多層神經網絡算法的計算特征建模方法
2019-06-26 10:04:56方榮強姚治成張偉功
計算機研究與發展 2019年6期
關鍵詞:模型
方榮強 王 晶,4 姚治成 劉 暢 張偉功
1(首都師范大學信息工程學院 北京 100048)2(體系結構國家重點實驗室(中國科學院計算技術研究所) 北京 100190)3(高可靠嵌入式系統技術北京市工程研究中心(首都師范大學) 北京 100048)4(北京成像理論與技術高精尖創新中心(首都師范大學) 北京 100048)
隨著神經網絡越來越廣泛地應用于語音識別、計算機視覺、智能機器人、故障檢測、市場分析、決策優化等領域[1-2],人們對網絡精度的要求不斷提高,網絡層數越來越多,計算復雜度越來越高,如2014年GoogLeNet[3]網絡已經達到22層.日益增加的計算復雜度使得訓練和推理的開銷問題逐步凸顯出來,當前GPU和FPGA等專用硬件加速芯片已經成為神經網絡運行的重要平臺.而隨著人工智能技術的進步,移動設備、嵌入式設備等在計算、體積、功耗等方面受限的設備也需要應用深度學習技術.由于設備資源的約束,導致現有復雜的深度神經網絡無法進行高效的計算.上述場景為計算機體系結構提出了新的挑戰:如何在保持現有神經網絡精度不變的情況下,使得網絡模型能在資源受限的設備上高效運行,并最大化系統資源利用率.
針對上述問題可以從算法角度減小網絡計算量,也可以從硬件角度優化資源利用率.現有研究從算法角度提出了大量優化方案[4]:針對神經網絡運算矩陣和矩陣相乘的運算方式,可以利用奇異值分解來壓縮神經網絡計算量[5];針對權重矩陣往往比較稀疏的特性,可以利用矩陣稀疏編碼的方式壓縮神經網絡[6];通過改變卷積運算算法可以加速網絡執行[7-12];權值重載方式也能夠有效減少片上存儲開銷[13].算法的優化可以實現對深度神經網絡的壓縮,從而削減網絡的計算量和存儲需求,提高網絡執行的效率,但這些方法同時也都是預先靜態地對算法進行優化,無論裁剪到什么程度的網絡,最終都需要在實際的硬件上運行,因此從體系結構角度,在有限硬件資源上優化神經網絡的運行效率是當前研究的重要問題.
研究人員從體系結構角度入手,提出多種提升神經網絡執行速度的方案:利用神經網絡中數據重用的特點可以優化卷積神經網絡[14];文獻[15]將網絡權值矩陣和輸入矩陣進行矢量化操作,能夠大大減小運算量,提升計算效率.將神經網絡從通用處理器CPU的執行平臺,遷移到具有高并行度的GPU和FPGA平臺也是有效提高運行效率的手段.利用OpenCL將卷積計算轉化為并行度更高的矩陣乘法運算能夠進一步優化GPU平臺上卷積運算效率.FPGA平臺上利用可重構和流水化并行執行的卷積運算過程能夠實現對執行速度和資源利用率的同步提升,基于FPGA的可重構特性能夠化簡乘法運算,提高系統能效性[16-19].
然而,無論哪一種神經網絡加速器的設計,都需要了解算法的特征,根據不同算法的計算規模有針對性地分配計算和存儲資源,才能在提高程序運行效率的同時最大化系統資源利用率.此外,對于硬件加速器設計的驗證,如果運行真實的大規模神經網絡將導致驗證的周期和成本都大幅增加.而抽取典型計算片段不但能夠保證功能驗證覆蓋率,還能有效降低驗證成本.要達到這2方面目的,都需要對算法的特征進行分析,找出模型中頻繁出現的層,本文稱為算子(operator),了解算子的計算和訪存特點,從而找到加速優化的切入方向.
因此本文提出基于基本運算的神經網絡特征提取優化方法,主要貢獻包括3個方面:
1) 針對典型神經網絡進行分析,找出其中核心算子,對每個算子分析內部包含的基本運算、運算的數量和內存占用量隨輸入變化的關系.
2) 在算子的粒度,根據網絡的描述解析網絡基本結構,獲得包含算子和算子順序的模型通用表達式,并給出圖形化描述.根據分析獲得的算子內部特征和模型通用表達式,計算網絡模型的乘加運算量、存儲占用量等典型特征值.
3) 基于所獲得的運算量等網絡特征,結合硬件資源數量,提出基于最大值的網絡運行調度優化方案,提高了神經網絡的執行效率,同時最大化硬件資源的利用率.
1 基于運算操作的神經網絡特征提取方法
神經網絡通常由不同的層,如卷積層、池化層、全連層等以特定順序組合而成,其中乘法和加法操作(operation)是基本的運算.為了分析神經網絡運行對硬件資源的需求,首先從“層”的粒度分析網絡結構,然后基于每層的運算特點分析該層所需要的乘法和加法等基本操作的次數以及所需占用的存儲空間.
1.1 神經網絡模型解析
深度神經網絡雖然可以通過改變層級結構、神經元個數以及神經元之間的連接衍生出不同的網絡模型,但網絡中所涉及的核心算子種類并不多,通常包括卷積層、池化層、激活函數和全連接層等.盡管輸入和參數不同,但每個算子的運算方式是確定的,因此可以通過分析得到計算每個算子的基本操作和基本資源需求公式.
模型解析器可以分析神經網絡模型包含的算子以及算子的執行順序.按照算子的種類和執行順序,建立一個僅包含算子種類和其執行順序但不包含操作次數的圖形化通用表達式,把神經網絡中各種算子看作節點,把其所需要的輸入和產生的輸出作為連接節點的有向邊,這樣便產生了一個有向無環圖(DAG),這個圖結構作為后續特征提取模塊的輸入.
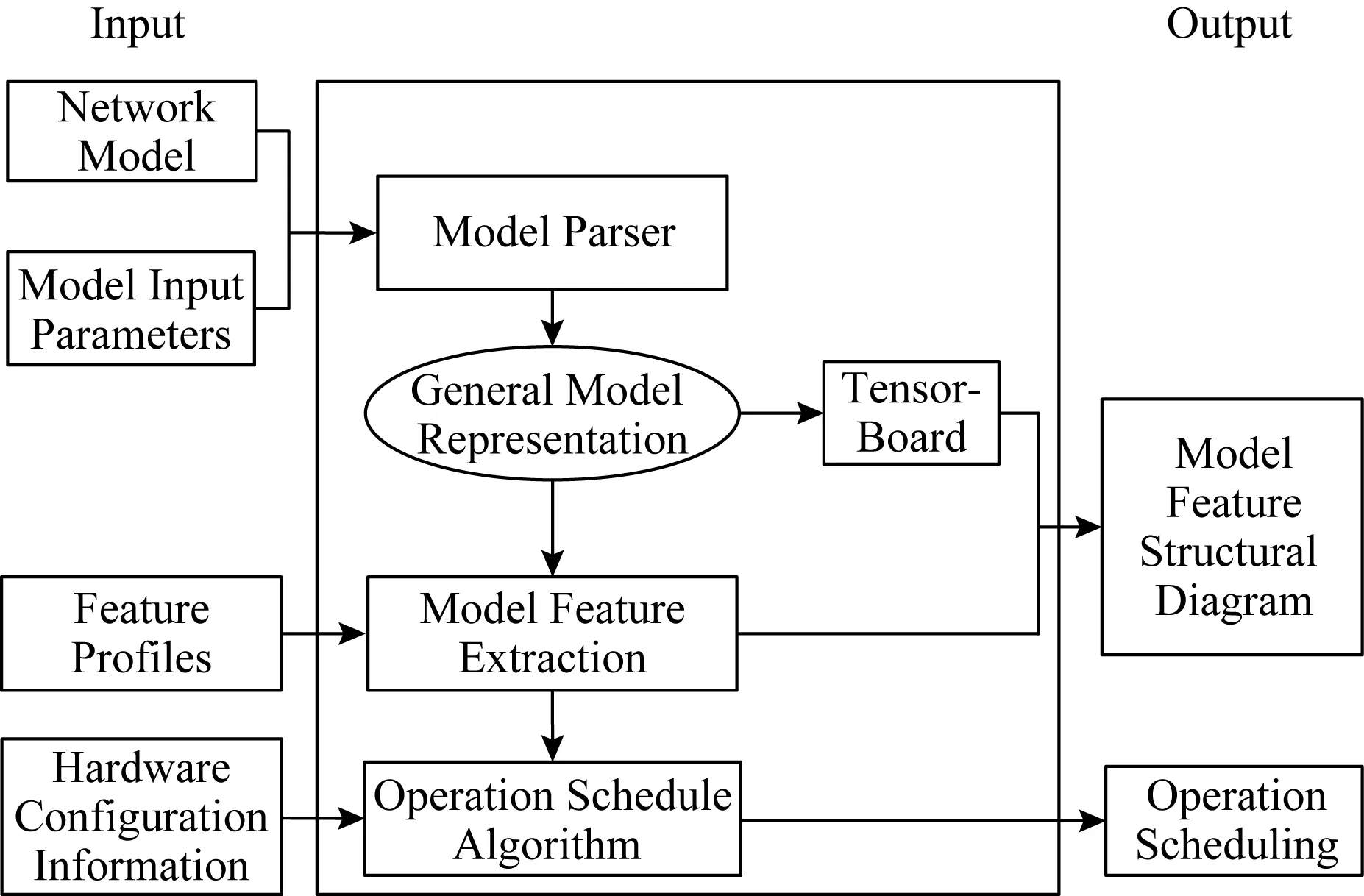
Fig. 1 Design of network feature extraction圖1 網絡特征提取整體設計
模型解析器是本文所提出的網絡特征提取方法的第1步,特征提取方法結構如圖1所示.模型解析器基于輸入的神經網絡模型和其對應的參數,分析模型所包含的層數和每層的功能,將網絡轉化成對應的通用表達式,然后通過TensorFlow內嵌的TensorBoard可視化組件獲得其圖形化的顯示,從而獲得模型結構和算子種類、算子數量和算子順序.在模型解析之后,模型特征提取模塊加載所獲得的通用表達式以及包含基礎算子的特征描述文件,獲得算子內包含的乘加等基本運算操作的類型、次數、存儲占用情況等特征.所獲得的計算和訪存特征作為運行調度模塊的輸入,結合系統硬件資源信息,例如FPGA芯片能夠支持的加法器和乘法器個數,運行調度模塊采用最大值更替算法計算出在給定硬件資源下最大化資源利用率的網絡運行調度方案.
1.2 基于算子的模型特征提取
算子的計算量等特征是可以通過加載提前設定的配置文件(profile)來解析統計出加法和乘法等基本操作計算公式.模型特征提取模塊負責根據計算公式對輸入模型進行整體的特征提取與計算.模塊的輸入包括2部分:配置文件和模型通用表達式,其中模型通用表達式是模型解析器傳遞的包含算子種類及執行順序的分析結果,也就是沒有神經元具體執行運算和內存占用信息的圖結構.算子特征描述文件定義了算法模型中具體算子的特征.
當模塊得到通用模型描述文件和配置信息的輸入后,遍歷代表網絡模型的圖結構,進行模型特征信息的構建.對每個算子進行單獨的特征提取,通過計算參數配置文件的算子特征公式,可以獲得加法和乘法基本操作次數等神經網絡的特征,并對所有特征進行統計與存儲.
算子特征提取流程如圖2所示:首先判斷算子對應的類型在配置文件中是否有定義,如果有,則從模型算子節點中加載,按照配置文件中該算子的公式定義來計算出對應的乘法和加法等基本操作的次數,而后輸出該算子的特征;如果配置文件中沒有定義,則進行第2步判斷,檢測系統內部是否有內置特征解析方法,若有,則調用提取特征的函數對該算子進行解析,若無,則輸出空特征.
特征提取模塊通過配置文件管理器來管理所有的配置文件,管理器包含2方面的管理功能:算法模型初始化參數的管理和算法基礎算子的特征管理.算法模型初始化參數的管理將每個算子對應的信息做初始化賦值,算法基礎算子的特征管理記錄是對每個算子預置基本操作的特定計算公式.在以Conv2D算子為例的算子配置文件內容中,分為Var和Feature兩大部分.當解析該算子的特征時,首先利用字段Var中指定的方法進行變量初始化,即按順序從Var中讀取指定的變量提取方法,并將執行方法得到的結果存放在指定的變量中.對于算法模型,算子的計算量往往和輸入數據大小、維度等有關,所以在計算“算子的計算量”之前,需要把算子所涉及的輸入輸出數據樣式確定下來,例如模型輸入圖片的大小、批大小(batch_size)等參數.神經網絡算法模型由不同功能的算子通過不同的連接方式組成,算子不同則計算類型、計算量、數據處理大小等都不一樣,所以對于“特征提取模塊”而言,它需要知道用于構建模型的每個算子參數、計算特征等,例如二維卷積算法需要知道卷積核的大小、移動步長、數據維度大小等特征后才能根據具體的算法得出該算子在模型中的特征.為了方便特征提取模塊獲取每個算子的屬性,參數配置文件管理器基于配置文件的算子管理方式,當用戶需要修改或者添加算子特征時只需修改對應的配置文件.
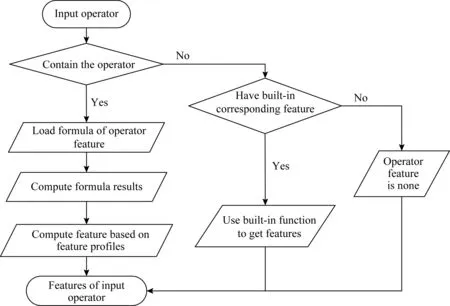
Fig. 2 Operator-based feature extraction process圖2 基于算子的特征提取流程
1.3 算子的特征計算方法
本文選取了10種典型神經網絡算子,根據算子的輸入參數列表,如表1所示,以加法為例給出了每個算子計算資源需求的公式,如表2所示.
1) Conv2D算子.它是2維卷積運算,該算子實際上是用濾波器矩陣在輸入圖像矩陣上沿水平或豎直方向上按步長數值滑動的同時做加權疊加的操作.卷積核單次計算加法次數為((f_height×f_width-1)×in_channels)×out_channels,所需加法次數為(f_height×f_width×in_channel-1)×[(in_height-f_height)strides+1]×[(in_width-f_width)strides+1],最后乘以圖片的張數和輸出結果的通道數就可以得到卷積算子包含的加法次數.而二維卷積所包含的乘法次數,首先計算單個卷積核單次計算的乘法次數(f_height×f_width×in_channels),再乘以圖片張數和移動步數即可獲得其包含的乘法次數.
2) Avg_Pool.它為平均池化算子,該算子是通過定義一個方形窗口濾波器矩陣,讓該窗口以不重疊的步長strides在輸入圖像上沿水平或豎直方向上運算的同時記錄下該窗口矩陣范圍內所有輸入圖像矩陣元素的平均數作為輸出圖像矩陣的像素值,而輸出結果的圖像矩陣大小取決于定義窗口矩陣的大小.該算子可以將輸入的圖像進行有效壓縮處理以節省資源消耗.關于平均池化的加法計算,步驟1是計算出它的移動步數,步驟2則是計算出它的每步所包含的數值的個數.首先,計算窗口大小ksize平均值需要Π(ksize)-1次加法;接著對輸出矩陣output進行求維度運算,可以獲得一個關于輸出結果的維度矩陣,即shape(output);而后對該維度矩陣求連乘積,即可獲得輸出矩陣中所包含的元素個數;最后將它們乘在一起就可以得到平均池化算子所包含的加法次數.而該算子所包含的乘法次數與輸出矩陣中的元素個數相等,因為對于每步池化都需要做一次乘法,又因為該池化核所走的步數等于輸出矩陣元素個數,因此其包含的乘法計算的次數為Π(shape(output)).
3) Max_Pool.它為最大池化算子,與平均池化算子相同,都包含ksize參數和同樣的生成規則,與之不同的僅在于它不取窗口內的平均值而取其最大值作為輸出結果.其加法計算即為在最大池化核的范圍內進行數據比較次數,實為減法操作次數,故需要比較Π(shape(output)×(Π(ksize)-1)) 次.由于該算子是將池化核內所有數據進行比較,因此不需要計算乘法.
4) Bias_Add.它是對2維卷積層和全連接層添加偏置值的標準化函數,該算子所包含的加法次數即為矩陣的維度,由于是直接相加,因此乘法計算次數為零.

Table 1 Typical Operation Input Parameters表1 典型算子輸入參數

Table 2 Analysis of Add Operation Feature of Typical Operators表2 典型算子加法特征分析
5) MatMul.它為矩陣乘法算子,是全連層主要的運算.其輸入為Ax×m和Bm×y的矩陣,這2個矩陣經MatMul算子運算后得到Cx×y的矩陣,因此產生的結果中有x×y個新數值,結果元素可計算為
cij=ai1b1j+ai2b2j+…+aimbmj.
每個元素的計算需要m-1個已有數值相加,因此其加法次數為x×y×(m-1)次,而乘法次數也相應為x×y×m次.
6) LRN.它為局部相應歸一化算子,用來抑制過擬合現象,并加快收斂速度的算子[20].可計算為

7) Softmax.它為神經元激活函數算子,該算子將多分類的輸出數值轉化為相對概率,經常被用于分類器后的輸出單元做處理,依據Softmax函數的計算公式:Softmax[i,j]=exp(logits[i,j])sum_j(exp(logits[i,j])),可知其分母由輸出層類別個數num_classes相加而成,因此加法計算次數為num_classes-1.又因為訓練一個樣本有num_classes個結果需要激活函數Softmax函數進行計算,所以加法次數為num_classes×(num_classes-1),最后乘以每次訓練投放的樣本個數batch_size可以獲得一次完整訓練所進行的加法次數.對于分母累加中的每一項,分別有logits[i,j]-1次乘法,共有num_classes項相加,故有(num_classes)×(logits[i,j]-1)次乘法.又因為需要對樣本中每個數據做Softmax激活,而每次激活時需要做一次除法.除法在機器運算實為右移操作,而乘法為左移操作,在功耗上的消耗相當,因此可看做是做一次乘法,故需要做batch_size×num_classes+1次.而Softmax包含的乘法次數為(batch_size×num_classes)×num_classes×[(logits[i,j]-1)+1].
8) Sigmoid.它也是神經元激活函數算子,其計算公式為Sigmoid(Output_index)=1(1+e-Output_index),其加法次數為1次,乘法次數在分母運算了Output_index次,共計Output_index+1次.
9) tanh.它是常用的激活函數算子,也稱為雙曲正切函數.tanh在特征相差明顯時效果較好,在循環過程中會不斷擴大特征效果.其計算公式為
tanh(Output_index)=(eOutput_index-e-Output_index)
(eOutput_index+e-Output_index),
其加法次數為2次,乘法次數由于eOutput_index計算一遍后可以多次重用,故其乘法次數為Output_index+1次.
10) ReLU.它為激活函數算子,由于函數解析式簡單,因此能獲得更快的收斂速度.其計算公式為ReLU(Output_index)=max{0,Output_index},該算子不包含乘法,僅有一次比較,故加法次數為1.
本文針對以VGG和AlexNet為代表的主流神經網絡,在層粒度進行了解析.所提出的靜態分析方案不增加動態網絡運行延遲和能耗開銷.同時,本文所提出的方案給出了網絡層粒度的任務分布,可以結合對網絡數據流的分析,建立動態網絡運行分析模型,為綜合優化性能和能耗提供支持.
神經網絡架構通常計算密度高、存儲需求大,為了適應低功耗的移動等存儲環境,裁剪和量化技術被廣泛應用.量化技術通常對所有輸入數據采用統一的方法,如散列和定點化進行處理,因此對于增加量化技術的神經網絡,量化的計算量與輸入數據規模成比例.而對于應用剪枝技術的神經網絡,本方法可以計算出網絡的計算量和存儲量上限,結合裁剪技術的具體實現方案,通過對權值矩陣的分析統計裁剪情況,得出實際的網絡計算特征.
2 基于神經網絡特征的運行優化算法
支持深度神經網絡運行的GPU和FPGA平臺能夠同時并行執行大量乘加運算,甚至可以支持多個算子的并行執行,流水化地執行多個輸入可以有效提高硬件資源利用率[21].以FPGA為例,FPGA芯片可以劃分為多個DSP,乘法器和加法器都由若干個DSP組成,此時算子所需硬件計算單元就可以轉化為DSP數量,當算子在FPGA芯片上執行無法占滿整個芯片時,可以根據所需DSP數量計算組合方案,在同一時間內可以讓多個算子同時處理.
專用硬件加速器和FPGA通常都只能包含固定數量的加法器和乘法器,具體的數值則由它的結構和硬件工藝所確定.然而,硬件支持的乘加運算器數量和神經網絡不同層次所需要的乘加操作次數難以完美匹配,也就是可以放入同一塊芯片或加速單元中運行的算子有多重組合.如果沒有對網絡結構和拓撲進行全局性的分析,系統只能順序或者隨機地選取算子執行,不但無法保證資源利用率,往往還會影響加速性能,加大硬件開銷.因此針對網絡內部不同層對硬件資源的需求,結合實際計算資源的情況進行優化調度是必要的.
本文利用所提取的特征分析結果對神經網絡在特定硬件資源下的運行調度方案進行優化,我們將不同的算子轉化成乘法和加法操作次數,結合系統資源的劃分,如FPGA中DSP的資源數量,提出最大值更替調度算法.本文以卷積層為例來進行調度的規劃,算法可以推廣到神經網絡包含的各種算子的硬件資源調度.
神經網絡的基本乘法和加法操作還可以歸一化量化為基本單元數,例如量化為邏輯門的數量或DSP的數量,根據不同的硬件描述和實現工藝,不同的層可以用乘法和加法數量乘以乘法器和加法器的門的數量需求得到本層以基本單元數為單位的尺寸.神經網絡的調度算法可以建模為不同大小的層,盡可能放入有限大小的硬件芯片上,這類似于背包問題.但與背包問題有2方面區別:1)背包問題只選擇部分物品裝滿一個背包即可,而神經網絡的所有操作都需要執行,如果總的操作數量大于當前硬件能夠支持的計算量,則需要多次執行,也就相當于多次背包;2)背包問題只給出選擇物品的數量,而調度算法需要獲得調度方案和具體順序以指導實際運行,因此我們改進了背包算法,提出基于最大值更替的調度算法.算法的描述如算法1所示.
算法1.基于最大值更替的調度算法.
輸入:硬件容量C、卷積層種數N、第i種卷積層的總個數ki、第i種卷積層綜合乘法開銷W[i];
輸出:使用的硬件總數、每個硬件分別承載的卷積層種類和其數量.
while (仍有卷積層未刪除) {
if (Ci-max≥0) {
Ci=Ci-max;
ki=ki-1;
記錄當前的bi;
if (ki==0) {
刪除該卷積層;
最大值設為當前數據中的最大值;
if (刪除的是最小值) {
最小值更新為當前數據中的最小值;
} }
}
else {
if (max==min) {
輸出所有記錄的bi;
重置記錄bi的數組;
算法計數器+1;
Ci=C;
最大值設為當前數據中的最大值;
}
else
max值更改為當前數據中的次大值;
}
}
算法1輸入分為2部分:1)網絡模型的各卷積層所包含的乘法和加法次數列表數據,該部分數據來自特征提取模塊所輸出的結果;2)當前所應用的硬件資源包含的基本單元數.設網絡模型中卷積層的大小有N種,第i(0≤i≤N)種卷積層執行所需的基本單元數W[i]由上一步的特征提取給出.在算法運行過程中記錄第i種的3方面信息:該種卷積層已被規劃了的次數ai、該種卷積層是輸入當中的序號bi以及該種卷積層當前的個數ki;同時將硬件平臺所包含的基本單元數量記為C.在規劃過程中,首先判斷當前基本單元數Ci是否大于當前最大卷積操作的資源需求max,如果大于那么當前卷積可以執行,則Ci=Ci-max且最大值的ki=ki-1;此時再判斷ki是否為0,如果為0那么從當前數據中移除該種卷積,最大值max重新設為當前數據中的最大值,如果此時移除的恰好是當前最小卷積操作資源需求min,那么將該卷積移除后更新min值為當前數據中的最小值.如果當前基本單元數量Ci比卷積操作的最大值max小,那么就判斷當前的最大值是否跟當前數據中的最小值重合,如果重合那么將當前基本單元數Ci重置為C,最大值max重新設為當前數據中的最大值;而如果最大值和最小值還未重合,那么最大值設為當前數據中的次大值,而后再次進行Ci與max的比較.依次進行上述操作,直到所有卷積都完成規劃.
3 實驗評估
本文選取了6個被廣泛應用于各個領域中的神經網絡模型.
1) 圖像識別類模型.通過多層卷積算子提取出圖像的特征,根據提取出的特征對圖像進行處理、分析和理解,以識別各種不同模式的目標和對象.常見的包括:AlexNet模型、VGG模型和Inception模型.
2) 音頻識別類模型.主要作用是區分人聲、動物聲音或者音樂演奏等聲音,典型的神經網絡模型是VGGish.
3) 視頻識別類模型SSD.SSD是基于前向傳播的神經網絡、無全連接層、參數少、運行速度快、識別精度高.
4) 文本類模型Attention.Attention模型從網絡中某些狀態集合中選取與給定狀態較為相似的狀態,然后訓練一個模型來對輸入進行選擇性的學習并且在模型輸出時將輸出序列與之進行關聯.
首先,通過分析各個模型所包含的算子類型和數量,如表3所示;然后從模型復雜度和資源需求等方面對算子的特征進行分析;最后,采用所提出的最大值更替算法給出了調度方案,并同順序調度方案對比資源利用率的提升效果.本文用TensorFlow中的圖形化組件TensorBoard,按前面的設計方法,可以提取出神經網絡的圖形化表示,如AlexNet的圖形化表示,如圖3所示.通過分析可以清楚地得到AlexNet網絡的結構圖,由8層組成,共有5個卷積層和3個全連接層,分別是輸入層→卷積→池化→卷積→池化→卷積→卷積→卷積→池化→全連接→dropout→全連接→dropout→全連接,在每一個卷積層后都經過了降采樣(pooling處理),同時該模型中加入了dropout操作.我們將6個神經網絡模型均按照上述方式進行建模,進而分析出它們的特征.

Table 3 Six Classical Neural Network Models表3 6個經典神經網絡模型

Fig. 3 The visualization model of AlexNet圖3 AlexNet可視化模型
3.1 經網絡特征分析
加速器的選取主要從3個角度進行分析:從模型的總體角度統計運算量,給出針對模型選用加速器的建議;從算子角度,通過對各個算子的運算量比較,得出針對該算子的加速器設計建議;考慮時間因素判斷模型各階段應使用的加速器結構.針對這3個需求,我們主要從模型復雜程度、卷積算子占算子總數比例、各模型占用內存量情況以及運算量4個角度對網絡的特征進行分類分析.
1) 模型復雜度分析
由模型復雜程度的對比,我們統計了所有算子的總數量.由于模型結構這一概念過于抽象,很難直接對模型結構進行討論,因此對模型的復雜度采用操作總數作為比較標準.
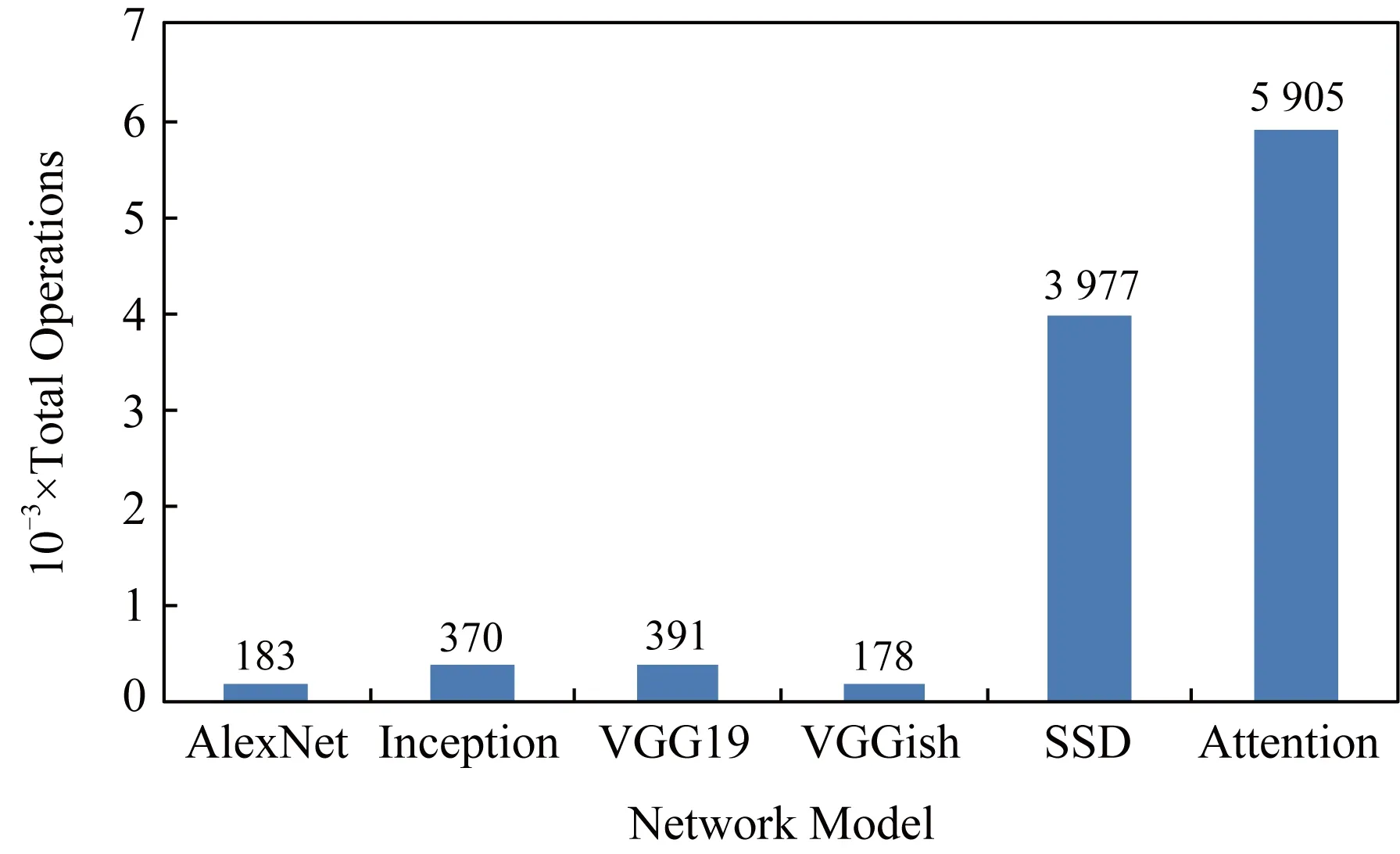
Fig. 4 Model complexity圖4 模型復雜度
從圖4對6種網絡的分析結果中可以看出,Attention網絡的算子個數最多,達到了5 905個,整個網絡模型也最復雜;而VGGish的算子個數最少,僅有178個,其結構也就最簡單.因此在模型結構復雜度角度,視頻識別模型SSD、文本識別類模型的操作數量非常龐大,因此可以在不影響模型功能的前提下從精簡算子數量的角度對模型進行優化.
2) 卷積算子占比分析
卷積操作是神經網絡眾多算子中計算復雜度和能耗開銷最高的算子,卷積的優化對提高網絡性能有重要的影響.基于本文所提出的方法,對6種網絡的卷積操作比例進行了統計,如圖5所示:

Fig. 5 Convolution operator proportion圖5 卷積算子占比
由圖5可知,圖像、視頻識別類模型、卷積算子占比明顯多于文本類模型和音頻模型中的卷積算子占比.這是由于卷積在網絡中擔當著對輸入進行特征提取的工作,卷積算子越多,對輸入提取出的特征就越詳細.音頻分析網絡由于沒有圖片特征分析那么高的要求,故比例相對較低.根據這些分析,在加速器設計過程中對卷積占比高的神經網絡進行加速,可以通過減少卷積操作方式或個數等技術達到更好的效果.

Fig. 7 Radar charts of hardware resource consumption distribution for neural network models圖7 各神經網絡模型硬件資源消耗分布雷達圖
3) 內存需求分析
神經網絡的執行過程中要存儲大量中間結果,因此對內存需求量往往較大.我們使用各個模型總內存占用量除以運算次數得到如圖6所示的內存占用量.
針對統計出的模型中平均每次運算占用的內存量設定閾值0.1B次,超過閾值的模型體現為訪存密集型;小于閾值的模型則體現計算密集型.在這些網絡中,AlexNet的平均每次運算占用的內存量遠超過其他的神經網絡,它在這些網絡模型中訪存比例更高,因此調度運算順序,減小運算中間結果的存儲等優化方法能夠有效提高這類網絡的性能.

Fig. 6 Operational memory usage圖6 運算占用內存使用量
4) 模型特征分析
基于對模型的操作數、卷積占比、平均內存量、加法次數、乘法次數5個方面的統計信息,通過雷達圖對比不同模型的特征,如圖7所示.結果顯示每個模型都有自己的特點:SSD和Attention計算占用內存方面比較小,其他資源消耗比較平衡.而AlexNet,Inception,VGG19和VGGish這4個模型都是卷積占比突出,因此本文針對這4個模型歸一比較,如圖8所示.模型在不同的維度展現出不同的特征,通過雷達圖結果的分析,能夠為未來加速器設計技術從加速卷積操作、減少內存占用等方面的選擇提供指導.
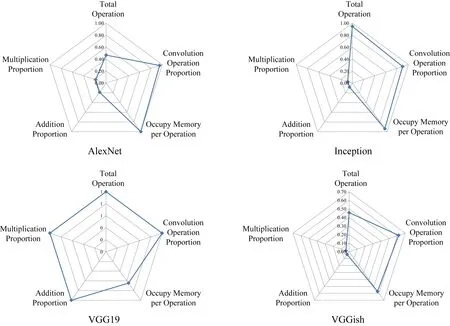
Fig. 8 Detailed comparison of AlexNet, Inception, VGG19 and VGGish resources圖8 AlexNet,Inception,VGG19,VGGish網絡資源占比詳細分析
3.2 神經網絡調度優化評測
我們對比了所提出的最大值更替調度算法和順序執行方案的資源利用率.順序調度方案將可以同時執行的操作按從大到小的順序依次放入芯片中.若可以放下,則更新當前芯片容量,同時減少該種算子的數量;若放不下則啟用下一個芯片計數繼續放置,算法描述如算法2所示.
算法2.順序調度.
while (仍有卷積層未刪除) {
if (Ci-max≥0) {
Ci=Ci-max;
ki=ki-1;
記錄當前的bi;
if (ki==0) {
刪除該卷積層;
最大值設為當前數據中的最大值;
}
}
else {
輸出所有記錄的bi;
重置記錄bi的數組;
算法計數器+1;
Ci=C;
最大值設為當前數據中的最大值;
}
}
本文參考XC7VX690T系統資源進行調度,該實驗板的DSP數量為3 600.規劃方案中芯片的平均利用率如圖9所示:
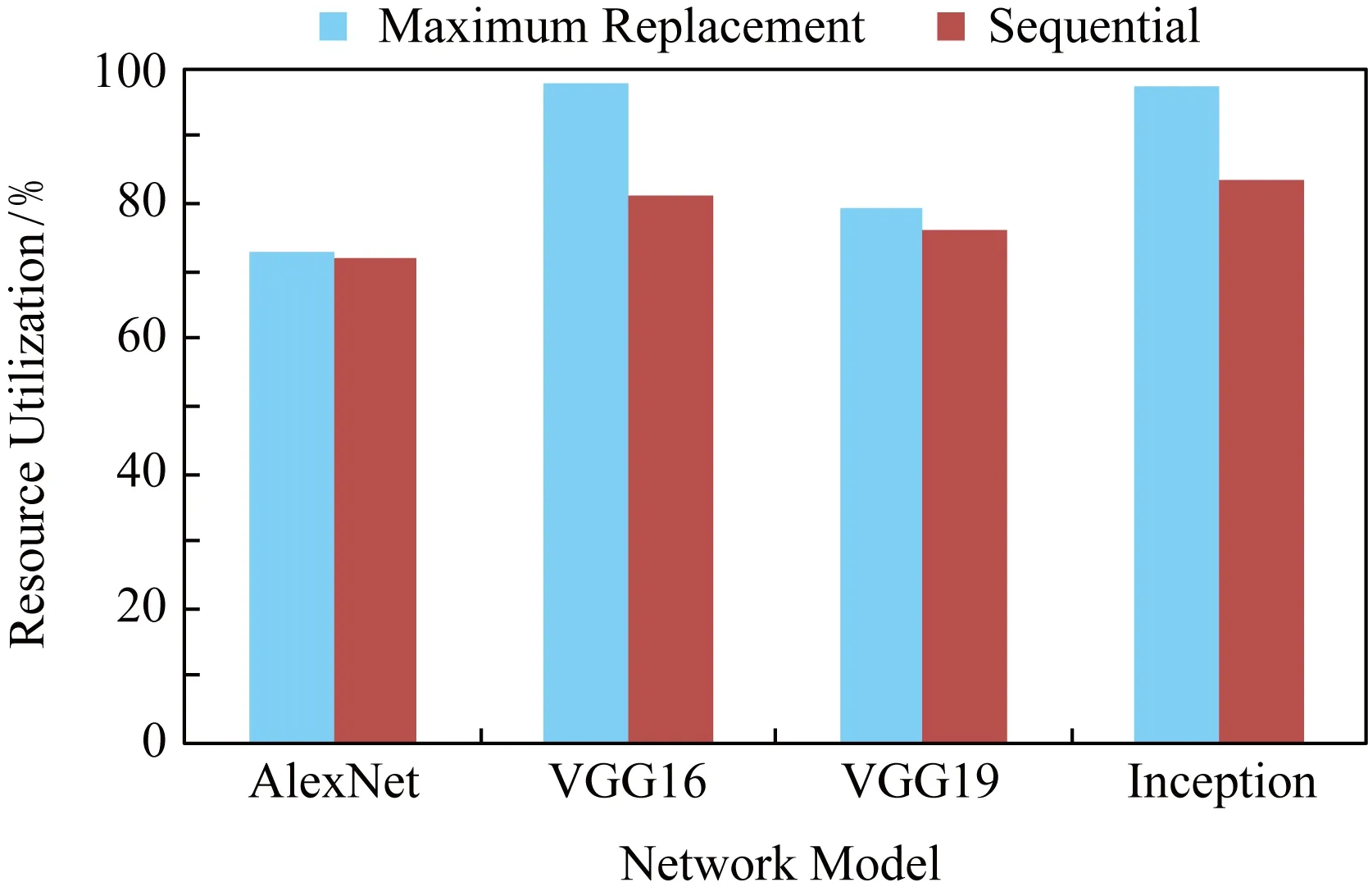
Fig. 9 Hardware resource utilization rate圖9 硬件資源利用率
結果顯示最大值更替調度算法顯著地提高了VGG16和Inception網絡運行時的硬件資源利用率.VGG16網絡中,相對于傳統的順序調度,芯片利用率僅有81.31%,而在相同條件下,采用最大值更替調度算法,可以將芯片使用率提升到97.57%.于此類似,在Inception網絡中,最大值更替調度算法將資源利用率提高了13.89%.而對于AlexNet和VGG19兩種算法的調度結果相差不大.從網絡特性角度分析,AlexNet網絡的雷達圖同Inception以及VGG都不同,而對于AlexNet算法順序調度得到的結果已經相對較好,因此最大值更替算法的提升效果不明顯.
而對比VGG16和VGG19,最大值更替算法能否產生作用,與輸入的數據分布有關.在這2個實驗中,模型上的差異只有層數不一樣,而卷積的相關參數是相同的,在這種情況下,同樣的輸入會使得調度大同小異,但若改變輸入的數據,其調度結果會因調度算法的選擇而產生較大的不同.本文所提出算法的計算復雜度為O(n!),順序調度方式雖然計算復雜較低,但是其芯片利用率遠小于基于最大值更替調度算法所提供的調度效果.
4 結 論
神經網絡技術日益發展的今天,各個領域對網絡運算速度和精度的需求都在不斷提高.然而隨著應用領域的不同,網絡模型也千差萬別.如何根據網絡規模設計高能效的加速器,以及基于有限硬件資源如何提高網絡性能并最大化資源利用率是當今體系結構領域研究的重要問題.為此,本文提出一種基于算子的模型分析方法,將神經網絡的層視為算子,首先分析模型的算子種類、數量和順序.然后基于不同算子功能分析統計算子中乘法和加法等基本操作數量以及內存占用量等特征的公式,實現基于不同輸入的模型特征分析.此外,本文提出基于計算特征的最大值更替調度算法,實現基于給定硬件資源和不同模型規模的運行調度方案.實驗結果顯示,本文所提出的方法為從體系結構角度分析神經網絡,優化硬件加速器的設計提供了參考和指導.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
