基于分類型矩陣對象數據的MD fuzzy k-modes聚類算法
2019-06-26 10:18:06李順勇張苗苗曹付元
計算機研究與發展 2019年6期
李順勇 張苗苗 曹付元
1(山西大學數學科學學院 太原 030006)2(山西大學計算機與信息技術學院 太原 030006)
聚類算法中最具代表性的是k-means,k-modes,k-prototype算法,其中,k-means[1]主要用于對數值型數據進行聚類.現實中,分類型屬性數據也常見.1998年Huang[2]提出了k-modes算法,該算法用簡單匹配計算2個對象間的距離,用modes代替means,基于頻率來更新類中心.2001年Chaturvedi等人[3]改進了k-modes算法,提出了k-modes-CGC算法,有效地運用非參數方法對分類型數據進行聚類.隨后,Huang等人[4]證明了二者的等價性.此外,在初始類中心的選取上,Ying等人[5]考慮將迭代求精法與k-modes算法結合;在相異性度量的選取上,Ng等人[6]和San等人[7]基于屬性頻率計算相似度,Li等人[8]基于生物特征計算距離.Liang等人[9-14]也基于不同度量提出了多種k-modes的改進算法.
以上種種算法在考慮類別歸屬時,其隸屬度只考慮了0,1這2個值,即只能劃分到確定的某一類中,屬于硬劃分.而數據的不同屬性重要度會給部分數據的真實類別歸屬帶來模糊性.粗糙集[15]和模糊集[16]理論的提出為數據在數據集中的位置提供了有利的基礎,軟劃分應運而生.Bezdek提出的fuzzyc-means(FCM)算法[17]是軟劃分聚類的典例.1999年Huang等人[18]在FCM算法的基礎上引進模糊因子、隸屬度矩陣等,進一步提出fuzzyk-modes算法.2004年Kim等人[19]用模糊集對類中心的模糊化刻畫分類數據中類的不確定性,提出了具有模糊類中心的Fuzzyk-modes算法.2005年Li等人[20]提出了基于特征加權的模糊聚類新算法(novel feature weighted clustering algorithm, NFWFCA).2007年Cai等人[21]結合局部空間和灰度信息,提出了快速通用的聚類算法(fast generalized fuzzyc-means, FGFCM).2016年Zhou等人[22]結合多目標優化算法與模糊中心點聚類,提出一種新穎的多目標模糊聚類算法.總之,k-modes算法對后續眾多的拓展算法起到了積極的鋪墊作用.
已有的聚類算法普遍使用X={X1,X2,…,Xn}的數據表示模式,X表示由n個對象組成的對象集,Xi=(Xi1,Xi2,…,Xim)表示每個對象由m個屬性特征描述,每個屬性特征有且僅有唯一的取值.然而實際應用中,對象的每個屬性特征可能有不同的取值.例如顧客購物時,可能同時購買多個產品,這就容易產生矩陣對象數據[23].若利用已有的聚類算法處理該類數據,需用先驗知識來選取其中一條記錄,這會嚴重損失信息并破壞數據的原始性,且違背了以數據總體來做數據分析的初衷.因此,為了利用多條消費記錄發現客戶的消費喜好,從而做出更具針對性的推薦[23],有必要研究基于矩陣對象數據的聚類算法.Cao等人[24]首先提出基于集值對象的Set-Valuek-modes (SV-k-modes)算法和fuzzy Set-Valuek-modes(fuzzy SV-k-modes)算法[25].之后,Cao等人又提出基于矩陣對象的k-multi-weighted-modes(k-mw-modes)聚類算法[23].該算法在考慮類別歸屬的同時,其隸屬度也僅僅考慮了0,1這2個值.由于數據集中屬性重要度的不同,常常會給部分數據的真實類別歸屬帶來模糊性.本文兼顧模糊集引入模糊因子,提出一種基于矩陣對象數據的模糊聚類算法(matrix-object data fuzzyk-modes, MD fuzzyk-modes).本文的主要貢獻有4個方面:
1) 結合模糊集的概念提出了一種更新類中心啟發式算法;
2) 提出了基于分類型矩陣對象數據的MD fuzzyk-modes聚類算法;
3) 實驗驗證了MD fuzzyk-modes算法的有效性;
4) 分析了模糊因子β與隸屬度w的關系.
1 回顧fuzzy k-modes算法
設X={X1,X2,…,Xn}是由n個對象、m個屬性描述的分類型數據集,則Xi與Xj間的相異性度量定義為
(1)

Q是X的類中心,如果Q能最小化
(2)
fuzzyk-modes算法用迭代方式將數據分為k類, 此算法的目的是最小化目標函數:
(3)
其中,W為隸屬度矩陣.
2 MD fuzzy k-modes聚類算法
經典的k-type算法[1-2]主要由3部分組成:相異性度量的定義、類中心的表示和類中心的更新過程.本文提出的MD fuzzyk-modes算法也從這3方面考慮.
2.1 矩陣對象間的相異性度量
用簡單0-1匹配、屬性頻率等相異性度量來計算數據間的距離適用于1對1對象數據,而矩陣對象數據每個屬性有多于一個的屬性值,這些相異性度量對矩陣對象數據有一定的局限性,由于k-mw-modes算法[23]中定義了2個矩陣對象間的相異性度量,本文直接引用此相異性度量.
定義1.相異性度量.給定矩陣對象Xi,Xj,每個對象由m個分類型屬性{A1,A2,…,Am}來描述,則Xi與Xj的相異性度量定義為
(4)
其中:
δ(Xis,Xjs)=
(5)

(6)

可以驗證該相異性度量滿足非負性、對稱性和三角不等式性,的確是一個距離.
例1.表1是某一矩陣對象數據集的描述,其中X={X1,X2},A={A1,A2},計算X1,X2間的距離.


Table 1 A Matrix-Object Data Set表1 某一矩陣對象數據集
2.2 類中心的定義及啟發式更新過程
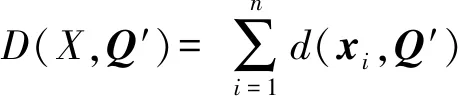
定義2.類中心.如果Ql能使目標函數達到最小:
(7)
則Ql是X的類中心.

這種全局性更新類中心算法的時間復雜度為O(nmtk×2|V′|),n表示對象數,m表示屬性個數,k表示分類個數,t表示迭代次數,|V′|=max{|Vs|,1≤s≤m}.由此可知,全局性更新類中心的算法時間復雜度隨著對象個數、屬性個數、分類數及迭代次數的增多呈線性增長,屬性值的個數呈指數增長.
當矩陣對象數據中屬性值個數過多時,全局更新類中心的算法計算量過大,耗時增強,故本文提出了啟發式更新類中心算法.首先分析
(8)







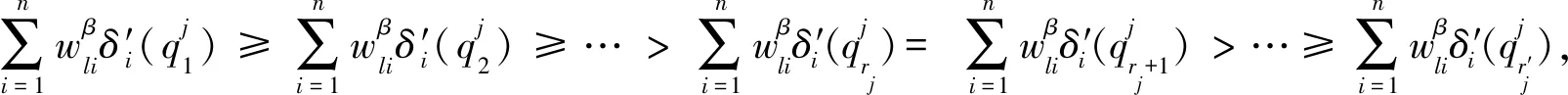
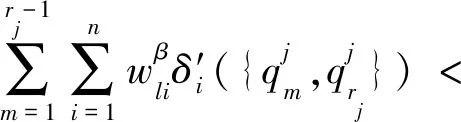




2.3 MD fuzzy k-modes聚類算法
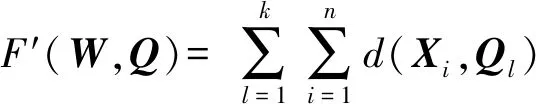
本文在k-mw-modes算法的基礎上,引入模糊因子并改進了類中心的表示及更新過程,提出了MD fuzzyk-modes算法.
定義3.最小化目標函數.將一矩陣對象數據集X={X1,X2,…,Xn}劃分為k類,則需最小化目標函數:
(9)
且滿足:
wli∈[0,1], 1≤l≤k, 1≤i≤n,
(10)
(11)
(12)
其中,Q=(Q1,Q2,…,Qk)中的元素Ql表示第l類的中心,Ql=(Ql1,Ql2,…,Qlm);W=(wli)是一個k×n維的隸屬度矩陣,wli=1表示Xi被分到l類.
為使F′(W,Q)達到最小,要通過多次迭代過程使其收斂:1) 初始化類中心Qt;2) 固定Qt,找出使F′(W,Q)最小的Wt;3) 固定Wt,用啟發式更新算法找出Qt+1使F′(W,Q)達到最小;4) 重復步驟1)2)3),直到類中心不變或目標函數小于閾值為止.
其中,隸屬度矩陣W由定理1計算而來,類中心Q的更新由啟發式更新算法而來.
定理1.固定Q,在式(10)~(12)的限制下使F′(W,Q)最小,則W的更新為
(13)
MD fuzzyk-modes算法的基本步驟:
1) 隨機選取k個對象作為初始類中心;
2) 根據2.1節,計算每個對象到k個中心的距離,將對象分配到與其距離最小的類中;
3) 根據2.2節,計算每個對象到k個中心的隸屬度,并更新k個類的類中心;
4) 重復步驟2)3),直到類中心或目標函數不變為止.
算法1.MD fuzzyk-modes算法.
輸入:X為由m個屬性描述的n維矩陣對象數據,k為需要聚類個數,ε為閾值,idCenters為k個初始類中心的標簽,β為模糊因子;
輸出:cid是聚類后所有對象的標簽,num是迭代次數.
①Q是初始類中心,value=0,num=0;
② whilenum<100 do
③newvalue=0;
④ fori=1 tondo
⑤ forl=1 tokdo
⑥ 計算第i個對象到第l個中心的距離d(Xi,Ql)(用式(4));
⑦ end for
⑧ end for
⑨ fori=1 tondo
⑩ forl=1 tokdo
3 實驗分析
為了評價MD fuzzyk-modes算法的有效性,本文考慮了5個真實數據集:Market Basket,Micro-soft Web,Musk,MovieLens,Alibaba.Market Basket記錄了1 001個顧客的交易記錄,每條記錄由用戶ID、交易時間、產品名稱和產品ID這4個屬性描述;Microsoft Web來自UCI數據集,記錄了1998年1月份某周內32 711個匿名用戶的網頁瀏覽情況,每個用戶由用戶ID和網頁ID這2個屬性描述;Musk也來自UCI數據集,包括92個對象,每個對象由167個屬性描述;MovieLens從MovieLens網站上下載,本文只使用其中的ratings數據,它記錄了6 040個觀眾對3 900部電影的1 000 209條評分情況,每條記錄由用戶ID、電影ID、用戶評分和提交評價的時間這4個屬性描述;Alibaba是884個用戶瀏覽某些品牌的182 880條記錄,也由4個屬性描述.這5個數據集均為矩陣對象數據集.為了增強聚類效果,本文對各數據集的屬性做了相應的預處理,預處理后的數據形式如表2所示:
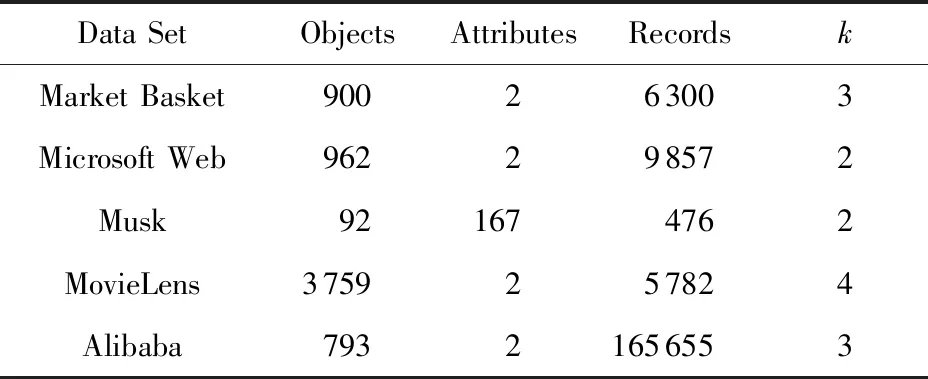
Table 2 Data Set after Preprocessing表2 預處理后的數據集
3.1 評價標準
本文采用精度(AC)、純度(PR)、召回率(RE)、蘭德指數(ARI)、歸一化互信息(NMI)這5個評價指標對所提算法進行了有效性評價.AC表示分類正確的比例;PR表示預測為正的樣本中有多少是對的;RE表示樣本中的正例有多少被預測正確;ARI和NMI用來衡量2個數據分布的吻合程度.AC,PR,RE,ARI,NMI的值越大,聚類結果越接近于數據集的真實劃分,聚類效果越好.
設X是一矩陣對象數據集,C={C1,C2,…,Ck}是X的聚類結果,P={P1,P2,…,Pk′}是真實標簽,聚類個數為k,真實類別數為k′.假定k=k′,5種評價指標定義為
(14)
(15)
(16)


(17)
(18)

3.2 啟發式與全局性更新類中心算法的比較
為了評價啟發式更新類中心算法的有效性,本節在用MD fuzzyk-modes算法聚類的過程中,分別采用啟發式(HAMF)和全局性算法(GAMF)更新類中心,對比了實驗結果與運行時間.以Market Basket為例,運行10次,結果如表3和表4所示.其中,表3的“±”前后分別表示均值和標準差.

Table 3 Comparison Results of the MD fuzzy k-modes Algorithms with GAMF and HAMF表3 在MD fuzzy k-modes算法中用GAMF和HAMF更新類中心的結果比較
Table 4Running Time of the MD fuzzyk-modes Algorithms
with GAMF and HAMF
表4 MD fuzzyk-modes算法中用GAMF和HAMF更新
類中心的運行時間

AlgorithmsRunning Time∕sMD fuzzy k-modes+GAMF3.46725×105 MD fuzzy k-modes+HAMF160.313812
Notes: The bold value represents that the running time of the MD fuzzyk-modes algorithm with HAMF is much shorter than GAMF.
從表3和表4可以看出,用全局性算法更新類中心的聚類效果要好于啟發式更新算法,但耗時長達96 h.而啟發式更新算法在聚類效果相似的情況下只需耗時160 s.因此,在用MD fuzzyk-modes算法進行聚類時,選用本文提出的啟發式更新算法更有效.
3.3 MD fuzzy k-modes算法與其他算法的比較
本文選SV-k-modes,k-mw-modes,fuzzyk-modes,fuzzy SV-k-modes這4種算法與MD fuzzyk-modes算法進行比較,其中,fuzzyk-modes算法必須把矩陣數據轉換為單值屬性值形式,SV-k-modes,fuzzy SV-k-modes算法需把矩陣數據轉換為集值數據形式.在與SV-k-modes,k-mw-modes算法比較時,由于這2種算法不含模糊因子β,本文假定MD fuzzyk-modes算法中的β=1.1.在與fuzzyk-modes,fuzzy SV-k-modes算法進行比較時,由于在fuzzyk-type聚類算法[17-21]中,初始類中心的選取和模糊因子β對聚類結果有重要的影響,不同的初始化類中心和不同的β取值會導致聚類結果不同.本文從這2方面驗證MD fuzzyk-modes算法的有效性.在β的取值上,目前很多學者研究這一問題.Pal和Bezdek[26]在fuzzyk-means算法中設置β∈[1.5,2.5],Zhou等人[27]認為β的最優區間是[2.5,3],Huang等人[18]設置最小值β=1.1.由于β的取值沒有公認的準則,目前研究的最小值為1.1,最大值為3.本文設置β∈[1.1,2.9],步長為0.2.在初始類中心的選擇上,本文隨機初始化類中心30次,即2種算法在不同的β取值下分別運行30次,通過計算平均聚類質量來驗證MD fuzzyk-modes算法的有效性.數據集Market Basket,Microsoft Web,Musk,MovieLens,Alibaba在這5種評價標準上的實驗結果如表5~9所示.其中,“±”前后分別表示30次實驗結果的均值和標準差.
從表5可以看出,在不考慮模糊因子β的情況下,新提出的MD fuzzyk-modes算法比SV-k-modes算法、k-mw-modes算法在5種評價標準上的值高,說明聚類效果更好.
表6~9顯示,考慮模糊因子β時, MD fuzzyk-modes算法相較fuzzyk-modes算法在5種評價標準上的值有明顯提高.尤其是Market Basket和Microsoft Web數據集上,AC,PR,RE,ARI,NMI值有30%~60%的提高,這說明MD fuzzyk-modes算法要比fuzzyk-modes算法的聚類效果好得多.在MovieLens數據集上RE值雖有所下降,但在其他評價標準上有20%左右的提高;Musk數據集的實驗結果雖然沒有前3個數據集的效果明顯,但仍比fuzzyk-modes算法的值高.再者,相較fuzzy SV-k-modes算法,5種評價標準上的值也有所提高.在Market Basket和Microsoft Web數據集上,AC,PR,RE,ARI,NMI值有10%~20%的提高,在Musk,MovieLens數據集上的值相近,但比fuzzy SV-k-modes算法的值高,也說明聚類效果好.
上述實驗結果充分驗證了MD fuzzyk-modes算法對矩陣對象數據進行聚類具有較好的可行性與有效性.

Table 5 Comparison Results of the Three Algorithms on Five Data Sets表5 在5個數據集上3種算法的對比
Notes: The bold values represent that the highest value obtained by the MD fuzzyk-modes algorithm.

Table 6 Comparison Results of the Three Algorithms on Market Basket表6 在Market Basket數據集上3種算法的對比
Notes: The bold values represent that the highest value obtained by the MD fuzzyk-modes algorithm.
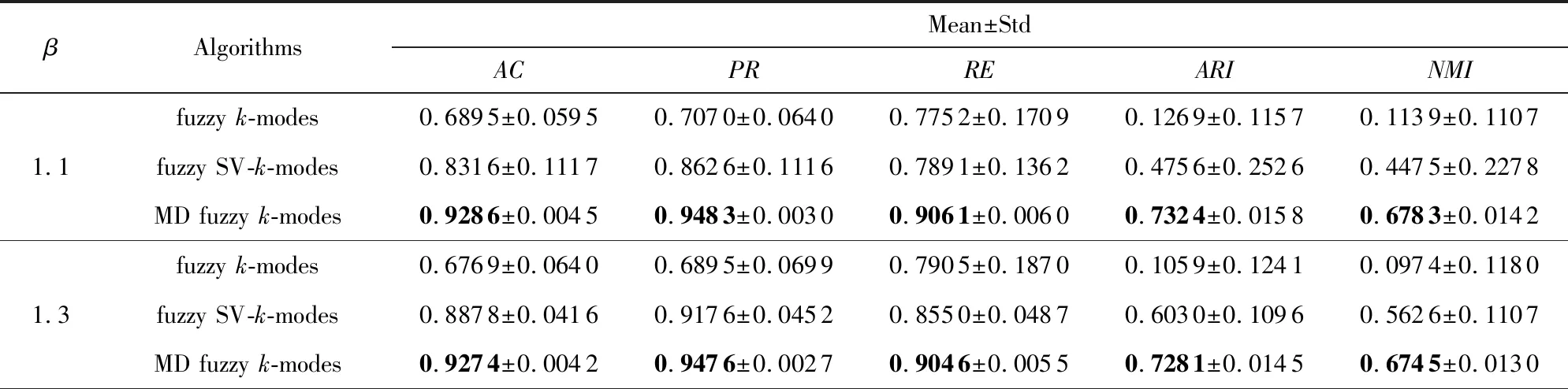
Table 7 Comparison Results of the Three Algorithms on Microsoft Web表7 在Microsoft Web數據集上3種算法的對比

Continued (Table 7)
Notes: The bold values represent that the highest value obtained by the MD fuzzyk-modes algorithm.

Table 8 Comparison Results of the Three Algorithms on Musk表8 在Musk數據集上3種算法的對比

Continued (Table 8)
Notes: The bold values represent that the highest value obtained by the MD fuzzyk-modes algorithm.

Table 9 Comparison Results of the Three Algorithms on MovieLens表9 在MovieLens數據集上3種算法的對比

Continued (Table 9)
Notes: The bold values represent that the highest value obtained by the MD fuzzyk-modes algorithm.
3.4 β與w的關系
由于β的取值直接影響矩陣對象歸屬到每個類別的隸屬度,因此有必要分析模糊因子β與隸屬度w的關系.由于數據集的對象數過多,本文只取前10個對象作為研究對象.經過30次實驗后求平均,Market Basket,Microsoft Web,Musk,MovieLens這4個數據集的實驗結果分別如圖1~4所示.其中,“○”表示矩陣對象分到第1類,“★”表示矩陣對象分到第2類,“□”表示矩陣對象分到第3類,“+”表示矩陣對象分到第4類.

Fig. 1 Relationship between β and w on Market Basket圖1 在Market Basket數據集上β與w的關系圖

Fig. 2 Relationship between β and w on Microsoft Web圖2 在Microsoft Web數據集上β與w的關系圖
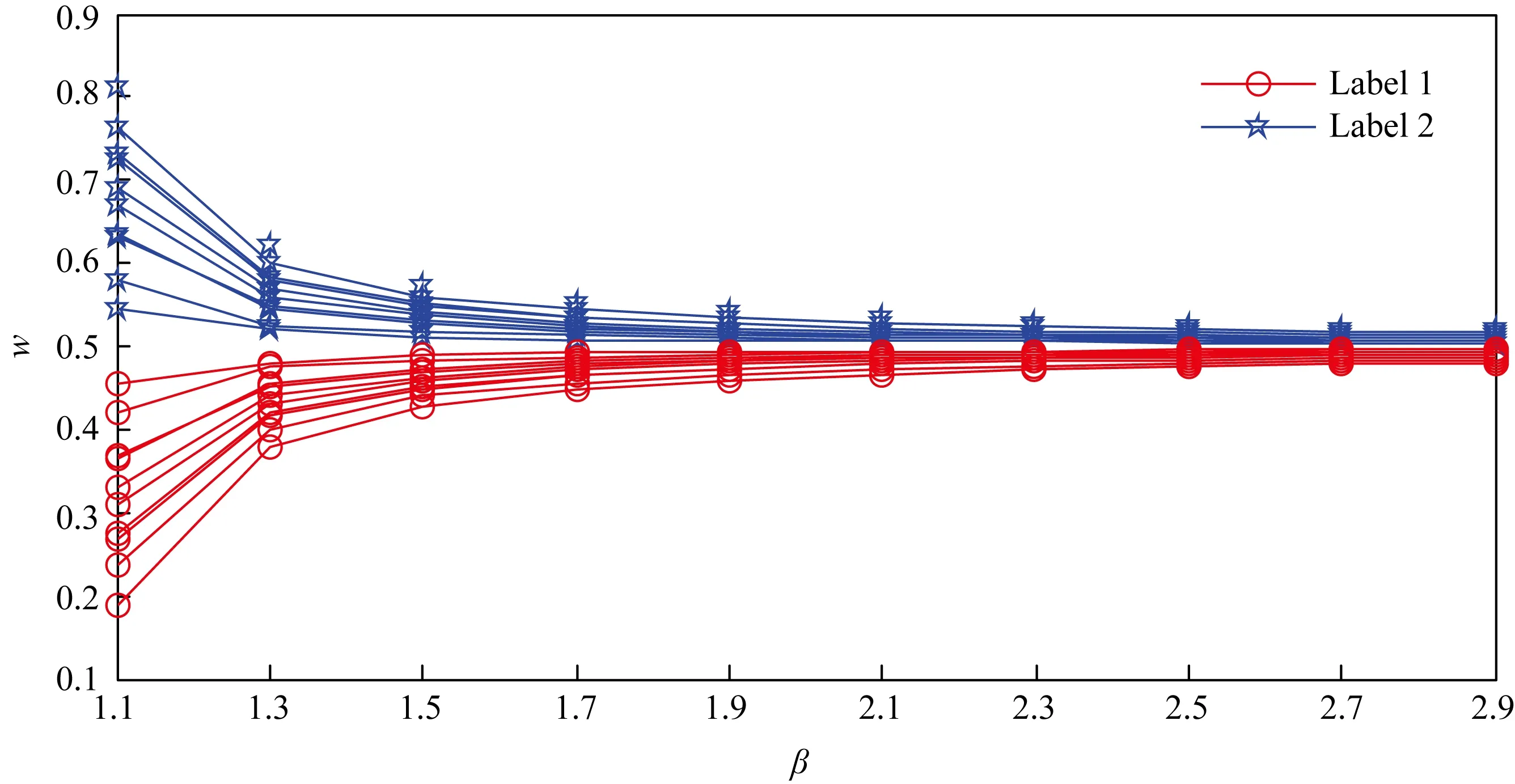
Fig. 3 Relationship between β and w on Musk圖3 在Musk數據集上β與w的關系圖
由圖1~4可知:隸屬度w明顯受模糊因子β的影響.隨著β的增大,w的值呈遞減(或遞增)形式變化.β的值越大,曲線越平緩,即隸屬同一類別的可能性越趨于一致.
4 結 論
實際應用中,大多數數據都是矩陣對象數據,為了對這類數據進行聚類,本文提出了一種新的聚類算法——MD fuzzyk-modes算法.首先,引用了矩陣對象間的相異性度量;其次,給出類中心的表示及啟發式更新算法;再次,提出了MD fuzzyk-modes算法;最后通過在Market Basket,Microsoft Web,Musk,MovieLens,Alibaba這5個數據集上的實驗分析,驗證了本文所提出的MD fuzzyk-modes算法在聚類效果上的有效性并分析了模糊因子β與隸屬度w之間的關系.大數據時代,通過MD fuzzyk-modes算法對多條記錄進行聚類,能更易發現客戶的消費喜好,從而做出具有針對性的推薦.
