融合深度學習與機器學習的在線評論情感分析
2019-06-10 01:01:19劉曉彤田大鋼
軟件導刊 2019年2期
劉曉彤 田大鋼

摘 要:情感分析可以幫助商家了解客戶喜好從而生產出滿意度更高的商品,也可以監督網上輿論等。為此,基于傳統機器學習方法,加入深度學習模塊,對在線評論進行情感分析與對比。在詞向量訓練模塊中引入Word2vec模型,用高維向量表示詞語、句子,既可防止過度擬合問題,又可減少訓練參數個數,提高訓練效率。將得到的句向量作為輸入代入機器學習模型(MLP、SVM、樸素貝葉斯等)與深度學習模型(CNN、LSTM、BILSTM等),比較實驗結果,提出優化方向。結果表明,基于深度學習的情感分析模型準確率明顯高于單一機器學習模型,但是深度學習需要大量語料,對實驗機器要求也較高,很難完全展現其魅力。
關鍵詞:情感分析;深度學習;機器學習;Word2vec模型
DOI:10. 11907/rjdk. 182576
中圖分類號:TP301文獻標識碼:A文章編號:1672-7800(2019)002-0001-04
Abstract:Sentiment analysis is very important,it can help merchants understand the preferences of customers so that they can produce more satisfying goods, and it can also supervise online public opinion. This paper is mainly based on the traditional machine learning method to give the results and do the comparison by employing the deep learning module. A total of two modules can be divided. First, the word vector training module introduces the Word2vec model, and uses high-dimensional vectors to represent words and sentences. Here, the pre-trained Word2vec model is introduced, which not only prevents the over-fitting problem, but also reduces the number of training parameters and improves the training efficiency. The second is to enter the obtained sentence vector as the input into the machine learning model (MLP, SVM, Na?ve Bayes, etc), deep learning model (CNN, LSTM, BILSTM, etc), compare the experimental results, and propose the optimization direction. The accuracy of sentiment analysis models based on deep learning is significantly higher than that of a single machine learning model, but deep learning requires a large amount of corpus, and the requirements for experimental machines are relatively high. It is difficult to demonstrate its charm fully.
Key Words: sentiment analysis; deep learning; machine learing; Word2vec model
0 引言
情感分析又稱意見挖掘、傾向分析,是自然語言處理領域的一個基礎任務,其目的是利用機器提取人們對某人某物或者某事件的態度是正向支持還是反向反對,從而發現潛在問題并加以解決,或者進行預測以預防新問題產生。
近年來,互聯網迅速發展,人們日常生活多方面都離不開網絡,微博、電子商務平臺等熱門應用吸引了大量用戶,由此產生大量用戶參與的對于任務、事件、產品等有價值的評論信息。如此一來,也影響了社會信息傳播格局[1]。這些評論信息大都包含了人們的情感色彩和情感傾向,如喜、怒、哀、樂以及批評、贊許。隨著新興社交平臺的發展,網民數量呈爆炸式增長,大量評論信息迅速傳播[2]。對在線評論進行情感分析,實施急需的網絡安全監管有重大意義[3-4]。但是,面對如此海量的信息,僅僅依靠人工挖掘是不夠的,因此如何高效地進行情感分析、意見挖掘變得至關重要。
目前中文文本情感分析主要分為三大類:第一類是基于詞典的詞典匹配法,需要很完備的高質量詞典支持。常見的情感詞典包括WordNet[5]、General Inquier(GI)等。Kim等[6-7]利用情感詞典對種子情感詞進行擴展,并得到對種子情感詞分析影響較大的結論。第二類是基于機器學習的情感分析,機器學習極度依賴語料,將手機語料訓練出來的分類器用來給書評分類注定要失敗,但是其整體準確率還是非常樂觀的。第三類則是運用近來比較火熱的深度學習算法,在有大量全面訓練語料的情況下,深度學習在情感分析方面的成效非常可觀。Bengio 等[8]提出采用神經網絡構建分布式詞向量,Mikolov等[9]提出了Word2ve模型,Kim等[10]提出采用 Word2vec預訓練得到詞向量。隨后,梁軍等[11]利用深度學習方法進行中文微博情感分析工作。
21世紀初,情感分析就已經在自然語言處理領域研究中活躍起來,尤其是在數據挖掘、文本挖掘等方面表現極為突出。傳統的無監督方面主要是以情感詞典為代表,為了準確識別情感詞,肖江等[12]構建了基準情感詞典以及相關領域情感詞典,其主要核心是采用相似度計算確定情感詞的情感傾向。文獻[13]也是基于詞典的情感分析,采用的方法則是擴展點互信息So-PMI算法,該方法機械地將分好詞后的文本信息與情感字典匹配從而確定其情感傾向,其結果雖然優化了,但是依然存在很大缺陷。比如:“好開心啊,我中了五百萬!”情感詞典匹配法會把此處的“好”和“開心”都標記為情感詞,而實際上“好”不過是一個程度副詞用來修飾“開心”而已。基于詞典的情感會因為詞典匹配語義表達的豐富性而出現很大誤差,而且分類準確率過于依賴詞典,而新興詞語太多,對于詞典的補充也太浪費時間人力。由此可見,傳統的情感詞典方法在情感分析中表現不是很理想。機器學習則需要大規模人工標注工作,并通過計算機進行訓練求解,其分類結果過于依賴標注數據集。好的分類器就要依賴一個好的數據集,如此不但可大量減少人工工作,節省人力時間,而且分類結果上也較為可觀。Catal等[14]采用樸素貝葉斯算法、支持向量機、Bagging算法等多種分類器進行情感分析,最終利用投票算法確定分類的最終結果。Liu等[15-16]將 Co-training 協同訓練算法與 SVM 相結合進行推文的情感分析,Co-training 協同訓練算法可以實現語料半自主標注,省時省力,再利用 SVM 算法實現推文的情感分類。但是機器學習模型在判斷文檔和句子的情感傾向時,跟情感詞典法一樣,極有可能忽略文本中不帶感情色彩的情感詞。卷積神經網絡(CNN)是一種基于卷積運算的神經網絡,隨著研究深入,人們發現CNN也可以用于自然語言處理任務,尤其是分類任務,有人提出基于CNN模型的情感分析,其是使用CNN學習句子的向量表示,然后再進行分類任務。李陽輝等[17]提出基于深度學習的細粒度情感分析,分析對象來自不同語料,包括評價詞典、微博、影評、知乎等,分析粒度從詞語級別到篇章級別。 時至今日,在谷歌Word2vec工具開源后,詞向量的學習方法多種多樣,結合深度學習方法進行建模在自然語言處理多個領域取得了巨大突破[18-20]。目前最有效和流行的詞向量表示方式依然是Word2vec,其訓練方法簡單,直接調用python工具中Gennsim的Word2vec方法即可,也是本文選擇用來訓練詞向量的工具。
1 數據預處理
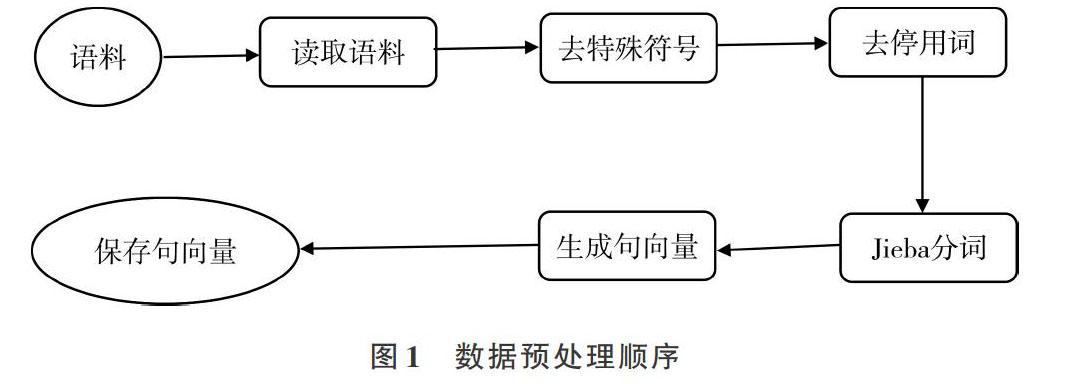
預處理主要是對數據進行標準化處理,并且訓練詞向量,數據預處理活動可大致表示如圖1所示。
1.1 數據集
本文訓練情感分析模型所用數據來自于網上各種新聞評論和商品評論(購買和爬蟲獲取),其中共11個大類,每類抽取2 000條數據,總計22 000條語料。格式如圖2所示。
1.2 數據清洗及分詞
數據清洗是指將收集到的數據集整理成后面實驗可用的形式,其中工作主要包括繁簡轉化、停用詞與特殊符號去除。中文繁簡轉換工作很容易實現,可以依靠Linux系統中自帶的OpenCC工具,直接對數據集文件執行opencc命令即可。
命令行輸入:opencc-i inputfile.txt-o outputfile.txt-c zht2zhs.ini
其中inputfile.txt是輸入等待轉換的數據集,outputfile.txt是轉換好的輸出文件名。對于數據集中的特殊符號則需用Python正則化方法,即re正則表達式。
數據清洗后即可以進行分詞操作,本文采用的是分詞工具是“結巴”分詞,支持3種分詞模式:一是精確模式,它試圖將句子最精確地切開,適合文本分析;二是全模式,它把句子中所有可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義;三是搜索引擎模式,在精確模式基礎上,對長詞再次切分,提高召回率,適合用于搜索引擎分詞。舉例如下:
1.3 情感詞向量
建模環節中最重要一步是特征提取,在自然語言處理中也不例外。為了將一個句子轉化成可以用數字表示的有效實現,有人提出,可以把每個詞語都用一個對應數字表示,而且相近詞語給予相近編號,該方法看似解決了問題,但事實結果并不樂觀,因為忽略了語義因素。語義不是單一的,而應該是多維的,比如我們談到“家園”,有人會想到近義詞“家庭”,從“家庭”又會想到“親人”,其都是有相近意思的詞語;另外,有的人從“家園”會想到“地球”,從“地球”又會想到“火星”,換句話說,“親人”、“火星”都可以看作是“家園”的二級近似,但是“親人”跟“火星”本身沒有什么明顯聯系。Word2vec正好解決了上述問題,簡單說,Word2vec可以用高維向量表示詞語,并把相近意思的詞語放在相近位置,而且用的是實數向量(不局限于整數)。只需要有大量某語言的語料,就可以用來訓練模型,獲得詞向量。實現Word2vec,讀者可通過Google官方提供的C語言源代碼自行編譯,Python的Gensim庫中也提供了現成的Word2vec作為子庫。部分代碼如下:
2 實驗與對比
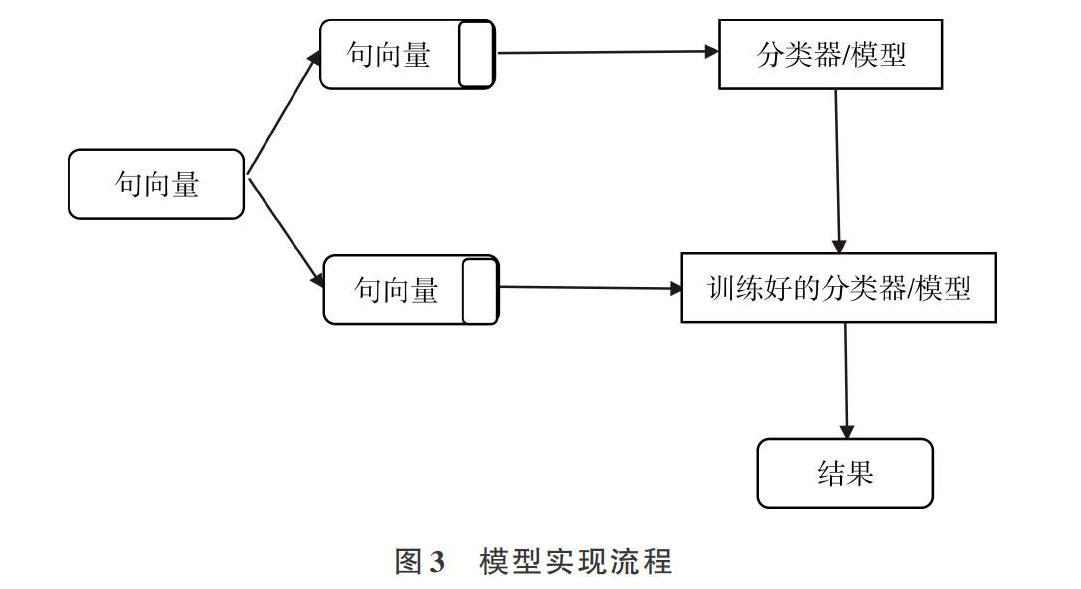
將上述整理好的數據按4∶1分成訓練集與測試集,并輸入各個分類器,采用情感分析模型進行實驗對比,大致流程如圖3所示。
2.1 模型代碼與參數設置
根據不同算法構建不同分類器,用測試集檢驗各種算法分類器的準確度。傳統的機器學習使用sklearn實踐,深度學習則采用keras工具,其代碼部分很相似,下面給出深度學習(LSTM、BILSTM)模型偽代碼。
2.2 實驗結果與對比
傳統的機器學習選取樸素貝葉斯、SVM兩個分類器進行實驗與對比,而深度學習則用到了詞向量表示方法Word2vec和深度網絡CNN、LSTM(后面可以嘗試其改進版BILSTM),最后將深度學習與機器學習相結合,構建Word2vec+SVM模型,并進行實驗對比。實驗主要模型結構和部分結果分別見圖4、圖5。
實驗結果顯示,LSTM 需要訓練的參數個數遠小于 CNN,但訓練時間長于 CNN,LSTM的結果也不如其它分類器或模型好,是由訓練數據不全、過少導致的,因此要想讓 LSTM 優勢得到發揮,首先要保證訓練數據量。加入Word2vec模型后,結果都得到了優化,證明了其有效性。
各模型以及分類器準確率如表1所示。
3 結語
本文情感分析方法是基于傳統機器學習與深度學習的有監督模型,需要大量語料訓練模型,但事實卻是中文環境下有標簽的數據太少,作者本身獲取數據的能力也有限,所以整體實驗結果沒有達到預期。尤其是深度學習模型,受到數據的極大限制。所以,未來情感分析領域要加強對無監督或者半監督方法的研究,使大量有效的無標簽數據派上用場。
參考文獻:
[1] 丁兆云,賈焰,周斌. 微博數據挖掘研究綜述[J]. 計算機研究與發展,2015,51(4):691-706.
[2] 李洋,陳毅恒,劉挺. 微博信息傳播預測研究綜述. 軟件學報,2016,27(2):247-263.
[3] 陳曉宇. 我國網絡監管制度初探[J]. 福建公安高等專科學校學報,2004(2):62-65.
[4] 王樂,王勇,王東安,等. 社交網絡中信息傳播預測的研究綜述[J]. 信息網絡安全,2015(5):47-55.
[5] MILLER G A,BECKWITH R,FELLBAUM C,et al. WordNet:an on-line lexical database[J]. International Journal of Lexicography,1990,3( 4):235-244.
[6] KIM S M,HOVY E. Automatic detection of opinion bearing words and sentences[C]. Berlin: Proceedings of the International Joint Conference on Natural Language Processing,2005.
[7] KIM S M ,HOVY E. Identifying and analyzing judgment opinions[C]. Proceedings of the Joint Human Language Technology/North American Chapter of the ACL Conference,2006:200-207.
[8] BENGIO Y,DUCHARME R,VINCENT P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research,2003,3:1137-1155.
[9] MIKOLOV T,SUTSKEVER I,CHEN K,et al. Distributed representations of words and phrases and their compositionality [C]. Proc of the NIPS,2013:3111-3119.
[10] KIM Y. Convolutional neural networks for sentence classification[C]. Proc of the EMNL,2014.
[11] 梁軍,柴玉梅,原慧斌,等. 基于深度學習的微博情感分析[J]. 中文信息學報, 2014,28(5):155-161.
[12] 肖江,丁星,何榮杰. 基于領域情感詞典的中文微博情感分析[J]. 電子設計工程,2015 (12): 18-21.
[13] 陳曉東. 基于情感詞典的中文微博情感傾向分析研究[D]. 武漢:華中科技大學,2012.
[14] CATAL C, NANGIR M. A sentiment classification model based on multiple classifiers[J]. Applied Soft Computing,2017(50): 135-141.
[15] LIU S, LI F, LI F, et al. Adaptive co-training SVM for sentiment classification on tweets[C]. Proc of ACM International Conference on Information & Knowledge Management, 2013: 2079-2088.
[16] LIU P,MENG H.SeemGo:conditional random fields labeling and maximum
entropy classification for aspect based sentiment analysis[C]. Proc of International Workshop on Semantic Evaluation,2014:527-531.
[17] 李陽輝,謝明,易陽. 基于深度學習的社交網絡平臺細粒度情感分析[J]. 計算機應用研究,2017,34(3):743-747.
[18] TURIAN J,RATINOV L,BENGIO Y. Word representations:a simple and general method for semi-supervised learning[C]. Proceedings of the Meeting of the Association for Computational Linguistics,2010:384-394.
[19] COLLOBERT R,WESTON J,BOTTOU L,et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research,2011,12(1):2493-2537.
[20] HUANG E H,SOCHER R,MANNIng C D,et al. Improving word representations via global context and multiple word prototypes[C]. Meeting of the Association for Computational Linguistics,2012:873-882.
(責任編輯:何 麗)
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
科學與財富(2016年28期)2016-10-14 21:19:17
