采用CNN和Bidirectional GRU的時間序列分類研究*
2019-06-19 12:34:00張國豪
計算機(jī)與生活 2019年6期
張國豪,劉 波
暨南大學(xué) 信息科學(xué)技術(shù)學(xué)院,廣州 510632
1 引言
時間序列數(shù)據(jù)分類在許多領(lǐng)域都有應(yīng)用,包括醫(yī)學(xué)、生物學(xué)、金融學(xué)、工程學(xué)以及工業(yè)界等領(lǐng)域[1]。由于時間序列數(shù)據(jù)具有非離散性,數(shù)據(jù)之間有著前后的時序相關(guān)性,特征空間維度非常大等特點,使得傳統(tǒng)的數(shù)據(jù)挖掘、機(jī)器學(xué)習(xí)算法不能直接對其進(jìn)行分類。因此,研究人員提出了多種方法:基于距離的方法、基于特征的方法、基于集成(ensemble)學(xué)習(xí)的方法等。但這些方法都需要對數(shù)據(jù)進(jìn)行復(fù)雜的預(yù)處理,或者進(jìn)行復(fù)雜且繁重的特征工程。近年來,由于神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)的發(fā)展,基于神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)的時間序列分類方法被陸續(xù)提出,例如多通道卷積神經(jīng)網(wǎng)絡(luò)模型[2]、全卷積神經(jīng)網(wǎng)絡(luò)模型[3]、多層感知器[3]等,但是這些方法也未能考慮到時間序列數(shù)據(jù)的多種特征。
本文通過對卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)以及循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)的研究,充分發(fā)揮卷積神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)的作用,提出了一種BiGRU-FCN模型,使用雙向的門控循環(huán)單元(bidirectional gated recurrent unit,BiGRU)和卷積神經(jīng)網(wǎng)絡(luò)相結(jié)合的結(jié)構(gòu)。本文主要工作及貢獻(xiàn)如下:
(1)探索了卷積神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)在時間序列數(shù)據(jù)上的作用。卷積神經(jīng)網(wǎng)絡(luò)通過卷積核在時序數(shù)據(jù)上進(jìn)行卷積操作,獲得了不同時間窗的信息與特征。BiGRU通過循環(huán)神經(jīng)元以及門控機(jī)制,對時間序列數(shù)據(jù)處理,獲得了時間序列數(shù)據(jù)的時序依賴特征,雙向結(jié)構(gòu)可以獲得來自整個輸入序列正向與反向的特征,很好地提高了模型的分類效果。
(2)將卷積神經(jīng)網(wǎng)絡(luò)和雙向門控循環(huán)單元通過Merge層連接,構(gòu)建一個完整的端對端模型。
(3)對比了多種模型在UCR時間序列數(shù)據(jù)集上的效果,驗證了本文模型的先進(jìn)性。
本文實驗數(shù)據(jù)采用時間序列分類研究的權(quán)威數(shù)據(jù)集——UCR數(shù)據(jù)倉庫[4],并與多種方法進(jìn)行了實驗對比。結(jié)果表明,本文方法有效地提高了深度學(xué)習(xí)模型在時間序列分類的表現(xiàn),不用對數(shù)據(jù)進(jìn)行復(fù)雜的預(yù)處理,也不用對模型進(jìn)行過多的調(diào)參,比其他方法有著更高的準(zhǔn)確率。
2 背景及相關(guān)工作
在時間序列分類研究中,主要采用基于距離的方法、基于特征的方法、基于集成學(xué)習(xí)的方法、基于深度學(xué)習(xí)的方法等。
在基于距離度量的方法中,首先定義距離函數(shù)用于計算兩個時間序列之間的相似性,然后根據(jù)每條時間序列實例與訓(xùn)練數(shù)據(jù)中距離最近的實例所屬的類,將該序列實例分類到對應(yīng)的類中。時間序列分類的距離度量函數(shù)一般有歐幾里德距離(euclidean distance,ED)[5]、動態(tài)時間規(guī)整(dynamic time warping,DTW)[6]、編輯距離(edit distance)[7]、最長公共子序列(longest common sub-sequence,LCS)[8]等方法。其中動態(tài)時間規(guī)整結(jié)合1-近鄰(one-nearest-neighbor,1NN)分類器,是時間序列分類問題的一個基本方法。
基于特征(feature-based)的分類方法通常包括兩個步驟:定義時序特征,然后訓(xùn)練基于定義的時序特征的分類器進(jìn)行分類。例如,Nanopoulos等[9]提取了統(tǒng)計學(xué)特征,包括整個時間序列的均值和方差等特征,然后使用多層感知器神經(jīng)網(wǎng)絡(luò)進(jìn)行分類。這種方法只是提取到了時間序列的全局屬性,而忽略了包含重要分類信息的時間序列局部特征。Geurts[10]通過離散化時間序列來提取局部時序信息特征,以便傳統(tǒng)的分類算法可以對時間序列數(shù)據(jù)進(jìn)行分類。Rodríguez等[11]提出了兩種不同類型的樹模型:基于區(qū)間的樹模型以及基于動態(tài)時間規(guī)整的樹模型。文獻(xiàn)[12]提出使用支持向量機(jī)(support vector machine,SVM)對通過提升的二進(jìn)制樹樁(boosted binary stumps)[13]提取到的時序特征進(jìn)行分類。Deng等[14]提出了時間序列森林(time series forest,TSF)方法,結(jié)合了熵增益(entropy gain)和距離度量,用于評估節(jié)點的分裂,在每個樹節(jié)點處隨機(jī)地對特征進(jìn)行采樣,采用時間重要性曲線以捕獲對分類有用的時間特征。Baydogan等[15]提出了一種TSBF(time series classification with a bag of features)的特征袋框架,從每個間隔中提取具有不同時間尺度的間隔特征形成實例,然后使用隨機(jī)森林進(jìn)行分類。Sch?fer[16]提出了BOSS(bag-of-SFA-symbols)模型,結(jié)合了符號傅里葉近似(symbolic Fourier approximation,SFA)[17]的噪聲度量和基于結(jié)構(gòu)表示的詞袋模型。BOSSVS(bag-of-SFA-symbols in vector space classifier)方法[18]將 BOSS模型與向量空間模型相結(jié)合,通過對具有不同窗口大小的模型進(jìn)行集成來減少時間復(fù)雜度并提高性能,然后使用1-近鄰分類器執(zhí)行最終分類。
基于集成學(xué)習(xí)(ensemble learning)的方法是將不同的分類器組合在一起以實現(xiàn)更高的準(zhǔn)確度。不同的集成模型集成了不同的特征和分類器。Lines和Bagnall將基于彈性距離測量的11個分類器構(gòu)建加權(quán)集成模型PROP(proportional elastic ensemble)[19]。SE(shapelet ensemble)[20]通過shapelet變換與異構(gòu)集合的結(jié)合生成分類器。基于變換的集成方法COTE[20](collective of transformation-based ensembles)集成了基于時域和頻域提取的特征的35個不同的分類器。
以上各種方法都需要對數(shù)據(jù)進(jìn)行復(fù)雜的預(yù)處理,或者進(jìn)行復(fù)雜且繁重的特征工程,尤其是基于特征的方法。近年來,隨著神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)的迅猛發(fā)展,深度神經(jīng)網(wǎng)絡(luò)已經(jīng)在時間序列分類上做出了突出的貢獻(xiàn),尤其是卷積神經(jīng)網(wǎng)絡(luò)用于端對端(end-to-end)的時間序列分類。Zheng等[2]提出了一種多通道卷積神經(jīng)網(wǎng)絡(luò)(multi-channel deep CNN,MC-DCNN)用于多變量時間序列分類,在每個單獨(dú)的通道上應(yīng)用濾波器,將不同通道產(chǎn)生的特征“壓平”(flattened)送入全連接層,作為全連接層的輸入,應(yīng)用滑動窗口來增強(qiáng)數(shù)據(jù)。文獻(xiàn)[21]提出了一種用于單變量時間序列分類的多尺度卷積神經(jīng)網(wǎng)絡(luò)MCNN(multi-scale CNN),在44個UCR時間序列數(shù)據(jù)集上取得了很好的表現(xiàn),但是大量的數(shù)據(jù)預(yù)處理和超參數(shù)使得模型的部署變得復(fù)雜。在基于深度學(xué)習(xí)的時間序列分類問題上,Wang等[3]提出了一個簡單而有效的模型——全卷積神經(jīng)網(wǎng)絡(luò)(fully convolutional neural networks,F(xiàn)CN),不需要對原始數(shù)據(jù)進(jìn)行復(fù)雜的預(yù)處理,提供了一個端對端深度學(xué)習(xí)模型的起點。Karim等[22]提出了LSTM-FCN和ALSTMFCN模型,結(jié)合CNN和RNN建立一個端對端模型,探索了長短期記憶網(wǎng)絡(luò)(long short-term memory,LSTM)在UCR時間序列分類數(shù)據(jù)庫上的表現(xiàn),并且提出了一種微調(diào)(fine-tuning)的做法。
深度學(xué)習(xí)能充分地提取時間序列的各種特征。在時間序列數(shù)據(jù)中,卷積神經(jīng)網(wǎng)絡(luò)作為一種時序卷積,提取了不同時間窗口下的時序特征以及初級特征與高級特征(隨著網(wǎng)絡(luò)層的加深),可以視為對時間序列的一種空間信息特征提取,而RNN本身的特性使得能獲得歷史數(shù)據(jù)的依賴,刻畫序列內(nèi)部或序列之間(多維的情況下)的時序關(guān)聯(lián)。而雙向RNN能夠更好地獲取過去和未來的長期依賴特征。因此,本文進(jìn)一步探索深度學(xué)習(xí)網(wǎng)絡(luò),提出了BiGRU-FCN模型,通過結(jié)合CNN和雙向GRU,充分獲取了時間序列數(shù)據(jù)的多種特征信息,有效地提高了深度學(xué)習(xí)模型的表現(xiàn)。
3 時間序列分類的深度學(xué)習(xí)網(wǎng)絡(luò)結(jié)構(gòu)
一個時間序列數(shù)據(jù)集是一組序列數(shù)據(jù),在相等時間間隔的一段時間內(nèi)的觀測值。在時間序列分類問題中,任意實值型有次序的數(shù)據(jù)都可以被當(dāng)作一條時間序列。假定有一組數(shù)據(jù)量大小為n的時間序列數(shù)據(jù)T={T1,T2,…,Tn},每個時間序列有m個觀測值,即Ti=<ti1,ti2,…,tim> ,對應(yīng)于類標(biāo)yi,yi∈{1,2,…,C},C表示類數(shù)目。
本文提出的應(yīng)用于時間序列分類的深度學(xué)習(xí)網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。時序卷積網(wǎng)絡(luò)和雙向門控循環(huán)單元網(wǎng)絡(luò)分別作為模型的兩個分支,得出不同特征,最后通過merge層連接起來,進(jìn)入softmax層進(jìn)行分類。
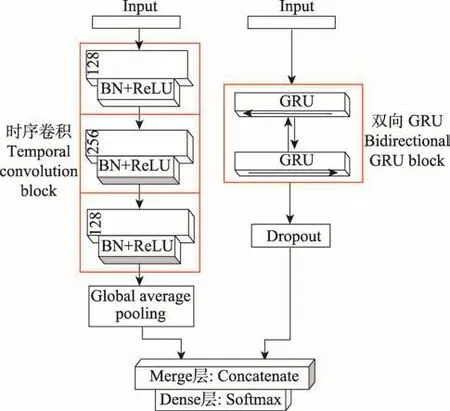
Fig.1 Network architecture of BiGRU-FCN圖1 BiGRU-FCN網(wǎng)絡(luò)結(jié)構(gòu)
3.1 時間序列上的卷積神經(jīng)網(wǎng)絡(luò)
卷積網(wǎng)絡(luò)(convolutional network),也叫卷積神經(jīng)網(wǎng)絡(luò)(CNN),卷積是一種局部操作,通過一定大小的卷積核作用于局部區(qū)域獲得輸入數(shù)據(jù)的局部特征信息,將高層語義信息逐層由原始數(shù)據(jù)輸入層中抽取出來,逐層抽象。
這里把卷積神經(jīng)網(wǎng)絡(luò)視為是一種能在不同的時間層次上提取特征的時序卷積網(wǎng)絡(luò)。
在多層卷積中,上一層的特征映射(feature map)與這一層的卷積核進(jìn)行卷積操作,卷積操作后的輸出與偏置(bias,待訓(xùn)練)相加后,通過激活函數(shù)計算后作為本層輸出的特征映射。如下式所示:

在全卷積神經(jīng)網(wǎng)絡(luò)(FCN)中使用卷積網(wǎng)絡(luò)作為一個特征提取模塊。一個基本的卷積塊包含有卷積層(convolution layer)、批量歸一化層(batch normalization)[23]、激活函數(shù)ReLU。一個基本的卷積塊表示為:

其中,?是卷積運(yùn)算符(convolution operator),堆疊三個卷積塊構(gòu)建全卷積神經(jīng)網(wǎng)絡(luò)分支,如圖2所示,每個卷積塊的濾波器大小分別設(shè)置為{128,256,128},與MCNN和MC-DCNN不同的是每個卷積核中略去了池化(pooling)操作,只是在最后第三個卷積塊結(jié)束之后輸入到全局平均池化層。批量歸一化層可以加速收斂并且提高泛化能力,防止梯度消失、梯度爆炸。
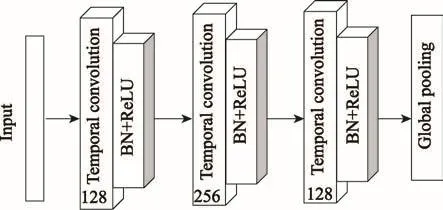
Fig.2 Convolution network branch圖2 卷積網(wǎng)絡(luò)分支
從UCR數(shù)據(jù)集中隨機(jī)抽取四個數(shù)據(jù)集進(jìn)行卷積操作,卷積操作對時間序列分類的作用如圖3所示。可以看出,采用三層的卷積操作能達(dá)到很好的分類效果。
3.2 雙向GRU的時序建模
3.2.1 RNN、LSTM、GRU
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)[24]是一類用于序列數(shù)據(jù)的神經(jīng)網(wǎng)絡(luò),是專門用于處理序列x(1),x(2),…,x(t)的神經(jīng)網(wǎng)絡(luò)。
給定一個輸入序列x=(x1,x2,…,xT),一個循環(huán)神經(jīng)網(wǎng)絡(luò)從t=1到T迭代以下公式計算隱藏向量序列h=(h1,h2,…,ht)和輸出序列y=(y1,y2,…,yT):
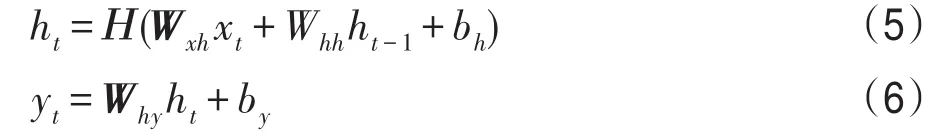
W表示權(quán)重矩陣(例如,Wxh指的是從輸入x到隱藏層h的權(quán)重矩陣),b表示偏置,H指的是隱藏層的激活函數(shù)。結(jié)構(gòu)如圖4所示。
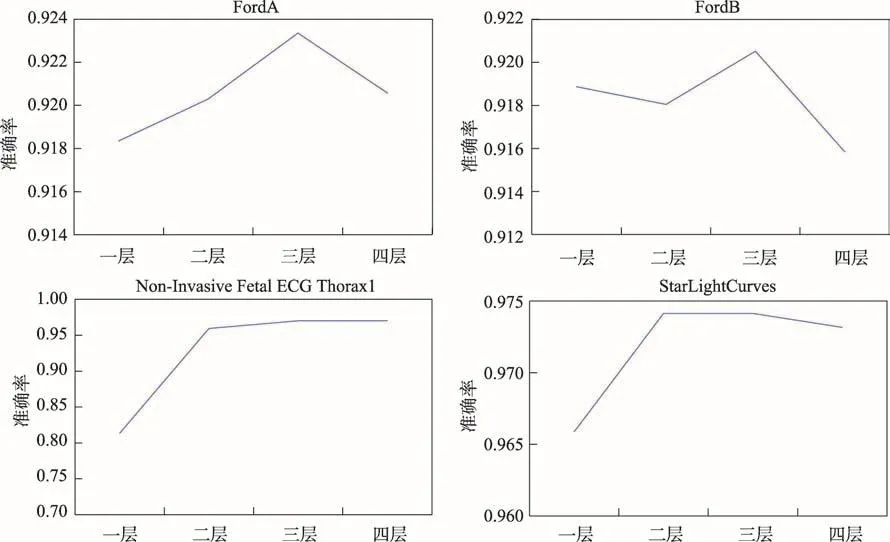
Fig.3 Accuracy of convolution operations on UCR datasets圖3 卷積操作在UCR數(shù)據(jù)集上的準(zhǔn)確率變化
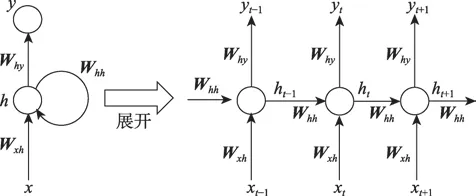
Fig.4 Recurrent neural network structure圖4 循環(huán)神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
原始的循環(huán)神經(jīng)網(wǎng)絡(luò)缺乏學(xué)習(xí)序列數(shù)據(jù)的長期依賴性,容易產(chǎn)生梯度消失或梯度爆炸[25],使得基于梯度的優(yōu)化方法變得比較困難。為解決這個問題,其兩個擴(kuò)展模型:長短期記憶(LSTM)[26]和門控循環(huán)單元(GRU)[27]先后被提出來。本文選擇門控循環(huán)單元,因為其在各種任務(wù)中表現(xiàn)出與LSTM類似的性能[28],同時具有比較簡潔的結(jié)構(gòu),降低了網(wǎng)絡(luò)的復(fù)雜性,減少了整個神經(jīng)網(wǎng)絡(luò)模型的參數(shù),提高了防止過擬合的能力,并且收斂得更快,更加適應(yīng)本文的任務(wù)。
3.2.2 Bidirectional GRU
在經(jīng)典的循環(huán)神經(jīng)網(wǎng)絡(luò)中,狀態(tài)之間的傳輸是從前往后的一個單向傳播過程,在時刻t的狀態(tài)只能從過去的序列x(1),x(2),…,x(t-1)以及當(dāng)前的輸入x(t)捕獲信息,只能利用先前的上下文信息(previous context)。然而,在很多問題及應(yīng)用中,要輸出的y(t)可能依賴于整個輸入序列。應(yīng)用雙向RNN作為模型的一個重要分支,RNN的結(jié)構(gòu)單元采用GRU,如圖5所示。雙向結(jié)構(gòu)使得模型既能獲得正向的累積依賴信息,又能獲得反向的來自未來的累積依賴信息,在本文的多種任務(wù)數(shù)據(jù)集中均表現(xiàn)出了作用,豐富了提取的特征信息。
Fig.5 Bidirectional gated recurrent unit branch圖5 雙向門控循環(huán)單元支路
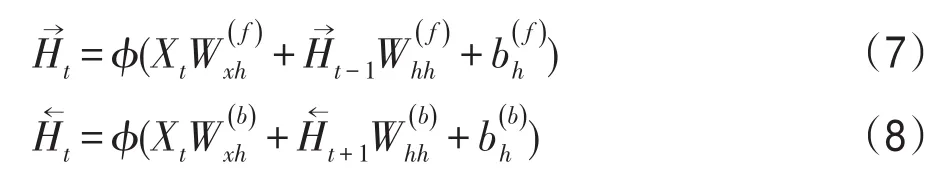

3.3 時間序列上的卷積神經(jīng)網(wǎng)絡(luò)與循環(huán)神經(jīng)網(wǎng)絡(luò)的結(jié)合
如圖1網(wǎng)絡(luò)結(jié)構(gòu)圖所示,將卷積神經(jīng)網(wǎng)絡(luò)獲得的時序卷積特征VFCN(temporal convolutional feature map)與雙向門控循環(huán)單元獲得的雙向時序依賴特征VBiGRU(BiGRU feature map)通過merge層結(jié)合起來:

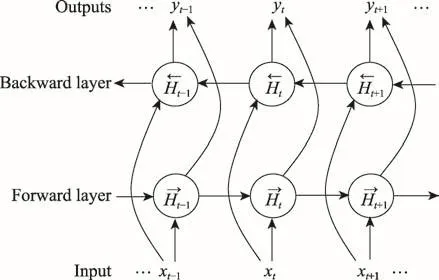
Fig.6 Bidirectional RNN structure圖6 雙向RNN結(jié)構(gòu)
其中,V是輸入到softmax層的特征向量,⊕是merge層的Concatenate運(yùn)算。
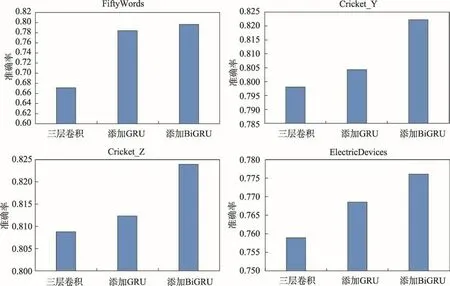
Fig.7 Comparison of effects of CNN,GRU-FCN and BiGRU-FCN圖7 卷積神經(jīng)網(wǎng)絡(luò)、單向GRU-FCN、BiGRU-FCN的效果比較
圖7 展示了在圖3所示卷積操作中,加入門控循環(huán)單元與雙向門控循環(huán)單元,通過merge層結(jié)合之后模型的分類效果。可以看出,通過門控循環(huán)單元,模型能獲取時間序列數(shù)據(jù)的時序依賴特征,雙向門控循環(huán)單元提取了整個序列的正向時序依賴特征和反向時序依賴特征,進(jìn)一步豐富了模型的特征提取能力和提升了分類效果。表1舉例了UCR數(shù)據(jù)集中的Adiac數(shù)據(jù)集在本文模型BiGRU-FCN中的分類過程。
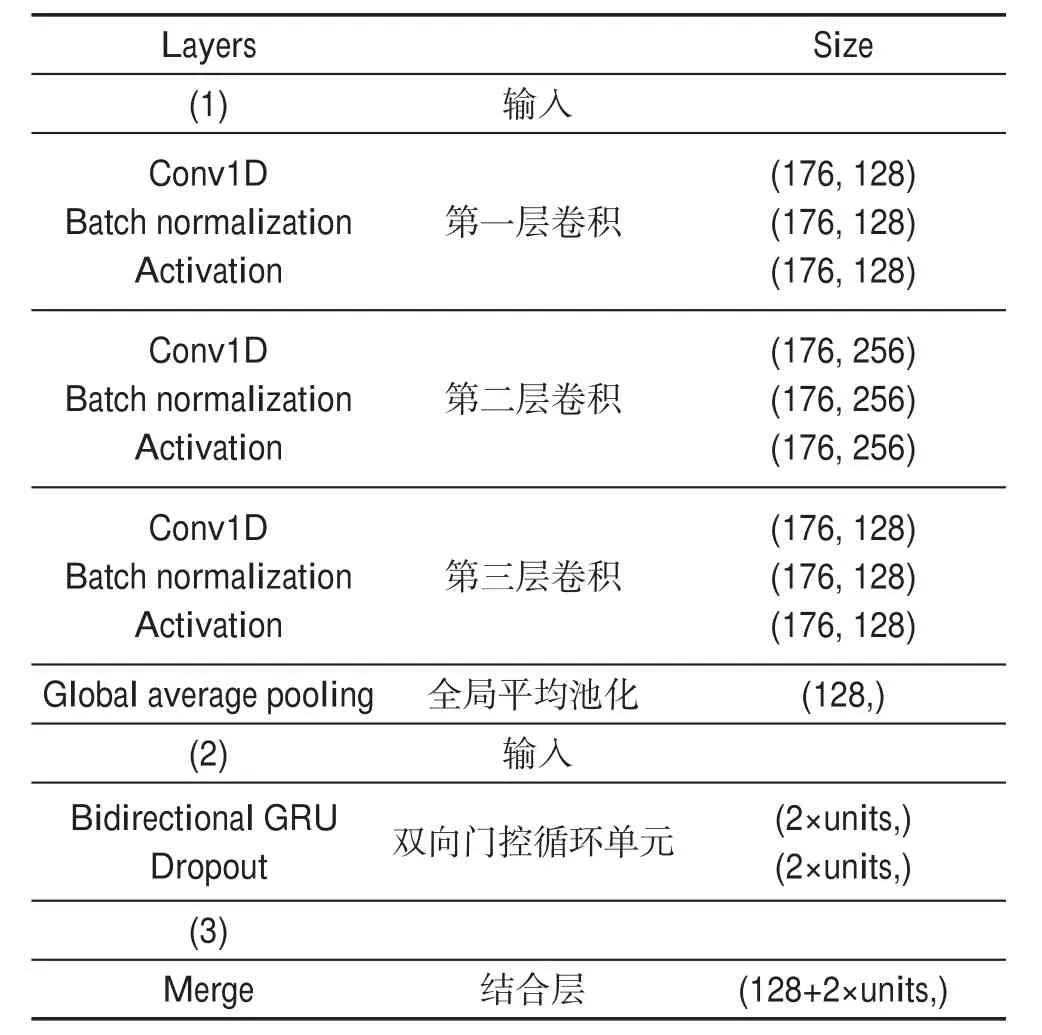
Table1 Classification process ofAdiac dataset表1 Adiac數(shù)據(jù)集在本文模型中的分類過程
4 實驗結(jié)果分析與對比
本章詳細(xì)分析對比了本文模型的分類效果與目前多個文獻(xiàn)公布模型的分類效果,其中包括多種基準(zhǔn)方法。基于距離的方法:1-NN ED[4]、1-NN DTW(r)[4]、1-NNDTW[4]。基于特征的分類方法:TSBF[15]、BOSSVS[18]、BOSS[16]、TSF[14]。基于集成學(xué)習(xí)的分類方法:PROP[19]、COTE[20]、SE1[20]。基于神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)的方法:MLP(deep multilayer perceptrons)[3]、FCN[3]、ResNet[3]、LSTM-FCN[22]、ALSTM-FCN[22]。這些模型方法已在背景及相關(guān)工作中依次進(jìn)行簡單介紹。
實驗數(shù)據(jù)均來自UCR時間序列數(shù)據(jù)倉庫(UCR time series classification archive)[4],包含了多個領(lǐng)域多個種類的時間序列基準(zhǔn)數(shù)據(jù)集(time series benchmarks),采用了UCR中44個數(shù)據(jù)集進(jìn)行實驗。
4.1 實驗平臺
實驗環(huán)境為個人電腦,系統(tǒng)為Ubuntu 16.04.1,Intel?CoreTMi5-3470 CPU@3.20 GHz,GPU是GeForce GTX 1060,6 GB。所有模型都在基于TensorFlow的Keras深度學(xué)習(xí)框架中進(jìn)行訓(xùn)練。
4.2 實驗設(shè)置
在實驗中,全連接神經(jīng)網(wǎng)絡(luò)模塊有3個卷積塊(每塊包含Conv1D層、Batch normalization層、ReLU激活層)和1個全局平均池化層(global average pooling)組成,卷積核大小是{128,256,128}。雙向門控循環(huán)網(wǎng)絡(luò)中,GRU單元的數(shù)量從[4,8,16,32,64,128]中搜索,找到最佳的數(shù)量。訓(xùn)練迭代次數(shù)為2 500次,批尺寸(batch size)大小設(shè)置為32。模型通過Adam optimizer進(jìn)行訓(xùn)練,初始化學(xué)習(xí)率為0.001,設(shè)置回調(diào)函數(shù)在訓(xùn)練過程中調(diào)整學(xué)習(xí)率,在100代中模型效果如果并沒有提升,則按照公式:
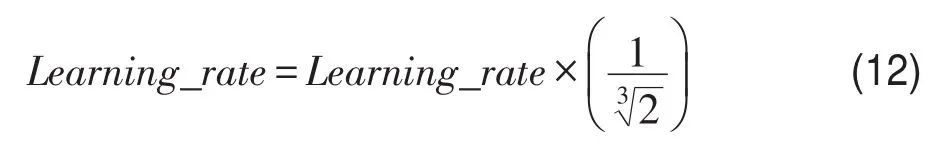
調(diào)整學(xué)習(xí)率,直到學(xué)習(xí)率為0.000 1。
4.3 實驗結(jié)果
4.3.1 評估指標(biāo)
為了更好分析實驗結(jié)果,本文通過多個指標(biāo)來評價:分類錯誤率、平均各類誤差(mean per-class error,MPCE)、平均算術(shù)排名(AVG Rank.avg)、平均排名(AVG Rank.eq)、威爾科克森符號秩檢驗(Wilcoxon sign rank test,WSR)。
MPCE[3]是一種用于衡量特定模型在多個數(shù)據(jù)集上分類性能的指標(biāo)。給定模型M={mi},數(shù)據(jù)集集合D={dk}以及對應(yīng)的類標(biāo)個數(shù)C={ck}、錯誤率E={ek}。

其中,k表示每個數(shù)據(jù)集,i表示每個模型。MPCE表示所有數(shù)據(jù)集中單個類的預(yù)期錯誤率。通過考慮類的數(shù)量,MPCE更具有魯棒性。
算術(shù)排名(Rank.avg)指的是在某數(shù)據(jù)集中,該模型相對于其他模型的分類錯誤率大小的算術(shù)排名(排名相同,則取平均值排名)。平均算術(shù)排名(AVG Rank.avg)則表示該模型在本文所有數(shù)據(jù)集中的算術(shù)排名的均值。排名(Rank.eq)與算術(shù)排名(Rank.avg)的區(qū)別在于排名相同時,并不計算均值。平均排名(AVG Rank.eq)則表示該模型在本文所有數(shù)據(jù)集中的排名的均值。
使用Wilcoxon符號秩檢驗[22]進(jìn)一步驗證了BiGRU-FCN模型與其他模型的區(qū)別。Wilcoxon符號秩檢驗用于比較所提出的模型和現(xiàn)有先進(jìn)模型的中心位置的秩(median rank)。零假設(shè)(null hypothesis)和替代假設(shè)(alternative hypothesis)如下:
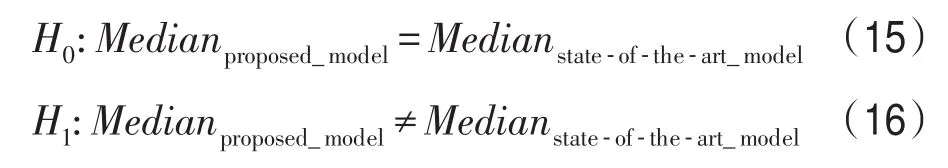
利用Matlab軟件算出在零假設(shè)下的p值,如果p值較小(小于或等于給定的顯著水平,α=0.05,p<0.05),則可以拒絕零假設(shè),說明其分布有差異性。
4.3.2 實驗結(jié)果
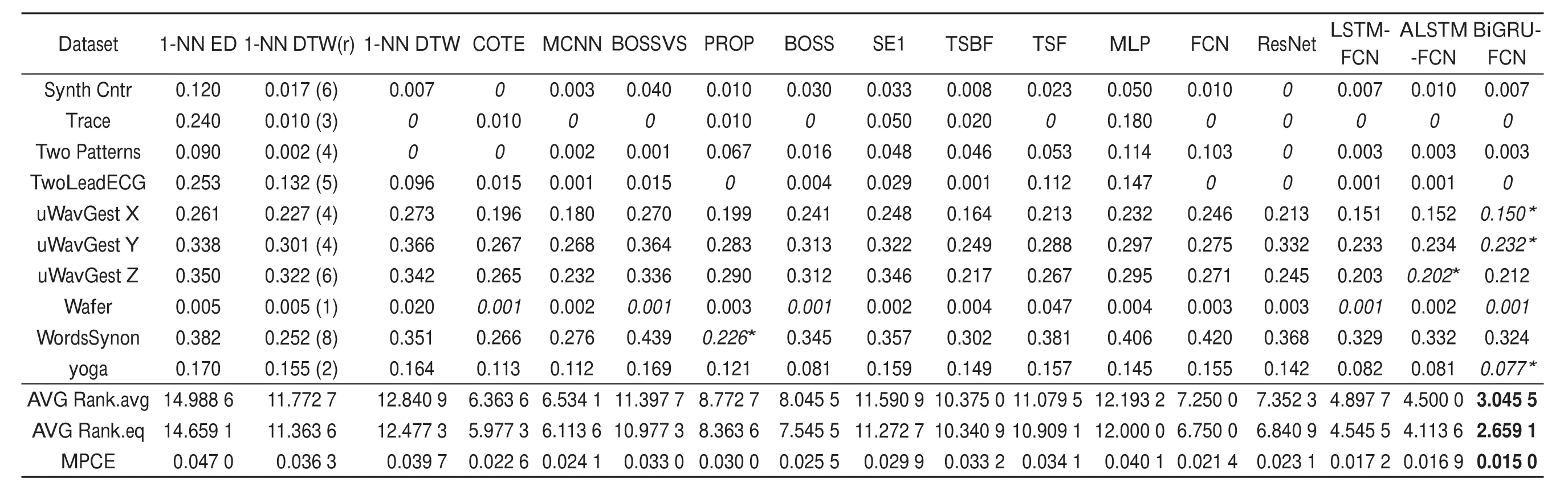
上述指標(biāo)分析結(jié)果如表2所示,其中包括多個文獻(xiàn)公布的結(jié)果,涉及基于距離、特征、集成學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)的多種方法。
通過實驗發(fā)現(xiàn):在UCR的所有85個數(shù)據(jù)集中,BiGRU-FCN在大部分?jǐn)?shù)據(jù)集上達(dá)到了目前較好的分類效果。由于有些文獻(xiàn)沒有公布針對所有85個數(shù)據(jù)集的實驗結(jié)果,表2中僅給出了針對44個數(shù)據(jù)集的結(jié)果,所對比的方法都提供了針對這44個數(shù)據(jù)集的分類錯誤率。表2中斜體表示模型達(dá)到當(dāng)前最優(yōu)結(jié)果,數(shù)字后面帶“*”表示該模型有著比所有模型都高的分類準(zhǔn)確率,可以看出,本文模型在給出的44個數(shù)據(jù)集上,在25個數(shù)據(jù)集上達(dá)到最優(yōu)結(jié)果,其中有14個優(yōu)于其他所有模型。
表2的后3行給出了各模型在44個數(shù)據(jù)集上的平均算術(shù)排名(AVG Rank.avg)、平均排名(AVG Rank.eq)以及平均各類誤差(MPCE),本文的模型均達(dá)到了很好的效果。
從表2可以看出,從不同類型方法的差異的角度,分類效果是4種方法逐步提升:基于距離度量的方法<基于特征的方法<基于集成學(xué)習(xí)的方法<基于深度學(xué)習(xí)的方法。集成學(xué)習(xí)方法集成了基于距離度量與特征學(xué)習(xí)的方法,例如COTE,能取得比基于距離度量與特征學(xué)習(xí)方法更好的效果,因為集成了其兩者的優(yōu)點,有著更高的準(zhǔn)確率。隨著模型技術(shù)的不斷更新,模型越來越復(fù)雜,例如深度學(xué)習(xí)模型的變更,以及對應(yīng)的調(diào)優(yōu)技巧也不斷更新;例如本文模型中深度學(xué)習(xí)的Dropout及優(yōu)化函數(shù)Adam、激活函數(shù)ReLU等,使得深度學(xué)習(xí)在時間序列分類問題的效果也逐漸提高。
從實驗表格中可以看出,本文方法在少數(shù)數(shù)據(jù)集上沒有達(dá)到最優(yōu),在這少數(shù)數(shù)據(jù)集上,大部分都接近最優(yōu)結(jié)果,所有基于深度學(xué)習(xí)的方法效果都接近最優(yōu)結(jié)果,這也說明了深度學(xué)習(xí)方法在時間序列分類上的先進(jìn)性。但仍有幾個數(shù)據(jù)集,深度學(xué)習(xí)模型效果并不好,如CinC_ECG、WordsSynonyms數(shù)據(jù)集,分析其數(shù)據(jù)特點,發(fā)現(xiàn)其數(shù)據(jù)量少,訓(xùn)練數(shù)據(jù)量不足,分類類別過多,導(dǎo)致深度學(xué)習(xí)模型未能很好地抓取其特征,分類效果不佳。訓(xùn)練數(shù)據(jù)量較小也是UCR時間序列數(shù)據(jù)倉庫的一個問題。
表3給出了各模型間Wilcoxon符號秩檢驗的p值(p-value),可以看出,本文模型與各種模型的結(jié)果相比,p值均小于α值(0.05),說明拒絕零假設(shè),本文提出的模型在多個數(shù)據(jù)集上的效果分布與其他模型有差異性。
5 總結(jié)和展望
時間序列分類問題是時間序列分析中的一個重要方面。針對傳統(tǒng)方法以及當(dāng)前研究存在的問題,通過對深度學(xué)習(xí)的研究,提出了一個端對端模型BiGRU-FCN。本模型通過卷積神經(jīng)網(wǎng)絡(luò)在時間序列數(shù)據(jù)上的時序卷積,獲取不同時間尺度的特征;通過雙向的門控循環(huán)單元,獲取來自過去以及未來的長期依賴特征信息;不需要對數(shù)據(jù)進(jìn)行復(fù)雜的預(yù)處理,通過不同的網(wǎng)絡(luò)運(yùn)算來獲取多種特征信息,對單維時間序列進(jìn)行分類。在大量的基準(zhǔn)數(shù)據(jù)集上對模型進(jìn)行實驗與評估,結(jié)果表明:與現(xiàn)有的多種方法相比,所提出的模型具有更高的準(zhǔn)確率。
將進(jìn)一步研究模型,能學(xué)習(xí)到抓取到更多更全面的特征,構(gòu)成更全面的特征映射。在時間序列分析方面,鑒于模型的有效性,可以將其擴(kuò)展到多維時間序列中。
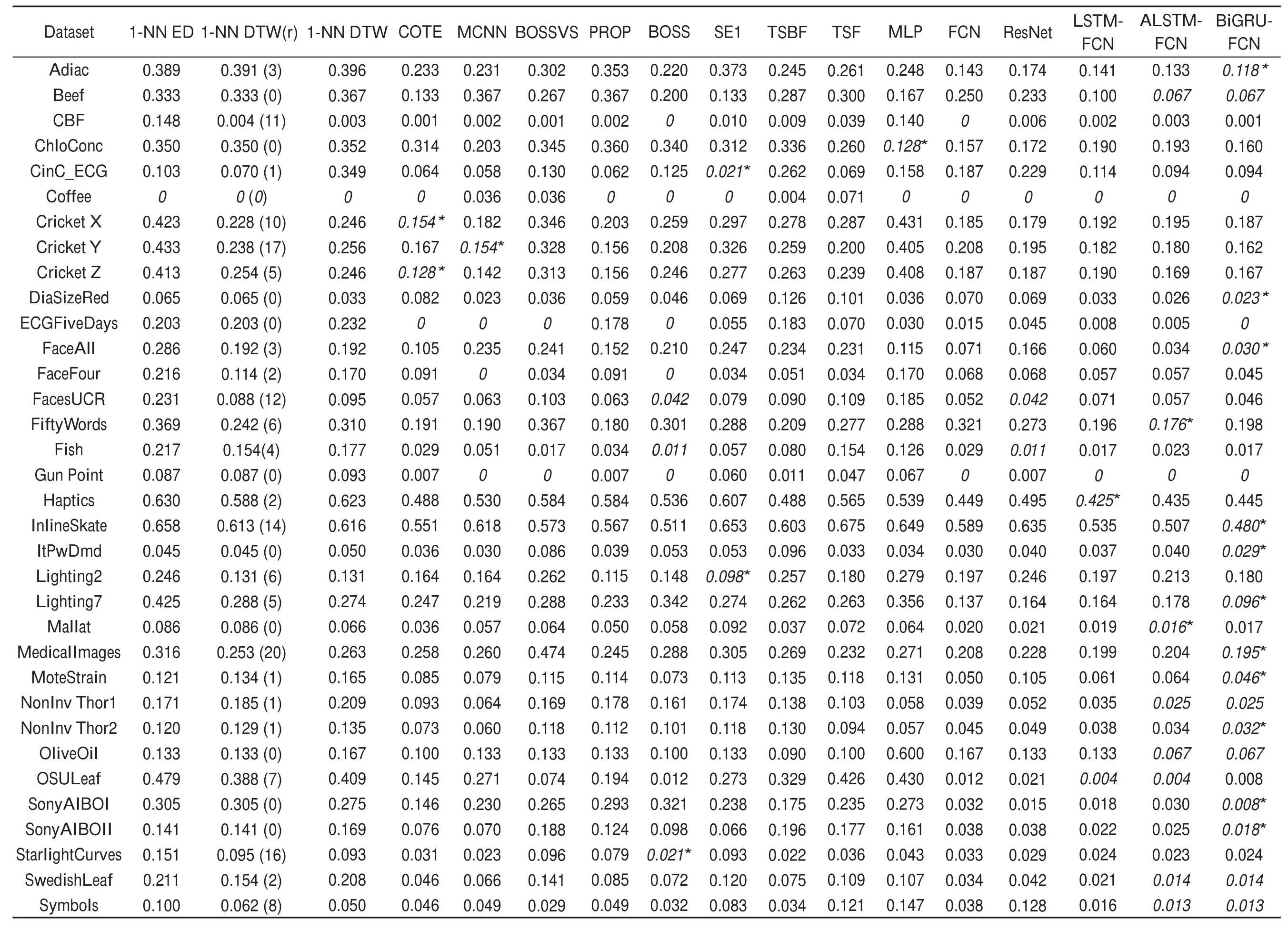
Table2 Comparison of error rate and various indicators of different models表2 不同模型的分類錯誤率、各項指標(biāo)的對比
續(xù)表2
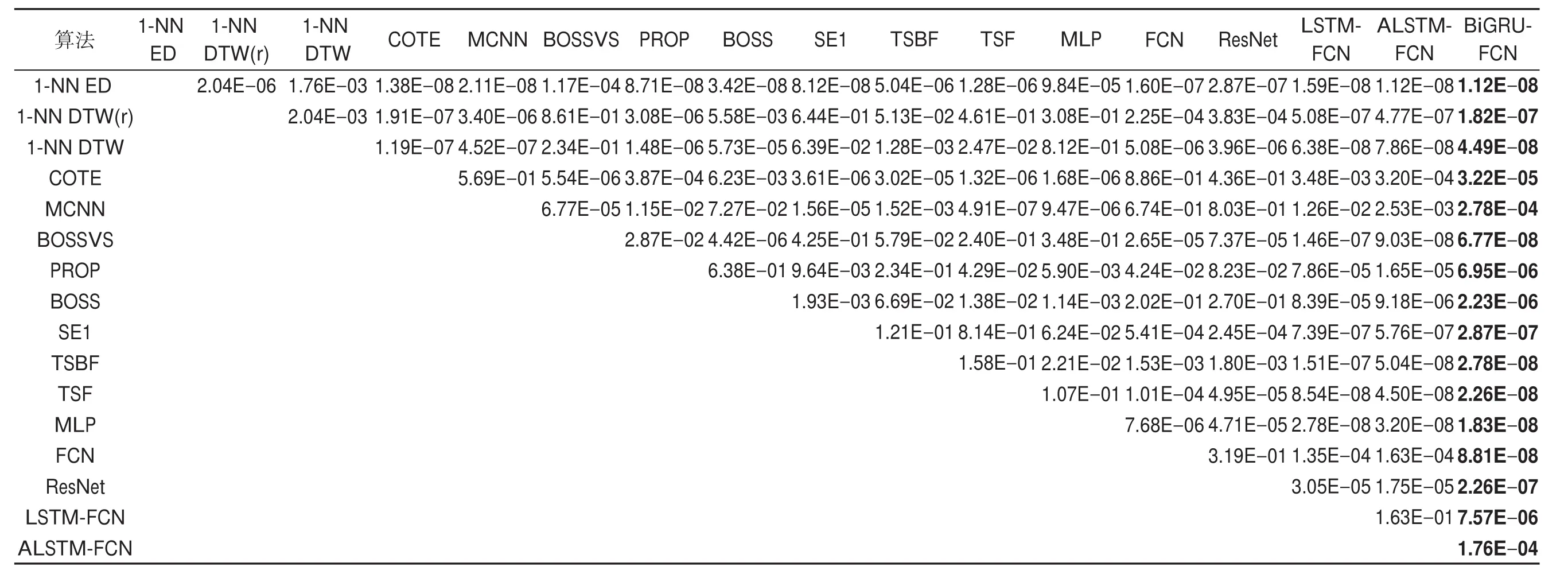
Table3 p-values ofWilcoxon sign rank test between different models表3 各模型間Wilcoxon符號秩檢驗的p 值
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
