2個概要圖均顯示為1,根據選取的聚合函數選擇最小權值為1,實踐證明使用多個獨立散列函數能提高查詢的準確性.
TCM模型在查詢優化方面比基于頻率計數或者單一樣本的概要圖更優越,同時在針對各種類型的流數據處理時,其自身具備更好的適用性和普遍性.
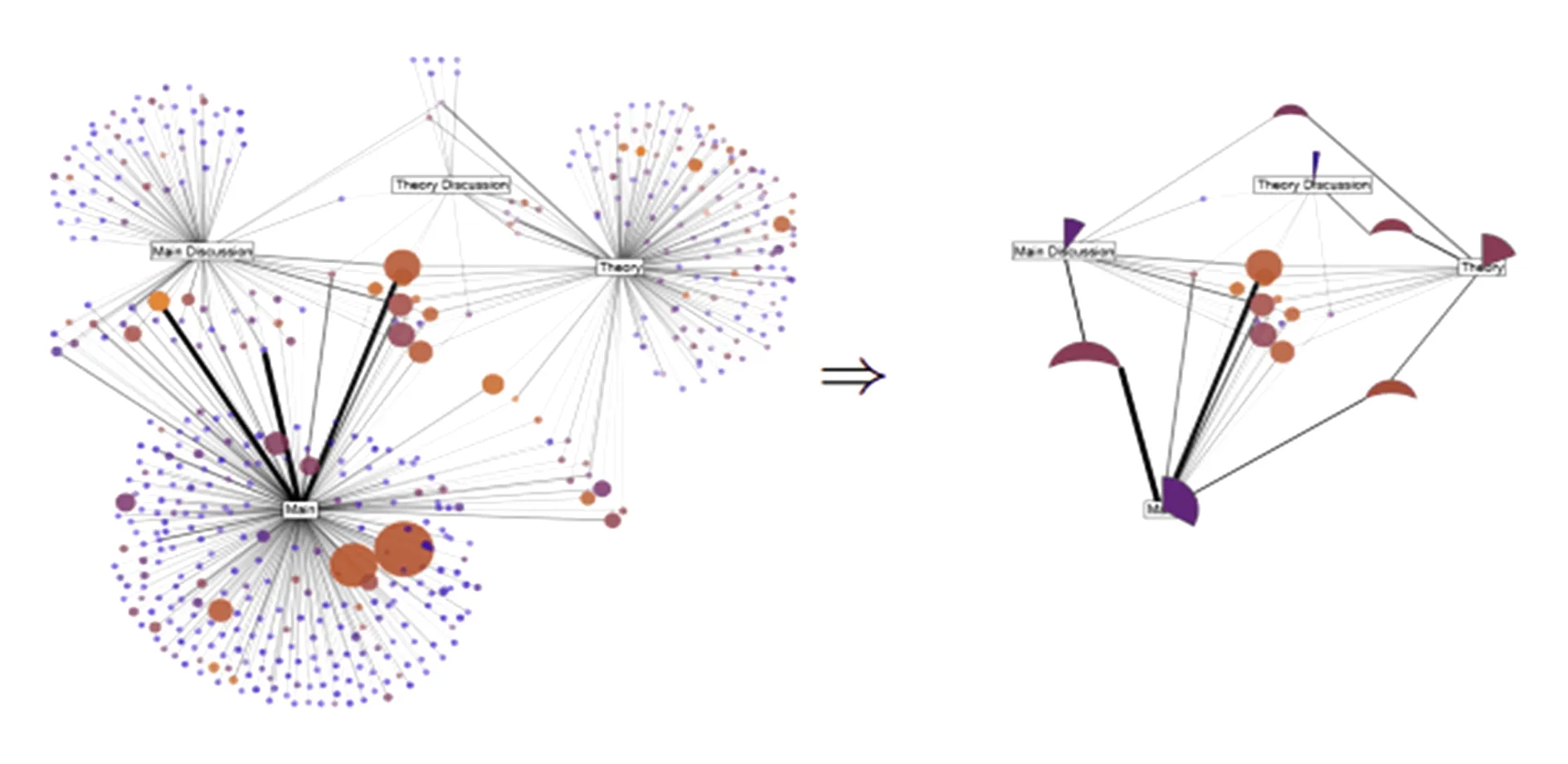
Bandyopadhyay等人[55]提出的一種基于局部鄰域最小散列的可擴展概要圖,使用k個散列函數維護一個最小鄰居頂點的采樣子圖,對于每一個散列函數選取具有最小散列值的數據作為局部樣本,濾除單個數據流中的頻繁更新對采樣偏斜的影響.然后,對于相同散列函數產生的樣本,選取具有最小散列值的樣本作為全局樣本,完成局部樣本集在中心頂點的合并,濾除在分布頂點上的重復更新對樣本偏斜的影響,同時可以導出圖結構的無偏估計量,例如三角形.如圖9所示,散列函數的結果H1:1,5,2,4,3;H2:4,1,5,2,3;此時更新矩陣Mk和計數表C,當新來一條邊(i,j)時,判斷H1(j) 基于可視化的概要方法通過刪除或合并不重要的頂點或邊緣對原始圖進行高度的抽象描述,產生一個可直觀理解的概要圖,幫助用戶在特定應用場景下理解分析原始圖的實際意義.這里的概要圖由原始頂點和邊緣的子集組成.通常,基于可視化[56]生成概要圖主要有基于頂點邊緣的可視化和基于模式結構可視化2種策略. 基于頂點邊緣的可視化是通過特定頂點的語義對網絡進行剪枝、結構抽象或性質過濾,比較典型的有OntoVis[57],一種依靠頂點過濾的視覺分析工具,用于分析不同的大型異構社交網絡,使用與社交網絡相關聯的本體中的信息從語義上修剪大的異構網絡[58],獲得語義抽象.除語義抽象外,OntoVis允許用戶進行結構抽象和重要性過濾,使用統計度量來評估頂點類型之間的連通性和相關性,以使大型網絡易于管理分析. 文獻[59]提出了一種無監督的機制,可用于自我中心信息抽象,根據網絡子結構自動篩選,即k-hop鄰域漸進地構建了一個自我中心抽象圖,允許用戶可視化結果.針對與OntoVis相同類型的圖形,采用邊緣而不是頂點過濾,提出了一種無監督機制建立中心抽象圖. 虛擬頂點挖掘(virtual node miner, VNM)[60]是Web圖形的有損壓縮方案,VNM使用頻繁挖掘方法通過將每個頂點的出入邊作為事務項集來提取有意義的連接.對于每個循環模式,它從其頂點中刪除鏈接,并在S中生成一個新的頂點(虛擬頂點),添加一個出邊,從而允許增量圖表更新.相關地,引入了主題簡化的思想來增強網絡可視化,其中頂點和鏈接的常見模式被緊湊的字形替換以幫助可視化和了解實體及其屬性之間復雜的關系,如圖10所示,原始圖共30條邊,添加VN后只需要11條邊,并完整地保留原始圖信息. 基于模式結構的可視化是面向圖形挖掘應用領域和用戶興趣形成的一些特殊的圖形概要方法,為了滿足特定的需求,以一個或多個固定的結構作為核心特征合并成超頂點,尋找“異常”模式,通過可視化揭露實體屬性的特征關系. Motif[61]是一種依靠圖簡化技術,利用網絡中的重復圖案來減少可視化的復雜性,提高可閱讀性.該技術采取易于理解的結構來替換網絡中的圖案,結構必須具有3個特征:1)需要較少的屏幕空間,確保可視化的閱讀性;2)易于理解的結構性;3)可展示隱藏的關系.文獻[61]中提出2個結構:扇形圖案和并行圖案,并設計有效的算法進行可視化,如圖11所示: Fig. 11 Motif: graph summary of sector structure[61]圖11 Motif:扇形結構的概要化[61] 文獻[62]基于MDL原理,將原始圖拆分為多個可能重復的子圖,再與6種基本結構詞匯表匹配壓縮,分別是星、鏈、完全團、近似團、二分核、近似二分核.每一步壓縮的過程中追求代價最小化,最后選擇多個算法結合提出的質量度量依次選擇候選結構,生成最適合的概要模型,圖12顯示了維基百科的編輯網絡圖的可視化結果,旨在發現用戶爭議分歧最大的相關主題. Fig. 12 Wikipedia editor conflict war visualization[62]圖12 維基百科編輯-沖突戰爭可視化[62] 針對動態圖,基于模式挖掘的概要方法從時間數據中提取有意義的模式.TIME-C[63]描述了具有1組重要時間結構的大型動態圖.文獻[63]的作者將時間圖概要問題正式轉化為信息理論優化問題,其目標是確定時間行為的局部靜態結構,最小化動態圖的全局描述長度.它引入了很多基于時間行為的詞典(閃爍、周期、單詞),主要分為4步:1)識別每個時間戳中的靜態結構;2)使用靜態詞典標記它們;3)鏈接在一起查找時間結構;4)時間詞典標記它們;5)選擇最小化描述時間成本的時間結構.縫合靜態結構對應于進化跟蹤,其通過迭代奇異值分解(SVD)處理以找到潛在的時間相干結構,然后利用余弦相似性度量所發現的結構的時間相干性. Fig. 13 Cluster graph of COARSENET[67]圖13 COARSENET的聚類圖[67] 影響和擴散趨勢分析是圖挖掘長期研究的重點,其本質是隨著時間演變,如何在動態網絡中總結影響擴散的主要過程.基于影響擴散的圖概要旨在尋找原始大圖中影響力的動態描述,方便理解影響傳播的模式,主要通過概要化過程中維持優化與應用相關的信息實現. 影響和擴散過程本質上是時間的演變對社會網絡的影響.OSNet[64]總結了動態圖中有趣的擴散過程.輸入時間有序的交互流,表示為標記頂點間的無向邊.OSNet的目標是在有向圖中捕獲級聯(即擴散過程,如新聞傳播),從而顯示動態的流動.輸出概要圖由原始輸入圖中“有趣”頂點的子圖組成,其中將興趣定義為頂點擴散程度的線性組合(即擴散過程中感染的頂點數量),以及最大“傳播半徑”(即從擴散過程根到頂點的路徑長度).OSNet的關鍵思想是:1)構建傳播樹;2)通過其熵和閾值來計算摘要的特征表現.文獻[65]側重于了解社會團體隨著時間推移的集體活動.該文作者提出了通過多圖(用戶照片、用戶評論、照片標簽和評論標簽圖)非負矩陣分解[66]來提取活動主題,以獲得用戶和概念的潛在空間.潛在空間中的頂級用戶和術語定義了與活動主題相對應的“重要”動作,應用余弦相似性來隨著時間的演變跟蹤主題. 一種近線性時間算法COARSENET[67]使用評分技術反復合并2個相鄰頂點對獲得加權圖,尋找對網絡擴散性能影響不大的邊緣,使得概要圖保留其主要性質,實驗表明其空間縮小至原始圖的10%而不會丟失主要信息.為了表示網絡的擴散特性,最近的研究表明當鄰接矩陣的第一特征值為與原始圖的第一特征值相似時表明它們是自然相近的,當合并頂點對時需要重新對邊進行權值計算,權值的更新取其刪減邊緣和鄰接邊的平均值,選擇使特征值變化最小的頂點(閾值限制)對進行合并.如圖13所示,計算當前原始圖每一條邊的評分,當特征值變化低于閾值時用實線框標注,視為一次成功的合并,高于閾值時則用虛線框標注,視為一次失敗的合并,其中頂點4,5,8,9,12,15合并為超點,6,11合并為超點,右側則顯示了一次迭代后的概要圖. 文獻[68]基于圖譜理論提出了一個圖概要框架,對于大型圖而言,具有相近光譜特性的網絡圖具有相似的結構模式,并提出光譜距離來度量概要圖與原始圖的結構相似性.其中光譜距離定義為 (7) 其中,λ為歸一化拉普拉斯矩陣的特征值,光譜距離將粗化圖的特征值與原始網絡的頭尾進行比較,參數l則控制匹配的位置. Fig. 14 Difference between VEGAS and traditional clustering圖14 VEGAS聚類和傳統的圖聚類的區別 VEGAS[69]是一個典型的針對引文網絡圖的最大化影響分析的概要方法,其核心算法是基于k-means,通過矩陣分解生成概要圖,并支持基于流的影響模式,支持豐富的屬性信息擴展.為了流影響的最大化,生成的頂點簇內的一致性不再取決于密集的內部連接,而是由同一簇中的高度頂點拓撲相似性來定義.在這個目標中,跨越群集的邊緣會比傳統方法更多,從而突出描繪影響模式的流程.如圖14所示,假設原始圖存在統一的權值,原始圖中虛線框內頂點聚類為概要圖中的正方形超點,超點上方標記了影響流的大小,左側是傳統的圖聚類,導致了更大的影響內流,其值是0.8,而右側的VEGAS聚類,則更好地表示了群內和群間的影響流. 為了綜合比較主流的圖概要方法,本節對1.1~1.4節提到的各類算法從輸入圖的類型、結構、參數、輸出圖等進行綜合比較,比較結果如表1所示: Table 1 Comparison of Graph Summarization Methods表1 圖概要方法對比 Notes:“√” stands for support; “×” stands for non-support. 表1主要從輸入圖的類型區分加權圖、無權圖、有向圖、無向圖、同質圖、異構圖以及是否需要給定參數和時間復雜度來區分各個圖概要技術,其中√代表支持,×代表不支持. 1) 大部分主流概要技術應用于無向無權的簡單圖數據,針對加權和異構圖的概要技術較少. 2) 在基于空間壓縮的圖概要技術中,支持加權圖的概要技術一般采用圖聚類的思想,但能勝任異構網絡概要化的研究方法比較匱乏. 3) 在查詢優化的圖概要技術中尚未考慮到加權圖的查詢,大部分方法的算法復雜度是非線性的,只解決了某些特定查詢的優化,在動態圖流上圖概要查詢優化技術取得不小的進展,領先于其他應用領域的動態概要技術. 4) 影響分析的圖概要技術除了OSNet外,都是針對有向圖,無需輸入參數,能客觀地分析網絡結構中頂點間的影響關系,實際應用中影響分析擴散傳播往往需要考慮時間粒度. 5) 模式可視化的概要技術不支持加權的圖數據,除了VNM算法外,都是針對無向圖,算法TIME-C和Moitif能同時處理同構圖和異構圖. 隨著圖數據規模的擴大、屬性的多樣化和結構的復雜化,有學者開始致力于分布式圖概要的研究.當前關于分布式下圖形概要化的工作剛剛起步,相關文獻較少.分布式圖概要主要面臨3個問題: 1) 由于頂點和邊緣分布在不同的設備內存中,集中式圖形摘要算法中看似簡單的操作需要在分布式環境中跨多個頂點的消息傳遞和仔細協調. 2) 集中式算法不需要擔心計算如何分布,但是一個好的分布式圖表匯總方法應該在不同的機器上完全分配計算,以實現高效的并行化. 3) 計算量和通信成本成為分布式圖概要的主要因素. 文獻[75]首次提出了分布式下的圖概要,在Apache Graph上實現了3種分布式算法:1)第1種對應于文獻[34]的集中式貪心策略,尋找超級頂點對,但造成了大量的通信和計算成本.2)第2種采用隨機策略尋找頂點對,但隨機性負面地影響了概要的準確性.3)第3種為Dist-LSH,采用Striped-minhash的技術,新增了權值歸一化處理,快速比較2個集合的相似度,直接找出合適的候選人進行檢查,從而完全消除了與不必要檢查相關的計算和網絡成本.如圖15所示,將權重向量{ai:wi}作為輸入除以權值范圍[0,1]進行歸一化處理,以頂點個數作為桶數進行區域劃分,如圖15中w1=0.53,給定集合A和B,在每個縱軸上應用不同的散列函數,如果散列到同一桶中則視為命中1次,總的命中次數越高則代表集合的相似性越高,即采用這種方案尋找最相似的加權候選集. Fig. 15 Normalization of Striped-minhash weights圖15 R=5時Striped-minhash權值歸一化 文獻[76]提出了一種新的度量主干的概念來提高大型圖形數據的分析效率,度量主干即為保留權值的最短路徑的最小子圖,用于替代原始圖精確或近似進行各個指標的度量.計算度量主干需要解決所有頂點對的最短路徑問題 (all-pairs-shortest-paths, APSP)問題,該文獻通過算法避免APSP并證明了半度量子圖依然能提升計算性能.同時,可作為一種有損壓縮機制,半度量邊數量作為存儲的邊.最后給出了算法在Apache Graph上的分布式實現:1)檢測第1階半度量邊;2)迭代標記局部度量邊;3)標記所有剩余的度量邊. 圖的概要化是一個相對廣泛的概念,其核心技術本身與用戶的興趣和應用目的緊密聯系,導致不同應用領域的概要技術無法客觀地對比,原因在于解決主要問題的技術方案不同,不同維度的評價指標無法展示各個圖概要技術的優越性. 相對而言,基于空間壓縮的概要圖技術,核心任務基本一致,對比的指標相同.本文在無屬性的圖上選取了經典的基于MDL壓縮的MDL-R[34],REF[72],GBASE[73],GRAC[29]四種算法進行了實驗性能的比較. 1) MDL-R.第1個基于MDL的壓縮概要技術,雖然在大型圖數據下效率偏低,但提供了高質量的概要圖. 2) REF.一個流行的Web壓縮技術,該方法由2個邏輯部分組成:第1部分減少每個頂點鄰居列表的大小;第2部分使用復雜的比特級編碼進行壓縮.為了實驗對比的公平性,去除比特級編碼運行該算法. 3) GBASE.一個針對大型圖存儲壓縮的查詢優化系統方案,本研究只采用其壓縮技術——塊存儲編碼,將鄰接矩陣轉換為二進制字符串. 4) GRAC.加權圖的圖聚類算法,將給定的加權圖進行劃分使得權重最小. 實驗的數據集為CNR,RouteView,Wordnet,Facebook四種數據集. 1) CNR.該網絡是從CNR域網爬蟲提取的,由有向邊轉化為無向邊,最大的CNR數據集具有10萬頂點和40萬余條邊. 2) RouteView.這是一個表示Internet拓撲系統的模型,這個數據集是由俄勒崗大學路線視圖項目組收集,大約具有1萬個頂點和3萬條邊. 3) Wordnet.自然語言處理應用程序中常用的英語單詞的大型詞匯數據庫,將每個單詞對應于1個頂點,如果每個單詞具有相近或包含或前置的關系,則頂點之間存在邊,該圖大約有7萬個頂點和12萬條邊. 4) Facebook.該數據集是2005年康奈爾大學從自身大學社區提取的Facebook網絡圖,有1.5萬頂點和14萬條邊,每個頂點存在邊即表示學生之間為朋友關系. Fig. 16 Experiment on information retention rate and compression ratio of non-attribute graph圖16 無屬性圖信息保持率和壓縮率的對比實驗 圖16顯示了無屬性圖上4種算法的信息保持率和壓縮率的實驗結果.信息保持率上,GRAC的性能相對優越,值得關注的是REF在Facebook數據集上幾乎沒有丟失信息,但結合壓縮率指標可知,該現象是由壓縮效果不理想引起.對于另外2種算法,概要化過程中為了追求一定的壓縮率都采取了誤差閾值進行擴展:MDL-R在各類數據集上均可以取得最大化壓縮的結果,主要原因在于根據MDL信息理論,其在迭代壓縮過程中始終基于貪心策略尋找最大化壓縮頂點,而GRAC的壓縮效果相對最差, Facebook數據集由于其頂點和邊緣的高度比,壓縮性明顯最差.值得關注的是GRAC在該數據集上效果最好,其核心是基于聚類的分區思想,在這種高度密集的圖數據上更有優勢. 圖17是針對無屬性圖的運行時間比較.MDL-R時間開銷最大,因為采用貪心策略,重心永遠關注在如何全局最大化降低成本上,MDL-R可以擴展基于局部最優的隨機策略進行概要化,減少時間開銷的增大,其生成的概要模型忽略了頂點存儲的自身信息.在時間代價上GRAC表現最為優異,主要通過權值相同聚類降低有限的成本,但缺陷在于需要重復給定分類參數,尋找合適的壓縮率. Fig. 17 Experiments on time cost of non-attributed graphs圖17 無屬性圖時間代價的對比實驗 在屬性圖上進行了實驗,選取壓縮率、屬性熵[77]以及時間代價進行對比.算法選擇SAC[74],K-SNAP[45],AGSUM[40],S-Entropy[41]這4種算法. 1) SAC.一種針對屬性圖的聚類算法,通過隨機游走距離度量屬性相似性和結構相似性. 2) K-SNAP.第1個基于用戶屬性分組進行概要技術的經典方案. 3) AGSUM.在K-SNAP基礎上進一步優化了結構一致性的壓縮. 4) S-Entropy.是一種基于屬性熵和結構熵的統一模型,產生近似同質分區. 數據集采用Political Books(PB)和DBLP[78]數據集. 1) Political Books(PB).政治家的博客數據集,具有1 500頂點、2萬條邊和3個屬性,其中平均度8. 2) DBLP.是計算機領域內以作者為核心的一個計算機類英文文獻的數據庫系統,按年代列出了作者科研成果、國際期刊和會議等發表的論文.實驗選擇的數據集包括3個DBLP數據集,DBLP1只包含選定的數據庫出版物,具有7 000頂點和2萬條邊,DBLP2新增了AL出版物,具有1.5萬個頂點和3.8萬條邊,DBLP3包含了所有會議和期刊的出版物,具有10萬頂點和24萬條邊. 圖18顯示了4種圖概要技術在屬性圖上壓縮率和信息熵的實驗.在圖18(b)熵的指標上K-SNAP性能最好,主要原因在于K-SNAP單純通過頂點的屬性進行概要匯總,未考慮網絡的結構,因此結構性能上表現最差,壓縮率最高;而AGSUM充分考慮了屬性和結構的一致性,生成了緊湊的概要圖,壓縮率降低,熵比較大是因為犧牲了屬性的一致性;SAC是基于距離的一般聚類方法,將屬性頂點轉化為增廣頂點,導致不同屬性的頂點放在一起從而產生較高的熵;S-Entropy基于熵的維度平衡結構和屬性一致性,概要圖的結構性能降低. Fig. 18 Experiments on entropy and compression ratio of attribute graph圖18 屬性圖信息熵和壓縮率的對比實驗 由圖19可知,K-SNAP時間開銷最低,主要原因是只考慮一個維度的概要化,計算量明顯低于其他方法;S-Entropy比其他性能更為優異.隨著數據集的增大,S-Entropy的時間性能更接近線性增長,表明了該技術在大型數據集上良好的擴展性,相比較AGSUM,S-Entropy更重視屬性的一致性,對于結構熵的度量缺乏更多有力的說明,這也是概要技術評價需要考慮的標準之一. Fig. 19 Experiments on time cost of attribute graph圖19 屬性圖時間代價的對比實驗 隨著互聯網的迅速發展,實際生活中圖數據量不斷增加,研究者識別大規模圖數據的模式和隱藏意義的困難持續增加,從而影響決策過程.圖概要技術為理解和識別圖數據中的結構和意義提供了可能.圖概要的應用與現實生活緊密聯系、息息相關,主要有5個方面的應用領域: 1) 減少數據量和存儲空間.現實世界圖形數據集往往極為龐大,例如Facebook的社交網絡超過30億的用戶,每天郵件的發送投遞超過1 000億,這些應用所產生的圖數據已經超出內存的限制,大多數圖算法無法直接作用于原始圖去提煉潛在的結構特征.圖概要技術下的社交網絡圖具有更小的空間,且讓研究者在更高層次對原始圖進行分析研究,準確揭露隱藏結構. 2) 圖數據的查詢優化.大量通用的圖數據查詢算法在解決龐大的復雜數據圖時面臨著效率低下、準確性降低的弊端,特定的概要技術可以極大提高查詢的效率和準確性,例如社交網絡圖上最經典的查詢可能詢問2個頂點是否存在邊或者路徑.這樣的查詢通過鄰接矩陣概要化技術可以比最先進的圖查詢算法提速50倍,減少平均錯誤率.其他類似的提高查詢效率的有三角形查詢、權重估計等.然而,針對常見的查詢尚缺乏能取得優化效果的通用型圖概要技術. 3) 可視化分析.在交互式圖形界面領域,圖概要技術作為可視化的重要手段,解決原始圖過大而無法加載到屏幕的弊端,幫助用戶直觀地理解原始圖的結構特征,加速分析.比較經典的可視化技術,通過結合用戶自身的興趣結構,給定一些特殊的結構去壓縮原始圖,例如文獻[61]通過一些特定詞匯結構針對維基百科編輯圖進行可視化,旨在尋找用戶分歧較大的主題,這往往能發現許多額外的有趣現象. 4) 影響分析和擴散.部分文獻通過圖概要技術,試圖尋找大型圖中影響力的動態擴散模式,以便理解影響傳播的模式和重要條件,一般結合實際背景維持一些與影響有關的全局因子并捕捉變化模式,經典應用有網絡作品的影響力分析[68]、社交圖譜的概要化[79]、圖表抽象從模擬異構犯罪數據集中提取影響流、高效識別犯罪團伙. 5) 噪聲過濾和隱私保護.真實的圖數據通常是大規模、具有很多噪聲的數據,例如錯誤的連接或者標簽屬性,這種數據阻礙了分析,隱藏了重要信息,增加了數據工作的處理量.概要化技術有利于濾除噪聲,揭示隱藏模式.同樣,針對現實網絡圖的真實信息,概要技術可以濾出與應用需求無關的部分用戶敏感信息,加強對用戶的隱私保護[49]. 近年來,盡管涌現了許多圖數據概要方面的研究工作,但該領域仍然是新興的,需要更多的深入研究,目前尚面臨許多問題和挑戰: 1) 圖概要化評價標準的確立[80-81].圖數據的概要化是一個相對廣泛的概念,尚沒有明確的定義,其本身是依賴于用戶的興趣和應用需求,不同應用領域的概要技術無法直觀地對比,因此缺乏統一標準的概要評估技術.如果概要化的目的是為了解決存儲空間的限制,可以采用壓縮率、信息保持率等評價標準;當概要化是為了加速圖形算法的查詢效率,則評估的標準應是查詢時間、準確度等;當概要化是為了圖的可視化,則評價指標更加難以度量.本文調查表明,應用背景和目的需求相近時的圖概要技術,才能依照統一的評價指標衡量算法的優劣,例如本文的實驗針對空間壓縮的應用需求,壓縮率、信息保持率以及時間代價可以作為衡量指標.當前還沒有統一的評價指標對各種圖概要技術進行評價,考慮到概要技術的應用性,可以針對其概要技術提出一個多領域評估框架,囊括主流的概要技術,根據應用需求選擇適應的評估方案,這也是圖概要領域的研究者當前亟需確立的任務. 2) 基于動態圖流的概要化[82].現實世界中的社交網絡是基于時間維度的,對于這類圖概要需要捕獲隨時間變化的結構和屬性的模式[83].然而,針對動態圖流的概要技術尚未得到充分的探索,當前部分模型通過嵌入技術將頂點投影到低維向量空間,并保持其頂點的結構相似性.現實生活中,Facebook用于發送消息所形成的社交網絡、網絡服務器之間的鏈接和消息流動、智能家居設備之間的信號傳遞都可以被視為動態圖流.圖流中每個頂點具有自己的鄰接矩陣,通過矩陣的更新提取頂點隨著時間變化的動態特征并進行個性化分析是圖流概要化的核心技術.然而,增加時間維度將面臨更多的挑戰:如何描述隨著時間推移而形成的動態圖形的結構特征?如何濾除冗余的變化?如何根據實際應用需求捕捉合適的時間窗口,確定圖流對時間的敏感度,這都是導致動態圖概要研究進展緩慢的原因.動態圖流的概要化無法用單一的概要圖描述其空間特征和時間特征,而是需要一系列概要圖序列描述其變化趨勢.未來工作可以借助機器學習領域的Boosting思想,構建概要圖序列,初始概要圖代表初始時間窗口的特征(樹),下一時刻概要圖描述矯正信息(圖流更新信息),通過一系列概要圖序列擬合動態圖流的變化趨勢,描述并預測動態圖流的結構特征.時間窗口的選取可通過偏方差和懲罰項制定損失函數,自適應地調整,避免過擬合,提升概要圖序列對圖流特征描述的泛化能力. 3) 異構信息網絡的圖概要[84].當前大多數關于網絡科學、社交和信息網絡的研究,普通是同構網絡,即網絡中的頂點都是相同實體類型的對象,并且鏈接都是相同類型的關系.這些研究獲得了許多有趣的結果以及眾多有重要影響的應用.然而,實際中大多數網絡是異構的(heterogeneous)[85],即網絡中的頂點和關系并不是相同類型的.例如,在一個醫療保健預測網絡中,頂點可以是病人、醫生、檢查、疾病、藥物、醫院、治療措施等,構建出頂點類型不同的異構網絡.而現有的圖概要技術多是基于相同頂點類型的同構網絡,由于頂點實體類型的多樣化和結構的復雜化,無法移植到異構網絡中,但針對異構網絡建模可以捕獲真實世界中最根本的語義信息.有2種策略可以幫助建立異構網絡的圖概要,一是借鑒現有的屬性與結構的相似性轉化操作,將異構網絡中不同的實體類型以增加屬性域的方法轉化為同一實體的不同屬性,從而將異構網絡轉化為同構網絡來處理;二是將異構網絡拆分為多個同構網絡分別進行概要化操作,提取隱藏的模式結構,揭示不同頂點之間的隱藏關系,不失為一種有效策略.目前針對異構網絡的概要化技術尚未得到足夠的關注. 4) 分布式圖概要技術的擴展[86].當前的圖概要技術,大多采取單個進程內存處理所有的任務.隨著圖數據規模的指數級增長和信息結構的復雜化,尤其在處理千億個頂點和邊時,單機的概要化技術往往陷入數據災難.分布式環境能提供更多的存儲內存,并行計算能極大地提高概要化效率.目前,分布式下的概要技術尚未得到重視,這主要取決于計算和通信成本的嚴峻挑戰.首先頂點和邊緣分布在不同的內存中,因此集中式圖概要技術看似簡單的操作,需要在分布式環境中跨越多個頂點進行消息傳遞和仔細協調.其次,單機的概要算法不需要考慮計算資源的分配,而一個優秀的分布式下圖概要技術應該充分利用每一個機器,以實現高效的并行化計算,克服這些挑戰.通過設計輕量級的過濾交互算法,在每一次迭代前對圖數據進行預處理,可避免不必要的計算和通信開銷,分布式下的概要技術更能勝任大圖流下的計算分析,圖概要領域的研究者更應重視這一方向的工作. 5) 圖概要的低維嵌入表示[87].近年來以深度學習(deep learning)[88]為代表的表征學習方法在語音識別、圖像理解以及機器翻譯等任務上取得了巨大的成功.這些方法通過設計多層的非線性神經網絡從原始數據提取有效特征,整個模型從數據的原始輸入到目標任務的最終輸出,實現了端到端的學習.由于深度學習等表征學習方法在多個領域的有效性,近年來涌現了大量的致力于面向網絡結構數據的表征學習的工作.深度學習網絡表征學習算法的目標是獲得網絡的低維稠密表示,對于大規模網絡(如社會網絡),網絡表征學習的目標是把網絡中的每個頂點表示成為一個低維稠密的向量并且保證在這個低維空間上能夠很好地保留網絡的拓撲結構.頂點表示能夠當作頂點的特征用于頂點分類、頂點聚類、網絡可視化、鏈接預測等不同的任務,本質上是通過保留網絡的局部結構性來估計頂點的表示.概要技術可以引入其思想,將圖數據的特征映射到低維向量空間中進行概要化,這種充滿潛力的方案似乎更能解決大型復雜網絡的概要化難點.1.3 基于模式可視化的圖概要

1.4 基于影響擴散的圖概要


1.5 圖概要算法小結

2 分布式環境下的圖概要化
3 部分圖概要算法實驗
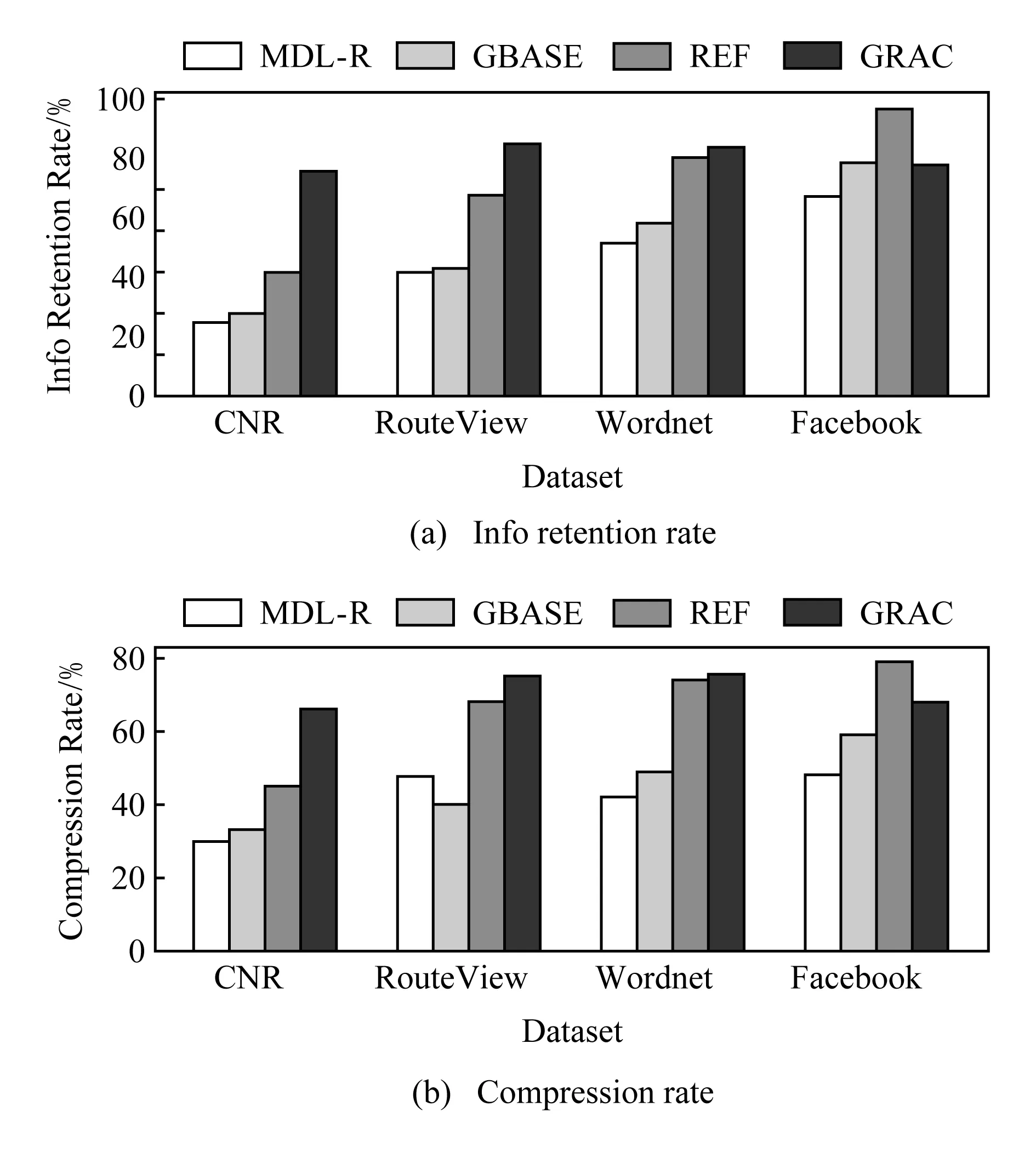
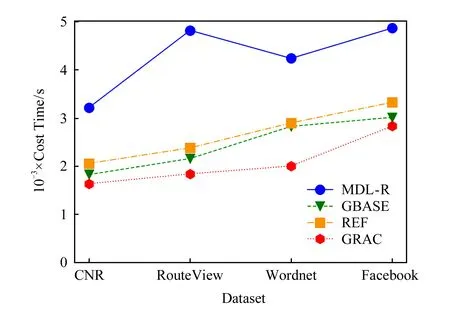


4 圖概要應用
5 存在的問題及挑戰
猜你喜歡
小獼猴智力畫刊(2023年4期)2023-04-23 08:49:58
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
中學生數理化·高一版(2018年1期)2018-02-10 05:20:03
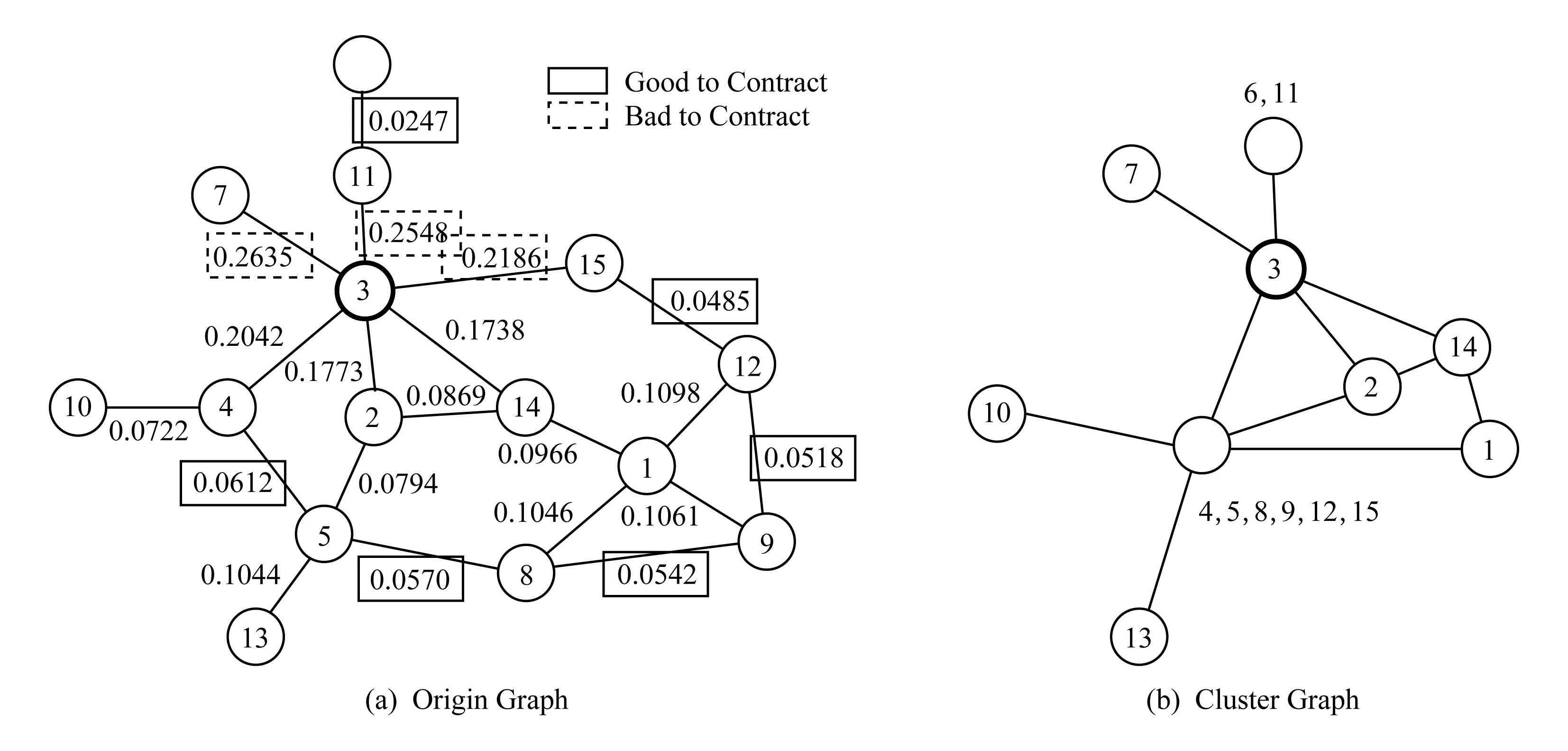
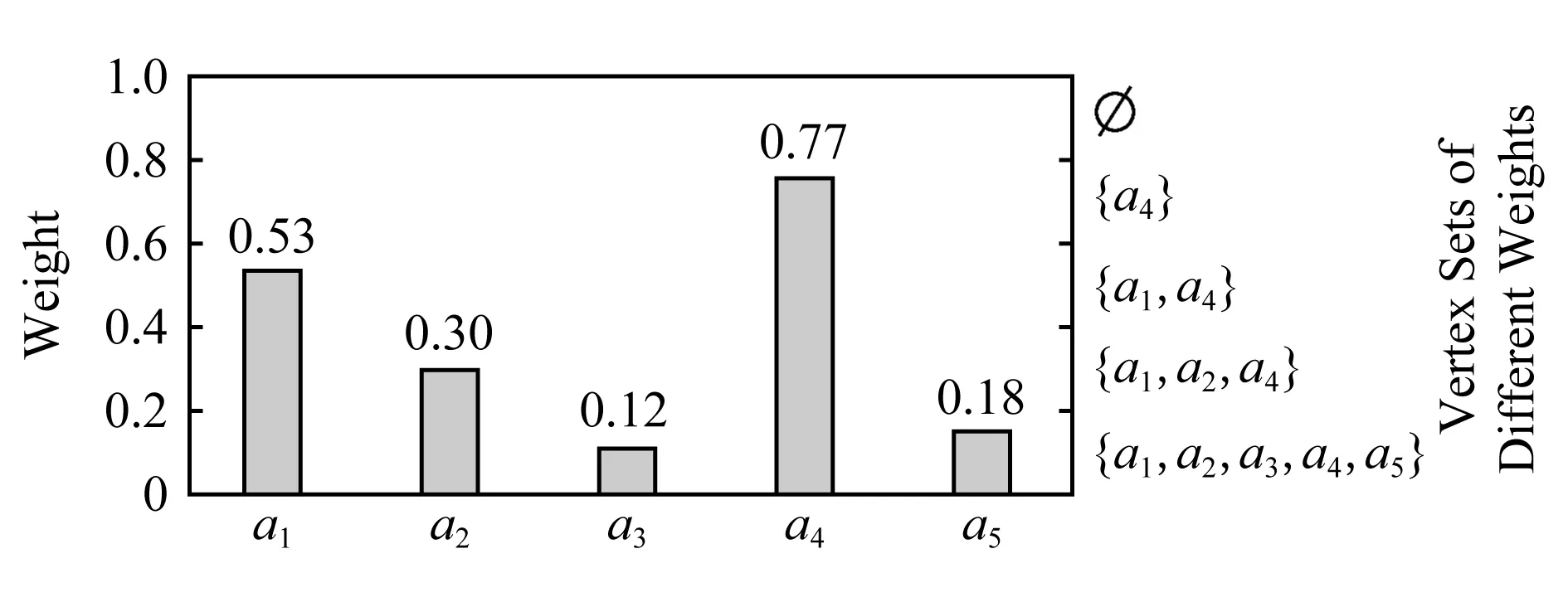
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
七彩語文·寫字與書法(2016年7期)2016-07-28 21:40:22
七彩語文·寫字與書法(2016年6期)2016-07-15 19:36:34
人間(2015年21期)2015-03-11 15:23:21
現代企業(2015年9期)2015-02-28 18:56:50
