GPU無鎖跳步哈希表
2019-06-19 12:34:04孫建伶
計算機與生活 2019年6期
關鍵詞:指令
張 娟,孫建伶
1.浙江大學 計算機科學與技術學院,杭州 310027
2.阿里巴巴-浙江大學前沿技術聯合研究中心,杭州 311121
1 引言
圖形處理單元(graphics processing unit,GPU)具有卓越的并行加速能力。將通用內存索引結構應用到GPU之上成為了一個新的研究方向。目前針對GPU優化的內存索引結構還較少,只有很少的完全并發且可動態更新的結構能夠適應GPU。
完全并發的GPU數據結構的應用場景更加廣泛,無鎖特性又可以解決傳統基于鎖的方法由于大量駐留線程對資源的爭用而造成的低效率。本文設計并實現GPU完全并發且可動態更新的無鎖跳步哈希表——GPU無鎖跳步哈希表(GPU lock-free hopscotch Hash table,GLHT)。
目前尚未有GPU完全并發且可動態更新的跳步哈希表,但是有少許GPU其他哈希表設計。GPU其他哈希表設計主要分為兩個方向:靜態哈希表、完全并發且可動態更新的哈希表。據本文所知,雖然已有多種有效的GPU靜態哈希表(例如Alcantara等人設計的杜鵑哈希表[1]),但完全并發且可動態更新的GPU哈希表目前只有Misra和Chaudhuri實現的無鎖鏈式哈希表[2]和Ashkiani等人設計的Slab Hash[3],并且文獻[2]中的哈希表還不是完全動態的。
GLHT的基礎數據結構是跳步哈希表[4]。跳步哈希表的插入操作保持數據的緊湊。當發生數據沖突時,新數據插入到哈希槽(哈希槽即指鍵原始應該被哈希到的槽)隨后的H個槽,這H個槽稱為當前槽的鄰域,H是用戶設置的常數。每個槽關聯一個由H+1個bit組成的bitmap,指示當前槽和后續H個槽中的項是否是最初哈希到當前槽的項。若某個槽的項本來應該哈希到前面的槽,則稱這個槽“從屬”于前面的那個槽。圖1是鍵v插入跳步哈希表的過程,白色表示空槽,灰色表示槽中有項,該哈希表的H為3。鍵v本應哈希到槽6,但是發生了數據沖突。于是,首先通過線性探測找到距槽6最近的空槽13。如果兩個槽的距離小于等于H,則可以將鍵直接插入到該空槽中,但是槽13到槽6超過了H的范圍,因此需要按照鄰域從屬關系,置換它們之間的鍵,將空槽移近槽6。觀察槽10(13-H=10)的bitmap,發現只有槽11從屬于槽10,于是置換槽11的鍵w到槽13并更新槽10的bitmap。現在空槽為槽11,但它仍然不在槽6的鄰域內,于是觀察槽8(11-H=8)的bitmap,發現槽9從屬于槽8,于是置換鍵z到槽11并更新槽8的bitmap。現在,槽9在槽6的鄰域范圍內了,可以直接將鍵v安排在槽9。通過這一系列的移位操作,跳步哈希表保證了數據與原始哈希槽的距離不會大于H,因此查找時只需檢查哈希槽及其鄰域中是否有目標鍵,若無則可確定目標鍵不存在,由此保證任何情況下的查找時間都是O(1)。
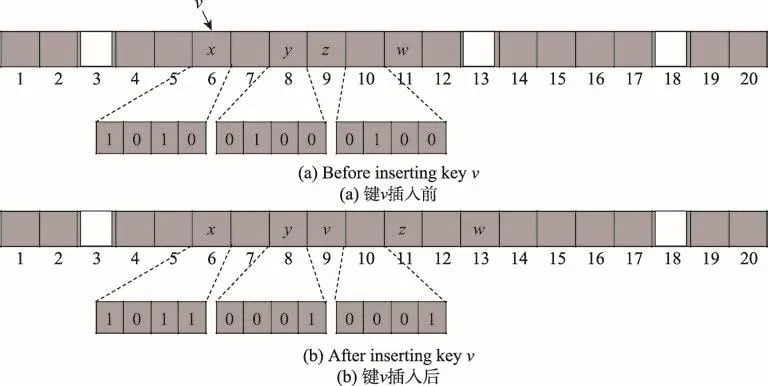
Fig.1 Insert key vinto hopscotch Hash table圖1 鍵v插入跳步哈希表
在GPU中,若一個warp內的線程請求訪問連續對齊的內存塊,則會進行合并訪問(coalesced access)以便最大化內存帶寬。跳步哈希表的所有操作恰好都只需要并行讀取連續內存范圍內的哈希槽和鄰域,因此可以使用高效的GPU合并訪問完成讀取請求。而其他哈希表,例如杜鵑哈希表[5],在插入過程中反而追求項的隨機分布,自然不利于合并訪問的使用。
設計實現GPU哈希表并不是直接將原有的CPU哈希表簡單地放置到GPU上,不僅需要考慮GPU環境下的并發安全問題,還要結合GPU的硬件特性,實現哈希表在GPU上的并行性能最大化。GLHT的設計主要圍繞兩方面:
(1)warp內并行:采用warp協同工作共享策略(warp-cooperative work sharing strategy),減少程序控制流中的分支與發散,以實現對哈希表單個操作的并行加速。
(2)warp間完全并發:全局內存配合CUDA(compute unified device architecture)原子操作atomic-CAS以及特殊的并發控制策略設計,在實現完全并發和無鎖特性的同時,保證了讀操作的無等待特性,以實現哈希表多個操作的并發執行。
本文進行了實驗評估,結果表明GLHT具有在靈活性和性能上的優勢。GLHT與其他GPU靜態哈希表相比,具有可以接受的構建和檢索速度;與現有的CPU跳步哈希表相比,具有4~9倍的性能優勢;比采取預先分配內存的GPU無鎖鏈式哈希表[2]更加靈活,并且在寫操作較多的工作負載中獲得了更好的性能。
本文工作安排如下:第2章介紹GPU數據結構相關工作;第3章描述GLHT的總體設計;第4章介紹GLHT的實現細節;第5章為實驗評估;第6章對全文進行總結。
2 相關工作
目前有多種GPU靜態哈希表。Alcantara等人的杜鵑哈希表[1]在批量構建階段和檢索階段都有很好的性能,但隨著負載因子要求的增加,批量構建過程越來越有可能失敗。該哈希表已用于CUDA數據并行原語庫(CUDA data parallel primitives library,CUDPP)[6]。García等人[7]提出了一種基于Robin hood的哈希方法,他們專注于更高的負載因子并利用了圖形應用程序的空間局部性,但代價是該哈希方法與杜鵑哈希相比性能有所下降。Khorasani等人[8]提出了Stadium Hashing(Stash)技術,它也是一種杜鵑哈希表設計,可以擴展為大型哈希表。它解決的重點問題是out-of-core哈希表不能完整地放進單個GPU內存中。通過將表容器存儲在CPU內存中,Stash消除了將哈希表整個維護在有限的GPU內存上的限制。Stash使用了名為ticket-board的緊湊數據結構,這個數據結構引導了哈希表上的所有操作。在最好的情況下(即空表),Stash的插入操作只需要一個原子操作和一個常規的內存寫操作,查找操作則至少需要兩個內存讀取操作。雖然各種靜態哈希表的側重有所不同,但文獻[1]似乎是這些設計中具有最佳性能指標的通用in-core哈希表。
在GPU完全并發且可動態更新的哈希表研究方面,Misra和Chaudhuri[2]測試了幾種已知的CPU無鎖數據結構移植到GPU后的加速情況。他們實現了一個GPU上的無鎖鏈表,并由此實現了無鎖鏈式哈希表,這個哈希表能夠支持并發的插入、刪除和查找操作。但該實現實際上仍然不是完全動態的,因為在它的實驗中,為將來所有的插入操作都預先分配了一個結點資源數組(必須在編譯時知道),并且不能在運行時動態分配新項和釋放已刪除項,這就是所謂的“預先分配內存”,而本文實現的GLHT則完全不需要這樣的過程,因此更具靈活性。Cederman等人[9]對各種已知的基于鎖和無鎖的Queue實現進行了類似文獻[2]的實驗,他們得出的結論是:Queue面向GPU的并行優化將有利于性能的提升。現在,人們也開發出了一些更簡單的、專為GPU設計的數據結構,例如隊列[10]和鏈表[11]。此外,graph-based算法也使用優化的GPU實現了速度的加快[12-14]。受文獻[2]的啟發,Moscovici等人[15]提出了基于細粒度鎖的GPU友好的跳表(GPU-friendly skip list,GFSL),該工作主要考慮的是GPU的優選合并內存訪問(preferred coalesced memory accesses)。
最近,Ashkiani等人[3]設計了一種完全并發的GPU動態無鎖鏈式哈希表——Slab Hash。他們認為,GFSL無論在插入、刪除還是查找操作中,都無法擊敗Slab Hash的性能峰值。
3 設計
GLHT通過warp內并行實現對單個操作的并行加速,通過warp間并發實現多個操作的并發執行。
3.1 warp內并行:warp協同工作共享策略
GPU運行時,各個線程塊被分配給不同的流式多處理器(streaming multiprocessors,SM)執行。SM會以32個線程為一組執行線程塊操作,這稱為warp調度。一個warp中的線程從相同的程序計數器開始執行,但是也可以獨立地進行分支與發散(branch and diverge)。如果一個warp內的線程由于判斷條件的不同而進行了分支,則warp將依次執行每個線程所采用的分支路徑。當所有的分支路徑被執行完時,warp中的線程才會重新聚到共同路徑中。
在GPU上執行一組獨立操作的傳統方法是讓每個線程都獨立處理一個操作,例如,GPU上經典的鏈表操作[2]。圖2描繪了傳統方法的執行過程,圖中空白的時間塊表明當線程在處理分支時,其他線程將處于等待狀態。頻繁的控制流發散將會嚴重影響執行性能,由此可知,這種傳統方法并沒有充分發揮出GPU線程的并行能力。
Slab Hash[3]和 warp-wide直方圖計算[16],讓 warp內的線程協同地并行工作,可以指定warp內線程,使用一些warp-wide指令,協同處理同一個操作,也就是將原本分配給不同線程的操作統一分配給整個warp來處理,如圖3這種方法就稱為warp協同工作共享策略。warp-wide指令指的是NVIDIA GPU支持的一組內建函數,可以協同warp內線程的通信過程以減少分支與發散。與傳統的單線程獨立處理相比,warp協同工作共享策略顯著減少GPU程序中的分支與發散。
3.2 warp間完全并發:全局內存配合CUDA原子操作
如圖4,雖然GLHT讓warp大小的整個線程塊內的線程協同地處理同一個操作任務,但不同線程塊之間仍然是操作獨立且完全并發。
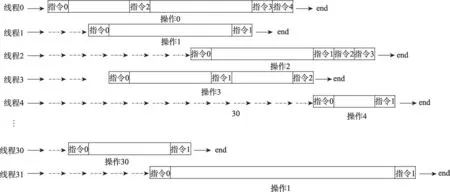
Fig.2 Traditional method圖2 傳統方法
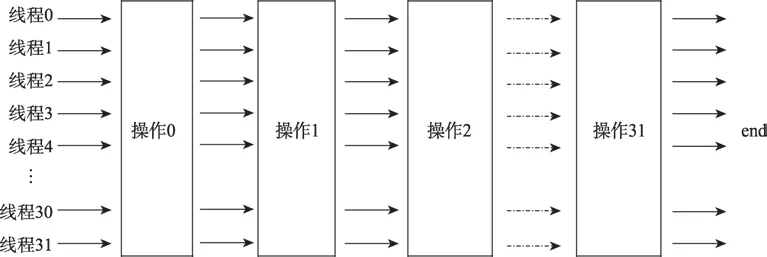
Fig.3 warp-cooperative work sharing strategy圖3 warp協同工作共享策略
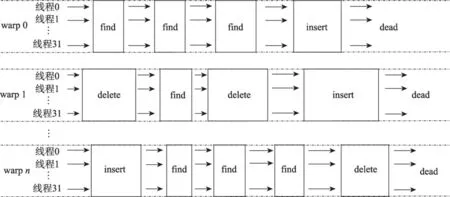
Fig.4 Fully concurrent operations between warp圖4 warp間完全并發的操作
如何做到warp間完全并發,首先需要考慮操作執行在GPU內存的哪個層次。GPU的內存結構分為三個層次:可以被設備內所有線程訪問的大的全局內存;每個線程塊有著的更小但更快的共享內存;線程塊中每個線程的本地寄存器。共享內存很小(通常為16 KB),并且它進行了分區,因此來自不同塊的線程無法訪問另一個塊的共享內存。GPU的全局內存容量大,可供所有線程訪問。由于數以百萬計的線程可以執行GPU內核函數,但只有有限數量的SM存在,因此線程塊需要排隊等待SM。因此,除了內核函數結束的時候,并沒有辦法可以全局地同步所有線程。為了實現warp間操作的完全并發,GLHT通過全局內存實現各線程對所有數據狀態的共享。
GLHT選擇無鎖樂觀并發控制。這種控制方法會在訪問內存資源時“樂觀地”假設沒有并發沖突,對數據不加鎖就直接拿來用,在最后真正更新數據時再判斷沖突是否發生。選擇這種并發控制方法的好處:一是在GPU編程環境中,鎖的設計代價非常昂貴;二是它可以減少成千上萬的駐留線程對鎖資源的爭用,從而提高執行效率。而這種并發控制方法的缺點是,當數據沖突發生時,解決沖突的代價較大,除非沖突發生的幾率很小。
常見的無鎖編程一般基于原子操作。常用的原子操作是比較和設置(compare-and-set,CAS)操作。CAS操作將內存數據與給定值進行比較,只有當它們相同時,才會將該內存數據修改為新值。GLHT就用到了CUDA的CAS原子操作atomicCAS。
4 實現
GLHT的實際數據結構是一個在GPU內存中的unsigned long long int數組,而對GLHT查找操作、刪除操作和插入操作的具體實現細節感興趣的讀者可自行閱讀代碼及注釋(https://github.com/fanny2011/GLHT),本章僅作簡要介紹。
4.1 拆分操作階段
首先將插入操作拆分為不同的階段并區分不同階段的槽角色。拆分階段是為了細分并發操作的粒度,而區分槽角色只是為了描述的方便。
插入操作可以拆分成find、find_empty、update和find_closer_empty四個階段,其中find_closer_empty階段又可以循環多個swap_value_into_empty階段,如圖5。而GLHT的刪除操作則只用分為find和update兩個階段。
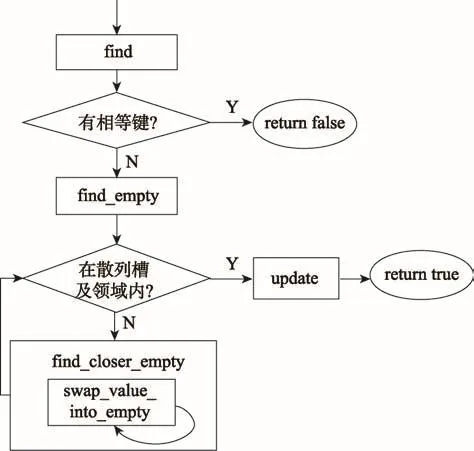
Fig.5 Phase decomposition of insert operation圖5 插入操作的階段分解
下面描述插入操作不同階段的槽角色,先將哈希槽以角色hash_pos表示。find階段找出哈希表中是否已有相等的鍵,沒有則執行find_empty階段。插入操作和刪除操作的find階段與查找操作做的是相同的事情。
find_empty階段返回正好為空的hash_pos或后方最靠近hash_pos的空槽,若空槽為hash_pos或在hash_pos鄰域內,則將此空槽以角色target表示,并執行update階段,否則執行find_closer_empty階段。
插入操作的update階段將目標鍵通過atomic-CAS放進hash_pos,而刪除操作的update階段將target通過atomicCAS置為空,update階段的槽角色如圖6,注意target可能與hash_pos重合。

Fig.6 Slot role in update phase圖6 update階段的槽角色
find_closer_empty階段的目標是將找到的空槽向前移動一次,find_closer_empty階段循環多個swap_value_into_empty階段,直到移動成功。swap_value_into_empty階段每次對一塊置換區域操作,置換區域的第一個槽以角色swap_head表示,置換區域的最后一個槽即前面找到的那個空槽。從前到后在置換區域中尋找一個“從屬”于swap_head的槽,將這個槽以角色swap表示,并置換target和swap的項,置換完成則find_closer_empty階段也完成了;但若沒有找到swap,則find_closer_empty階段將角色swap_head向后推動一個位置,并循環swap_value_into_empty階段。find_closer_empty階段最初將swap_head定在target前的第H個位置。swap_value_into_empty階段的槽角色如圖7所示,注意swap_head與swap可能重合。

Fig.7 Slot role in swap_value_into_empty phase圖7 swap_value_into_empty階段的槽角色
4.2 鎖標記
GLHT采用樂觀并發控制,在數據項上設置鎖標記,操作時使用原子操作來更改這些鎖標記,以達到使用原子操作鎖定數據項的目的。對應于上一節所述的四個角色(hash_pos、target、swap_head和swap),GLHT設計了兩種鎖標記:multiple_lock和swap_lock。規定鎖標記間的互斥關系及它們對并發讀寫操作的互斥性質,就能保證warp間操作的完全并發安全性。
multiple_lock的含義如下:
(1)當其標記在非空槽時,表示該槽正處于插入或刪除操作的update階段的hash_pos角色。
(2)當其標記在空槽時,有兩種可能:①該槽正處于swap_value_into_empty階段的target角色;②該槽正處于插入操作的update階段的target角色。
swap_lock的含義如下:
表示該槽正處于swap_head角色,或表示該槽正處于swap角色。
兩種鎖標記均為排他鎖標記,即當槽帶上上述標記后,不能再帶上另外的鎖標記,也不能重復帶上相同的標記。
GLHT查找操作不涉及對鎖標記的操作,只讀取鎖標記的狀態,根據hash_pos中的項是否帶有multiple_lock鎖標記(項帶有的swap_lock可以忽略),決定重讀或繼續下一個步驟。
刪除操作在update階段,若發現hash_pos帶有任何鎖標記,就需要從頭重試整個操作;否則,為hash_pos帶上multiple_lock,以表明本操作對該hash_pos及其領域擁有了操作權,其他操作發現鎖標記的狀態改變后只能重試。然后,刪除操作將target改變為空槽。最后,操作收尾,取消hash_pos上的multiple_lock。期間,任何一個原子操作失敗后,都需要清理鎖標記并從頭重試整個操作。
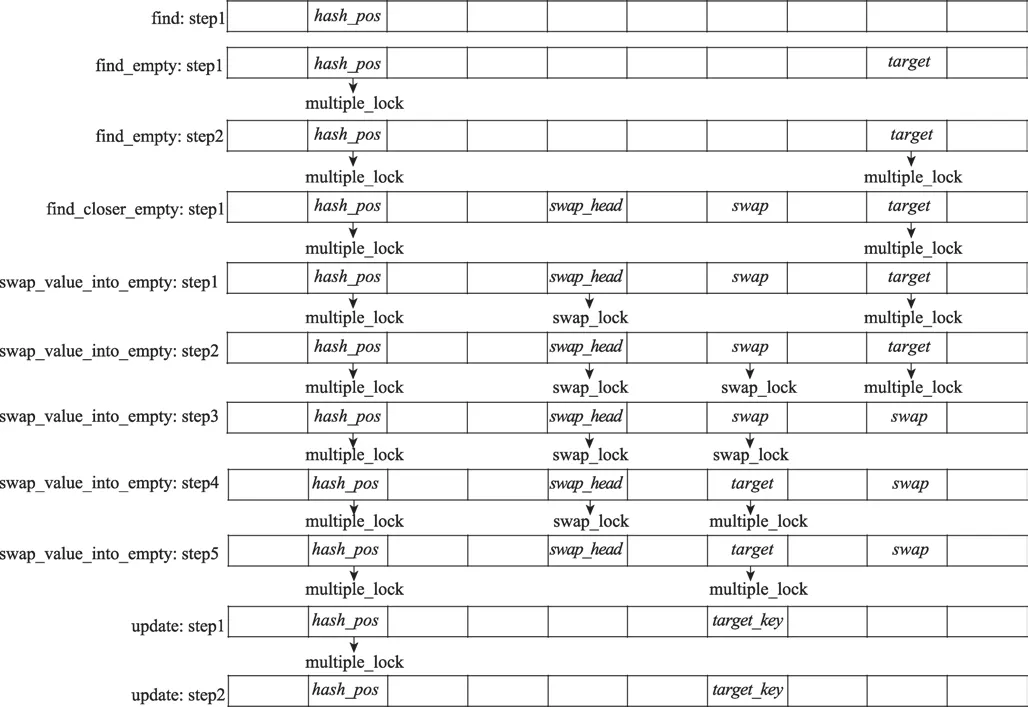
Fig.8 Operations on lockflag during insert operation圖8 插入操作過程中對鎖標記的操作
插入操作過程中對鎖標記執行的操作與刪除操作類似,但更為復雜,如圖8。首先,在find_empty階段開始前,需要在hash_pos上帶上multiple_lock。發現target后,也要為它帶上multiple_lock,這是因為后續可能伴隨著find_closer_empty階段,這個階段持續時間較長,所以需要提前搶占這個槽,保持它只能被本操作讀寫。在swap_value_into_empty階段,首先,為swap_head帶上swap_lock;然后,為swap帶上swap_lock;接著,在target中填入swap的項,同時取消target的multiple_lock;將swap變為空槽,同時取消swap_lock并帶上multiple_lock,在下一階段,這個槽就成為了新的target;最后,取消swap_head的swap_lock。在插入操作期間,任何一個原子操作失敗后,都需要按帶上時的倒序清理鎖標記并從特定階段的開頭重試操作。
之所以設計了兩種互斥鎖,原因在于multiple_lock與swap_lock在讀-寫互斥關系的表達上是不同的:multiple_lock用作寫-寫互斥和讀-寫互斥,即當發現槽帶有multiple_lock時,這對該槽及其“從屬”槽的操作,無論讀操作還是寫操作,都需要不斷重試直到multiple_lock消失。swap_lock只用作寫-寫互斥,即對帶有這個標記的槽,任何針對該槽及其“從屬”槽的寫操作都需要重試,但讀操作可以忽略它。
4.3 warp內并行:warp-wide指令的使用
應用warp協同工作共享策略的GLHT使用了warp-wide指令shuffle、ballot和ffs。shuffle指令允許線程直接讀取同一個warp內的其他線程的寄存器值,這種通信方式比通過訪問共享內存進行線程間通信的效果更好、延遲更低,同時也不用消耗額外的內存資源來執行數據交換。ballot指令的作用是在warp內線程間進行投票,也常用于讓線程根據同名變量了解其他線程所處的狀態。每個線程將同名變量作為輸入,ballot指令將判斷這些變量是否等于零,比較結果將統一廣播給每一個線程,若比較結果的第N位被置為1,則表示該warp內的第N個線程處于活動狀態且它的變量非零。ffs指令返回輸入的最低有效位(即最低為1的bit)的下標,下標從1開始,減去1即得到真正的最低有效位下標,這個指令通常會搭配ballot指令。
warp-wide指令以32個線程為一組執行操作,因此,GLHT設置線程塊大小為32,運用warp協同工作共享策略對槽數組進行操作。相應的,設置常數H=31,使得GLHT可以以線程塊為單位對整個鄰域進行操作。
4.3.1 查找操作
1.__device__void Find(LLkey,LL*result,Slot*position){
2.hash=Hash(key);
3.do{
4.*position=table[hash+threadIdx.x];
5.*hash_pos=__shfl(*position,0);
6.}while((*hash_pos& MULTIPLE_LOCK_MASK)!=0);
7.bitmap=getBitmap(*hash_pos);
8.if(isValid(*position,bitmap)
9.&&(((*position)&EMP_FLAG_MASK)==0)
10.&&isEqual(*position,key)
11.&&(getHash(*position)==hash)){
12.predict=1;
13.}
14.ans=__ffs(__ballot(predict));
15.if(ans==0){
16.*result=WRONG_POS;
17.}else{
18.*result=hash+(ans-1);
19.}
20.}
以上是查找操作Find的偽代碼,其中MULTIPLE_LOCK_MASK用來判斷槽是否帶有multiple_lock鎖標記,EMP_FLAG_MASK用來判斷是否為空槽。
warp內的每個線程根據其帶有的threadIdx確定其應該讀取的槽,threadIdx指示線程在warp內的下標,線程應該讀取的槽position與下標為hash的槽hash_pos的偏移正好與threadIdx.x相對應(line 4)。雖然讀取的槽不同,但每個線程都需要對hash_pos中數據進行條件判斷,因此此時會使用shuffle指令將第一個線程讀取到的hash_pos中數據分發給其他線程(line 5)。
GLHT執行查找操作時,會反復讀取hash_pos和領近槽的數據,并檢查hash_pos中的項是否帶有multiple_lock鎖標記(line 3~6)。
在檢查是否有等于查找鍵的槽數據時,首先根據判斷條件設置同名變量predict(line 8~13),然后用ballot和ffs指令并行地對所有warp內線程持有的數據進行同步判斷(line 14)。
4.3.2 插入操作
插入操作使用了shuffle指令,主要用在兩方面:(1)在所有warp內線程間同步hash_pos數據;(2)在某一個線程執行atomicCAS操作后,將表達操作最終成功與否的變量廣播給其他線程以同步地推進所有warp內線程的控制流判斷。
除了shuffle指令,插入操作還會在以下情況使用ballot和ffs指令組合:(1)在find_empty階段,找到最靠近hash_pos的不帶multiple_lock鎖標記的空槽;(2)在swap_value_into_empty階段,找到不帶任何鎖標記的swap槽。插入操作的ballot和ffs指令組合的具體使用方式與查找操作的方式(見偽代碼line 8~14)相似。
4.3.3 刪除操作
GLHT的刪除操作只使用到了與插入操作一樣的shuffle指令使用方式。
4.4 warp間完全并發:特殊的并發控制策略
之前的相關工作也使用了全局內存配合CUDA原子操作,但全局內存訪問速度要比共享內存慢幾個數量級。為了提升性能,GLHT在此基礎上設計了特殊的并發控制策略(包括4.2節描述的鎖標記和暫時重復策略兩方面),保證了讀操作的無等待特性,在一定程度上彌補了全局內存訪問慢的缺點。
在GLHT插入操作的swap_value_into_empty階段,需要置換target和swap的項。但是這個置換過程并非原子過程,且GLHT沒有結構鎖,其他warp的讀操作很容易發生在置換過程的各個操作之間,很可能出現其他warp在讀取swap_head及其“從屬”槽時,讀取不到swap中有效鍵的情況。為此,GLHT設計了“暫時重復策略”,即先將swap中的項復制到target中,再將swap置為空。雖然造成了短暫的項重復,但保證了數據的正確性(即warp不會出現讀取不到正確存儲在表中的有效值)和讀取操作不需要等待的設計要求。
GLHT的查找操作不涉及任何原子操作,因此可以保證在有限的步驟內完成,因此是無等待的,實際上所有的讀操作都是無等待的。除了hash_pos的multiple_lock,任何其他的寫操作標記都不會影響查找操作的進程,從而消除了讀操作與寫操作對于資源的互斥等待。這也正是GLHT將swap_lock和multiple_lock分開設計的原因,就是為了提高讀操作效率。無論是鍵-值對映射還是鍵集合操作,從統計經驗上來說,應用程序的讀操作數量相對寫操作會多一些,因此,提高讀操作效率對提高整體操作效率是非常有意義的。
需要強調的是,GLHT的設計方案只能保證GPU上數據結構的無鎖并發安全性,CPU上無法實現相同的安全效果。這是因為warp內的并行模式保證了多個位置的內存讀操作是真正并行的,相當于在同一時間給多個位置的內存狀態做了一個快照,后續所有對這些內存的聯合判斷都相當于是在同一時間內完成的,從而保證了操作的并發安全,而CPU無法做到這一點。
5 實驗評估
本實驗全部在Intel Xeon E5-2620服務器上執行,該服務器擁有1個Socket,每個Socket有6個核,每個核有2個超線程。內存為2×16 GB DDR3 SDRAM。高速緩存為32 KB L1數據緩存,32 KB L1指令緩存,256 KB L2緩存,15 360 KB L3緩存。操作系統為64位的Ubuntu 16.04.3。CPU代碼采用打開O3優化的gcc-5.4.0編譯器編譯。GPU部分是在NVDIA GeForce GTX 1080上進行評估比較的,GDDR5X容量為8 GB。CUDA代碼采用CUDA 8.0編譯器(V8.0.61)編譯。
實驗評估分為兩方面:首先是靜態基準,以兩個操作階段(批量構建和檢索)分步執行的方式與其他GPU靜態哈希表(線性探測、平方探測和CUDPP的杜鵑哈希實現[6])進行比較;其次是動態并發基準,以并發執行隨機混合操作(插入、刪除和查找操作按比例混合)的方式與CPU跳步哈希表和Misra和Chaud-huri實現的完全并發且可動態更新的GPU無鎖鏈式哈希表[2]進行比較。
5.1 靜態基準
GPU靜態哈希表有兩個操作階段:(1)批量構建階段,給定一個固定的負載因子(可以簡單地按照預先設計的內存使用率來表示)和一個鍵-值對輸入數組,以批量的插入操作構建整個數據結構,若構建階段發生插入失敗則需要從頭重建。(2)檢索階段,在批量構建階段結束后,以鍵數組作為輸入,在數據結構中執行批量的查找操作,并將返回找到的對應的值存儲在輸出數組中。
本實驗基準以吞吐量(操作總數量/執行時間)作為衡量數據結構性能的指標。所有數據結構選取的槽數組都是大小一致的,并固定內存使用率為0.8。各數據結構的哈希函數也保持一致。操作總數作為橫坐標。GPU數據結構的線程數量就等于操作總數量。在確定GPU數據結構的線程數量后,需要決定每個線程塊的線程數量(線程塊數量=線程總數/每個線程塊的線程數量)。
圖9是各數據結構的構建速度比較。GLHT雖然比線性探測和平方探測靜態哈希表慢,但作為動態哈希表,它的速度基本上還是可以接受的。
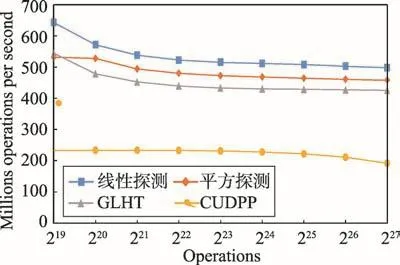
Fig.9 Comparison on build speed圖9 構建速度比較
預設所有檢索鍵都已存在于數據結構。圖10是各數據結構的檢索速度比較。與其他靜態哈希表相比,GLHT的速度仍然較為合理。
5.2 動態并發基準
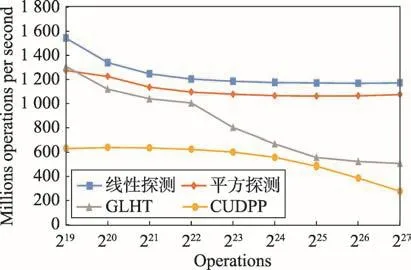
Fig.10 Comparison on retrieve speed圖10 檢索速度比較
文獻[4]已提出了CPU跳步哈希表的并發版本,后續實驗中以CPU lock-based hopscotch表示。此外,為了與之前他人提出的GPU哈希表進行比較,本實驗基準選擇了Misra和Chaudhuri提供的GPU上的無鎖鏈式哈希表[2]作為參照。注意到文獻[2]的槽數組實際是鏈表結點的指針數組,操作過程中需要動態地為鏈表結點進行內存分配。文獻[2]稱,為了確保性能評估可以集中在數據結構本身可實現的原始吞吐量上而不受內存分配開銷的任何干擾,在GPU內核函數啟動之前從CPU預先分配了足夠數量的鏈表結點到GPU內存中,以便并發操作過程中不從GPU調用動態內存分配。本文把這個過程稱為“預先分配內存”。這么做的原因是,在操作過程中從GPU調用動態內存分配是非常耗時的事情。但GLHT不需要這樣的預分配過程和相關的耗時操作,因此更具有靈活性。若以文獻[2]不計算“預先分配內存”的執行時間與GLHT直接相比,GLHT的優勢將不能體現,因此為了公平,本實驗將同時考慮文獻[2]的不計算“預先分配內存”的情況(以GPU chained without allocation表示)和計算“預先分配內存”的情況(以GPU chained with allocation表示)下的吞吐量。
本實驗基準以吞吐量(操作總數量/執行時間)作為衡量數據結構性能的指標。數據結構的性能可能取決于不同操作的混合比例、鍵的取值范圍以及操作總數量。為評估不同的操作組合,將不同混合比例表示為三元組[x,y,z],表示具有x%的插入操作、y%的刪除操作和z%的查找操作。本實驗選取了兩個操作組合,[20,20,60]和[40,40,20]。為評估鍵的取值范圍,在每個操作組合上設計4個不同的整數鍵范圍,[0,100],[0,1 000],[0,10 000]和[0,100 000]。操作總數固定為100 000。每個測試的操作序列都是根據混合比例和總數量預先生成的,操作鍵從被評估的鍵范圍中隨機生成。每個測試都需要在GPU上或CPU上評估3次,并且以中值作為其真實執行時間。所有數據結構選取的槽數組大小都是固定一致的,哈希函數也保持一致。線程數量對于CPU數據結構的執行性能來說,并不是越多越好。在本實驗環境下,為CPU數據結構選擇了達到最佳性能的線程數16。而GPU數據結構的線程數量是根據每次測試的操作總數量決定的,文獻[2]稱每個線程執行一個操作時效果是最好的,于是GPU數據結構的線程數量就等于操作總數量。文獻[2]選擇每個線程塊512個線程,而GLHT根據設計方案選擇每個線程塊32個線程。
操作組合[20,20,60]偏向讀操作。從圖11可以看出,雖然GPU chained without allocation具有明顯的性能優勢,但是計算上預先分配內存時間后的GPU chained with allocation恰是執行時間最長的,實際上GLHT對GPU chained with allocation有200倍左右的性能提升。并且,隨著鍵范圍的增大,GPU chained without allocation對GLHT的性能優勢也沒有那么明顯了,從2、3倍的優勢降低到了1倍多。而GLHT對CPU lock-based hopscotch大概有4、5倍的性能優勢。
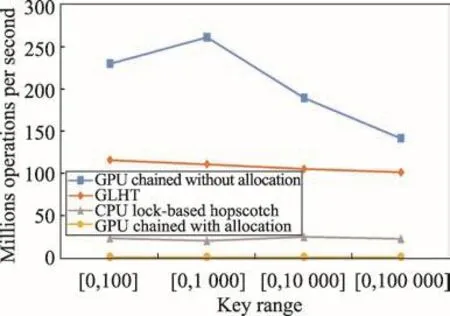
Fig.11 Comparison on throughput of combination[20,20,60]圖11 組合[20,20,60]的吞吐量對比
操作組合[40,40,20]偏向寫操作。依舊是GPU chained without allocation比較具優勢,而GPU chained with allocation最差。但是從圖12可以看到,與操作組合[20,20,60]相比,GLHT的優勢越來越明顯,GPU chained without allocation對GLHT僅有1倍多的性能優勢,甚至在鍵范圍較大的情況下,存在GLHT性能超越GPU chained without allocation的現象;GLHT對GPU chained with allocation有200~400倍的性能比;另一方面,GLHT依舊具有對基于鎖的CPU跳步哈希表的優勢,且優勢擴大到了5~9倍。
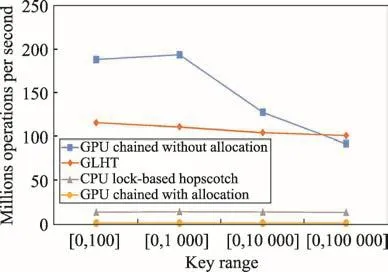
Fig.12 Comparison on throughput of combination[40,40,20]圖12 組合[40,40,20]的吞吐量對比
從以上實驗數據可以明顯看出,無論是讀操作比重較大的情況還是寫操作比重較大的情況,本章實現的GLHT對CPU上的跳步哈希表具有絕對的性能優勢(4~9倍)。
至于文獻[2]提供的GPU上的無鎖鏈式哈希表,雖然它也支持并發的插入、刪除和查找操作,但其實仍然不是完全動態的數據結構。GPU內核函數通常無法直接訪問CPU內存,因此在處理CPU內存之前必須將數據復制到GPU上,然后再寫回CPU。但是,將數據復制到GPU或從GPU復制數據需要付出非常昂貴的時間代價,文獻[2]正是采用了這種昂貴的方式為實驗中的所有插入操作都預先分配了結點資源(必須在編譯時知道具體分配計劃),并且不能在運行時動態分配新項和釋放已刪除項。這是GPU上鏈式哈希表的一個最大的限制。而GLHT就沒有這樣的限制,因此更具靈活性。
鏈式哈希表必須為每個插入結點分配相應的內存,但幸運的是開放尋址的哈希表可以避免大量的內存分配,GLHT中作為結構基礎的跳步哈希表正是開放尋找哈希表的一個典型。雖然表面上看GLHT比GPU chained without allocation性能差,但在真實生產環境中更關心的是程序的總體運行時間,也就是GPU chained with allocation的運行性能,因此可以毫不猶豫地說,GLHT更具有競爭優勢,畢竟它相對GPU chained with allocation有200~400倍的性能比。退一步說,即使不考慮GPU chained with allocation,GLHT也已經在寫操作比重較大的工作負載中超越了GPU chained without allocation。
6 結束語
跳步哈希表可以使用高效的GPU合并訪問完成讀取請求,相對其他哈希表,更適合用于GPU設計,本文提出并實現了一種GPU跳步哈希表GLHT,它是首個GPU完全并發且可動態更新的跳步哈希表。GLHT與之前的工作相比,具有以下兩個特點:(1)warp內單個操作并行,采用warp協同工作共享策略,減少程序控制流中的分支與發散;(2)warp間多個操作并發,使用全局內存配合CUDA原子操作以及特殊的并發控制策略設計,在實現完全并發和無鎖特性的同時保證了讀操作的無等待特性。GLHT與其他GPU靜態哈希表相比,具有可以接受的構建和檢索速度;與現有的CPU跳步哈希相比,具有4~9倍的性能優勢;比采取預先分配內存的GPU無鎖鏈式哈希表[1]更加靈活,并且在寫操作較多的工作負載中獲得了更好的性能。
本文實現的GLHT中,為了模型設計和說明的簡便,直接以unsigned long long int作為數據結構的項,未來可以將鍵值存儲部分改為指向鍵-值對的指針以提高使用性。另外,由于目前GPU原子操作的限制(例如atomicCAS操作只涉及整數數據類型),GLHT的設計模型仍顯粗糙,未來可以等GPU原子操作可以涉及結構對象時,繼續豐富本模型。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
時代農機(2015年3期)2015-11-14 01:14:29
科技傳播(2015年20期)2015-03-25 08:20:30
信息安全研究(2015年3期)2015-02-28 20:18:12
西安航空學院學報(2014年5期)2014-07-13 01:27:52
家電科技(2014年5期)2014-04-16 03:11:28
汽車零部件(2014年2期)2014-03-11 17:46:27
