類腦機的思想與體系結構綜述
2019-06-26 10:16:56黃鐵軍余肇飛劉怡俊
計算機研究與發展 2019年6期
關鍵詞:模型
黃鐵軍 余肇飛 劉怡俊
1(北京大學計算機科學技術系 北京 100871)2(廣東工業大學信息工程學院 廣州 510006)
1 類腦基本思想
1.1 圖靈機
眾所周知,現代計算機產生的數學基礎是數理邏輯,物理基礎是開關電路.數理邏輯的研究對象是證明和計算這2個直觀概念符號化后的形式系統.1936年阿蘭·麥席森·圖靈(Alan Mathison Turing,1912—1954)為了研究不可計算數而提出了圖靈機模型,這一看似簡單的思想實驗抓住了數理邏輯和抽象符號處理的本質,劃定了計算的理論邊界:計算是機械式執行長度有限的算法的過程,這種計算都可以由圖靈機完成;所有算法都可以編碼成為一個整數,因此是可數的;盡管如此,并不存在枚舉出所有算法的算法.
但是,現在很多人把計算這個概念隨意泛化為任意的信息處理過程,這是不合適的.圖靈機的狀態和操作對象都是離散的,在圖靈可計算意義下,1和0.1111…(無窮循環小數)是2個不同的數,產生這2個可計算數的圖靈機也是不同的,圖靈機并不能發現在極限意義下兩者相等.極限是人類大腦的創造,在這個意義上,人腦是超越圖靈機的.
1.2 馮·諾依曼體系結構
1938年克勞德·艾爾伍德·香農提出開關電路模型,在數理邏輯和電路實現之間架起了橋梁.1946年首臺計算機ENIAC研制成功,實際上是一個近1.8萬個電子管作為開關的大型開關電路系統.之前的1945年,參與了ENIAC項目的馮·諾依曼(John von Neumann,1903—1957)提出存儲和計算分離的EDVAC結構,這篇報告分15章,長達百頁,但是后來成為經典的“馮·諾依曼體系結構”只是其中的前3章,篇幅不到全文十分之一,之后報告重點就轉到了神經系統.第15章沒寫完,馮·諾依曼后來也沒繼續寫下去,而是轉向研究怎樣用不可靠元件設計可靠的自動機,以及建造自己能再生產的自動機.
馮·諾依曼體系結構被經典計算機沿用至今,雖然有各種優化,但無根本性變化.在摩爾定律作用下,馮·諾依曼體系結構計算機的性能呈指數增長,一直作為包括人工智能在內的各種信息應用的基礎平臺.2004年至2005年前后,丹納德尺度縮微定律(在半導體的尺寸不斷縮小的同時其功耗密度大致保持不變)失效,普遍認為摩爾定律在持續50年后將于2020年左右走到盡頭,迫使人們重新思考計算機的體系結構問題.
1.3 人工神經網絡
1956年,人工智能的概念正式登上歷史舞臺.60多年來,人工智能經歷了3次浪潮,基本思想可大致劃分為三大流派:符號主義、連接主義和行為主義,從不同側面抓住了智能的部分特征.連接主義也稱神經網絡學派,其基本思想是:既然人腦智能是由神經網絡產生的,那就通過人工方式構造神經網絡,進而產生智能.
神經網絡思想的提出早于計算機的發明,1943年麥卡洛克和皮茨把神經元想象成“全或無”的邏輯開關,他們提出的神經元模型至今還是人工神經網絡使用的基本單元.80多年來,人們提出了各種各樣的人工神經網絡,但是實現神經元和神經突觸功能的物理器件一直未能發展起來.相比之下,馮·諾依曼體系結構計算機憑借集成電路摩爾定律的支持,性能呈指數增長,因此,缺少物理實現載體的人工神經網絡逐步“寄生”在計算機上運行.但必須指出的是,人工神經網絡結構和馮·諾依曼體系結構毫無可比性,從體系結構角度看,馮·諾依曼體系結構不是實現神經網絡運行的合理方案.
2006以來,多層神經網絡和機器學習相結合的深度學習在圖像和語音識別等領域取得突破性進展,大規模深度神經網絡和大數據訓練對計算能力提出了更高需求,經典計算機運行神經網絡能耗居高不下,按照神經網絡的結構設計新的機器結構,已是大勢所趨和必然選擇.
1.4 生物神經網絡
經典的人工神經網絡(artificial neural network, ANN)借鑒了生物神經網絡的基本特征,但過度簡化.1)人工神經網絡采用的神經元模型還是1943年提出的簡化模型,與生物神經元的標準數學模型霍奇金-赫胥黎微分方程相距甚遠,不是簡單的數值計算;2)人類大腦是由數百種不同類型的上千億的神經細胞所構成的極為復雜的生物組織,每個神經元通過數千甚至上萬個神經突觸和其他神經元相連接,即使采用簡化的神經元模型,用目前最強大的計算機來模擬人腦,也還有2個數量級的差異;3)生物神經網絡是一種復雜的脈沖神經網絡(spiking neural network, SNN),采用動作電位表達和傳遞信息,按照非線性動力學機制處理信息,目前的深度學習等人工神經網絡的時序特性還很初級.
僅就神經元模型而言,采用數字計算方法仿真生物神經元,計算復雜度比人工神經元模型要高多個數量級.即使采用簡化的脈沖神經網絡模型——泄漏積分發放(leaky integrate-and-fire, LIF)模型來實時仿真人類大腦,也約需要100臺太湖之光超級計算機.
更嚴重的是,神經網絡結構和馮·諾依曼體系結構大相徑庭,這對性能的影響更為致命.2010年左右提出的評價超級計算機的新指標——在大型隨機圖上每秒穿越的邊數(traversed edges per second, TEPS),能夠兼顧計算性能和通訊性能.如果將2個大腦神經元之間的一次脈沖傳遞類比為在圖上穿越一個邊,采用TEPS指標,人腦比當今最快的超級計算機也要快一個數量級.
與生物神經網絡相比,人工神經網絡過度簡化,要實現更強的智能,需要更復雜、更精細的神經網絡,最直接的藍本就是生物神經網絡.當前在計算機上采用軟件方式仿真實現神經網絡只是權宜之計,網絡規模難以擴大,更直接的方案是直接按照神經網絡結構設計全新的體系結構.
1.5 類腦機
理解意識現象和功能背后的發生機理(簡稱“理解智能”)是人類的終極性問題,制造類似人腦的具有自我意識的智能機器(簡稱“制造智能”)是工程技術領域重大挑戰.一種常見看法是制造智能的前提是理解智能,這實際上把問題的解決建立在解決另一個更難問題的基礎上,犯了本末倒置的錯誤.
要實現更強的機器智能乃至通用人工智能,首先要分清大腦的結構(主要是皮層神經網絡)和大腦的功能(智能、意識)這2個層次.盡管目標是實現智能功能,但理解智能機器困難,更現實的做法是回到結構層次,嘗試先制造出具有同樣結構的機器,通過訓練產生預期功能.自古以來人類的很多工程實踐都是采用這種技術路線,以深度學習為例,其網絡結構清晰、效果好,但機理不清楚,可解釋性理論是下一步需要突破的問題,而不是設計深度神經網絡的前提.
從人類大腦出發研究更強的機器智能乃至通用人工智能,我們認為更可行的技術路線是先結構仿腦,再功能類腦,最后才是理解大腦.因此,本文的“類腦”,主要是指結構類腦,即仿真、模擬和借鑒大腦神經網絡結構和基元(神經元、神經突觸)信息處理過程,中心任務是制造類腦機(brain-like machine),或稱神經機(neuromachine)[1-2].制造出這樣的智能機器,理解機器智能的機理,將能加速對人類大腦智能奧秘的揭開.
類腦機是仿照生物神經網絡、采用神經形態器件構造的、以時空信息處理為特征的智能機器.與生物神經系統一樣,類腦機是一種脈沖神經網絡,采用光電微納器件模擬生物神經元和神經突觸的信息處理功能,在仿真精度達到一定范圍后,有望具備生物大腦類似的信息處理功能和系統行為.簡言之,類腦機不是等待理解智能的機理后再進行模擬,而是繞過這個更為困難的科學問題,通過結構仿真等工程技術手段間接達到功能模擬的目的.
生物是類腦機的原型,生物智能活動主要是接收來自環境的多種刺激、實時處理并及時響應,這也是類腦機的主要功能和存在目的.
1.6 大腦解析進展
類腦機的體系結構源自生物大腦,這就需要獲得生物大腦基本單元(各類神經元和神經突觸等)的功能及其連接關系(網絡結構).人腦擁有數百種、上千億個神經元(即1011數量級),每個神經元通過數千乃至上萬神經突觸和其他神經元相連接(連接數量達到1014數量級).盡管如此,人腦神經系統仍然是一個復雜度有限的物理結構,采用神經科學實驗手段,從分子生物學和細胞生物學層次解析大腦神經元和突觸的物理化學特性,理解神經元和突觸的信號加工和信息處理特性,并無突破不了的技術障礙.
神經系統解析貫穿了神經科學百年歷史.1906年,諾貝爾生理學或醫學獎授予“在神經系統結構研究上的工作”的卡米洛·高爾基(Camilo Golgi,1843—1926)和圣地亞哥·拉蒙·卡哈爾(Santiago Ramon y Cajal,1852—1934),他們提出神經元染色法并繪制了大量精美的生物神經網絡圖譜,沿用至今.1939年劍橋大學阿蘭·霍奇金和博士后安德魯·赫胥黎開始研究神經元信號加工過程,自制工具測量到神經元的靜息電位和動作電位.二戰爆發,他們投筆從戎,1946年重新拿起膜片鉗,精細測量神經元傳遞電信號(或稱神經脈沖,更準確地稱為動作電位)的動態過程,并給出了精確描述這一動力學過程的微分方程,稱為霍奇金-赫胥黎方程(Hodgkin-Huxley方程,簡稱HH方程)[3].HH模型對不同類型的神經元具有通用性,1963年獲得諾貝爾獎.
加拿大生理心理學家唐納德·赫布1949年提出赫布法則(Hebb’s Law):同時激發的神經元之間的突觸連接會增強[4],至今這都是人工神經網絡模型廣泛采用的基本原則.1952年,中國現代神經科學奠基人張香桐(1907—2007)發現樹突具有電興奮性,樹突上的突觸可能對神經元的興奮精細調節起重要作用,1992年國際神經網絡學會授予張香桐終身成就獎,評價他“…為樹突電流在神經整合中起重要作用這一概念提供了直接證據……為我們將來發展使用微分方程和連續時間變數的神經網絡、而不再使用數字脈沖邏輯的電子計算機奠定了基礎”.1998年,Tsodyks和Markram等人提出了神經突觸計算模型[5].同年,畢國強和蒲慕明提出了神經突觸脈沖時間依賴的可塑性(spike-timing dependent plasticity, STDP)機制[6-7]:反復出現的突觸前脈沖有助于緊隨其后產生的突觸后動作電位并將導致長期增強,相反的時間關系將導致長期抑制.2000年,宋森等人給出了STDP的數學模型[8-9].
2008年,美國工程院把“大腦反向工程”列為本世紀14個重大工程問題之一.2013年以來,歐洲“人類大腦計劃”以及美、日、韓和我國的“腦計劃”相繼登場,都把大腦結構圖譜繪制作為重要內容.2014年,“單細胞分辨的全腦顯微光學切片斷層成像”獲得國家自然科學二等獎,并被歐洲人類大腦計劃用作鼠腦仿真的基礎數據.2016年3月,美國情報高級研究計劃署(IARPA)啟動大腦皮層網絡機器智能(MICrONS)計劃,對1 mm3的大腦皮層進行反向工程,并運用這些發現改善機器學習和人工智能算法.2016年4月,全球腦計劃研討會(the Global Brain Workshop 2016)提出需要應對三大挑戰,第一個挑戰就是繪制大腦結構圖譜[10]:“在10年內,我們希望能夠完成包括但不限于以下動物大腦的解析:果蠅、斑馬魚、鼠、狨猴,并將開發出大型腦圖譜繪制分析工具.”2016年9月8日,日本東海大學宣布繪制出包括十多萬神經元的果蠅大腦神經網絡三維模型,2019年1月,《Science》封面文章報道只用了3天時間就對果蠅完整大腦進行了納米級成像[11].
2018年,我國在北京懷柔開始建設“多模態跨尺度生物醫學成像”國家重大科技基礎設施,將具備從埃米到米、從微秒到小時跨越10個空間與時間尺度的解析能力,分步驟實現多種模式動物大腦的高精度動態解析.各方面的進展表明,人腦神經網絡精細圖譜有望在20年內完成.
2 類腦機研究進展
類腦機不是一個新想法.早在計算機發明之前的1943年,圖靈和香農就曾圍繞想象中的“電腦”進行過爭論,香農提議把“文化的東西”灌輸給電腦,而圖靈高聲反駁:“不,我對建造一顆強大的大腦不感興趣,我想要的不過是一顆尋常的大腦,跟美國電報電話公司董事長的腦袋瓜差不多即可[12].”1950年,圖靈在開辟人工智能方向的論文《計算機與智能》中明確表示:“真正的智能機器必須具有學習能力,制造這種機器的方法:先制造一個模擬童年大腦的機器,再教育訓練[13].”馮·諾依曼也曾認真思考過大腦,根據他未完成的西列曼演講整理而成的《計算機與人腦》一書1958年出版[14],上半部分為計算機,下半部分為人腦,討論神經元、神經脈沖、神經網絡以及人腦的信息處理機制.
實踐意義上的類腦機研制可以追溯到20世紀80年代.美國生物學家杰拉爾德·艾德曼(Gerald Maurice Edelman,1929—2014)1981年提出了統稱為“綜合神經建模(synthetic neural modeling)”的理論,即逼近真實解剖和生理數據的神經系統大規模仿真[15],并研制了一系列名為“Darwin”的“仿腦機”(brain-based-devices, BBD)[16-17],通過從多種仿真神經回路中進行選擇而實現學習.起初是軟件,1992年開始采用硬件,以2005—2007年研制的達爾文10號和11號為例,仿真約50個腦區、10萬神經元和140萬突觸連接,通過模擬嚙齒類動物走迷宮的過程,理解大腦空間記憶的形成過程.基于BBD的足球機器人于2004—2006年參加RoboCup機器人足球公開賽,曾5局全勝卡內基梅隆大學基于經典人工智能的系統.
現代微電子學和大規模集成電路先驅、加州理工學院教授卡弗·米德(Carver Andress Mead,1934—)也是在20世紀80年代把興趣轉向了生物神經系統的,與艾德曼關注神經元群體和神經環路不同,米德的關注點在神經元的硬件實現,開創了“神經形態工程(Neuromorphic Engineering)”這個方向[18-19],提出采用亞閾值模擬電路來仿真脈沖神經網絡,并提出了“神經形態處理器(Neuromorphic Processors)”的概念.1989年5月,米德在電路與系統研討會(International Symposium on Circuits and Systems, ISCAS)會議期間組織了“模擬集成神經系統(Analog Integrated Neural Systems)”研討會[20],主要參會人員至今仍然活躍在這一領域.
2.1 斯坦福大學的Neurogrid與BrainStorm
米德1989年招收的博士生博阿漢(Kwabena Boahen)2005年加入斯坦福大學,成立了“硅腦”(Brains in Silicon)實驗室,2009年研制出了神經形態電路板Neurogrid,每塊板16顆Neurocore芯片.每顆芯片內集成了65 536個神經元,每個神經元用340個亞閾值工作狀態的晶體管模擬,這樣一塊Neurogrid板就支持100萬個神經元和60億個突觸聯結,能耗只有5 W.每個Neurocore芯片都包括一個路由器,能夠在其本地芯片、父芯片及其2個子芯片之間傳送脈沖數據包.路由器支持多播樹路由組織,其中脈沖數據被點對點傳送到位于樹中所有預期目的地之上的節點,然后到達所有目的地,需要時可以復制.據稱Neurogrid在神經系統模擬方面可媲美能耗1 MW的超級計算機[21].
Neurogrid團隊2017年開發了新一代神經形態芯片BrainStorm,這一項目2013年啟動,由美國海軍研究辦公室資助,最后的成果將成為嵌入式應用和集群服務器上的計算芯片,可以運行全腦模型.目前還沒有相關論文解釋該項目的細節,但博阿漢指出Brainstorm與其他已有神經形態芯片設計存在著很大不同:“目前有很多神經形態設備使用的是超級計算機所使用的路由機制,就像網格一樣.問題在于,在網格架構中你只能進行點對點信號傳遞.如果你想一次發出多個信號,系統就會鎖死.”博阿漢說Brainstorm是首個實現從高層次描述合成的脈沖神經網絡的芯片,能解決多維非線性微分方程描述的問題,或者說是基于當前狀態與輸入隨時間變化而變化的那類問題.
2.2 從軟件仿真到IBM TrueNorth芯片
2005年,瑞士洛桑聯邦理工學院(EPFL)亨利·馬克拉姆(Henry Markram,1962—)牽頭“藍色大腦計劃”,在IBM藍色基因超級計算機上仿真大腦皮層[22].2007年IBM Almaden研究中心認知計算研究組在美國國防高級研究計劃局(DARPA)支持下開展神經形態自適應可塑性可擴展電子系統(systems of neuromorphic adaptive plastic scalable electronics, SyNAPSE)研究,開發了大腦模擬軟件——皮層模擬器(cortical simulator),2009年在藍色基因超級計算機上實現了8.61 T個神經突觸的貓腦模擬[23],所采用的神經元模型是簡化的LIF,即使如此,根據計算能力測算,實時模擬人類大腦也需要100臺太湖之光超級計算機.同樣在2009年,馬克拉姆團隊在藍色基因超級計算機上構造出出生2周大鼠的新皮質柱精細模型,包括1萬個神經元和數千萬個突觸連接,實現了生物神經網絡才擁有的伽馬振蕩現象.在此基礎上,由馬克拉姆領銜的歐洲“人類大腦計劃”于2013年1月獲得歐盟批準,提出整合從單分子探測到大腦整體結構解析,實現全腦仿真模擬[24].
IBM主導的SyNAPSE項目在超級計算機上進行大腦皮層仿真基礎上,為了突破規模瓶頸,也開發了神經形態芯片TrueNorth芯片[25],2014年Science將之列為年度十大科學進展.
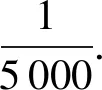
2016年4月,采用TrueNorth,美國勞倫斯·利弗莫爾國家實驗室和IBM公司公布了一款智能超級計算機,實驗室數據科學副主任吉姆·布雷斯表示:“仿神經運算為我們創造了令人激動的新機會,這正是我們國家安全任務的核心——高性能運算和模擬技術的未來發展方向.仿神經計算機的潛在能力,以及它可以實現的機器智能,將改變我們研究科學的方式.”
2.3 歐洲的SpiNNaker和BrainScaleS
為了實現全腦仿真的目標,歐洲人類大腦計劃支持了2臺大型神經形態計算系統的研制:英國曼徹斯特大學的SpiNNaker系統和德國海德堡大學的BrainScaleS,2016年3月2臺階段樣機正式上線運行.
SpiNNaker[26-27]源于2005年開始的EPSRC項目,負責人是ARM處理器發明人史蒂夫·佛伯(Steve Furber,1953—).SpiNNaker系統采用定制ARM處理器作為基本單元,分為5代,最初的102機使用了約102個ARM核,計劃2020年完成的106機則集成了約106個ARM核.SpiNNaker研究的中心任務就是探索新的體系結構,采用包交換來模擬神經元之間的異步稀疏脈沖交換,可以在物理連接大大少于大腦的情況下實現相同性能的信息交換,具體細節將在第3節詳細介紹.
BrainScaleS由德國海德堡大學卡爾海因茨·邁耶(Karlheinz Meier,1955—2018)教授負責[28-29],前身是2005—2010年的FACTES項目,特點是從微觀層面研究神經元的信號處理特性及模擬電路實現,在介觀層面研究突觸可塑性及數字電路實現,在8英寸晶園上實現了20萬神經元和5千萬突觸,晶圓內總線速度達每秒1 T脈沖,晶圓間分布式通信速度每秒10 G脈沖.在人類大腦計劃支持下,2016年完成了20塊晶圓、400萬神經元和10億突觸的神經形態計算系統[30],速度比生物系統快1萬倍.2022年(也就是人類大腦計劃結束前)預計構造出一個500塊到5 000塊晶圓組成的大型系統,即使是500塊方案,也能同時仿真5億神經元,由于其速度比生物神經元高萬倍,因此將具備實時仿真人類大腦的能力.
2.4 我國相關進展
我國類腦研究起步較晚,但近年來十分活躍,北京大學、清華大學、中國科學院自動化研究所、浙江大學、四川大學等單位成立了多個類腦計算或類腦智能方面的研究中心.
2015年9月1日,北京市科學技術委員會正式發布“北京腦科學研究”專項規劃,從“腦認知與腦醫學”和“腦認知與類腦計算”2個方面進行布局[31].“腦認知與類腦計算”沿著“結構仿真、器件逼近和功能超越”這條技術路線,布局了3個層次、9個方面的科研任務:建設四大基礎性公共平臺(大腦解析仿真平臺、認知功能模擬平臺、神經形態器件平臺和類腦計算機系統平臺),開發2款類腦計算處理器芯片(類腦處理器和機器學習處理器),研制類腦計算機軟硬件系統,在視聽感知、自主學習、自然會話三大類腦智能方向取得突破并實現規模應用.經過3年多的持續支持,北京已經在類腦計算方面形成了較為系統的技術積累,清華大學研制的天機系列芯片和北京大學研制的超速全時視網膜芯片是其中的代表性成果.
清華大學團隊提出了類腦混合計算范式架構,開發了“天機”系列類腦芯片.2015年11月研制出首款跨模態異構融合神經形態類腦計算芯片,可進行大規模神經元網絡的模擬,具有超高速、實時、低功耗等特點,相關結果于2016年12月發表在《Science》智能機器人特刊.2017年10月研制成功天機2代神經形態芯片,采用28納米半導體技術,集成了千萬突觸和約4萬個神經元,同時支持脈沖神經網絡算法和人工神經網絡算法,與IBM TrueNorth相比,在芯片密度、速度和帶寬都有大幅度提升.2018年利用脈沖神經網絡的時空特性,實現了在時空域的SNN誤差反向傳播算法,解決了函數逼近的方法處理脈沖發放時刻不可導問題,建立了SNN全連接及卷積神經網絡新算法.
北京大學在北京“腦認知與類腦計算”支持下,圍繞視覺系統解析仿真開展研究,研制出類腦機的“眼睛”.2015—2016年對靈長類視網膜進行了高精度解析仿真,實現了視網膜中央凹神經細胞和神經環路精細建模,提出了模擬視網膜機理的仿生視頻脈沖編碼模型.2017—2018年初,研制成功脈沖陣列式超速全時仿視網膜芯片.生物視覺信息處理機制雖然優越,但受限于生理限制,“主頻”很慢,靈長類視網膜每秒發放的神經脈沖數平均不超過數十個.仿視網膜芯片脈沖發放頻率達到40 000 Hz,“超速”人眼千倍,能夠“看清”高速旋轉葉片的文字.“全時”是指從芯片采集的神經脈沖序列中重構出任意時刻的畫面,這是真正機器視覺的基礎,有望重塑包括表示、編碼、檢測、跟蹤、識別在內的整個視覺信息處理體系.
浙江大學及杭州電子科技大學聯合研究團隊主要面向低功耗嵌入式應用領域,于2015年研發了一款基于CMOS數字邏輯的脈沖神經網絡芯片“達爾文”,支持基于LIF神經元模型的脈沖神經網絡建模.2016 IEEE CIS計算智能相關的暑期學校將達爾文芯片作為一個案例供所有參加人員編程實踐與應用開發.
2017年國家自然基金委信息科學部研究確定了“人工智能(F06)”代碼,專門設置了“認知與神經科學啟發的人工智能(F0607)”方向,其中與類腦直接相關的支持方向包括:視聽覺感知模型、神經信息編碼與解碼、神經系統建模與分析、神經形態工程、類腦芯片、類腦計算.從2018年起,我國類腦領域的基礎研究已經全面展開.
3 脈沖神經網絡體系結構SpiNNaker
SpiNNaker是脈沖神經網絡體系結構(The spiking neural network architecture)的縮寫,是英國曼徹斯特大學Steve Furber教授帶領的先進處理器技術團隊(APT)研發的類腦計算系統,研究始于2005年,目的是借鑒大腦神經網絡結構研究新的計算體系結構.
SpiNNaker是一個大型脈沖神經網絡,采用獨特的全局異步局部同步(GALS)互連網絡結構,最新系統將不同時域的一百萬ARM微處理器核心和1 200個互連計算主板高效集成為1臺高度并行的超級計算機,每秒執行200萬億次定點運算操作,支持實時事件驅動的編程模式,適用于生物神經網絡的實時模擬.
3.1 體系結構
SpiNNaker系統由ARM微處理器核心、多核CPU芯片、計算主板、機架、機柜和整機等6個不同的層次構成,如圖1所示.2018年11月上線的最新系統采用的微處理器核心是200 MHz的32-bit ARM968微處理器,擁有32 KB指令存儲器和64 KB數據存儲器,不帶浮點運算單元.每顆多核CPU芯片包含18顆ARM968和一個中央片上網絡路由器,用異步片上網絡連接.48顆SpiNNaker多核CPU芯片構成一塊計算主板.24塊主板組成一個機架.5個機架構成一個機柜.10個機柜組成整個SpiNNaker系統.因此,SpiNNaker系統包含的ARM CPU數量為18×48×24×5×10=1 036 800個.一個200 MHz的ARM CPU可以生物實時模擬1 000~10 000個IF(integrate-and-fire)級別的簡單神經元模型,整個SpiNNaker系統理論上可以生物實時模擬10~100億個這樣的神經元.
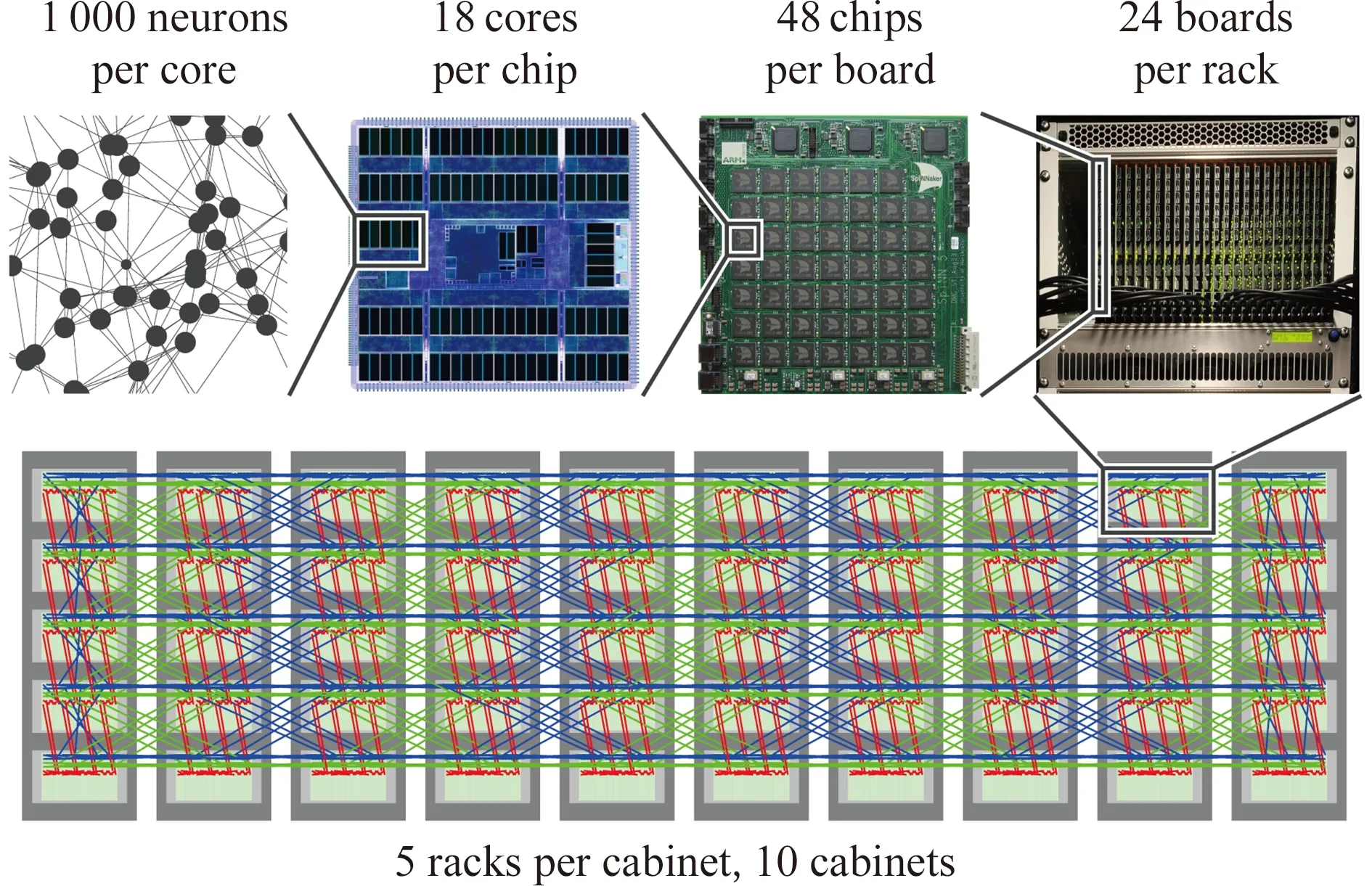
Fig. 1 Hierarchical structure of SpiNNaker圖1 SpiNNaker系統的層次結構
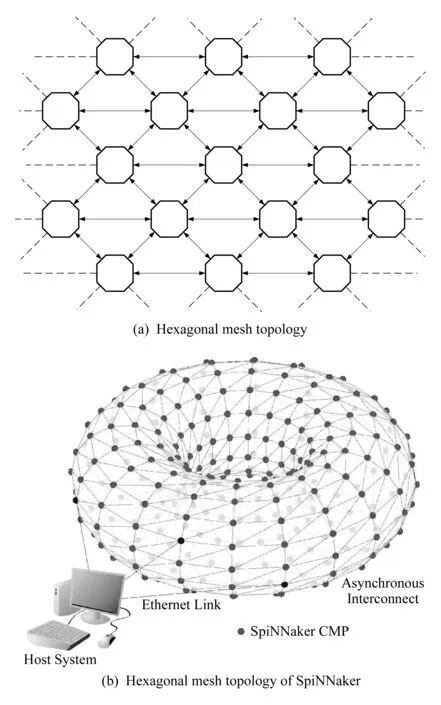
Fig. 2 Network topology of the SpiNNaker system[32]圖2 SpiNNaker系統的網絡拓撲結構[32]
SpiNNaker多核CPU芯片包含一個6端口的通信路由器與其他芯片連接.整個系統形成一個六邊形平面網格(hexagon 2D mesh)的拓撲結構,如圖2(a)所示,平面網格結構的左右和上下方向的邊緣接口相連,最終構成一個輪胎形態的環狀結構,如圖2(b)所示(其中CMP為chip multiple processors的縮寫,表示多核處理器芯片).
3.2 海量脈沖異步傳輸機制
人腦中的每個神經元通過神經突觸與成千上萬其他神經元相連接,每個神經脈沖要傳遞給成千上萬個神經元,這種高扇出(fan-out)的多播(multicast)傳輸方式對傳統超級計算機來說是個巨大挑戰.傳統超算支持點對點的大數據塊傳輸非常高效,但實現海量短小神經脈沖數據包的多播傳輸效率很低.
SpiNNaker系統研發了一種適用于大規模脈沖神經網絡模擬的高效“源地址多播傳輸”機制.SpiNNaker支持相鄰神經元數據包(nearest neighbor package)傳輸、點對點數據包(point-to-point package)傳輸、固定路徑(fixed route package)傳輸、神經脈沖數據包(the neural event package)傳輸等4種不同的數據包傳輸方式.前3種數據包用于初始化、狀態檢測、控制信息和參數傳遞等.
Fig. 4 Propagation mechanism of source-addressed multicasting圖4 源地址廣播的實現機制
神經脈沖數據包傳輸是SpiNNaker中最重要的傳輸方式,其數據包的格式如圖3所示.神經脈沖數據包為40 b或72 b,包括32 b數據載荷和8 b控制字,還可以額外攜帶一個32 b的數據載荷.通常意義上的神經脈沖數據包不需要攜帶數據,一個數據包的到來代表著一個神經脈沖到來的事件.在SpiNNaker系統中,負載是發送該神經脈沖的神經元的32 b源地址(可能遵循一定的規則,如16 b代表CPU編碼,16 b代表在該CPU中模擬的神經元地址).然而,這個結構中并沒有說明目的地址,數據包如何被精確地傳遞到成千上萬個目的地呢?SpiNNaker提出了“源地址多播傳輸”機制——數據包經過的路由器根據32 b源地址查找路由表,將該數據包復制到不同的輸出口,一級級傳遞下去.

Fig. 3 Neural spike package layout[32]圖3 神經脈沖數據包結構[32]
如圖4所示,每顆多核CPU芯片的路由器有東(E)、西(W)、東南(SE)、西南(SW)、東北(NE)和西北(NW)6個傳輸方向,簡稱a,b,c,d,e,f,還有一個“local”方向表示該芯片本地18顆CPU的傳輸方向.路由器中有一個路由表.路由表在實現上是一個CAM芯片,存儲許多行(如1 024行)的路由信息,支持所有行源地址的并行比較.每行有左右2列,左邊代表一個發送數據包的源地址,右邊代表傳輸的方向,由多位構成,表示多個方向.
路由器接收到一個數據包后,根據包的源地址并行查找路由表.如果查到,路由器就按照路由表的方向指示向一個或多個方向傳輸該數據包;如果沒有查到,路由器將包按照來的方向直接傳遞(a→d,b→e,c→f,d→a,e→b,f→c).如圖4所示,假如節點4傳遞一個數據包到節點7,源地址為4;節點7路由表中沒有4,按照直線傳給10;節點10路由表中顯示源地址為4的數據包按照d方向傳遞給9;節點9路由表再按照d,c方向傳遞給節點8和節點12(這時數據包被復制了),以此類推.路由表的信息在脈沖神經網絡運行之前由sPyNNaker軟件系統(3.3節介紹)統一初始化.
采用源地址多播傳輸機制進行海量神經脈沖的高扇出分發傳遞,使得數據包無需指明眾多的目的地址就能夠大規模地按照指定方向進行多播并行傳輸,有利于保證數據包格式的規范性,大大縮短了數據包的長度,提高了傳輸的速度.
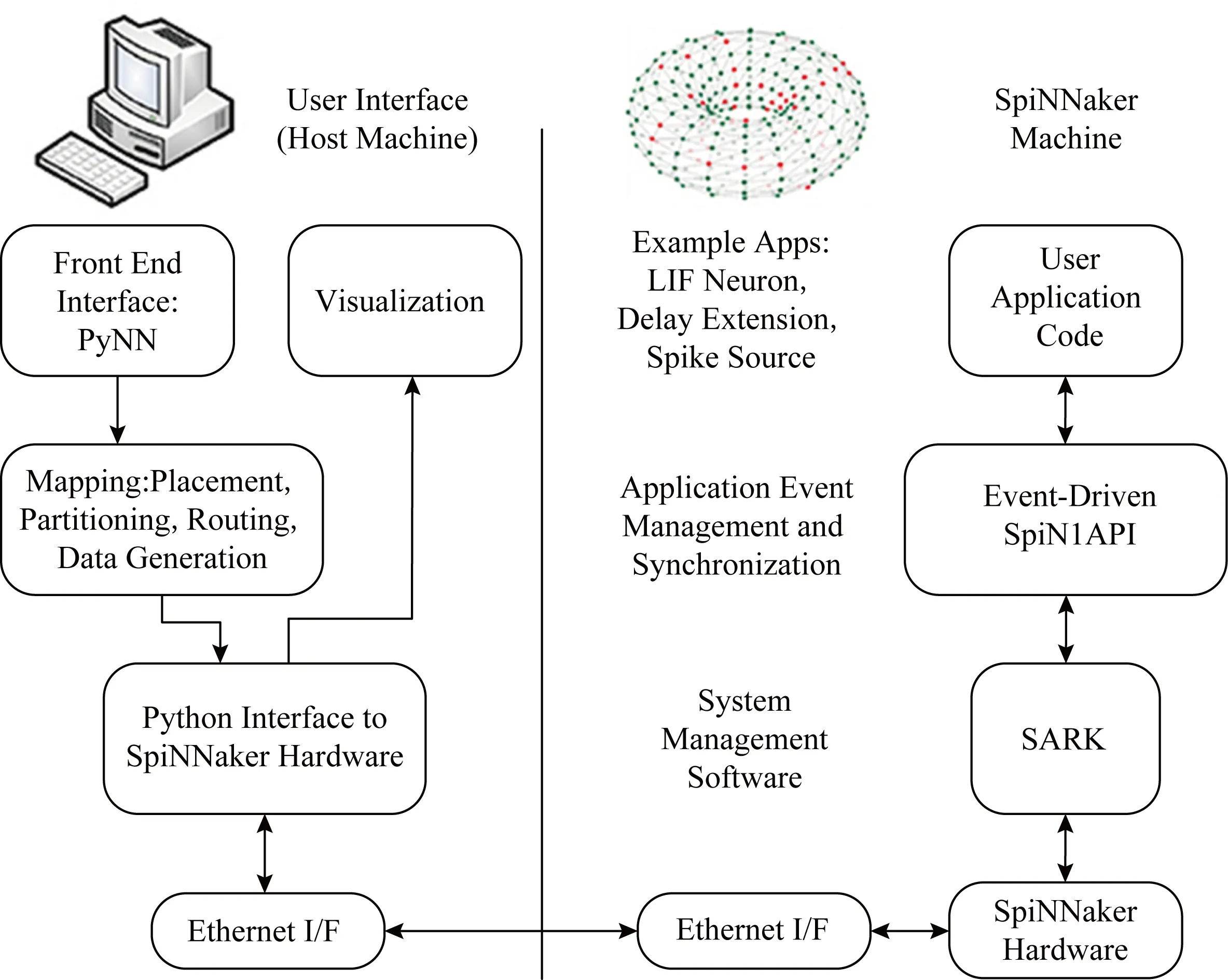
Fig. 5 Software system architecture of SpiNNaker[32]圖5 SpiNNaker的軟件系統結構[32]
3.3 SpiNNaker軟件系統
SpiNNaker的軟件系統稱為sPyNNaker,可以將PyNN語言描述的脈沖神經網絡解析并在SpiNNaker系統中仿真運行.PyNN語言是一種基于Python的跨平臺脈沖神經網絡描述高級語言,支持主流的脈沖神經網絡軟件仿真平臺,包括NEST,NEURON和Brian,因此SpiNNaker和BrainScaleS都支持它,以兼任支持各種脈沖神經網絡模型.
sPyNNaker軟件系統架構如圖5所示,各部分組成和功能均有顯示.
1) Front End Interface:PyNN.PyNN的前端接口模塊,用戶可以在客戶端利用PyNN接口編寫脈沖神經網絡模型.
2) Mapping:Placement, Partitioning, Routing, Data Gnenration.將PyNN描述的脈沖神經網絡根據用戶分配的硬件資源分解并映射到相應的CPU、內存和路由表中,生成配置信息.
3) Python Interface to SpiNNaker Hardware.負責客戶端與SpiNNaker硬件系統的接口,包括將配置信息通過互聯網下載到SpiNNaker計算機、傳輸模擬控制命令、將SpiNNaker的模擬結果傳回到前端等功能.
4) Visualization. SpiNNaker的虛擬可視化界面.
5) SARK(SpiNNaker application runtime kernel).底層的硬件管理,主要控制DMA、網絡接口和通信控制器等.
6) Event-Driven SpiN1API.支持事件驅動的操作系統,主要負責維護CPU內核中的任務安排進程、任務調度進程和快速事件響應等3個主要進程,支持實時事件模擬.
7) User Application Code.與神經網絡生成和模擬相關的應用開發庫文件,支持不同神經元模型、延時模型和脈沖源等.
sPyNNaker采用時間驅動(time-driven)和事件驅動(event-driven)兩種混合驅動方式來模擬脈沖神經網絡,時間驅動模擬神經元的變化,事件驅動模擬突觸的變化,如圖6所示.CPU用時間輪詢的方式模擬生物時間,例如ΔTCPU時間模擬1 ms的生物時間,在ΔT時間內,CPU輪詢該CPU中模擬的所有神經元,更新它們的狀態.CPU同時還需要響應來自于本CPU中神經元或者外部神經元發送的神經脈沖到達的事件,支持以組播的方式更新相連接的突觸,并更新神經元的狀態.各神經元狀態變化后可能產生新的神經脈沖,觸發事件驅動.
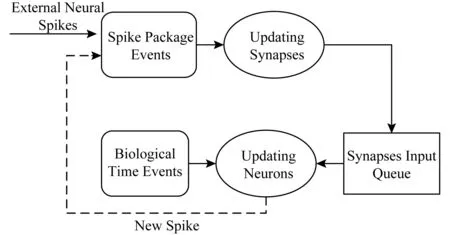
Fig. 6 Time-driven and event-driven simulation mode[32]圖6 時間驅動和事件驅動的模擬方式[32]
綜上,通過sPyNNaker軟件系統,用戶可以遠程使用SpiNNaker虛擬機,開發和操作接口與目前主流的脈沖神經網絡仿真平臺類似.
4 類腦機的信息處理潛力
類腦機和大腦都是脈沖神經網絡.本節先介紹采用脈沖神經網絡構造任意圖靈機的一種方法,它證明了脈沖神經網絡的信息處理能力不低于圖靈機;然后介紹脈沖神經網絡如何超越人工神經網絡;最后介紹噪聲可以提高脈沖神經網絡的性能,使得脈沖神經網絡具有實現馬爾可夫鏈蒙特卡洛(Markov chain Monte Carlo, MCMC)采樣與求解約束滿足NP-hard問題的能力.
4.1 脈沖神經網絡
脈沖神經網絡也被稱為第三代人工神經網絡[33],與前兩代人工神經網絡McCulloch-Pitts-Neuron[34],Perceptron[35]不同,脈沖神經網絡認為神經元脈沖發放以及脈沖之間的時間間隔也是一種重要的特性,更貼近于人腦中的真實神經元[36-37].
一個典型的生物神經元的結構如圖7所示,主要包括樹突、胞體和軸突3個部分.樹突收集其他神經元傳來的信息并通過電流的形式將其傳給胞體,胞體相當于一個中央處理器,樹突傳來的電流引起胞體膜電位變化,當膜電位超過一定閾值時,神經元將發放一個脈沖信號(稱為動作電位)并通過軸突傳給其他神經元.動作電位是一個幅值大約100 mV、持續時間1~2 ms的電脈沖[39].
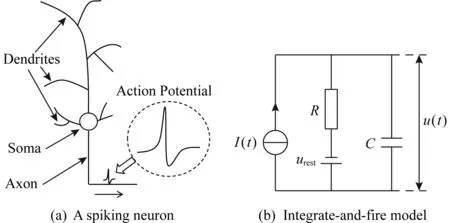
Fig. 7 A spiking neuron and integrate-and-fire model[38]圖7 脈沖神經元示意圖與積分發放模型[38]
計算神經科學家根據生物神經元的特性建立了諸多脈沖神經元模型,主要包括積分發放(integrate-and-fire)模型[40-41]、Hodgkin-Huxley模型[3,42-44]、Izhikevich模型[45-46]和脈沖響應(spike response)模型[47-48].這些模型以不同的精度描述了生物神經元產生動作電位的動態過程.
常用的積分發放模型最簡單如圖7所示,它將神經元的膜表示為一個電容器C,當神經元接受輸入電流時,神經元的膜電位u(t)可以表示為
(1)
其中,R,I(t),urest分別表示神經元的電阻、輸入電流和靜息電位.當時刻t神經元的膜電位u(t)超過一個閾值θ時,神經元將發放一個脈沖且膜電位復位到ur<θ,即:
(2)
前神經元的軸突與后神經元的樹突相互接觸之處叫做突觸,它影響著神經元之間的交換信息[6-9].當突觸前神經元發放一個脈沖時,將通過突觸在后突觸神經元的樹突上產生一個電勢變化,也叫做突觸后電位(postsynaptic potential, PSP).突觸后電位的取值可正可負,其中正的電位叫做興奮性突觸后電位(excitatory postsynaptic potential, EPSP),負的電位稱為抑制性突觸后電位(inhibitory post-synaptic potential, IPSP).
單個神經元的計算能力有限,當一群神經聚集在一起構成脈沖神經網絡時可以實現復雜的計算.一個脈沖神經網絡可以被定義為一個圖G=(V,E),其中節點V表示神經元的集合,邊E?V×V表示突觸的集合.不同脈沖神經網絡可以用不同的圖結構表示.
4.2 脈沖神經網絡的能力不低于圖靈機
本節證明利用脈沖神經網絡發放脈沖之間的相位差就可以實現圖靈機.
圖靈機的基本思想就是用機器來模擬人們用紙筆進行數學計算的過程[49],它包括一條無限長的紙帶(多條紙帶為推廣情況)、一個讀寫頭、一個狀態寄存器和一套控制程序指令.其中,紙帶上包含一個個連續的存儲格子,每個格子存儲一個數字或者符號;讀寫頭可以在紙帶上移動,并可以讀取紙帶上的內容或者寫入新的內容;狀態寄存器用于存儲機器當前所處的狀態且機器狀態數量有限;控制程序指令可以根據機器當前所處狀態以及當前讀寫頭所指格子上的數字或符號來確定讀寫頭的移動方向(左移一格或者右移一格).理論證明,圖靈機可以模擬人類所能進行的任何計算過程[50-51].
Maass[52]證明了對于任意給定的d∈N,都存在一個有限規模的脈沖神經網絡NTM(d),它可以實時模擬任意的包含d條無限長紙帶的圖靈機.主要證明包括3個步驟:
1) 構建幾種局部脈沖神經網絡,分別實現延時器、信號抑制器、振蕩器、起搏器、同步器、脈沖相位大小比較器、布爾閾值電路以及相位乘法運算(相位乘以一個固定常數).
2) 證明有限規模的脈沖神經網絡可以實現堆棧的功能,從而可以緩存數據.具體來說,堆棧中一串二值序列〈b1,b2,…,bl〉∈{0,1}*可以表示為振蕩器OS的相位差:
(3)
其中,φS表示振蕩器OS與具有相同周期的一個起搏器的相位差;參數c用于控制相位差的大小,保證相位差小于振蕩器的震蕩周期,在此基礎上證明入棧(push)和出棧(pop)指令可以由式(1)中定義的基本網絡實現.
3) 根據文獻[53],任意的包含d條無限長的紙帶的圖靈機可以類似地包含2d個堆棧的類似的圖靈機實現,其中每條紙帶讀寫頭所指處的左右2個部分分別用一個堆棧來表示,因此圖靈機的計算可以轉化為入棧和出棧的操作;再結合文獻[54],可以進一步證明任意圖靈機的計算過程可以通過有限個布爾閾值電路來模擬,而脈沖神經網絡又可以實現布爾閾值電路,因此脈沖神經網絡可以模擬圖靈機的計算過程.
Maass[52]指出脈沖神經網絡的能力優于圖靈機,主要原因有2點:1)相比于圖靈機,脈沖神經網絡的輸入輸出可以為任意的實數;2)圖靈機的基本操作只能作用于有限的位數,而脈沖神經網絡的序列存儲于相位φS中,因此基本操作可以直接改變整個序列.
4.3 噪聲可以提高脈沖神經網絡的性能
4.1節中介紹的積分發放等脈沖神經元模型都是確定性模型,事實上單個神經元的離子通道門控[55]、神經遞質的突觸釋放[56]、皮層細胞反應變異性[57]和人腦的認知活動[58]都具有隨機性.Maass[59]指出噪聲可以作為脈沖神經網絡計算和學習的資源,可以提高脈沖神經網絡的計算性能,下面分別介紹相關工作.
Gerstner等人[48]認為噪聲存在于神經元發放的閾值上,這樣神經元的膜電位取任何值時神經元都可以發放,膜電位越大時發放概率越高,這樣的模型也叫做隨機脈沖響應模型.在此基礎上Buesing等人[60]將神經元的發放過程理解為一個采樣過程,他們證明了一個包含K個相互連接神經元z1,z2,…,zK的脈沖神經網絡可以表示一個概率分布p(x1,x2,…,xK),進一步若神經元的發放概率與隨機變量x1,x2,…,xK的后驗概率滿足條件(神經適應條件):
(4)
則神經元的發放活動等價于MCMC采樣.其中,p(zi(t)=1)表示神經元zi在時刻t發放一個脈沖的概率;xi表示除了xi之外的其他隨機變量;τ表示神經元發放之后的抑制期的時長.基于此結論,Buesing等人[60]證明了脈沖神經網絡可以實現邊緣概率推理,他們證明了如果概率分布服從玻爾茲曼分布,則神經適應條件可以由脈沖神經網絡中神經元的連接自然實現.當網絡的動態性收斂時,脈沖神經元可以看作是在對平穩分布(目標分布)進行采樣,統計一段時間內神經元發放時間占總時間的比例即為邊緣概率.Pecevski等人[61]指出文獻[60]的研究只適用于二值隨機變量,提出了3種方法將以上結果推廣到一般圖模型:1)證明通過增加輔助變量可以將任意分布轉化為玻爾茲曼分布;2)利用馬爾可夫毯來擴展神經適應條件;3)利用因式分解來擴展神經適應條件.Probst等人[62]將這3種方法推廣到積分發放神經元模型,證明了基于電導的積分發放神經元可以實現MCMC采樣與邊緣推理.Habenschuss等人[63]研究了脈沖神經網絡采樣推理的收斂速度,并證明脈沖神經網絡所表示的概率分布將以指數速度收斂到平穩分布.
噪聲還可以存在于神經元的突觸上,Kappel等人[64-65]發現如果在突觸上疊加符合維納過程的隨機噪聲,突觸參數的動態性可以實現Langvein采樣.據此他們提出了突觸采樣學習框架,并證明了整個網絡參數所表示的分布將收斂于一個平穩分布,該框架不僅可以實現脈沖神經網絡的學習,而且解釋了脈沖神經網絡持續重新布線的原因.Yu等人[66]提出哈密頓突觸采樣學習框架,揭示了實現突觸可塑性的重要分子CaMKII加速脈沖神經網絡學習的計算機理.Kappel等人[67]進一步將突觸采樣框架應用到獎勵學習問題中,解釋了多巴胺、STDP和噪聲時人腦強化學習的基礎.
此外Jonke等人[68]證明了包含噪聲的脈沖神經網絡具有求解NP-hard約束滿足問題的能力.其主要思想是基于機,一方面Hopfield等人[69]和Aarts等人[70]已證明玻爾茲曼機可以求解NP-hard約束滿足問題;另一方面包含噪聲的脈沖神經網絡可以模擬任意的玻爾茲曼機,因此可以用脈沖神經網絡求解NP-hard約束滿足問題.Jonke等人[68]還發現了相比于人工神經網絡,脈沖神經網絡在求解約束滿足問題時具有更快的求解速度.
5 總結與展望
經典計算機的理論基礎是圖靈1936年奠定的,圖靈機的理論邊界那個時刻就已經明確.馮·諾依曼體系結構是圖靈機的一種物理實現模型,采用這種體系結構的經典計算機能力的理論邊界當然受限于圖靈機模型.
神經網絡是人工智能三大流派之一,從智能實現載體層次“自底向上”地開展研究,現在看來是構筑機器智能物理基礎的最主要的可行路線.大規模神經網絡的復雜結構和異步通信機制迥異于馮·諾依曼體系結構,在經典計算機上進行神經信息處理的功耗也越來越難以承受,發展面向神經網絡的體系結構,對人工智能還是一般意義上的信息處理都是必由之路.
目前廣泛應用的人工神經網絡與生物神經網絡相比,還過于簡化.模擬動物大腦和人腦的精細解析有望在20年內逐步完成,這將成為未來神經網絡體系結構的基本藍圖,基于這一藍圖研制的類腦機,將成為實現更強人工智能乃至通用人工智能的物理平臺.
類腦機的思想在計算機發明之前就提出了,研究開發實踐也已經進行了30多年,多臺類腦系統已經上線運行,其中SpiNNaker專注于類腦系統的體系結構研究,提出了一種行之有效的類腦方案.
以SpiNNaker為代表的類腦機采用傳統計算硬件和軟件實現脈沖神經網絡,因此沒超出經典圖靈機的范疇.隨著神經形態器件的發展,未來20年,有望研制出逼近乃至超越生物腦的類腦機,硬件神經元和神經突觸將具有真正的隨機性,硬件的神經環路也將像生物神經網絡一樣具備豐富的非線性動力學行為,是否能夠突破可計算性的理論邊界、超越圖靈機?這是一個尚待解決的重大理論問題,類腦機的研究開發和實現應該有助于這個問題的解決.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
