基于圖數(shù)據(jù)的關(guān)鍵字覆蓋集合問題
2019-06-11 09:54:16劉慧娟
電子技術(shù)與軟件工程 2019年7期
文/劉慧娟
任何一個企業(yè)的組成或者結(jié)構(gòu)都可以看成一個大的數(shù)據(jù)圖,那么這個問題就可以定義為:給定有向無環(huán)圖G,關(guān)鍵字的集合覆蓋問題主要回答找到k關(guān)鍵字,使k個關(guān)鍵字能夠覆蓋給定的屬性集合,并且這k個關(guān)鍵字的影響力最大,這是多種數(shù)據(jù)管理應(yīng)用中的核心操作之一,如XML和RDF數(shù)據(jù)庫以及社交網(wǎng)絡(luò)和生物信息網(wǎng)絡(luò)等,是研究者廣泛關(guān)注的熱點(diǎn)問題。如日常生活中普遍存在的工程設(shè)計問題,在電網(wǎng)企業(yè)中人員調(diào)動、通信網(wǎng)絡(luò)安全、資源分配、電路設(shè)計、信息通信管理、運(yùn)輸車輛路徑安排等領(lǐng)域有廣泛的應(yīng)用,多年來吸引了眾多計算機(jī)科學(xué)家、運(yùn)籌學(xué)研究人員的研究興趣。對這一問題,相繼有很多學(xué)者利用不同的思想提出了很多不同的算法。現(xiàn)有求解關(guān)鍵字覆蓋集合的方法主要分為四類,基于分?jǐn)?shù)的貪心算法、基于鴿子洞的貪心算法、基于劃分的算法、基于劃分的優(yōu)質(zhì)算法。
1 背景知識及相關(guān)工作
本文用G=(V,E)表示有向無環(huán)圖,其中V表示G中的頂點(diǎn)集合,E表示G中有向邊的集合,|V|表示G中頂點(diǎn)的個數(shù),|E|表示G中邊的個數(shù)。若(u,v)∈E,則說明G中有一條從u到v的邊,反之不存在。w(u,v)是從節(jié)點(diǎn)u到節(jié)點(diǎn)v概率,取值范圍是(0,1]。
在社交網(wǎng)絡(luò)G中,節(jié)點(diǎn)v的屬性集合用A(v)表示,如果屬性ai∈A(v),那么節(jié)點(diǎn)v覆蓋屬性ai,否則就認(rèn)為節(jié)點(diǎn)v沒有覆蓋屬性ai。節(jié)點(diǎn)集合覆蓋屬性集合A={a1, a2,…, am}當(dāng)且僅當(dāng)任意的屬性ai∈A,至少有一個節(jié)點(diǎn)v(v∈V′)覆蓋屬性ai。用V(A)表示節(jié)點(diǎn)集合,在集合中的每一個節(jié)點(diǎn)都能覆蓋屬性集A。集合屬性的劃分是基于覆蓋組的概念進(jìn)行劃分的,設(shè)一個屬性集合Q和Q的一種局部劃分P={A1, A2, …, Am}令ri=|Ai|(i∈[1,m])是屬性Ai集合中元素的個數(shù)。集合R={r1, r2, …, rm}是P的覆蓋組。
2 PICS-IN方法
本節(jié)首先介紹索引結(jié)構(gòu),在每次查詢覆蓋特定屬性m的節(jié)點(diǎn)時,直接查找屬性m的倒排表即可,減少了時間代價來減少需要訪問的頂點(diǎn)數(shù)量,簡稱PICS-IN,然后介紹基于閾值的高效的剪枝策略,并將其應(yīng)用于PICS-IN算法來提升系統(tǒng)性能。
2.1 離線索引結(jié)構(gòu)
本文方法所使用的集合劃分策略是根據(jù)覆蓋組的方法進(jìn)行劃分組合,覆蓋組,當(dāng)判斷節(jié)點(diǎn)u的屬性是否能覆蓋屬性某一屬性m時,PICS-IN的基本思想是:首先根據(jù)圖1中節(jié)點(diǎn)集合中包含的所有不重復(fù)的屬性集合,建立屬性集合的倒排索引,選擇符合條件的節(jié)點(diǎn)集合。
給定一個屬性集合Q,一個正整數(shù)k,一個社交網(wǎng)絡(luò)G=(V, E, w, A)。圖中的每個節(jié)點(diǎn)都有屬性標(biāo)簽,每個節(jié)點(diǎn)的屬性標(biāo)簽的個數(shù)不同,其中也有的節(jié)點(diǎn)的屬性個數(shù)為0,圖1中,節(jié)點(diǎn)1到節(jié)點(diǎn)23之間每個節(jié)點(diǎn)的屬性標(biāo)簽個數(shù)不一定相同,同一個屬性a可能會出現(xiàn)在多個節(jié)點(diǎn)中,例如節(jié)點(diǎn)1的屬性標(biāo)簽集合是{a, b, c, d},節(jié)點(diǎn)2的屬性集合是{a, b, c, e},重復(fù)的屬性是{a, b, c}三個。建立的索引結(jié)構(gòu)是關(guān)于節(jié)點(diǎn)的不重復(fù)的屬性集合A(V)和節(jié)點(diǎn)的索引,屬于離線索引。建立離線索引需要三步,首先遍歷節(jié)點(diǎn)集合V,然后對于每個節(jié)點(diǎn)v,遍歷節(jié)點(diǎn)v的屬性集合中任意的屬性a,最后把節(jié)點(diǎn)v放到屬性a的倒排表中,當(dāng)遍歷完節(jié)點(diǎn)集合中的節(jié)點(diǎn),以及節(jié)點(diǎn)集合中每個節(jié)點(diǎn)的屬性集合,那么就建立了屬性的倒排表。圖1中,節(jié)點(diǎn)集合為V={1, 2, 3, 4, …,23},節(jié)點(diǎn)集合V中所有節(jié)點(diǎn)的不重復(fù)的屬性是{a, b, c, d, e, f},把包含屬性集合中任一屬性的節(jié)點(diǎn)存放到屬性的倒排表中,遍歷節(jié)點(diǎn)集合V,訪問1號節(jié)點(diǎn)時,1號節(jié)點(diǎn)的屬性集合是{a, b, c, d},那么就把1號節(jié)點(diǎn)分別添加到屬性a,b,c,d的倒排表中,建立的索引結(jié)構(gòu)如圖2所示,那么建立的倒排索引中,屬性a的倒排表中是包含屬性a的節(jié)點(diǎn),其他屬性也一樣。由圖1得到的屬性索引結(jié)構(gòu)如上的表1所示。
2.2 高效的閾值剪枝策略
定理1(新生成組合的判斷條件)給定一個鏈表集合L1,L2,…,Lm,一個組合集合C,鏈表Li在第d層元組用表示,如果新生成的組合至少滿足以下條件之一,則直接把這個組合進(jìn)行刪除,不再和集合C中其他的組合結(jié)合在一起產(chǎn)生新的組合,條件如下:
首先在已經(jīng)構(gòu)建的倒排索引中,找到前k個能夠覆蓋給定的屬性集合Q中的屬性,并且有最大影響力的節(jié)點(diǎn);其次,對于屬性集合Q每一個覆蓋組R,從已經(jīng)選擇的節(jié)點(diǎn)集合中取前k-|R|個節(jié)點(diǎn)作為自由集的解,并在已經(jīng)劃分的覆蓋組中除去已經(jīng)被自由集中的節(jié)點(diǎn)覆蓋的屬性;最后,根據(jù)PICS+算法中構(gòu)建在線索引鏈表的方法,構(gòu)建索引鏈表,即把覆蓋相同屬性個數(shù)的節(jié)點(diǎn)放在同一鏈表中,并把節(jié)點(diǎn)組合成元組的形式,如圖2所示,構(gòu)建的在線的索引鏈表如表2所示。然后把鏈表中不同列的元組進(jìn)行組合,利用取上界的Upperbound算法求出能夠覆蓋這些屬性并且影響力最大的節(jié)點(diǎn),最后得到的這些節(jié)點(diǎn)就是受約束集Sp,最后返回的k個節(jié)點(diǎn)就是由自由集中的節(jié)點(diǎn)和受約束集中節(jié)點(diǎn)組成的并集。
3 結(jié)論
通過實(shí)驗(yàn)對比現(xiàn)有的幾種算法和本文提出的PICS-IN算法的索引大小、創(chuàng)建索引的時間、查詢節(jié)點(diǎn)的時間以及實(shí)驗(yàn)中需要訪問的頂點(diǎn)數(shù)量,通過幾種性能的對比,驗(yàn)證了本文提出算法的結(jié)果的準(zhǔn)確性和時間的高效性。最后對PICS-IN算法在取不同k值時,不同|Q|值時的查詢處理性能進(jìn)行了實(shí)驗(yàn)對比,進(jìn)一步驗(yàn)證了本文提出的PICS-IN算法的擴(kuò)展性。
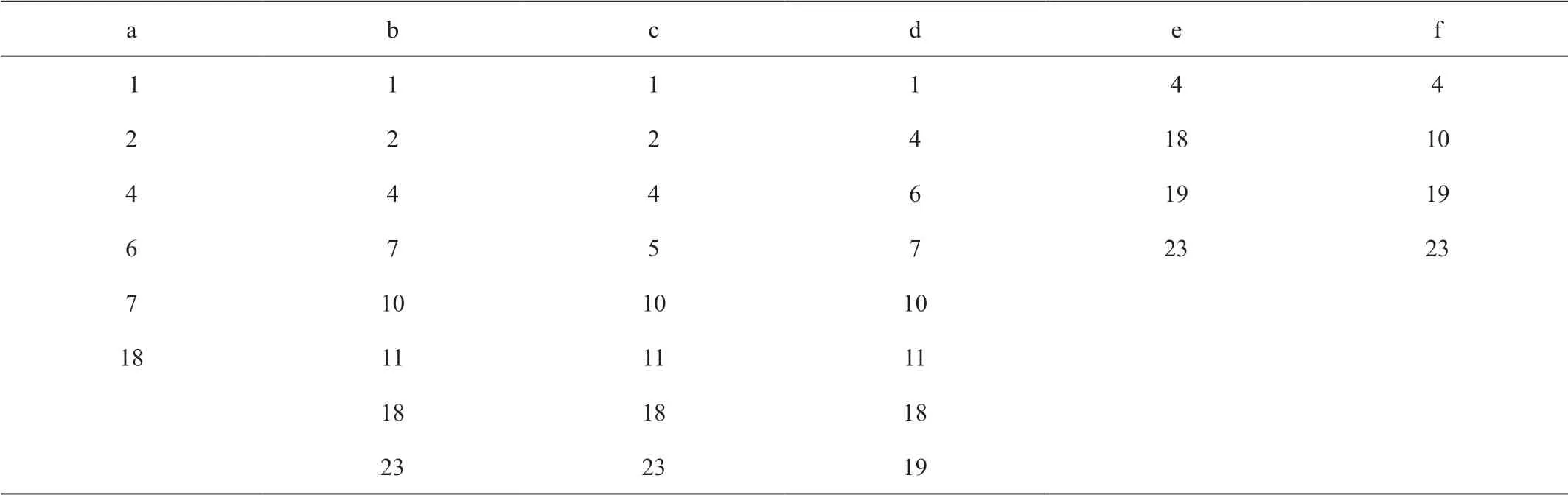
表1:屬性的索引結(jié)構(gòu)

表2:覆蓋組的鏈表
集合覆蓋方法對企業(yè)物資的調(diào)度、電路的設(shè)計等起到了良好的推動作用,并通過數(shù)據(jù)分析,可以得出最優(yōu)的、最合理的解,也就是實(shí)際問題的解決辦法,集合覆蓋技術(shù)的研究將將大大的減少人工核算的人員和資源的浪費(fèi),為電網(wǎng)的發(fā)展提供更加合理化、數(shù)據(jù)化的理論支撐,更加準(zhǔn)確、有效的推進(jìn)企業(yè)規(guī)劃中的資源配置和部署。
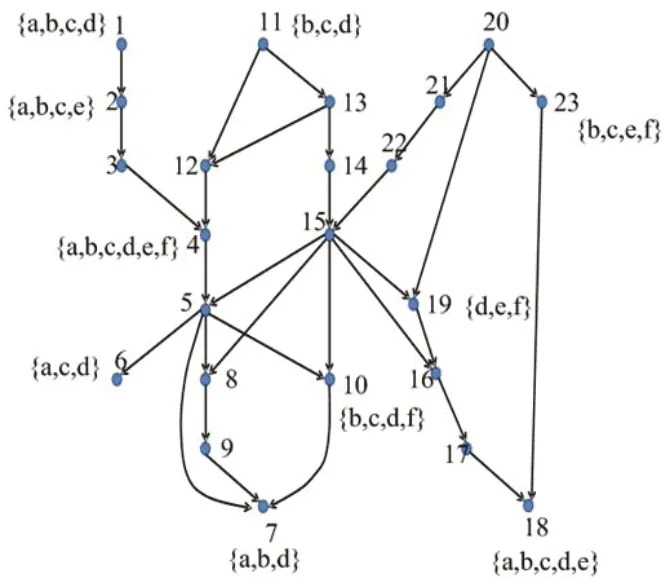
圖1:有向無環(huán)圖G及頂點(diǎn)屬性標(biāo)簽圖
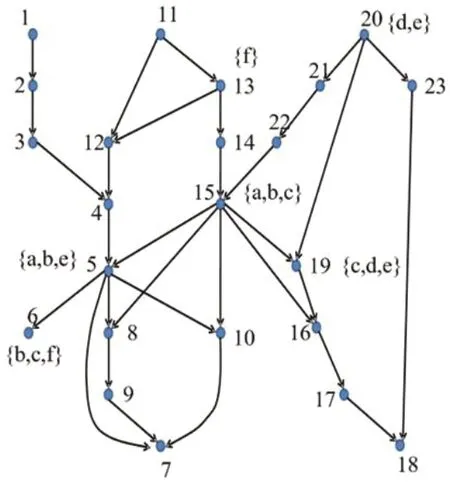
圖2:有向圖G及節(jié)點(diǎn)的屬性標(biāo)簽圖
